

Pada 14 Maret 2017, Artur Khachuyan, CEO Social Data Hub, berbicara di ruang kuliah BBDO. Ia membahas pemantauan cerdas, membangun model perilaku, mengenali konten foto dan video, serta berbagai perangkat dan riset Social Data Hub lainnya yang memungkinkan penargetan audiens menggunakan media sosial dan teknologi Big Data.

Artur Khachuyan (selanjutnya - AH): Halo! Halo semuanya! Nama saya Artur Khachuyan, dan saya mengelola Social Data Hub, tempat kami melakukan berbagai analisis intelektual yang menarik tentang sumber data terbuka, bidang informasi, dan melakukan berbagai penelitian menarik.
Hari ini, rekan-rekan saya dari BBDO Group meminta saya untuk membahas teknologi analitik big data modern, baik yang besar maupun kecil, untuk periklanan: bagaimana penerapannya, dan untuk berbagi beberapa contoh menarik. Saya harap Anda akan bertanya selama sesi ini, karena saya mungkin akan sedikit membosankan dan tidak membahas inti permasalahannya, jadi jangan ragu.
Faktanya, area utama penerapan solusi "hampir-big-data" sudah jelas: penargetan audiens, analisis, dan pelaksanaan semacam riset pemasaran analitis. Namun, selalu menarik untuk melihat data tambahan apa yang bisa ditemukan, makna tambahan apa yang bisa dipetik dari penerapan analisis tersebut.
Mengapa kita membutuhkan teknologi untuk periklanan?
Dari mana kita mulai? Yang paling jelas adalah iklan media sosial. Saya mengambil ini tadi pagi: entah kenapa, VKontakte merasa saya harus melihat iklan ini... Baik atau buruk itu pertanyaan lain. Kita lihat bahwa saya jelas termasuk dalam kategori wajib militer:

Hal pertama dan paling menarik yang bisa dianggap sebagai solusi teknologi... Hal pertama yang ingin saya putuskan sebelum kita mulai adalah mendefinisikan istilah-istilahnya: apa itu data terbuka dan apa itu big data? Karena setiap orang punya pemahamannya masing-masing tentang hal ini, dan saya tidak ingin memaksakan istilah saya kepada siapa pun, tapi... Agar tidak ada perbedaan.
Secara pribadi, saya menganggap data terbuka sebagai apa pun yang dapat saya akses tanpa login atau kata sandi. Ini termasuk profil media sosial terbuka, hasil pencarian, registri terbuka, dan sebagainya. Big data, dalam pemahaman saya, adalah sebagai berikut: jika berupa tabel data, isinya miliaran baris; jika berupa semacam penyimpanan berkas, isinya sekitar satu petabyte data. Apa pun selain itu, dalam terminologi saya, bukanlah big data, melainkan sesuatu yang mendekatinya.
Profil presisi tinggi dan penilaian profil
Mari kita bahas langkah demi langkah. Hal pertama dan paling menarik yang dapat dipetik dari analisis sumber data terbuka adalah profiling dan penilaian profil presisi tinggi. Apa itu? Ini adalah konsep di mana akun media sosial Anda dapat digunakan untuk memprediksi tidak hanya siapa Anda, tetapi juga minat Anda.
Namun kini, dengan menggabungkan berbagai sumber, Anda dapat memahami gaji rata-rata, harga apartemen, dan lokasinya. Semua data ini dapat dimanfaatkan secara harfiah dari sumber daya yang tersedia. Misalnya, jika Anda menggunakan akun media sosial, misalnya, lihat tempat tinggal dan tempat kerja Anda; pahami sektor bisnis perusahaan tempat Anda bekerja; unduh lowongan serupa dari HH dan Superjob jika Anda seorang analis, manajer, dll.; lihat tempat tinggal Anda (misalnya, basis data dari CIAN), pahami berapa biaya sewa di sana, berapa biaya untuk membeli di sana, dan perkirakan kira-kira penghasilan Anda. Lebih lanjut, dengan menggunakan media sosial, Anda dapat memahami seberapa sering Anda bepergian, lokasi Anda, dan seberapa loyal Anda kepada perusahaan.
Dengan demikian, kami dapat melakukan apa pun yang kami inginkan dengan metrik yang begitu banyak. Kami dapat menyajikan produk yang Anda minati. Bayangkan sebuah toko online? Anda pergi ke sana—toko online tersebut mendeteksi akun media sosial Anda dan memberi tahu Anda, "Masha, kamu baru saja putus dengan pacarmu, ini beberapa produk khusus untukmu." Itu bukan masa depan yang dekat...
Bagaimana geolokasi seseorang ditentukan?
Jawaban atas pertanyaan dari hadirin:
- Biasanya, 80% dari semua check-in didasarkan pada tempat tinggal pasti mereka. Namun, bagi mereka yang tidak melakukan check-in di mana pun, ada beberapa pilihan: check-in, geolokasi, atau analisis postingan dan publikasi selama periode waktu orang tersebut menulis sesuatu... Dan di suatu tempat, sesuatu seperti "Saya ingin membeli kereta dorong bayi di dekat Akademicheskaya" atau "Saya baru-baru ini melihat grafiti jelek di dinding sini" akan muncul. Dengan kata lain, bagi hampir 80% orang, geolokasi, tempat kerja, dan tempat tinggal mereka dapat ditentukan dari data atau metadata yang dikumpulkan dari media sosial.
Ini, sekali lagi, adalah analisis pasca. Dalam bentuknya yang paling sederhana, ini adalah analisis check-in dan geolokasi di jejaring sosial yang tidak menghapus metadata JPEG (yang dapat digunakan untuk menguraikan beberapa informasi). Namun, bagi orang-orang lainnya, ini biasanya berupa siaran teks: seseorang mengungkapkan lokasi mereka saat mengunggah sesuatu, atau mereka mengungkapkan nomor telepon mereka, yang dapat digunakan untuk menemukan iklan di Avito atau akun mereka di Avto.ru. Dengan menggunakan data ini, kita dapat menggabungkan data (misalnya, "Saya menjual mobil di dekat Mayakovskaya") dan membuat perkiraan kasar.
- Orang-orang biasanya mengunggah ini di media sosial. Kami bekerja secara eksklusif dengan sumber terbuka, dan di sini kami hanya berbicara tentang sumber terbuka. Mereka biasanya mengunggah iklan—artinya, dalam sekitar enam puluh persen kasus, cerita paling umum ketika orang "membagikan" nomor ponsel mereka saat ini adalah iklan untuk sesuatu yang dijual. Entah orang tersebut mengunggah di suatu grup ("Saya menjual ini atau itu di sana"), atau mereka bergabung dengan grup lain.
Ya! Mereka biasanya berkomentar seperti ini, "Jawab saya, kirimi saya pesan teks, atau hubungi saya di nomor ini. Ini sangat sering terjadi pada orang yang menjual atau membeli barang di media sosial, atau berkomunikasi dengan seseorang..." Dengan demikian, nomor ini kemudian dapat ditautkan ke profil mereka di CIAN, jika mereka pernah mengunggah sesuatu, atau, sekali lagi, di Avito. Ini hanyalah sumber terpopuler dan teratas, dan akan terus ditautkan—Avito, CIAN, dan seterusnya.
- Saya sedang membahas toko online. Selanjutnya akan dibahas teknologi pengenalan wajah dan pencocokan profil (nanti kita bahas). Secara teori, ini juga bisa diterapkan di toko fisik. Impian besar saya adalah ketika spanduk jalanan muncul, kamera akan melacak wajah Anda saat Anda berjalan. Tapi ini akan dilarang oleh hukum karena melanggar privasi. Saya harap itu akan terwujud cepat atau lambat.
- Saya mengalaminya sendiri. Sering kali, ketika seseorang menulis surat kepada Anda, Anda menggunakan fakta-fakta dari kehidupan mereka yang seharusnya Anda rahasiakan... Orang-orang biasanya takut. Tapi! Menurut statistik terbaru, jumlah akun pribadi di media sosial telah menurun sebesar 14%. Jumlah akun palsu meningkat, sementara jumlah akun terbuka juga meningkat – orang-orang semakin cenderung terbuka. Saya pikir dalam tiga atau empat tahun, mereka akan berhenti bereaksi berlebihan terhadap seseorang yang mengetahui informasi tentang mereka yang mungkin seharusnya tidak mereka ketahui. Namun kenyataannya, hal ini sangat mudah diketahui dengan melihat dinding mereka.
Apa yang bisa diambil dari sumber terbuka?
Ada daftar kasar hal-hal yang dapat disimpulkan dengan tingkat kepastian yang cukup tinggi dari sumber terbuka. Kenyataannya, ada lebih banyak metrik yang berbeda; semuanya tergantung pada siapa yang menugaskan penelitian tersebut. Agensi SDM mungkin tertarik untuk mengetahui apakah Anda mengumpat di media sosial atau di tempat umum lainnya. Seseorang mungkin tertarik untuk mengetahui apakah Anda menyukai unggahan Navalny atau, sebaliknya, unggahan Rusia Bersatu, atau apakah Anda menyukai konten pornografi—hal-hal seperti ini cukup sering terjadi.
Faktor-faktor utamanya adalah nilai-nilai keluarga, perkiraan biaya apartemen atau rumah, mencari mobil, dan sebagainya. Berdasarkan semua faktor ini, orang-orang dapat dibagi ke dalam kelompok-kelompok sosial. Berikut adalah pengguna Tinder Moskow, siapa mereka (berdasarkan foto dan akun Facebook mereka); berdasarkan minat, mereka dibagi menjadi berbagai kelompok sosial:

