

KDB+, produk perusahaan adalah database kolom yang dikenal luas di kalangan sempit, sangat cepat, yang dirancang untuk menyimpan deret waktu dan perhitungan analitis berdasarkan deret waktu tersebut. Awalnya, ini (dan) sangat populer di industri keuangan - semua 10 bank investasi teratas dan banyak dana lindung nilai, bursa, dan organisasi lain yang terkenal menggunakannya. Baru-baru ini, KX memutuskan untuk memperluas basis pelanggannya dan kini menawarkan solusi di area lain di mana terdapat sejumlah besar data, yang diatur berdasarkan waktu atau lainnya - telekomunikasi, bioinformatika, manufaktur, dll. Mereka juga menjadi mitra tim Aston Martin Red Bull Racing di Formula 1, di mana mereka membantu mengumpulkan dan memproses data dari sensor mobil serta menganalisis pengujian terowongan angin. Pada artikel ini, saya ingin memberi tahu Anda fitur-fitur apa saja yang dimiliki KDB+ yang membuatnya berkinerja super, mengapa perusahaan bersedia mengeluarkan banyak uang untuk itu, dan terakhir, mengapa KDB+ sebenarnya bukan sebuah database.

Pada artikel kali ini saya akan mencoba memberi tahu Anda secara umum apa itu KDB+, apa saja kemampuan dan keterbatasan yang dimilikinya, serta apa manfaatnya bagi perusahaan yang ingin mengolah data dalam jumlah besar. Saya tidak akan membahas detail implementasi KDB+ atau detail bahasa pemrograman Q. Kedua topik ini sangat luas dan memerlukan artikel terpisah. Banyak informasi mengenai topik ini dapat ditemukan di code.kx.com, termasuk buku tentang Q - Q For Mortals (lihat link di bawah).
Beberapa istilah
- Basis data dalam memori. Basis data yang menyimpan data dalam RAM untuk akses lebih cepat. Keuntungan dari database seperti itu jelas, namun kelemahannya adalah kemungkinan kehilangan data dan kebutuhan untuk memiliki banyak memori di server.
- Basis data kolom. Basis data tempat data disimpan kolom demi kolom, bukan catatan demi catatan. Keuntungan utama dari database semacam itu adalah data dari satu kolom disimpan bersama di disk dan memori, yang secara signifikan mempercepat akses ke database tersebut. Tidak perlu memuat kolom yang tidak digunakan dalam kueri. Kerugian utamanya adalah sulitnya mengubah dan menghapus catatan.
- Rangkaian waktu. Data dengan kolom tanggal atau waktu. Biasanya, pengurutan waktu penting untuk data tersebut, sehingga Anda dapat dengan mudah menentukan rekaman mana yang mendahului atau mengikuti rekaman saat ini, atau untuk menerapkan fungsi yang hasilnya bergantung pada urutan rekaman. Basis data klasik dibangun dengan prinsip yang sama sekali berbeda - mewakili kumpulan catatan sebagai satu set, di mana urutan catatan, pada prinsipnya, tidak ditentukan.
- Vektor. Dalam konteks KDB+, ini adalah daftar unsur dengan tipe atom yang sama, misalnya bilangan. Dengan kata lain, serangkaian elemen. Array, tidak seperti daftar, dapat disimpan secara kompak dan diproses menggunakan instruksi prosesor vektor.
sejarah
KX didirikan pada tahun 1993 oleh Arthur Whitney, yang sebelumnya bekerja di Morgan Stanley Bank pada bahasa A+, penerus APL - bahasa yang sangat orisinal dan pernah populer di dunia keuangan. Tentu saja, di KX, Arthur melanjutkan dengan semangat yang sama dan menciptakan bahasa fungsional vektor K, dipandu oleh ide-ide minimalis radikal. Program K terlihat seperti kumpulan tanda baca dan karakter khusus, arti dari tanda dan fungsi bergantung pada konteksnya, dan setiap operasi membawa lebih banyak arti dibandingkan dengan bahasa pemrograman konvensional. Oleh karena itu, program K hanya memerlukan sedikit ruang—beberapa baris dapat menggantikan halaman teks dalam bahasa verbose seperti Java—dan merupakan implementasi algoritme yang sangat terkonsentrasi.
