

Պավել Սելիվանովը՝ Southbridge-ի լուծումների ճարտարապետը և Slurm-ի ուսուցիչը, ներկայացրեց DevOpsConf 2019-ին: Այս զրույցը Kubernetes-ի «Slurm Mega» խորացված դասընթացի թեմաներից մեկի մասն է:
նոյեմբերի 18-20-ը Մոսկվայում։
— Մոսկվա, նոյեմբերի 22-24.
միշտ հասանելի:

Կտրվածքի ներքևում ներկայացված է զեկույցի սղագրությունը:
Բարի լույս, գործընկերներ և նրանց համակրողներ։ Այսօր ես կխոսեմ անվտանգության մասին։
Ես տեսնում եմ, որ այսօր դահլիճում անվտանգության աշխատակիցները շատ են։ Ես նախապես ներողություն եմ խնդրում ձեզանից, եթե օգտագործում եմ անվտանգության աշխարհի տերմինները ոչ ճիշտ այնպես, ինչպես ձեզ համար ընդունված է:
Այնպես եղավ, որ մոտ վեց ամիս առաջ ես հանդիպեցի մեկ հանրային Kubernetes կլաստերի: Հանրային նշանակում է, որ կա անվանատարածքների n-րդ թիվը, այս անվանատարածքներում կան օգտվողներ, որոնք մեկուսացված են իրենց անվանատարածքում: Այս բոլոր օգտվողները պատկանում են տարբեր ընկերությունների: Դե, ենթադրվում էր, որ այս կլաստերը պետք է օգտագործվի որպես CDN: Այսինքն, նրանք ձեզ տալիս են կլաստեր, նրանք ձեզ տալիս են այնտեղ օգտվող, դուք գնում եք այնտեղ ձեր անվանատարածք, տեղակայում ձեր ճակատները:
Իմ նախորդ ընկերությունը փորձել է վաճառել նման ծառայություն: Եվ ինձ խնդրեցին խոթել կլաստերը՝ տեսնելու՝ արդյոք այս լուծումը հարմար է, թե ոչ:
Ես եկել եմ այս կլաստերին: Ինձ տրվեցին սահմանափակ իրավունքներ, սահմանափակ անվանական տարածք: Այնտեղի տղաները հասկացան, թե ինչ է անվտանգությունը։ Նրանք կարդացել են Role-ի վրա հիմնված մուտքի վերահսկման (RBAC) մասին Kubernetes-ում, և նրանք շրջել են այն այնպես, որ ես չկարողանամ բացել pods-ը տեղակայումներից առանձին: Ես չեմ հիշում այն խնդիրը, որը ես փորձում էի լուծել՝ առանց տեղակայման pod գործարկելով, բայց ես իսկապես ուզում էի գործարկել միայն pod: Հաջողության համար ես որոշեցի տեսնել, թե ինչ իրավունքներ ունեմ ես կլաստերում, ինչ կարող եմ անել, ինչ չեմ կարող անել, և ինչ են նրանք խեղաթյուրել այնտեղ: Միևնույն ժամանակ, ես ձեզ կասեմ, թե ինչ են նրանք սխալ կարգավորել RBAC-ում:
Այնպես եղավ, որ երկու րոպեի ընթացքում ես ստացա նրանց կլաստերի ադմինիստրատորը, նայեցի բոլոր հարևան անվանատարածքները, տեսա այնտեղ աշխատող ընկերությունների արտադրական ճակատները, որոնք արդեն գնել էին ծառայությունը և տեղակայել: Ես հազիվ էի ինձ խանգարում գնալ ինչ-որ մեկի առաջ և հայհոյանք դնել գլխավոր էջում:
Ես ձեզ օրինակներով կասեմ, թե ինչպես եմ դա արել և ինչպես պաշտպանվել ձեզ դրանից:
Բայց նախ ներկայացնեմ. Ես Պավել Սելիվանովն եմ։ Ես Սաութբրիջի ճարտարապետ եմ: Ես հասկանում եմ Kubernetes-ը, DevOps-ը և բոլոր տեսակի շքեղ բաները: Սաութբրիջի ինժեներները և ես կառուցում ենք այս ամենը, և ես խորհրդակցում եմ:
Ի լրումն մեր հիմնական գործունեության, մենք վերջերս սկսել ենք նախագծեր, որոնք կոչվում են Slurms: Մենք փորձում ենք Kubernetes-ի հետ աշխատելու մեր ունակությունը մի փոքր հասցնել զանգվածներին, սովորեցնել այլ մարդկանց նույնպես աշխատել K8-ի հետ:
Ինչի՞ մասին կխոսեմ այսօր։ Զեկույցի թեման ակնհայտ է՝ Kubernetes կլաստերի անվտանգության մասին։ Բայց ես ուզում եմ անմիջապես ասել, որ այս թեման շատ մեծ է, և, հետևաբար, ուզում եմ անմիջապես պարզաբանել, թե ինչի մասին հաստատ չեմ խոսի: Ես չեմ խոսի մոլեգնած տերմինների մասին, որոնք արդեն հարյուր անգամ օգտագործվել են համացանցում: Բոլոր տեսակի RBAC և վկայագրեր:
Ես կխոսեմ այն մասին, թե ինչն է ինձ և իմ գործընկերներին ցավում Kubernetes կլաստերի անվտանգության հարցում: Մենք տեսնում ենք այս խնդիրները ինչպես Kubernetes-ի կլաստերներ տրամադրող մատակարարների, այնպես էլ մեզ մոտ եկող հաճախորդների շրջանում: Եվ նույնիսկ հաճախորդներից, ովքեր գալիս են մեզ խորհրդատվական այլ ադմինիստրատորական ընկերություններից: Այսինքն՝ ողբերգության մասշտաբները իրականում շատ մեծ են։
Բառացիորեն երեք կետ կա, որոնց մասին այսօր կխոսեմ.
