

Saya sarankan Anda membaca transkrip laporan Georgy Rylov awal tahun 2020, "WAL-G: Peluang Baru dan Perluasan Komunitas."
Para pengelola sumber terbuka menghadapi berbagai tantangan seiring perkembangan mereka. Bagaimana kami menulis fitur yang semakin banyak diminta, memperbaiki masalah yang semakin banyak, dan menangani permintaan tarik yang terus meningkat? Menggunakan WAL-G (alat cadangan untuk PostgreSQL) sebagai contoh, saya akan berbagi bagaimana kami memecahkan masalah ini dengan meluncurkan kursus pengembangan sumber terbuka di universitas, apa yang telah kami capai, dan ke mana kami akan melangkah selanjutnya.

Halo semuanya! Saya pengembang Yandex dari Yekaterinburg. Hari ini saya akan membahas WAL-G.
Judul presentasinya tidak menyebutkan tentang backup. Ada yang tahu apa itu WAL-G? Atau semua orang tahu? Angkat tangan kalau belum tahu. Astaga, kamu datang ke presentasi ini dan tidak tahu apa yang dibahas.
Izinkan saya memberi tahu Anda apa yang akan dibahas hari ini. Ternyata tim kami sudah cukup lama berkecimpung di dunia pencadangan data. Ini adalah sesi lain dalam seri di mana kami membahas cara menyimpan data dengan aman, terlindungi, nyaman, dan efisien.

Di seri sebelumnya, ada banyak presentasi dari Andrey Borodin dan Vladimir Leskov. Banyak sekali dari kita yang hadir. Dan kita semua sudah membahas WAL-G selama bertahun-tahun.
clck.ru/F8ioz —
clck.ru/Ln8Qw —
Pembicaraan ini akan sedikit berbeda dari yang lain karena lebih bersifat teknis, tetapi di sini saya akan berbicara tentang bagaimana kami menghadapi tantangan terkait dengan pertumbuhan komunitas dan bagaimana kami menemukan ide kecil yang membantu kami mengatasinya.

Beberapa tahun yang lalu, WAL-G adalah proyek yang relatif kecil yang kami warisi dari Citus Data. Kami baru saja mengambil alihnya. Dan proyek ini dikembangkan oleh satu orang.
Dan hanya di WAL-G tidak ada:
- Cadangan dari replika.
- Tidak ada pencadangan tambahan.
- Tidak ada cadangan WAL-Delta.
- Dan masih banyak barang yang hilang.
WAL-G telah berkembang pesat selama beberapa tahun terakhir.

Dan pada tahun 2020, semua hal di atas telah terwujud. Selain itu, kini kita memiliki:
- Lebih dari 1.000 bintang di GitHub.
- 150 garpu.
- Sekitar 15 PR terbuka.
- Dan masih banyak lagi kontributor lainnya.
- Dan selalu ada masalah yang belum terselesaikan. Padahal, kami benar-benar datang ke sana setiap hari dan melakukan sesuatu untuk mengatasinya.

Dan kami sampai pada kesimpulan bahwa proyek ini membutuhkan lebih banyak perhatian kami, bahkan ketika kami sendiri tidak perlu mengimplementasikan apa pun untuk layanan Basis Data Terkelola kami di Yandex.
Dan sekitar musim gugur 2018, kami menemukan sebuah ide. Sebuah tim biasanya memiliki beberapa cara untuk membangun fitur dan memperbaiki bug jika kekurangan staf. Misalnya, Anda bisa merekrut pengembang lain dan membayarnya. Atau Anda bisa merekrut pekerja magang untuk sementara waktu dan juga membayarnya gaji. Namun, ada juga sekelompok orang yang cukup besar, beberapa di antaranya benar-benar tahu cara menulis kode. Anda hanya tidak selalu tahu kualitas kode tersebut.