Sebuah fungsi di K yang mengimplementasikan sebagian besar generator parser LL1 berdasarkan tata bahasa tertentu:
1. pp:{q:{(x;p3(),y)};r:$[-11=@x;$x;11=@x;q[`N;$*x];10=abs@@x;q[`N;x]
2. ($)~*x;(`P;p3 x 1);(1=#x)&11=@*x;pp[{(1#x;$[2=#x;;,:]1_x)}@*x]
3. (?)~*x;(`Q;pp[x 1]);(*)~*x;(`M;pp[x 1]);(+)~*x;(`MP;pp[x 1]);(!)~*x;(`Y;p3 x 1)
4. (2=#x)&(@x 1)in 100 101 107 7 -7h;($[(@x 1)in 100 101 107h;`Ff;`Fi];p3 x 1;pp[*x])
5. (|)~*x;`S,(pp'1_x);2=#x;`C,{@[@[x;-1+#x;{x,")"}];0;"(",]}({$[".s.C"~4#x;6_-2_x;x]}'pp'x);'`pp];
6. $[@r;r;($[1<#r;".s.";""],$*r),$[1<#r;"[",(";"/:1_r),"]";""]]}
Arthur mewujudkan filosofi efisiensi ekstrim dengan gerakan tubuh yang minimal di KDB+, yang muncul pada tahun 2003 (saya rasa sekarang sudah jelas dari mana huruf K pada namanya berasal) dan tidak lebih dari penafsir versi keempat dari K. bahasa Versi yang lebih ramah pengguna telah ditambahkan di atas K K yang disebut Q. Q juga menambahkan dukungan untuk dialek SQL tertentu - QSQL, dan interpreter - dukungan untuk tabel sebagai tipe data sistem, alat untuk bekerja dengan tabel di memori dan di disk, dll.
Jadi dari sudut pandang pengguna, KDB+ hanyalah penerjemah bahasa Q dengan dukungan untuk tabel dan ekspresi gaya LINQ seperti SQL dari C#. Inilah perbedaan paling penting antara KDB+ dan database lain serta keunggulan kompetitif utamanya, yang sering diabaikan. Ini bukan database + bahasa tambahan yang dinonaktifkan, tetapi bahasa pemrograman yang kuat dan lengkap + dukungan bawaan untuk fungsi database. Pembedaan ini akan memainkan peran yang menentukan dalam mencantumkan seluruh manfaat KDB+. Misalnya…
Ukuran
Berdasarkan standar modern, KDB+ hanya berukuran mikroskopis. Ini sebenarnya adalah satu file sub-megabyte yang dapat dieksekusi dan satu file teks kecil dengan beberapa fungsi sistem. Kenyataannya - kurang dari satu megabyte, dan untuk program ini perusahaan membayar puluhan ribu dolar per tahun untuk satu prosesor di server.
- Ukuran ini memungkinkan KDB+ terasa hebat di perangkat keras apa pun - mulai dari komputer mikro Pi hingga server dengan memori terabyte. Ini tidak mempengaruhi fungsionalitas dengan cara apa pun; terlebih lagi, Q dimulai secara instan, yang memungkinkannya untuk digunakan, antara lain, sebagai bahasa skrip.
- Pada ukuran ini, penerjemah Q sepenuhnya masuk ke dalam cache prosesor, yang mempercepat eksekusi program.
- Dengan ukuran file yang dapat dieksekusi sebesar ini, proses Q hanya memakan sedikit ruang di memori; Anda dapat menjalankan ratusan file tersebut. Terlebih lagi, jika diperlukan, Q dapat beroperasi dengan memori puluhan atau ratusan gigabyte dalam satu proses.
fleksibilitas
Q sangat bagus untuk berbagai aplikasi. Proses Q dapat bertindak sebagai database historis dan menyediakan akses cepat ke informasi berukuran terabyte. Misalnya, kami memiliki lusinan basis data historis, yang beberapa di antaranya membutuhkan lebih dari 100 gigabyte untuk satu hari data yang tidak dikompresi. Namun, dalam batasan yang wajar, kueri ke database akan diselesaikan dalam waktu puluhan hingga ratusan milidetik. Secara umum, kami memiliki batas waktu universal untuk permintaan pengguna - 30 detik - dan ini sangat jarang berhasil.
