

pengenalan
Saat menerapkan sistem lain, kami dihadapkan pada kebutuhan untuk memproses log berbeda dalam jumlah besar. ELK dipilih sebagai alatnya. Artikel ini akan membahas pengalaman kami dalam menyiapkan tumpukan ini.
Kami tidak menetapkan tujuan untuk menggambarkan semua kemampuannya, tetapi kami ingin berkonsentrasi secara khusus pada pemecahan masalah-masalah praktis. Hal ini disebabkan meskipun terdapat cukup banyak dokumentasi dan gambar yang sudah jadi, terdapat cukup banyak jebakan, setidaknya kami menemukannya.
Kami menyebarkan tumpukan melalui docker-compose. Selain itu, kami memiliki docker-compose.yml yang ditulis dengan baik, yang memungkinkan kami meningkatkan tumpukan hampir tanpa masalah. Dan bagi kami tampaknya kemenangan sudah dekat, sekarang kami akan mengubahnya sedikit agar sesuai dengan kebutuhan kami dan hanya itu.
Sayangnya, upaya untuk mengkonfigurasi sistem untuk menerima dan memproses log dari aplikasi kami tidak berhasil. Oleh karena itu, kami memutuskan bahwa ada baiknya mempelajari setiap komponen secara terpisah, dan kemudian kembali ke hubungannya.
Jadi, kami mulai dengan logstash.
Lingkungan, penerapan, menjalankan Logstash dalam sebuah kontainer
Untuk penerapan, kami menggunakan docker-compose, eksperimen yang dijelaskan di sini dilakukan pada MacOS dan Ubuntu 18.0.4.
Gambar logstash yang terdaftar di docker-compose.yml asli kami adalah docker.elastic.co/logstash/logstash:6.3.2
Kami akan menggunakannya untuk eksperimen.
Kami menulis docker-compose.yml terpisah untuk menjalankan logstash. Tentu saja, dimungkinkan untuk meluncurkan gambar dari baris perintah, tetapi kami memecahkan masalah tertentu, di mana semuanya diluncurkan dari docker-compose.
Secara singkat tentang file konfigurasi
Sebagai berikut dari uraiannya, logstash dapat dijalankan untuk satu saluran, dalam hal ini ia harus meneruskan file *.conf, atau untuk beberapa saluran, dalam hal ini ia perlu meneruskan file pipelines.yml, yang, pada gilirannya, , akan ditautkan ke file .conf untuk setiap saluran.
Kami mengambil jalur kedua. Bagi kami, hal ini tampak lebih universal dan terukur. Oleh karena itu, kami membuat pipelines.yml, dan membuat direktori pipelines di mana kami akan meletakkan file .conf untuk setiap saluran.
Ada file konfigurasi lain di dalam wadah - logstash.yml. Kami tidak menyentuhnya, kami menggunakannya apa adanya.
Jadi, struktur direktori kami:
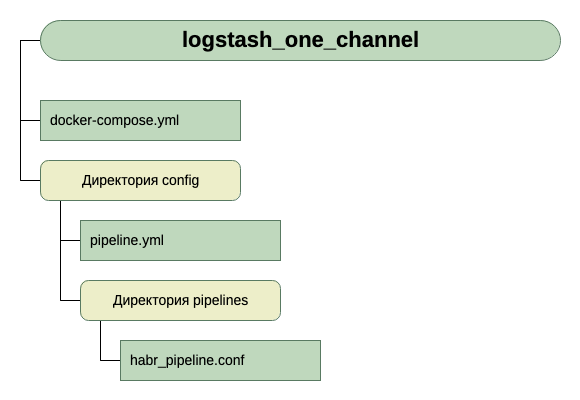
Untuk menerima data input, untuk saat ini kita asumsikan ini adalah tcp pada port 5046, dan untuk output kita akan menggunakan stdout.
Berikut adalah konfigurasi sederhana untuk peluncuran pertama. Karena tugas awalnya adalah meluncurkan.
Jadi, kami memiliki docker-compose.yml ini
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Apa yang kita lihat di sini?
- Jaringan dan volume diambil dari docker-compose.yml asli (tempat seluruh tumpukan diluncurkan) dan menurut saya keduanya tidak terlalu memengaruhi gambaran keseluruhan di sini.
- Kami membuat satu layanan logstash dari gambar docker.elastic.co/logstash/logstash:6.3.2 dan beri nama logstash_one_channel.
