


Selama beberapa tahun terakhir, database time-series telah berubah dari hal yang aneh (sangat terspesialisasi digunakan baik dalam sistem pemantauan terbuka (dan terikat pada solusi spesifik) atau dalam proyek Big Data) menjadi “produk konsumen”. Di wilayah Federasi Rusia, terima kasih khusus harus diberikan kepada Yandex dan ClickHouse untuk ini. Hingga saat ini, jika Anda perlu menyimpan data deret waktu dalam jumlah besar, Anda harus menerima kebutuhan untuk membangun tumpukan Hadoop yang sangat besar dan memeliharanya, atau berkomunikasi dengan protokol individual untuk setiap sistem.
Tampaknya di tahun 2019 artikel tentang TSDB mana yang layak digunakan hanya terdiri dari satu kalimat: “gunakan saja ClickHouse”. Tapi... ada perbedaannya.
Memang benar, ClickHouse secara aktif berkembang, basis pengguna tumbuh, dan dukungan sangat aktif, namun apakah kita telah menjadi sandera kesuksesan publik ClickHouse, yang telah membayangi solusi lain yang mungkin lebih efektif/dapat diandalkan?
Pada awal tahun lalu, kami mulai mengerjakan ulang sistem pemantauan kami sendiri, yang pada saat itu muncul pertanyaan tentang memilih database yang sesuai untuk menyimpan data. Saya ingin berbicara tentang sejarah pilihan ini di sini.
Pernyataan masalah
Pertama-tama, kata pengantar yang diperlukan. Mengapa kita memerlukan sistem pemantauan kita sendiri dan bagaimana sistem itu dirancang?
Kami mulai menyediakan layanan dukungan pada tahun 2008, dan pada tahun 2010 menjadi jelas bahwa menjadi sulit untuk mengumpulkan data tentang proses yang terjadi di infrastruktur klien dengan solusi yang ada pada saat itu (yang kita bicarakan, Tuhan maafkan saya, Cacti, Zabbix dan Grafit yang muncul).
Persyaratan utama kami adalah:
- dukungan (pada saat itu - lusinan, dan di masa depan - ratusan) klien dalam satu sistem dan pada saat yang sama adanya sistem manajemen peringatan terpusat;
- fleksibilitas dalam mengelola sistem peringatan (eskalasi peringatan antar petugas jaga, penjadwalan, basis pengetahuan);
- kemampuan untuk merinci grafik secara mendalam (Zabbix pada waktu itu membuat grafik dalam bentuk gambar);
- penyimpanan jangka panjang dari sejumlah besar data (satu tahun atau lebih) dan kemampuan untuk mengambilnya dengan cepat.
Pada artikel ini kami tertarik pada poin terakhir.
Berbicara tentang penyimpanan, persyaratannya adalah sebagai berikut:
- sistem harus bekerja dengan cepat;
- diharapkan sistem memiliki antarmuka SQL;
- sistem harus stabil dan memiliki basis pengguna aktif serta dukungan (setelah kami dihadapkan pada kebutuhan untuk mendukung sistem seperti MemcacheDB, yang tidak lagi dikembangkan, atau penyimpanan terdistribusi MooseFS, yang pelacak bugnya disimpan dalam bahasa Cina: kami mengulangi cerita ini karena proyek kami tidak mau);
- kepatuhan dengan teorema CAP: Konsistensi (wajib) - data harus mutakhir, kami tidak ingin sistem manajemen peringatan tidak menerima data baru dan mengeluarkan peringatan tentang tidak datangnya data untuk semua proyek; Toleransi Partisi (wajib) - kami tidak ingin mendapatkan sistem Split Brain; Ketersediaan (tidak penting, jika ada replika aktif) - kita dapat beralih ke sistem cadangan sendiri jika terjadi kecelakaan, menggunakan kode.
Anehnya, saat itu MySQL ternyata menjadi solusi ideal bagi kami. Struktur data kami sangat sederhana: id server, id penghitung, stempel waktu, dan nilai; pengambilan sampel data panas yang cepat dijamin oleh kumpulan buffer yang besar, dan pengambilan sampel data historis dijamin oleh SSD.