Q bisa dengan mudah menjadi database dalam memori. Data baru ditambahkan ke tabel dalam memori dengan sangat cepat sehingga permintaan pengguna menjadi faktor pembatasnya. Data dalam tabel disimpan dalam kolom, yang berarti operasi apa pun pada kolom akan menggunakan cache prosesor dengan kapasitas penuh. Selain itu, KX mencoba mengimplementasikan semua operasi dasar seperti aritmatika melalui instruksi vektor prosesor, sehingga memaksimalkan kecepatannya. Q juga dapat melakukan tugas-tugas yang tidak biasa untuk database - misalnya, memproses streaming data dan menghitung secara “real time” (dengan penundaan dari puluhan milidetik hingga beberapa detik tergantung pada tugasnya) berbagai fungsi agregasi untuk instrumen keuangan untuk waktu yang berbeda interval atau membangun model pengaruh transaksi yang sempurna terhadap pasar dan melakukan pembuatan profilnya segera setelah selesai. Dalam tugas seperti itu, penundaan waktu utama yang paling sering bukanlah Q, tetapi kebutuhan untuk menyinkronkan data dari sumber yang berbeda. Kecepatan tinggi dicapai karena fakta bahwa data dan fungsi yang memprosesnya berada dalam satu proses, dan pemrosesan direduksi menjadi mengeksekusi beberapa ekspresi dan gabungan QSQL, yang tidak diinterpretasikan, tetapi dieksekusi oleh kode biner.
Terakhir, Anda dapat menulis proses layanan apa pun di Q. Misalnya, proses Gateway yang secara otomatis mendistribusikan permintaan pengguna ke database dan server yang diperlukan. Pemrogram memiliki kebebasan penuh untuk menerapkan algoritme apa pun untuk penyeimbangan, penentuan prioritas, toleransi kesalahan, hak akses, kuota, dan pada dasarnya apa pun yang diinginkan hatinya. Masalah utama di sini adalah Anda harus menerapkan semuanya sendiri.
Sebagai contoh, saya akan mencantumkan jenis proses apa yang kita miliki. Semuanya digunakan secara aktif dan bekerja sama, menggabungkan lusinan database berbeda menjadi satu, memproses data dari berbagai sumber dan melayani ratusan pengguna dan aplikasi.
- Konektor (feedhandler) ke sumber data. Proses ini biasanya menggunakan pustaka eksternal yang dimuat ke Q. Antarmuka C di Q sangat sederhana dan memungkinkan Anda membuat fungsi proxy dengan mudah untuk pustaka C/C++ apa pun. Q cukup cepat untuk menangani, misalnya, memproses banjir pesan FIX dari seluruh bursa saham Eropa secara bersamaan.
- Distributor data (tickerplant), yang berfungsi sebagai penghubung antara konektor dan konsumen. Pada saat yang sama, mereka menulis data yang masuk ke log biner khusus, memberikan ketahanan bagi konsumen terhadap kehilangan koneksi atau restart.
- Basis data dalam memori (rdb). Basis data ini menyediakan akses tercepat ke data mentah dan baru dengan menyimpannya di memori. Biasanya, mereka mengumpulkan data dalam tabel pada siang hari dan mengatur ulangnya pada malam hari.
- Basis data tetap (pdb). Basis data ini memastikan bahwa data untuk hari ini disimpan dalam basis data historis. Sebagai aturan, tidak seperti rdb, mereka tidak menyimpan data dalam memori, tetapi menggunakan cache khusus pada disk pada siang hari dan menyalin data pada tengah malam ke database historis.
- Basis data sejarah (hdb). Basis data ini menyediakan akses ke data untuk hari, bulan, dan tahun sebelumnya. Ukurannya (dalam hari) hanya dibatasi oleh ukuran hard drive. Data dapat ditempatkan dimana saja, khususnya pada disk yang berbeda untuk mempercepat akses. Dimungkinkan untuk mengompresi data menggunakan beberapa algoritma yang dapat dipilih. Struktur database terdokumentasi dengan baik dan sederhana, data disimpan kolom demi kolom dalam file biasa, sehingga dapat diproses, termasuk melalui sistem operasi.