Kami memikirkannya dan memutuskan untuk mencoba melibatkan mahasiswa. Namun, mahasiswa tidak akan terlibat dalam segala hal. Mereka hanya akan mengerjakan sebagian kecil pekerjaan. Misalnya, mereka akan menulis tes, memperbaiki bug, dan mengimplementasikan fitur yang tidak memengaruhi fungsionalitas inti. Fungsionalitas inti adalah membuat dan memulihkan cadangan. Jika kami membuat kesalahan pencadangan, kami akan kehilangan data. Dan tentu saja tidak ada yang menginginkan hal itu. Semua orang ingin semuanya sangat andal. Oleh karena itu, kami tentu tidak ingin menyertakan kode yang kurang kami percayai dibandingkan kode kami sendiri. Dengan kata lain, kode yang tidak penting itulah yang ingin kami dapatkan dari tenaga kerja tambahan kami.
Dalam kondisi apa PR siswa diterima?
- Mereka diharuskan untuk menutupi kode mereka dengan pengujian. Semuanya harus berjalan di CI.
- Dan kami juga akan membahas dua ulasan. Satu oleh Andrey Borodin dan satu lagi oleh saya.
- Dan untuk memastikan ini tidak merusak apa pun di layanan kami, saya mengunggah versi terpisah dengan komitmen ini. Kami kemudian menggunakan pengujian menyeluruh untuk memastikan tidak ada yang rusak.
Kursus khusus tentang Open Source

Sedikit tentang mengapa ini penting dan mengapa saya pikir ini adalah ide yang keren.
Bagi kami manfaatnya jelas:
- Kita mendapat bantuan tambahan.
- Kami mencari kandidat tim di antara mahasiswa cerdas yang menulis kode cerdas.
Apa manfaatnya bagi siswa?
Mereka mungkin kurang kentara karena siswa, paling tidak, tidak menerima uang untuk kode yang mereka tulis, tetapi hanya menerima nilai di buku catatan mereka.
Saya bertanya kepada mereka tentang hal itu. Dan menurut mereka:
- Pengalaman Kontributor Sumber Terbuka.
- Dapatkan baris di CV Anda.
- Buktikan diri Anda dan lulus wawancara di Yandex.
- Menjadi anggota GSoC.
- +1 kursus khusus bagi mereka yang ingin menulis kode.
Saya tidak akan membahas detail tentang struktur kursusnya. Saya hanya akan mengatakan bahwa WAL-G adalah proyek utamanya. Kami juga menyertakan proyek-proyek seperti Odyssey, PostgreSQL, dan ClickHouse.
Dan mereka memberikan soal tidak hanya di mata kuliah ini, tetapi juga mengeluarkan ijazah dan makalah.
Lalu bagaimana dengan manfaatnya bagi pengguna?
Sekarang mari kita beralih ke bagian yang paling menarik bagi Anda. Apa manfaatnya bagi Anda? Manfaatnya adalah para siswa telah memperbaiki banyak bug dan menerapkan permintaan fitur yang Anda minta.
Dan izinkan saya bercerita tentang hal-hal yang sudah lama Anda inginkan dan telah terwujud.
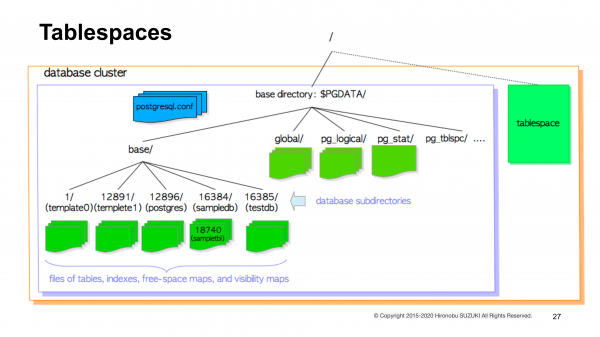
Dukungan tablespace. Tablespace di WAL-G mungkin sudah diharapkan sejak WAL-G dirilis, karena WAL-G merupakan penerus alat pencadangan lain, WAL-E, yang mendukung pencadangan basis data dengan tablespace.
