

Հիշեցնենք, որ Elastic Stack-ը հիմնված է Elasticsearch ոչ հարաբերական տվյալների բազայի, Kibana վեբ ինտերֆեյսի և տվյալների հավաքիչների վրա (ամենահայտնի Logstash, տարբեր Beats, APM և այլն): Թվարկված արտադրանքի ամբողջ փաթեթի գեղեցիկ լրացումներից մեկը տվյալների վերլուծությունն է՝ օգտագործելով մեքենայական ուսուցման ալգորիթմներ: Հոդվածում մենք հասկանում ենք, թե որոնք են այս ալգորիթմները: Խնդրում եմ կատվի տակ:
Մեքենայի ուսուցումը shareware Elastic Stack-ի վճարովի հատկանիշն է և ներառված է X-Pack-ում: Այն օգտագործելու համար բավական է ակտիվացնել 30-օրյա փորձաշրջանը տեղադրումից հետո։ Փորձաշրջանի ավարտից հետո կարող եք աջակցություն խնդրել՝ այն թարմացնելու կամ բաժանորդագրություն գնելու համար: Բաժանորդագրության գինը հաշվարկվում է ոչ թե տվյալների քանակով, այլ օգտագործվող հանգույցների քանակով։ Ոչ, տվյալների քանակն ազդում է, իհարկե, պահանջվող հանգույցների քանակի վրա, բայց, այնուամենայնիվ, լիցենզավորման այս մոտեցումն ավելի մարդասիրական է ընկերության բյուջեի հետ կապված։ Եթե բարձր կատարողականության կարիք չկա, կարող եք գումար խնայել:
Elastic Stack-ում ML-ը գրված է C++-ով և աշխատում է JVM-ից դուրս, որտեղ աշխատում է ինքը Elasticsearch-ը: Այսինքն՝ պրոցեսը (ի դեպ, այն կոչվում է autodetect) սպառում է այն ամենը, ինչ JVM-ն չի կուլ տալիս։ Դեմո ստենդում սա այնքան էլ կարևոր չէ, բայց արդյունավետ միջավայրում կարևոր է առանձին հանգույցներ հատկացնել ML առաջադրանքների համար:
Մեքենայի ուսուցման ալգորիթմները բաժանվում են երկու կատեգորիայի и . Elastic Stack-ում ալգորիթմը «չվերահսկվող» կատեգորիայից է: Ըստ Դուք կարող եք տեսնել մեքենայական ուսուցման ալգորիթմների մաթեմատիկական ապարատը:
Մեքենայի ուսուցման ալգորիթմը վերլուծություն կատարելու համար օգտագործում է Elasticsearch ինդեքսներում պահվող տվյալները: Դուք կարող եք վերլուծության առաջադրանքներ ստեղծել ինչպես Kibana ինտերֆեյսից, այնպես էլ API-ի միջոցով: Եթե դուք դա անում եք Kibana-ի միջոցով, ապա ձեզ հարկավոր չէ որոշ բաներ իմանալ: Օրինակ՝ լրացուցիչ ինդեքսներ, որոնք ալգորիթմն օգտագործում է շահագործման ընթացքում։
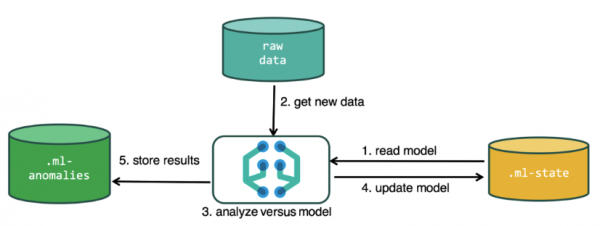
Վերլուծության գործընթացում օգտագործվող լրացուցիչ ցուցանիշներ.ml-state - տեղեկատվություն վիճակագրական մոդելների մասին (վերլուծության կարգավորումներ);