- Օգտատիրոջ իրավունքները ընդդեմ pod իրավունքների: Օգտատիրոջ իրավունքներն ու պատի իրավունքները նույնը չեն:
- Կլաստերի մասին տեղեկատվության հավաքում: Ես ցույց կտամ, որ դուք կարող եք հավաքել ձեզ անհրաժեշտ բոլոր տեղեկությունները կլաստերից՝ առանց հատուկ իրավունքներ ունենալու այս կլաստերում:
- DoS հարձակում կլաստերի վրա: Եթե չկարողանանք տեղեկատվություն հավաքել, ամեն դեպքում կկարողանանք կլաստեր դնել։ Ես կխոսեմ կլաստերի կառավարման տարրերի վրա DoS հարձակումների մասին:
Մեկ այլ ընդհանուր բան, որը ես կնշեմ, այն է, թե ինչի վրա եմ փորձարկել այս ամենը, որի վրա հաստատ կարող եմ ասել, որ այդ ամենն աշխատում է։
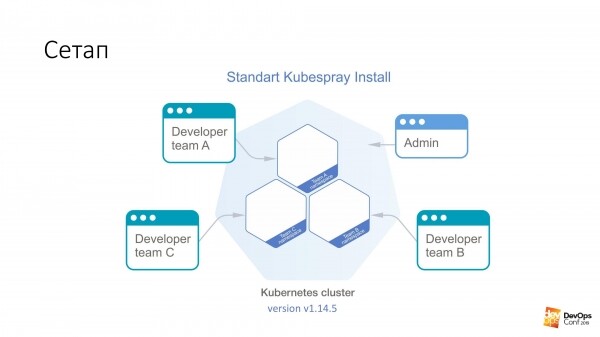
Մենք հիմք ենք ընդունում Kubernetes կլաստերի տեղադրումը Kubespray-ի միջոցով: Եթե որևէ մեկը չգիտի, սա իրականում Ansible-ի դերերի հավաքածու է: Մենք այն անընդհատ օգտագործում ենք մեր աշխատանքում։ Լավն այն է, որ դուք կարող եք այն գլորել ցանկացած վայրում. կարող եք գլորել այն երկաթի կտորների վրա կամ ինչ-որ տեղ ամպի մեջ: Տեղադրման մեկ մեթոդը սկզբունքորեն աշխատում է ամեն ինչի համար:
Այս կլաստերում ես կունենամ Kubernetes v1.14.5: Ամբողջ Cube կլաստերը, որը մենք կքննարկենք, բաժանված է անվանատարածքների, յուրաքանչյուր անվանատարածք պատկանում է առանձին թիմին, և այս թիմի անդամները մուտք ունեն յուրաքանչյուր անվանատարածք: Նրանք չեն կարող գնալ տարբեր անունների տարածքներ, միայն իրենց սեփականը: Բայց կա որոշակի ադմինիստրատորի հաշիվ, որն իրավունք ունի ամբողջ կլաստերի վրա:
Ես խոստացա, որ առաջին բանը, որ կանենք, կլաստերի վրա ադմինիստրատորի իրավունքներ ստանալն է: Մեզ պետք է հատուկ պատրաստված պատիճ, որը կկոտրի Kubernetes կլաստերը: Մեզ անհրաժեշտ է միայն կիրառել այն Kubernetes կլաստերի վրա:
kubectl apply -f pod.yamlԱյս պատիճը կհասնի Kubernetes կլաստերի վարպետներից մեկին: Եվ դրանից հետո կլաստերը մեզ հաճույքով կվերադարձնի admin.conf կոչվող ֆայլը: Cube-ում այս ֆայլը պահում է ադմինիստրատորի բոլոր վկայականները և միևնույն ժամանակ կարգավորում է կլաստերի API-ը: Ահա թե որքան հեշտ է ադմինիստրատորի հասանելիությունը, կարծում եմ, Kubernetes կլաստերների 98%-ին:
Կրկնում եմ՝ այս պատիճը ստեղծվել է ձեր կլաստերի մեկ ծրագրավորողի կողմից, ով ունի իր առաջարկները մեկ փոքր անվանատարածքի մեջ տեղակայելու հնարավորություն, այն բոլորը սեղմված է RBAC-ի կողմից: Նա իրավունք չուներ։ Բայց, այնուամենայնիվ, վկայականը վերադարձվել է։
Հիմա եկեք խոսենք հատուկ պատրաստված պոդի մասին։ Մենք կարող ենք այն գործարկել ցանկացած պատկերի վրա։ Եկեք սա վերցնենք որպես օրինակ։ debian:ջեսսի։
Մենք ունենք այս բանը.