- Basis data dengan informasi agregat. Mereka menyimpan berbagai agregasi, biasanya dengan, dikelompokkan berdasarkan nama instrumen dan interval waktu. Basis data dalam memori memperbarui statusnya dengan setiap pesan masuk, dan basis data historis menyimpan data yang telah dihitung sebelumnya untuk mempercepat akses ke data historis.
- Akhirnya, proses gerbangmelayani aplikasi dan pengguna. Q memungkinkan Anda menerapkan pemrosesan pesan masuk yang sepenuhnya tidak sinkron, mendistribusikannya ke seluruh database, memeriksa hak akses, dll. Perhatikan bahwa pesan tidak dibatasi dan seringkali bukan ekspresi SQL, seperti halnya di database lain. Paling sering, ekspresi SQL disembunyikan dalam fungsi khusus dan dibangun berdasarkan parameter yang diminta oleh pengguna - waktu dikonversi, disaring, data dinormalisasi (misalnya, harga saham disamakan jika dividen dibayarkan), dll.
Arsitektur khas untuk satu tipe data:
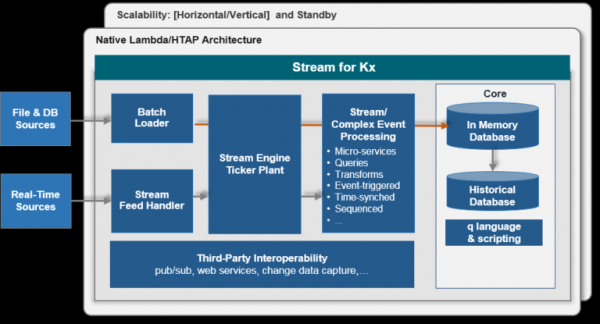
Mempercepat
Meskipun Q adalah bahasa interpretasi, Q juga merupakan bahasa vektor. Ini berarti bahwa banyak fungsi bawaan, terutama fungsi aritmatika, menggunakan argumen dalam bentuk apa pun - angka, vektor, matriks, daftar - dan pemrogram diharapkan mengimplementasikan program sebagai operasi array. Dalam bahasa seperti itu, jika Anda menambahkan dua vektor dari sejuta elemen, bahasa tersebut tidak lagi menjadi masalah; penambahan akan dilakukan oleh fungsi biner yang sangat dioptimalkan. Karena sebagian besar waktu dalam program Q dihabiskan untuk pengoperasian tabel menggunakan fungsi dasar vektor ini, outputnya adalah kecepatan pengoperasian yang sangat baik, memungkinkan kami memproses data dalam jumlah besar bahkan dalam satu proses. Ini mirip dengan perpustakaan matematika di Python - meskipun Python sendiri adalah bahasa yang sangat lambat, ia memiliki banyak perpustakaan bagus seperti numpy yang memungkinkan Anda memproses data numerik dengan kecepatan bahasa yang dikompilasi (omong-omong, numpy secara ideologis dekat dengan Q ).
Selain itu, KX mengambil pendekatan yang sangat hati-hati dalam mendesain tabel dan mengoptimalkan pekerjaan dengannya. Pertama, beberapa jenis indeks didukung, yang didukung oleh fungsi bawaan dan dapat diterapkan tidak hanya pada kolom tabel, tetapi juga pada vektor apa pun - pengelompokan, pengurutan, atribut keunikan, dan pengelompokan khusus untuk database historis. Indeks diterapkan secara sederhana dan secara otomatis disesuaikan saat menambahkan elemen ke kolom/vektor. Indeks juga dapat berhasil diterapkan ke kolom tabel baik di memori maupun di disk. Saat menjalankan kueri QSQL, indeks digunakan secara otomatis jika memungkinkan. Kedua, pekerjaan dengan data historis dilakukan melalui mekanisme tampilan file OS (peta memori). Tabel besar tidak pernah dimuat ke dalam memori; sebaliknya, kolom-kolom yang diperlukan dipetakan langsung ke dalam memori dan hanya bagian dari tabel tersebut yang benar-benar dimuat (indeks juga membantu di sini) yang diperlukan. Tidak ada bedanya bagi programmer apakah datanya ada di memori atau tidak, mekanisme untuk bekerja dengan mmap sepenuhnya tersembunyi di kedalaman Q.