.ml-anomalies-* - ML ալգորիթմների արդյունքներ;
.ml-notifications — ծանուցման կարգավորումներ՝ հիմնված վերլուծության արդյունքների վրա:
Elasticsearch տվյալների բազայի տվյալների կառուցվածքը բաղկացած է ինդեքսներից և դրանցում պահվող փաստաթղթերից: Հարաբերական տվյալների բազայի համեմատ՝ ինդեքսը կարելի է համեմատել տվյալների բազայի սխեմայի հետ, իսկ փաստաթուղթը՝ աղյուսակի գրառումների հետ: Այս համեմատությունը պայմանական է և տրված է պարզեցնելու հետագա նյութի ըմբռնումը նրանց համար, ովքեր միայն լսել են Elasticsearch-ի մասին:
Նույն ֆունկցիոնալությունը հասանելի է API-ի միջոցով, ինչ վեբ ինտերֆեյսի միջոցով, այնպես որ հասկացությունների պարզության և հասկանալու համար մենք ցույց կտանք, թե ինչպես կարելի է կարգավորել Kibana-ի միջոցով: Ձախ կողմի մենյուում կա Machine Learning բաժինը, որտեղ կարող եք ստեղծել նոր աշխատանք (Աշխատանք): Kibana ինտերֆեյսում այն կարծես ստորև նկարում է: Այժմ մենք կվերլուծենք առաջադրանքի յուրաքանչյուր տեսակ և ցույց կտանք վերլուծության այն տեսակները, որոնք կարելի է կառուցել այստեղ:
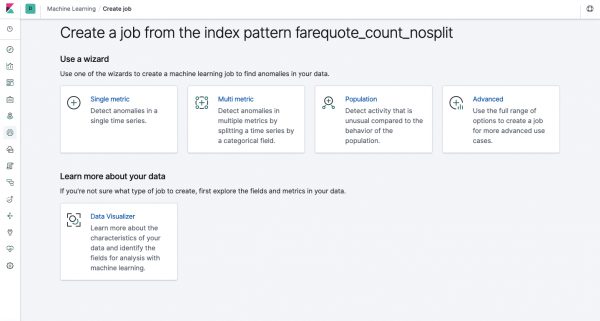
Single Metric - մեկ մետրիկի վերլուծություն, Multi Metric - երկու կամ ավելի ցուցանիշների վերլուծություն: Երկու դեպքում էլ յուրաքանչյուր մետրիկ վերլուծվում է մեկուսացված միջավայրում, այսինքն. Ալգորիթմը հաշվի չի առնում զուգահեռաբար վերլուծված չափումների վարքագիծը, ինչպես դա կարող է թվալ Multi Metric-ի դեպքում: Հաշվարկելու համար՝ հաշվի առնելով տարբեր չափումների հարաբերակցությունը, կարող եք կիրառել Բնակչության վերլուծությունը: Իսկ Advanced-ը ալգորիթմների ճշգրտում է՝ որոշակի առաջադրանքների համար լրացուցիչ տարբերակներով:
Մեկ մետրիկ
Մեկ չափման մեջ փոփոխությունները վերլուծելը ամենահեշտ բանն է այստեղ անել: Ստեղծել աշխատանք սեղմելուց հետո ալգորիթմը կփնտրի անոմալիաներ:
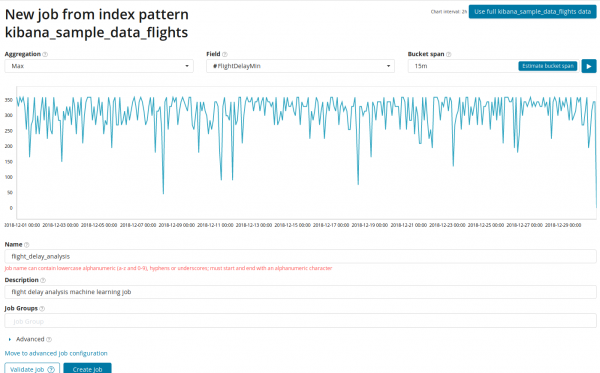
Ի դաշտում Ագրեգացիա դուք կարող եք ընտրել անոմալիաների որոնման մոտեցումը: Օրինակ, երբ Min բնորոշ արժեքներից ցածր արժեքները կհամարվեն աննորմալ: Ուտել Առավելագույն, բարձր միջին, ցածր, միջին, հստակ եւ ուրիշներ. Բոլոր գործառույթների նկարագրությունը կարելի է գտնել .