Mendekati periklanan, kami secara bertahap beralih dari penargetan iklan standar, di mana Anda memilih, misalnya, di VKontakte, bahwa Anda tertarik pada pria berusia 18 tahun yang mengikuti grup tertentu. Saya punya gambar ini di bawah, akan saya tunjukkan sekarang:

Intinya, sebagian besar layanan yang melakukan analisis saat ini—dan, faktanya, orang-orang yang menganalisis media sosial—secara khusus berfokus pada analisis minat. Hal pertama yang terlintas dalam pikiran adalah menganalisis kelompok pengikut teratas mereka. Ini mungkin berhasil bagi sebagian orang, tetapi menurut saya pribadi itu pada dasarnya salah. Mengapa?
Suka Anda dikumpulkan dan dianalisis
Ambil ponsel Anda sekarang dan lihat grup favorit Anda—pasti ada lebih dari 50% grup yang sudah Anda lupakan. Konten ini sama sekali tidak relevan bagi Anda. Anda tidak mengaksesnya sama sekali, tetapi sistem akan tetap memfilter Anda berdasarkan konten tersebut: entah Anda berlangganan resep atau grup populer. Dengan kata lain, Anda akan mengganggu sistem yang menganalisis profil Anda, dan minat Anda akan salah sasaran.
Lanjut... Apa yang ada di sana? Kita berasumsi apa yang dilakukan orang lain. Cara paling akurat untuk menilai minat pengguna, menurut kami, adalah melalui suka. Misalnya, VKontakte tidak memiliki fitur suka, dan orang-orang berpikir tidak ada yang tahu apa yang mereka sukai. Ya, beberapa suka memang ada di Instagram, dan kita melihat beberapa hal di Facebook, tetapi sebagian besar konten di grup tertentu tidak disiarkan ke fitur umum, dan orang-orang menjalani hidup mereka dengan berpikir tidak ada yang akan tahu apa yang mereka sukai.
Dan dengan mengumpulkan konten spesifik yang menarik bagi kami, mengumpulkan postingan-postingan ini, mengumpulkan suka-suka ini, lalu membandingkan orang tersebut dengan basis data ini, kami dapat menentukan dengan akurasi tinggi siapa mereka, apa latar belakang mereka, dan apa minat mereka. Kami dapat secara tepat menempatkan mereka dalam kelompok sosial tertentu dan berinteraksi dengan mereka.
Membeli mobil mengubah perilaku
Saya punya contoh. Saya akan langsung mengklarifikasi bahwa contoh saya murni terkait periklanan dan pemasaran, karena, seperti yang Anda ketahui, sebagian besar kasus dilindungi oleh NDA dan sebagainya. Namun, masih banyak informasi menarik. Jadi, begini ceritanya dengan orang-orang ini: mereka adalah pria yang membeli mobil antara tahun 2010 dan 2015. Bagaimana perilaku sosial daring mereka berubah ditandai dengan kode warna. Persentase pelanggan perempuan berubah, mereka bergabung dengan grup publik "pria", menemukan pasangan seksual tetap...
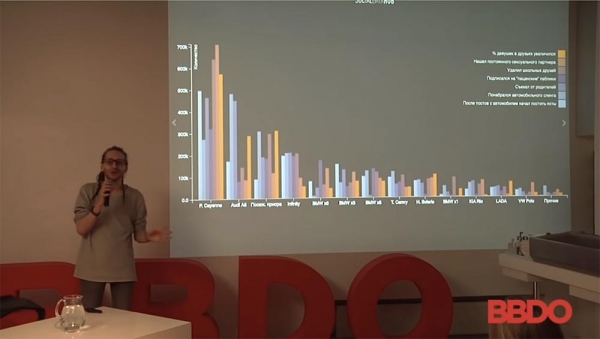
Semua ini dipecah berdasarkan merek mobil dan jumlah orang. Dari sini, kita dapat menarik banyak kesimpulan menarik tentang perilaku manusia dan bagaimana semuanya bekerja. Saya dapat mengatakan bahwa Porsche Cayenne dan Priora yang ditanam praktis identik dalam hal audiens yang mereka tarik. Kualitas audiens ini, perilaku mereka, berbeda, tetapi jumlahnya kurang lebih sama. Kesimpulan yang dapat Anda tarik dari ini, lebih dekat dengan pasar Anda, adalah apa pun yang Anda suka. Jika Anda menjual Audi, Anda membuat slogan "Beli Audi – jauhi orang tua Anda!" dan seterusnya.
Ya, ini contoh lucu tentang bagaimana perilaku orang, berdasarkan analisis suka, grup tempat mereka berpindah, dan konten yang mereka analisis, hampir 100% akurat mengungkapkan siapa Anda. Karena jika Anda tidak memiliki akses ke lalu lintas jaringan atau membaca pesan pribadi, suka akan selalu memberi tahu Anda siapa orang tersebut—seorang wanita hamil, seorang ibu, seorang tentara, seorang polisi. Dan bagi Anda, sebagai seseorang yang dapat memasang iklan, ini sangat bermanfaat.
Jawaban atas pertanyaan penonton:
- Setiap batang mewakili jumlah orang yang memiliki mobil tertentu dan bagaimana pola perilaku mereka telah berubah. Lihat: orang yang membeli Porsche Cayenne—sekitar 550 (kuning), persentase pengikut perempuan telah meningkat.
- Sampel terdiri dari pengguna jejaring sosial VKontakte, Facebook, dan Instagram dari tahun 2010 hingga 2015. Satu-satunya klarifikasi: kendaraan yang dipilih dapat diidentifikasi dalam foto dengan akurasi lebih dari 80% menggunakan alat tertentu.
- Selama kurun waktu tertentu, mobilnya (yah, bukan mobilnya, kita serahkan saja pada media sosial)... Selama kurun waktu tertentu, orang tersebut terus-menerus berfoto dengan mobilnya, berada di dalamnya, unggahannya beragam, fotonya diambil dari berbagai sudut, dan sebagainya. Nanti akan ada foto orang-orang yang berfoto dengan mobil yang mana dan... Ya, itu pertanyaan kedua—kepercayaan data media sosial.
- Mengingat kita sedang membahas topik ini, sayangnya, data media sosial tidak selalu akurat. Orang-orang tidak selalu bersedia membagikan informasi mereka. Saya pribadi melakukan studi yang membandingkan jumlah lulusan universitas di Moskow dengan jumlah orang yang terdaftar di media sosial. Rata-rata, 60% lebih banyak orang yang terdaftar di media sosial—lulusan Universitas Negeri Moskow pada tahun tertentu dan di bidang tertentu—dibandingkan jumlah sebenarnya. Jadi, ya, tentu saja ada sejumlah kesalahan, dan tidak ada yang menyembunyikannya. Data di sini hanya berdasarkan mobil yang dapat diidentifikasi dengan tingkat kepastian lebih dari 80%.
Daftar sumber untuk melatih model
Berikut ini adalah contoh daftar sumber yang dapat digunakan untuk menentukan profil sosial seseorang dengan tingkat keandalan tinggi, siapa dia.

