

CAP թեորեմը բաշխված համակարգերի տեսության հիմնաքարն է: Իհարկե, դրա շուրջ հակասությունները չեն մարում. դրանում տեղ գտած սահմանումները կանոնական չեն, և չկա խիստ ապացույց... Այնուամենայնիվ, ամուր կանգնելով առօրյա ողջախոհության դիրքերի վրա՝ մենք ինտուիտիվ հասկանում ենք, որ թեորեմը ճշմարիտ է:

Միակ բանը, որ ակնհայտ չէ, դա «P» տառի իմաստն է։ Երբ կլաստերը բաժանվում է, այն որոշում է՝ չպատասխանել մինչև քվորումի հասնելը, թե՞ հետ տալ առկա տվյալները: Կախված այս ընտրության արդյունքներից՝ համակարգը դասակարգվում է որպես CP կամ AP: Cassandra-ն, օրինակ, կարող է իրեն պահել ցանկացած կերպ՝ կախված ոչ թե կլաստերի կարգավորումներից, այլ յուրաքանչյուր կոնկրետ հարցումի պարամետրերից: Բայց եթե համակարգը «P» չէ, և այն պառակտվում է, ապա ի՞նչ։
Այս հարցի պատասխանը որոշ չափով անսպասելի է. CA կլաստերը չի կարող բաժանվել:
Ինչպիսի՞ կլաստեր է սա, որը չի կարող բաժանվել:
Նման կլաստերի էական ատրիբուտը տվյալների պահպանման համատեղ համակարգն է: Դեպքերի մեծ մասում սա նշանակում է կապ SAN-ի միջոցով, ինչը սահմանափակում է CA լուծումների օգտագործումը միայն խոշոր ձեռնարկությունների համար, որոնք կարող են պահպանել SAN ենթակառուցվածք: Որպեսզի մի քանիսը սերվերներ Նույն տվյալների հետ աշխատելու համար անհրաժեշտ է կլաստերային ֆայլային համակարգ: Նման ֆայլային համակարգերը հասանելի են HPE (CFS), Veritas (VxCFS) և IBM (GPFS) պորտֆելներում:
Oracle RAC
«Իրական կիրառական կլաստեր» տարբերակն առաջին անգամ հայտնվել է 2001 թվականին՝ Oracle 9i-ի թողարկմամբ։ Նման կլաստերում բազմաթիվ օրինակներ սերվեր աշխատել նույն տվյալների բազայի հետ։
Oracle-ը կարող է աշխատել ինչպես կլաստերային ֆայլային համակարգի, այնպես էլ սեփական լուծումների հետ՝ ASM, Ավտոմատ պահպանման կառավարում:
Յուրաքանչյուր օրինակ պահում է իր սեփական օրագիրը: Գործարքը կատարվում և կատարվում է մեկ ատյանի կողմից: Եթե օրինակը ձախողվում է, գոյատևած կլաստերային հանգույցներից մեկը (օրինակները) կարդում է իր գրանցամատյանը և վերականգնում կորցրած տվյալները՝ դրանով իսկ ապահովելով հասանելիությունը:
Բոլոր ատյանները պահպանում են իրենց սեփական քեշը, և նույն էջերը (բլոկները) կարող են լինել միաժամանակ մի քանի օրինակների քեշում։ Ավելին, եթե մի օրինակին անհրաժեշտ է էջ, և այն գտնվում է մեկ այլ օրինակի քեշում, այն կարող է ստանալ իր հարևանից՝ օգտագործելով քեշի միաձուլման մեխանիզմը՝ սկավառակից կարդալու փոխարեն։
