

Հայտարարություն
Գործընկերներ, ամառվա կեսերին ես նախատեսում եմ հրապարակել հերթական հոդվածաշարը հերթագրման համակարգերի նախագծման վերաբերյալ. «VTrade Experiment»-ը առևտրային համակարգերի համար շրջանակ գրելու փորձ: Սերիան կուսումնասիրի բորսայի, աճուրդի և խանութի կառուցման տեսությունն ու պրակտիկան: Հոդվածի վերջում ես ձեզ հրավիրում եմ քվեարկել ձեզ ամենաշատ հետաքրքրող թեմաների օգտին:

Սա Erlang/Elixir-ում բաշխված ռեակտիվ հավելվածների վերաբերյալ շարքի վերջին հոդվածն է: IN դուք կարող եք գտնել ռեակտիվ ճարտարապետության տեսական հիմունքները: ցույց է տալիս նման համակարգերի կառուցման հիմնական օրինաչափությունները և մեխանիզմները:
Այսօր մենք կբարձրացնենք կոդի բազայի և ընդհանրապես նախագծերի մշակման խնդիրները։
Ծառայությունների կազմակերպում
Իրական կյանքում, ծառայություն մշակելիս, դուք հաճախ ստիպված եք լինում համատեղել մի քանի փոխազդեցության օրինաչափություններ մեկ կարգավորիչում: Օրինակ՝ օգտվողների ծառայությունը, որը լուծում է նախագծի օգտատերերի պրոֆիլների կառավարման խնդիրը, պետք է պատասխանի req-resp հարցումներին և pub-sub-ի միջոցով զեկուցի պրոֆիլի թարմացումները։ Այս դեպքը բավականին պարզ է՝ հաղորդագրությունների ետևում կա մեկ վերահսկիչ, որն իրականացնում է ծառայության տրամաբանությունը և հրապարակում թարմացումները:
Իրավիճակն ավելի է բարդանում, երբ մեզ անհրաժեշտ է իրականացնել անսարքությունների հանդուրժող բաշխված ծառայություն: Եկեք պատկերացնենք, որ օգտվողների պահանջները փոխվել են.
- այժմ ծառայությունը պետք է մշակի հարցումները 5 կլաստերային հանգույցների վրա,
- կարողանալ կատարել ֆոնային մշակման առաջադրանքներ,
- և նաև կարող է դինամիկ կառավարել բաժանորդագրությունների ցուցակները պրոֆիլի թարմացումների համար:
Նշում: Մենք չենք դիտարկում հետևողական պահպանման և տվյալների կրկնօրինակման հարցը: Ենթադրենք, որ այս խնդիրները լուծվել են ավելի վաղ, և համակարգն արդեն ունի հուսալի և մասշտաբային պահեստային շերտ, և մշակողները ունեն դրա հետ փոխազդելու մեխանիզմներ:
Օգտատերերի ծառայության պաշտոնական նկարագրությունը դարձել է ավելի բարդ: Ծրագրավորողի տեսանկյունից փոփոխությունները նվազագույն են՝ կապված հաղորդագրությունների օգտագործման հետ: Առաջին պահանջը բավարարելու համար մենք պետք է կարգավորենք հավասարակշռումը req-resp փոխանակման կետում:
Ֆոնային առաջադրանքները մշակելու պահանջը հաճախ է առաջանում: Օգտատերերի մոտ դա կարող է լինել օգտատիրոջ փաստաթղթերի ստուգումը, ներբեռնված մուլտիմեդիայի մշակումը կամ տվյալների համաժամացումը սոցիալական լրատվամիջոցների հետ: ցանցեր։ Այս առաջադրանքները պետք է ինչ-որ կերպ բաշխվեն կլաստերի ներսում և վերահսկվեն կատարման առաջընթացը: Հետևաբար, մենք ունենք լուծման երկու տարբերակ. կա՛մ օգտագործեք նախորդ հոդվածի առաջադրանքների բաշխման ձևանմուշը, կա՛մ, եթե այն չի համապատասխանում, գրեք հատուկ առաջադրանքների ժամանակացույց, որը կկառավարի պրոցեսորների լողավազանը մեզ անհրաժեշտ ձևով:
3-րդ կետը պահանջում է pub-sub կաղապարի ընդլայնում: Իսկ իրականացման համար փաբ-ենթափոխանակման կետ ստեղծելուց հետո մենք պետք է լրացուցիչ գործարկենք այս կետի վերահսկիչը մեր ծառայության շրջանակներում։ Այսպիսով, մենք կարծես բաժանորդագրությունների և բաժանորդագրությունների մշակման տրամաբանությունը հաղորդագրությունների շերտից տեղափոխում ենք օգտատերերի ներդրում:
Արդյունքում, խնդրի տարրալուծումը ցույց տվեց, որ պահանջներին բավարարելու համար մենք պետք է գործարկենք ծառայության 5 օրինակ տարբեր հանգույցների վրա և ստեղծենք լրացուցիչ սուբյեկտ՝ pub-sub վերահսկիչ, որը պատասխանատու է բաժանորդագրության համար։
5 կարգավորիչներ գործարկելու համար ձեզ հարկավոր չէ փոխել ծառայության կոդը: Միակ լրացուցիչ գործողությունը փոխանակման կետում հավասարակշռման կանոնների սահմանումն է, որի մասին կխոսենք մի փոքր ուշ:
Կա նաև լրացուցիչ բարդություն. pub-sub վերահսկիչը և հատուկ առաջադրանքների ժամանակացույցը պետք է աշխատեն մեկ օրինակով: Կրկին, հաղորդագրությունների ծառայությունը, որպես հիմնարար ծառայություն, պետք է ապահովի առաջնորդ ընտրելու մեխանիզմ։
Առաջնորդի ընտրություն
Բաշխված համակարգերում առաջնորդի ընտրությունը որոշակի բեռի բաշխված մշակման պլանավորման համար պատասխանատու մեկ գործընթաց նշանակելու ընթացակարգ է:
Համակարգերում, որոնք հակված չեն կենտրոնացման, օգտագործվում են ունիվերսալ և կոնսենսուսի վրա հիմնված ալգորիթմներ, ինչպիսիք են paxos-ը կամ raft-ը:
Քանի որ հաղորդագրությունների փոխանակումը բրոքեր է և կենտրոնական տարր, այն գիտի ծառայության բոլոր վերահսկիչների՝ թեկնածու առաջնորդների մասին: Հաղորդագրությունները կարող են ղեկավար նշանակել առանց քվեարկության:
Փոխանակման կետին գործարկելուց և միանալուց հետո բոլոր ծառայությունները ստանում են համակարգային հաղորդագրություն #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers}. Եթե LeaderPid հետ pid ընթացիկ ընթացքը, այն նշանակվում է որպես առաջատար, և ցուցակը Servers ներառում է բոլոր հանգույցները և դրանց պարամետրերը:
Այս պահին հայտնվում է նորը, և աշխատանքային կլաստերային հանգույցն անջատված է, բոլոր սպասարկման կարգավորիչները ստանում են #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} и #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} համապատասխանաբար:
Այսպիսով, բոլոր բաղադրիչները տեղյակ են բոլոր փոփոխություններին, և կլաստերը երաշխավորված է, որ ցանկացած պահի կունենա մեկ առաջնորդ:
Միջնորդներ
Բաշխված մշակման բարդ գործընթացներ իրականացնելու, ինչպես նաև գոյություն ունեցող ճարտարապետության օպտիմալացման խնդիրներում հարմար է օգտագործել միջնորդներ:
Որպեսզի չփոխեք ծառայության կոդը և չլուծեք, օրինակ, հաղորդագրությունների լրացուցիչ մշակման, երթուղավորման կամ գրանցման խնդիրները, կարող եք ծառայությունից առաջ ակտիվացնել պրոքսի կառավարիչը, որը կկատարի բոլոր լրացուցիչ աշխատանքները:
Pub-sub-ի օպտիմալացման դասական օրինակ է բաշխված հավելվածը բիզնեսի միջուկով, որը ստեղծում է թարմացման իրադարձություններ, ինչպիսիք են շուկայում գների փոփոխությունները, և մուտքի շերտ՝ N սերվերներ, որոնք ապահովում են վեբ-հաճախորդների համար վեբսոկետային API:
Եթե դուք որոշում եք առջևում, ապա հաճախորդների սպասարկումն ունի հետևյալ տեսքը.