Kami mendapatkan profil dari media sosial, perkiraan biaya apartemen dari CIAN, dan gaji rata-rata seseorang dari HeadHunter dan SuperJob. Saya harap tidak ada perwakilan HeadHunter di sini, karena mereka merasa tidak pantas mengambil data ini dari mereka. Namun, ini adalah gaji rata-rata untuk wilayah tertentu untuk jenis pekerjaan tertentu, berdasarkan lowongan pekerjaan.
Avito, Avto.ru: sering kali, ketika orang mengungkapkan nomor telepon mereka, mereka pasti mencantumkannya (dalam banyak kasus) di suatu tempat di Avito, Avto.ru, atau beberapa situs web lain yang dapat membantu mengidentifikasi mereka. Jika mereka menggunakan nomor telepon itu untuk menjual kereta dorong bayi atau mobil... Rosstat dan Daftar Badan Hukum Negara Bersatu, bagaimanapun juga, lebih seperti registri yang dapat digunakan untuk memeringkat perusahaan pemberi kerja—berdasarkan suatu formula, sebuah model yang dapat didefinisikan oleh siapa pun (Anda dapat memperkirakan kekayaan bersih orang tersebut secara kasar, dll.).
Tinder membantu mengumpulkan data tentang situasi orang-orang
Selain itu, ada hal menarik ini (yang sebenarnya cukup lucu dalam penelitian ini)—lagi-lagi, mereka mengumpulkan data dari Tinder Moskow menggunakan bot Tinder. Mereka menentukan jarak ke orang-orang, lalu perkiraan lokasi mereka.
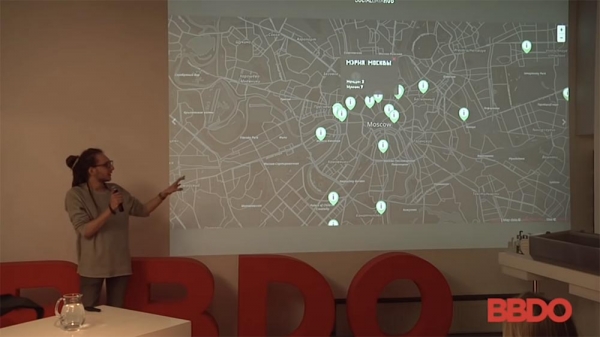
Tujuan studi ini adalah untuk menentukan jumlah akun Tinder di lembaga pemerintah—Duma, kejaksaan, dan sebagainya. Namun, sebagai pengiklan, Anda dapat membayangkannya sesuka Anda: misalnya, Starbucks atau yang lainnya... Artinya, jumlah orang di Tinder yang minum kopi bersama Anda, memesan sesuatu, atau sedang berbelanja. Mengenai geolokasi ini: hal ini dapat dilakukan dengan layanan apa pun.
Jawaban atas pertanyaan dari hadirin:
- Tinder? Nggak tahu? Tinder itu aplikasi kencan, di mana kamu tinggal menggeser foto ke kiri dan kanan, dan aplikasinya akan menunjukkan jarak ke seseorang. Kalau kamu mengukur jarak ke orang itu dari tiga sudut berbeda, kamu bisa memperkirakan lokasinya secara kasar (+5-7 meter). Dalam hal ini, tidak sulit untuk menemukan seseorang di kantor kejaksaan atau Gedung Duma Negara. Tapi, bisa juga di tokomu, atau di mana saja.
Misalnya, kami pernah mengalami kasus serupa (bukan studi) dahulu kala. Kami menerima data kepadatan lalu lintas dari operator seluler, beserta data kepadatan pergerakan lokasi seluler, dan informasi ini ditumpangkan pada koordinat papan reklame yang terletak di jalan raya. Tugas operator seluler adalah menentukan perkiraan jumlah orang yang berkendara dan berpotensi melihat papan reklame tersebut.
Jika ada pakar periklanan papan reklame di sini, Anda mungkin berkata: tidak mungkin untuk memberi tahu dengan sangat andal—seseorang sedang mengemudi, seseorang tidak melihat, seseorang melihatnya... Namun demikian, ini adalah contoh bagaimana 20 miliar poligon seperti itu di Moskow, yang menunjukkan kepadatan orang-orang ini setiap jam di sepanjang rute tertentu... Anda dapat melihat apa yang dilewati orang-orang ini pada saat tertentu dan memperkirakan secara kasar arus penumpang.
Jawaban atas pertanyaan dari hadirin:
- Tidak ada yang menyediakan data tersebut. Kami melakukan studi semacam itu untuk salah satu operator; ini murni cerita internal, jadi sayangnya, tidak disajikan dalam bentuk gambar. Namun seringkali, agensi periklanan besar tidak memiliki masalah dalam menghubungi operator. Setidaknya di Moskow, ada banyak preseden di mana, misalnya, perusahaan asuransi beralih ke perusahaan seperti GetTaxi, yang menyediakan data anonim tentang usia pengemudi, kebiasaan mengemudi mereka (baik atau buruk, sembrono atau tidak), untuk memprediksi premi asuransi, dan sebagainya. Semua orang kesulitan dengan hal ini, tetapi di tingkat internal, saya rasa tidak ada yang memiliki masalah dalam menyediakan data anonim.
Pengenalan gambar dan pola
Baiklah, mari kita lanjutkan. Favorit saya adalah pengenalan gambar. Akan ada bagian singkat tentang pengenalan wajah, tetapi kita tidak akan membahasnya. Kita akan secara khusus berfokus pada pengenalan gambar dan mengidentifikasi isi gambar—merek mobil, warnanya, dan sebagainya.

Saya punya contoh lucu:

Ada sebuah studi yang meneliti tato di berbagai platform media sosial. Oleh karena itu, hal yang sama dapat diterapkan pada merek apa pun, citra visual apa pun, dan hampir semua citra visual. Ada beberapa yang tidak dapat diidentifikasi dengan cukup pasti (kami tidak akan membahasnya).
Ini favorit saya. Merek mobil sering meminta tugas semacam ini karena tujuan mereka, misalnya, untuk menemukan semua pemilik BMW X6, memahami siapa mereka, bagaimana hubungan mereka, apa minat mereka, dan sebagainya. Ini terkait dengan pertanyaan tentang mobil apa yang difoto orang di media sosial.

Tidak ada penyaringan sama sekali di sini: subjeknya milik mereka, mobilnya bukan milik mereka; yang ada hanyalah rincian mobil – usia, dan sebagainya. Namun, pengenalan citra visual cukup sering digunakan: ini termasuk pencarian wanita hamil dan pencarian logo merek di berbagai media (siapa yang mengunggah apa).

Contoh favorit saya (yang digunakan berbagai restoran): gulungan sushi apa yang mereka posting di media sosial. Lucu, tapi sebenarnya ini memungkinkan kita untuk memahami banyak hal, pertama-tama, tentang pelanggan kita: siapa yang datang dan mengapa mereka melakukannya. Karena bukan rahasia lagi kalau di bar sushi, kebanyakan orang (saya tidak akan bilang "perempuan") mengambil foto untuk check-in, memotret barang-barang, dll.
Sebuah merek dapat memanfaatkan hal ini. Mereka tertarik pada produk spesifik apa yang perlu difoto dan ditampilkan dengan indah, serta tipe pengunjung seperti apa. Hal ini dapat dilakukan dengan hampir semua hal, mulai dari makanan.
Pengenalan gambar dalam video
Jawaban atas pertanyaan dari hadirin:
- Tidak di video. Kami sedang mengujinya. Kami sudah mencoba teknologi ini, tetapi ternyata... Teknologi ini mengenali semua hal dari video dengan cukup baik, tetapi kami belum menemukan aplikasinya. Sejauh ini. Selain menganalisis seberapa banyak dan video blogger mana yang berbicara di suatu tempat... Ada studi semacam itu. Berapa banyak wajah mereka yang muncul, seberapa sering. Tapi kami belum menemukan di mana kami bisa menerapkannya untuk merek. Mungkin suatu hari nanti akan terwujud.
Sekali lagi, itu makanan, bisa wanita hamil, pria (tidak hamil), mobil - apa saja.
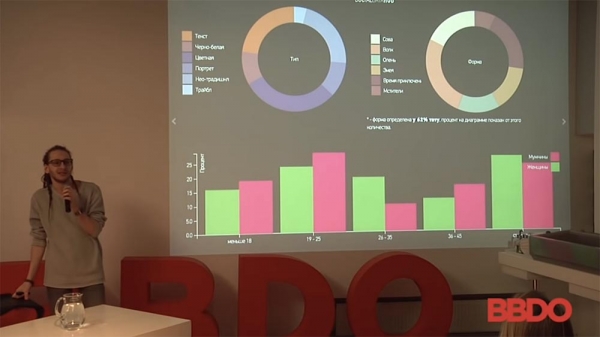
Alternatifnya, ada studi Tahun Baru untuk sebuah media. Studi ini juga jauh dari iklan, tapi tetap saja. Studi ini membahas tentang makanan apa yang diposting orang-orang di Tahun Baru:

Ini juga dipecah berdasarkan usia. Anda dapat melihat korelasinya: anak muda kebanyakan memesan makanan, sementara orang dewasa kebanyakan menyiapkan makanan tradisional. Ini mungkin terdengar seperti lelucon, tetapi jika Anda memikirkannya sebagai pemilik merek, Anda dapat menilai banyak hal: siapa yang menggunakan produk Anda dan bagaimana, apa yang orang tulis tentangnya. Orang-orang seringkali tidak menyebutkan merek itu sendiri dalam teks, dan sistem pemantauan analitik tradisional tidak selalu dapat mendeteksi penyebutan merek ini hanya karena tidak disebutkan dalam teks. Atau teksnya salah eja, tagarnya hilang, atau apa pun.
Anda bisa melihat foto-fotonya. Dengan foto, Anda bisa tahu apakah foto itu objek utama dalam bingkai atau bukan. Lalu, Anda bisa melihat apa yang ditulis orang tersebut. Namun, sering kali, ini digunakan untuk menemukan calon audiens yang pernah mengendarai mobil tertentu, dan sebagainya. Lalu, kami akan melakukan banyak hal menarik dengan mobil-mobil ini.
Bot sedang dilatih untuk meniru manusia
Ada juga opsi untuk menggunakan penghitungan orang:

Ada metode untuk mencocokkan orang, di mana Anda perlu menemukan orang berdasarkan foto, memahami profil sosial mereka, dan mengidentifikasi diri mereka. Sekali lagi, kita kembali ke poin bahwa jika kita memiliki kamera di toko fisik, itu cara yang cukup baik untuk memahami siapa yang datang kepada Anda, siapa mereka, apa minat mereka, dan apa yang mendorong mereka untuk datang kepada Anda.
Sekarang tibalah bagian yang paling menarik: jika kita mengumpulkan akun media sosial mereka, memahami siapa mereka, dan apa minat mereka, kita dapat (opsional) membuat bot yang menyerupai orang-orang ini. Bot ini akan mulai berperilaku seperti orang-orang ini dan menganalisis iklan yang dilihatnya di berbagai jejaring sosial. Ini akan memungkinkan kita untuk memahami dengan tingkat akurasi yang cukup tinggi merek mana yang menargetkan orang ini. Ini juga merupakan situasi yang cukup umum, ketika kita perlu tidak hanya menganalisis siapa orang ini dan apa minatnya, tetapi juga iklan apa yang ditargetkan oleh calon pesaing Anda atau orang lain yang tertarik kepada mereka.

Analisis tautan jaringan sosial

Hal berikutnya yang menarik: analisis hubungan antarmanusia. Analisis hubungan dalam jaringan, grafik jaringan ini—tidak ada yang baru sama sekali, semua orang sudah mengetahuinya.

Namun, menerapkan hal ini pada periklanan adalah bagian yang paling menarik. Intinya adalah menemukan orang-orang yang menciptakan tren, menemukan orang-orang yang menyebarkan informasi berdasarkan kriteria tertentu dalam jaringan tertentu. Katakanlah kita tertarik pada pemilik model BMW tertentu. Dengan mengumpulkan mereka semua, kita dapat menemukan orang-orang yang memegang kendali opini publik. Mereka tidak harus blogger otomotif atau semacamnya. Biasanya, mereka adalah orang-orang biasa yang sering mengunjungi berbagai grup publik, tertarik pada konten tertentu, dan dapat, dalam waktu yang sangat singkat, menarik merek Anda atau orang lain yang Anda minati ke area tanggung jawab ini, ke zona minat Anda.
Berikut contohnya. Kita punya beberapa orang potensial, koneksi antarmanusia. Yang oranye adalah orang-orang, titik-titik kecil adalah kelompok umum, teman bersama.

Jika Anda menggabungkan semua koneksi ini, Anda dapat melihat dengan sangat jelas bahwa ada orang-orang yang memiliki banyak kelompok yang sama, teman yang sama, dan mereka berada di sana di antara mereka sendiri... Dan jika Anda memecah visualisasi yang sama ini menjadi kelompok-kelompok berdasarkan minat, konten yang mereka distribusikan, dan seberapa banyak mereka berinteraksi satu sama lain... Di sini Anda dapat melihat bahwa gambar sebelumnya telah menjadi seperti ini:

Di sini, kelompok-kelompok tersebut dibedakan dengan jelas berdasarkan warna. Dalam hal ini, mereka adalah mahasiswa program magister kami di Sekolah Tinggi Ekonomi. Anda dapat melihat bahwa kelompok ungu/biru adalah mereka yang mendukung Transparency International, Open Russia, dan halaman publik Khodorkovsky. Di kiri bawah adalah kelompok hijau, mereka yang mendukung Rusia Bersatu.
Anda bisa melihat bahwa gambar sebelumnya seperti ini (hanya koneksi antar-orang), tetapi sekarang tergambar dengan jelas. Artinya, semua orang selalu terhubung, mereka memiliki minat yang sama, mereka berteman satu sama lain. Ada yang di atas, ada yang di bawah, dan ada juga yang sejawat. Dan jika Anda memvisualisasikan setiap subgraf kecil ini secara terpisah dengan parameter yang berbeda dan mengamati kecepatan distribusi konten (secara kasar, siapa yang mengunggah ulang apa), Anda dapat menemukan satu atau dua orang di setiap bagian yang selalu memegang opini publik. Dengan berinteraksi dengan mereka, meminta mereka untuk membagikan postingan atau hal lainnya, Anda dapat memperoleh respons dari seluruh audiens yang menarik ini.
Saya punya contoh lain seperti itu. Juga sebuah grafik: ini adalah karyawan BBDO Group, yang ditemukan di media sosial sebagai contoh. Grafiknya terlihat tidak menarik, besar, berwarna hijau, dan hubungan di antara mereka...

Tapi saya punya versi yang sudah ada grupnya. Lalu, kalau ada yang tertarik, ada versi interaktifnya—kamu bisa klik dan lihat.
Kanan atas adalah mereka yang mencintai Putin. Yang berwarna ungu di sini adalah para desainer; mereka yang tertarik pada desain, apa pun yang menarik, dan sebagainya. Yang berwarna putih di sini adalah tim manajemen (saya rasa begitulah pemahaman saya); mereka adalah orang-orang yang tidak benar-benar terhubung dengan cara apa pun, tetapi bekerja di posisi yang kurang lebih sama. Sisanya adalah kelompok, koneksi, dan sebagainya yang sama.
Merek tidak membutuhkan blogger, mereka membutuhkan pemimpin opini
Kami menemukan orang-orang ini, lalu agensi periklanan memutuskan sendiri: mereka dapat membayar orang ini untuk berinteraksi dengan konten ini, atau konten lain, atau menargetkan mereka dengan kampanye iklan spesifik mereka sendiri. Hal ini juga cukup sering digunakan, terutama saat ini, karena semua merek ingin bekerja sama dengan blogger, ingin mereka mempromosikan konten mereka, tetapi agensi periklanan enggan untuk terlibat (yah, itu memang terjadi).
Solusi sebenarnya untuk masalah ini adalah menemukan orang-orang yang bukan blogger atau beauty blogger, melainkan, misalnya, orang-orang nyata yang berinteraksi dengan merek tersebut, yang dapat menulis di halaman publik yang kurang menarik bernama "Mail.ru Answers" dan mendapatkan jumlah penayangan tertentu. Orang-orang ini, yang selalu tertarik dengan konten orang tersebut, akan menyebarkannya, dan merek tersebut akan mendapatkan engagement.
Cara kedua untuk menggunakan teknologi ini, yang cukup relevan saat ini, adalah dengan mencari bot, favorit saya. Hal ini dapat menimbulkan risiko reputasi bagi pesaing Anda, menyaring orang-orang yang tidak relevan dari kampanye iklan Anda, dan melakukan berbagai hal lainnya (seperti menghapus komentar dan menemukan koneksi antar orang). Saya punya contohnya, yang juga besar dan interaktif—Anda dapat memindahkannya. Ini menunjukkan koneksi antar orang yang berkomentar di komunitas "Lentach".
Berikut contoh untuk membantu Anda memahami betapa mudahnya mengenali bot; Anda bahkan tidak memerlukan pengetahuan teknis apa pun untuk melakukannya. Jadi, Lentach menerbitkan postingan tentang investigasi FBK terhadap Dmitry Medvedev, dan beberapa orang mulai berkomentar. Kami telah menyusun daftar semua orang yang berkomentar—mereka adalah para pemula. Mari saya tunjukkan:

Orang-orang adalah yang berwarna hijau (yang menulis komentar). Mereka ada di sini, mereka ada di sini. Titik-titik biru di antara mereka adalah grup bersama mereka, yang berwarna kuning adalah pelanggan, teman, dan sebagainya yang mereka miliki bersama. Itulah sebagian besar orang yang terhubung. Karena, apa pun teori tiga, empat, atau lima derajat pemisahan, semua orang terhubung di media sosial. Tidak ada yang terisolasi satu sama lain. Bahkan teman-teman saya yang fobia sosial, yang menggunakan VKontakte hanya untuk menonton video, masih berlangganan beberapa halaman publik yang sama dengan kami.
Navalny juga menggunakan bot. Semua orang punya bot.
Sebagian besar orang (di sini mereka) saling terhubung. Namun, ada sekelompok kecil kawan yang hanya berteman satu sama lain. Inilah mereka, yang hijau, dan inilah teman dan kelompok mereka. Mereka bahkan bercabang sendiri di sini:

Dan secara kebetulan yang beruntung, orang-orang yang sama ini menulis di bawah unggahan ini, "Navalny tidak punya bukti," dan seterusnya, meninggalkan komentar yang identik. Saya tentu saja tidak terburu-buru mengambil kesimpulan. Namun, saya memang punya unggahan lain di Facebook selama debat Lebedev-Navalny, dan saya menganalisis komentar-komentarnya dengan cara yang sama: ternyata semua orang yang menulis "Lebedev itu sampah" tidak masuk ke media sosial selama empat bulan terakhir, tidak berlangganan halaman publik mana pun, tiba-tiba menemukan unggahan ini, menulis komentar ini, lalu pergi. Sekali lagi, Anda tidak bisa menarik kesimpulan dari ini, tetapi seseorang dari tim Navalny berkomentar bahwa mereka tidak menggunakan bot. Ya sudahlah!
Lebih dekat dengan periklanan, lebih dekat dengan merek. Semua orang punya bot sekarang! Kita punya, pesaing kita punya, dan begitu pula beberapa yang lain. Bot-bot itu sebaiknya dibuang atau disimpan agar bisa berkembang; berdasarkan data ini (menunjuk slide sebelumnya), kita harus menyempurnakannya agar terlihat seperti manusia sungguhan, baru setelah itu kita boleh menggunakannya. Meskipun menggunakan bot itu buruk! Namun, ini kasus yang cukup umum...
Dalam mode otomatis, fitur ini memungkinkan Anda menyaring orang-orang yang tidak relevan dari analisis Anda, orang-orang yang seharusnya tidak dimasukkan dalam sampel, orang-orang yang seharusnya tidak dimasukkan dalam studi ini. Fitur ini sangat sering digunakan. Sekali lagi, tidak semua pemilik mobil benar-benar memiliki mobil. Terkadang, Anda hanya tertarik pada orang-orang yang berpotensi memiliki mobil, yang merupakan anggota kelompok tertentu, yang berkomunikasi dengan orang lain, dan yang memiliki audiens tertentu di sana.
Analisis fakta dan opini
Hal berikutnya yang juga menjadi favorit saya. Ini adalah analisis fakta dan opini.

Semua orang tahu cara menyebutkan merek mereka di berbagai sumber akhir-akhir ini. Tidak ada rahasia untuk itu. Dan sepertinya semua orang tahu cara mengukur sentimen... Meskipun, secara pribadi, saya pikir metrik sentimen itu sendiri tidak terlalu menarik, karena ketika Anda datang ke klien dan memberi tahu mereka, "Bung, netralitas Anda 37%," dan mereka seperti, "Wow! Keren!" Jadi akan lebih menarik untuk bergerak sedikit lebih jauh: dari menilai sentimen ke menilai opini orang-orang tentang produk Anda.
Dan ini juga hal yang sangat menarik, karena... Saya pribadi percaya bahwa pesan netral pada prinsipnya mustahil, karena jika seseorang menulis sesuatu di ruang publik, pesan tersebut pasti akan ternoda. Saya pribadi belum pernah melihat pesan netral yang menyebutkan merek tertentu. Biasanya, itu semacam fitnah.
Jika kita mengambil sejumlah besar pesan ini (bisa jutaan, bahkan 10 juta), mengekstrak gagasan utama dari setiap pesan, dan menggabungkannya, kita dapat memahami dengan cukup akurat apa yang orang katakan tentang merek ini, apa yang mereka pikirkan. "Saya tidak suka kemasannya," "Saya tidak suka konsistensinya," dan seterusnya.
Apa pendapat orang tentang Transaero, lolipop, dan Presiden AS?
Saya punya contoh lucu: infografis ini tentang apa yang akan dilakukan pengguna media sosial terhadap Transaero setelah kebangkrutannya.

Ada banyak contoh menarik: bakar, bunuh, deportasi ke Eropa; bahkan ada 2% yang menulis, "Kirim mereka ke Suriah untuk berperang." Beralih dari yang konyol, bisa jadi merek apa saja—dari makanan anjing favorit saya hingga mobil. Mereka yang tidak suka kemasannya, mereka yang tidak suka barang asli—mereka selalu bisa mengatasinya, mereka selalu bisa dipertimbangkan. Ada banyak contoh orang yang praktis mengubah produksi produk mereka karena mereka menulis di media sosial bahwa lolipopnya kurang bulat atau kurang manis.
Ini contoh lucu lainnya. Coba tebak apa komentarnya dan tentang siapa?

Entah kenapa, analisis opini, analisis fakta yang diekstrak dari pesan, belum banyak digunakan atau tersebar luas saat ini. Meskipun teknologi ini bukan rahasia besar, praktis tidak ada pengetahuan di baliknya, karena mengekstrak subjek, predikat, dan mengelompokkannya dari komentar orang—Anda tidak perlu jenius dalam linguistik komputasional untuk melakukannya. Tidak sesulit itu. Tapi saya harap dalam beberapa tahun ke depan, orang-orang akan mulai menggunakannya, karena... Umpan balik otomatis semacam ini akan luar biasa! Anda selalu tahu apa yang orang katakan tentang Anda. Ya, Anda tahu, hal itu pernah dilakukan terhadap Presiden AS.
Jawaban atas pertanyaan dari hadirin:
- Ya, ini Facebook dalam bahasa Inggris. Terjemahannya ke bahasa Rusia di sini. Ini ditulis di suatu tempat.
Big Data dan teknologi politik
Sebenarnya, saya punya banyak contoh politik menarik tentang Trump dan semua orang lainnya, tetapi kami memutuskan untuk tidak mencantumkannya di sini. Namun, ada satu contoh politik.
Ini pemilihan Duma Negara. Kapan? Tahun lalu? Hampir satu setengah tahun yang lalu.
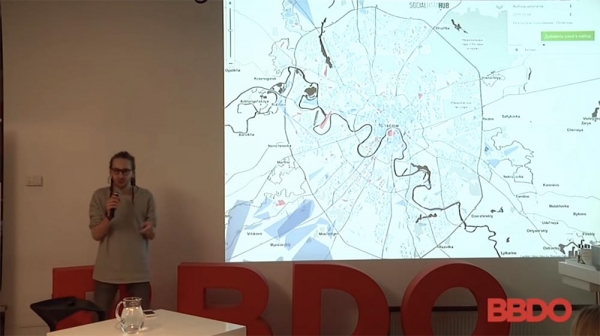
Berikut adalah orang-orang yang lokasi persisnya telah ditentukan, hingga titik geolokasi tertentu, untuk menentukan tempat pemungutan suara mereka. Dari sana, hanya mereka yang menyatakan pendapat spesifik tentang siapa yang akan mereka pilih yang disertakan.
Dari perspektif strategi politik, ini kurang tepat, karena semuanya perlu disesuaikan dengan kepadatan penduduk dan sebagainya. Meskipun demikian, para pemilih biru di sini berencana untuk memilih Anda-tahu-siapa, dan para pemilih merah untuk rekan-rekan oposisi, yang, omong-omong, jumlahnya tidak banyak.
Secara pribadi, saya pikir Big Data masih jauh dari penerapannya pada teknologi politik, tetapi seorang kandidat juga merupakan sebuah merek. Dan ini, sampai batas tertentu, merupakan analisis fakta dan opini tentang merek mereka, dan ini cukup menarik karena Anda dapat memahami secara langsung siapa yang melakukan apa. Saya mengetahui beberapa kasus di BBC di mana mereka memantau media sosial secara langsung selama siaran: respons seperti ini, orang-orang menulis tentangnya, mengajukan pertanyaan seperti ini – dan itu fantastis! Saya pikir ini akan segera digunakan, karena menarik bagi semua orang.
Memodelkan posisi merek

Selanjutnya, saya akan memodelkan posisi merek. Sebuah tulisan singkat dan ringkas tentang bagaimana merek dapat diperingkat menggunakan berbagai metrik (bukan hanya suka di media sosial, tetapi juga metrik yang kompleks, minat konten, dan waktu yang dihabiskan untuk mengumpulkan metrik).

