


Halo semuanya! Nama saya Dmitry Samsonov, dan saya bekerja sebagai administrator sistem utama di Odnoklassniki. Kami memiliki lebih dari 7 server fisik, 11 kontainer di cloud kami, dan 200 aplikasi, yang dalam berbagai konfigurasi membentuk 700 klaster berbeda. Sebagian besar server berjalan CentOS 7.
Pada 14 Agustus 2018, informasi tentang kerentanan FragmentSmack dipublikasikan
() dan SegmenSmack (). Ini adalah kerentanan dengan vektor serangan jaringan dan skor yang cukup tinggi (7.5), yang mengancam penolakan layanan (DoS) karena kehabisan sumber daya (CPU). Perbaikan kernel untuk FragmentSmack tidak diusulkan pada saat itu; terlebih lagi, perbaikan ini muncul lebih lambat dari publikasi informasi tentang kerentanan. Untuk menghilangkan SegmentSmack, diusulkan untuk memperbarui kernel. Paket updatenya sendiri dirilis di hari yang sama, yang tersisa hanyalah menginstalnya.
Tidak, kami sama sekali tidak menentang pembaruan kernel! Namun, ada nuansa...
Bagaimana kami memperbarui kernel pada produksi
Secara umum, tidak ada yang rumit:
- Unduh paket;
- Instal di sejumlah server (termasuk server yang menghosting cloud kami);
- Pastikan tidak ada yang rusak;
- Pastikan semua pengaturan kernel standar diterapkan tanpa kesalahan;
- Tunggu beberapa hari;
- Periksa kinerja server;
- Alihkan penerapan server baru ke kernel baru;
- Memperbarui semua server berdasarkan pusat data (satu pusat data dalam satu waktu untuk meminimalkan dampak pada pengguna jika terjadi masalah);
- Nyalakan ulang semua server.
Ulangi untuk semua cabang kernel yang kita miliki. Saat ini adalah:
- Stok CentOS 7 3.10 - untuk sebagian besar server biasa;
- Vanila 4.19 - untuk kita , karena kita membutuhkan BFQ, BBR, dll;
- Elrepo kernel-ml 5.2 - untuk , karena 4.19 dulu berperilaku tidak stabil, namun fitur yang sama diperlukan.
Seperti yang sudah Anda duga, me-reboot ribuan server membutuhkan waktu paling lama. Karena tidak semua kerentanan penting untuk semua server, kami hanya me-reboot server yang dapat diakses langsung dari Internet. Di cloud, agar tidak membatasi fleksibilitas, kami tidak mengikat container yang dapat diakses secara eksternal ke server individual dengan kernel baru, tetapi me-reboot semua host tanpa kecuali. Untungnya, prosedur di sana lebih sederhana dibandingkan dengan server biasa. Misalnya, container stateless dapat dengan mudah dipindahkan ke server lain saat reboot.
Namun, masih banyak pekerjaan yang harus dilakukan, dan dapat memakan waktu beberapa minggu, dan jika ada masalah dengan versi baru, dapat memakan waktu hingga beberapa bulan. Penyerang memahami hal ini dengan sangat baik, sehingga mereka memerlukan rencana B.
FragmentSmack/SegmentSmack. Solusi
Untungnya, untuk beberapa kerentanan, ada rencana B, dan ini disebut Solusi. Seringkali, ini adalah perubahan dalam pengaturan kernel/aplikasi yang dapat meminimalkan efek yang mungkin terjadi atau sepenuhnya menghilangkan eksploitasi kerentanan.
Dalam kasus FragmentSmack/SegmentSmack Solusi ini:
«Anda dapat mengubah nilai default 4MB dan 3MB di net.ipv4.ipfrag_high_thresh dan net.ipv4.ipfrag_low_thresh (dan padanannya untuk ipv6 net.ipv6.ipfrag_high_thresh dan net.ipv6.ipfrag_low_thresh) masing-masing menjadi 256 kB dan 192 kB atau lebih rendah. Pengujian menunjukkan penurunan kecil hingga signifikan dalam penggunaan CPU selama serangan, bergantung pada perangkat keras, pengaturan, dan kondisi. Namun, mungkin ada beberapa dampak kinerja karena ipfrag_high_thresh=262144 byte, karena hanya dua fragmen 64K yang dapat dimasukkan ke dalam antrean perakitan ulang pada satu waktu. Misalnya, ada risiko aplikasi yang bekerja dengan paket UDP besar akan rusak'.
