

Kveðja, habr.
Ef einhver misnotar kerfið og lenti í vandræðum með afköst geymslu (IO, neytt diskpláss), þá ættu líkurnar á því að ClickHouse hafi verið varpað í staðinn að vera einn. Þessi yfirlýsing gefur til kynna að útfærsla þriðja aðila sé nú þegar notuð sem púki sem tekur á móti mæligildum, til dæmis eða .
ClickHouse leysir vel lýst vandamálum. Til dæmis, eftir að hafa flutt 2TiB af gögnum frá whisper, passa þau inn í 300GiB. Ég mun ekki dvelja í smáatriðum við samanburðinn; það eru fullt af greinum um þetta efni. Að auki, þar til nýlega, var ekki allt fullkomið með ClickHouse geymslunni okkar.
Vandamál með neytt pláss
Við fyrstu sýn ætti allt að virka vel. Á eftir , búðu til stillingar fyrir mæligildisgeymslukerfið (nánari retention), búðu síðan til töflu í samræmi við tilmæli valins bakenda fyrir grafítvef: + eða , eftir því hvaða stafli er notaður. Og... tímasprengjan springur.
Til að skilja hver þeirra þarftu að vita hvernig innlegg virka og frekari lífsleið gagna í töflum yfir vélar * fjölskyldunnarMergeTree ClickHouse (töflur teknar úr Alexey Zatelepin):
- Sett inn
блокgögn. Í okkar tilviki voru það mælikvarðar sem komu.

- Hver slíkur kubb er flokkaður eftir lyklinum áður en hann er skrifaður á diskinn.
ORDER BYtilgreint við gerð töflunnar. - Eftir flokkun,
кусок(part) gögn eru skrifuð á disk.
- Miðlarinn fylgist með í bakgrunni þannig að það eru ekki margir slíkir hlutir og setur bakgrunn
слияния(merge, hér eftir sameinað).
- Miðlarinn hættir að keyra sameinast á eigin spýtur um leið og gögn hætta að streyma virkan inn í
партицию(partition), en þú getur hafið ferlið handvirkt með skipuninniOPTIMIZE. - Ef það er aðeins eitt stykki eftir í skiptingunni, þá muntu ekki geta keyrt sameininguna með því að nota venjulega skipunina; þú verður að nota
OPTIMIZE ... FINAL
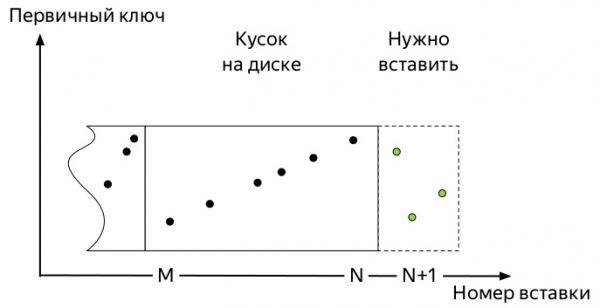
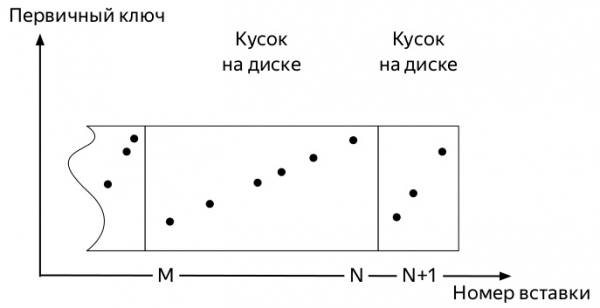
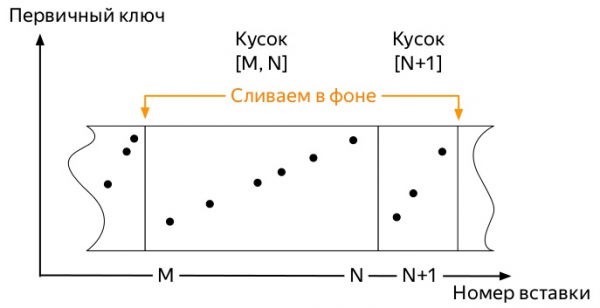
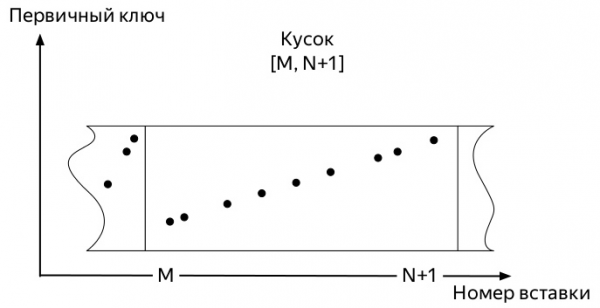
Svo, fyrstu mælingarnar koma. Og þeir taka smá pláss. Síðari atburðir geta verið nokkuð mismunandi eftir mörgum þáttum:
- Skiptingalykillinn getur verið annað hvort mjög lítill (á dag) eða mjög stór (nokkrir mánuðir).
- Varðveislustillingin gæti passað við nokkra mikilvæga gagnasöfnunarþröskulda innan virku skiptingarinnar (þar sem mælingar eru skráðar), eða kannski ekki.
- Ef það er mikið af gögnum, þá munu elstu bitarnir, sem vegna bakgrunnssamruna gætu þegar verið stórir (ef þú velur óákjósanlegur skiptingarlykil), ekki sameinast nýjum litlum bitum.
Og það endar alltaf eins. Plássið sem mælingar í ClickHouse eykst aðeins ef:
- eiga ekki við
OPTIMIZE ... FINALhandvirkt eða - ekki setja gögn inn í öll skipting stöðugt, þannig að fyrr eða síðar hefjist bakgrunnssamruni
Önnur aðferðin virðist vera auðveldust í framkvæmd og því er hún röng og var reynt fyrst.
Ég skrifaði frekar einfalt python handrit sem sendi dummy mæligildi fyrir hvern dag undanfarin 4 ár og keyrði cron á klukkutíma fresti.
Þar sem allur rekstur ClickHouse DBMS er byggður á því að þetta kerfi mun fyrr eða síðar vinna alla bakgrunnsvinnuna, en ekki er vitað hvenær, gat ég ekki beðið eftir því augnabliki þegar gömlu risastóru stykkin heiðruðust að byrja að sameinast nýir smáir. Það varð ljóst að við þurftum að leita leiða til að gera þvingaðar hagræðingar sjálfvirkar.

