


Tujuan utama Patroni adalah menyediakan Ketersediaan Tinggi untuk PostgreSQL. Tapi Patroni hanyalah sebuah template, bukan alat yang sudah jadi (yang secara umum dikatakan dalam dokumentasi). Sekilas, setelah menyiapkan Patroni di lab pengujian, Anda dapat melihat betapa hebatnya alat itu dan betapa mudahnya menangani upaya kami untuk memecahkan cluster. Namun, dalam praktiknya, di lingkungan produksi, semuanya tidak selalu terjadi seindah dan seanggun di lab uji.

Saya akan menceritakan sedikit tentang diri saya. Saya memulai sebagai administrator sistem. Bekerja di pengembangan web. Saya telah bekerja di Data Egret sejak 2014. Perusahaan ini bergerak dalam bidang konsultasi di bidang Postgres. Dan kami melayani Postgres dengan tepat, dan kami bekerja dengan Postgres setiap hari, jadi kami memiliki keahlian berbeda terkait pengoperasian.
Dan di akhir tahun 2018, kami mulai menggunakan Patroni secara perlahan. Dan beberapa pengalaman telah terkumpul. Kami entah bagaimana mendiagnosisnya, menyetelnya, sampai pada praktik terbaik kami. Dan dalam laporan ini saya akan membicarakannya.
Selain Postgres, saya suka LinuxSaya suka bereksperimen dan mengeksplorasi, dan saya suka membangun kernel. Saya menyukai virtualisasi, kontainer, Docker, dan Kubernetes. Saya tertarik pada semua ini karena kebiasaan admin lama saya mulai muncul kembali. Saya suka bereksperimen dengan pemantauan. Saya juga menyukai hal-hal terkait Postgres yang berhubungan dengan admin, seperti replikasi dan pencadangan. Dan di waktu luang saya, saya menulis dalam bahasa Go. Saya bukan insinyur perangkat lunak, saya hanya menulis dalam bahasa Go untuk diri saya sendiri. Dan saya menikmatinya.

- Saya rasa banyak dari Anda yang tahu bahwa Postgres tidak memiliki HA (Ketersediaan Tinggi) di luar kotak. Untuk mendapatkan HA, Anda perlu menginstal sesuatu, mengonfigurasinya, berusaha, dan mendapatkannya.
- Ada beberapa alat dan Patroni adalah salah satunya yang menyelesaikan HA dengan cukup keren dan sangat baik. Tetapi dengan meletakkan semuanya di lab uji dan menjalankannya, kita dapat melihat bahwa semuanya berfungsi, kita dapat mereproduksi beberapa masalah, melihat bagaimana Patroni melayani mereka. Dan kita akan melihat bahwa semuanya bekerja dengan baik.
- Namun dalam praktiknya, kami menghadapi masalah yang berbeda. Dan saya akan berbicara tentang masalah ini.
- Saya akan memberi tahu Anda bagaimana kami mendiagnosisnya, apa yang kami atur - apakah itu membantu kami atau tidak.

- Saya tidak akan memberi tahu Anda cara menginstal Patroni, karena Anda dapat google di Internet, Anda dapat melihat file konfigurasi untuk memahami bagaimana semuanya dimulai, bagaimana konfigurasinya. Anda dapat memahami skema, arsitektur, mencari informasi tentangnya di Internet.
- Saya tidak akan berbicara tentang pengalaman orang lain. Saya hanya akan berbicara tentang masalah yang kami hadapi.
- Dan saya tidak akan membicarakan masalah yang berada di luar Patroni dan PostgreSQL. Jika, misalnya, ada masalah yang terkait dengan penyeimbangan, ketika cluster kami runtuh, saya tidak akan membicarakannya.

Dan sebuah penafian kecil sebelum kami memulai laporan kami.
Semua masalah yang kami temui ini, kami alami dalam 6-7-8 bulan pertama operasi. Seiring waktu, kami sampai pada praktik terbaik internal kami. Dan masalah kami hilang. Oleh karena itu, laporan tersebut diumumkan sekitar enam bulan yang lalu, ketika semuanya masih segar di kepala saya dan saya mengingat semuanya dengan sempurna.
Dalam proses menyiapkan laporan, saya sudah mengangkat postmortem lama, melihat log. Dan beberapa perincian dapat dilupakan, atau beberapa perincian tidak dapat diselidiki sepenuhnya selama analisis masalah, sehingga pada beberapa titik tampaknya masalah tidak sepenuhnya dipertimbangkan, atau ada kekurangan informasi. Jadi saya meminta Anda untuk memaafkan saya untuk saat ini.

Apa itu Patroni?
- Ini adalah template untuk membangun HA. Itulah yang tertulis dalam dokumentasi. Dan dari sudut pandang saya, ini adalah klarifikasi yang sangat tepat. Patroni bukanlah peluru perak yang akan menyelesaikan semua masalah Anda, yaitu Anda perlu berusaha agar berhasil dan membawa manfaat.
- Ini adalah layanan agen yang diinstal pada setiap layanan basis data dan merupakan semacam sistem init untuk Postgres Anda. Itu memulai Postgres, berhenti, memulai ulang, mengkonfigurasi ulang, dan mengubah topologi klaster Anda.
- Oleh karena itu, untuk menyimpan status cluster, representasinya saat ini, seperti yang terlihat, diperlukan semacam penyimpanan. Dan dari sudut pandang ini, Patroni mengambil jalan menyimpan negara dalam sistem eksternal. Ini adalah sistem penyimpanan konfigurasi terdistribusi. Itu bisa Etcd, Konsul, ZooKeeper, atau kubernetes Etcd, yaitu salah satu opsi ini.
- Dan salah satu fitur Patroni adalah Anda mengeluarkan autofiler dari kotaknya, hanya dengan mengaturnya. Jika kita menggunakan Repmgr sebagai perbandingan, maka filer disertakan di sana. Dengan Repmgr, kami mendapatkan pengalihan, tetapi jika kami menginginkan autofiler, kami perlu mengonfigurasinya sebagai tambahan. Patroni sudah memiliki autofiler di luar kotak.
- Dan masih banyak hal lainnya. Misalnya, pemeliharaan konfigurasi, menuangkan replika baru, cadangan, dll. Tapi ini di luar cakupan laporan, saya tidak akan membicarakannya.

Dan hasil kecilnya adalah tugas utama Patroni adalah melakukan autofile dengan baik dan andal agar cluster kami tetap beroperasi dan aplikasi tidak melihat perubahan pada topologi cluster.

Namun saat kami mulai menggunakan Patroni, sistem kami menjadi sedikit lebih rumit. Jika sebelumnya kita memiliki Postgres, maka saat menggunakan Patroni kita mendapatkan Patroni itu sendiri, kita mendapatkan DCS tempat penyimpanan status. Dan itu semua harus bekerja entah bagaimana. Jadi apa yang salah?
Mungkin pecah:
- Postgres mungkin rusak. Itu bisa master atau replika, salah satunya mungkin gagal.
- Patroni itu sendiri bisa pecah.
- DCS tempat status disimpan dapat rusak.
- Dan jaringan bisa putus.
Semua poin ini akan saya pertimbangkan dalam laporan.

