

Selamat siang. Sudah 2 tahun sejak itu ditulis. tentang parsing Habr, dan beberapa poin telah berubah.
Ketika saya ingin memiliki salinan Habr, saya memutuskan untuk menulis parser yang akan menyimpan semua konten penulis ke database. Bagaimana itu terjadi dan kesalahan apa yang saya temui - Anda dapat membaca di bawah potongan.
TLDR-
Versi pertama dari parser. Satu utas, banyak masalah
Untuk memulainya, saya memutuskan untuk membuat prototipe skrip di mana artikel akan diuraikan dan ditempatkan di database segera setelah diunduh. Tanpa pikir panjang, saya menggunakan sqlite3, karena. itu kurang padat karya: tidak perlu memiliki server lokal, dibuat-tampak-dihapus dan hal-hal seperti itu.
one_thread.py
from bs4 import BeautifulSoup
import sqlite3
import requests
from datetime import datetime
def main(min, max):
conn = sqlite3.connect('habr.db')
c = conn.cursor()
c.execute('PRAGMA encoding = "UTF-8"')
c.execute("CREATE TABLE IF NOT EXISTS habr(id INT, author VARCHAR(255), title VARCHAR(255), content TEXT, tags TEXT)")
start_time = datetime.now()
c.execute("begin")
for i in range(min, max):
url = "https://m.habr.com/post/{}".format(i)
try:
r = requests.get(url)
except:
with open("req_errors.txt") as file:
file.write(i)
continue
if(r.status_code != 200):
print("{} - {}".format(i, r.status_code))
continue
html_doc = r.text
soup = BeautifulSoup(html_doc, 'html.parser')
try:
author = soup.find(class_="tm-user-info__username").get_text()
content = soup.find(id="post-content-body")
content = str(content)
title = soup.find(class_="tm-article-title__text").get_text()
tags = soup.find(class_="tm-article__tags").get_text()
tags = tags[5:]
except:
author,title,tags = "Error", "Error {}".format(r.status_code), "Error"
content = "При парсинге этой странице произошла ошибка."
c.execute('INSERT INTO habr VALUES (?, ?, ?, ?, ?)', (i, author, title, content, tags))
print(i)
c.execute("commit")
print(datetime.now() - start_time)
main(1, 490406)Semuanya klasik - kami menggunakan Beautiful Soup, permintaan, dan prototipe cepat sudah siap. Itu hanya…
Pengunduhan halaman dilakukan dalam satu utas
Jika Anda menghentikan eksekusi skrip, maka seluruh database tidak akan kemana-mana. Lagi pula, komit dilakukan hanya setelah semua penguraian.
Tentu saja, Anda dapat melakukan perubahan ke database setelah setiap penyisipan, tetapi waktu eksekusi skrip akan meningkat secara signifikan.Mengurai 100 artikel pertama membutuhkan waktu 000 jam.
Selanjutnya saya menemukan artikel pengguna , yang saya baca dan menemukan beberapa peretasan kehidupan untuk mempercepat proses ini:
- Menggunakan multithreading terkadang mempercepat pengunduhan.
- Anda tidak bisa mendapatkan versi lengkap dari habr, tetapi versi selulernya.
Misalnya, jika artikel kointegrasi di versi desktop beratnya 378 KB, maka di versi mobile sudah 126 KB.
Versi kedua. Banyak utas, larangan sementara dari Habr
Ketika saya menjelajahi Internet tentang topik multithreading dengan python, saya memilih opsi paling sederhana dengan multiprocessing.dummy, saya perhatikan bahwa masalah muncul bersamaan dengan multithreading.
SQLite3 tidak ingin bekerja dengan lebih dari satu utas.
tetap check_same_thread=False, tetapi kesalahan ini bukan satu-satunya, ketika mencoba memasukkan ke dalam database, terkadang terjadi kesalahan yang tidak dapat saya selesaikan.
Oleh karena itu, saya memutuskan untuk meninggalkan penyisipan instan artikel langsung ke database dan, mengingat solusi kointegrasi, saya memutuskan untuk menggunakan file, karena tidak ada masalah dengan penulisan multi-utas ke file.
Habr mulai melarang penggunaan lebih dari tiga utas.
Upaya yang sangat bersemangat untuk menghubungi Habr dapat berakhir dengan larangan ip selama beberapa jam. Jadi Anda harus menggunakan hanya 3 utas, tetapi ini sudah bagus, karena waktu untuk mengulang lebih dari 100 artikel berkurang dari 26 menjadi 12 detik.