Saya punya contoh untuk merek tertentu, "Pharma." Lingkaran kecil berwarna cerah di dalamnya mewakili jumlah konten teks yang dibuat oleh merek itu sendiri, dan lingkaran besar mewakili jumlah konten foto dan video yang dibuat oleh merek itu sendiri.
Kedekatan dengan pusat menunjukkan betapa menariknya konten ini bagi audiens. Ini model yang besar, dengan berbagai metrik berbeda: suka, repost, waktu respons, rata-rata sharer... Begini contohnya: ada Kagocel yang luar biasa, yang menginvestasikan sejumlah besar uang untuk membuat kontennya sendiri, dan karena itu, mereka cukup dekat dengan pusat. Lalu ada yang juga membuat konten mereka sendiri, tetapi audiensnya tidak tertarik. Ini bukan contoh yang akurat, karena semua akun ini praktis sudah mati.
Yegor Creed lebih dicintai daripada Basta

Sayangnya, sisanya... dari apa yang dapat ditampilkan... Di sini, ada juga rapper Rusia, sebagai pilihan, dari perusahaan sungguhan.
Apa keuntungannya? Perusahaan dapat memasukkan hampir semua faktor ke dalam model ini, mulai dari gaji rata-rata pelanggan merek Anda; model apa pun yang mereka sukai. Karena setiap agensi periklanan menghitung metriknya sendiri secara berbeda, dan merek menghitung metrik mereka sendiri secara berbeda.
Ada juga orang seperti Basta, yang menghasilkan banyak konten, tapi dia berada di pinggiran karena tampaknya kontennya kurang menarik bagi penonton. Sekali lagi, saya bukan orang yang berhak menghakimi. Tapi ada juga Yegor Creed, yang menurut media sosial, bisa dibilang salah satu penampil terbaik di zaman kita, tapi dia hanya mengunggah foto pribadinya. Dia memang punya banyak pengikut: sekitar satu juta orang. Saya tidak ingat angka pastinya; saya ingat tingkat keterlibatannya jauh lebih tinggi dari 85%, artinya untuk setiap satu juta pengikutnya, dia mendapat 850 respons dari orang sungguhan—sungguh luar biasa. Benar sekali.