- հաճախորդը կապեր է հաստատում հարթակի հետ: Սերվերի այն կողմում, որը դադարեցնում է տրաֆիկը, գործարկվում է այս կապը սպասարկելու գործընթաց:
- Ծառայության գործընթացի համատեքստում տեղի է ունենում թույլտվություն և թարմացումների բաժանորդագրություն: Գործընթացը թեմաների համար անվանում է բաժանորդագրության մեթոդ:
- Երբ միջուկում ստեղծվում է իրադարձություն, այն փոխանցվում է կապերը սպասարկող գործընթացներին:
Պատկերացնենք, որ «նորություններ» թեմայի 50000 բաժանորդ ունենք։ Բաժանորդները հավասարաչափ բաշխված են 5 սերվերների վրա: Արդյունքում փոխանակման կետ ժամանող յուրաքանչյուր թարմացում կկրկնօրինակվի 50000 անգամ՝ 10000 անգամ յուրաքանչյուր սերվերի վրա՝ ըստ դրա բաժանորդների քանակի: Շատ արդյունավետ սխեմա չէ, չէ՞:
Իրավիճակը բարելավելու համար ներկայացնենք վստահված անձ, որն ունի փոխանակման կետի նույն անվանումը։ Համաշխարհային անունների գրանցողը պետք է կարողանա վերադարձնել ամենամոտ գործընթացը անունով, սա կարևոր է:
Եկեք գործարկենք այս պրոքսին մուտքի շերտի սերվերների վրա, և մեր բոլոր գործընթացները, որոնք սպասարկում են websocket api-ին, կբաժանորդագրվեն դրան, և ոչ թե միջուկի սկզբնական pub-sub փոխանակման կետին: Proxy-ը բաժանորդագրվում է հիմնականին միայն եզակի բաժանորդագրության դեպքում և կրկնօրինակում է մուտքային հաղորդագրությունը իր բոլոր բաժանորդներին:
Արդյունքում միջուկի և մուտքի սերվերների միջև կուղարկվի 5 հաղորդագրություն՝ 50000-ի փոխարեն։
Ուղղորդում և հավասարակշռում
Req-Resp
Ընթացիկ հաղորդագրությունների իրականացման մեջ կա հարցումների բաշխման 7 ռազմավարություն.
default. Հարցումն ուղարկվում է բոլոր կարգավարներին:round-robin. Հարցումները թվարկվում և ցիկլային կերպով բաշխվում են վերահսկիչների միջև:consensus. Վերահսկիչները, որոնք սպասարկում են ծառայությունը, բաժանվում են առաջնորդների և ստրուկների: Հարցումները ուղարկվում են միայն առաջնորդին:consensus & round-robin. Խումբն ունի ղեկավար, սակայն հարցումները բաշխվում են բոլոր անդամների միջև:sticky. Հեշ ֆունկցիան հաշվարկվում և վերագրվում է կոնկրետ մշակողին: Այս ստորագրությամբ հետագա հարցումները գնում են նույն մշակողին:sticky-fun. Փոխանակման կետը սկզբնավորելիս հեշի հաշվարկման ֆունկցիան էstickyհավասարակշռում.fun. Կպչուն զվարճանքի նման, միայն դուք կարող եք լրացուցիչ վերահղել, մերժել կամ նախապես մշակել այն:
Բաշխման ռազմավարությունը սահմանվում է, երբ փոխանակման կետը սկզբնավորվում է:
Հավասարակշռումից բացի, հաղորդագրությունների փոխանակումը թույլ է տալիս պիտակավորել սուբյեկտները: Դիտարկենք պիտակների տեսակները համակարգում.