tolerations:
- effect: NoSchedule
operator: Exists
nodeSelector:
node-role.kubernetes.io/master: "" Ի՞նչ է հանդուրժողականությունը: Կուբերնետեսի կլաստերի վարպետները սովորաբար նշվում են ինչ-որ բանով, որը կոչվում է բիծ: Եվ այս «վարակի» էությունն այն է, որ ասում է, որ պատիճները չեն կարող վերագրվել վարպետ հանգույցներին: Բայց ոչ ոք չի խանգարում որևէ պատիճում նշել, որ այն հանդուրժող է «վարակին»: Հանդուրժողականություն բաժինը պարզապես ասում է, որ եթե որոշ հանգույց ունի NoSchedule, ապա մեր հանգույցը հանդուրժող է նման վարակի նկատմամբ, և խնդիրներ չկան:
Ավելին, մենք ասում ենք, որ մեր տակը ոչ միայն հանդուրժող է, այլև ցանկանում է հատուկ թիրախավորել վարպետին: Որովհետև վարպետներն ունեն մեզ ամենահամեղ բանը՝ բոլոր վկայականները։ Հետևաբար, մենք ասում ենք nodeSelector - և մենք ունենք ստանդարտ պիտակ վարպետների վրա, որը թույլ է տալիս կլաստերի բոլոր հանգույցներից ընտրել հենց այն հանգույցները, որոնք վարպետ են:
Այս երկու բաժիններով նա անպայման կգա վարպետի մոտ։ Եվ նրան թույլ կտան ապրել այնտեղ։
Բայց միայն վարպետի մոտ գալը մեզ քիչ է։ Սա մեզ ոչինչ չի տա: Այսպիսով, հաջորդիվ մենք ունենք այս երկու բանը.
hostNetwork: true
hostPID: true Մենք նշում ենք, որ մեր բլոկը, որը մենք գործարկում ենք, կապրի միջուկի անվանատարածքում, ցանցի անվանատարածքում և PID անվանումների տարածքում: Հենց որ pod-ը գործարկվի վարպետի վրա, այն կկարողանա տեսնել այս հանգույցի իրական, կենդանի միջերեսները, լսել ամբողջ տրաֆիկը և տեսնել բոլոր գործընթացների PID-ը:
Հետո դա մանրուքների հարց է: Վերցրեք etcd և կարդացեք այն, ինչ ուզում եք:
Ամենահետաքրքիրը Kubernetes-ի այս ֆունկցիան է, որը լռելյայն առկա է այնտեղ։
volumeMounts:
- mountPath: /host
name: host
volumes:
- hostPath:
path: /
type: Directory
name: host Եվ դրա էությունն այն է, որ մենք կարող ենք ասել, որ pod-ում մենք գործարկում ենք, նույնիսկ առանց այս կլաստերի իրավունքների, որ ցանկանում ենք ստեղծել hostPath տիպի ծավալ: Սա նշանակում է վերցնել այն հոսթից այն ճանապարհը, որով մենք կգործարկենք, և այն վերցնել որպես ծավալ: Եվ հետո մենք այն անվանում ենք՝ հյուրընկալող: Մենք տեղադրում ենք այս ամբողջ hostPath-ը պատի ներսում: Այս օրինակում դեպի / host գրացուցակ:
Կրկնեմ էլի. Մենք ասացինք pod-ին, որ գա վարպետի մոտ, այնտեղ ստանա hostNetwork-ը և hostPID-ը և տեղադրի վարպետի ամբողջ արմատը այս պատի ներսում:
Դուք հասկանում եք, որ Debian-ում մենք ունենք bash run, և այս bash-ն անցնում է արմատի տակ: Այսինքն՝ մենք ուղղակի արմատ ենք ստացել վարպետի վրա՝ առանց Kubernetes կլաստերի որևէ իրավունք ունենալու։
Այնուհետև ամբողջ խնդիրն այն է, որ գնան ենթատեղեկատու /host /etc/kubernetes/pki, եթե չեմ սխալվում, այնտեղ վերցնել կլաստերի բոլոր հիմնական վկայականները և, համապատասխանաբար, դառնալ կլաստերի ադմինիստրատոր։
Եթե դուք դրան նայեք այս կերպ, ապա սրանք մի քանի ամենավտանգավոր իրավունքներից են pods-ում՝ անկախ նրանից, թե ինչ իրավունքներ ունի օգտատերը.
Եթե ես իրավունք ունեմ կլաստերի ինչ-որ անվանատարածքում փոդ գործարկելու, ապա այս պատիճը լռելյայն ունի այս իրավունքները: Ես կարող եմ գործարկել արտոնյալ pods, և դրանք, ընդհանուր առմամբ, բոլոր իրավունքներն են, գործնականում արմատավորում են հանգույցի վրա:
Իմ սիրելին Root օգտվողն է: Եվ Kubernetes-ն ունի այս Run As Non-Root տարբերակը: Սա հաքերից պաշտպանվելու տեսակ է։ Գիտե՞ք ինչ է «մոլդավական վիրուսը»։ Եթե դուք հանկարծ հաքեր եք և գալիս եք իմ Kubernetes կլաստերը, ապա մենք՝ խեղճ ադմինիստրատորներս, հարցնում ենք. Հակառակ դեպքում այնպես կլինի, որ դուք պրոցեսը վարեք ձեր pod-ում root տակ, և ձեզ համար շատ հեշտ կլինի կոտրել ինձ։ Խնդրում եմ պաշտպանվեք ինքներդ ձեզանից»:
Հյուրընկալող ուղու ծավալը, իմ կարծիքով, Kubernetes կլաստերից ցանկալի արդյունք ստանալու ամենաարագ ճանապարհն է:
Բայց ի՞նչ անել այս ամենի հետ։
Կուբերնետեսի հետ հանդիպող ցանկացած նորմալ ադմինիստրատորի միտքը հետևյալն է. «Այո, ես ասացի ձեզ, Kubernetes-ը չի աշխատում: Նրա մեջ կան անցքեր: Եվ ամբողջ Cube-ը հիմարություն է»: Փաստորեն, փաստաթղթավորում ասվածը կա, ու եթե նայես, բաժին կա .