- Kami meneruskan port 5046 di dalam container, ke port internal yang sama.
- Kami memetakan file konfigurasi pipa kami ./config/pipelines.yml ke file /usr/share/logstash/config/pipelines.yml di dalam wadah, di mana logstash akan mengambilnya dan menjadikannya hanya-baca, untuk berjaga-jaga.
- Kami memetakan direktori ./config/pipelines, tempat kami memiliki file dengan pengaturan saluran, ke direktori /usr/share/logstash/config/pipelines dan juga menjadikannya hanya-baca.
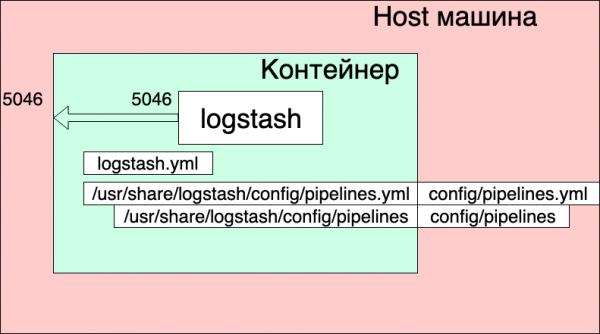
File pipa.yml
- pipeline.id: HABR
pipeline.workers: 1
pipeline.batch.size: 1
path.config: "./config/pipelines/habr_pipeline.conf"
Satu saluran dengan pengidentifikasi HABR dan jalur ke file konfigurasinya dijelaskan di sini.
Dan terakhir file “./config/pipelines/habr_pipeline.conf”
input {
tcp {
port => "5046"
}
}
filter {
mutate {
add_field => [ "habra_field", "Hello Habr" ]
}
}
output {
stdout {
}
}
Mari kita tidak membahas uraiannya untuk saat ini, mari kita coba menjalankannya:
docker-compose up
Apa yang kita lihat
Penampung telah dimulai. Kami dapat memeriksa pengoperasiannya:
echo '13123123123123123123123213123213' | nc localhost 5046
Dan kami melihat responsnya di konsol container:
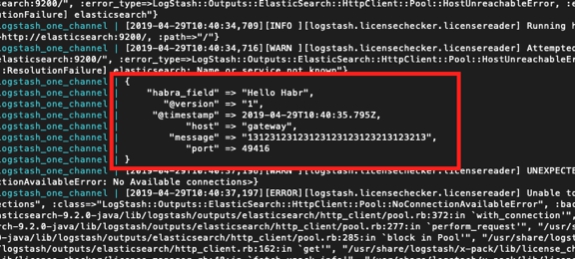
Namun pada saat yang sama, kita juga melihat:
logstash_one_channel | [2019-04-29T11:28:59,790][ERROR][logstash.licensechecker.licensereader] Tidak dapat mengambil informasi lisensi dari server lisensi {:message=>“Elasticsearch Unreachable: [http://elasticsearch:9200/][Manticore ::ResolutionFailure] pencarian elastis", ...
logstash_one_channel | [2019-04-29T11:28:59,894][INFO ][logstash.pipeline ] Pipeline berhasil dimulai {:pipeline_id=>".monitoring-logstash", :thread=>"# "}
logstash_one_channel | [2019-04-29T11:28:59,988][INFO ][logstash.agent ] Saluran pipa berjalan {:count=>2, :running_pipelines=>[:HABR, :".monitoring-logstash"], :non_running_pipelines=>[ ]}
logstash_one_channel | [2019-04-29T11:29:00,015][ERROR][logstash.inputs.metrics] X-Pack diinstal di Logstash tetapi tidak di Elasticsearch. Silakan instal X-Pack di Elasticsearch untuk menggunakan fitur pemantauan. Fitur lain mungkin tersedia.