Saya akan mempertimbangkan kasus karena menjadi lebih kompleks, bukan dari sudut pandang kasus yang melibatkan banyak komponen. Dan dari sudut pandang perasaan subyektif, bahwa kasing ini sulit bagi saya, sulit untuk dibongkar ... begitu pula sebaliknya, ada kasing yang ringan dan mudah untuk dibongkar.

Dan kasus pertama adalah yang termudah. Ini adalah kasus ketika kami mengambil klaster database dan menerapkan penyimpanan DCS kami pada klaster yang sama. Ini adalah kesalahan yang paling umum. Ini adalah kesalahan dalam membangun arsitektur, yaitu menggabungkan komponen yang berbeda di satu tempat.
Jadi, ada filer, mari kita bahas apa yang terjadi.

Dan di sini kami tertarik pada saat filer terjadi. Artinya, kami tertarik pada saat ini ketika status cluster berubah.
Tetapi filer tidak selalu instan, mis. tidak memakan waktu berapa pun, bisa ditunda. Itu bisa tahan lama.
Oleh karena itu, ia memiliki waktu mulai dan waktu berakhir, yaitu peristiwa yang berkelanjutan. Dan kami membagi semua peristiwa menjadi tiga interval: kami memiliki waktu sebelum filer, selama filer, dan setelah filer. Artinya, kami mempertimbangkan semua peristiwa di garis waktu ini.

Dan yang pertama, ketika filer terjadi, kami mencari penyebab dari apa yang terjadi, apa penyebab dari apa yang menyebabkan filer tersebut.
Jika kita melihat lognya, itu adalah log Patroni klasik. Dia memberi tahu kita di dalamnya bahwa server telah menjadi master, dan peran master telah diteruskan ke node ini. Di sini disorot.

Selanjutnya, kita perlu memahami mengapa filer terjadi, yaitu peristiwa apa yang terjadi yang menyebabkan peran master berpindah dari satu node ke node lainnya. Dan dalam hal ini, semuanya sederhana. Kami memiliki kesalahan dalam berinteraksi dengan sistem penyimpanan. Master menyadari bahwa dia tidak dapat bekerja dengan DCS, yaitu, ada masalah dengan interaksi. Dan dia berkata bahwa dia tidak bisa lagi menjadi master dan mengundurkan diri. Baris ini "menurunkan diri" mengatakan hal itu.

Jika kita melihat peristiwa yang mendahului filer, kita dapat melihat di sana alasan yang menjadi masalah kelanjutan wizard.
Jika kita melihat log Patroni, kita akan melihat bahwa kita memiliki banyak kesalahan, waktu habis, yaitu agen Patroni tidak dapat bekerja dengan DCS. Dalam hal ini, ini adalah agen Konsul, yang sedang berkomunikasi di port 8500.
Masalahnya di sini adalah Patroni dan basis data berjalan pada host yang sama. Server Consul juga berjalan pada host yang sama. Dengan menciptakan beban pada server, kita malah menimbulkan masalah bagi... server Konsul. Mereka tidak dapat berkomunikasi secara normal.

Setelah beberapa waktu, ketika beban mereda, Patroni kami dapat berkomunikasi kembali dengan agen. Pekerjaan normal dilanjutkan. Dan server Pgdb-2 yang sama menjadi master lagi. Artinya, ada flip kecil, yang menyebabkan node mengundurkan diri dari kekuatan master, dan kemudian mengambilnya lagi, yaitu, semuanya kembali seperti semula.

Dan ini dapat dianggap sebagai alarm palsu, atau dapat dianggap bahwa Patroni melakukan segalanya dengan benar. Artinya, dia menyadari bahwa dia tidak dapat mempertahankan keadaan cluster dan melepaskan otoritasnya.
Dan di sini masalah muncul karena fakta bahwa server Konsul berada di perangkat keras yang sama dengan pangkalan. Oleh karena itu, beban apa pun: apakah itu beban pada disk atau prosesor, itu juga memengaruhi interaksi dengan cluster Konsul.

Dan kami memutuskan bahwa itu tidak boleh hidup bersama, kami mengalokasikan cluster terpisah untuk Konsul. Dan Patroni sudah bekerja dengan Konsul tersendiri, yaitu ada klaster Postgres tersendiri, klaster Konsul tersendiri. Ini adalah instruksi dasar tentang cara membawa dan menyimpan semua barang ini agar tidak hidup bersama.
Sebagai opsi, Anda dapat memutar parameter ttl, loop_wait, retry_timeout, mis. mencoba bertahan dari puncak beban jangka pendek ini dengan meningkatkan parameter ini. Tapi ini bukan pilihan yang paling cocok, karena beban ini bisa lama. Dan kami hanya akan melampaui batas parameter ini. Dan itu mungkin tidak terlalu membantu.
Masalah pertama, seperti yang Anda pahami, sederhana. Kami mengambil dan menyatukan DCS dengan pangkalan, kami mendapat masalah.

Masalah kedua mirip dengan yang pertama. Hal serupa terjadi lagi karena kami memiliki masalah interoperabilitas dengan sistem DCS.

Jika kita melihat log, kita akan melihat bahwa kita kembali mengalami kesalahan komunikasi. Dan Patroni mengatakan saya tidak dapat berinteraksi dengan DCS sehingga master saat ini masuk ke mode replika.
Tuan tua menjadi replika, di sini Patroni bekerja sebagaimana mestinya. Ini berjalan pg_rewind untuk memundurkan log transaksi dan kemudian terhubung ke master baru untuk mengejar master baru. Di sini Patroni berhasil, sebagaimana mestinya.

Di sini kita harus menemukan tempat yang mendahului filer, yaitu kesalahan yang menyebabkan kita memiliki filer. Dan dalam hal ini, log Patroni cukup nyaman untuk digunakan. Dia menulis pesan yang sama pada interval tertentu. Dan jika kita mulai menggulir log ini dengan cepat, kita akan melihat dari log bahwa log telah berubah, yang berarti beberapa masalah telah dimulai. Kami segera kembali ke tempat ini, lihat apa yang terjadi.
Dan dalam situasi normal, log terlihat seperti ini. Pemilik kunci diperiksa. Dan jika pemiliknya, misalnya, telah berubah, maka beberapa peristiwa dapat terjadi yang harus ditanggapi oleh Patroni. Tapi dalam hal ini, kami baik-baik saja. Kami mencari tempat di mana kesalahan dimulai.

Dan setelah menggulir ke titik di mana kesalahan mulai muncul, kami melihat bahwa kami memiliki fileover otomatis. Dan karena kesalahan kami terkait dengan interaksi dengan DCS dan dalam kasus kami, kami menggunakan Konsul, kami juga melihat log Konsul, apa yang terjadi di sana.
Secara kasar membandingkan waktu pelapor dan waktu di log Konsul, kita melihat bahwa tetangga kita di klaster Konsul mulai meragukan keberadaan anggota klaster Konsul lainnya.

