


Չնայած այն հանգամանքին, որ այժմ գրեթե ամենուրեք շատ տվյալներ կան, վերլուծական տվյալների բազաների կառավարման համակարգերը (ՏԲԿՀ) դեռևս բավականին էկզոտիկ են։ Դրանք քիչ հայտնի են և նույնիսկ ավելի վատն են արդյունավետ օգտագործման առումով։ Շատերը շարունակում են «կակտուս ուտել» MySQL-ով կամ PostgreSQL-ով, որոնք նախատեսված են այլ սցենարների համար, տառապում են NoSQL-ից կամ գերավճարում են առևտրային լուծումների համար։ ClickHouse-ը փոխում է խաղի կանոնները և զգալիորեն իջեցնում վերլուծական ՏԲԿՀ-ի աշխարհ մուտք գործելու շեմը։
Զեկույցը վերցված է BackEnd Conf 2018-ից և հրապարակվում է խոսնակի թույլտվությամբ։


Ո՞վ եմ ես և ինչո՞ւ եմ խոսում ClickHouse-ի մասին: Ես LifeStreet-ի զարգացման տնօրենն եմ, որը ClickHouse-ն օգտագործող ընկերություն է: Ես նաև Altinity-ի հիմնադիրն եմ, որը Yandex-ի գործընկեր է, որը խթանում է ClickHouse-ը և օգնում Yandex-ին ավելի հաջողակ դարձնել ClickHouse-ը: Ես նաև պատրաստ եմ կիսվել ClickHouse-ի մասին իմ գիտելիքներով:

Եվ ես Պետյա Զայցևի եղբայրը չեմ։ Ինձ հաճախ են հարցնում այս մասին։ Ոչ, մենք եղբայրներ չենք։

«Բոլորը գիտեն», որ ClickHouse-ը.
- Շատ արագ,
- Շատ հարմար,
- Օգտագործվում է Yandex-ում։
Այն մի փոքր պակաս հայտնի է, թե որ ընկերություններում և ինչպես է այն օգտագործվում։

Ես ձեզ կասեմ, թե ինչու, որտեղ և ինչպես է օգտագործվում ClickHouse-ը՝ բացի Yandex-ից։
Ես ձեզ կպատմեմ, թե ինչպես են տարբեր ընկերություններում լուծվում որոշակի խնդիրներ ClickHouse-ի օգնությամբ, ինչ ClickHouse գործիքներ կարող եք օգտագործել ձեր խնդիրների համար և ինչպես են դրանք օգտագործվել տարբեր ընկերություններում։
Ես ընտրել եմ երեք օրինակ, որոնք ցույց են տալիս ClickHouse-ը տարբեր կողմերից։ Կարծում եմ՝ հետաքրքիր կլինի։

Առաջին հարցն է՝ «Ինչո՞ւ մեզ ClickHouse է պետք»։ Թվում է, թե սա բավականին ակնհայտ հարց է, բայց դրան կան մեկից ավելի պատասխաններ։

- Առաջին պատասխանը կատարողականության համար է։ ClickHouse-ը շատ արագ է։ ClickHouse-ի վերլուծությունները նույնպես շատ արագ են։ Այն հաճախ կարող է օգտագործվել այն դեպքերում, երբ ինչ-որ բան շատ դանդաղ կամ շատ վատ է աշխատում։
- Երկրորդ պատասխանը ծախսն է։ Եվ առաջին հերթին՝ մասշտաբավորման արժեքը։ Օրինակ, Vertica-ն բացարձակապես գերազանց տվյալների բազա է։ Այն շատ լավ է աշխատում, եթե դուք չունեք շատ տերաբայթ տվյալներ։ Բայց երբ խոսքը հարյուրավոր տերաբայթերի կամ պետաբայթերի մասին է, լիցենզավորման և աջակցության արժեքը բավականին զգալի է դառնում։ Եվ դա թանկ է։ Եվ ClickHouse-ը անվճար է։
- Երրորդ պատասխանը շահագործման ծախսերն են։ Սա մի փոքր այլ մոտեցում է։ RedShift-ը հիանալի անալոգ է։ Դուք կարող եք շատ արագ լուծում պատրաստել RedShift-ի վրա։ Այն լավ կաշխատի, բայց միևնույն ժամանակ, ամեն ժամ, ամեն օր, ամեն ամիս, դուք բավականին շատ կվճարեք Amazon-ին, քանի որ դա զգալիորեն թանկ ծառայություն է։ Google-ում նաև BigQuery-ն։ Եթե որևէ մեկն օգտագործել է այն, նա գիտի, որ այնտեղ կարող եք մի քանի հարցումներ կատարել և հանկարծ հարյուրավոր դոլարների հաշիվ ստանալ։
ClickHouse-ը այս խնդիրները չունի։

Որտե՞ղ է այժմ օգտագործվում ClickHouse-ը։ Բացի Yandex-ից, ClickHouse-ը օգտագործվում է մի շարք տարբեր բիզնեսներում և ընկերություններում։
- Նախևառաջ, սա վեբ հավելվածների վերլուծություն է, այսինքն՝ սա օգտագործման դեպք է, որը եկել է Yandex-ից։
- Շատ գովազդային տեխնոլոգիական ընկերություններ օգտագործում են ClickHouse-ը։
- Բազմաթիվ ընկերություններ, որոնք պետք է վերլուծեն տարբեր աղբյուրներից ստացված գործառնական գրանցամատյանները։
- Մի քանի ընկերություններ օգտագործում են ClickHouse-ը անվտանգության գրանցամատյանները վերահսկելու համար։ Նրանք դրանք վերբեռնում են ClickHouse, ստեղծում հաշվետվություններ և ստանում են անհրաժեշտ արդյունքները։
- Ընկերությունները սկսում են այն օգտագործել ֆինանսական վերլուծություններում, այսինքն՝ աստիճանաբար խոշոր բիզնեսը նույնպես մոտենում է ClickHouse-ին։
- CloudFlare: Եթե որևէ մեկը հետևում է ClickHouse-ին, ապա հավանաբար լսել է այս ընկերության անունը: Այն համայնքի նշանակալի ներդրողներից մեկն է: Եվ նրանք ունեն ClickHouse-ի շատ լուրջ տեղադրում: Օրինակ, նրանք ստեղծել են Kafka Engine-ը ClickHouse-ի համար:
- Հեռահաղորդակցության ընկերությունները սկսել են օգտագործել այն։ Մի քանի ընկերություններ օգտագործում են ClickHouse-ը կամ որպես հայեցակարգի ապացույց, կամ արդեն արտադրության մեջ։
- Մի ընկերություն օգտագործում է ClickHouse-ը արտադրական գործընթացները վերահսկելու համար։ Նրանք փորձարկում են չիպերը, գրանցում են մի շարք պարամետրեր, կան մոտ 2 բնութագրեր։ Եվ հետո նրանք վերլուծում են՝ խմբաքանակը լավն է, թե վատը։
- Բլոկչեյնի վերլուծություն։ Կա մի ռուսական ընկերություն՝ Bloxy.info անունով։ Սա եթերիում ցանցի վերլուծություն է։ Նրանք դա արել են նաև ClickHouse-ում։

Եվ չափը կարևոր չէ։ Կան բազմաթիվ ընկերություններ, որոնք օգտագործում են մեկ փոքր սերվեր, և դա լուծում է նրանց խնդիրները։ Եվ նույնիսկ ավելի շատ ընկերություններ օգտագործում են բազմաթիվ մեծ կլաստերներ։ սերվերներ կամ տասնյակ սերվերներ։
Եվ եթե նայեք գրառումներին, ապա.
- Yandex. 500+ սերվեր, օրական 25 միլիարդ գրառում, որոնք նրանք պահում են այնտեղ։
- LifeStreet: 60 սերվեր, օրական մոտ 75 միլիարդ գրառում: Ավելի քիչ սերվերներ, ավելի շատ գրառումներ, քան Yandex-ում:
- CloudFlare. 36 սերվեր, օրական պահում են 200 միլիարդ գրառում։ Նրանք ունեն ավելի քիչ սերվերներ և պահում են ավելի շատ տվյալներ։
- Բլումբերգ. 102 սերվեր, օրական մոտավորապես մեկ տրիլիոն գրառում։ Գրառումների ռեկորդակիր։
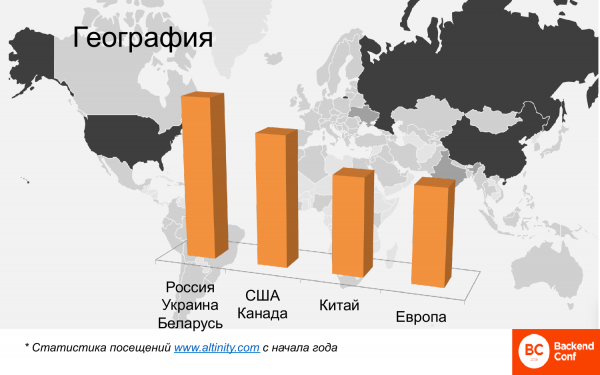
Աշխարհագրական առումով սա նույնպես շատ է։ Այս քարտեզը ցույց է տալիս ClickHouse-ի օգտագործման ջերմային քարտեզը աշխարհում։ Այստեղ առանձնանում են Ռուսաստանը, Չինաստանը և Ամերիկան։ Եվրոպական երկրները քիչ են։ Եվ կարելի է առանձնացնել 4 կլաստեր։
Սա համեմատական վերլուծություն է, անհրաժեշտ չէ բացարձակ թվեր փնտրել: Սա Altinity կայքում անգլերեն լեզվով նյութեր կարդացող այցելուների վերլուծություն է, քանի որ այնտեղ ռուսախոս օգտատերեր չկան: Եվ Ռուսաստանը, Ուկրաինան, Բելառուսը, այսինքն՝ համայնքի ռուսախոս մասը, ամենաշատ օգտատերերն են: Այնուհետև գալիս են ԱՄՆ-ն և Կանադան: Չինաստանը շատ արագ է հասնում: Վեց ամիս առաջ Չինաստանը գրեթե գոյություն չուներ, հիմա Չինաստանն արդեն անցել է Եվրոպայից և շարունակում է աճել: Հին Եվրոպան շատ հեռու չէ, և ClickHouse-ի օգտագործման առաջատարը, տարօրինակ կերպով, Ֆրանսիան է:

Ինչո՞ւ եմ սա ձեզ պատմում։ Որպեսզի ցույց տամ, որ ClickHouse-ը դառնում է մեծ տվյալների վերլուծության ստանդարտ լուծում և արդեն օգտագործվում է շատ տեղերում։ Եթե դուք օգտագործում եք այն, ապա ճիշտ միտման մեջ եք։ Եթե դեռ չեք օգտագործում այն, ապա չեք կարող վախենալ, որ մենակ կմնաք, և ոչ ոք չի օգնի ձեզ, քանի որ շատերն արդեն դա անում են։

Սրանք ClickHouse-ի մի քանի ընկերություններում օգտագործման իրական օրինակներ են։
- Առաջին օրինակը գովազդային ցանցն է՝ Vertica-ից ClickHouse անցումը։ Եվ ես գիտեմ մի քանի ընկերություններ, որոնք Vertica-ից անցել են կամ գտնվում են անցման գործընթացում։
- Երկրորդ օրինակը ClickHouse-ում գործարքային պահեստ է։ Սա հակա-մոդելների վրա կառուցված օրինակ է։ Այստեղ արվում է այն ամենը, ինչը չպետք է արվի ClickHouse-ում՝ մշակողների խորհուրդների համաձայն։ Եվ դա արվում է այնքան արդյունավետ, որ աշխատում է։ Եվ այն աշխատում է շատ ավելի լավ, քան սովորական գործարքային լուծումը։
- Երրորդ օրինակը ClickHouse-ի վրա բաշխված հաշվարկն է: Հարց առաջացավ այն մասին, թե ինչպես կարելի է ClickHouse-ը ինտեգրել Hadoop էկոհամակարգին: Ես կցույց տամ, թե ինչպես է ընկերությունը ClickHouse-ի վրա ստեղծել քարտեզի կրճատման կոնտեյների անալոգ, որը վերահսկում է տվյալների տեղայնացումը և այլն՝ շատ ոչ տրիվիալ առաջադրանք հաշվարկելու համար:

- LifeStreet – Սա գովազդային տեխնոլոգիաների ընկերություն է, որն ունի գովազդային ցանց վարելու համար անհրաժեշտ բոլոր տեխնոլոգիաները։
- Նա զբաղվում է գովազդի օպտիմալացմամբ, ծրագրային առաջարկներով։
- Շատ տվյալներ՝ օրական մոտ 10 միլիարդ իրադարձություն։ Միևնույն ժամանակ, իրադարձությունները կարելի է բաժանել մի քանի ենթաիրադարձությունների։
- Այս տվյալների շատ հաճախորդներ կան, և դրանք ոչ միայն մարդիկ են, այլև շատ ավելին՝ սրանք տարբեր ալգորիթմներ են, որոնք զբաղվում են ծրագրային աճուրդով։

Ընկերությունն ունեցել է երկար և փշոտ ճանապարհ։ Եվ ես դրա մասին խոսել եմ HighLoad-ում։ Սկզբում LifeStreet-ը MySQL-ից (Oracle-ի վրա կարճ կանգառով) անցավ Vertica-ի։ Եվ դուք կարող եք գտնել դրա մասին պատմություն։
Եվ ամեն ինչ շատ լավ էր, բայց շուտով պարզ դարձավ, որ տվյալները աճում էին, և Vertica-ն թանկ էր։ Այսպիսով, փնտրվեցին տարբեր այլընտրանքներ։ Դրանցից մի քանիսը ներկայացված են այստեղ։ Եվ իրականում, մենք իրականացրինք գրեթե բոլոր տվյալների բազաների կոնցեպտի հաստատում կամ երբեմն կատարողականության թեստավորում, որոնք շուկայում հասանելի էին 13-ից 16 թվականներին և մոտավորապես համապատասխանում էին ֆունկցիոնալությանը։ Եվ ես նաև խոսեցի դրանցից մի քանիսի մասին HighLoad-ում։

Խնդիրն այն էր, որ նախևառաջ Vertica-ից տեղափոխվեին, քանի որ տվյալները աճում էին։ Եվ դրանք աճում էին էքսպոնենցիալ տեմպերով մի քանի տարի շարունակ։ Հետո դրանք մնացին դարակում, բայց այնուամենայնիվ։ Եվ կանխատեսելով այս աճը, բիզնեսի պահանջները տվյալների ծավալի համար, որի վրա պետք է որոշ վերլուծություններ արվեին, պարզ էր, որ շուտով խոսքը պետաբայթերի մասին կլինի։ Եվ պետաբայթերի համար վճարելն արդեն շատ թանկ է, ուստի նրանք փնտրում էին այլընտրանք, թե որտեղ գնալ։
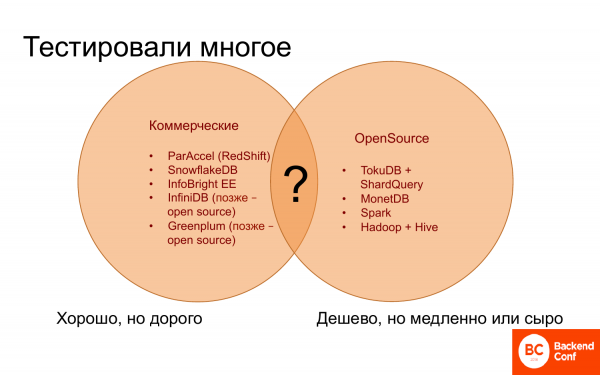
Ուր գնալ։ Եվ երկար ժամանակ բացարձակապես անհասկանալի էր, թե որտեղ գնալ, քանի որ մի կողմից կան առևտրային տվյալների բազաներ, դրանք, կարծես, լավ են աշխատում։ Որոշները գրեթե նույնքան լավ են աշխատում, որքան Vertica-ն, որոշները՝ ավելի վատ։ Բայց դրանք բոլորը թանկ են, ավելի էժան և լավ բան հնարավոր չէ գտնել։
Մյուս կողմից, կան բաց կոդով լուծումներ, որոնք շատ չեն, այսինքն՝ վերլուծության համար դրանք կարելի է մատների վրա հաշվել։ Եվ դրանք անվճար են կամ էժան, բայց դանդաղ են աշխատում։ Եվ հաճախ զուրկ են անհրաժեշտ և օգտակար ֆունկցիոնալությունից։
Եվ չկար ոչինչ, որը համատեղեր առևտրային տվյալների բազաներում առկա լավ բաները և բաց կոդով առկա անվճար ամեն ինչ։

Ոչինչ չկար, մինչև Yandex-ը հանկարծակի ClickHouse-ը չհանեց, ինչպես կախարդը գլխարկից նապաստակ է հանում։ Եվ դա անսպասելի որոշում էր, և մարդիկ դեռևս հարցնում են. «Ինչո՞ւ», բայց այնուամենայնիվ։
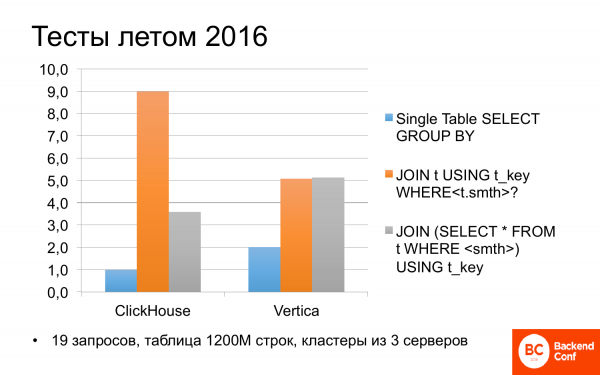
Եվ անմիջապես 2016 թվականի ամռանը մենք սկսեցինք ուսումնասիրել, թե ինչ է ClickHouse-ը։ Եվ պարզվեց, որ այն երբեմն կարող է ավելի արագ լինել, քան Vertica-ն։ Մենք փորձարկեցինք տարբեր սցենարներ տարբեր հարցումների վրա։ Եվ եթե հարցումն օգտագործում էր միայն մեկ աղյուսակ, այսինքն՝ առանց որևէ միացման, ապա ClickHouse-ը երկու անգամ ավելի արագ էր, քան Vertica-ն։
Ես ծույլ չէի և մյուս օրը նայեցի Yandex-ի թեստերը։ Այնտեղ նույնն է. ClickHouse-ը Vertica-ից երկու անգամ արագ է, ուստի նրանք հաճախ են խոսում դրա մասին։
Բայց եթե հարցումներում կան միացումներ, ապա ամեն ինչ այդքան էլ պարզ չէ։ Եվ ClickHouse-ը կարող է երկու անգամ ավելի դանդաղ լինել, քան Vertica-ն։ Բայց եթե մի փոքր ուղղեք և վերաշարադրեք հարցումը, ապա դրանք մոտավորապես հավասար կլինեն։ Վատ չէ։ Եվ անվճար։