Ի դաշտում Դաշտ փաստաթղթում նշված է թվային դաշտը, ըստ որի մենք կիրականացնենք վերլուծությունը։
Ի դաշտում - բացերի հստակությունը ժամանակացույցի վրա, ըստ որի կիրականացվի վերլուծությունը: Դուք կարող եք վստահել ավտոմատացմանը կամ ընտրել ձեռքով: Ստորև բերված պատկերը ցույց է տալիս չափազանց ցածր հատիկավորության օրինակ. կարող եք բաց թողնել անոմալիան: Այս պարամետրով դուք կարող եք փոխել ալգորիթմի զգայունությունը անոմալիաների նկատմամբ:
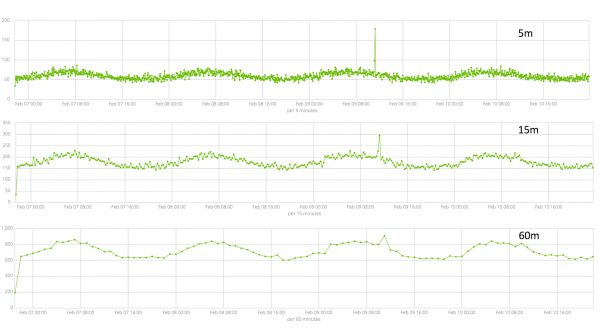
Հավաքված տվյալների տեւողությունը առանցքային բան է, որն ազդում է վերլուծության արդյունավետության վրա: Վերլուծության ընթացքում ալգորիթմը որոշում է կրկնվող բացերը, հաշվարկում է վստահության միջակայքը (հիմնական գծերը) և հայտնաբերում անոմալիաները՝ չափիչի սովորական վարքագծի անտիպ շեղումները: Պարզապես օրինակ.
Տվյալների փոքր հատվածի հիմնական գծերը.
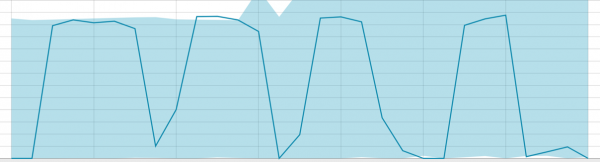
Երբ ալգորիթմը սովորելու բան ունի, ելակետային գծերն այսպիսի տեսք ունեն.
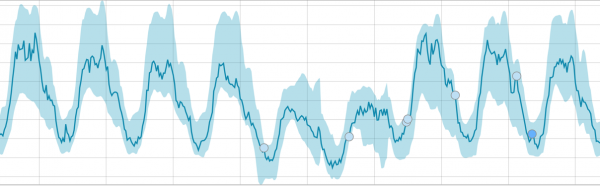
Առաջադրանքը սկսելուց հետո ալգորիթմը որոշում է նորմայից աննորմալ շեղումները և դասակարգում դրանք ըստ անոմալիայի հավանականության (համապատասխան պիտակի գույնը նշված է փակագծերում).
Զգուշացում (կապույտ)՝ 25-ից պակաս
Մինոր (դեղին)՝ 25-50
Մայոր (նարնջագույն)՝ 50-75
Կրիտիկական (կարմիր)՝ 75-100
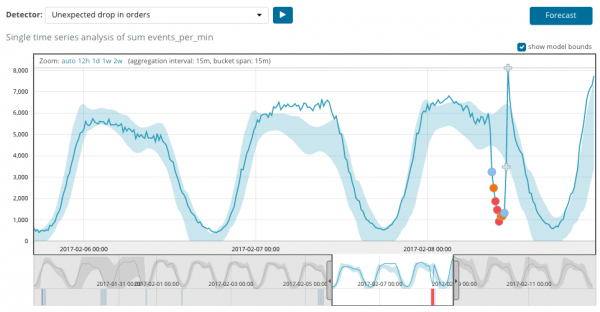
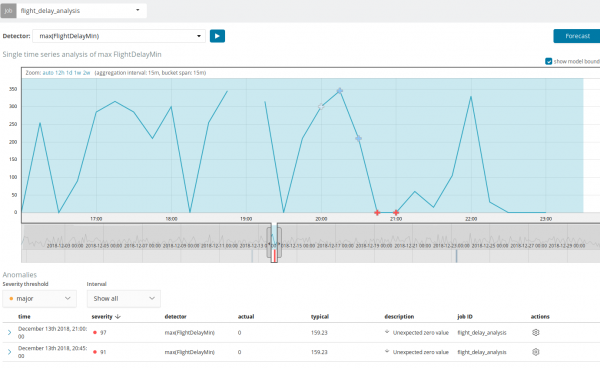
Ստորև բերված գրաֆիկը ցույց է տալիս հայտնաբերված անոմալիաների օրինակ:
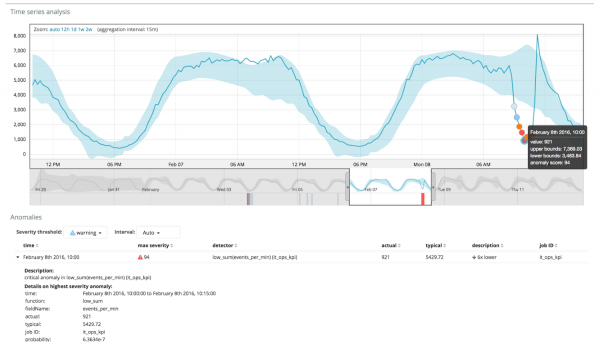