Parameternya sendiri dijelaskan sebagai berikut:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Kami tidak memiliki UDP besar pada layanan produksi. Tidak ada lalu lintas yang terfragmentasi di LAN; ada lalu lintas yang terfragmentasi di WAN, tetapi tidak signifikan. Tidak ada tanda-tanda - Anda dapat meluncurkan Solusi!
FragmentSmack/SegmentSmack. Darah pertama
Masalah pertama yang kami temui adalah wadah cloud terkadang menerapkan pengaturan baru hanya sebagian (hanya ipfrag_low_thresh), dan terkadang tidak menerapkannya sama sekali - pengaturan tersebut hanya crash di awal. Masalah tidak dapat direproduksi secara stabil (semua pengaturan diterapkan secara manual tanpa kesulitan apa pun). Memahami mengapa container mogok di awal juga tidak mudah: tidak ditemukan kesalahan. Satu hal yang pasti: mengembalikan pengaturan akan menyelesaikan masalah kerusakan container.
Mengapa menerapkan Sysctl pada host saja tidak cukup? Kontainer tersebut berada di Namespace jaringan khusus miliknya sendiri, jadi setidaknya dalam wadah mungkin berbeda dari hostnya.
Bagaimana tepatnya pengaturan Sysctl diterapkan dalam wadah? Karena container kami tidak memiliki hak istimewa, Anda tidak akan dapat mengubah pengaturan Sysctl apa pun dengan masuk ke container itu sendiri - Anda tidak memiliki cukup hak. Untuk menjalankan container, cloud kami saat itu menggunakan Docker (sekarang ). Parameter kontainer baru diteruskan ke Docker melalui API, termasuk pengaturan Sysctl yang diperlukan.
Saat mencari versinya, ternyata Docker API tidak mengembalikan semua kesalahan (setidaknya di versi 1.10). Saat kami mencoba memulai container melalui “docker run”, kami akhirnya melihat setidaknya sesuatu:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Nilai parameter tidak valid. Tapi kenapa? Dan mengapa kadang-kadang tidak valid saja? Ternyata Docker tidak menjamin urutan penerapan parameter Sysctl (versi terbaru yang diuji adalah 1.13.1), jadi terkadang ipfrag_high_thresh mencoba diatur ke 256K ketika ipfrag_low_thresh masih 3M, yaitu batas atas lebih rendah dari batas bawah, yang menyebabkan kesalahan.
Pada saat itu, kami telah menggunakan mekanisme kami sendiri untuk mengkonfigurasi ulang container setelah dimulai (membekukan container setelahnya dan menjalankan perintah di namespace wadah melalui ), dan kami juga menambahkan parameter penulisan Sysctl ke bagian ini. Masalah terselesaikan.
FragmentSmack/SegmentSmack. Darah Pertama 2
Sebelum kami sempat memahami penggunaan Workaround di cloud, keluhan pertama yang jarang terjadi dari pengguna mulai berdatangan. Pada saat itu, beberapa minggu telah berlalu sejak dimulainya penggunaan Workaround di server pertama. Investigasi awal menunjukkan bahwa keluhan diterima terhadap layanan individual, dan tidak semua server layanan tersebut. Masalahnya kembali menjadi sangat tidak pasti.
Pertama-tama, kami mencoba mengembalikan pengaturan Sysctl, tetapi itu tidak berpengaruh. Berbagai manipulasi pengaturan server dan aplikasi juga tidak membantu. Reboot baru berhasil. Reboot untuk... Linux sama tidak wajarnya seperti kondisi normal dalam bekerja dengan Windows Dulu memang begitu. Tapi cara itu berhasil, dan kami menganggapnya sebagai "kesalahan kernel" saat menerapkan pengaturan Sysctl baru. Betapa bodohnya kami...