logstash_one_channel | [2019-04-29T11:29:00,526][INFO ][logstash.agent ] Berhasil memulai titik akhir Logstash API {:port=>9600}
logstash_one_channel | [2019-04-29T11:29:04,478][INFO ][logstash.outputs.elasticsearch] Menjalankan pemeriksaan kesehatan untuk melihat apakah koneksi Elasticsearch berfungsi {:healthcheck_url=>http://elasticsearch:9200/, :path=> "/"}
logstash_one_channel | [2019-04-29T11:29:04,487][PERINGATAN ][logstash.outputs.elasticsearch] Mencoba menghidupkan kembali koneksi ke instance ES yang mati, tetapi mendapat kesalahan. {:url=>“:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>"Elasticsearch Tidak Dapat Dijangkau: [http://elasticsearch:9200/][Manticore::ResolutionFailure] pencarian elastis"}
logstash_one_channel | [2019-04-29T11:29:04,704][INFO ][logstash.licensechecker.licensereader] Menjalankan pemeriksaan kesehatan untuk melihat apakah koneksi Elasticsearch berfungsi {:healthcheck_url=>http://elasticsearch:9200/, :path=> "/"}
logstash_one_channel | [2019-04-29T11:29:04,710][PERINGATAN ][logstash.licensechecker.licensereader] Mencoba menghidupkan kembali koneksi ke instance ES yang mati, tetapi mendapat kesalahan. {:url=>“:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>"Elasticsearch Tidak Dapat Dijangkau: [http://elasticsearch:9200/][Manticore::ResolutionFailure] pencarian elastis"}
Dan log kami terus bertambah setiap saat.
Di sini saya telah menyorot dengan warna hijau pesan bahwa saluran pipa telah berhasil diluncurkan, dengan warna merah pesan kesalahan dan dengan warna kuning pesan tentang upaya untuk menghubungi : 9200.
Hal ini terjadi karena logstash.conf, yang disertakan dalam gambar, berisi pemeriksaan ketersediaan elasticsearch. Bagaimanapun, logstash berasumsi bahwa itu berfungsi sebagai bagian dari tumpukan Elk, tetapi kami memisahkannya.
Dimungkinkan untuk bekerja, tetapi itu tidak nyaman.
Solusinya adalah menonaktifkan pemeriksaan ini melalui variabel lingkungan XPACK_MONITORING_ENABLED.
Mari kita ubah docker-compose.yml dan jalankan lagi:
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
environment:
XPACK_MONITORING_ENABLED: "false"
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Sekarang semuanya baik-baik saja. Wadah siap untuk eksperimen.
Kita bisa mengetik lagi di konsol berikutnya:
echo '13123123123123123123123213123213' | nc localhost 5046
Dan lihat:
logstash_one_channel | {
logstash_one_channel | "message" => "13123123123123123123123213123213",
logstash_one_channel | "@timestamp" => 2019-04-29T11:43:44.582Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "host" => "gateway",
logstash_one_channel | "port" => 49418
logstash_one_channel | }
Bekerja dalam satu saluran
Jadi kami meluncurkannya. Sekarang Anda sebenarnya dapat meluangkan waktu untuk mengonfigurasi logstash itu sendiri. Jangan sentuh file pipelines.yml untuk saat ini, mari kita lihat apa yang bisa kita dapatkan dengan bekerja dengan satu saluran.
Saya harus mengatakan bahwa prinsip umum bekerja dengan file konfigurasi saluran dijelaskan dengan baik dalam manual resmi, di sini
Jika Anda ingin membaca dalam bahasa Rusia, kami menggunakan yang ini (tetapi sintaks kuerinya sudah lama, kita perlu mempertimbangkan hal ini).
Mari kita beralih secara berurutan dari bagian Input. Kami telah melihat pekerjaan di tcp. Apa lagi yang menarik di sini?
Uji pesan menggunakan detak jantung
Ada peluang menarik untuk menghasilkan pesan pengujian otomatis.
Untuk melakukan ini, Anda perlu mengaktifkan plugin heartbean di bagian input.
input {
heartbeat {
message => "HeartBeat!"
}
}
Nyalakan, mulai terima satu menit sekali
logstash_one_channel | {
logstash_one_channel | "@timestamp" => 2019-04-29T13:52:04.567Z,
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "message" => "HeartBeat!",
logstash_one_channel | "@version" => "1",
logstash_one_channel | "host" => "a0667e5c57ec"
logstash_one_channel | }
Jika kita ingin menerima lebih sering, kita perlu menambahkan parameter interval.
Beginilah cara kami menerima pesan setiap 10 detik.
input {
heartbeat {
message => "HeartBeat!"
interval => 10
}
}
Mengambil data dari file
Kami juga memutuskan untuk melihat mode file. Jika berfungsi dengan baik dengan file tersebut, mungkin tidak diperlukan agen, setidaknya untuk penggunaan lokal.