Այստեղ կարելի է տեսնել 94 թիվը, որը ցույց է տալիս անոմալիայի հավանականությունը։ Հասկանալի է, որ քանի որ արժեքը մոտ է 100-ին, ուրեմն ունենք անոմալիա։ Գրաֆիկի ներքևի սյունակը ցույց է տալիս մետրային արժեքի 0.000063634% նվազ հավանականությունը, որը հայտնվում է այնտեղ:
Բացի Կիբանայում անոմալիաներ որոնելուց, կարող եք կանխատեսել: Սա արվում է տարրականորեն և անոմալիաներով նույն ներկայացումից՝ կոճակը Կանխատեսում վերին աջ անկյունում։
Կանխատեսումը կազմված է մինչև 8 շաբաթ առաջ: Նույնիսկ եթե դուք իսկապես ցանկանում եք, այլևս չեք կարող դիզայնով:
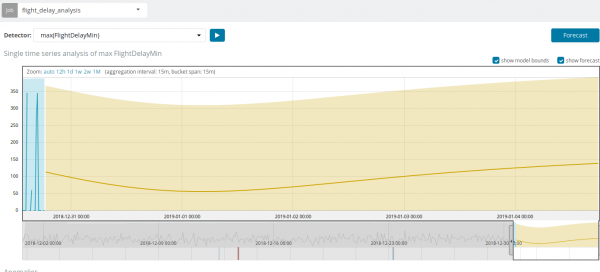
Որոշ իրավիճակներում կանխատեսումը շատ օգտակար կլինի, օրինակ՝ ենթակառուցվածքի վրա օգտագործողի բեռի մոնիտորինգի ժամանակ:
Մուլտիմետրիկ
Եկեք անցնենք Elastic Stack-ի ML-ի հաջորդ հատկանիշին՝ մեկ խմբաքանակում մի քանի չափումների վերլուծություն: Բայց դա չի նշանակում, որ մեկ մետրիկի կախվածությունը մյուսից կվերլուծվի։ Սա նույնն է, ինչ Single Metric-ը միայն մի քանի չափորոշիչներով մեկ էկրանին՝ մեկի վրա մյուսի վրա ազդեցության հեշտ համեմատելու համար: Մեկ մետրի մյուսից կախվածության վերլուծության մասին կխոսենք Բնակչություն մասում։
Multi Metric-ով քառակուսու վրա սեղմելուց հետո կհայտնվի կարգավորումներով պատուհան: Անդրադառնանք դրանց ավելի մանրամասն:
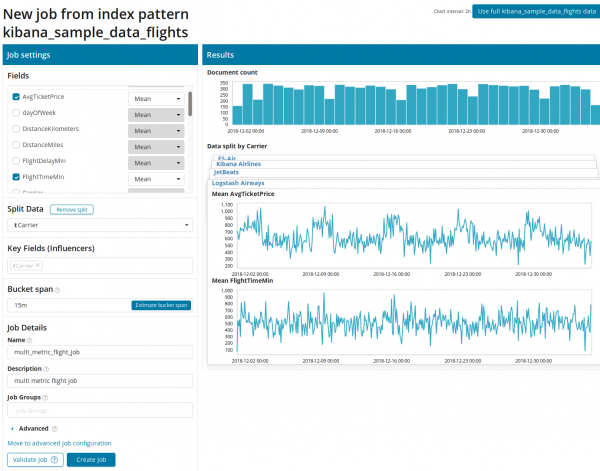
Նախ անհրաժեշտ է ընտրել վերլուծության համար նախատեսված դաշտերը և դրանց վերաբերյալ տվյալների համախմբումը: Այստեղ միավորման տարբերակները նույնն են, ինչ Single Metric-ի համար (Առավելագույն, բարձր միջին, ցածր, միջին, հստակ եւ ուրիշներ). Ավելին, տվյալները, ցանկության դեպքում, բաժանվում են դաշտերից մեկի (դաշտ Տրոհված տվյալներ) Օրինակում մենք դա արեցինք ամբողջ դաշտում OriginAirportID. Ուշադրություն դարձրեք, որ աջ կողմում գտնվող չափման գրաֆիկն այժմ ներկայացված է որպես գրաֆիկների մի շարք:
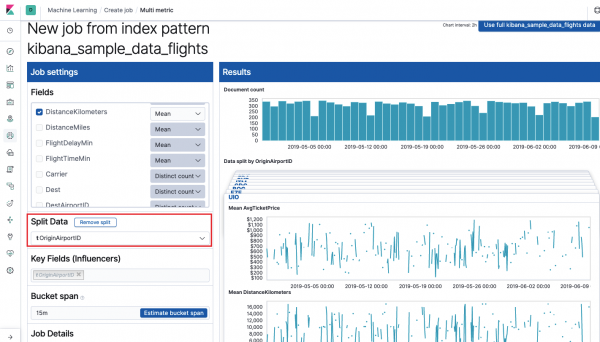
Դաշտ Հիմնական ոլորտները (ազդեցիկները) ուղղակիորեն ազդում է հայտնաբերված անոմալիաների վրա. Լռելյայն, միշտ կլինի առնվազն մեկ արժեք, և դուք կարող եք ավելացնել ավելին: Ալգորիթմը հաշվի կառնի այս դաշտերի ազդեցությունը վերլուծության մեջ և ցույց կտա ամենա«ազդեցիկ» արժեքները։
Գործարկումից հետո Kibana ինտերֆեյսում կհայտնվի հետևյալ նկարը.
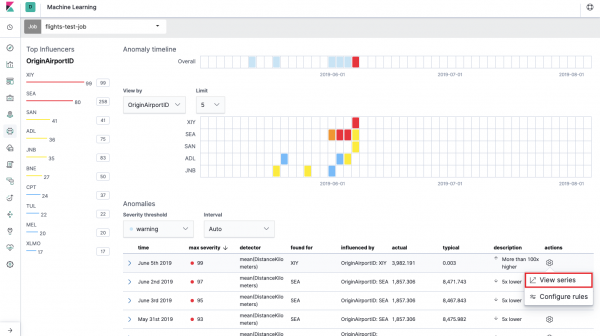
Սա այսպես կոչված. Անոմալիաների ջերմային քարտեզ յուրաքանչյուր դաշտի արժեքի համար OriginAirportIDորը մենք նշել ենք Տրոհված տվյալներ. Ինչպես Single Metric-ի դեպքում, գույնը ցույց է տալիս արտանետման մակարդակը: Հարմար է նմանատիպ վերլուծություն անել, օրինակ, աշխատատեղերում՝ հետևելու նրանց, որտեղ կասկածելիորեն շատ թույլտվություններ կան և այլն։ Մենք արդեն գրել ենք , որը նույնպես կարելի է հավաքել և վերլուծել այստեղ։
Ջերմային քարտեզի ներքևում ներկայացված է անոմալիաների ցանկը, որոնցից յուրաքանչյուրից կարող եք անցնել Single Metric տեսք՝ մանրամասն վերլուծության համար:
Բնակչություն
Տարբեր չափումների միջև փոխկապակցվածության մեջ անոմալիաներ փնտրելու համար Elastic Stack-ն ունի մասնագիտացված Բնակչության վերլուծություն: Հենց դրա օգնությամբ կարելի է անոմալ արժեքներ փնտրել սերվերի աշխատանքի մեջ՝ համեմատած մնացածի հետ, երբ, օրինակ, թիրախային համակարգին ուղղված հարցումների քանակի ավելացում կա:
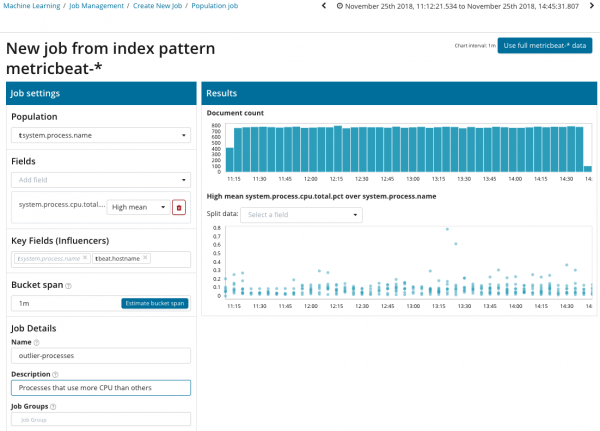
Այս նկարազարդման մեջ Բնակչության դաշտը ցույց է տալիս այն արժեքը, որին կվերաբերվեն վերլուծված չափումները: Այս դեպքում գործընթացի անվանումն է. Արդյունքում, մենք կտեսնենք, թե ինչպես է պրոցեսորային բեռնվածությունը յուրաքանչյուր գործընթացի վրա ազդել միմյանց վրա:
Խնդրում ենք նկատի ունենալ, որ վերլուծված տվյալների սյուժեն տարբերվում է Single Metric-ի և Multi Metric-ի դեպքերից: Դա արվում է Կիբանայում նախագծով, որպեսզի բարելավվի վերլուծված տվյալների արժեքների բաշխման ընկալումը:
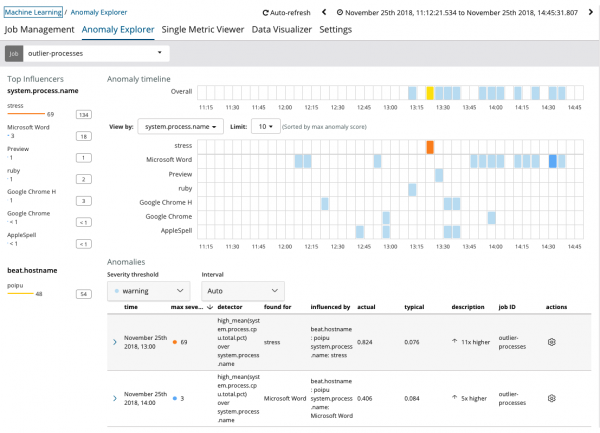
Գրաֆիկը ցույց է տալիս, որ գործընթացն աննորմալ է վարվել շեշտ (ի դեպ, գեներացվել է հատուկ օգտակար ծառայության կողմից) սերվերի վրա poipu, որն ազդել է (կամ պարզվել է, որ ազդեցիկ է) այս անոմալիայի առաջացման վրա։
Առաջադեմ
Վերլուծություն նուրբ թյունինգով: Kibana-ում Ընդլայնված վերլուծությամբ լրացուցիչ կարգավորումներ են հայտնվում: Ստեղծման ընտրացանկում «Ընդլայնված» սալիկի վրա սեղմելուց հետո հայտնվում է հետևյալ ներդիրային պատուհանը: ներդիր Աշխատանք մանրամասները միտումնավոր բաց թողնված, կան հիմնական պարամետրեր, որոնք ուղղակիորեն կապված չեն վերլուծության տեղադրման հետ:
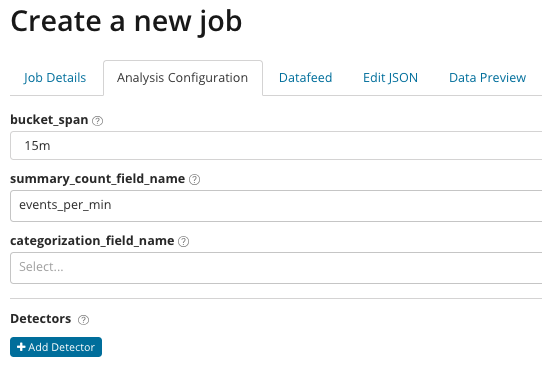
В summary_count_field_name ընտրովի, դուք կարող եք նշել դաշտի անվանումը ագրեգացված արժեքներ պարունակող փաստաթղթերից: Այս օրինակում իրադարձությունների քանակը րոպեում: IN նշում է փաստաթղթից դաշտի արժեքի անվանումը, որը պարունակում է որոշակի փոփոխական արժեք: Այս դաշտի դիմակով դուք կարող եք վերլուծված տվյալները բաժանել ենթաբազմությունների: Ուշադրություն դարձրեք կոճակին Ավելացնել դետեկտոր նախորդ նկարազարդման մեջ: Ստորև ներկայացված է այս կոճակը սեղմելու արդյունքը:
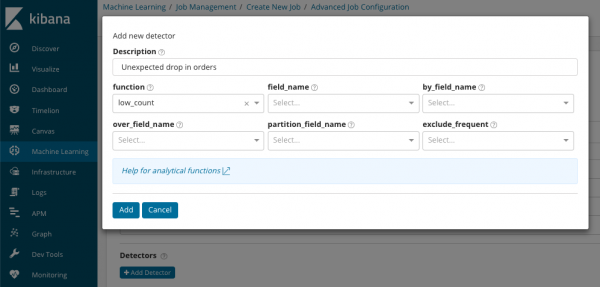