Tiga minggu kemudian masalahnya terulang kembali. Konfigurasi server ini cukup sederhana: Nginx dalam mode proxy/penyeimbang. Tidak banyak lalu lintas. Catatan pengantar baru: jumlah kesalahan 504 pada klien meningkat setiap hari (). Grafik menunjukkan jumlah 504 kesalahan per hari untuk layanan ini:
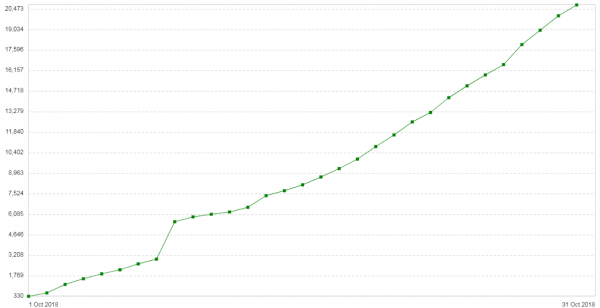
Semua kesalahan terjadi pada backend yang sama - pada backend yang ada di cloud. Grafik konsumsi memori untuk fragmen paket di backend ini terlihat seperti ini:
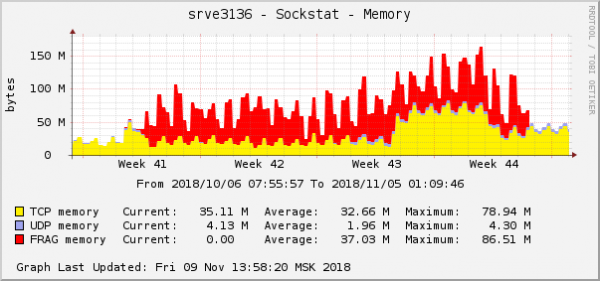
Ini adalah salah satu manifestasi paling jelas dari masalah grafik sistem operasi. Di cloud, pada saat yang sama, masalah jaringan lain dengan pengaturan QoS (Kontrol Lalu Lintas) telah diperbaiki. Pada grafik konsumsi memori untuk fragmen paket, terlihat persis sama:
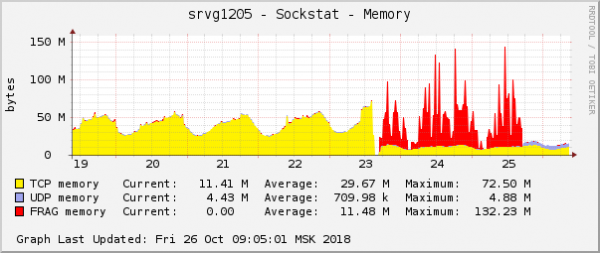
Asumsinya sederhana: jika grafiknya terlihat sama, berarti alasannya sama. Selain itu, masalah dengan jenis memori ini sangat jarang terjadi.
Inti dari masalah yang diperbaiki adalah kami menggunakan penjadwal paket fq dengan pengaturan default di QoS. Secara default, untuk satu koneksi, ini memungkinkan Anda untuk menambahkan 100 paket ke antrian, dan beberapa koneksi, dalam situasi kekurangan saluran, mulai menyumbat antrian hingga mencapai kapasitas. Dalam hal ini, paket akan dibuang. Pada statistik tc (tc -s qdisc) dapat dilihat seperti ini:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
“464545 flow_plimit” adalah paket yang dijatuhkan karena melebihi batas antrian satu koneksi, dan “dropped 464545” adalah jumlah dari semua paket yang dijatuhkan dari penjadwal ini. Setelah menambah panjang antrian menjadi 1 dan memulai ulang kontainer, masalah tidak lagi terjadi. Anda bisa duduk santai dan minum smoothie.
FragmentSmack/SegmentSmack. Darah Terakhir
Pertama, beberapa bulan setelah kerentanan kernel diumumkan, perbaikan untuk FragmentSmack akhirnya dirilis (ingat, pengumuman bulan Agustus hanya merilis perbaikan untuk SegmentSmack), yang memberi kami kesempatan untuk meninggalkan Workaround, yang telah menyebabkan kami cukup banyak masalah. Kami telah memigrasikan beberapa server ke kernel baru selama waktu ini, dan sekarang kami harus memulai dari awal. Mengapa kami memperbarui kernel tanpa menunggu perbaikan FragmentSmack? Faktanya adalah bahwa proses perlindungan terhadap kerentanan ini bertepatan (dan menyatu) dengan proses pembaruan Workaround itu sendiri. CentOS (yang bahkan memakan waktu lebih lama daripada sekadar memperbarui kernel). Selain itu, SegmentSmack adalah kerentanan yang lebih berbahaya, dan perbaikannya tersedia dengan segera, jadi itu masuk akal. Namun, sekadar memperbarui kernel CentOS Kami tidak bisa karena adanya kerentanan FragmentSmack yang muncul selama CentOS Masalah pada versi 7.5 baru diperbaiki di versi 7.6, jadi kami harus menghentikan pembaruan ke versi 7.5 dan memulai kembali dari awal dengan pembaruan ke versi 7.6. Hal ini juga terjadi.