Izinkan saya merangkum secara singkat apa ini dan mengapa ini diperlukan. Biasanya, semua data Postgres Anda menempati satu direktori di sistem berkas, yang disebut direktori dasar. Direktori ini sudah berisi semua berkas dan subdirektori yang dibutuhkan Postgres.
Tablespace adalah direktori yang berisi data Postgres, tetapi tidak berada di luar direktori dasar. Slide menunjukkan bahwa tablespac berada di luar direktori dasar.
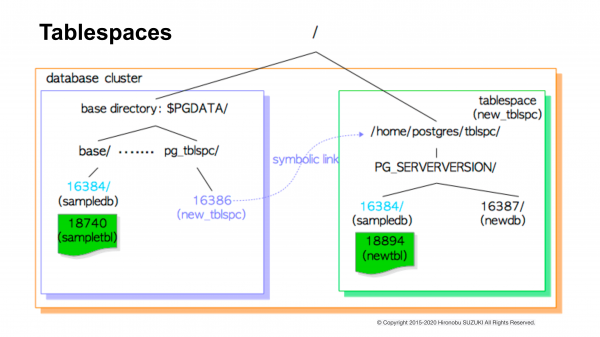
Bagaimana tampilannya untuk Postgres sendiri? Direktori dasar berisi subdirektori terpisah, pg_tblspc. Subdirektori ini berisi tautan simbolik ke direktori yang sebenarnya berisi data Postgres di luar direktori dasar.

Ketika Anda menggunakan semua ini, perintah-perintahnya mungkin terlihat seperti ini. Artinya, Anda membuat tabel di tablespace tertentu dan melihat di mana tabel tersebut berada saat ini. Dua baris terakhir ini adalah dua perintah terakhir yang dipanggil. Dan Anda dapat melihat ada jalur di sana. Namun sebenarnya, itu bukanlah jalur yang sebenarnya. Itu adalah jalur awalan dari direktori dasar ke tablespace. Dan dari sana, jalur tersebut dicocokkan dengan symlink yang mengarah ke data Anda yang sebenarnya.
Kami tidak menggunakan fitur ini di tim kami, tetapi banyak pengguna WAL-E lainnya menggunakannya dan menulis kepada kami bahwa mereka ingin bermigrasi ke WAL-G, tetapi hal itu menjadi kendala. Sekarang fitur ini didukung.
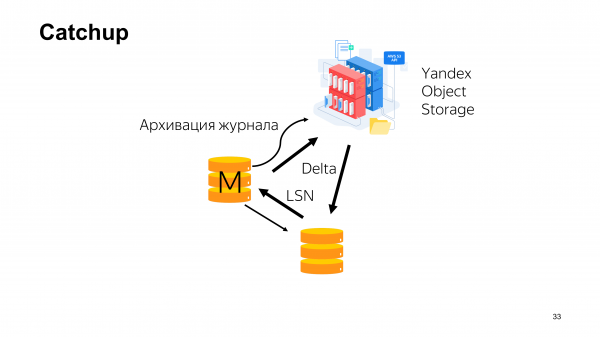
Fitur lain yang kami dapatkan dari kursus khusus kami adalah catchup. Catchup dikenal oleh orang-orang yang mungkin lebih sering menggunakan Oracle daripada Postgres.
Mari kita jelaskan secara singkat apa itu. Topologi kluster umum dalam layanan kita mungkin terlihat seperti ini. Kita memiliki master. Ada replika yang mengalirkan log write-ahead darinya. Replika memberi tahu master LSN tempat replika tersebut berada saat ini. Log dapat diarsipkan di suatu tempat secara paralel. Selain pengarsipan log, cadangan juga dikirim ke cloud. Dan cadangan delta juga dikirim.
Apa masalahnya? Ketika Anda memiliki basis data yang cukup besar, Anda mungkin mendapati replika Anda tertinggal jauh di belakang master. Replika tertinggal begitu jauh sehingga tidak dapat mengejarnya. Masalah ini biasanya perlu diatasi.