Եվ ստանալով թեստի արդյունքները և դրանք տարբեր անկյուններից դիտարկելով՝ LifeStreet-ը գնաց ClickHouse:

Սա 16-րդ տարին է, հիշեցնում եմ ձեզ։ Այն նման էր մկների մասին կատակի, որոնք լաց էին լինում և ծակծկում էին իրենց, բայց շարունակում էին ուտել կակտուսը։ Եվ այն մանրամասն պատմվեց, կա տեսանյութ դրա մասին և այլն։

Ահա թե ինչու ես մանրամասն չեմ անդրադառնա դրա վրա, պարզապես կխոսեմ արդյունքների և մի քանի հետաքրքիր բաների մասին, որոնց մասին այն ժամանակ չխոսեցի։
Արդյունքներն են՝
- Հաջող միգրացիա, և համակարգը գործարկվել է ավելի քան մեկ տարի։
- Արդյունավետությունն ու ճկունությունը բարձրացել են։ 10 միլիարդ գրառումից, որոնք մենք կարող էինք պահել օրական և ոչ երկար ժամանակով, LifeStreet-ը այժմ պահպանում է օրական 75 միլիարդ գրառում և կարող է դա անել 3 ամիս կամ ավելի։ Եթե հաշվարկեք գագաթնակետային ժամանակահատվածում, ապա վայրկյանում պահվում է մինչև մեկ միլիոն իրադարձություն։ Այս համակարգ է մտնում օրական ավելի քան մեկ միլիոն SQL հարցում, հիմնականում տարբեր ռոբոտներից։
- Չնայած այն հանգամանքին, որ ClickHouse-ը սկսեց ավելի շատ սերվերներ օգտագործել, քան Vertica-ն, նաև խնայողություն եղավ սարքավորումների վրա, քանի որ Vertica-ն օգտագործում էր բավականին թանկ SAS սկավառակներ: ClickHouse-ն օգտագործում էր SATA: Ինչո՞ւ: Որովհետև Vertica-ն ունի համաժամանակյա ներմուծում: Եվ համաժամեցումը պահանջում է, որ սկավառակները չափազանց չդանդաղեն, ինչպես նաև որ ցանցը չափազանց չդանդաղի, այսինքն՝ դա բավականին թանկ գործողություն է: Իսկ ClickHouse-ում ներմուծումը ասինխրոն է: Ավելին, դուք միշտ կարող եք ամեն ինչ գրել տեղային, դրա համար լրացուցիչ ծախսեր չկան, ուստի տվյալները կարող են ClickHouse-ում ներմուծվել շատ ավելի արագ, քան Vertica-ում, նույնիսկ ոչ ամենաարագ սկավառակների վրա: Եվ ընթերցումը մոտավորապես նույնն է: SATA-ի վրա ընթերցումը, եթե դրանք RAID-ում են, ապա ամեն ինչ բավականին արագ է:
- Չի սահմանափակվում լիցենզիայով, այսինքն՝ 3 պետաբայթ տվյալ 60 սերվերներում (20 սերվերը մեկ կրկնօրինակ է) և 6 տրիլիոն գրառում փաստերի և ագրեգատների տեսքով: Vertica-ն նման բան չէր կարող թույլ տալ:

Հիմա անցնեմ այս օրինակի գործնական բաներին։
- Առաջինը արդյունավետ սխեման է։ Շատ բան կախված է սխեմայից։
- Երկրորդը արդյունավետ SQL ստեղծումն է։
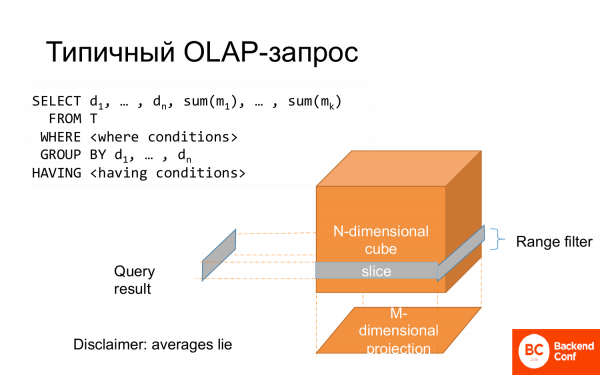
OLAP հարցումներից մեկը select-ն է: Որոշ սյուներ group by-ի են պատկանում, որոշները՝ aggregate functions-ի: Կա where , որը կարելի է ներկայացնել որպես խորանարդի մի կտոր: Ամբողջ group by-ն կարելի է ներկայացնել որպես պրոյեկցիա: Եվ այդ պատճառով այն կոչվում է բազմաչափ տվյալների վերլուծություն:

Եվ հաճախ սա մոդելավորվում է աստղային դիագրամի տեսքով, երբ ճառագայթների երկայնքով, կողքերին կա կենտրոնական փաստ և այդ փաստի բնութագրեր։

Եվ ֆիզիկական դիզայնի տեսանկյունից, թե ինչպես է այն տեղավորվում աղյուսակում, սովորաբար նրանք ստեղծում են նորմալացված ներկայացում։ Դուք կարող եք դենորմալացնել, բայց դա թանկ է սկավառակի վրա և շատ արդյունավետ չէ հարցումների առումով։ Հետևաբար, սովորաբար նրանք ստեղծում են նորմալացված ներկայացում, այսինքն՝ փաստերի աղյուսակ և շատ, շատ չափողականության աղյուսակներ։
Բայց ClickHouse-ում այն վատ է աշխատում։ Կան երկու պատճառ՝
- Առաջինը պայմանավորված է նրանով, որ ClickHouse-ը շատ լավ միացումներ չունի, այսինքն՝ կան միացումներ, բայց դրանք վատն են։ Մինչև հիմա վատն են։
- Երկրորդը՝ աղյուսակները չեն թարմացվում։ Սովորաբար այս աղյուսակներում, որոնք գտնվում են աստղային սխեմայի շուրջ, ինչ-որ բան պետք է փոխվի։ Օրինակ՝ հաճախորդի անունը, ընկերության անվանումը և այլն։ Եվ դա չի աշխատում։
Եվ ClickHouse-ում կա ելք դրանից։ Իրականում, կան երկուսը.
- Առաջինը բառարանների օգտագործումն է։ Արտաքին բառարաններն են, որոնք օգնում են լուծել աստղային սխեմայի, թարմացումների և այլնի հետ կապված խնդիրների 99%-ը։
- Երկրորդը զանգվածների օգտագործումն է։ Զանգվածները նաև օգնում են ազատվել միացումների և նորմալացման խնդիրներից։

- Միացումներ անհրաժեշտ չեն։
- Թարմացվող։ 2018 թվականի մարտից ի վեր հայտնվել է չփաստաթղթավորված գործառույթ (դուք այն չեք գտնի փաստաթղթերում)՝ բառարանները, այսինքն՝ այն գրառումները, որոնք փոխվել են, մասնակիորեն թարմացնելու համար։ Գործնականում դա աղյուսակի նման է։
- Միշտ հիշողության մեջ է, ուստի բառարանի հետ միացումները ավելի արագ են աշխատում, քան եթե դա սկավառակի վրա գտնվող աղյուսակ լիներ, և փաստ չէր, որ այն քեշում էր, ամենայն հավանականությամբ՝ ոչ։

- Միացումների կարիք նույնպես չկա։
- Սա կոմպակտ 1-ից շատերի ներկայացում է։
- Եվ իմ կարծիքով, զանգվածները նախատեսված են գիկերի համար։ Սրանք լամբդա ֆունկցիաներ են և այլն։
Սա պարզապես կարգախոս չէ։ Սա շատ հզոր ֆունկցիոնալություն է, որը թույլ է տալիս շատ բաներ անել շատ պարզ և նրբագեղ։