Upplýsingar í ClickHouse kerfistöflum
Við skulum skoða töfluskipulagið . Þetta eru yfirgripsmiklar upplýsingar um hvert stykki af öllum borðum á ClickHouse þjóninum. Inniheldur meðal annars eftirfarandi dálka:
- db nafn (
database); - borð nafn (
table); - heiti skiptingarinnar og auðkenni (
partition&partition_id); - þegar verkið var búið til (
modification_time); - lágmarks- og hámarksdagsetning í stykki (skipting fer fram eftir degi) (
min_date&max_date);
Það er líka borð , með eftirfarandi áhugaverðu sviðum:
- db nafn (
Tables.database); - borð nafn (
Tables.table); - mæligildi þegar beita ætti næstu samsöfnun (
age);
Svo:
- Við höfum töflu yfir klumpur og töflu yfir söfnunarreglur.
- Við sameinum gatnamót þeirra og fáum allar töflur *GraphiteMergeTree.
- Við leitum að öllum skiptingum þar sem:
- meira en eitt stykki
- eða tími er kominn til að beita næstu samlagningarreglu, og
modification_timeeldri en þessa stund.
Framkvæmd
Þessi beiðni
SELECT
concat(p.database, '.', p.table) AS table,
p.partition_id AS partition_id,
p.partition AS partition,
-- Самое "старое" правило, которое может быть применено для
-- партиции, но не в будущем, см (*)
max(g.age) AS age,
-- Количество кусков в партиции
countDistinct(p.name) AS parts,
-- За самую старшую метрику в партиции принимается 00:00:00 следующего дня
toDateTime(max(p.max_date + 1)) AS max_time,
-- Когда партиция должна быть оптимизированна
max_time + age AS rollup_time,
-- Когда самый старый кусок в партиции был обновлён
min(p.modification_time) AS modified_at
FROM system.parts AS p
INNER JOIN
(
-- Все правила для всех таблиц *GraphiteMergeTree
SELECT
Tables.database AS database,
Tables.table AS table,
age
FROM system.graphite_retentions
ARRAY JOIN Tables
GROUP BY
database,
table,
age
) AS g ON
(p.table = g.table)
AND (p.database = g.database)
WHERE
-- Только активные куски
p.active
-- (*) И только строки, где правила аггрегации уже должны быть применены
AND ((toDateTime(p.max_date + 1) + g.age) < now())
GROUP BY
table,
partition
HAVING
-- Только партиции, которые младше момента оптимизации
(modified_at < rollup_time)
-- Или с несколькими кусками
OR (parts > 1)
ORDER BY
table ASC,
partition ASC,
age ASCskilar hverri af *GraphiteMergeTree töflusneiðunum þar sem sameining þeirra ætti að losa um pláss. Það eina sem eftir er að gera er að fara í gegnum þá alla með beiðni OPTIMIZE ... FINAL. Endanleg útfærsla tekur einnig tillit til þess að ekki er þörf á að snerta skipting með virkri upptöku.
Þetta er nákvæmlega það sem verkefnið gerir . Fyrrverandi samstarfsmenn frá Yandex.Market reyndu það í framleiðslu, afrakstur vinnunnar má sjá hér að neðan.
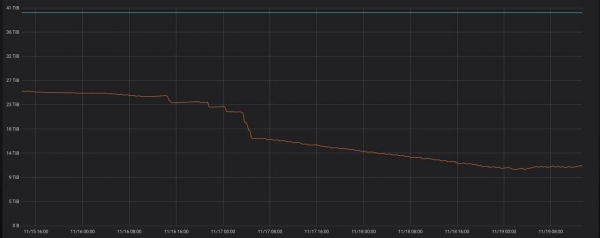
Ef þú keyrir forritið á netþjóni með ClickHouse mun það einfaldlega byrja að virka í púkaham. Einu sinni á klukkutíma verður beiðni framkvæmd, athugað hvort ný skipting eldri en þriggja daga hafi birst sem hægt er að fínstilla.
Strax áætlanir okkar eru að veita að minnsta kosti deb pakka, og ef mögulegt er einnig rpm.
Í stað þess að niðurstöðu
Undanfarna 9+ mánuði hef ég verið inni í fyrirtækinu mínu eyddi miklum tíma í að fikta á mótum ClickHouse og grafítvefs. Þetta var góð reynsla, sem leiddi til þess að umskipti voru fljótleg frá hvísli yfir í ClickHouse sem mælikvarðageymslu. Ég vona að þessi grein sé eitthvað af byrjun á röð um hvaða endurbætur við höfum gert á ýmsum hlutum þessa stafla og hvað verður gert í framtíðinni.
Nokkrir lítrar af bjór og admin dögum fóru í að þróa beiðnina ásamt , sem ég vil þakka honum fyrir. Og líka fyrir að rifja upp þessa grein.
Heimild: www.habr.com