Kedua, keluhan pengguna yang jarang tentang masalah telah kembali kepada kami. Sekarang kita sudah tahu pasti bahwa itu semua terkait dengan upload file dari klien ke beberapa server kita. Selain itu, sejumlah kecil unggahan dari total massa melewati server ini.
Seperti yang kita ingat dari cerita di atas, memutar kembali Sysctl tidak membantu. Reboot membantu, tapi sementara.
Kecurigaan terhadap Sysctl tidak hilang, tapi kali ini perlu mengumpulkan informasi sebanyak mungkin. Ada juga kurangnya kemampuan untuk mereproduksi masalah unggahan pada klien untuk mempelajari lebih tepat apa yang terjadi.
Analisis terhadap semua statistik dan log yang tersedia tidak membawa kita lebih dekat untuk memahami apa yang sedang terjadi. Ada kekurangan yang akut dalam kemampuan untuk mereproduksi masalah untuk “merasakan” hubungan tertentu. Terakhir, pengembang, dengan menggunakan versi khusus aplikasi, berhasil mencapai reproduksi masalah yang stabil pada perangkat uji saat terhubung melalui Wi-Fi. Ini merupakan terobosan dalam penyelidikan. Klien terhubung ke Nginx, yang diproksi ke backend, yang merupakan aplikasi Java kami.
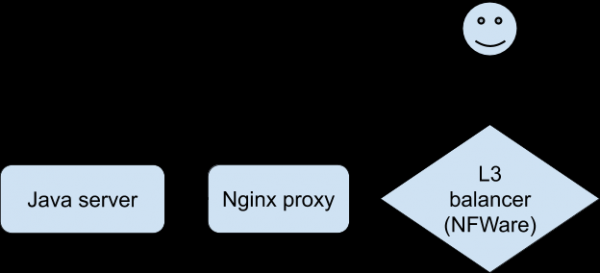
Dialog untuk masalah seperti ini (diperbaiki di sisi proxy Nginx):
- Klien: permintaan untuk menerima informasi tentang pengunduhan file.
- Server Java: respons.
- Klien: POST dengan file.
- Server Java: kesalahan.
Pada saat yang sama, server Java menulis ke log bahwa 0 byte data diterima dari klien, dan proxy Nginx menulis bahwa permintaan tersebut memakan waktu lebih dari 30 detik (30 detik adalah batas waktu aplikasi klien). Mengapa batas waktu habis dan mengapa 0 byte? Dari perspektif HTTP, semuanya berfungsi sebagaimana mestinya, tetapi POST dengan file tersebut tampaknya menghilang dari jaringan. Selain itu, menghilang antara klien dan Nginx. Saatnya mempersenjatai diri dengan Tcpdump! Namun pertama-tama Anda perlu memahami konfigurasi jaringan. Proksi Nginx berada di belakang penyeimbang L3 . Tunneling digunakan untuk mengirimkan paket dari penyeimbang L3 ke server, yang menambahkan headernya ke paket:
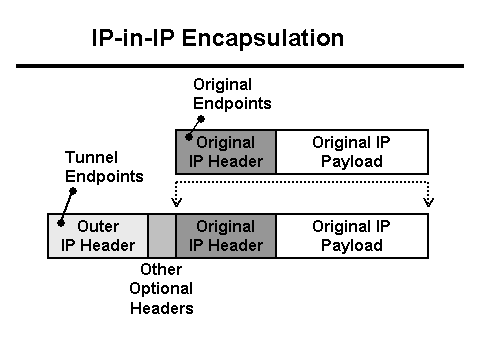
Dalam hal ini, jaringan datang ke server ini dalam bentuk lalu lintas bertanda Vlan, yang juga menambahkan bidangnya sendiri ke paket:
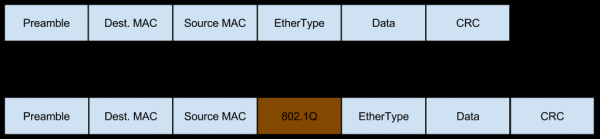
Dan lalu lintas ini juga dapat terfragmentasi (persentase kecil dari lalu lintas masuk terfragmentasi yang kita bicarakan saat menilai risiko dari Workaround), yang juga mengubah konten header:
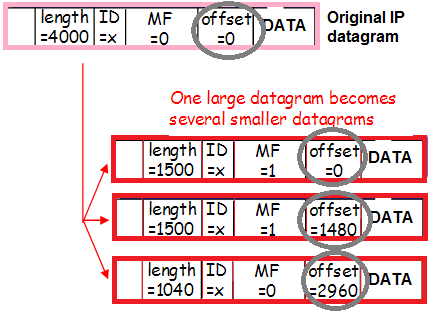
Sekali lagi: paket dienkapsulasi dengan tag Vlan, dienkapsulasi dengan terowongan, terfragmentasi. Untuk lebih memahami bagaimana hal ini terjadi, mari kita telusuri rute paket dari klien ke proxy Nginx.