Menurut uraiannya, mode pengoperasiannya harus serupa dengan tail -f, yaitu. membaca baris baru atau, sebagai opsi, membaca seluruh file.
Jadi apa yang ingin kita dapatkan:
- Kami ingin menerima baris yang ditambahkan ke satu file log.
- Kami ingin menerima data yang ditulis ke beberapa file log, sekaligus dapat memisahkan apa yang diterima dari mana.
- Kami ingin memastikan bahwa ketika logstash dimulai ulang, logstash tidak menerima data ini lagi.
- Kami ingin memeriksa apakah logstash dimatikan, dan data terus ditulis ke file, maka ketika kami menjalankannya, kami akan menerima data ini.
Untuk melakukan percobaan, mari tambahkan baris lain ke docker-compose.yml, membuka direktori tempat kita meletakkan file.
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
environment:
XPACK_MONITORING_ENABLED: "false"
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
- ./logs:/usr/share/logstash/input
Dan ubah bagian input di habr_pipeline.conf
input {
file {
path => "/usr/share/logstash/input/*.log"
}
}
Ayo mulai:
docker-compose up
Untuk membuat dan menulis file log kita akan menggunakan perintah:
echo '1' >> logs/number1.log
{
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "@timestamp" => 2019-04-29T14:28:53.876Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "message" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log"
logstash_one_channel | }
Ya, itu berhasil!
Pada saat yang sama, kami melihat bahwa kami telah menambahkan bidang jalur secara otomatis. Artinya di masa mendatang, kami akan dapat memfilter rekaman berdasarkan data tersebut.
Mari coba lagi:
echo '2' >> logs/number1.log
{
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "@timestamp" => 2019-04-29T14:28:59.906Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "message" => "2",
logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log"
logstash_one_channel | }
Dan sekarang ke file lain:
echo '1' >> logs/number2.log
{
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "@timestamp" => 2019-04-29T14:29:26.061Z,
logstash_one_channel | "@version" => "1",
logstash_one_channel | "message" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log"
logstash_one_channel | }
Besar! File telah diambil, jalur telah ditentukan dengan benar, semuanya baik-baik saja.
Hentikan logstash dan mulai lagi. Mari menunggu. Kesunyian. Itu. Kami tidak menerima catatan ini lagi.
Dan sekarang eksperimen paling berani.
Instal logstash dan jalankan:
echo '3' >> logs/number2.log
echo '4' >> logs/number1.log
Jalankan logstash lagi dan lihat:
logstash_one_channel | {
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "message" => "3",
logstash_one_channel | "@version" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log",
logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.589Z
logstash_one_channel | }
logstash_one_channel | {
logstash_one_channel | "host" => "ac2d4e3ef70f",
logstash_one_channel | "habra_field" => "Hello Habr",
logstash_one_channel | "message" => "4",
logstash_one_channel | "@version" => "1",
logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log",
logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.856Z
logstash_one_channel | }
Hore! Semuanya diambil.
Namun kami harus memperingatkan Anda tentang hal berikut. Jika wadah dengan logstash dihapus (docker stop logstash_one_channel && docker rm logstash_one_channel), maka tidak ada yang akan diambil. Posisi file yang dibaca disimpan di dalam wadah. Jika Anda menjalankannya dari awal, itu hanya akan menerima baris baru.
Membaca file yang ada
Katakanlah kita meluncurkan logstash untuk pertama kalinya, tetapi kita sudah memiliki log dan ingin memprosesnya.
Jika kita menjalankan logstash dengan bagian input yang kita gunakan di atas, kita tidak akan mendapatkan apa-apa. Hanya baris baru yang akan diproses oleh logstash.
Agar baris dari file yang ada dapat ditarik, Anda harus menambahkan baris tambahan ke bagian input:
input {
file {
start_position => "beginning"
path => "/usr/share/logstash/input/*.log"
}
}
Selain itu, ada perbedaannya: ini hanya memengaruhi file baru yang belum dilihat logstash. Untuk file yang sama yang sudah terlihat oleh logstash, ia telah mengingat ukurannya dan sekarang hanya akan mengambil entri baru di dalamnya.
Mari kita berhenti di sini dan mempelajari bagian masukan. Masih banyak pilihan, tapi itu cukup bagi kami untuk eksperimen lebih lanjut saat ini.