Սա yaml օբյեկտ է. մենք կարող ենք այն ստեղծել Kubernetes կլաստերում, որը վերահսկում է անվտանգության ասպեկտները, մասնավորապես, պատիճների նկարագրության մեջ: Այսինքն, ըստ էության, այն վերահսկում է ցանկացած hostNetwork, hostPID, որոշակի ծավալի տեսակների օգտագործման իրավունքները, որոնք գտնվում են գործարկման ժամանակ: Pod Security Policy-ի օգնությամբ այս ամենը կարելի է նկարագրել։
Pod Security Policy-ի հետ կապված ամենահետաքրքիրն այն է, որ Kubernetes կլաստերում բոլոր PSP տեղադրողները ոչ միայն որևէ կերպ նկարագրված չեն, այլ պարզապես անջատված են լռելյայն: Pod անվտանգության քաղաքականությունը միացված է ընդունելության հավելվածի միջոցով:
Լավ, եկեք տեղակայենք Pod Security Policy-ը կլաստերի մեջ, ասենք, որ անունների տարածքում ունենք որոշ սպասարկման բլոկներ, որոնց մուտք ունեն միայն ադմինները: Ասենք, մնացած բոլոր դեպքերում պատիճները սահմանափակ իրավունքներ ունեն։ Որովհետև, ամենայն հավանականությամբ, մշակողները կարիք չունեն գործարկել արտոնյալ բլոկներ ձեր կլաստերում:
Իսկ մեզ մոտ ամեն ինչ կարծես թե լավ է։ Իսկ մեր Kubernetes կլաստերը հնարավոր չէ կոտրել երկու րոպեում:
Խնդիր կա. Ամենայն հավանականությամբ, եթե դուք ունեք Kubernetes կլաստեր, ապա ձեր կլաստերի վրա տեղադրվում է մոնիտորինգ: Ես նույնիսկ կգնայի այնքան հեռու, որ կանխատեսեի, որ եթե ձեր կլաստերը մոնիտորինգ ունենա, այն կկոչվի Պրոմեթևս:
Այն, ինչ ես պատրաստվում եմ ձեզ ասել, վավեր կլինի և՛ Պրոմեթևսի օպերատորի, և՛ Պրոմեթևսի համար, որը մատուցվում է իր մաքուր տեսքով: Հարցն այն է, որ եթե ես չկարողանամ այդքան արագ ադմին ներգրավել կլաստերի մեջ, ապա դա նշանակում է, որ ես պետք է ավելի շատ փնտրեմ: Եվ ես կարող եմ որոնել ձեր մոնիտորինգի օգնությամբ։
Հավանաբար բոլորը կարդում են նույն հոդվածները Habré-ում, և մոնիտորինգը գտնվում է մոնիտորինգի անվանման տարածքում: Սաղավարտի աղյուսակը կոչվում է մոտավորապես նույնը բոլորի համար: Ես կռահում եմ, որ եթե դուք տեղադրեք stable/prometheus, դուք կստանաք մոտավորապես նույն անունները: Եվ, ամենայն հավանականությամբ, ես նույնիսկ ստիպված չեմ լինի գուշակել DNS անունը ձեր կլաստերում: Քանի որ դա ստանդարտ է:
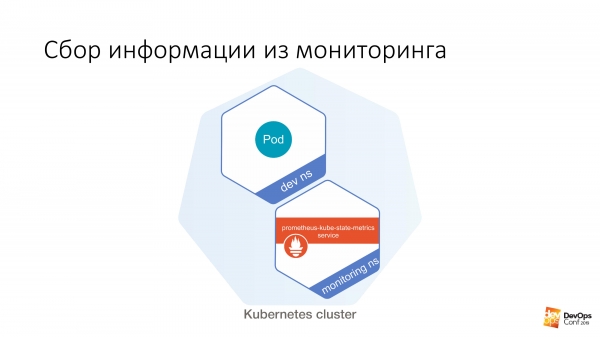
Հաջորդը մենք ունենք որոշակի dev ns, որտեղ դուք կարող եք գործարկել որոշակի pod: Եվ հետո այս պատյանից շատ հեշտ է նման բան անել.