Perlu dicatat bahwa versi ini agak tidak stabil, dan unduhan secara berkala gagal pada sejumlah besar artikel.
async_v1.py
from bs4 import BeautifulSoup
import requests
import os, sys
import json
from multiprocessing.dummy import Pool as ThreadPool
from datetime import datetime
import logging
def worker(i):
currentFile = "files\{}.json".format(i)
if os.path.isfile(currentFile):
logging.info("{} - File exists".format(i))
return 1
url = "https://m.habr.com/post/{}".format(i)
try: r = requests.get(url)
except:
with open("req_errors.txt") as file:
file.write(i)
return 2
# Запись заблокированных запросов на сервер
if (r.status_code == 503):
with open("Error503.txt", "a") as write_file:
write_file.write(str(i) + "n")
logging.warning('{} / 503 Error'.format(i))
# Если поста не существует или он был скрыт
if (r.status_code != 200):
logging.info("{} / {} Code".format(i, r.status_code))
return r.status_code
html_doc = r.text
soup = BeautifulSoup(html_doc, 'html5lib')
try:
author = soup.find(class_="tm-user-info__username").get_text()
timestamp = soup.find(class_='tm-user-meta__date')
timestamp = timestamp['title']
content = soup.find(id="post-content-body")
content = str(content)
title = soup.find(class_="tm-article-title__text").get_text()
tags = soup.find(class_="tm-article__tags").get_text()
tags = tags[5:]
# Метка, что пост является переводом или туториалом.
tm_tag = soup.find(class_="tm-tags tm-tags_post").get_text()
rating = soup.find(class_="tm-votes-score").get_text()
except:
author = title = tags = timestamp = tm_tag = rating = "Error"
content = "При парсинге этой странице произошла ошибка."
logging.warning("Error parsing - {}".format(i))
with open("Errors.txt", "a") as write_file:
write_file.write(str(i) + "n")
# Записываем статью в json
try:
article = [i, timestamp, author, title, content, tm_tag, rating, tags]
with open(currentFile, "w") as write_file:
json.dump(article, write_file)
except:
print(i)
raise
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Необходимы параметры min и max. Использование: async_v1.py 1 100")
sys.exit(1)
min = int(sys.argv[1])
max = int(sys.argv[2])
# Если потоков >3
# то хабр банит ipшник на время
pool = ThreadPool(3)
# Отсчет времени, запуск потоков
start_time = datetime.now()
results = pool.map(worker, range(min, max))
# После закрытия всех потоков печатаем время
pool.close()
pool.join()
print(datetime.now() - start_time)Versi ketiga. Terakhir
Saat men-debug versi kedua, saya menemukan bahwa Habr, tiba-tiba, memiliki API yang diakses oleh versi seluler situs tersebut. Ini memuat lebih cepat daripada versi seluler, karena ini hanya json, yang bahkan tidak perlu diuraikan. Pada akhirnya, saya memutuskan untuk menulis ulang naskah saya lagi.
Jadi, setelah ditemukan API, Anda dapat mulai menguraikannya.
async_v2.py
import requests
import os, sys
import json
from multiprocessing.dummy import Pool as ThreadPool
from datetime import datetime
import logging
def worker(i):
currentFile = "files\{}.json".format(i)
if os.path.isfile(currentFile):
logging.info("{} - File exists".format(i))
return 1
url = "https://m.habr.com/kek/v1/articles/{}/?fl=ru%2Cen&hl=ru".format(i)
try:
r = requests.get(url)
if r.status_code == 503:
logging.critical("503 Error")
return 503
except:
with open("req_errors.txt") as file:
file.write(i)
return 2
data = json.loads(r.text)
if data['success']:
article = data['data']['article']
id = article['id']
is_tutorial = article['is_tutorial']
time_published = article['time_published']
comments_count = article['comments_count']
lang = article['lang']
tags_string = article['tags_string']
title = article['title']
content = article['text_html']
reading_count = article['reading_count']
author = article['author']['login']
score = article['voting']['score']
data = (id, is_tutorial, time_published, title, content, comments_count, lang, tags_string, reading_count, author, score)
with open(currentFile, "w") as write_file:
json.dump(data, write_file)
if __name__ == '__main__':
if len(sys.argv) < 3:
print("Необходимы параметры min и max. Использование: asyc.py 1 100")
sys.exit(1)
min = int(sys.argv[1])
max = int(sys.argv[2])
# Если потоков >3
# то хабр банит ipшник на время
pool = ThreadPool(3)
# Отсчет времени, запуск потоков
start_time = datetime.now()
results = pool.map(worker, range(min, max))
# После закрытия всех потоков печатаем время
pool.close()
pool.join()
print(datetime.now() - start_time)
Ini berisi bidang yang terkait dengan artikel itu sendiri dan penulis yang menulisnya.