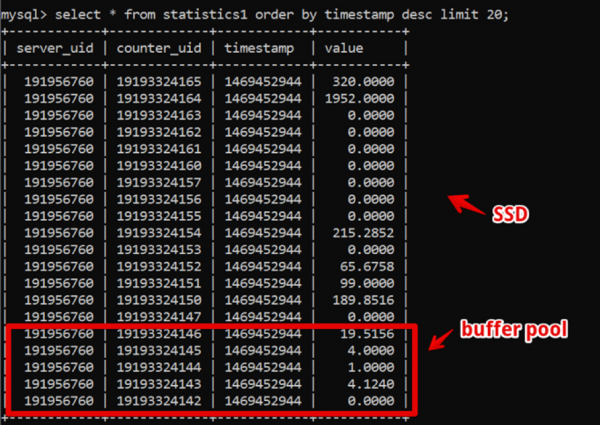
Oleh karena itu, kami mendapatkan sampel data baru dalam dua minggu, dengan detail hingga 200 ms kedua sebelum data dirender sepenuhnya, dan berada dalam sistem ini untuk waktu yang cukup lama.
Sementara itu, waktu berlalu dan jumlah data bertambah. Pada tahun 2016, volume data mencapai puluhan terabyte, yang merupakan pengeluaran yang signifikan dalam konteks penyimpanan SSD sewaan.
Pada saat ini, database kolom telah tersebar luas secara aktif, yang mulai kami pikirkan secara aktif: dalam database kolom, data disimpan, seperti yang dapat Anda pahami, dalam kolom, dan jika Anda melihat data kami, mudah untuk melihat sejumlah besar jumlah duplikat yang bisa, jika Anda menggunakan database kolom, kompres menggunakan kompresi.
Namun, sistem kunci perusahaan terus bekerja dengan stabil, dan saya tidak ingin bereksperimen dengan beralih ke sistem lain.
Pada tahun 2017, pada konferensi Percona Live di San Jose, pengembang Clickhouse mungkin mengumumkan diri mereka untuk pertama kalinya. Sekilas, sistemnya sudah siap produksi (Yandex.Metrica adalah sistem produksi yang tangguh), dukungannya cepat dan sederhana, dan yang terpenting, pengoperasiannya sederhana. Sejak 2018, kami telah memulai proses transisi. Namun pada saat itu, terdapat banyak sistem TSDB yang “dewasa” dan telah teruji oleh waktu, dan kami memutuskan untuk mencurahkan banyak waktu dan membandingkan alternatif untuk memastikan bahwa tidak ada solusi alternatif selain Clickhouse, sesuai dengan kebutuhan kami.
Selain persyaratan penyimpanan yang telah ditentukan, persyaratan baru telah muncul:
- sistem baru harus memberikan setidaknya kinerja yang sama seperti MySQL pada jumlah perangkat keras yang sama;
- penyimpanan sistem baru akan memakan lebih sedikit ruang;
- DBMS harus tetap mudah dikelola;
- Saya ingin mengubah aplikasi secara minimal ketika mengubah DBMS.
Sistem apa yang mulai kami pertimbangkan?
Apache Sarang/Apache Impala
Tumpukan Hadoop lama yang telah teruji dalam pertempuran. Pada dasarnya, ini adalah antarmuka SQL yang dibangun untuk menyimpan data dalam format asli di HDFS.
Pro
- Dengan pengoperasian yang stabil, sangat mudah untuk menskalakan data.
- Ada solusi kolom untuk penyimpanan data (lebih sedikit ruang).
- Eksekusi tugas paralel yang sangat cepat ketika sumber daya tersedia.
Cons
- Ini Hadoop, dan sulit digunakan. Jika kami belum siap untuk mengambil solusi siap pakai di cloud (dan kami belum siap dalam hal biaya), seluruh tumpukan harus dirakit dan didukung oleh tangan admin, dan kami benar-benar tidak mau ini.
- Data dikumpulkan .
Namun:

Kecepatan dicapai dengan menskalakan jumlah server komputasi. Sederhananya, jika kita adalah perusahaan besar, bergerak di bidang analitik, dan sangat penting bagi bisnis untuk mengumpulkan informasi secepat mungkin (bahkan dengan mengorbankan sumber daya komputasi dalam jumlah besar), ini mungkin pilihan kita. Namun kami belum siap memperbanyak armada perangkat keras untuk mempercepat tugas.
Druid/Pinot
Ada lebih banyak hal khusus tentang TSDB, tetapi sekali lagi, tumpukan Hadoop.
Ada .
Singkatnya: Druid/Pinot terlihat lebih baik daripada Clickhouse jika:
- Anda memiliki sifat data yang heterogen (dalam kasus kami, kami hanya mencatat deret waktu metrik server, dan sebenarnya ini adalah satu tabel. Namun mungkin ada kasus lain: deret waktu peralatan, deret waktu ekonomi, dll. - masing-masing dengan strukturnya sendiri, yang perlu dikumpulkan dan diproses).