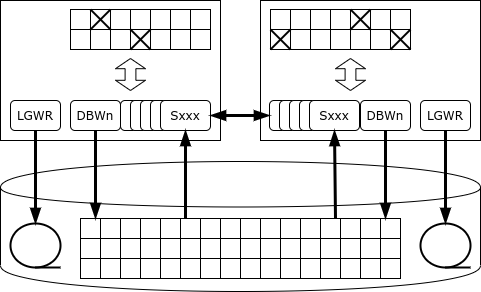
Բայց ինչ է տեղի ունենում, եթե դեպքերից մեկը պետք է փոխի տվյալները:
Oracle-ի առանձնահատկությունն այն է, որ այն չունի հատուկ կողպման ծառայություն. եթե սերվերը ցանկանում է կողպել տողը, ապա կողպման գրառումը տեղադրվում է անմիջապես հիշողության էջում, որտեղ գտնվում է կողպված տողը: Այս մոտեցման շնորհիվ Oracle-ը մոնոլիտ տվյալների շտեմարանների մեջ կատարողականի առաջատարն է. կողպման ծառայությունը երբեք չի դառնում խոչընդոտ: Բայց կլաստերի կոնֆիգուրացիայի դեպքում նման ճարտարապետությունը կարող է հանգեցնել ցանցի ինտենսիվ տրաֆիկի և փակուղիների:
Երբ գրառումը կողպված է, օրինակը տեղեկացնում է բոլոր մյուս դեպքերին, որ էջը, որը պահում է այդ գրառումը, ունի բացառիկ պահում: Եթե մեկ այլ օրինակ պետք է փոխի գրառումը նույն էջում, այն պետք է սպասի, մինչև էջի փոփոխությունները կատարվեն, այսինքն՝ փոփոխության տեղեկատվությունը գրվի սկավառակի վրա գտնվող ամսագրում (և գործարքը կարող է շարունակվել): Կարող է պատահել նաև, որ էջը հաջորդաբար փոխվի մի քանի օրինակով, իսկ հետո էջը սկավառակի վրա գրելիս պետք է պարզեք, թե ով է պահում այս էջի ընթացիկ տարբերակը:
Միևնույն էջերի պատահական թարմացումը տարբեր RAC հանգույցներում հանգեցնում է տվյալների բազայի կատարողականի կտրուկ նվազմանը, այն աստիճանի, որ կլաստերի կատարողականը կարող է ավելի ցածր լինել, քան մեկ օրինակում:
Oracle RAC-ի ճիշտ օգտագործումը տվյալների ֆիզիկապես բաժանումն է (օրինակ՝ օգտագործելով բաժանված աղյուսակի մեխանիզմը) և մուտք գործել բաժանմունքների յուրաքանչյուր խումբ հատուկ հանգույցի միջոցով: RAC-ի հիմնական նպատակը ոչ թե հորիզոնական մասշտաբն էր, այլ սխալների հանդուրժողականության ապահովումը:
Եթե հանգույցը դադարում է արձագանքել սրտի բաբախյունին, ապա այն հայտնաբերած հանգույցը սկզբում սկսում է քվեարկության ընթացակարգը սկավառակի վրա: Եթե բացակայող հանգույցն այստեղ նշված չէ, ապա հանգույցներից մեկն իր վրա է վերցնում տվյալների վերականգնման պատասխանատվությունը.
- «սառեցնում է» բոլոր էջերը, որոնք եղել են բացակայող հանգույցի քեշում.
- կարդում է բացակայող հանգույցի տեղեկամատյանները (կրկնել) և նորից կիրառում այս տեղեկամատյաններում գրանցված փոփոխությունները՝ միաժամանակ ստուգելով, թե արդյոք այլ հանգույցներում կան փոփոխվող էջերի ավելի վերջին տարբերակները.