Dan jika Anda juga melihat log dari agen Konsul lainnya, Anda juga dapat melihat bahwa ada semacam keruntuhan jaringan. Dan seluruh anggota klaster Konsul saling meragukan keberadaannya. Dan ini adalah dorongan untuk filer.
Jika Anda melihat apa yang terjadi sebelum kesalahan ini, Anda dapat melihat bahwa ada banyak kesalahan, misalnya tenggat waktu, RPC jatuh, yaitu jelas ada beberapa masalah dalam interaksi anggota cluster Konsul satu sama lain. .

Jawaban paling sederhana adalah memperbaiki jaringan. Tapi bagi saya, berdiri di podium, mudah mengatakannya. Tetapi keadaan sedemikian rupa sehingga pelanggan tidak selalu mampu memperbaiki jaringan. Dia mungkin tinggal di DC dan mungkin tidak dapat memperbaiki jaringan, mempengaruhi peralatan. Dan beberapa opsi lain diperlukan.

Ada pilihan:
- Opsi paling sederhana, yang menurut saya tertulis, bahkan dalam dokumentasi, adalah menonaktifkan pemeriksaan Konsul, yaitu, cukup berikan larik kosong. Dan kami memberi tahu agen Konsul untuk tidak menggunakan cek apa pun. Dengan pemeriksaan ini, kami dapat mengabaikan badai jaringan ini dan tidak memulai filer.
- Opsi lainnya adalah memeriksa ulang raft_multiplier. Ini adalah parameter dari server Konsul itu sendiri. Secara default, ini diatur ke 5. Nilai ini direkomendasikan oleh dokumentasi untuk lingkungan pementasan. Bahkan, hal ini mempengaruhi frekuensi pengiriman pesan antar anggota jaringan Konsul. Padahal, parameter ini mempengaruhi kecepatan komunikasi pelayanan antar anggota klaster Konsul. Dan untuk produksi, sudah disarankan untuk menguranginya agar node lebih sering bertukar pesan.
- Opsi lain yang kami buat adalah meningkatkan prioritas proses Konsul di antara proses lain untuk penjadwalan proses sistem operasi. Ada parameter yang "bagus", itu hanya menentukan prioritas proses yang diperhitungkan oleh penjadwal OS saat menjadwalkan. Kami juga telah mengurangi nilai bagus untuk agen Konsul, yaitu. meningkatkan prioritas sehingga sistem operasi memberikan lebih banyak waktu kepada proses Konsul untuk bekerja dan mengeksekusi kode mereka. Dalam kasus kami, ini menyelesaikan masalah kami.
- Pilihan lain adalah tidak menggunakan Konsul. Saya punya teman yang merupakan pendukung besar Etcd. Dan kami secara teratur berdebat dengannya mana yang lebih baik Dll atau Konsul. Tetapi dalam hal mana yang lebih baik, kami biasanya setuju dengannya bahwa Konsul memiliki agen yang harus berjalan di setiap node dengan database. Artinya, interaksi Patroni dengan klaster Konsul melalui agen ini. Dan agen ini menjadi hambatan. Jika terjadi sesuatu pada agen, maka Patroni tidak dapat lagi bekerja dengan klaster Konsul. Dan inilah masalahnya. Tidak ada agen dalam paket Etcd. Patroni dapat bekerja langsung dengan daftar server Etcd dan sudah berkomunikasi dengan mereka. Dalam hal ini, jika Anda menggunakan Etcd di perusahaan Anda, Etcd mungkin akan menjadi pilihan yang lebih baik daripada Konsul. Tetapi kami di pelanggan kami selalu dibatasi oleh apa yang telah dipilih dan digunakan klien. Dan kami memiliki Konsul sebagian besar untuk semua klien.
- Dan poin terakhir adalah merevisi nilai parameter. Kami dapat menaikkan parameter ini dengan harapan masalah jaringan jangka pendek kami akan singkat dan tidak berada di luar jangkauan parameter ini. Dengan cara ini kami dapat mengurangi agresivitas Patroni untuk melakukan autofile jika terjadi beberapa masalah jaringan.
Saya pikir banyak yang menggunakan Patroni sudah familiar dengan perintah ini.
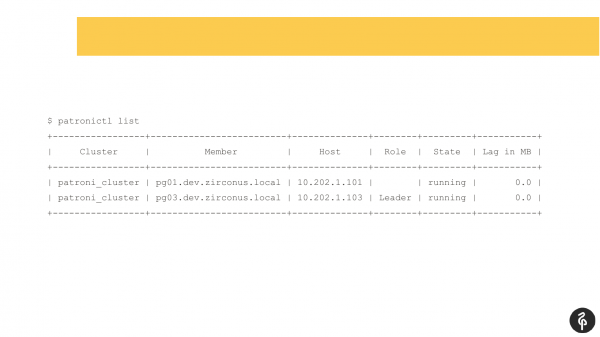
Perintah ini menunjukkan status cluster saat ini. Dan sekilas, gambaran ini mungkin tampak biasa saja. Kami memiliki master, kami memiliki replika, tidak ada jeda replikasi. Tapi gambar ini normal sampai kita tahu bahwa cluster ini harus memiliki tiga node, bukan dua.

Karenanya, ada file otomatis. Dan setelah file otomatis ini, replika kami menghilang. Kita perlu mencari tahu mengapa dia menghilang dan membawanya kembali, memulihkannya. Dan kami kembali ke log dan melihat mengapa kami memiliki fileover otomatis.

Dalam hal ini, replika kedua menjadi masternya. Tidak apa-apa di sini.

Dan kita perlu melihat replika yang jatuh dan yang tidak ada di cluster. Kami membuka log Patroni dan melihat bahwa kami mengalami masalah selama proses menghubungkan ke cluster pada tahap pg_rewind. Untuk terhubung ke cluster, Anda perlu memundurkan log transaksi, meminta log transaksi yang diperlukan dari master, dan menggunakannya untuk mengejar master.
Dalam hal ini, kami tidak memiliki log transaksi dan replika tidak dapat dimulai. Karenanya, kami menghentikan Postgres dengan kesalahan. Dan karena itu tidak ada di cluster.

Kami perlu memahami mengapa itu tidak ada di kluster dan mengapa tidak ada log. Kami pergi ke master baru dan melihat apa yang dia miliki di log. Ternyata saat pg_rewind selesai, terjadi checkpoint. Dan beberapa log transaksi lama hanya diganti namanya. Ketika master lama mencoba menyambung ke master baru dan menanyakan log ini, mereka sudah diganti namanya, hanya saja tidak ada.

Saya membandingkan stempel waktu saat peristiwa ini terjadi. Dan di sana perbedaannya adalah 150 milidetik, yaitu, pos pemeriksaan selesai dalam 369 milidetik, segmen WAL diganti namanya. Dan secara harfiah pada 517, setelah 150 milidetik, replika lama mulai memutar ulang. Artinya, secara harfiah 150 milidetik sudah cukup bagi kami sehingga replika tidak dapat terhubung dan menghasilkan uang.