API.png
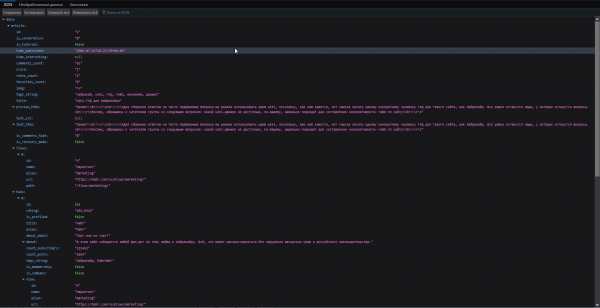
Saya tidak membuang json lengkap dari setiap artikel, tetapi hanya menyimpan bidang yang saya butuhkan:
- id
- is_tutorial
- waktu_diterbitkan
- judul
- Konten
- jumlah_komentar
- lang adalah bahasa yang digunakan untuk menulis artikel. Sejauh ini, hanya ada en dan ru.
- tags_string - semua tag dari postingan
- membaca_hitungan
- penulis
- skor - peringkat artikel.
Jadi, dengan menggunakan API, saya mengurangi waktu eksekusi skrip menjadi 8 detik per 100 url.
Setelah kita mengunduh data yang kita butuhkan, kita perlu mengolahnya dan memasukkannya ke dalam database. Saya juga tidak punya masalah dengan ini:
parser.py
import json
import sqlite3
import logging
from datetime import datetime
def parser(min, max):
conn = sqlite3.connect('habr.db')
c = conn.cursor()
c.execute('PRAGMA encoding = "UTF-8"')
c.execute('PRAGMA synchronous = 0') # Отключаем подтверждение записи, так скорость увеличивается в разы.
c.execute("CREATE TABLE IF NOT EXISTS articles(id INTEGER, time_published TEXT, author TEXT, title TEXT, content TEXT,
lang TEXT, comments_count INTEGER, reading_count INTEGER, score INTEGER, is_tutorial INTEGER, tags_string TEXT)")
try:
for i in range(min, max):
try:
filename = "files\{}.json".format(i)
f = open(filename)
data = json.load(f)
(id, is_tutorial, time_published, title, content, comments_count, lang,
tags_string, reading_count, author, score) = data
# Ради лучшей читаемости базы можно пренебречь читаемостью кода. Или нет?
# Если вам так кажется, можно просто заменить кортеж аргументом data. Решать вам.
c.execute('INSERT INTO articles VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)', (id, time_published, author,
title, content, lang,
comments_count, reading_count,
score, is_tutorial,
tags_string))
f.close()
except IOError:
logging.info('FileNotExists')
continue
finally:
conn.commit()
start_time = datetime.now()
parser(490000, 490918)
print(datetime.now() - start_time)
statistika
Nah, secara tradisional, akhirnya, Anda dapat mengekstrak beberapa statistik dari data:
- Dari 490 unduhan yang diharapkan, hanya 406 artikel yang diunduh. Ternyata lebih dari separuh (228) artikel di Habré disembunyikan atau dihapus.
- Seluruh database, yang terdiri dari hampir setengah juta artikel, memiliki berat 2.95 GB. Dalam bentuk terkompresi - 495 MB.
- Secara total, 37804 orang adalah penulis Habré. Saya mengingatkan Anda bahwa statistik ini hanya dari posting langsung.
- Penulis paling produktif di Habré - - 8774 artikel.