$ curl http://prometheus-kube-state-metrics.monitoring prometheus-kube-state-metrics-ը Պրոմեթևսի արտահանողներից մեկն է, որը չափումներ է հավաքում հենց Kubernetes API-ից: Այնտեղ շատ տվյալներ կան, թե ինչ է աշխատում ձեր կլաստերում, ինչ է դա, ինչ խնդիրներ ունեք դրա հետ։
Որպես պարզ օրինակ.
kube_pod_container_info{namespace=“kube-system”,pod=”kube-apiserver-k8s- 1″,container=”kube-apiserver”,image=
«gcr.io/google-containers/kube-apiserver:v1.14.5»
,image_id=»docker-pullable://gcr.io/google-containers/kube- apiserver@sha256:e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989″,container_id=»docker://7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b»} 1
Կատարելով պարզ գանգրացման հարցում ոչ արտոնյալ պատիճից, կարող եք ստանալ հետևյալ տեղեկատվությունը. Եթե չգիտեք, թե Kubernetes-ի որ տարբերակն եք օգտագործում, այն հեշտությամբ կպատմի ձեզ:
Եվ ամենահետաքրքիրն այն է, որ բացի kube-state-metrics մուտք գործելուց, դուք նույնքան հեշտությամբ կարող եք ուղղակիորեն մուտք գործել հենց ինքը՝ Պրոմեթևսը: Այնտեղից կարող եք չափումներ հավաքել: Դուք նույնիսկ կարող եք չափումներ կառուցել այնտեղից: Նույնիսկ տեսականորեն, դուք կարող եք նման հարցում կառուցել Պրոմեթևսի կլաստերից, որը պարզապես կանջատի այն: Եվ ձեր մոնիտորինգն ընդհանրապես կդադարի աշխատել կլաստերից:
Եվ այստեղ հարց է առաջանում՝ արդյոք որեւէ արտաքին մոնիտորինգ վերահսկո՞ւմ է ձեր մոնիտորինգը։ Ես հենց նոր հնարավորություն ստացա գործել Kubernetes կլաստերում՝ առանց ինձ համար որևէ հետևանքի։ Դուք նույնիսկ չեք իմանա, որ ես այնտեղ եմ գործում, քանի որ այլևս մոնիտորինգ չկա։
Ինչպես PSP-ի դեպքում, խնդիրն այն է, որ այս բոլոր շքեղ տեխնոլոգիաները՝ Kubernetes, Prometheus, պարզապես չեն աշխատում և լի են անցքերով: Իրականում ոչ:
Նման բան կա - .
Եթե դուք նորմալ ադմին եք, ապա, ամենայն հավանականությամբ, դուք գիտեք Ցանցային քաղաքականության մասին, որ սա հերթական yaml-ն է, որից արդեն շատ են դրանք կլաստերում: Եվ որոշ Ցանցային Քաղաքականություններ հաստատ պետք չեն: Եվ նույնիսկ եթե դուք կարդաք, թե ինչ է ցանցային քաղաքականությունը, որ դա Kubernetes-ի yaml firewall է, այն թույլ է տալիս սահմանափակել մուտքի իրավունքները անունների տարածքների միջև, ապա դուք, անշուշտ, որոշել եք, որ Kubernetes-ում yaml ձևաչափով firewall-ը հիմնված է հաջորդ աբստրակցիաների վրա: ... Ոչ, ոչ: Սա հաստատ անհրաժեշտ չէ։
Նույնիսկ եթե դուք չեք ասել ձեր անվտանգության մասնագետներին, որ օգտագործելով ձեր Kubernetes-ը, դուք կարող եք կառուցել շատ հեշտ և պարզ firewall, ընդ որում՝ շատ հատիկավոր: Եթե նրանք դեռ չգիտեն դա և չեն անհանգստացնում ձեզ. «Դե, տուր ինձ, տուր ինձ...»: Այնուհետև, ամեն դեպքում, ձեզ հարկավոր է Ցանցային քաղաքականություն՝ արգելափակելու մուտքը սպասարկման որոշ վայրեր, որոնք կարող են հանվել ձեր կլաստերից: առանց որևէ թույլտվության։
Ինչպես իմ բերած օրինակում, դուք կարող եք վեր հանել kube վիճակի չափումները Kubernetes կլաստերի ցանկացած անվանատարածքից՝ առանց դրա իրավունք ունենալու: Ցանցային քաղաքականությունը փակ մուտք ունի բոլոր մյուս անվանատարածքներից դեպի մոնիտորինգի անվանատարածք և վերջ. մուտք չկա, խնդիրներ չկան: Բոլոր գծապատկերներում, որոնք գոյություն ունեն, և՛ ստանդարտ Պրոմեթևսը, և՛ Պրոմեթևսը, որը գտնվում է օպերատորում, ուղղակի ղեկի արժեքներում կա մի տարբերակ՝ պարզապես նրանց համար ցանցային քաղաքականությունը միացնելու համար: Պարզապես պետք է միացնել այն, և նրանք կաշխատեն:
Այստեղ իսկապես մեկ խնդիր կա. Լինելով սովորական մորուքավոր ադմին, դուք, ամենայն հավանականությամբ, որոշել եք, որ ցանցային քաղաքականություններն անհրաժեշտ չեն: Եվ Habr-ի նման ռեսուրսների վերաբերյալ բոլոր տեսակի հոդվածներ կարդալուց հետո դուք որոշեցիք, որ ֆլանելը, հատկապես host-gateway ռեժիմով, լավագույն բանն է, որ կարող եք ընտրել:
Ինչ անել?