- Apalagi datanya banyak sekali.
- Tabel dan data dengan deret waktu muncul dan menghilang (yaitu, kumpulan data tertentu tiba, dianalisis, dan dihapus).
- Tidak ada kriteria yang jelas untuk mempartisi data.
Sebaliknya, ClickHouse berkinerja lebih baik, dan inilah kasus kami.
KlikRumah
- Seperti SQL
- Mudah dikelola.
- Orang bilang itu berhasil.
Dipilih untuk pengujian.
masuknyaDB
Alternatif asing untuk ClickHouse. Minusnya : High Availability hanya ada pada versi komersil saja, namun perlu dibandingkan.
Dipilih untuk pengujian.
Cassandra
Di satu sisi, kita tahu bahwa ini digunakan untuk menyimpan deret waktu metrik oleh sistem pemantauan seperti, misalnya, atau OkMeter. Namun, ada hal spesifiknya.
Cassandra bukanlah database kolom dalam pengertian tradisional. Tampilannya lebih mirip tampilan baris, namun setiap baris dapat memiliki jumlah kolom berbeda, sehingga memudahkan penataan tampilan kolom. Dalam pengertian ini, jelas bahwa dengan batas 2 miliar kolom, dimungkinkan untuk menyimpan beberapa data dalam kolom (dan deret waktu yang sama). Misalnya, di MySQL ada batasan 4096 kolom dan mudah untuk menemukan kesalahan dengan kode 1117 jika Anda mencoba melakukan hal yang sama.
Mesin Cassandra difokuskan pada penyimpanan data dalam jumlah besar dalam sistem terdistribusi tanpa master, dan teorema Cassandra CAP yang disebutkan di atas lebih banyak tentang AP, yaitu tentang ketersediaan data dan ketahanan terhadap partisi. Oleh karena itu, alat ini sangat berguna jika Anda hanya perlu menulis ke database ini dan jarang membacanya. Dan di sini logis untuk menggunakan Cassandra sebagai penyimpanan “dingin”. Artinya, sebagai tempat jangka panjang dan andal untuk menyimpan data historis dalam jumlah besar yang jarang diperlukan, namun dapat diambil jika diperlukan. Meski begitu, demi kelengkapannya, kami akan mengujinya juga. Namun, seperti yang saya katakan sebelumnya, tidak ada keinginan untuk secara aktif menulis ulang kode untuk solusi database yang dipilih, jadi kami akan mengujinya secara terbatas - tanpa menyesuaikan struktur database dengan spesifikasi Cassandra.
Prometheus
Karena penasaran, kami memutuskan untuk menguji kinerja penyimpanan Prometheus - hanya untuk memahami apakah kami lebih cepat atau lebih lambat dibandingkan solusi saat ini dan seberapa besar kinerjanya.
Metodologi dan hasil pengujian
Jadi, kami menguji 5 database dalam 6 konfigurasi berikut: ClickHouse (1 node), ClickHouse (tabel terdistribusi untuk 3 node), InfluxDB, Mysql 8, Cassandra (3 node) dan Prometheus. Rencana pengujiannya adalah sebagai berikut:
- mengunggah data historis selama seminggu (840 juta nilai per hari; 208 ribu metrik);
- kami menghasilkan beban rekaman (6 mode beban dipertimbangkan, lihat di bawah);
- Sejalan dengan perekaman, kami secara berkala membuat pilihan, meniru permintaan pengguna yang bekerja dengan grafik. Agar tidak terlalu memperumit masalah, kami memilih data untuk 10 metrik (jumlah persisnya ada pada grafik CPU) selama seminggu.
Kami memuat dengan meniru perilaku agen pemantauan kami, yang mengirimkan nilai ke setiap metrik setiap 15 detik sekali. Pada saat yang sama, kami tertarik untuk memvariasikan:
- jumlah total metrik tempat data ditulis;
- interval pengiriman nilai ke satu metrik;
- ukuran tumpukan.
Tentang ukuran batch. Karena tidak disarankan untuk memuat hampir semua database eksperimental kami dengan satu sisipan, kami memerlukan relai yang mengumpulkan metrik yang masuk dan mengelompokkannya ke dalam grup dan menulisnya ke database sebagai sisipan batch.
Selain itu, untuk lebih memahami cara menafsirkan data yang diterima, bayangkan kita tidak hanya mengirimkan sekumpulan metrik, namun metrik tersebut disusun ke dalam server - 125 metrik per server. Di sini server hanyalah sebuah entitas virtual - hanya untuk memahami bahwa, misalnya, 10000 metrik sama dengan sekitar 80 server.