Apa saja pilihannya?
Kami awalnya menggunakan slot replikasi. Kami pikir itu bagus. Meskipun pada tahap pertama operasi kami mematikan slotnya. Tampaknya bagi kami jika slot mengumpulkan banyak segmen WAL, kami dapat menjatuhkan masternya. Dia akan jatuh. Kami menderita selama beberapa waktu tanpa slot. Dan kami menyadari bahwa kami membutuhkan slot, kami mengembalikan slotnya.
Tapi ada masalah di sini, ketika master pergi ke replika, itu menghapus slot dan menghapus segmen WAL bersama dengan slotnya. Dan untuk mengatasi masalah ini, kami memutuskan untuk menaikkan parameter wal_keep_segments. Standarnya adalah 8 segmen. Kami menaikkannya menjadi 1 dan melihat berapa banyak ruang kosong yang kami miliki. Dan kami menyumbangkan 000 gigabyte untuk wal_keep_segments. Artinya, saat beralih, kami selalu memiliki cadangan 16 gigabyte log transaksi di semua node.
Dan plus - masih relevan untuk tugas pemeliharaan jangka panjang. Katakanlah kita perlu memperbarui salah satu replika. Dan kami ingin mematikannya. Kami perlu memperbarui perangkat lunak, mungkin sistem operasi, sesuatu yang lain. Dan saat kami mematikan replika, slot untuk replika itu juga dihapus. Dan jika kita menggunakan wal_keep_segments kecil, maka dengan tidak adanya replika yang lama, log transaksi akan hilang. Kami akan membuat replika, itu akan meminta log transaksi tersebut di mana ia berhenti, tetapi mungkin tidak ada di master. Dan replika juga tidak akan bisa terhubung. Oleh karena itu, kami menyimpan stok majalah dalam jumlah besar.

Kami memiliki basis produksi. Sudah ada proyek yang sedang berjalan.
Ada filer. Kami masuk dan melihat - semuanya beres, replika sudah terpasang, tidak ada jeda replikasi. Tidak ada kesalahan di log juga, semuanya beres.
Tim produk mengatakan bahwa seharusnya ada beberapa data, tetapi kami melihatnya dari satu sumber, tetapi kami tidak melihatnya di database. Dan kita perlu memahami apa yang terjadi pada mereka.

Jelas bahwa pg_rewind merindukan mereka. Kami segera memahami ini, tetapi pergi untuk melihat apa yang terjadi.

Di log, kita selalu dapat menemukan kapan filer terjadi, siapa yang menjadi master, dan kita dapat menentukan siapa master lama dan kapan dia ingin menjadi replika, yaitu kita memerlukan log ini untuk mengetahui jumlah log transaksi yang Sudah hilang.
Tuan lama kita telah melakukan boot ulang. Dan Patroni terdaftar di autorun. Meluncurkan Patroni. Dia kemudian memulai Postgres. Lebih tepatnya, sebelum memulai Postgres dan sebelum membuatnya menjadi replika, Patroni meluncurkan proses pg_rewind. Oleh karena itu, dia menghapus sebagian dari log transaksi, mengunduh yang baru, dan terhubung. Di sini Patroni bekerja dengan cerdas, seperti yang diharapkan. Cluster telah dipulihkan. Kami memiliki 3 node, setelah filer 3 node - semuanya keren.

Kami telah kehilangan beberapa data. Dan kita perlu memahami seberapa banyak kita telah kehilangan. Kami mencari momen ketika kami mundur. Kita dapat menemukannya di entri jurnal tersebut. Rewind dimulai, melakukan sesuatu di sana dan berakhir.

Kita perlu menemukan posisi di log transaksi tempat master lama tinggalkan. Dalam hal ini, ini adalah tandanya. Dan kita membutuhkan tanda kedua, yaitu jarak yang membedakan master lama dari yang baru.
Kami mengambil pg_wal_lsn_diff biasa dan membandingkan kedua tanda ini. Dan dalam hal ini, kami mendapatkan 17 megabita. Banyak atau sedikit, semua orang memutuskan sendiri. Karena bagi seseorang 17 megabyte tidak banyak, bagi seseorang itu banyak dan tidak dapat diterima. Di sini, setiap individu menentukan sendiri sesuai dengan kebutuhan bisnisnya.

Tapi apa yang telah kita temukan sendiri?
Pertama, kita harus memutuskan sendiri - apakah kita selalu membutuhkan Patroni untuk melakukan autostart setelah reboot sistem? Seringkali kita harus pergi ke tuan tua, melihat seberapa jauh dia pergi. Mungkin memeriksa segmen log transaksi, lihat apa yang ada di sana. Dan untuk memahami apakah kami dapat kehilangan data ini atau apakah kami perlu menjalankan master lama dalam mode mandiri untuk mengeluarkan data ini.
Dan hanya setelah itu kita harus memutuskan apakah kita dapat membuang data ini atau memulihkannya, menghubungkan node ini sebagai replika ke cluster kita.
Selain itu, ada parameter "maximum_lag_on_failover". Secara default, jika ingatanku baik, parameter ini memiliki nilai 1 megabyte.
Bagaimana dia bekerja? Jika replika kita tertinggal 1 megabyte data dalam jeda replikasi, maka replika ini tidak mengikuti pemilihan. Dan jika tiba-tiba ada fileover, Patroni melihat replika mana yang tertinggal. Jika mereka tertinggal oleh sejumlah besar log transaksi, mereka tidak bisa menjadi master. Ini adalah fitur keamanan yang sangat bagus yang mencegah Anda kehilangan banyak data.
Tetapi ada masalah bahwa kelambatan replikasi di cluster Patroni dan DCS diperbarui pada interval tertentu. Saya pikir 30 detik adalah nilai default ttl.
Oleh karena itu, mungkin ada situasi di mana ada satu kelambatan replikasi untuk replika di DCS, tetapi sebenarnya mungkin ada kelambatan yang sama sekali berbeda atau mungkin tidak ada kelambatan sama sekali, yaitu hal ini tidak realtime. Dan itu tidak selalu mencerminkan gambaran sebenarnya. Dan tidak ada gunanya melakukan logika mewah di atasnya.
Dan risiko kerugian selalu ada. Dan dalam kasus terburuk, satu rumus, dan dalam kasus rata-rata, rumus lain. Artinya, ketika kita merencanakan implementasi Patroni dan mengevaluasi berapa banyak data yang bisa hilang, kita harus mengandalkan rumus ini dan membayangkan secara kasar berapa banyak data yang bisa hilang.
Dan ada kabar baik. Ketika master lama telah melanjutkan, dia dapat melanjutkan karena beberapa proses latar belakang. Artinya, ada semacam autovacuum, dia menulis datanya, menyimpannya ke log transaksi. Dan kita dapat dengan mudah mengabaikan dan kehilangan data ini. Tidak ada masalah dalam hal ini.