Դուք կարող եք փորձել վերատեղակայել ցանցային լուծումը, որը դուք ունեք ձեր Kubernetes կլաստերում, փորձեք այն փոխարինել ավելի ֆունկցիոնալով: Նույն Calico-ի համար, օրինակ. Բայց ես ուզում եմ անմիջապես ասել, որ Kubernetes աշխատանքային կլաստերում ցանցային լուծումը փոխելու խնդիրը բավականին աննշան է: Ես երկու անգամ լուծեցի այն (երկու անգամն էլ, սակայն, տեսականորեն), բայց մենք նույնիսկ ցույց տվեցինք, թե ինչպես դա անել Slurms-ում: Մեր ուսանողների համար մենք ցույց տվեցինք, թե ինչպես փոխել ցանցային լուծումը Kubernetes կլաստերում: Սկզբունքորեն, դուք կարող եք փորձել համոզվել, որ արտադրական կլաստերի վրա ժամանակ չի լինի: Բայց, հավանաբար, ձեզ չի հաջողվի:
Իսկ խնդիրն իրականում շատ պարզ է լուծվում։ Կլաստերում կան վկայագրեր, և դուք գիտեք, որ ձեր վկայականների ժամկետը կլրանա մեկ տարուց: Դե, և սովորաբար նորմալ լուծում է սերտիֆիկատներով կլաստերում. ինչու ենք մենք անհանգստանում, մենք մոտակայքում նոր կլաստեր կբարձրացնենք, թույլ կտանք, որ հինը փչանա և ամեն ինչ վերաբաշխենք: Ճիշտ է, երբ այն փչանա, մենք ստիպված կլինենք մի օր նստել, բայց ահա նոր կլաստեր:
Երբ բարձրացնում եք նոր կլաստեր, միևնույն ժամանակ ֆլանելի փոխարեն ներդիր Calico-ն:
Ի՞նչ անել, եթե ձեր վկայականները տրվում են հարյուր տարով, և դուք չեք պատրաստվում վերատեղակայել կլաստերը: Գոյություն ունի Kube-RBAC-Proxy-ի նման բան: Սա շատ հիանալի զարգացում է, այն թույլ է տալիս իրեն որպես կողային բեռնարկղ տեղադրել Kubernetes կլաստերի ցանկացած պատիճ: Եվ այն իրականում թույլտվություն է ավելացնում այս պատին հենց Kubernetes-ի RBAC-ի միջոցով:
Մեկ խնդիր կա. Նախկինում այս Kube-RBAC-Proxy լուծումը ներկառուցված էր օպերատորի Prometheus-ում: Բայց հետո նա գնացել էր։ Այժմ ժամանակակից տարբերակները հիմնվում են այն փաստի վրա, որ դուք ունեք ցանցային քաղաքականություն և փակեք այն՝ օգտագործելով դրանք: Եվ հետևաբար, մենք ստիպված կլինենք մի փոքր վերաշարադրել աղյուսակը: Փաստորեն, եթե դուք գնում եք , կան օրինակներ, թե ինչպես կարելի է սա օգտագործել որպես կողային վահանակներ, և գծապատկերները պետք է նվազագույնը վերաշարադրվեն:
Կա ևս մեկ փոքր խնդիր. Պրոմեթևսը միակը չէ, որ իր ցուցանիշները տալիս է որևէ մեկին: Մեր բոլոր Kubernetes կլաստերի բաղադրիչները նույնպես կարող են վերադարձնել իրենց չափումները:
Բայց ինչպես արդեն ասացի, եթե չես կարող մուտք գործել կլաստեր և տեղեկություններ հավաքել, ապա կարող ես գոնե ինչ-որ վնաս հասցնել:
Այսպիսով, ես արագ ցույց կտամ երկու ճանապարհ, թե ինչպես կարող է քանդվել Kubernetes կլաստերը:
Դուք կծիծաղեք, երբ ես ձեզ սա ասեմ, սրանք երկու իրական կյանքի դեպքեր են։
Մեթոդ առաջին. Ռեսուրսների սպառում.
Եկեք գործարկենք ևս մեկ հատուկ պատիճ: Այն կունենա այսպիսի բաժին.
resources:
requests:
cpu: 4
memory: 4Gi Ինչպես գիտեք, հարցումները CPU-ի և հիշողության քանակն է, որը վերապահված է հոսթին հատուկ խնդրանքներով պատյանների համար: Եթե մենք ունենք չորս միջուկանի հոսթ Kubernetes կլաստերում, և չորս պրոցեսորային պատիճներ ժամանում են այնտեղ հարցումներով, դա նշանակում է, որ այլևս հարցումներով պատյաններ չեն կարողանա գալ այս հոսթ:
Եթե ես գործարկեմ այդպիսի պատիճ, ապա կգործարկեմ հրամանը.