- հետ է վերադարձնում սպասվող գործարքները:
Հանգույցների միջև անցումը պարզեցնելու համար Oracle-ն ունի ծառայության հայեցակարգ՝ վիրտուալ օրինակ: Օրինակը կարող է սպասարկել մի քանի ծառայություններ, իսկ ծառայությունը կարող է շարժվել հանգույցների միջև: Տվյալների բազայի որոշակի հատվածին սպասարկող հավելվածի օրինակը (օրինակ՝ հաճախորդների խումբ) աշխատում է մեկ ծառայության հետ, և տվյալների բազայի այս մասի համար պատասխանատու ծառայությունը տեղափոխվում է մեկ այլ հանգույց, երբ հանգույցը ձախողվում է։
IBM Pure Data Systems գործարքների համար
DBMS-ի կլաստերային լուծումը հայտնվեց Blue Giant պորտֆելում 2009 թվականին: Գաղափարական առումով այն «սովորական» սարքավորումների վրա կառուցված զուգահեռ Sysplex կլաստերի իրավահաջորդն է: 2009-ին DB2 pureScale-ը թողարկվեց որպես ծրագրային փաթեթ, իսկ 2012-ին IBM-ն առաջարկեց մի սարք, որը կոչվում էր Pure Data Systems for Transactions: Այն չպետք է շփոթել Pure Data Systems for Analytics-ի հետ, որը ոչ այլ ինչ է, քան վերանվանված Netezza:
Առաջին հայացքից, pureScale ճարտարապետությունը նման է Oracle RAC-ին. նույն կերպ, մի քանի հանգույցներ միացված են տվյալների պահպանման ընդհանուր համակարգին, և յուրաքանչյուր հանգույց գործարկում է իր սեփական DBMS օրինակը՝ իր հիշողության տարածքներով և գործարքների մատյաններով: Բայց, ի տարբերություն Oracle-ի, DB2-ն ունի հատուկ կողպման ծառայություն, որը ներկայացված է db2LLM* գործընթացների մի շարքով: Կլաստերային կոնֆիգուրացիայի դեպքում այս ծառայությունը տեղադրվում է առանձին հանգույցի վրա, որը կոչվում է զուգավորում (CF) զուգահեռ Sysplex-ում և PowerHA՝ մաքուր տվյալների մեջ:
PowerHA-ն տրամադրում է հետևյալ ծառայությունները.
- կողպեքի կառավարիչ;
- գլոբալ բուֆերային քեշ;
- միջգործընթացային հաղորդակցության տարածքը.
PowerHA-ից տվյալների բազայի հանգույցներ և ետ փոխանցելու համար օգտագործվում է հեռավոր հիշողության հասանելիություն, ուստի կլաստերային փոխկապակցումը պետք է աջակցի RDMA արձանագրությանը: PureScale-ը կարող է օգտագործել ինչպես Infiniband-ը, այնպես էլ RDMA-ն Ethernet-ի միջոցով:
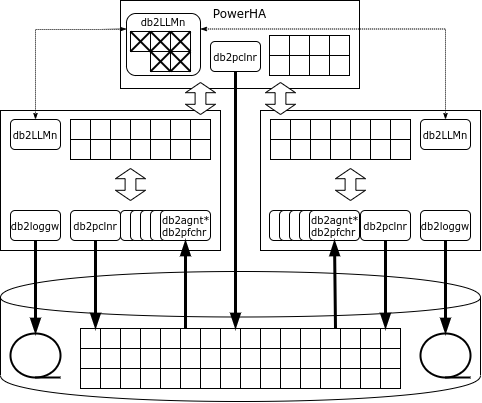
Եթե հանգույցին անհրաժեշտ է էջ, և այս էջը քեշում չէ, ապա հանգույցը պահանջում է էջը գլոբալ քեշում, և միայն եթե այն չկա, այն կարդում է սկավառակից: Ի տարբերություն Oracle-ի, հարցումը գնում է միայն PowerHA-ին, այլ ոչ թե հարևան հանգույցներին։
Եթե օրինակը պատրաստվում է փոխել տողը, այն կողպում է այն բացառիկ ռեժիմում, իսկ էջը, որտեղ գտնվում է տողը՝ ընդհանուր ռեժիմում: Բոլոր կողպեքները գրանցված են գլոբալ կողպեքի մենեջերում: Երբ գործարքն ավարտվում է, հանգույցը հաղորդագրություն է ուղարկում կողպեքի կառավարչին, որը պատճենում է փոփոխված էջը գլոբալ քեշում, ազատում է կողպեքները և անվավեր է դարձնում փոփոխված էջը այլ հանգույցների քեշում:
Եթե էջը, որում գտնվում է փոփոխված տողը, արդեն կողպված է, ապա կողպեքի կառավարիչը կկարդա փոփոխված էջը փոփոխություն կատարած հանգույցի հիշողությունից, կթողարկի կողպեքը, անվավեր կդարձնի փոփոխված էջը այլ հանգույցների քեշերում և տալ էջի կողպումը այն հանգույցին, որը խնդրել է այն:
«Կեղտոտ», այսինքն՝ փոխված, էջերը սկավառակի վրա կարելի է գրել ինչպես սովորական հանգույցից, այնպես էլ PowerHA-ից (castout):
Եթե pureScale հանգույցներից մեկը ձախողվի, վերականգնումը սահմանափակվում է միայն այն գործարքներով, որոնք դեռևս չեն ավարտվել ձախողման պահին. ավարտված գործարքներում այդ հանգույցի կողմից փոփոխված էջերը գտնվում են PowerHA-ի գլոբալ քեշում: Հանգույցը վերագործարկվում է կրճատված կազմաձևով կլաստերի սերվերներից մեկի վրա, հետ է գլորում սպասվող գործարքները և ազատում կողպեքները:
PowerHA-ն աշխատում է երկու սերվերի վրա, և հիմնական հանգույցը սինխրոն կերպով կրկնում է իր վիճակը: Եթե առաջնային PowerHA հանգույցը ձախողվի, ապա կլաստերը շարունակում է աշխատել պահեստային հանգույցի հետ:
Իհարկե, եթե դուք մուտք եք գործում տվյալների հավաքածու մեկ հանգույցի միջոցով, ապա կլաստերի ընդհանուր կատարումը ավելի բարձր կլինի: PureScale-ը նույնիսկ կարող է նկատել, որ տվյալների որոշակի տարածք մշակվում է մեկ հանգույցի կողմից, և այնուհետև այդ տարածքի հետ կապված բոլոր կողպեքները կմշակվեն լոկալ հանգույցի կողմից՝ առանց PowerHA-ի հետ շփվելու: Բայց հենց որ հավելվածը փորձի մուտք գործել այս տվյալներ այլ հանգույցի միջոցով, կենտրոնացված կողպման մշակումը կվերսկսվի:
IBM-ի ներքին թեստերը 90% կարդալու և 10% գրելու ծանրաբեռնվածության վրա, որը շատ նման է իրական արտադրության աշխատանքային ծանրաբեռնվածությանը, ցույց են տալիս գրեթե գծային մասշտաբավորում մինչև 128 հանգույց: Փորձարկման պայմանները, ցավոք, չեն բացահայտվում։
HPE NonStop SQL
Hewlett-Packard Enterprise-ի պորտֆելը նույնպես ունի իր բարձր հասանելի հարթակը: Սա NonStop հարթակն է, որը շուկա է թողարկվել 1976 թվականին Tandem Computers-ի կողմից: 1997 թվականին ընկերությունը ձեռք է բերվել Compaq-ի կողմից, որն իր հերթին միացվել է Hewlett-Packard-ին 2002 թվականին։
NonStop-ն օգտագործվում է կարևոր հավելվածներ ստեղծելու համար, օրինակ՝ HLR կամ բանկային քարտերի մշակում: Պլատֆորմն առաքվում է ծրագրային և ապարատային համալիրի (ապարատի) տեսքով, որը ներառում է հաշվողական հանգույցներ, տվյալների պահպանման համակարգ և կապի սարքավորումներ։ ServerNet ցանցը (ժամանակակից համակարգերում՝ Infiniband) ծառայում է ինչպես հանգույցների միջև փոխանակման, այնպես էլ տվյալների պահպանման համակարգ մուտք գործելու համար։
Համակարգի վաղ տարբերակներում օգտագործվում էին սեփական պրոցեսորներ, որոնք սինխրոնիզացված էին միմյանց հետ. բոլոր գործողությունները կատարվում էին սինխրոն մի քանի պրոցեսորների կողմից, և հենց որ պրոցեսորներից մեկը սխալ էր թույլ տալիս, այն անջատվում էր, իսկ երկրորդը շարունակում էր աշխատել: Հետագայում համակարգը անցավ սովորական պրոցեսորների (նախ MIPS, ապա Itanium և վերջապես x86), և համաժամացման համար սկսեցին օգտագործվել այլ մեխանիզմներ.