Dan ini adalah tampilan log jika maximum_lag_on_failover disetel dan filer telah terjadi, dan Anda perlu memilih master baru. Replika menilai dirinya tidak mampu mengikuti pemilu. Dan dia menolak untuk berpartisipasi dalam perlombaan untuk menjadi pemimpin. Dan dia menunggu master baru dipilih, sehingga dia dapat terhubung dengannya. Ini adalah tindakan tambahan terhadap kehilangan data.

Di sini kami memiliki tim produk yang menulis bahwa produk mereka bermasalah dengan Postgres. Pada saat yang sama, master itu sendiri tidak dapat diakses, karena tidak tersedia melalui SSH. Dan autofile juga tidak terjadi.
Tuan rumah ini terpaksa melakukan reboot. Karena reboot, file otomatis terjadi, meskipun dimungkinkan untuk melakukan file otomatis manual, seperti yang saya mengerti sekarang. Dan setelah reboot, kami akan melihat apa yang kami miliki dengan master saat ini.
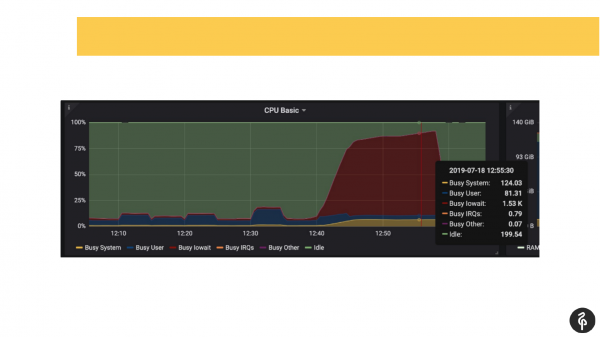
Pada saat yang sama, kami mengetahui sebelumnya bahwa kami memiliki masalah dengan disk, yaitu, kami sudah tahu dari pemantauan ke mana harus menggali dan apa yang harus dicari.

Kami masuk ke log postgres, mulai melihat apa yang terjadi di sana. Kami melihat komit yang bertahan di sana selama satu, dua, tiga detik, yang sama sekali tidak normal. Kami melihat bahwa autovacuum kami mulai dengan sangat lambat dan aneh. Dan kami melihat file sementara di disk. Artinya, ini semua adalah indikator masalah pada disk.

Kami melihat ke dalam sistem dmesg (log kernel). Dan kami melihat bahwa kami memiliki masalah dengan salah satu disk. Subsistem disk adalah perangkat lunak Raid. Kami melihat /proc/mdstat dan melihat bahwa kami kehilangan satu drive. Artinya, ada Raid 8 disk, kami kehilangan satu. Jika Anda hati-hati melihat slide, maka pada output Anda dapat melihat bahwa kami tidak memiliki sde di sana. Pada kami, secara kondisional, disk telah putus. Ini memicu masalah disk, dan aplikasi juga mengalami masalah saat bekerja dengan cluster Postgres.

Dan dalam hal ini, Patroni tidak akan membantu kami dengan cara apa pun, karena Patroni tidak memiliki tugas untuk memantau status server, status disk. Dan kita harus memantau situasi seperti itu dengan pemantauan eksternal. Kami dengan cepat menambahkan pemantauan disk ke pemantauan eksternal.
Dan ada pemikiran seperti itu - dapatkah perangkat lunak pagar atau pengawas membantu kita? Kami pikir dia tidak akan membantu kami dalam kasus ini, karena selama masalah Patroni terus berinteraksi dengan cluster DCS dan tidak melihat adanya masalah. Artinya, dari sudut pandang DCS dan Patroni, semuanya baik-baik saja dengan cluster tersebut, meskipun sebenarnya ada masalah dengan disk, ada masalah dengan ketersediaan database.
Menurut saya, ini adalah salah satu masalah teraneh yang telah saya teliti sejak lama, saya telah membaca banyak log, mengambil kembali dan menyebutnya sebagai simulator cluster.

Masalahnya adalah master lama tidak bisa menjadi replika normal, mis. Patroni memulainya, Patroni menunjukkan bahwa node ini hadir sebagai replika, tetapi pada saat yang sama itu bukan replika normal. Sekarang Anda akan melihat alasannya. Inilah yang saya simpan dari analisis masalah itu.

Dan bagaimana semuanya dimulai? Itu dimulai, seperti pada masalah sebelumnya, dengan rem cakram. Kami memiliki komitmen untuk satu detik, dua.

Ada pemutusan koneksi, mis., Klien terputus.

Ada penyumbatan dengan berbagai tingkat keparahan.

Dan, karenanya, subsistem disk tidak terlalu responsif.

Dan hal yang paling misterius bagi saya adalah permintaan penghentian segera yang tiba. Postgres memiliki tiga mode shutdown:
- Sangat anggun saat kami menunggu semua klien memutuskan sambungan sendiri.
- Ada yang cepat ketika kita memaksa client untuk disconnect karena kita akan shutdown.
- Dan segera. Dalam hal ini, bahkan langsung tidak memberitahu klien untuk mematikan, itu hanya mati tanpa peringatan. Dan untuk semua klien, sistem operasi telah mengirimkan pesan RST (pesan TCP bahwa koneksi terputus dan klien tidak memiliki apa-apa lagi untuk ditangkap).
Siapa yang mengirim sinyal ini? Proses latar belakang Postgres tidak mengirimkan sinyal seperti itu satu sama lain, yaitu ini adalah kill-9. Mereka tidak mengirim hal-hal seperti itu satu sama lain, mereka hanya bereaksi terhadap hal-hal seperti itu, mis. ini adalah restart darurat Postgres. Siapa pengirimnya, saya tidak tahu.
Saya melihat perintah "terakhir" dan saya melihat satu orang yang juga masuk ke server ini bersama kami, tetapi saya terlalu malu untuk bertanya. Mungkin itu adalah kill -9. Saya akan melihat kill -9 di log, karena Postgres mengatakan butuh kill -9, tapi saya tidak melihatnya di log.

Melihat lebih jauh, saya melihat bahwa Patroni tidak menulis ke log untuk waktu yang cukup lama - 54 detik. Dan jika kita membandingkan dua stempel waktu, tidak ada pesan selama sekitar 54 detik.
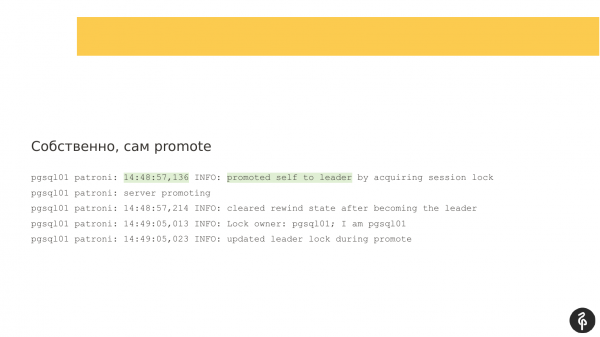
Dan selama ini ada autofile. Patroni melakukan pekerjaan dengan baik di sini lagi. Tuan lama kami tidak ada, sesuatu terjadi padanya. Dan pemilihan master baru dimulai. Semuanya bekerja dengan baik di sini. pgsql01 kami telah menjadi pemimpin baru.