- Միացման պիտակ: Թույլ է տալիս հասկանալ, թե ինչ կապով են առաջացել իրադարձությունները։ Օգտագործվում է, երբ վերահսկիչի գործընթացը միանում է նույն փոխանակման կետին, բայց տարբեր երթուղային ստեղներով:
- Ծառայության պիտակ. Թույլ է տալիս միավորել կարգավորիչները խմբերի մեկ ծառայության համար և ընդլայնել երթուղիների և հավասարակշռման հնարավորությունները: req-resp օրինաչափության համար երթուղավորումը գծային է: Մենք հարցում ենք ուղարկում փոխանակման կետ, այնուհետև այն փոխանցում է ծառայությանը։ Բայց եթե մեզ անհրաժեշտ է կարգավորիչները բաժանել տրամաբանական խմբերի, ապա բաժանումը կատարվում է պիտակների միջոցով: Տեգ նշելիս հարցումը կուղարկվի վերահսկիչների որոշակի խմբի:
- Հարցման պիտակ: Թույլ է տալիս տարբերակել պատասխանները: Քանի որ մեր համակարգը ասինխրոն է, ծառայության պատասխանները մշակելու համար մենք պետք է կարողանանք հարցում ուղարկելիս նշել RequestTag: Դրանից մենք կկարողանանք հասկանալ, թե որ խնդրանքի պատասխանն է եկել մեզ։
Փաբ-ենթ
Փաբ-sub-ի համար ամեն ինչ մի փոքր ավելի պարզ է: Մենք փոխանակման կետ ունենք, որտեղ հաղորդագրություններ են հրապարակվում։ Փոխանակման կետը հաղորդագրություններ է տարածում այն բաժանորդների միջև, ովքեր բաժանորդագրվել են իրենց անհրաժեշտ երթուղային ստեղներին (կարող ենք ասել, որ դա նման է թեմաներին):
Ընդարձակություն և սխալների հանդուրժողականություն
Համակարգի մասշտաբայնությունը որպես ամբողջություն կախված է համակարգի շերտերի և բաղադրիչների մասշտաբայնության աստիճանից.
- Ծառայությունները մասշտաբավորվում են՝ այս ծառայության համար կարգավորիչներով կլաստերին ավելացնելով լրացուցիչ հանգույցներ: Փորձնական շահագործման ընթացքում դուք կարող եք ընտրել օպտիմալ հավասարակշռման քաղաքականություն:
- Հաղորդագրությունների ծառայությունն ինքնին առանձին կլաստերի մեջ սովորաբար մասշտաբվում է կամ առանձնապես բեռնված փոխանակման կետերը տեղափոխելով առանձին կլաստերային հանգույցներ, կամ պրոքսի գործընթացներ ավելացնելով կլաստերի հատկապես բեռնված տարածքներին:
- Ամբողջ համակարգի մասշտաբայնությունը որպես բնութագիր կախված է ճարտարապետության ճկունությունից և առանձին կլաստերները ընդհանուր տրամաբանական միավորի մեջ միավորելու կարողությունից:
Ծրագրի հաջողությունը հաճախ կախված է մասշտաբավորման պարզությունից և արագությունից: Հաղորդագրություններն իր ընթացիկ տարբերակում աճում են հավելվածի հետ մեկտեղ: Եթե նույնիսկ 50-60 մեքենաներից բաղկացած կլաստեր չունենանք, կարող ենք դիմել ֆեդերացիային։ Ցավոք սրտի, ֆեդերացիայի թեման դուրս է այս հոդվածի շրջանակներից:
Ամրագրում
Բեռի հավասարակշռումը վերլուծելիս մենք արդեն քննարկել ենք սպասարկման կարգավորիչների ավելորդությունը: Այնուամենայնիվ, հաղորդագրությունները նույնպես պետք է վերապահվեն: Հանգույցի կամ մեքենայի խափանման դեպքում հաղորդագրությունները պետք է ինքնաբերաբար վերականգնվեն և հնարավորինս կարճ ժամանակում:
Իմ նախագծերում ես օգտագործում եմ լրացուցիչ հանգույցներ, որոնք վերցնում են բեռը ընկնելու դեպքում: Erlang-ն ունի ստանդարտ բաշխված ռեժիմի ներդրում OTP հավելվածների համար: Բաշխված ռեժիմը կատարում է վերականգնում ձախողման դեպքում՝ գործարկելով ձախողված հավելվածը նախկինում գործարկված մեկ այլ հանգույցի վրա: Գործընթացը թափանցիկ է, ձախողումից հետո հավելվածը ավտոմատ կերպով տեղափոխվում է ձախողման հանգույց: Դուք կարող եք ավելին կարդալ այս ֆունկցիոնալության մասին .
Արտադրողականություն
Փորձենք գոնե մոտավորապես համեմատել rabbitmq-ի և մեր հատուկ հաղորդագրությունների կատարումը:
ես գտա rabbitmq թեստավորում openstack թիմից:
6.14.1.2.1.2.2 կետում. Բնօրինակ փաստաթուղթը ցույց է տալիս RPC CAST-ի արդյունքը.