- հաղորդագրություններ. յուրաքանչյուր համակարգային գործընթաց ունի «ստվերային» երկվորյակ, որին ակտիվ գործընթացը պարբերաբար հաղորդագրություններ է ուղարկում իր կարգավիճակի մասին. եթե հիմնական գործընթացը ձախողվում է, ստվերային գործընթացը սկսում է աշխատել վերջին հաղորդագրությամբ որոշված պահից.
- քվեարկություն. պահեստավորման համակարգն ունի հատուկ ապարատային բաղադրիչ, որն ընդունում է մի քանի նույնական մուտքեր և կատարում դրանք միայն այն դեպքում, եթե մուտքերը համընկնում են. Ֆիզիկական համաժամացման փոխարեն պրոցեսորները գործում են ասինխրոն, և նրանց աշխատանքի արդյունքները համեմատվում են միայն մուտքի/ելքի պահերին։
1987 թվականից ի վեր հարաբերական DBMS-ն աշխատում է NonStop հարթակում՝ սկզբում SQL/MP, իսկ ավելի ուշ՝ SQL/MX:
Ամբողջ տվյալների բազան բաժանված է մասերի, և յուրաքանչյուր մաս պատասխանատու է Տվյալների հասանելիության կառավարչի (DAM) սեփական գործընթացի համար: Այն ապահովում է տվյալների գրանցման, քեշավորման և կողպման մեխանիզմներ: Տվյալների մշակումն իրականացվում է Executor Server Processes-ով, որոնք աշխատում են նույն հանգույցների վրա, ինչ համապատասխան տվյալների կառավարիչները: SQL/MX ժամանակացույցը առաջադրանքները բաժանում է կատարողների միջև և միավորում արդյունքները: Երբ անհրաժեշտ է կատարել համաձայնեցված փոփոխություններ, օգտագործվում է TMF (Transaction Management Facility) գրադարանի կողմից տրամադրված երկփուլ commit արձանագրությունը:
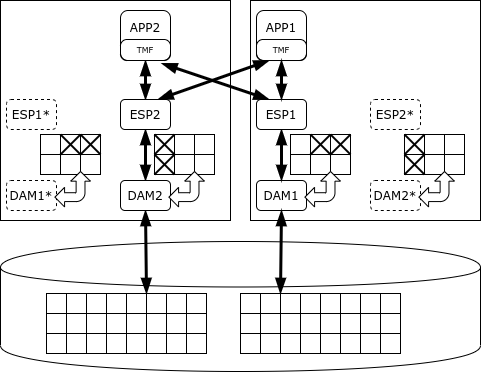
NonStop SQL-ը կարող է առաջնահերթություն տալ գործընթացներին, որպեսզի երկար վերլուծական հարցումները չխանգարեն գործարքների կատարմանը: Այնուամենայնիվ, դրա նպատակը հենց կարճ գործարքների մշակումն է, այլ ոչ թե վերլուծությունը։ Մշակողը երաշխավորում է NonStop կլաստերի հասանելիությունը հինգ «ինը» մակարդակում, այսինքն՝ պարապուրդը տարեկան ընդամենը 5 րոպե է։
ՍԱՊ ՀԱՆԱ
HANA DBMS-ի (1.0) առաջին կայուն թողարկումը տեղի ունեցավ 2010 թվականի նոյեմբերին, իսկ SAP ERP փաթեթը անցավ HANA-ի 2013 թվականի մայիսին: Պլատֆորմը հիմնված է գնված տեխնոլոգիաների վրա՝ TREX Search Engine (որոնում սյունակային պահեստում), P*TIME DBMS և MAX DB:
«ՀԱՆԱ» բառն ինքնին հապավում է՝ Բարձր արդյունավետության վերլուծական սարք: Այս DBMS-ը տրամադրվում է կոդի տեսքով, որը կարող է աշխատել ցանկացած x86 սերվերի վրա, սակայն արդյունաբերական տեղակայումները թույլատրվում են միայն հավաստագրված սարքավորումների վրա: Լուծումները հասանելի են HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi, NEC ընկերություններից: Lenovo-ի որոշ կոնֆիգուրացիաներ նույնիսկ թույլ են տալիս աշխատել առանց SAN-ի. ընդհանուր պահպանման համակարգի դերը խաղում է GPFS կլաստերը տեղական սկավառակների վրա:
Ի տարբերություն վերը թվարկված պլատֆորմների՝ HANA-ն հիշողության մեջ գտնվող DBMS է, այսինքն՝ առաջնային տվյալների պատկերը պահվում է RAM-ում, և միայն տեղեկամատյաններն ու պարբերական նկարները գրվում են սկավառակի վրա՝ աղետի դեպքում վերականգնելու համար:
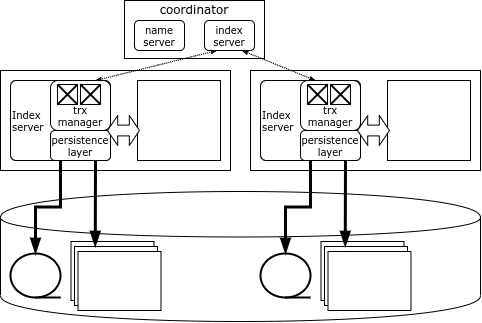
Յուրաքանչյուր HANA կլաստերային հանգույց պատասխանատու է տվյալների իր մասի համար, և տվյալների քարտեզը պահվում է հատուկ բաղադրիչում՝ Name Server-ում, որը գտնվում է համակարգող հանգույցում: Տվյալները չեն կրկնօրինակվում հանգույցների միջև: Կողպման տեղեկատվությունը նույնպես պահվում է յուրաքանչյուր հանգույցի վրա, սակայն համակարգն ունի փակուղու գլոբալ դետեկտոր:
Երբ HANA հաճախորդը միանում է կլաստերին, այն ներբեռնում է իր տոպոլոգիան և կարող է անմիջապես մուտք գործել ցանկացած հանգույց՝ կախված նրանից, թե ինչ տվյալներ են իրեն անհրաժեշտ: Եթե գործարքը ազդում է մեկ հանգույցի տվյալների վրա, ապա այն կարող է իրականացվել լոկալ այդ հանգույցի կողմից, բայց եթե մի քանի հանգույցների տվյալները փոխվում են, նախաձեռնող հանգույցը կապվում է համակարգող հանգույցի հետ, որը բացում և համակարգում է բաշխված գործարքը՝ կատարելով այն օգտագործելով օպտիմիզացված երկփուլ կատարման արձանագրություն:
Համակարգող հանգույցը կրկնօրինակվում է, ուստի, եթե համակարգողը ձախողվի, պահեստային հանգույցն անմիջապես վերցնում է իր վերահսկողությունը: Բայց եթե տվյալներ ունեցող հանգույցը ձախողվի, ապա դրա տվյալներին մուտք գործելու միակ միջոցը հանգույցը վերագործարկելն է: Որպես կանոն, HANA կլաստերները պահպանում են պահեստային սերվեր, որպեսզի հնարավորինս արագ վերագործարկեն կորցրած հանգույցը:
Source: www.habr.com