Kami memiliki replika yang telah menjadi master. Dan ada tanggapan kedua. Dan ada masalah dengan replika kedua. Dia mencoba mengkonfigurasi ulang. Seperti yang saya pahami, dia mencoba mengubah recovery.conf, restart Postgres dan sambungkan ke master baru. Dia menulis pesan setiap 10 detik yang dia coba, tetapi dia tidak berhasil.

Dan selama upaya ini, sinyal shutdown segera tiba di master lama. Master dimulai ulang. Dan juga pemulihan berhenti karena master lama masuk ke reboot. Artinya, replika tidak dapat terhubung dengannya, karena sedang dalam mode mati.

Pada titik tertentu, itu berhasil, tetapi replikasi tidak dimulai.
Satu-satunya dugaan saya adalah ada alamat master lama di recovery.conf. Dan saat master baru muncul, replika kedua masih mencoba menyambung ke master lama.
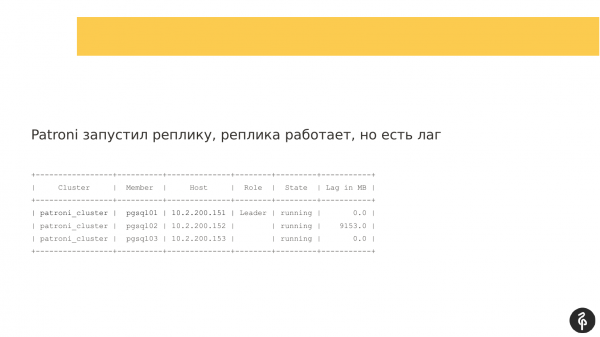
Ketika Patroni memulai replika kedua, node mulai tetapi tidak dapat mereplikasi. Dan jeda replikasi terbentuk, yang terlihat seperti ini. Artinya, ketiga node ada di tempatnya, tetapi node kedua tertinggal.
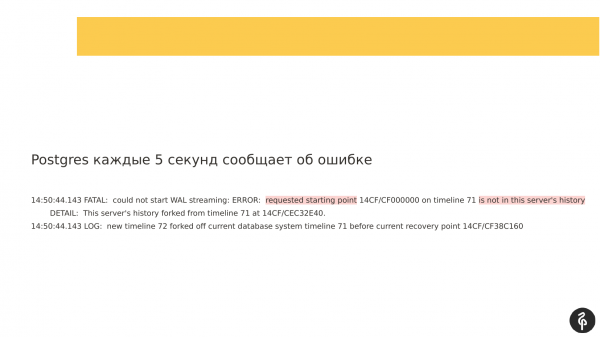
Pada saat yang sama, jika Anda melihat log yang ditulis, Anda dapat melihat bahwa replikasi tidak dapat dimulai karena log transaksi berbeda. Dan log transaksi yang ditawarkan master, yang ditentukan dalam recovery.conf, sama sekali tidak sesuai dengan node kami saat ini.

Dan di sini saya membuat kesalahan. Saya harus datang dan melihat apa yang ada di recovery.conf untuk menguji hipotesis saya bahwa kami terhubung ke master yang salah. Tetapi kemudian saya hanya berurusan dengan ini dan itu tidak terpikir oleh saya, atau saya melihat replika itu tertinggal dan harus diisi ulang, yaitu, entah bagaimana saya bekerja dengan sembarangan. Ini adalah sendi saya.

Setelah 30 menit, admin sudah datang yaitu saya me-restart Patroni di replika. Saya sudah mengakhirinya, saya pikir itu harus diisi ulang. Dan saya pikir - saya akan memulai kembali Patroni, mungkin sesuatu yang baik akan terjadi. Pemulihan dimulai. Dan pangkalan itu bahkan terbuka, siap menerima koneksi.
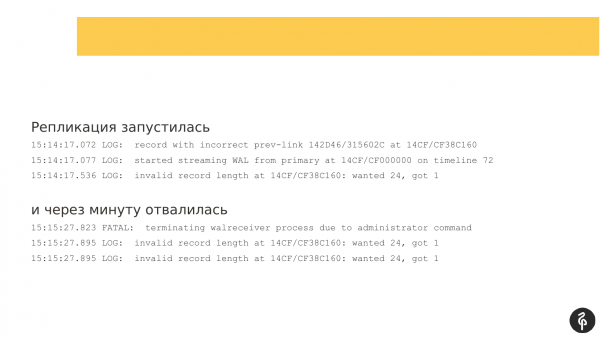
Replikasi telah dimulai. Tapi semenit kemudian, dia jatuh dengan kesalahan bahwa log transaksi tidak cocok untuknya.

Saya pikir saya akan memulai kembali. Saya me-restart Patroni lagi, dan saya tidak me-restart Postgres, tetapi me-restart Patroni dengan harapan secara ajaib akan memulai database.

Replikasi dimulai lagi, tetapi tanda di log transaksi berbeda, tidak sama dengan upaya awal sebelumnya. Replikasi berhenti lagi. Dan pesannya sudah sedikit berbeda. Dan itu tidak terlalu informatif bagi saya.

Dan kemudian terpikir oleh saya - bagaimana jika saya memulai kembali Postgres, saat ini saya membuat pos pemeriksaan pada master saat ini untuk memindahkan titik di log transaksi sedikit ke depan sehingga pemulihan dimulai dari saat lain? Plus, kami masih memiliki stok WAL.

Saya memulai ulang Patroni, melakukan beberapa pos pemeriksaan pada master, beberapa titik mulai ulang pada replika saat dibuka. Dan itu membantu. Saya berpikir lama mengapa itu membantu dan bagaimana cara kerjanya. Dan replika dimulai. Dan replikasi tidak lagi robek.

Masalah seperti itu bagi saya adalah salah satu yang lebih misterius, di mana saya masih memikirkan apa yang sebenarnya terjadi di sana.
Apa implikasinya di sini? Patroni dapat berfungsi sebagaimana mestinya dan tanpa kesalahan. Tetapi pada saat yang sama, ini bukanlah jaminan 100% bahwa semuanya baik-baik saja dengan kami. Replika dapat dimulai, tetapi mungkin dalam keadaan semi-berfungsi, dan aplikasi tidak dapat bekerja dengan replika tersebut, karena akan ada data lama.
Dan setelah filer, Anda selalu perlu memeriksa apakah semuanya beres dengan cluster, yaitu, ada jumlah replika yang diperlukan, tidak ada jeda replikasi.
Dan saat kita membahas masalah ini, saya akan membuat rekomendasi. Saya mencoba menggabungkannya menjadi dua slide. Mungkin semua cerita bisa digabungkan menjadi dua slide dan hanya diceritakan.