Cara termudah adalah menghapus replika dan mengunggahnya kembali, karena replika tersebut tidak akan pernah bisa menyusul, dan masalahnya perlu diatasi. Namun, itu cukup memakan waktu, karena memulihkan seluruh cadangan basis data 10 TB adalah proses yang sangat, sangat panjang. Dan kami ingin melakukannya secepat mungkin jika masalah seperti itu muncul. Dan itulah tujuan dari catchup.
Catchup memungkinkan Anda menggunakan cadangan delta yang disimpan di cloud dengan cara ini. Anda menentukan LSN replika lagging dan menentukannya dalam perintah catchup untuk membuat cadangan delta antara LSN tersebut dan LSN klaster Anda. Kemudian, Anda memulihkan cadangan ini ke replika lagging.
Pangkalan lainnya
Para mahasiswa juga memberikan kami banyak fitur sekaligus. Karena kami bekerja dengan lebih dari sekadar Postgres di Yandex—kami juga memiliki MySQL, MongoDB, Redis, dan ClickHouse—pada suatu saat, kami membutuhkan kemampuan untuk membuat cadangan dengan pemulihan point-in-time untuk MySQL dan mengunggahnya ke cloud.
Kami ingin melakukan ini dengan cara yang mirip dengan WAL-G. Kami memutuskan untuk bereksperimen dan melihat bagaimana hasilnya nanti.
Awalnya, kami menulis kode dalam fork tanpa memisahkan logika ini. Kami melihat bahwa kami memiliki semacam model yang berfungsi dan dapat berfungsi. Kemudian kami menyadari bahwa komunitas inti kami adalah pengguna Postgres; mereka menggunakan WAL-G. Jadi, kami perlu memisahkan bagian-bagian ini. Artinya, ketika kami memperbaiki kode Postgres, kami tidak merusak MySQL, dan ketika kami memperbaiki MySQL, kami tidak merusak Postgres.
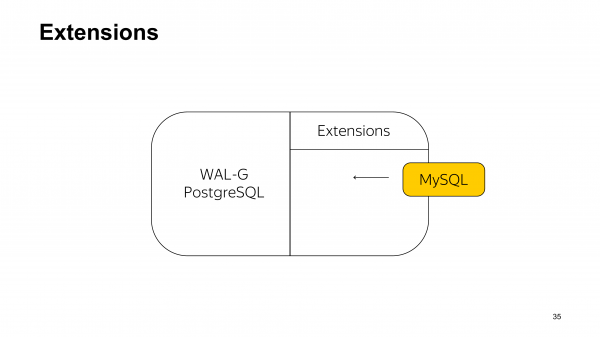
Ide pertama untuk memisahkan keduanya adalah menggunakan pendekatan yang sama dengan yang digunakan dalam ekstensi PostgreSQL. Intinya, untuk mencadangkan MySQL, Anda harus memasang semacam pustaka dinamis.
Namun, asimetri pendekatan ini langsung terlihat. Saat Anda mencadangkan Postgres, Anda memasang cadangan Postgres biasa di dalamnya, dan semuanya baik-baik saja. Namun untuk MySQL, ternyata Anda memasang cadangan Postgres dan juga memasang pustaka tautan dinamis MySQL. Kedengarannya agak aneh. Kami pun berpikir demikian dan memutuskan bahwa itu bukanlah solusi yang kami butuhkan.
Berbagai build untuk Postgres, MySQL, MongoDB, dan Redis
Namun, kami yakin hal ini memungkinkan kami untuk mencapai solusi yang tepat: build terpisah untuk basis data yang berbeda. Hal ini memungkinkan kami untuk mengisolasi logika yang terkait dengan pencadangan basis data berbeda yang akan mengakses API umum yang diimplementasikan oleh WAL-G.