Jawaban atas pertanyaan penonton:
Berapa lama waktu yang dibutuhkan untuk mengembangkan model analisis rapper?
- Masing-masing memiliki target audiens, minat, dan perhitungannya sendiri... Semua ini distandarisasi berdasarkan perkiraan jarak ke pusat; posisi radialnya tidak penting (hanya disebar di sini untuk tujuan estetika, agar tidak tumpang tindih). Yang penting hanyalah perkiraan jaraknya ke pusat. Inilah model yang kami gunakan. Misalnya, saya lebih suka lingkaran; beberapa orang menggunakan setengah lingkaran.
- Model ini disusun dengan cepat, dalam dua atau tiga jam (ya, oleh satu orang). Semuanya tentang metrik: apa yang kita kalikan dengan apa, jumlahkan, lalu standarisasi. Tergantung modelnya. Beberapa orang tertarik dengan gaji rata-rata (sungguh) pengikut mereka. Dan untuk melakukannya, Anda perlu mencari kontak mereka, Avito, menghitung semuanya, lalu mengalikannya. Terkadang perhitungannya memakan waktu lama, tetapi yang satu ini (lihat slide sebelumnya)—memiliki parameter yang sangat sederhana: pengikut, repost, dan sebagainya. Butuh waktu sekitar dua atau tiga jam untuk menyusunnya. Jadi, alat ini kemudian diperbarui secara real-time, dan siap digunakan.
Sekarang tibalah bagian yang paling menarik. Saya sudah kehabisan contoh, karena tidak menarik untuk berbicara panjang lebar sendirian. Dan saya harap Anda akan bertanya sekarang, dan kita akan beralih dari satu topik ke topik lainnya, karena saya punya contoh tentang bagaimana teknologi dapat digunakan dan sebagainya...
Jawaban atas pertanyaan penonton:
- Saya punya satu kasus pribadi dengan tempat yang disebut "mirip kasino", di mana mereka memasang kamera, melakukan pengenalan wajah, dan sebagainya. Persentase orang yang dikenali memang cukup tinggi—baik di apotek kami maupun di kompetitor kami. Tapi sebenarnya ini cukup menarik. Saya melihatnya sebagai hal yang menarik: kita bisa memahami siapa orang-orang ini dan memprediksi dengan cukup baik mengapa mereka datang ke sana, apa yang berubah dalam hidup mereka yang membuat mereka memutuskan untuk datang ke kasino. Tapi untuk jenis bisnis tertentu... Jika kita memasang alat semacam itu di apotek, tidak ada gunanya—kita tidak bisa memprediksi mengapa seseorang akan datang ke apotek sejak awal.
Tantangan besarnya di sini adalah membangun model untuk memahami kapan seseorang berpotensi tertarik dengan merek Anda, sehingga Anda dapat menargetkan mereka dengan iklan bukan setelah mereka membeli sesuatu (seperti yang terjadi saat ini), melainkan "memprediksi" kapan hal itu akan benar-benar terjadi. Hal yang menarik dengan pengaturan "seperti kasino" ini; ada persentase yang cukup menarik dari orang-orang ini—alasannya: beberapa mendapat promosi mendadak, yang lain karena alasan lain—itu adalah wawasan yang menarik. Namun, dengan toko-toko tertentu, dengan ritel, dengan toko pil, saya rasa itu kurang tepat.
Apakah Big Data digunakan secara offline?
- Itu sedang offline. Anda hanya perlu memahami secara pasti, secara kasar, apakah model ini akan berhasil atau tidak. Sekali lagi, dengan air soda... Saya sungguh tertarik pada semuanya, tetapi saya pribadi tidak mengerti sejauh mana, bagaimana profil dan perilaku orang-orang ini mungkin bergantung pada kapan mereka ingin membeli air minum kemasan. Meskipun itu mungkin benar, saya tidak tahu.
Berapa banyak akun media sosial terbuka yang Anda miliki?
- Kita punya 11 jejaring sosial spesifik: VKontakte, Facebook, Twitter, Odnoklassniki, Instagram, dan beberapa jejaring sosial kecil lainnya (saya bisa melihat daftar seperti Mail.ru dan sebagainya). Kita pasti punya salinan semua orang ini di VKontakte. Kita punya orang di VKontakte—430 juta dari semua orang yang pernah ada (sekitar 200 juta di antaranya aktif terus-menerus); ada grup, ada koneksi di antara orang-orang ini, dan ada konten yang menarik minat kita (teks), dan beberapa media, tetapi sebagian sangat kecil... Secara garis besar, kita lihat gambar ini: jika ada wajah, kita simpan; jika ada meme, kita tidak simpan, karena kita pun tidak punya cukup sumber daya untuk menyimpan konten media tersebut.
Ada Facebook berbahasa Rusia. Saat ini, sekitar 60-80% penggunanya adalah Odnoklassniki; dalam beberapa bulan, kita mungkin akan mengakses semuanya. Ada Instagram berbahasa Rusia. Semua jejaring sosial ini memiliki grup, orang, koneksi di antara mereka, dan teks.
- Sekitar 400 juta orang. Ada kehalusannya: ada orang yang kotanya tidak tercantum (kemungkinan mereka orang Rusia/non-Rusia); dari jumlah tersebut, rata-rata di seluruh jejaring sosial—misalnya, di VKontakte, 14% adalah akun pribadi; saya tidak tahu angka pastinya untuk Facebook.
- Kami juga tidak menyimpan media di Instagram—hanya jika berisi wajah. Kami tidak menyimpan konten media (lainnya). Biasanya, kami hanya tertarik pada teks, koneksi antar orang—itu saja. Riset Instagram yang paling umum adalah riset audiens standar: siapa orang-orang ini, dan yang terpenting, koneksi mereka ke jejaring sosial lain. Menemukan profil orang ini di VKontakte dan Facebook berguna untuk menghitung usia mereka, dan sebagainya.
- Belum perlu bersaing dengan yang lain—hanya karena belum ada klien. Soal bahasa: kami punya bahasa Rusia, Inggris, dan Spanyol, tetapi bahasa-bahasa tersebut masih digunakan secara eksklusif untuk merek-merek Rusia, atau setidaknya untuk perusahaan yang mengoperasikannya dari Rusia.
- Kami mensurvei orang-orang setiap hari dalam rangkaian yang tak terhitung jumlahnya: kami mengumpulkan data dengan mengikis web, dan kami memperbarui metrik ini menggunakan API. Dalam dua atau tiga hari, Anda dapat menyisir seluruh jaringan VKontakte; dalam waktu sekitar seminggu, Anda dapat menyisir seluruh jaringan Facebook, memahami siapa yang memperbarui apa dan siapa yang belum. Dan kemudian kami menyusun kembali orang-orang ini satu per satu: apa yang sebenarnya berubah, dan mencatat seluruh riwayat. Seingat saya, sangat jarang profil media sosial lama seseorang digunakan untuk tujuan bisnis apa pun. Ini pernah terjadi, ketika seorang tokoh politik mendekati kami, dan tugasnya adalah untuk memahami tipe orang yang datang ke markas kampanye, dan siapa mereka 6-8 bulan yang lalu (apakah mereka menghapus profil mereka dan benar-benar memilih kandidat lain, atau apakah mereka datang untuk merusak surat suara).
Dan beberapa kali – kisah pribadi, ketika foto seseorang dipublikasikan. Perlu mencari koneksi, dll. Sayangnya, ini memalukan, tetapi kami tidak dapat bersaksi di pengadilan karena basis data kami ilegal secara hukum.
- Penyimpanan MongoDB adalah favorit saya.
Jejaring sosial mencoba memerangi pengumpulan data.
- Kami biasanya hanya memberikan daftar akun-akun ini kepada pengiklan, dan kemudian mereka menggunakan standar... Artinya, di jejaring sosial, seperti VKontakte, Anda dapat menentukan daftar orang-orang ini.
Namun, Facebook menggunakan kuki yang dibeli. Kami sendiri tidak menggunakan kuki, tetapi ada beberapa kasus di mana pengiklan menyediakan kuki tertentu kepada orang-orang tertentu, dan kami berinteraksi dengan mereka—mereka memiliki jaringan ini, dengan iklan teaser dan non-teaser, kuki ini. Penautan mungkin dilakukan—tidak masalah! Tapi saya kurang suka hal-hal seperti ini karena menurut saya kurang dapat diandalkan. Menurut saya, ini seperti pelacakan TNS pada TV—tidak jelas apakah Anda sedang menonton TV, tidak menontonnya, atau apakah Anda sedang mencuci piring saat TV menyala... Dan di sini juga sama: Saya sering mencari sesuatu di Google, tetapi bukan berarti saya ingin membelinya.
- Jika Anda menggunakan jaringan periklanan kontekstual standar, saya sudah beberapa kali mendengar cerita tentang orang-orang yang kami bongkar dan coba menautkan mereka ke kuki di situs mereka menggunakan antarmuka mereka. Tapi saya kurang suka hal semacam itu.
Rumus perhitungan gaji pengguna internet
- Rumus umum untuk gaji rata-rata adalah: wilayah tempat tinggal seseorang, kategori bisnis tempat mereka bekerja (yaitu, perusahaan tempat mereka bekerja), lalu posisi mereka di perusahaan ini diambil, gaji rata-rata untuk posisi ini diperkirakan... Gaji rata-rata diambil dari Head Hunter dan Superjob (dan beberapa sumber lain) untuk lowongan tertentu di wilayah tertentu dan untuk konteks bisnis tertentu.
Avito dan Avto.ru biasanya memberikan informasi tambahan jika seseorang telah membocorkan nomor teleponnya. Avito memungkinkan Anda melihat jenis barang yang dijual seseorang—mahal, murah, bekas, atau tidak. Avto.ru memungkinkan Anda melihat apakah seseorang memiliki mobil—apakah mereka memilikinya atau tidak. Ini mewakili kurang dari 20% orang yang secara tidak sengaja menjatuhkan ponsel mereka di suatu tempat, dan akun mereka dapat ditautkan dengan informasi ini.
Berapa banyak volume yang ditangani oleh perusahaan pengumpulan data?
- Volume foto yang tersimpan dalam petabita adalah 6,4. Saya tidak bisa mengatakan seberapa cepat pertumbuhannya saat ini, karena pada tahun 2016 kami mulai merekam "periskop" dan baru saja mulai merekam video.
Saya tidak bisa mengatakan kapan tepatnya data itu nol. Kami berpindah dari satu perusahaan ke perusahaan lain—ceritanya panjang. Tapi saya bisa bilang bahwa VK, Facebook, Instagram, dan Twitter—semua hal itu (orang, grup, dan koneksi di antara mereka) dengan teks dan konten—tidaklah sebesar itu, bahkan hampir satu petabita pun. Saya rasa sekitar 700, mungkin 800 gigabita.
Apakah Anda membantu klien mengidentifikasi ceruk yang relevan dan di mana harus menggalinya?
- Ketika klien datang, kami menyarankan hal-hal seperti itu kepada mereka, tetapi kami sendiri, seperti Google Trends, tidak melakukan hal-hal seperti itu.
- Kami telah memiliki beberapa berita terkait sosiologi, termasuk berita pemilu dan pra-pemilu—kami telah menganalisis semuanya. Dengan merek dan penilaian opini merek, semuanya hampir selalu cocok. Namun, berita pemilu dan pra-pemilu—tidak demikian (dengan penilaian mereka tentang kandidat mana yang seharusnya menang). Saya tidak tahu siapa yang salah di sini—kami atau orang-orang yang melakukan riset di VTsIOM.