- Paket mencapai penyeimbang L3. Untuk perutean yang benar di dalam pusat data, paket dienkapsulasi dalam terowongan dan dikirim ke kartu jaringan.
- Karena header paket + terowongan tidak sesuai dengan MTU, paket dipotong menjadi beberapa bagian dan dikirim ke jaringan.
- Sakelar setelah penyeimbang L3, saat menerima paket, menambahkan tag Vlan ke dalamnya dan mengirimkannya.
- Switch di depan proxy Nginx melihat (berdasarkan pengaturan port) bahwa server mengharapkan paket yang dienkapsulasi Vlan, sehingga server mengirimkannya apa adanya, tanpa menghapus tag Vlan.
- Linux menerima potongan-potongan dari kemasan individual dan merekatkannya menjadi satu kemasan besar.
- Selanjutnya, paket mencapai antarmuka Vlan, di mana lapisan pertama - enkapsulasi Vlan - dihapus darinya.
- kemudian Linux mengirimkannya ke antarmuka Tunnel, di mana lapisan lain dihilangkan darinya - enkapsulasi Tunnel.
Kesulitannya adalah meneruskan semua ini sebagai parameter ke tcpdump.
Mari kita mulai dari akhir: apakah ada paket IP yang bersih (tanpa header yang tidak perlu) dari klien, dengan enkapsulasi vlan dan terowongan dihapus?
tcpdump host <ip клиента>
Tidak, tidak ada paket seperti itu di server. Jadi masalahnya pasti sudah ada sebelumnya. Apakah ada paket yang hanya menghapus enkapsulasi Vlan?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx adalah alamat IP klien dalam format hex.
32:4 — alamat dan panjang field di mana IP SCR ditulis dalam paket Tunnel.
Alamat bidang harus dipilih secara brute force, karena di Internet mereka menulis sekitar 40, 44, 50, 54, tetapi tidak ada alamat IP di sana. Anda juga dapat melihat salah satu paket dalam hex (parameter -xx atau -XX di tcpdump) dan menghitung alamat IP yang Anda ketahui.
Apakah ada fragmen paket tanpa enkapsulasi Vlan dan Tunnel yang dihapus?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Keajaiban ini akan menunjukkan kepada kita semua pecahannya, termasuk yang terakhir. Mungkin, hal yang sama dapat difilter berdasarkan IP, tetapi saya tidak mencobanya, karena paket seperti itu tidak banyak, dan paket yang saya butuhkan mudah ditemukan di aliran umum. Di sini mereka:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 Dalam 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), panjang 62: (tos 0x0, ttl 63, id 53652, offsetnya 1480, bendera [tidak ada], proto IPIP (4), panjang 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000.............
Ini adalah dua fragmen dari satu paket (ID yang sama 53652) dengan sebuah foto (kata Exif terlihat di paket pertama). Karena kenyataan bahwa ada paket pada level ini, tetapi tidak dalam bentuk gabungan di dump, masalahnya jelas ada pada perakitan. Akhirnya ada bukti dokumenter mengenai hal ini!