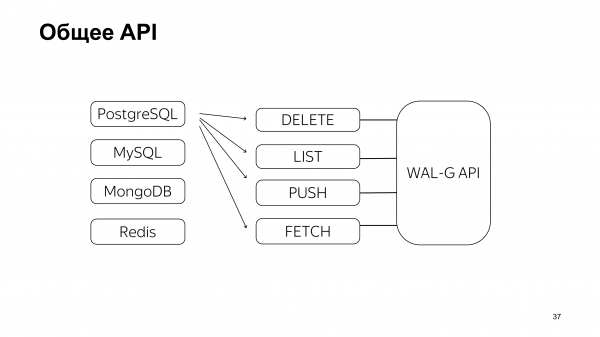
Ini adalah bagian yang kami tulis sendiri, sebelum memberikan soal kepada siswa. Jadi, di bagian inilah mereka mungkin melakukan kesalahan, jadi kami memutuskan akan lebih baik jika kami mengerjakannya dengan cara ini dan semuanya akan baik-baik saja.
Setelah itu, kami membagikan soal-soal tersebut. Soal-soal tersebut langsung terjawab. Para siswa diminta untuk mempertahankan tiga basis.
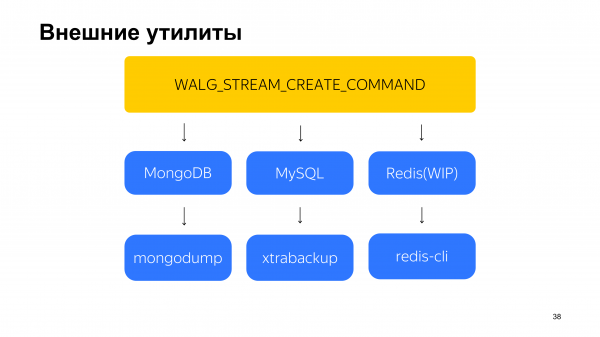
Ini adalah MySQL, yang telah kami cadangkan menggunakan WAL-G dengan cara ini selama lebih dari setahun sekarang.
Dan sekarang MongoDB sudah mendekati tahap produksi, di mana ia sedang disempurnakan. Intinya, kami menulis kerangka kerja untuk semua ini. Kemudian para siswa menulis beberapa kode yang berfungsi. Dan kemudian kami menyempurnakannya hingga siap untuk diimplementasikan dalam tahap produksi.
Tugas-tugas ini tidak mengharuskan siswa untuk menulis alat pencadangan lengkap untuk masing-masing basis data ini. Kami tidak mengalami masalah itu. Masalahnya adalah kami menginginkan pemulihan point-in-time dan kami ingin mencadangkannya ke cloud. Jadi, kami meminta siswa untuk menulis beberapa kode yang akan menyelesaikan masalah ini. Para siswa menggunakan alat pencadangan yang sudah ada yang entah bagaimana membuat cadangan, lalu menggabungkannya dengan WAL-G, yang mengirimkan semuanya ke cloud. Mereka juga menambahkan pemulihan point-in-time ke dalam solusi ini.

Apa lagi yang disumbangkan para mahasiswa? Mereka menambahkan dukungan enkripsi Libsodium ke WAL-G.
Kami juga memperkenalkan kebijakan retensi cadangan. Kini Anda dapat menandai cadangan sebagai permanen. Hal ini memudahkan layanan Anda untuk mengotomatiskan proses retensinya.

Apa hasil percobaan ini?
Lebih dari 100 orang awalnya mendaftar untuk kursus ini. Awalnya saya tidak menyebutkan bahwa universitas di Yekaterinburg adalah Universitas Federal Ural. Kami mengumumkan semuanya di sana. 100 orang mendaftar. Jumlah orang yang benar-benar mulai belajar jauh lebih sedikit, sekitar 30 orang.
Bahkan lebih sedikit lagi yang berhenti dari kursus karena mengharuskan penulisan tes untuk kode yang sudah ada, serta memperbaiki bug atau mengimplementasikan fitur. Beberapa mahasiswa memang berhenti.