- Biasanya, hasil tolok ukur ini kami dapatkan langsung dari mereknya sendiri, dan juga dari orang-orang yang melakukan riset—survei telepon, riset pemasaran, dan sebagainya. Selain itu, semua ini dapat diverifikasi dengan hal-hal dasar: apakah seseorang merespons buletin, atau apakah seseorang menyelesaikan survei... Jika mereknya besar (Coca-Cola, misalnya), mereka pasti memiliki satu atau dua juta ulasan pelanggan internal mereka sendiri—bukan hanya komentar di media sosial dan opini; mereka memiliki sistem internal, umpan balik, dan sebagainya.
Hukum tidak “mengetahui” apa itu data pribadi!
- Kami menganalisis sumber data terbuka secara eksklusif, tanpa pernah menggali informasi yang tidak akurat. Model kami didasarkan pada fakta bahwa kami menyimpan semua data terbuka di pusat data publik, atau menyewanya di tempat lain, dan menganalisisnya secara internal, di server kami sendiri, di kantor kami, dan tanpa pernah meninggalkan kantor kami.
Namun undang-undang kita di bidang data terbuka sangat tidak jelas.
Kita belum memiliki pemahaman yang jelas tentang apa itu data terbuka, apa itu data pribadi—ada Undang-Undang Federal 152, tapi tetap saja... Bagaimana mereka menghitungnya? Jadi, jika saya menyimpan nama dan nomor telepon Anda di satu basis data, nomor telepon dan email Anda di basis data lain, dan alamat email dan mobil Anda di basis data ketiga—semua ini tampak seperti data non-pribadi. Jika Anda menggabungkan semua ini, secara hukum, semuanya menjadi data pribadi.
Kami mengatasinya dengan dua cara. Pertama, kami memasang server dengan perangkat lunak klien agar data ini tidak keluar dari wilayah mereka, dan kemudian klien bertanggung jawab atas penyebaran data pribadi, data non-pribadi, dan sebagainya. Atau, kedua, jika ini adalah situasi di mana kami harus menuntut jejaring sosial atau semacamnya...
Kami melakukan studi seperti ini (selama pemilihan pendahuluan Rusia Bersatu) di mana kami mengumpulkan akun-akun orang-orang ini untuk LifeNews dan melihat konten porno yang mereka sukai. Lucu memang, tapi tetap saja. Kami menjualnya sebagai opini pribadi kami, tanpa mengungkapkan secara hukum dalam dokumen apa yang kami analisis—Daftar Badan Hukum Negara Bersatu, gaji, media sosial. Kami menjual opini ahli kami, lalu, di balik layar, kami menjelaskan kepada orang tersebut apa yang kami analisis dan bagaimana caranya.
Ada beberapa cerita, tetapi semuanya terkait dengan proyek komersial publik. Misalnya, kami memiliki proyek nirlaba gratis untuk para pengguna longboard (longboard seperti ini): tujuannya adalah mengumpulkan postingan orang-orang—ketika seseorang memposting, "Saya pergi ke Taman Gorky untuk berseluncur." Jadi, postingan tersebut akan muncul di peta, dan orang-orang di sekitar mereka dapat melihat bahwa seseorang berada di dekatnya. VK telah lama melawan kami tentang hal ini karena mereka tidak suka kami mempublikasikan informasi ini tanpa izin orang-orang. Namun, kasus ini tidak sampai ke pengadilan karena kami menambahkan klausul pada aturan untuk beberapa komunitas besar yang mengizinkan data tersebut digunakan oleh pihak ketiga, agensi, perusahaan, untuk analisis, dan sebagainya. Tentu saja, hal itu tidak terlalu etis, tetapi tetap saja. - Kami baru saja bangun tepat waktu dan mulai menjual pendapat ahli kami kepada semua orang.
Apakah Anda bekerja dengan lembaga pendidikan?
- Kami memang berkolaborasi dengan berbagai institusi pendidikan. Kami punya banyak sekali pilihan: kami punya program magister di Sekolah Pascasarjana, dan kami juga berkolaborasi dengan universitas lain. Kami sangat mencintai universitas!
- Saya punya informasi kontak saya—Anda bisa menulis surat kepada saya. Dan ini tautan ke presentasinya, jika ada yang tertarik—semua contohnya ada di sana, Anda bisa membagikannya.
- Jika nomor telepon dan alamat email diketahui, hampir bisa dipastikan; tidak ada yang akan menghapusnya. Jika tidak ada nomor telepon, biasanya berupa foto; jika tidak ada foto, biasanya berupa tahun, tempat tinggal, dan pekerjaan. Artinya, hampir semua orang selalu dapat diidentifikasi secara akurat berdasarkan tahun, tempat tinggal, dan pekerjaan. Namun, ini, sekali lagi, tergantung pada tugasnya.
Katakanlah kita punya klien yang menjual televisi internet. Seseorang berlangganan "Game of Thrones", dan tugasnya adalah menggunakan CRM mereka untuk menemukan orang-orang ini di media sosial, lalu menemukan prospek potensial dalam lingkup pengaruh mereka. Maksud saya, mereka hanya punya, misalnya, nama depan, nama belakang, dan alamat email... Jadi, sangat sulit untuk melakukan apa pun. Biasanya, Anda bisa menemukan orang berdasarkan alamat email.
- Kita biasanya "mencocokkan" orang berdasarkan teman media sosial mereka, tetapi ini tidak selalu benar. Bukan hanya karena tidak selalu benar—tidak selalu berhasil. Pertama, proses ini membutuhkan banyak tenaga, karena proses pencocokan ini harus dilakukan terlebih dahulu untuk setiap teman—untuk menentukan apakah mereka telah bermigrasi dari media sosial. Lalu, ada fakta umum bahwa kita memiliki beberapa teman di VKontakte dan beberapa teman di Facebook. Hal ini tidak berlaku untuk semua orang, tetapi berlaku untuk saya, misalnya; dan berlaku juga untuk kebanyakan orang.
Bagaimana Anda mengumpulkan data yang paling lengkap?
- Dengan memasang perangkat lunak di pihak klien. Sebuah server terpasang di pihak mereka yang hanya mengumpulkan data publik dari kami, tetapi memproses data pribadi mereka secara internal. Sebuah NDA ditandatangani dengan klien. Tentu saja tidak sepenuhnya adil bagi mereka untuk membagikan hal ini kepada kami, tetapi tanggung jawab hukum tetap berada di tangan klien—baik dengan memasang perangkat lunak maupun dengan mentransfer data anonim. Namun, hal ini sangat jarang terjadi, karena—entah anonimisasi itu benar atau salah—dalam kebanyakan kasus, koneksi antara orang-orang ini terputus.
Siapa yang membeli perangkat lunak pengenalan wajah?
- Kami sebenarnya datang ke sini karena perangkat lunak utama yang kami jual adalah pencarian wajah dan analisis hubungan, dan kami menjualnya ke instansi pemerintah. Jadi, satu setengah tahun yang lalu, kami memutuskan untuk memasukkan semua cerita ini ke dalam periklanan, pemasaran, dan pasar publik—begitulah Social Data Hub, sebuah badan hukum komersial, terbentuk. Jadi, kami baru saja datang ke sini sekarang. Kami sudah berada di sini selama satu setengah tahun, mencoba menjelaskan kepada orang-orang bahwa mereka seharusnya tidak diberi unduhan dengan penyebutan, bahwa mereka seharusnya diberi jawaban atas pertanyaan mereka, bahwa tidak perlu nada suara, dan sebagainya. Jadi, sulit untuk mengatakan di mana...
- (Siapa yang dimaksud?) Kepada semua kawan yang perlu mencari teroris, pedofil.
Saya dapat langsung mengatakan (ini akan menjadi pertanyaan berikutnya): berdasarkan informasi yang kami miliki, tidak ada guru yang dipenjara karena menyebarkan ulang. - Di VKontakte, persentasenya 14%; di Facebook, tidak ada yang namanya profil tertutup (mungkin mereka punya daftar teman tertutup, dll.). Dan yang paling menarik, saya baru saja menulis pesan—mereka akan menghitungnya dan memberi tahu Anda.
Jangan publikasikan sesuatu yang akan membuatmu malu!
- Jangan mengunggah apa pun di media sosial yang akan membuatmu malu—itulah panduan pribadi saya. Meskipun saya sudah sering mengalaminya sendiri karena saya mengumpat di Facebook. Ya, begitulah adanya, apa yang bisa Anda lakukan? Jangan mengunggah apa pun yang akan membuatmu malu! Jika Anda berencana bekerja untuk Kamar Dagang Publik nanti, ya, sebaiknya jangan berkomentar. Jika Anda tidak berencana melakukannya, maka, pada umumnya, tidak ada yang peduli. Saya hanya bisa meyakinkan Anda bahwa tidak ada yang membaca korespondensi pribadi Anda, dan semua eskalasi ini hanya akan memperburuk semuanya...
Setiap minggu, pasti ada saja yang datang ke saya dan bilang, "Lihat, foto-foto teman saya bocor ke grup publik anonim! Tolong!" Ngomong-ngomong, jangan pernah posting apa pun ke grup publik anonim.
- Saya tidak tahu tentang sistem pemantauan lain—kami pasti akan memperhitungkan bahwa penyebutan merek itu negatif, Tuhan ampuni saya... Tapi saya bisa bilang bahwa semua orang yang berafiliasi dengan pemerintah ini hanya tertarik pada orang-orang dengan audiens lebih dari 5 orang, dan opini publik mereka dapat memengaruhi seseorang. Berdasarkan pengalaman saya, saya belum pernah mendapati agensi SDM yang menugaskan kami untuk mengevaluasi profil berkata, "Kalau ada yang suka Navalny, jangan pekerjakan saya!"
Tentang publikasi hasil. Berapa banyak orang yang terlibat dalam penelitian ini?
- Dari 10 perusahaan periklanan teratas, tujuh di antaranya saat ini sedang menerbitkan. Sulit untuk mengatakannya: ketika kami memulai ini satu setengah tahun yang lalu... Kami memiliki beberapa orang di setiap bidang – beberapa di bank, beberapa di SDM, beberapa di periklanan. Dan sekarang kami sedang memikirkan siapa yang paling menguntungkan untuk dituju terlebih dahulu, siapa yang harus kami mulai kembangkan antarmukanya...
- (tentang jumlah orang per segmen pasar) Tidak lebih dari 25 orang, karena kami tidak memperkosa siapa pun.
- Secara umum, saya rasa lebih dari 50% pasar menggunakan teknologi ini. Beberapa digunakan dalam kampanye iklan, yang lainnya untuk analitik internal. Saya perkirakan 40% menggunakannya untuk analitik internal, sementara 50-60% menjualnya ke merek akhir. Tapi semuanya tergantung pada perusahaan periklanan itu sendiri. Begini, beberapa hanya melaporkan uang yang dikeluarkan dan iklan yang dimanipulasi, sementara yang lain benar-benar melaporkan berapa banyak orang yang mereka bawa, audiens yang mereka jangkau... Saya rasa itu benar, tapi saya bisa saja salah—saya tidak begitu mengerti cara kerja semua perusahaan ini. Saya hanya tahu data kuantitatif.

Beberapa iklan 🙂
Terima kasih untuk tetap bersama kami. Apakah Anda menyukai artikel kami? Ingin melihat konten yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman, , analog unik dari server level awal, yang kami temukan untuk Anda: (tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
Dell R730xd 2x lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya disini di Belanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai $99! Membaca tentang
Sumber: www.habr.com