Perutean dan Transformasi Data
Mari kita coba selesaikan masalah berikut, misalkan kita mendapat pesan dari satu saluran, beberapa di antaranya bersifat informasi, dan ada pula yang merupakan pesan kesalahan. Mereka berbeda berdasarkan tag. Ada yang INFO, ada pula yang ERROR.
Kita perlu memisahkannya di pintu keluar. Itu. Kami menulis pesan informasi di satu saluran, dan pesan kesalahan di saluran lain.
Untuk melakukan ini, berpindah dari bagian masukan ke filter dan keluaran.
Dengan menggunakan bagian filter, kita akan mengurai pesan masuk, mendapatkan hash (pasangan nilai kunci) darinya, yang sudah dapat kita kerjakan, yaitu. bongkar sesuai kondisi. Dan di bagian keluaran, kami akan memilih pesan dan mengirimkan masing-masing pesan ke salurannya sendiri.
Mengurai pesan dengan grok
Untuk mengurai string teks dan mendapatkan sekumpulan bidang darinya, ada plugin khusus di bagian filter - grok.
Tanpa menetapkan tujuan untuk memberikan penjelasan rinci tentangnya di sini (untuk ini saya rujuk ), saya akan memberikan contoh sederhana saya.
Untuk melakukan ini, Anda perlu memutuskan format string input. Saya memilikinya seperti ini:
1 pesan INFO1
2 Pesan KESALAHAN2
Itu. Pengidentifikasi didahulukan, lalu INFO/ERROR, lalu beberapa kata tanpa spasi.
Memang tidak sulit, tapi cukup memahami prinsip pengoperasiannya.
Jadi, di bagian filter pada plugin grok, kita harus mendefinisikan pola untuk mengurai string kita.
Ini akan terlihat seperti ini:
filter {
grok {
match => { "message" => ["%{INT:message_id} %{LOGLEVEL:message_type} %{WORD:message_text}"] }
}
}
Pada dasarnya ini adalah ekspresi reguler. Pola yang sudah jadi digunakan, seperti INT, LOGLEVEL, WORD. Deskripsi mereka, serta pola lainnya, dapat ditemukan di sini
Sekarang, melewati filter ini, string kita akan berubah menjadi hash dari tiga bidang: message_id, message_type, message_text.
Mereka akan ditampilkan di bagian keluaran.
Merutekan pesan ke bagian keluaran menggunakan perintah if
Di bagian keluaran, seingat kami, kami akan membagi pesan menjadi dua aliran. Beberapa - yaitu iNFO, akan dikeluarkan ke konsol, dan jika ada kesalahan, kami akan mengeluarkannya ke file.
Bagaimana kita memisahkan pesan-pesan ini? Kondisi masalah sudah menyarankan solusi - lagi pula, kami sudah memiliki bidang message_type khusus, yang hanya dapat mengambil dua nilai: INFO dan ERROR. Atas dasar inilah kita akan membuat pilihan menggunakan pernyataan if.
if [message_type] == "ERROR" {
# Здесь выводим в файл
} else
{
# Здесь выводим в stdout
}
Penjelasan tentang bekerja dengan bidang dan operator dapat ditemukan di bagian ini .
Sekarang, tentang kesimpulan sebenarnya.
Output konsol, semuanya jelas di sini - stdout {}
Tetapi keluaran ke sebuah file - ingatlah bahwa kita menjalankan semua ini dari sebuah wadah dan agar file tempat kita menulis hasilnya dapat diakses dari luar, kita perlu membuka direktori ini di docker-compose.yml.
Total:
Bagian output dari file kami terlihat seperti ini:
output {
if [message_type] == "ERROR" {
file {
path => "/usr/share/logstash/output/test.log"
codec => line { format => "custom format: %{message}"}
}
} else
{stdout {
}
}
}
Di docker-compose.yml kami menambahkan volume lain untuk keluaran:
version: '3'
networks:
elk:
volumes:
elasticsearch:
driver: local
services:
logstash:
container_name: logstash_one_channel
image: docker.elastic.co/logstash/logstash:6.3.2
networks:
- elk
environment:
XPACK_MONITORING_ENABLED: "false"
ports:
- 5046:5046
volumes:
- ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro
- ./config/pipelines:/usr/share/logstash/config/pipelines:ro
- ./logs:/usr/share/logstash/input
- ./output:/usr/share/logstash/output
Kami meluncurkannya, mencobanya, dan melihat pembagian menjadi dua aliran.
Sumber: www.habr.com