Saat Anda menggunakan Patroni, Anda harus memiliki pemantauan. Anda harus selalu tahu kapan autofileover terjadi, karena jika Anda tidak tahu Anda memiliki autofileover, Anda tidak memiliki kendali atas cluster. Dan itu buruk.
Setelah setiap filer, kami harus selalu memeriksa cluster secara manual. Kami perlu memastikan bahwa kami selalu memiliki jumlah replika yang terbaru, tidak ada jeda replikasi, tidak ada kesalahan dalam log yang terkait dengan replikasi streaming, dengan Patroni, dengan sistem DCS.
Otomasi dapat bekerja dengan sukses, Patroni adalah alat yang sangat bagus. Ini bisa berfungsi, tetapi ini tidak akan membawa cluster ke kondisi yang diinginkan. Dan jika kita tidak mengetahuinya, kita akan mendapat masalah.
Dan Patroni bukanlah peluru perak. Kita masih perlu memahami bagaimana Postgres bekerja, bagaimana replikasi bekerja dan bagaimana Patroni bekerja dengan Postgres, dan bagaimana komunikasi antar node disediakan. Ini diperlukan agar dapat memperbaiki masalah dengan tangan Anda.

Bagaimana saya mendekati masalah diagnosis? Kebetulan kami bekerja dengan klien yang berbeda dan tidak ada yang memiliki tumpukan ELK, dan kami harus memilah log dengan membuka 6 konsol dan 2 tab. Di satu tab, ini adalah log Patroni untuk setiap node, di tab lain, ini adalah log Konsul, atau Postgres jika perlu. Sangat sulit untuk mendiagnosis ini.
Pendekatan apa yang telah saya kembangkan? Pertama, saya selalu melihat ketika filer telah tiba. Dan bagi saya ini adalah daerah aliran sungai. Saya melihat apa yang terjadi sebelum filer, selama filer dan setelah filer. Fileover memiliki dua tanda: ini adalah waktu mulai dan berakhir.
Selanjutnya, saya mencari di log untuk peristiwa sebelum filer, yang mendahului filer, mis. Saya mencari alasan mengapa filer terjadi.
Dan ini memberi gambaran pemahaman apa yang terjadi dan apa yang bisa dilakukan di masa depan agar keadaan seperti itu tidak terjadi (dan akibatnya tidak ada filer).
Dan di mana kita biasanya mencari? Saya melihat:
- Pertama, ke log Patroni.
- Selanjutnya, saya melihat log Postgres, atau log DCS, tergantung pada apa yang ditemukan di log Patroni.
- Dan log sistem juga terkadang memberikan pemahaman tentang apa yang menyebabkan filer.

Bagaimana perasaan saya tentang Patroni? Saya memiliki hubungan yang sangat baik dengan Patroni. Menurut pendapat saya, ini adalah yang terbaik yang ada saat ini. Saya tahu banyak produk lain. Ini adalah Stolon, Repmgr, Pg_auto_failover, PAF. 4 alat. Saya mencoba semuanya. Patroni adalah favorit saya.
Jika mereka bertanya kepada saya: "Apakah saya merekomendasikan Patroni?". Saya akan mengatakan ya, karena saya suka Patroni. Dan saya pikir saya belajar cara memasaknya.
Jika Anda tertarik untuk melihat masalah lain apa yang ada pada Patroni selain masalah yang telah saya sebutkan, Anda selalu dapat melihat halamannya di GitHub. Ada banyak cerita berbeda dan banyak masalah menarik yang dibahas di sana. Dan sebagai hasilnya, beberapa bug diperkenalkan dan diselesaikan, yaitu bacaan yang menarik.
Ada beberapa cerita menarik tentang orang yang menembak dirinya sendiri di kaki. Sangat informatif. Anda membaca dan memahami bahwa tidak perlu melakukannya. Saya menandai diri saya sendiri.
Dan saya ingin mengucapkan terima kasih yang sebesar-besarnya kepada Zalando karena telah mengembangkan proyek ini, yaitu kepada Alexander Kukushkin dan Alexey Klyukin. Aleksey Klyukin adalah salah satu penulis bersama, dia tidak lagi bekerja di Zalando, tetapi ini adalah dua orang yang mulai mengerjakan produk ini.
Dan menurut saya Patroni adalah hal yang sangat keren. Saya senang dia ada, itu menarik dengannya. Dan terima kasih banyak untuk semua kontributor yang menulis tambalan ke Patroni. Saya berharap Patroni menjadi lebih dewasa, keren, dan efisien seiring bertambahnya usia. Ini sudah berfungsi, tapi saya harap ini akan menjadi lebih baik. Karena itu, jika Anda berencana menggunakan Patroni, jangan takut. Ini adalah solusi yang bagus, dapat diimplementasikan dan digunakan.
Itu saja. Jika Anda memiliki pertanyaan, tanyakan.