Sejauh ini, para siswa telah memperbaiki sekitar 14 masalah dan menciptakan 10 fitur dengan berbagai ukuran selama kursus ini. Dan, menurut saya, ini adalah pengganti yang lengkap untuk satu atau dua pengembang.
Di antaranya, kami menerbitkan ijazah dan tugas kuliah. Dan 12 di antaranya telah menerima ijazah. Enam di antaranya telah mempertahankan tesis mereka dengan nilai yang sangat baik. Sisanya belum mempertahankan tesis mereka, tetapi saya yakin mereka juga akan berhasil.
Планы на будущее
Apa rencana kita untuk masa depan?
Setidaknya, kami telah mendengar permintaan fitur dari pengguna dan ingin menerapkannya. Berikut ini adalah:
- Memantau ketepatan pelacakan linimasa dalam arsip cadangan klaster HA. Ini dapat dilakukan menggunakan WAL-G. Dan saya rasa kami memiliki mahasiswa yang bersedia mengerjakannya.
- Kami sudah memiliki orang yang bertanggung jawab untuk mentransfer cadangan dan WAL antar cloud.
- Dan baru-baru ini kami menerbitkan sebuah ide bahwa kami dapat mempercepat WAL-G lebih jauh lagi dengan membongkar cadangan tambahan tanpa menulis ulang halaman dan mengoptimalkan arsip yang kami kirim ke sana.
Anda dapat membagikannya di sini.
Apa inti dari laporan ini? Intinya, sekarang, selain kami berempat yang mendukung proyek ini, kami memiliki banyak bantuan tambahan. Terutama jika Anda mengirim pesan pribadi kepada mereka. Dan jika Anda mencadangkan data menggunakan WAL-G atau ingin bermigrasi ke WAL-G, kami dapat mengakomodasi keinginan Anda dengan mudah.

Ini adalah kode QR dan tautan. Anda bisa mengekliknya dan menuliskan semua keinginan Anda. Misalnya, mungkin kami tidak sedang memperbaiki bug tertentu. Atau mungkin ada fitur yang sangat Anda inginkan, tetapi karena suatu alasan belum tersedia di layanan pencadangan mana pun, termasuk layanan kami. Pastikan untuk memberi tahu kami.

pertanyaan
Halo! Terima kasih atas laporannya! Pertanyaan saya tentang WAL-G, bukan Postgres. WAL-G mencadangkan MySQL dan memanggil cadangan tambahan. Jika kita menggunakan instalasi modern pada CentOS Dan jika Anda menjalankan perintah `yum install MySQL`, MariDB akan terinstal. Sejak versi 10.3, pencadangan tambahan tidak lagi didukung; pencadangan MariDB didukung. Bagaimana pendapat Anda tentang hal ini?
Kami belum mencoba mencadangkan MariDB. Kami sudah menerima beberapa permintaan dukungan FoundationDB, tetapi umumnya, jika ada permintaan, kami bisa mencari orang untuk melakukannya. Prosesnya tidak selama atau sesulit yang saya bayangkan.
Selamat siang! Terima kasih atas presentasinya! Saya punya pertanyaan tentang fitur-fitur baru yang potensial. Apakah Anda siap untuk membuat WAL-G berfungsi dengan pita kaset sehingga kita bisa melakukan pencadangan ke pita kaset?
Pencadangan pada penyimpanan pita, kurasa?
Ya.
Ada Andrey Borodin, yang dapat menjawab pertanyaan ini lebih baik dari saya.