Տիպիկ օրինակներ, որոնք օգնում են լուծել զանգվածներ։ Այս օրինակները պարզ են և բավականին պատկերազարդ։
- Որոնել թեգերով։ Եթե այնտեղ հեշթեգեր ունեք և ցանկանում եք գտնել որոշ գրառումներ հեշթեգով։
- Որոնել բանալի-արժեք զույգերով։ Կան նաև որոշ ատրիբուտներ, որոնք ունեն արժեք։
- Պահպանել այն բանալիների ցուցակները, որոնք դուք պետք է թարգմանեք ինչ-որ այլ բանի։
Այս բոլոր խնդիրները կարելի է լուծել առանց զանգվածների։ Թեգերը կարելի է տեղադրել որևէ տողում և ընտրել կանոնավոր արտահայտությամբ կամ առանձին աղյուսակում, բայց այդ դեպքում դուք ստիպված կլինեք կատարել միացումներ։

Եվ ClickHouse-ում ձեզ հարկավոր չէ ոչինչ անել, բավական է նկարագրել հեշթեգերի համար տողային զանգված կամ ստեղծել բանալի-արժեք տիպի համակարգերի համար ներդրված կառուցվածք։
Ներկառուցված կառուցվածքը, թերևս, լավագույն անվանումը չէ։ Այն երկու զանգված է, որոնք ունեն անվան մեջ ընդհանուր մաս և որոշ փոխկապակցված բնութագրեր։
Եվ շատ հեշտ է որոնել թեգով։ Կա ֆունկցիա has, որը ստուգում է, որ զանգվածը պարունակում է տարր։ Այսքանը, մենք գտանք մեր կոնֆերանսին վերաբերող բոլոր գրառումները։
Subid-ով որոնումը մի փոքր ավելի բարդ է։ Մենք նախ պետք է գտնենք բանալու ինդեքսը, այնուհետև վերցնենք այս ինդեքսով տարրը և ստուգենք, որ այս արժեքը մեզ անհրաժեշտ է։ Բայց այնուամենայնիվ, այն շատ պարզ և կոմպակտ է։
Կանոնավոր արտահայտությունը, որը դուք կցանկանաք գրել, եթե այն ամբողջությամբ պահեք մեկ տողում, նախ, անհարմար կլինի։ Եվ երկրորդ, այն աշխատելու համար շատ ավելի երկար ժամանակ կպահանջվի, քան երկու զանգվածի դեպքում։

Մեկ այլ օրինակ։ Դուք ունեք մի զանգված, որտեղ պահում եք ID-ներ։ Եվ կարող եք դրանք թարգմանել անունների։ Ֆունկցիան arrayMapՍա տիպիկ լամբդա ֆունկցիա է։ Դուք այնտեղ փոխանցում եք լամբդա արտահայտություններ։ Եվ այն բառարանից դուրս է բերում յուրաքանչյուր ID-ի անվան արժեքը։
Որոնումը կարող է կատարվել նմանատիպ ձևով։ Անցկացվում է պրեդիկատի ֆունկցիա, որը ստուգում է, թե տարրերը ինչին են համապատասխանում։

Այս բաները մեծապես պարզեցնում են սխեման և լուծում են բազմաթիվ խնդիրներ։
Բայց հաջորդ խնդիրը, որին մենք հանդիպեցինք և որի մասին կցանկանայի նշել, արդյունավետ հարցումներն են։
- ClickHouse-ը հարցումների պլանավորիչ չունի։ Ընդհանրապես չունի։
- Բայց այնուամենայնիվ, բարդ հարցումները դեռ պետք է պլանավորվեն։ Ո՞ր դեպքերում։
- Եթե հարցման մեջ կան մի քանի միացումներ, դրանք փաթեթավորվում են ենթաընտրանքների մեջ։ Եվ կարևոր է, թե ինչ հերթականությամբ են դրանք կատարվում։
- Եվ երկրորդը՝ եթե հարցումը բաշխված է։ Քանի որ բաշխված հարցման դեպքում միայն ներքին ենթաընտրանքն է կատարվում բաշխված եղանակով, իսկ մնացած ամեն ինչ փոխանցվում է մեկ սերվերի, որին դուք միացել և այնտեղ եք կատարել։ Հետևաբար, եթե դուք ունեք բաշխված հարցումներ բազմաթիվ միացումներով, ապա պետք է ընտրեք հերթականությունը։
Եվ նույնիսկ ավելի պարզ դեպքերում, երբեմն անհրաժեշտ է նաև կատարել պլանավորողի աշխատանքը և մի փոքր վերաշարադրել հարցումները։

Ահա մի օրինակ։ Ձախ կողմում հարցում է, որը ցույց է տալիս լավագույն 5 երկրները։ Եվ այն տևում է 2,5 վայրկյան, կարծեմ։ Իսկ աջ կողմում՝ նույն հարցումը, բայց մի փոքր վերաշարադրված։ Տողային տողերով խմբավորելու փոխարեն, մենք սկսեցինք խմբավորել բանալիով (int)։ Եվ դա ավելի արագ է։ Եվ հետո արդյունքին միացրինք բառարան։ 2,5 վայրկյանի փոխարեն հարցումը տևում է 1,5 վայրկյան։ Դա լավ է։

Նմանատիպ օրինակ՝ վերաշարադրվող ֆիլտրերով։ Ահա Ռուսաստանի հարցումը։ Այն տևում է 5 վայրկյան։ Եթե մենք այն վերաշարադրենք այնպես, որ համեմատենք ոչ թե տողը, այլ թվերը Ռուսաստանին վերաբերող որևէ բանալիների հավաքածուի հետ, ապա դա շատ ավելի արագ կլինի։

Կան բազմաթիվ նման հնարքներ։ Եվ դրանք թույլ են տալիս զգալիորեն արագացնել այն հարցումները, որոնք, ձեր կարծիքով, արդեն արագ են աշխատում, կամ, ընդհակառակը, դանդաղ են աշխատում։ Դրանք կարելի է նույնիսկ ավելի արագ դարձնել։

- Առավելագույն աշխատանք բաշխված ռեժիմում։
- Դասակարգում նվազագույն տեսակների համաձայն, ինչպես ես արեցի ամբողջ թվերի համաձայն։
- Եթե կան որևէ միացումներ կամ բառարաններ, ավելի լավ է դրանք անել վերջում, երբ արդեն ունեք առնվազն մասամբ խմբավորված տվյալներ, այդ դեպքում միացման գործողությունը կամ բառարանի կանչը կկանչվի ավելի քիչ անգամ և ավելի արագ կլինի։
- Ֆիլտրերի փոխարինում։
Կան այլ տեխնիկաներ, բացի իմ ցուցադրածներից, և դրանցից յուրաքանչյուրը երբեմն կարող է զգալիորեն արագացնել հարցման կատարումը։

Անցնենք հաջորդ օրինակին։ ԱՄՆ-ից X ընկերություն։ Ի՞նչ է այն անում։
Առաջադրանքը հետևյալն էր.
- Գովազդային գործարքների անցանց կապակցում։
- Տարբեր կապող մոդելների մոդելավորում։

Ի՞նչ է սցենարը։
Սովորական այցելուն կայք է մտնում, օրինակ, ամսական 20 անգամ՝ տարբեր գովազդներից, կամ պարզապես երբեմն գալիս է առանց որևէ գովազդի, քանի որ հիշում է այս կայքը։ Նայում է որոշ ապրանքների, դնում է դրանք զամբյուղի մեջ, հանում զամբյուղից։ Եվ, վերջում, գնում է ինչ-որ բան։
Հիմնավորված հարցեր՝ «Ու՞մ պետք է վճարվի գովազդի համար, եթե անհրաժեշտ է» և «Ի՞նչ գովազդ է ազդել նրա վրա, եթե ազդել է»։ Այսինքն՝ ինչո՞ւ է նա գնել, և ինչպե՞ս կարող ենք այնպես անել, որ այս մարդուն նման մարդիկ նույնպես գնեն։
Այս խնդիրը լուծելու համար անհրաժեշտ է կայքում տեղի ունեցող իրադարձությունները ճիշտ կապել, այսինքն՝ ինչ-որ կերպ կապ ստեղծել դրանց միջև։ Այնուհետև դրանք փոխանցել DWH-ին՝ վերլուծության համար։ Եվ այս վերլուծության հիման վրա կառուցել մոդելներ, թե ում ինչ գովազդ ցուցադրել։

Գովազդային գործարքը օգտատիրոջ հետ կապված իրադարձությունների ամբողջություն է, որը սկսվում է գովազդի ցուցադրմամբ, այնուհետև ինչ-որ բան է տեղի ունենում, ապա գուցե գնում, և այդ դեպքում գնման շրջանակներում կարող են լինել գնումներ: Օրինակ, եթե դա բջջային հավելված է կամ բջջային խաղ, ապա հավելվածը սովորաբար տեղադրվում է անվճար, բայց եթե այնտեղ ինչ-որ այլ բան է արվում, ապա կարող է պահանջվել գումար: Եվ որքան շատ մարդ ծախսում է հավելվածում, այնքան ավելի արժեքավոր է այն: Բայց դրա համար ամեն ինչ պետք է միացված լինի:

Կան բազմաթիվ կապող մոդելներ։
Ամենատարածվածներն են՝
- Վերջին փոխազդեցություն, որտեղ փոխազդեցությունը կամ սեղմում է, կամ տպավորություն։
- Առաջին փոխազդեցությունը, այսինքն՝ առաջին բանը, որը մարդուն բերել է կայք։
- Գծային համադրություն - բոլորի համար հավասար բաժիններ:
- Մարում։
- Եվ այսպես շարունակ։
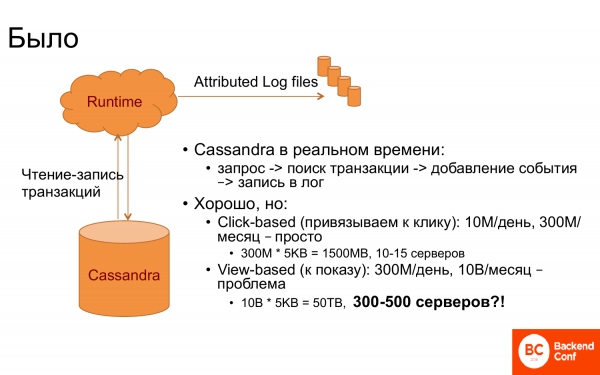
Եվ ինչպե՞ս էր այս ամենը աշխատում սկզբում։ Կար Runtime-ը և Cassandra-ն։ Cassandra-ն օգտագործվում էր որպես գործարքների պահեստ, այսինքն՝ բոլոր դրանց հետ կապված գործարքները պահվում էին այնտեղ։ Եվ երբ Runtime-ում տեղի էր ունենում որևէ իրադարձություն, օրինակ՝ ցուցադրվում էր որևէ էջ կամ ինչ-որ այլ բան, ապա Cassandra-ին հարցում էր արվում՝ արդյոք նման անձ գոյություն ունի, թե ոչ։ Այնուհետև նրան վերաբերող գործարքները վերականգնվում էին։ Եվ կապը կատարվում էր։
Եվ եթե բախտավոր եք, որ հարցումը ունի գործարքի ID, ապա դա հեշտ է։ Բայց սովորաբար դուք անհաջողակ եք։ Այսպիսով, դուք պետք է գտնեիք վերջին գործարքը կամ վերջին սեղմումով գործարքը և այլն։
Եվ ամեն ինչ շատ լավ էր աշխատում, քանի դեռ կապը վերջին սեղմման հետ էր։ Որովհետև սեղմումները, ասենք, օրական 10 միլիոն, ամսական 300 միլիոն են, եթե պատուհանը սահմանեք մեկ ամսվա համար։ Եվ քանի որ Cassandra-ում արագ աշխատելու համար ամեն ինչ պետք է հիշողության մեջ լինի, քանի որ Runtime-ը պետք է արագ արձագանքի, ապա անհրաժեշտ էր մոտ 10-15 սերվեր։
Եվ երբ նրանք ցանկացան գործարքը կապել էկրանին, դա միանգամից այդքան էլ հաճելի չստացվեց։ Եվ ինչո՞ւ։ Ակնհայտ է, որ անհրաժեշտ է պահպանել 30 անգամ ավելի շատ իրադարձություններ։ Եվ, համապատասխանաբար, անհրաժեշտ է 30 անգամ ավելի շատ սերվեր։ Եվ պարզվեց, որ սա ինչ-որ աստղաբաշխական թիվ է։ Կապը կատարելու համար մինչև 500 սերվեր պահելը, հաշվի առնելով, որ Runtime-ում զգալիորեն ավելի քիչ սերվերներ կան, սա ինչ-որ սխալ թիվ է։ Եվ նրանք սկսեցին մտածել, թե ինչ անել։

Եվ մենք գնացինք ClickHouse: Իսկ ինչպե՞ս անել դա ClickHouse-ում: Առաջին հայացքից թվում է, թե դա հակա-մոդելների հավաքածու է:
- Գործարքը մեծանում է, մենք դրան ավելի ու ավելի շատ նոր իրադարձություններ ենք կցում, այսինքն՝ այն փոփոխական է, և ClickHouse-ը շատ լավ չի աշխատում փոփոխական օբյեկտների հետ։
- Երբ այցելուն գալիս է մեզ մոտ, մենք պետք է արդյունահանենք նրա գործարքները բանալիով, նրա այցելության ID-ով։ Սա նույնպես կետային հարցում է, ClickHouse-ը դա չի անում։ ClickHouse-ը սովորաբար ունի մեծ ...սկանավորումներ, բայց այստեղ մենք պետք է արդյունահանենք մի քանի գրառում։ Նաև հակաօրինաչափություն։
- Բացի այդ, գործարքը json ձևաչափով էր, բայց նրանք չէին ուզում վերաշարադրել այն, ուստի ցանկանում էին պահպանել json-ը առանց կառուցվածքի, իսկ անհրաժեշտության դեպքում դրանից ինչ-որ բան հանել։ Եվ սա նույնպես հակա-մոդել է։
Այսինքն՝ հակաօրինաչափությունների ամբողջություն։
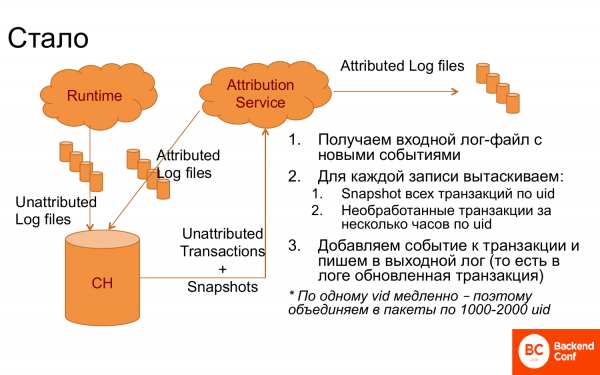
Բայց այնուամենայնիվ, մեզ հաջողվեց ստեղծել մի համակարգ, որը շատ լավ աշխատեց։
Ի՞նչ արվեց։ Հայտնվեց ClickHouse-ը, որի մեջ գրանցվում էին գրանցամատյաններ՝ բաժանված գրառումների։ Հայտնվեց վերագրվող ծառայություն, որը ClickHouse-ից ստանում էր գրանցամատյաններ։ Դրանից հետո, այցելության ID-ով յուրաքանչյուր գրանցամատյանի համար այն ստանում էր գործարքներ, որոնք դեռ չէին կարող մշակվել, գումարած snapshots, այսինքն՝ արդեն կապված գործարքներ, այսինքն՝ նախորդ աշխատանքի արդյունք։ Դրանցից այն տրամաբանություն էր ստեղծում, ընտրում էր ճիշտ գործարքը, կապում նոր իրադարձություններ։ Կրկին գրում էր գրանցամատյանում։ Գրանցամատյանը վերադառնում էր ClickHouse, այսինքն՝ սա անընդհատ ցիկլիկ համակարգ է։ Եվ բացի այդ, այն գնում էր DWH՝ այնտեղ այն վերլուծելու համար։
Այս ձևաչափով այն այդքան էլ լավ չէր աշխատում։ Եվ ClickHouse-ի համար գործը հեշտացնելու համար, երբ այցելության ID-ով հարցում էր լինում, նրանք խմբավորում էին այդ հարցումները 1-000 այցելության ID-ների բլոկների մեջ և ստանում էին 2-000 մարդու բոլոր գործարքները։ Եվ այդ ժամանակ ամեն ինչ աշխատեց։
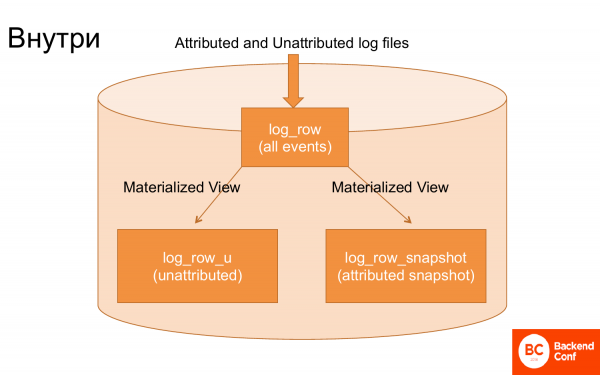
Եթե նայեք ClickHouse-ի ներսում, կան ընդամենը 3 հիմնական աղյուսակներ, որոնք սպասարկում են այս ամենը։
Առաջին աղյուսակը, որտեղ բեռնվում են գրանցամատյանները, և գրանցամատյանները բեռնվում են գործնականում առանց մշակման։
Երկրորդ աղյուսակը։ Նյութականացված տեսքի միջոցով այս գրանցամատյաններից արդյունահանվել են դեռևս չվերագրվող իրադարձություններ, այսինքն՝ կապ չունեցող։ Իսկ նյութականացված տեսքի միջոցով այս գրանցամատյաններից արդյունահանվել են գործարքներ՝ ակնթարթային պատկեր կառուցելու համար։ Այսինքն՝ հատուկ նյութականացված տեսքը ստեղծել է ակնթարթային պատկեր, այսինքն՝ գործարքի վերջին կուտակված վիճակը։
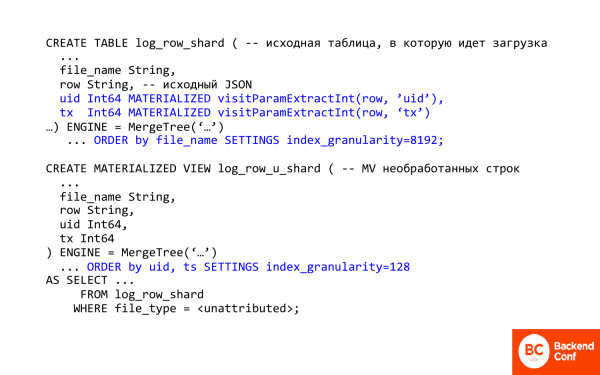
Ահա SQL-ով գրված տեքստը։ Ես կցանկանայի մեկնաբանել մի քանի կարևոր բաներ։
Առաջին կարևոր բանը ClickHouse-ում json-ից սյուներ և դաշտեր արդյունահանելու հնարավորությունն է։ Այսինքն՝ ClickHouse-ն ունի json-ի հետ աշխատելու որոշ մեթոդներ։ Դրանք շատ, շատ պարզունակ են։
visitParamExtractInt-ը թույլ է տալիս json ֆայլից արտիբուտներ արդյունահանել, այսինքն՝ առաջին հարվածը գործում է։ Եվ այս կերպ դուք կարող եք արդյունահանել գործարքի id-ն կամ visit id-ն։ Սա մեկն է։
Երկրորդ, այստեղ օգտագործվում է բարդ նյութականացված դաշտ։ Ի՞նչ է սա նշանակում։ Դա նշանակում է, որ դուք չեք կարող այն տեղադրել աղյուսակում, այսինքն՝ այն չի տեղադրվում, այն հաշվարկվում և պահվում է տեղադրվելիս։ Տեղադրվելուց հետո ClickHouse-ը կատարում է աշխատանքը ձեզ համար։ Եվ այն, ինչ ձեզ ավելի ուշ անհրաժեշտ կլինի, դուրս է բերվում json ֆայլից։
Այս դեպքում նյութականացված տեսքը նախատեսված է չմշակված տողերի համար։ Եվ օգտագործվում է առաջին աղյուսակը՝ գրեթե հում գրանցամատյաններով։ Եվ ի՞նչ է այն անում։ Նախ, այն փոխում է տեսակավորումը, այսինքն՝ տեսակավորումն այժմ կատարվում է այցելության ID-ով, քանի որ մենք պետք է արագորեն արդյունահանենք գործարքը որոշակի անձի համար։
Երկրորդ կարևոր բանը index_granularity-ն է: Եթե տեսել եք MergeTree-ն, ապա սովորաբար լռելյայն արժեքը 8 է index_granularity-ն: Ի՞նչ է դա: Սա ինդեքսի նոսրության պարամետրն է: ClickHouse-ում ինդեքսը նոսր է, այն երբեք ինդեքսավորում է յուրաքանչյուր գրառում: Այն դա անում է յուրաքանչյուր 192-ը: Եվ սա լավ է, երբ անհրաժեշտ է շատ տվյալներ հաշվարկել, բայց վատ է, երբ անհրաժեշտ է քիչ հաշվարկել, քանի որ վերադիր ծախսերը մեծ են: Եվ եթե դուք նվազեցնում եք ինդեքսի հատիկավորությունը, ապա մենք նվազեցնում ենք վերադիր ծախսերը: Դուք չեք կարող այն նվազեցնել մինչև մեկի, քանի որ կարող է բավարար հիշողություն չլինել: Ինդեքսը միշտ պահվում է հիշողության մեջ:

Եվ պատկերը օգտագործում է ClickHouse-ի մի քանի այլ հետաքրքիր գործառույթներ։
Նախ, դա AggregatingMergeTree-ն է։ Եվ AggregatingMergeTree-ն պահպանում է argMax-ը, այսինքն՝ սա վերջին ժամանակային նշագծին համապատասխանող գործարքի վիճակն է։ Այս այցելուի համար անընդհատ նոր գործարքներ են ստեղծվում։ Եվ այս գործարքի ամենավերջին վիճակում մենք ավելացրինք իրադարձություն և ստացանք նոր վիճակ։ Այն կրկին մտավ ClickHouse։ Եվ այս նյութականացված տեսքում argMax-ի միջոցով մենք միշտ կարող ենք ստանալ ընթացիկ վիճակը։

- Կապը անջատված է Runtime-ից։
- Ամսական պահպանում և մշակում է մինչև 3 միլիարդ գործարք։ Սա մի քանի անգամ ավելի մեծ է, քան Cassandra-ի տիպիկ գործարքային համակարգը։
- 2x5 ClickHouse սերվերների կլաստեր։ 5 սերվեր, և յուրաքանչյուր սերվեր ունի իր կրկնօրինակը։ Սա նույնիսկ ավելի քիչ է, քան Cassandra-ում էր՝ սեղմումների վրա հիմնված վերագրում կատարելու համար, իսկ այստեղ մենք ունենք տպավորությունների վրա հիմնված։ Այսինքն՝ սերվերների թիվը 30 անգամ ավելացնելու փոխարեն, դրանք կրճատվել են։

Եվ վերջին օրինակը Y ֆինանսական ընկերությունն է, որը վերլուծել է բաժնետոմսերի գների փոփոխությունների փոխհարաբերությունները։
Եվ առաջադրանքը հետևյալն էր.
- Կան մոտ 5 բաժնետոմսեր։
- Գնանշումները հայտնի են դառնում յուրաքանչյուր 100 միլիվայրկյանը մեկ։
- Տվյալները կուտակվել են 10 տարվա ընթացքում։ Պարզվում է՝ որոշ ընկերությունների համար դրանք ավելի շատ են, մյուսների համար՝ ավելի քիչ։
- Ընդհանուր առմամբ կա մոտ 100 միլիարդ տող։
Եվ անհրաժեշտ էր հաշվարկել փոփոխությունների համադրությունը։
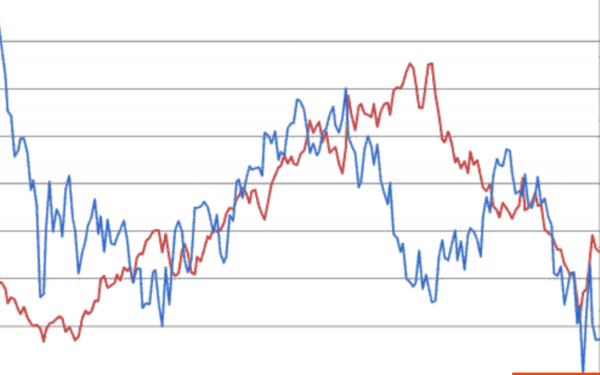
Ահա երկու բաժնետոմսեր և դրանց գնանշումները։ Եթե մեկը բարձրանում է, իսկ մյուսը՝ բարձրանում, ապա սա դրական կոռելյացիա է, այսինքն՝ մեկը աճում է, իսկ մյուսը՝ բարձրանում։ Եթե մեկը բարձրանում է, ինչպես գրաֆիկի վերջում, իսկ մյուսը՝ իջնում, ապա սա բացասական կոռելյացիա է, այսինքն՝ երբ մեկը աճում է, մյուսը իջնում է։
Այս փոխադարձ փոփոխությունները վերլուծելով՝ կարելի է կանխատեսումներ անել ֆինանսական շուկայում։

Սակայն խնդիրը բարդ է։ Ի՞նչ է արվում դրա համար։ Մենք ունենք 100 միլիարդ գրառում, որոնք պարունակում են՝ ժամանակը, բաժնետոմսը և գինը։ Նախ պետք է հաշվարկենք 100 միլիարդ անգամ runningDifference-ը գնային ալգորիթմից։ RunningDifference-ը ClickHouse-ի ֆունկցիա է, որը հաջորդաբար հաշվարկում է երկու տողերի միջև եղած տարբերությունը։
Եվ դրանից հետո դուք պետք է հաշվարկեք կորելացիան, և կորելացիան պետք է հաշվարկվի յուրաքանչյուր զույգի համար։ 5 բաժնետոմսի համար կա 000 միլիոն զույգ։ Եվ դա շատ է, այսինքն՝ դուք պետք է հաշվարկեք այս կորելացիայի ֆունկցիան 12,5 անգամ։
Եվ եթե ինչ-որ մեկը մոռացել է, ապա ͞x-ը և ͞y-ը նմուշի մաթեմատիկական սպասելիքներն են։ Այսինքն՝ մենք պետք է հաշվարկենք ոչ միայն արմատներն ու գումարները, այլև այդ գումարների ներսում գտնվող ևս մի քանի գումարներ։ Հաշվարկների մի ամբողջ փունջ պետք է կատարվի 12,5 միլիոն անգամ, և դրանք նաև պետք է խմբավորվեն ժամերով։ Եվ մենք նաև շատ ժամեր ունենք։ Եվ մենք պետք է դա անենք 60 վայրկյանում։ Սա կատակ է։