pertanyaan
Terima kasih atas laporannya! Jika setelah pengarsipan Anda masih perlu melihat ke sana dengan sangat hati-hati, lalu mengapa kami memerlukan pengarsipan otomatis?
Karena itu barang baru. Kami baru setahun bersamanya. Lebih baik aman. Kami ingin masuk dan melihat bahwa semuanya benar-benar berjalan sebagaimana mestinya. Ini adalah tingkat ketidakpercayaan orang dewasa - lebih baik periksa ulang dan lihat.
Misalnya, kami pergi di pagi hari dan melihat, bukan?
Tidak di pagi hari, kami biasanya langsung mengetahui tentang autofile. Kami menerima pemberitahuan, kami melihat bahwa autofile telah terjadi. Kami segera pergi dan melihat. Tetapi semua pemeriksaan ini harus dibawa ke tingkat pemantauan. Jika Anda mengakses Patroni melalui REST API, ada riwayatnya. Secara riwayat, Anda dapat melihat stempel waktu saat filer terjadi. Berdasarkan hal tersebut, pemantauan dapat dilakukan. Anda dapat melihat sejarahnya, berapa banyak peristiwa yang terjadi. Jika kami memiliki lebih banyak acara, maka file otomatis telah terjadi. Anda bisa pergi dan melihat. Atau otomatisasi pemantauan kami memeriksa apakah kami memiliki semua replika, tidak ada lag dan semuanya baik-baik saja.
Terima kasih!
Terima kasih banyak atas ceritanya yang luar biasa! Jika kita memindahkan klaster DCS ke suatu tempat yang jauh dari klaster Postgres, maka klaster ini juga perlu diservis secara berkala? Apa praktik terbaik yang perlu dimatikan beberapa bagian dari cluster DCS, sesuatu yang harus dilakukan dengannya, dll.? Bagaimana seluruh struktur ini bertahan? Dan bagaimana Anda melakukan hal-hal ini?
Untuk satu perusahaan, perlu dibuat matriks masalah, apa yang terjadi jika salah satu komponen atau beberapa komponen gagal. Menurut matriks ini, kami menelusuri semua komponen secara berurutan dan membangun skenario jika terjadi kegagalan komponen ini. Dengan demikian, untuk setiap skenario kegagalan, Anda dapat memiliki rencana tindakan untuk pemulihan. Dan dalam kasus DCS, ini hadir sebagai bagian dari infrastruktur standar. Dan admin yang mengelolanya, dan kami sudah mengandalkan admin yang mengelolanya dan kemampuan mereka untuk memperbaikinya jika terjadi kecelakaan. Jika tidak ada DCS sama sekali, maka kami menerapkannya, tetapi pada saat yang sama kami tidak memantaunya secara khusus, karena kami tidak bertanggung jawab atas infrastruktur, tetapi kami memberikan rekomendasi tentang bagaimana dan apa yang harus dipantau.
Yaitu, apakah saya mengerti dengan benar bahwa saya perlu menonaktifkan Patroni, menonaktifkan filer, menonaktifkan semuanya sebelum melakukan sesuatu dengan host?
Itu tergantung pada berapa banyak node yang kita miliki di cluster DCS. Jika ada banyak node dan jika kita menonaktifkan hanya satu node (replika), maka cluster mempertahankan kuorum. Dan Patroni tetap beroperasi. Dan tidak ada yang dipicu. Jika kami memiliki beberapa operasi kompleks yang memengaruhi lebih banyak node, yang ketiadaannya dapat merusak kuorum, maka - ya, mungkin masuk akal untuk menghentikan sementara Patroni. Ini memiliki perintah yang sesuai - patronictl pause, patronictl resume. Kami hanya menjeda dan autofiler tidak berfungsi saat itu. Kami melakukan pemeliharaan pada klaster DCS, lalu kami melepas jeda dan melanjutkan hidup.
Спасибо большое!
Terima kasih banyak atas laporan Anda! Bagaimana perasaan tim produk tentang hilangnya data?
Tim produk tidak peduli, dan pimpinan tim khawatir.
Jaminan apa yang ada?
Jaminan sangat sulit. Alexander Kukushkin memiliki laporan "Cara menghitung RPO dan RTO", yaitu waktu pemulihan dan berapa banyak data yang bisa hilang. Saya pikir kita perlu menemukan slide ini dan mempelajarinya. Seingat saya, ada langkah-langkah khusus tentang cara menghitung hal-hal ini. Berapa banyak transaksi yang bisa kita hilangkan, berapa banyak data yang bisa kita hilangkan. Sebagai opsi, kita dapat menggunakan replikasi sinkron pada level Patroni, tetapi ini adalah pedang bermata dua: kita memiliki keandalan data, atau kita kehilangan kecepatan. Ada replikasi sinkron, tetapi juga tidak menjamin perlindungan 100% terhadap kehilangan data.
Alexey, terima kasih atas laporannya yang bagus! Adakah pengalaman menggunakan Patroni untuk perlindungan level nol? Artinya, bersamaan dengan standby sinkron? Ini adalah pertanyaan pertama. Dan pertanyaan kedua. Anda telah menggunakan solusi yang berbeda. Kami menggunakan Repmgr, tetapi tanpa autofiler, dan sekarang kami berencana untuk menyertakan autofiler. Dan kami menganggap Patroni sebagai solusi alternatif. Apa yang bisa Anda katakan sebagai keunggulan dibandingkan dengan Repmgr?
Pertanyaan pertama adalah tentang replika sinkron. Tidak ada yang menggunakan replikasi sinkron di sini, karena semua orang takut (Beberapa klien sudah menggunakannya, pada prinsipnya, mereka tidak melihat masalah kinerja - Catatan pembicara). Tetapi kami telah mengembangkan aturan untuk diri kami sendiri bahwa setidaknya harus ada tiga node dalam kluster replikasi sinkron, karena jika kami memiliki dua node dan jika master atau replika gagal, maka Patroni mengalihkan node ini ke mode Standalone sehingga aplikasi terus berjalan. bekerja. Dalam hal ini, ada risiko kehilangan data.
Mengenai pertanyaan kedua, kami telah menggunakan Repmgr dan masih melakukannya dengan beberapa klien karena alasan historis. Apa yang bisa dikatakan? Patroni hadir dengan autofiler di luar kotak, Repmgr hadir dengan autofiler sebagai fitur tambahan yang perlu diaktifkan. Kita perlu menjalankan daemon Repmgr pada setiap node dan kemudian kita dapat mengonfigurasi autofiler.
Repmgr memeriksa apakah node Postgres masih hidup. Proses Repmgr memeriksa keberadaan satu sama lain, ini bukan pendekatan yang sangat efisien. mungkin ada kasus isolasi jaringan yang kompleks di mana cluster Repmgr yang besar dapat terpecah menjadi beberapa yang lebih kecil dan terus bekerja. Saya sudah lama tidak mengikuti Repmgr, mungkin sudah diperbaiki ... atau mungkin belum. Tetapi penghapusan informasi tentang status cluster di DCS, seperti yang dilakukan Stolon, Patroni, adalah opsi yang paling memungkinkan.
Alexey, saya punya pertanyaan, mungkin yang lamer. Dalam salah satu contoh pertama, Anda memindahkan DCS dari mesin lokal ke host jarak jauh. Kami memahami bahwa jaringan adalah sesuatu yang memiliki karakteristiknya sendiri, ia hidup dengan sendirinya. Dan apa yang terjadi jika karena alasan tertentu cluster DCS menjadi tidak tersedia? Saya tidak akan menyebutkan alasannya, bisa banyak alasannya: dari tangan bengkok para penggiat jejaring hingga masalah nyata.
Saya tidak mengatakannya dengan lantang, tetapi cluster DCS juga harus failover, yaitu jumlah node yang ganjil, agar kuorum terpenuhi. Apa yang terjadi jika klaster DCS menjadi tidak tersedia, atau kuorum tidak dapat dipenuhi, yaitu semacam pemisahan jaringan atau kegagalan node? Dalam hal ini, cluster Patroni beralih ke mode hanya baca. Cluster Patroni tidak dapat menentukan status cluster dan apa yang harus dilakukan. Itu tidak dapat menghubungi DCS dan menyimpan status klaster baru di sana, sehingga seluruh klaster menjadi hanya baca. Dan menunggu intervensi manual dari operator atau DCS untuk pulih.
Secara kasar, DCS menjadi layanan bagi kami sama pentingnya dengan pangkalan itu sendiri?
Ya ya. Di banyak perusahaan modern, Service Discovery merupakan bagian integral dari infrastruktur. Itu sedang diterapkan bahkan sebelum ada database di infrastruktur. Secara relatif, infrastruktur diluncurkan, diterapkan di DC, dan kami segera memiliki Penemuan Layanan. Jika itu Konsul, maka DNS dapat dibangun di atasnya. Jika ini Etcd, maka mungkin ada bagian dari kluster Kubernetes, di mana yang lainnya akan diterapkan. Menurut saya, Service Discovery sudah menjadi bagian integral dari infrastruktur modern. Dan mereka memikirkannya jauh lebih awal daripada tentang database.
Terima kasih!
Sumber: www.habr.com