(Andrey) Ya, terima kasih atas pertanyaannya! Kami menerima permintaan untuk memindahkan cadangan dari penyimpanan cloud ke tape. Dan untuk itu Migrasi lintas-cloud. Karena migrasi lintas-cloud merupakan versi umum dari migrasi pita. Kami juga memiliki arsitektur yang dapat diperluas untuk Storage. Kebetulan, banyak Storage yang ditulis oleh mahasiswa. Dan jika Anda menulis Storage untuk pita, tentu saja akan didukung. Kami terbuka untuk permintaan tarik (pull request). Ini melibatkan penulisan dan pembacaan berkas. Jika Anda mengimplementasikan hal-hal ini di Go, biasanya akan ada 50 baris kode. Maka WAL-G akan mendukung pita.
Terima kasih atas presentasinya! Proses pengembangannya menarik. Pencadangan merupakan bagian penting dari fungsionalitas yang perlu diuji dengan baik. Saat Anda mengimplementasikan fungsionalitas untuk basis data baru, apakah Anda meminta siswa menulis tesnya sendiri, atau Anda menulis tesnya sendiri lalu menyerahkannya kepada siswa?
Para mahasiswa juga menulis tes. Namun, mereka lebih banyak menulisnya untuk fitur-fitur seperti basis data baru. Mereka menulis tes integrasi. Dan mereka menulis tes unit. Jika tes integrasi berhasil—yaitu, pada titik ini—itu adalah skrip yang Anda jalankan secara manual atau minta cron untuk melakukannya, misalnya. Jadi, skripnya sangat jelas.
Para siswa belum memiliki banyak pengalaman. Berapa lama waktu yang dibutuhkan untuk meninjaunya?
Ya, peninjauan membutuhkan waktu yang cukup lama. Artinya, biasanya ketika beberapa komiter datang sekaligus dan berkata, "Saya sudah melakukan ini," dan "Saya sudah melakukan itu," Anda harus memikirkannya dan meluangkan waktu sekitar setengah hari untuk memahami apa yang telah mereka tulis. Karena kodenya perlu dibaca secara menyeluruh. Mereka belum diwawancarai. Kami tidak terlalu mengenal mereka, jadi proses ini membutuhkan waktu yang cukup lama.
Terima kasih atas laporannya! Andrey Borodin sebelumnya menyatakan bahwa archive_command di WAL-G harus dipanggil secara langsung. Namun, dalam kasus klaster, kita memerlukan logika tambahan untuk menentukan node asal pengiriman data. Bagaimana Anda menyelesaikan masalah ini?
Apa masalah yang Anda alami di sini? Katakanlah Anda memiliki replika sinkron yang sedang Anda cadangkan? Atau apa?
(Andrey) Masalahnya, WAL-G sebenarnya dirancang untuk digunakan tanpa skrip shell. Jika ada yang kurang, mari kita tambahkan logika yang seharusnya ada di dalam WAL-G. Mengenai sumber pengarsipan, kami yakin pengarsipan seharusnya berasal dari master saat ini di klaster. Pengarsipan dari replika bukanlah ide yang baik. Berbagai skenario masalah mungkin terjadi, terutama terkait linimasa pengarsipan dan informasi tambahan lainnya. Terima kasih atas pertanyaan Anda!
(Klarifikasi: Kami menyingkirkan pengikatan skrip shell )
Selamat malam! Terima kasih atas laporannya! Saya tertarik dengan fitur "catchup" yang Anda sebutkan. Kami mengalami situasi di mana replika mengalami lag dan tidak dapat mengejar. Saya tidak menemukan deskripsi fitur ini dalam dokumentasi WAL-G.
Catchup diluncurkan sekitar tanggal 20 Januari 2020. Dokumentasinya mungkin perlu sedikit perbaikan. Kami menulisnya sendiri, dan kami tidak melakukannya dengan sempurna. Dan mungkin kami harus mulai mewajibkan siswa untuk menulisnya.
Apakah sudah dirilis?
Pull request sudah digabungkan, artinya saya sudah memverifikasinya. Saya sudah mencobanya di kluster uji. Belum ada situasi di mana kami bisa mengujinya di tahap produksi.
Kapan dapat diharapkan?
Entahlah. Tunggu sebulan lagi, nanti kami periksa pastinya.
Sumber: www.habr.com