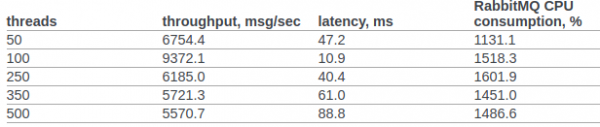
Մենք նախապես որևէ լրացուցիչ կարգավորում չենք անի OS միջուկին կամ erlang VM-ին: Փորձարկման պայմանները.
- erl ընտրում է՝ +A1 +sbtu.
- Մեկ erlang հանգույցում թեստն իրականացվում է բջջային տարբերակով հին i7-ով նոութբուքի վրա:
- Կլաստերային թեստերն իրականացվում են 10G ցանց ունեցող սերվերների վրա։
- Կոդն աշխատում է դոկեր կոնտեյներներում: Ցանցը NAT ռեժիմում:
Փորձարկման կոդը.
req_resp_bench(_) ->
W = perftest:comprehensive(10000,
fun() ->
messaging:request(?EXCHANGE, default, ping, self()),
receive
#'$msg'{message = pong} -> ok
after 5000 ->
throw(timeout)
end
end
),
true = lists:any(fun(E) -> E >= 30000 end, W),
ok.Սցենար 1: Թեստն իրականացվում է հին i7 բջջային տարբերակով նոութբուքի վրա: Փորձարկումը, հաղորդագրությունների փոխանակումը և սպասարկումն իրականացվում են մեկ Docker կոնտեյների մեկ հանգույցի վրա.
Sequential 10000 cycles in ~0 seconds (26987 cycles/s)
Sequential 20000 cycles in ~1 seconds (26915 cycles/s)
Sequential 100000 cycles in ~4 seconds (26957 cycles/s)
Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s)
Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s)
Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)Սցենար 23 հանգույցներ, որոնք աշխատում են տարբեր մեքենաների վրա docker-ի տակ (NAT):
Sequential 10000 cycles in ~1 seconds (8684 cycles/s)
Sequential 20000 cycles in ~2 seconds (8424 cycles/s)
Sequential 100000 cycles in ~12 seconds (8655 cycles/s)
Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s)
Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s)
Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s)
Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)Բոլոր դեպքերում պրոցեսորի օգտագործումը չի գերազանցել 250%-ը
Արդյունքները
Հուսով եմ, որ այս ցիկլը մտքի աղբանոց չի թվում, և իմ փորձը իրական օգուտ կբերի ինչպես բաշխված համակարգերի հետազոտողներին, այնպես էլ պրակտիկ մասնագետներին, ովքեր իրենց բիզնես համակարգերի համար բաշխված ճարտարապետություններ կառուցելու հենց սկզբում են և հետաքրքրությամբ նայում են Erlang/Elixir-ին: , բայց կասկածեք՝ արժե՞...
լուսանկար
Հարցմանը կարող են մասնակցել միայն գրանցված օգտվողները։ , խնդրում եմ:
Ի՞նչ թեմաներ պետք է ավելի մանրամասն անդրադառնամ որպես VTrade Experiment շարքի մաս:
Տեսություն՝ շուկաներ, պատվերներ և դրանց ժամկետները՝ DAY, GTD, GTC, IOC, FOK, MOO, MOC, LOO, LOC
Պատվերների գիրք. Խմբավորումներով գրքի իրականացման տեսություն և պրակտիկա
Առևտրի պատկերացում. տիզ, բարեր, լուծումներ: Ինչպես պահել և ինչպես սոսնձել
Backoffice. Պլանավորում և զարգացում. Աշխատակիցների մոնիտորինգ և միջադեպերի հետաքննություն
API. Եկեք պարզենք, թե ինչ միջերեսներ են անհրաժեշտ և ինչպես դրանք իրականացնել
Տեղեկատվության պահպանում՝ PostgreSQL, Timescale, Tarantool առևտրային համակարգերում
Ռեակտիվություն առևտրային համակարգերում
Այլ. Կգրեմ մեկնաբանություններում
Քվեարկել է 6 օգտատեր։ 4 օգտատեր ձեռնպահ է մնացել։
Source: www.habr.com