Dekoder paket tidak mengungkapkan masalah apa pun yang dapat menghalangi pembangunan. Mencobanya di sini: . Pada awalnya, ketika Anda mencoba memasukkan sesuatu ke sana, dekoder tidak menyukai format paketnya. Ternyata ada tambahan dua oktet antara Srcmac dan Ethertype (tidak terkait dengan informasi fragmen). Setelah menghapusnya, decoder mulai bekerja. Namun, hal itu tidak menunjukkan adanya masalah.
Apapun yang orang katakan, tidak ada lagi yang ditemukan kecuali Sysctl. Yang tersisa hanyalah menemukan cara untuk mengidentifikasi server yang bermasalah guna memahami skalanya dan memutuskan tindakan lebih lanjut. Penghitung yang diperlukan ditemukan cukup cepat:
netstat -s | grep "packet reassembles failed”
Itu juga ada di snmpd di bawah OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
“Jumlah kegagalan yang terdeteksi oleh algoritme perakitan ulang IP (untuk alasan apa pun: waktu habis, kesalahan, dll.).”
Di antara kelompok server tempat masalahnya dipelajari, penghitung ini meningkat dua kali lebih cepat, lebih lambat dua kali lipat, dan tidak meningkat sama sekali sebanyak dua kali. Membandingkan dinamika penghitung ini dengan dinamika kesalahan HTTP di server Java menunjukkan adanya korelasi. Artinya, meteran bisa dipantau.
Memiliki indikator masalah yang dapat diandalkan sangat penting sehingga Anda dapat menentukan secara akurat apakah memutar kembali Sysctl membantu, karena dari cerita sebelumnya kita mengetahui bahwa hal ini tidak dapat langsung dipahami dari aplikasi. Indikator ini memungkinkan kami mengidentifikasi semua area masalah dalam produksi sebelum pengguna menemukannya.
Setelah memutar kembali Sysctl, kesalahan pemantauan berhenti, sehingga penyebab masalahnya terbukti, serta fakta bahwa rollback membantu.
Kami mengembalikan pengaturan fragmentasi di server lain, tempat pemantauan baru mulai berlaku, dan di suatu tempat kami mengalokasikan lebih banyak memori untuk fragmen daripada default sebelumnya (ini adalah statistik UDP, yang kehilangan sebagian tidak terlihat dengan latar belakang umum) .
Pertanyaan paling penting
Mengapa paket terfragmentasi pada penyeimbang L3 kami? Sebagian besar paket yang datang dari pengguna ke penyeimbang adalah SYN dan ACK. Ukuran paket ini kecil. Namun karena porsi paket tersebut sangat besar, dengan latar belakangnya kami tidak melihat adanya paket besar yang mulai terfragmentasi.
Alasannya adalah skrip konfigurasi yang rusak pada server dengan antarmuka Vlan (hanya ada sedikit server dengan lalu lintas yang diberi tag dalam produksi pada saat itu). Advmss memungkinkan kami menyampaikan kepada klien informasi bahwa paket-paket ke arah kami harus berukuran lebih kecil sehingga setelah melampirkan header terowongan ke paket-paket tersebut, paket-paket tersebut tidak harus terfragmentasi.
Mengapa Sysctl rollback tidak membantu, tetapi reboot membantu? Mengembalikan Sysctl mengubah jumlah memori yang tersedia untuk menggabungkan paket. Pada saat yang sama, tampaknya fakta meluapnya memori untuk fragmen menyebabkan perlambatan koneksi, yang menyebabkan fragmen tertunda dalam antrian untuk waktu yang lama. Artinya, prosesnya berjalan dalam siklus.
Reboot membersihkan memori dan semuanya kembali normal.
Apakah mungkin dilakukan tanpa Workaround? Ya, tapi ada risiko tinggi meninggalkan pengguna tanpa layanan jika terjadi serangan. Tentu saja penggunaan Workaround menimbulkan berbagai masalah, termasuk melambatnya salah satu layanan bagi pengguna, namun kami yakin tindakan tersebut dapat dibenarkan.
Terima kasih banyak kepada Andrey Timofeev () untuk bantuan dalam melakukan penyelidikan, serta Alexei Krenev () - atas pekerjaan raksasa dalam memperbarui Centos dan inti server. Dalam kasus ini, proses harus dimulai ulang beberapa kali, sehingga memakan waktu berbulan-bulan.
Sumber: www.habr.com