- — 1448 plus
- – 1660841 tampilan
- — 2444 komentar
Nah, berupa atasan15 penulis teratas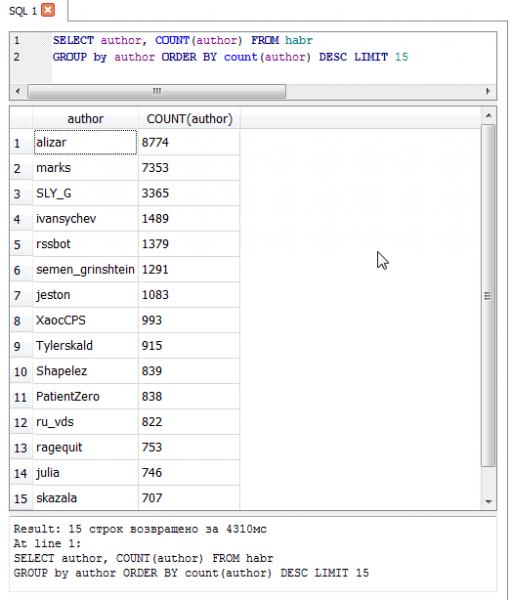
15 teratas berdasarkan peringkat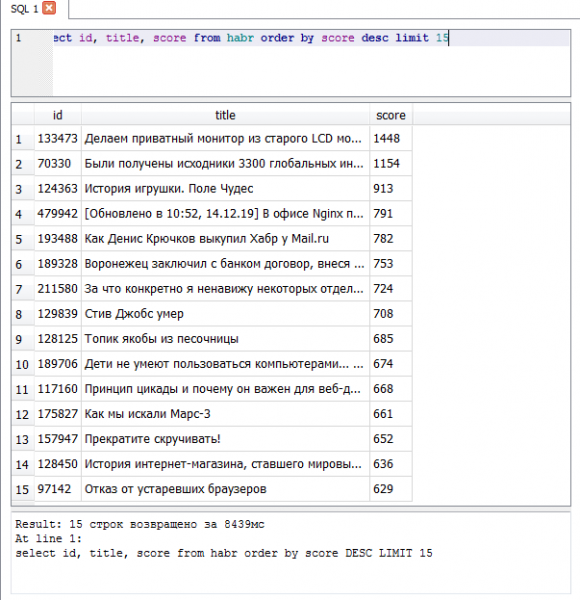
15 bacaan teratas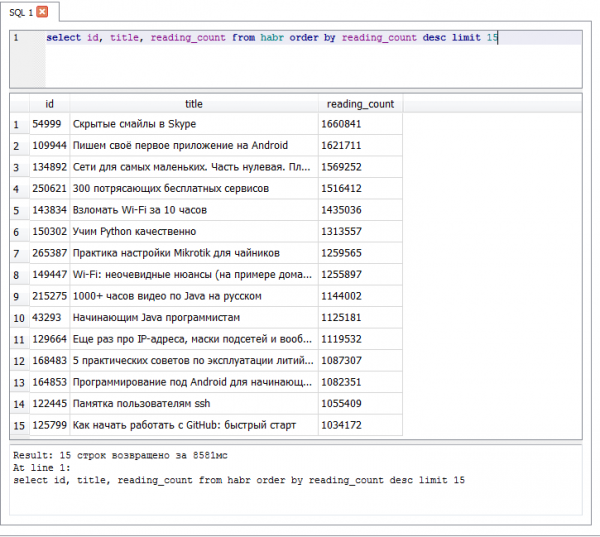
Top 15 Dibahas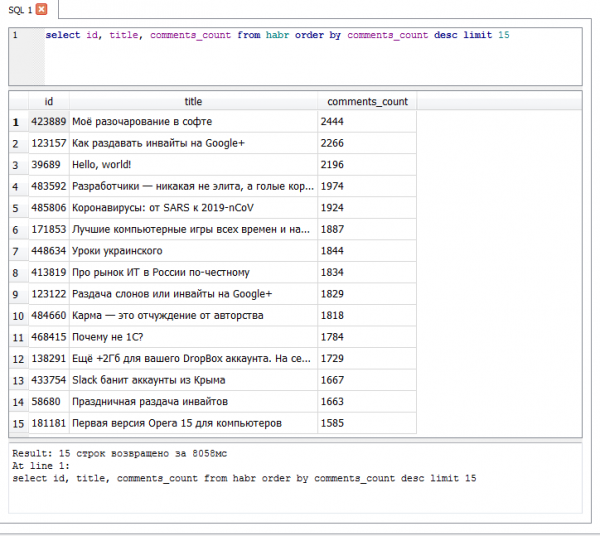
Sumber: www.habr.com