$ kubectl scale special-pod --replicas=...Այդ դեպքում ուրիշ ոչ ոք չի կարողանա տեղակայվել Kubernetes կլաստերում: Քանի որ բոլոր հանգույցների հարցումները կսպառվեն: Եվ այսպես, ես կկանգնեցնեմ ձեր Kubernetes կլաստերը: Եթե ես դա անեմ երեկոյան, ապա կարող եմ բավականին երկար ժամանակով դադարեցնել տեղակայումները։
Եթե նորից նայենք Kubernetes-ի փաստաթղթերին, կտեսնենք այս բանը, որը կոչվում է Սահմանափակ տիրույթ: Այն ռեսուրսներ է սահմանում կլաստերային օբյեկտների համար: Դուք կարող եք գրել Limit Range օբյեկտ yaml-ով, կիրառել այն որոշակի անվանատարածքների վրա, և այնուհետև այս անվանատարածքում կարող եք ասել, որ դուք ունեք լռելյայն, առավելագույն և նվազագույն ռեսուրսներ pods-ի համար:
Նման բանի օգնությամբ մենք կարող ենք սահմանափակել օգտատերերին թիմերի հատուկ ապրանքների անվանատարածքներում՝ իրենց պատյանների վրա բոլոր տեսակի տհաճ բաներ նշելու ունակությամբ: Բայց, ցավոք, նույնիսկ եթե օգտագործողին ասեք, որ նրանք չեն կարող գործարկել մեկից ավելի պրոցեսորների խնդրանքով պատյաններ, կա նման հրաշալի մասշտաբի հրաման, կամ նրանք կարող են մասշտաբներ կատարել վահանակի միջոցով:
Եվ այստեղից է գալիս թիվ երկու մեթոդը: Մենք գործարկում ենք 11 պատիճ: Դա տասնմեկ միլիարդ է: Սա ոչ թե այն պատճառով է, որ ես նման թիվ եմ հորինել, այլ այն պատճառով, որ ինքս եմ դա տեսել։
Իրական պատմություն. Ուշ երեկոյան ես պատրաստվում էի դուրս գալ գրասենյակից։ Ես տեսնում եմ մի խումբ ծրագրավորողներ, որոնք նստած են անկյունում և խելագարված ինչ-որ բան են անում իրենց նոութբուքերի հետ: Ես բարձրանում եմ տղաների մոտ և հարցնում. «Ի՞նչ է պատահել ձեզ»:
Քիչ առաջ, երեկոյան ժամը իննին մոտ, ծրագրավորողներից մեկը պատրաստվում էր տուն գնալ։ Եվ ես որոշեցի. Մեկը սեղմեցի, բայց ինտերնետը մի քիչ դանդաղեց։ Նա նորից սեղմեց մեկը, սեղմեց մեկը և սեղմեց Enter: Ես խփեցի այն ամենի վրա, ինչ կարող էի: Այնուհետև ինտերնետը կյանքի կոչվեց, և ամեն ինչ սկսեց կրճատվել մինչև այս թիվը:
Ճիշտ է, այս պատմությունը տեղի չի ունեցել Կուբերնետեսում, այն ժամանակ դա Nomad էր: Այն ավարտվեց նրանով, որ մեկ ժամ անց մեր փորձերից հետո՝ կանգնեցնելու Nomad-ին սանդղակի համառ փորձերից, Nomad-ը պատասխանեց, որ ինքը չի դադարի ընդլայնվել և այլ բան չի անի: «Հոգնել եմ, գնում եմ»։ Եվ նա կծկվեց:
Բնականաբար, ես փորձեցի նույնը անել Kubernetes-ում։ Կուբերնետեսը գոհ չէր տասնմեկ միլիարդ պատիճից, նա ասաց. «Ես չեմ կարող: Գերազանցում է բերանի ներքին պաշտպանիչ միջոցները»: Բայց 1 պատիճ կարող էր:
Ի պատասխան մեկ միլիարդի, խորանարդը չի քաշվել իր մեջ: Նա իսկապես սկսեց սանդղել: Որքան ավելի առաջ էր ընթանում գործընթացը, այնքան ավելի շատ ժամանակ էր պահանջվում նրանից՝ ստեղծելու նոր պատյաններ: Բայց, այնուամենայնիվ, գործընթացը շարունակվեց։ Միակ խնդիրն այն է, որ եթե ես կարողանամ անսահմանափակ կերպով բացել pods իմ անվանատարածքում, ապա նույնիսկ առանց հարցումների և սահմանափակումների ես կարող եմ գործարկել այնքան շատ pods որոշ առաջադրանքներով, որ այդ առաջադրանքների օգնությամբ հանգույցները կսկսեն ավելացնել հիշողության մեջ, CPU-ում: Երբ ես գործարկում եմ այդքան շատ pods, դրանցից ստացված տեղեկատվությունը պետք է մտնի պահեստ, այսինքն և այլն: Եվ երբ չափազանց շատ տեղեկատվություն է հասնում այնտեղ, պահեստը սկսում է շատ դանդաղ վերադառնալ, և Kubernetes-ը սկսում է ձանձրալի դառնալ:
Եվ ևս մեկ խնդիր... Ինչպես գիտեք, Kubernetes-ի կառավարման տարրերը ոչ թե մեկ կենտրոնական բան են, այլ մի քանի բաղադրիչ։ Մասնավորապես, կա վերահսկիչի կառավարիչ, ժամանակացույց և այլն: Այս բոլոր տղաները կսկսեն միաժամանակ անհարկի, հիմար աշխատանք կատարել, որը ժամանակի ընթացքում ավելի ու ավելի շատ ժամանակ կխլի: Կարգավորիչի կառավարիչը կստեղծի նոր պատյաններ: Scheduler-ը կփորձի նոր հանգույց գտնել նրանց համար: Ամենայն հավանականությամբ, շուտով ձեր կլաստերի նոր հանգույցները կսպառվեն: Kubernetes կլաստերը կսկսի աշխատել ավելի ու ավելի դանդաղ:
Բայց ես որոշեցի ավելի հեռուն գնալ։ Ինչպես գիտեք, Kubernetes-ում կա նման բան, որը կոչվում է ծառայություն։ Դե, լռելյայնորեն ձեր կլաստերներում, ամենայն հավանականությամբ, ծառայությունն աշխատում է IP աղյուսակների միջոցով:
Եթե, օրինակ, գործարկեք մեկ միլիարդ pods, ապա օգտագործեք սցենար՝ ստիպելու Kubernetis-ին ստեղծել նոր ծառայություններ.