Մենք պետք է ինչ-որ կերպ կարողանայինք դա անել, քանի որ այս ամենը շատ, շատ դանդաղ էր աշխատում, նախքան ClickHouse-ի հայտնվելը։

Նրանք փորձեցին հաշվարկել այն Hadoop-ի, Spark-ի, Greenplum-ի վրա։ Եվ այս ամենը շատ դանդաղ կամ թանկ էր։ Այսինքն՝ հնարավոր էր ինչ-որ կերպ հաշվարկել այն, բայց հետո այն թանկ էր։
Եվ հետո հայտնվեց ClickHouse-ը, և ամեն ինչ շատ ավելի լավը դարձավ։
Հիշեցնեմ, որ մենք խնդիր ունենք տվյալների տեղայնացման հետ, քանի որ կորելյացիաները չեն կարող տեղայնացվել։ Մենք չենք կարող որոշ տվյալներ տեղադրել մեկ սերվերի վրա, որոշները՝ մյուսի վրա և հաշվարկել, մենք պետք է բոլոր տվյալները ունենանք ամենուր։
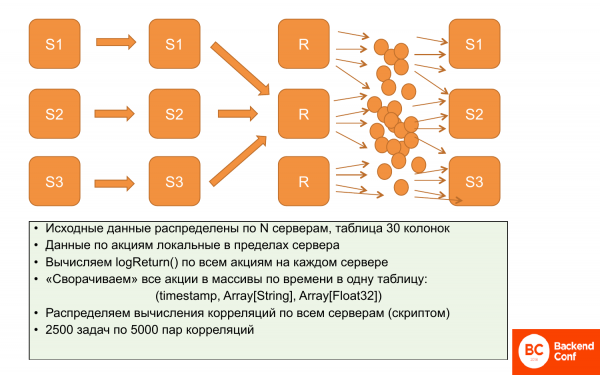
Ի՞նչ արեցին նրանք։ Սկզբում տվյալները տեղայնացված են։ Յուրաքանչյուր սերվեր պահպանում է տվյալներ բաժնետոմսերի որոշակի խմբի գնագոյացման վերաբերյալ։ Եվ դրանք չեն հատվում։ Հետևաբար, հնարավոր է logReturn-ը հաշվարկել զուգահեռ և անկախ, այս ամենը տեղի է ունենում զուգահեռ և բաշխված առայժմ։
Այնուհետև մենք որոշեցինք կրճատել այս տվյալները՝ առանց արտահայտչականությունը կորցնելու։ Կրճատել դրանք զանգվածների միջոցով, այսինքն՝ յուրաքանչյուր ժամանակային միջակայքի համար կազմել բաժնետոմսերի և գների զանգված։ Այս կերպ տվյալները շատ ավելի քիչ տեղ են զբաղեցնում։ Եվ դրանց հետ աշխատելը որոշ չափով ավելի հարմար է։ Սրանք գրեթե զուգահեռ գործողություններ են, այսինքն՝ մենք մասամբ հաշվարկում ենք զուգահեռ, ապա գրում սերվերի վրա։
Դրանից հետո այն կարող է կրկնօրինակվել։ «r» տառը նշանակում է, որ մենք կրկնօրինակել ենք այս տվյալները։ Այսինքն՝ մենք ունենք նույն տվյալները բոլոր երեք սերվերների՝ այս զանգվածների վրա։
Եվ այնուհետև, օգտագործելով հատուկ սկրիպտ, դուք կարող եք փաթեթներ պատրաստել այս 12,5 միլիոն կորելյացիաների հավաքածուից, որոնք պետք է հաշվարկվեն: Այսինքն՝ 2 առաջադրանք՝ 500 զույգ կորելյացիաներով: Եվ հաշվարկել այս առաջադրանքը որոշակի ClickHouse սերվերի վրա: Այն ունի բոլոր տվյալները, քանի որ տվյալները նույնն են, և այն կարող է հաշվարկել դրանք հաջորդաբար:
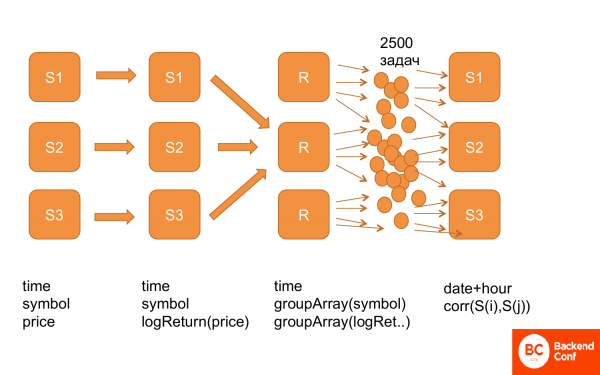
Եվս մեկ անգամ, թե ինչպես է այն տեսքը։ Սկզբում մենք ունենք այս կառուցվածքի բոլոր տվյալները՝ ժամանակը, բաժնետոմսերը, գինը։ Այնուհետև մենք հաշվարկեցինք logReturn-ը, այսինքն՝ նույն կառուցվածքի տվյալներ, միայն թե գնի փոխարեն ունենք logReturn-ը։ Այնուհետև դրանք վերամշակվեցին, այսինքն՝ մենք ստացանք time և groupArray by shares և by prices։ Կրկնօրինակվեցին։ Եվ դրանից հետո մենք ստեղծեցինք մի շարք առաջադրանքներ և ուղարկեցինք դրանք ClickHouse-ին, որպեսզի այն հաշվարկի դրանք։ Եվ այն աշխատում է։

Հայեցակարգի ապացուցման առաջադրանքի համար դա ենթաառաջադրանք էր, այսինքն՝ նրանք ավելի քիչ տվյալներ էին վերցնում։ Եվ միայն երեք սերվերների վրա։
Առաջին երկու քայլերը՝ Log_return-ի հաշվարկը և այն զանգվածներով փաթեթավորելը, տևեցին մոտ մեկ ժամ։
Եվ կորելացիայի հաշվարկը մոտ 50 ժամ է։ Սակայն 50 ժամը բավարար չէ, քանի որ նախկինում այն աշխատում էր շաբաթներ շարունակ։ Դա մեծ հաջողություն էր։ Եվ եթե հաշվեք, ապա այս կլաստերի վրա վայրկյանում 70 անգամ ամեն ինչ հաշվարկվում էր։
Բայց ամենակարևորն այն է, որ այս համակարգը գործնականում խոչընդոտներ չունի, այսինքն՝ այն գրեթե գծային կերպով է մասշտաբավորվում։ Եվ նրանք այն փորձարկեցին։ Նրանք այն հաջողությամբ մասշտաբավորեցին։

- Ճիշտ սխեման հաջողության կեսն է։ Իսկ ճիշտ սխեման բոլոր անհրաժեշտ ClickHouse տեխնոլոգիաների օգտագործումն է։
- Ամփոփելով/ԱգրեգացնելովՄիաձուլման Ծառերը (Summing/AggregatingMergeTrees)՝ դրանք տեխնոլոգիաներ են, որոնք թույլ են տալիս ագրեգացնել կամ դիտարկել վիճակի պատկերը որպես հատուկ դեպք։ Եվ սա զգալիորեն պարզեցնում է շատ բաներ։
- Նյութականացված տեսքերը թույլ են տալիս շրջանցել մեկ ինդեքսի սահմանափակումը։ Գուցե ես դա շատ հստակ չասացի, բայց երբ մենք բեռնեցինք գրանցամատյանները, հում գրանցամատյանները գտնվում էին աղյուսակում՝ մեկ ինդեքսով, իսկ ատրիբուտների գրանցամատյանները՝ աղյուսակում, այսինքն՝ նույն տվյալները, միայն ֆիլտրացված, բայց ինդեքսը բոլորովին այլ էր։ Թվում է, թե նույն տվյալներն են, բայց տարբեր տեսակավորումով։ Իսկ նյութականացված տեսքերը թույլ են տալիս շրջանցել այս ClickHouse սահմանափակումը, եթե դրա կարիքը ունեք։
- Նվազեցրեք ինդեքսի մանրամասնությունը կետային հարցումների համար։
- Եվ տվյալները իմաստուն կերպով բաշխեք, փորձեք տվյալները որքան հնարավոր է տեղայնացնել սերվերի ներսում։ Եվ փորձեք հարցումներում հնարավորինս շատ տեղայնացում կիրառել։
Եվ այս կարճ ելույթն ամփոփելով՝ կարող ենք ասել, որ ClickHouse-ը այժմ ամուր կերպով զբաղեցրել է ինչպես առևտրային, այնպես էլ բաց կոդով տվյալների բազաների տարածքը, այսինքն՝ հատկապես վերլուծության համար։ Այն զարմանալիորեն լավ է տեղավորվել այս միջավայրում։ Եվ ավելին, այն դանդաղորեն սկսում է դուրս մղել մյուսներին, քանի որ երբ դուք ունեք ClickHouse, ձեզ InfiniDB պետք չէ։ Vertika-ն շուտով կարող է ավելորդ լինել, եթե նրանք ապահովեն SQL-ի նորմալ աջակցություն։ Օգտագործեք այն։