KDB+ bukanlah database relasional; tabel dapat berisi data yang berubah-ubah, sedangkan urutan baris dalam tabel tidak berubah ketika elemen baru ditambahkan dan dapat dan harus digunakan saat menulis kueri. Fitur ini sangat dibutuhkan untuk bekerja dengan deret waktu (data dari pertukaran, telemetri, event log), karena jika data diurutkan berdasarkan waktu, maka pengguna tidak perlu menggunakan trik SQL apa pun untuk mencari baris pertama atau terakhir atau N baris dalam tabel, menentukan garis mana yang mengikuti garis ke-N, dan seterusnya. Penggabungan tabel semakin disederhanakan, misalnya, menemukan penawaran terakhir untuk 16000 transaksi VOD.L (Vodafone) dalam tabel yang berisi 500 juta elemen memerlukan waktu sekitar satu detik pada disk dan puluhan milidetik di memori.
Contoh penggabungan waktu - tabel kutipan dipetakan ke memori, jadi tidak perlu menentukan VOD.L di mana, indeks pada kolom sym dan fakta bahwa data diurutkan berdasarkan waktu digunakan secara implisit. Hampir semua gabungan di Q adalah fungsi reguler, bukan bagian dari ekspresi pemilihan:
1. aj[`sym`time;select from trade where date=2019.03.26, sym=`VOD.L;select from quote where date=2019.03.26]
Terakhir, perlu dicatat bahwa para insinyur di KX, dimulai dengan Arthur Whitney sendiri, sangat terobsesi dengan efisiensi dan berusaha keras untuk mendapatkan hasil maksimal dari fitur standar Q dan mengoptimalkan pola penggunaan yang paling umum.
Total
KDB+ populer di kalangan bisnis terutama karena keserbagunaannya yang luar biasa - KDB+ berfungsi sama baiknya sebagai database dalam memori, sebagai database untuk menyimpan data historis berukuran terabyte, dan sebagai platform untuk analisis data. Karena pemrosesan data terjadi langsung di database, kecepatan kerja tinggi dan penghematan sumber daya tercapai. Bahasa pemrograman lengkap yang terintegrasi dengan fungsi database memungkinkan Anda mengimplementasikan seluruh rangkaian proses yang diperlukan pada satu platform - mulai dari menerima data hingga memproses permintaan pengguna.
Untuk informasi lebih lanjut,
Kekurangan:
Kerugian signifikan dari KDB+/Q adalah ambang masuk yang tinggi. Bahasa ini memiliki sintaksis yang aneh, beberapa fungsi kelebihan beban (nilai, misalnya, memiliki sekitar 11 kasus penggunaan). Yang paling penting, hal ini memerlukan pendekatan yang sangat berbeda dalam menulis program. Dalam bahasa vektor, Anda harus selalu memikirkan transformasi array, mengimplementasikan semua loop melalui beberapa varian fungsi map/reduce (yang disebut kata keterangan di Q), dan jangan pernah mencoba menghemat uang dengan mengganti operasi vektor dengan operasi atom. Misalnya, untuk mencari indeks kemunculan elemen ke-N dalam array, Anda harus menulis:
1. (where element=vector)[N]
meskipun ini tampaknya sangat tidak efisien menurut standar C/Java (= membuat vektor boolean, yang mengembalikan indeks sebenarnya dari elemen di dalamnya). Namun notasi ini membuat arti ekspresi lebih jelas dan Anda menggunakan operasi vektor cepat daripada operasi atomik lambat. Perbedaan konseptual antara bahasa vektor dan bahasa lainnya sebanding dengan perbedaan antara pendekatan imperatif dan fungsional dalam pemrograman, dan Anda harus bersiap untuk hal ini.