for i in {1..1111111}; do
kubectl expose deployment test --port 80
--overrides="{"apiVersion": "v1",
"metadata": {"name": "nginx$i"}}";
done Կլաստերի բոլոր հանգույցներում մոտավորապես միաժամանակ կստեղծվեն ավելի ու ավելի շատ նոր iptables կանոններ: Ավելին, յուրաքանչյուր ծառայության համար կստեղծվի մեկ միլիարդ iptables կանոն:
Այս ամբողջը ստուգեցի մի քանի հազարի վրա, մինչև տասը։ Եվ խնդիրն այն է, որ արդեն այս շեմին բավականին խնդրահարույց է հանգույցին ssh անելը։ Քանի որ փաթեթները, անցնելով շատ շղթաներով, սկսում են իրենց ոչ այնքան լավ զգալ:
Եվ սա նույնպես լուծվում է Kubernetes-ի օգնությամբ։ Նման ռեսուրսների քվոտայի օբյեկտ կա։ Սահմանում է հասանելի ռեսուրսների և օբյեկտների քանակը կլաստերի անվանատարածքի համար: Մենք կարող ենք ստեղծել yaml օբյեկտ Kubernetes կլաստերի յուրաքանչյուր անվանատարածքում: Օգտագործելով այս օբյեկտը, մենք կարող ենք ասել, որ մենք ունենք որոշակի թվով հարցումներ և սահմանափակումներ, որոնք հատկացված են այս անվանատարածքին, այնուհետև կարող ենք ասել, որ այս անվանատարածքում հնարավոր է ստեղծել 10 ծառայություն և 10 պատիճ։ Եվ միայնակ մշակողը կարող է գոնե երեկոները խեղդել իրեն: Կուբերնետեսը նրան կասի. «Դուք չեք կարող չափել ձեր պատիճները այդ չափով, քանի որ ռեսուրսը գերազանցում է քվոտան»: Վերջ, խնդիրը լուծված է։ .
Այս առումով մեկ խնդրահարույց կետ է առաջանում. Դուք զգում եք, թե որքան դժվար է դառնում Kubernetes-ում անվանատարածք ստեղծելը: Այն ստեղծելու համար մենք պետք է շատ բաներ հաշվի առնենք։
Ռեսուրսների քվոտա + Սահմանափակ միջակայք + RBAC
• Ստեղծեք անվանատարածք
• Ստեղծեք սահմանային միջակայք ներսում
• Ստեղծեք ռեսուրսների քվոտա
• Ստեղծեք սպասարկման հաշիվ CI-ի համար
• Ստեղծեք rolebinding CI-ի և օգտվողների համար
• Ընտրովի գործարկեք անհրաժեշտ սպասարկման բլոկները
Ուստի, օգտվելով առիթից, կցանկանայի կիսվել իմ զարգացումներով։ Նման բան կա, որը կոչվում է SDK օպերատոր: Սա Kubernetes կլաստերի համար օպերատորներ գրելու միջոց է: Դուք կարող եք հայտարարություններ գրել Ansible-ի միջոցով:
Սկզբում գրված էր Ansible-ով, հետո տեսա, որ կա SDK օպերատոր և Ansible դերը վերագրեցի օպերատորի։ Այս հայտարարությունը թույլ է տալիս Kubernetes կլաստերում ստեղծել մի օբյեկտ, որը կոչվում է հրաման: Հրամանի ներսում այն թույլ է տալիս նկարագրել այս հրամանի միջավայրը yaml-ով: Եվ թիմային միջավայրում դա մեզ թույլ է տալիս նկարագրել, որ մենք այդքան շատ ռեսուրսներ ենք հատկացնում:
Փոքրիկ .
Եվ վերջում. Ի՞նչ անել այս ամենի հետ:
Առաջին. Pod անվտանգության քաղաքականությունը լավ է: Եվ չնայած այն հանգամանքին, որ Kubernetes-ի տեղադրողներից ոչ մեկը չի օգտագործում դրանք մինչ օրս, դուք դեռ պետք է օգտագործեք դրանք ձեր կլաստերներում:
Ցանցային քաղաքականությունը պարզապես ևս մեկ ավելորդ հատկանիշ չէ: Սա այն է, ինչ իսկապես անհրաժեշտ է կլաստերում:
LimitRange/ResourceQuota - ժամանակն է օգտագործել այն: Մենք սա սկսել ենք օգտագործել շատ վաղուց, և ես երկար ժամանակ համոզված էի, որ բոլորն օգտագործում են այն։ Պարզվեց, որ սա հազվադեպ է լինում։
Ի լրումն այն, ինչ ես նշեցի զեկույցի ժամանակ, կան չփաստաթղթավորված գործառույթներ, որոնք թույլ են տալիս հարձակվել կլաստերի վրա: Վերջերս թողարկված .
Որոշ բաներ այնքան տխուր են և վիրավորական: Օրինակ, որոշակի պայմաններում Kubernetes կլաստերի cubelets-ը կարող է warlocks գրացուցակի բովանդակությունը տրամադրել չարտոնված օգտվողին:
Կան հրահանգներ, թե ինչպես վերարտադրել այն ամենը, ինչ ես ձեզ ասացի: Կան ֆայլեր արտադրական օրինակներով, թե ինչպիսի տեսք ունեն ResourceQuota-ն և Pod Security Policy-ը: Եվ դուք կարող եք դիպչել այս ամենին:
Շնորհակալություն բոլորին.
Source: www.habr.com