-Շնորհակալություն զեկույցի համար։ Շատ հետաքրքիր էր։ Կային արդյոք համեմատություններ Apache Phoenix-ի հետ։
- Ոչ, ես չեմ լսել, որ որևէ մեկը համեմատություններ կատարի: Մենք և Yandex-ը փորձում ենք հետևել ClickHouse-ի բոլոր համեմատություններին տարբեր տվյալների բազաների հետ: Որովհետև եթե ինչ-որ բան ավելի արագ է պարզվում, քան ClickHouse-ը, ապա Լեշա Միլովիդովը գիշերները չի կարողանում քնել և սկսում է արագացնել այն: Ես նման համեմատության մասին չեմ լսել:
(Ալեքսեյ Միլովիդով) Apache Phoenix-ը Hbase-ի SQL շարժիչ է: Hbase-ը հիմնականում նախատեսված է բանալի-արժեք տիպի սցենարների համար: Յուրաքանչյուր տող կարող է ունենալ կամայական թվով սյուներ՝ կամայական անուններով: Սա կարելի է ասել այնպիսի համակարգերի մասին, ինչպիսիք են Hbase-ը, Cassandra-ն: Եվ ծանր վերլուծական հարցումները դրանց վրա նորմալ չեն աշխատի: Կամ կարող եք մտածել, որ դրանք նորմալ են աշխատում, եթե փորձ չունեք ClickHouse-ի հետ:
Շնորհակալություն
Բարև ձեզ։ Ես արդեն բավականին հետաքրքրված եմ այս թեմայով, քանի որ ունեմ վերլուծական ենթահամակարգ։ Բայց երբ նայում եմ ClickHouse-ին, ինձ թվում է, որ ClickHouse-ը շատ լավ է իրադարձությունները վերլուծելու համար, փոփոխական է։ Եվ եթե ես պետք է վերլուծեմ շատ բիզնես տվյալներ մեծ աղյուսակների միջոցով, ապա ClickHouse-ը, որքան ես հասկանում եմ, ինձ համար այնքան էլ հարմար չէ։ Հատկապես, եթե դրանք փոխվում են։ Սա ճի՞շտ է, թե՞ կան օրինակներ, որոնք կարող են հերքել դա։
Այո՛, ճիշտ է։ Եվ դա ճիշտ է մասնագիտացված վերլուծական տվյալների բազաների մեծ մասի համար։ Դրանք նախատեսված են մեկ կամ մի քանի մեծ, փոփոխական աղյուսակների և շատ փոքր աղյուսակների համար, որոնք դանդաղ են փոփոխվում։ Այսինքն՝ ClickHouse-ը Oracle-ի նման չէ, որտեղ կարող եք ամեն ինչ տեղադրել և կառուցել շատ բարդ հարցումներ։ ClickHouse-ը արդյունավետ օգտագործելու համար անհրաժեշտ է կառուցել սխեմա այնպես, որ այն լավ աշխատի ClickHouse-ում։ Այսինքն՝ խուսափեք չափազանց նորմալացումից, օգտագործեք բառարաններ, փորձեք ստեղծել ավելի քիչ երկար հղումներ։ Եվ եթե դուք կառուցեք սխեմա այս կերպ, ապա ClickHouse-ի վրա նմանատիպ բիզնես առաջադրանքները կարող են լուծվել շատ ավելի արդյունավետ, քան ավանդական ռելացիոն տվյալների բազայում։
Շնորհակալություն հաշվետվության համար։ Ես հարց ունեմ վերջին ֆինանսական գործի վերաբերյալ։ Նրանք ունեին վերլուծություններ։ Անհրաժեշտ էր համեմատել, թե ինչպես են դրանք աճում և նվազում։ Եվ ինչպես ես հասկանում եմ, դուք համակարգը կառուցել եք հատուկ այս վերլուծության համար։ Եթե վաղը, օրինակ, նրանց անհրաժեշտ լինի այս տվյալների վերաբերյալ որևէ այլ հաշվետվություն, արդյո՞ք նրանք պետք է նորից կառուցեն սխեման և բեռնեն տվյալները։ Այսինքն՝ կատարեն որոշակի նախնական մշակում՝ հարցումը ստանալու համար։
Իհարկե, սա ClickHouse-ի օգտագործումն է շատ կոնկրետ խնդրի համար: Այն կարելի էր ավելի ավանդական եղանակով լուծել Hadoop-ի շրջանակներում: Hadoop-ի համար սա իդեալական խնդիր է: Բայց Hadoop-ում այն շատ դանդաղ է: Եվ իմ նպատակն է ցույց տալ, որ ClickHouse-ը կարող է լուծել խնդիրներ, որոնք սովորաբար լուծվում են բոլորովին այլ միջոցներով, բայց միևնույն ժամանակ, դա կարելի է անել շատ ավելի արդյունավետ: Սա նախատեսված է կոնկրետ խնդրի համար: Ակնհայտ է, որ եթե կա մի խնդիր, որը որոշ չափով նման է, ապա այն կարող է լուծվել նմանատիպ ձևով:
Հասկացա։ Դուք ասացիք 50 ժամ մշակում։ Դա ամենասկզբից է, երբ դուք բեռնել եք տվյալները, թե՞ ստացել եք արդյունքները։
Այո, այո:
Լավ, շատ շնորհակալ եմ։
Սա 3 սերվերից բաղկացած կլաստերի վրա է։
Բարև ձեզ։ Շնորհակալություն զեկույցի համար։ Ամեն ինչ շատ հետաքրքիր է։ Ես կհարցնեմ ոչ թե ֆունկցիոնալության, այլ ClickHouse-ի օգտագործման մասին՝ կայունության տեսանկյունից։ Այսինքն՝ ունեցե՞լ եք որևէ բան, վերականգնե՞լ եք։ Ինչպե՞ս է ClickHouse-ը վարվում այս դեպքում։ Եվ պատահե՞լ է, որ դուք նույնպես ունեցել եք կրկնօրինակի խափանում։ Օրինակ՝ մենք ClickHouse-ի հետ կապված խնդրի հանդիպեցինք, երբ այն դեռևս գերազանցում է իր սահմանը և խափանվում է։
Իհարկե, իդեալական համակարգեր չկան: Եվ ClickHouse-ն ունի իր սեփական խնդիրները: Բայց լսե՞լ եք, որ Yandex.Metrica-ն երկար ժամանակ չի աշխատում: Հավանաբար՝ ոչ: Այն ClickHouse-ի վրա հուսալիորեն աշխատում է մոտավորապես 2012-2013 թվականներից: Կարող եմ նաև խոսել իմ փորձի մասին: Մենք երբեք լիակատար խափանումներ չենք ունեցել: Կարող էին տեղի ունենալ որոշ մասնակի բաներ, բայց դրանք երբեք բավականաչափ կարևոր չէին, որպեսզի լուրջ ազդեցություն ունենային բիզնեսի վրա: Սա երբեք տեղի չի ունեցել: ClickHouse-ը բավականին հուսալի է և պատահականորեն չի խափանվում: Դուք անհանգստանալու կարիք չունեք դրա համար: Դա հում բան չէ: Սա ապացուցել են բազմաթիվ ընկերություններ:
Բարև՛։ Դուք ասացիք, որ պետք է անմիջապես մտածեք տվյալների սխեմայի մասին։ Բայց ի՞նչ կլինի, եթե դա պատահի։ Իմ տվյալները անընդհատ գալիս-գնում են։ Անցնում է կես տարի, և ես հասկանում եմ, որ չեմ կարող այսպես ապրել, պետք է վերբեռնեմ տվյալները և ինչ-որ բան անեմ դրանց հետ։
Դա, իհարկե, կախված է ձեր համակարգից: Կան մի քանի եղանակներ դա գործնականում առանց կանգ առնելու անելու: Օրինակ, դուք կարող եք ստեղծել նյութականացված տեսք, որտեղ դուք ստեղծում եք տարբեր տվյալների կառուցվածք, եթե այն կարող է միանշանակորեն քարտեզագրվել: Այսինքն, եթե այն թույլ է տալիս քարտեզագրում ClickHouse-ի միջոցով, այսինքն՝ որոշ բաներ արդյունահանել, փոխել առաջնային բանալին, փոխել բաժանումը, ապա կարող եք ստեղծել նյութականացված տեսք: Վերաշարադրեք ձեր հին տվյալները այնտեղ, նորերը կգրվեն ավտոմատ կերպով: Եվ այնուհետև պարզապես անցեք նյութականացված տեսքի օգտագործմանը, այնուհետև փոխեք գրառումը և փակեք հին աղյուսակը: Սա մեթոդ է առանց ընդհանրապես կանգ առնելու:
Շնորհակալություն:
Source: www.habr.com