Dan di sini, dengan mempertimbangkan semua ini, adalah 6 mode pemuatan tulis database kami:
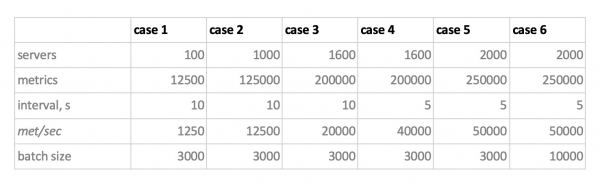
Ada dua poin di sini. Pertama, untuk Cassandra ukuran batch ini ternyata terlalu besar, kami menggunakan nilai 50 atau 100. Dan kedua, karena Prometheus bekerja secara ketat dalam mode tarik, yaitu. itu sendiri berjalan dan mengumpulkan data dari sumber metrik (dan bahkan pushgateway, terlepas dari namanya, tidak mengubah situasi secara mendasar), beban terkait diimplementasikan menggunakan kombinasi konfigurasi statis.
Hasil tesnya adalah sebagai berikut:
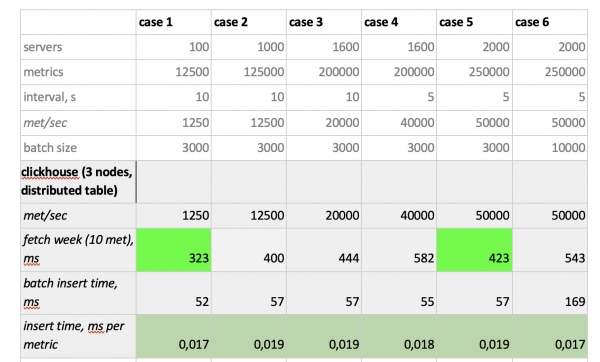
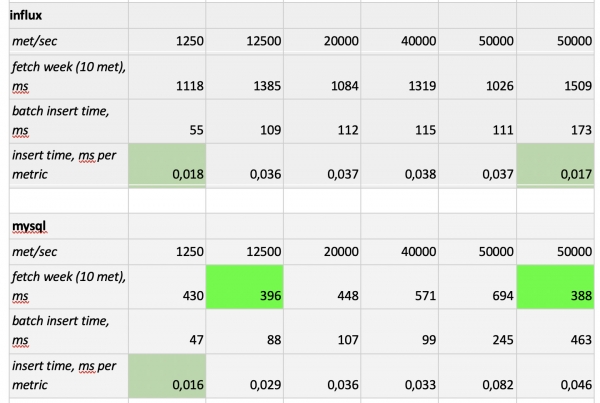
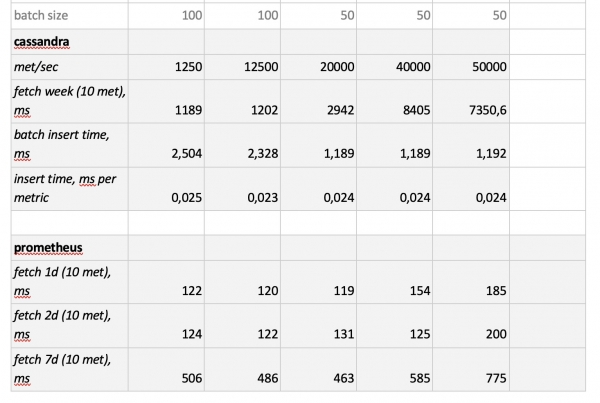
Apa yang perlu diperhatikan?: sampel yang sangat cepat dari Prometheus, sampel yang sangat lambat dari Cassandra, sampel yang sangat lambat dari InfluxDB; Dalam hal kecepatan perekaman, ClickHouse memenangkan semua orang, dan Prometheus tidak berpartisipasi dalam kompetisi, karena membuat sisipan sendiri dan kami tidak mengukur apa pun.
Sebagai hasilnya,: ClickHouse dan InfluxDB terbukti menjadi yang terbaik, tetapi cluster dari Influx hanya dapat dibangun berdasarkan versi Enterprise, yang memerlukan biaya, sedangkan ClickHouse tidak memerlukan biaya apa pun dan dibuat di Rusia. Masuk akal bahwa di AS pilihannya mungkin mendukung inInfluxDB, dan di negara kami lebih memilih ClickHouse.
Sumber: www.habr.com