Beberapa pengguna juga tidak puas dengan QSQL. Intinya hanya terlihat seperti SQL asli. Pada kenyataannya, ini hanyalah penerjemah ekspresi mirip SQL yang tidak mendukung optimasi kueri. Pengguna harus menulis kueri optimal sendiri, dan di Q, yang banyak orang belum siap. Di sisi lain, tentu saja, Anda selalu dapat menulis kueri optimal sendiri, daripada mengandalkan pengoptimal kotak hitam.
Sebagai nilai tambah, buku tentang Q - Q For Mortals tersedia gratis di , masih banyak juga materi bermanfaat lainnya yang dikumpulkan di sana.
Kerugian besar lainnya adalah biaya lisensi. Itu berarti puluhan ribu dolar per tahun per CPU. Hanya perusahaan besar yang mampu menanggung biaya sebesar itu. Baru-baru ini, KX telah membuat kebijakan lisensinya lebih fleksibel dan memberikan kesempatan untuk membayar hanya untuk waktu penggunaan atau sewa KDB+ di cloud Google dan Amazon. KX juga menawarkan untuk diunduh (Versi 32 bit atau 64 bit berdasarkan permintaan).
pesaing
Ada banyak database khusus yang dibangun berdasarkan prinsip serupa - berbentuk kolom, dalam memori, berfokus pada data dalam jumlah yang sangat besar. Masalahnya adalah ini adalah database khusus. Contoh yang mencolok adalah Clickhouse. Basis data ini memiliki prinsip yang sangat mirip dengan KDB+ untuk menyimpan data pada disk dan membangun indeks; basis data ini melakukan beberapa kueri lebih cepat dibandingkan KDB+, meskipun tidak secara signifikan. Tetapi bahkan sebagai database, Clickhouse lebih terspesialisasi daripada KDB+ - analisis web vs deret waktu arbitrer (perbedaan ini sangat penting - karena itu, misalnya, di Clickhouse tidak mungkin menggunakan pengurutan catatan). Namun, yang paling penting, Clickhouse tidak memiliki keserbagunaan KDB+, sebuah bahasa yang memungkinkan pemrosesan data secara langsung dalam database, daripada memuatnya terlebih dahulu ke dalam aplikasi terpisah, membuat ekspresi SQL arbitrer, menerapkan fungsi arbitrer dalam kueri, membuat proses tidak terkait dengan pelaksanaan fungsi database historis. Oleh karena itu, sulit untuk membandingkan KDB+ dengan database lain; mereka mungkin lebih baik dalam kasus penggunaan tertentu atau hanya lebih baik ketika menyangkut tugas database klasik, tapi saya tidak tahu alat lain yang sama efektif dan serbaguna untuk memproses data sementara.
Integrasi piton
Untuk membuat KDB+ lebih mudah digunakan bagi orang-orang yang belum terbiasa dengan teknologi ini, KX membuat perpustakaan untuk berintegrasi erat dengan Python dalam satu proses. Anda dapat memanggil fungsi Python apa pun dari Q, atau sebaliknya - memanggil fungsi Q apa pun dari Python (khususnya, ekspresi QSQL). Perpustakaan mengkonversi, jika perlu (tidak selalu demi efisiensi), data dari format satu bahasa ke format bahasa lain. Akibatnya, Q dan Python hidup dalam simbiosis yang begitu erat sehingga batasan di antara keduanya menjadi kabur. Hasilnya, pemrogram, di satu sisi, memiliki akses penuh ke berbagai pustaka Python yang berguna, di sisi lain, ia menerima basis cepat untuk bekerja dengan data besar yang terintegrasi ke dalam Python, yang sangat berguna bagi mereka yang terlibat dalam pembelajaran mesin. atau pemodelan.
Bekerja dengan Q dengan Python:
1. >>> q()
2.q)trade:([]date:();sym:();qty:())
3. q)
4. >>> q.insert('trade', (date(2006,10,6), 'IBM', 200))
5. k(',0')
6. >>> q.insert('trade', (date(2006,10,6), 'MSFT', 100))
7. k(',1')
referensi
Situs perusahaan -
Situs web untuk pengembang -
Buku Q Untuk Manusia (dalam bahasa Inggris) -
Artikel tentang aplikasi KDB+/Q dari karyawan kx -
Sumber: www.habr.com