Ահա կարգավորումների լրացուցիչ բլոկ՝ որոշակի առաջադրանքի համար անոմալիաների դետեկտորը կարգավորելու համար: Մենք նախատեսում ենք վերլուծել հատուկ օգտագործման դեպքերը (հատկապես անվտանգության դեպքերը) հաջորդ հոդվածներում: Օրինակ, դեպքի ուսումնասիրություններից մեկը։ Այն կապված է հազվադեպ հանդիպող արժեքների որոնման հետ և իրականացվում է .
Ի դաշտում ֆունկցիա դուք կարող եք ընտրել որոշակի գործառույթ՝ անոմալիաներ որոնելու համար: Բացառությամբ հազվադեպ, կան մի քանի հետաքրքիր գործառույթներ. . Նրանք բացահայտում են համապատասխանաբար օրվա կամ շաբաթվա ընթացքում չափումների վարքագծի անոմալիաները: Այլ վերլուծության գործառույթներ .
В դաշտի_անուն նշվում է փաստաթղթի դաշտը, որով կիրականացվի վերլուծությունը։ Ըստ_դաշտի_անունի կարող է օգտագործվել այստեղ նշված փաստաթղթի դաշտի յուրաքանչյուր առանձին արժեքի համար վերլուծության արդյունքները առանձնացնելու համար: Եթե լրացնել over_field_name մենք ստանում ենք բնակչության վերլուծությունը, որը մենք դիտարկել ենք վերևում: Եթե նշեք արժեքը partition_field_name, այնուհետև յուրաքանչյուր արժեքի համար առանձին ելակետային գծեր կհաշվարկվեն փաստաթղթի այս դաշտի համար (օրինակ, սերվերի անունը կամ սերվերի վրա գտնվող պրոցեսը կարող է որպես արժեք գործել): IN exclude_frequent կարող է ընտրել բոլորը կամ ոչ մեկը, ինչը կնշանակի բացառել (կամ ներառել) փաստաթղթի դաշտի ընդհանուր արժեքները:
Հոդվածում մենք փորձեցինք առավել հակիրճ պատկերացում տալ Elastic Stack-ում մեքենայական ուսուցման հնարավորությունների մասին, դեռ շատ մանրամասներ կան կուլիսներում: Պատմեք մեզ մեկնաբանություններում, թե ինչ գործեր եք կարողացել լուծել Elastic Stack-ի օգնությամբ և ինչ խնդիրների համար եք այն օգտագործում։ Մեզ հետ կապվելու համար կարող եք օգտագործել անձնական հաղորդագրություններ Habré կամ .
Source: www.habr.com
