

Athugið. þýð.: Þessi grein, skrifuð af Galo Navarro, sem gegnir stöðu aðalhugbúnaðarverkfræðings hjá evrópska fyrirtækinu Adevinta, er heillandi og lærdómsrík „rannsókn“ á sviði innviðareksturs. Upprunalegur titill þess var örlítið stækkaður í þýðingu af ástæðu sem höfundur útskýrir í upphafi.
Athugasemd frá höfundi: Lítur út eins og þessi færsla mun meiri athygli en búist var við. Ég fæ ennþá reiðar athugasemdir um að titill greinarinnar sé villandi og að sumir lesendur séu miður sín. Ég skil ástæðurnar fyrir því sem er að gerast, þess vegna, þrátt fyrir að hætta sé á að eyðileggja allt ráðabruggið, vil ég strax segja þér hvað þessi grein fjallar um. Forvitnilegt atriði sem ég hef séð þegar lið flytjast til Kubernetes er að alltaf þegar vandamál koma upp (svo sem aukin leynd eftir flutning) er það fyrsta sem er kennt um Kubernetes, en svo kemur í ljós að hljómsveitarstjórinn er í raun ekki að kenna. Þessi grein segir frá einu slíku tilviki. Nafn þess endurtekur upphrópun eins af þróunaraðilum okkar (síðar muntu sjá að Kubernetes hefur ekkert með það að gera). Þú munt ekki finna neinar óvæntar opinberanir um Kubernetes hér, en þú getur búist við nokkrum góðum kennslustundum um flókin kerfi.
Fyrir nokkrum vikum var teymið mitt að flytja eina örþjónustu yfir á kjarnavettvang sem innihélt CI/CD, keyrslutíma sem byggir á Kubernetes, mæligildi og annað góðgæti. Flutningurinn var tilraunaeðli: Við ætluðum að leggja hana til grundvallar og flytja um það bil 150 þjónustur til viðbótar á næstu mánuðum. Allir bera þeir ábyrgð á rekstri nokkurra af stærstu netkerfum Spánar (Infojobs, Fotocasa o.s.frv.).
Eftir að við sendum forritið til Kubernetes og sendum smá umferð á það, beið okkar skelfileg undrun. Töf (leynd) beiðnir í Kubernetes voru 10 sinnum hærri en í EC2. Almennt séð var nauðsynlegt að annað hvort finna lausn á þessu vandamáli eða hætta við flutning örþjónustunnar (og hugsanlega allt verkefnið).
Af hverju er leynd svona miklu hærri í Kubernetes en í EC2?
Til að finna flöskuhálsinn söfnuðum við mælingum meðfram allri beiðnileiðinni. Arkitektúr okkar er einfaldur: API-gátt (Zuul) sendir beiðnir til örþjónustutilvika í EC2 eða Kubernetes. Í Kubernetes notum við NGINX Ingress Controller og bakendarnir eru venjulegir hlutir eins og með JVM forriti á Spring pallinum.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Vandamálið virtist tengjast upphaflegu leynd í bakendanum (ég merkti vandamálasvæðið á grafinu sem "xx"). Á EC2 tók umsóknarsvarið um 20 ms. Í Kubernetes jókst leynd í 100-200 ms.
Við vísuðum fljótt frá hugsanlegum grunuðum í tengslum við breytinguna á keyrslutíma. JVM útgáfan er sú sama. Gámavæðingarvandamál höfðu heldur ekkert með það að gera: forritið var þegar keyrt með góðum árangri í gámum á EC2. Hleður? En við sáum mikla töf jafnvel við 1 beiðni á sekúndu. Hlé á sorphirðu gæti líka verið vanrækt.
Einn af Kubernetes stjórnendum okkar velti því fyrir sér hvort forritið hefði ytri ósjálfstæði vegna þess að DNS fyrirspurnir hefðu valdið svipuðum vandamálum áður.
Tilgáta 1: DNS nafnaupplausn
Fyrir hverja beiðni opnar forritið okkar AWS Elasticsearch dæmi einu til þrisvar sinnum á léni eins og elastic.spain.adevinta.com. Inni í gámunum okkar , svo við getum athugað hvort leit að léni taki í raun langan tíma.
DNS fyrirspurnir frá íláti:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecSvipaðar beiðnir frá einu af EC2 tilvikunum þar sem forritið er í gangi:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecMeð hliðsjón af því að uppflettingin tók um 30 ms, varð ljóst að DNS upplausn þegar opnað var fyrir Elasticsearch stuðlaði sannarlega að aukinni leynd.
Hins vegar var þetta undarlegt af tveimur ástæðum:
- Við höfum nú þegar fullt af Kubernetes forritum sem hafa samskipti við AWS auðlindir án þess að þjást af mikilli leynd. Hver sem ástæðan er, þá snýr hún sérstaklega að þessu máli.
- Við vitum að JVM gerir DNS skyndiminni í minni. Í myndunum okkar er TTL gildið skrifað inn
$JAVA_HOME/jre/lib/security/java.securityog stilltu á 10 sekúndur:networkaddress.cache.ttl = 10. Með öðrum orðum, JVM ætti að vista allar DNS fyrirspurnir í 10 sekúndur.
Til að staðfesta fyrstu tilgátuna ákváðum við að hætta að hringja í DNS um stund og athuga hvort vandamálið hverfi. Í fyrsta lagi ákváðum við að endurstilla forritið þannig að það hafi samband beint við Elasticsearch með IP tölu, frekar en í gegnum lén. Þetta myndi krefjast kóðabreytinga og nýrrar uppsetningar, svo við kortlögðum lénið einfaldlega á IP tölu þess í /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comNú fékk gámurinn IP nánast samstundis. Þetta leiddi til nokkurrar framförar, en við vorum aðeins aðeins nær væntanlegum biðtíma. Þrátt fyrir að DNS-upplausn hafi tekið langan tíma, fór hin raunverulega ástæða samt framhjá okkur.
Greining í gegnum net
Við ákváðum að greina umferð frá gámnum með því að nota tcpdumptil að sjá hvað nákvæmlega er að gerast á netinu:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Við sendum síðan nokkrar beiðnir og haluðum niður töku þeirra (kubectl cp my-service:/capture.pcap capture.pcap) til frekari greiningar í .
Það var ekkert grunsamlegt við DNS fyrirspurnirnar (nema eitt lítið sem ég mun tala um síðar). En það voru ákveðnar undarlegar í því hvernig þjónusta okkar tók á hverri beiðni. Hér að neðan er skjáskot af myndinni sem sýnir að beiðnin er samþykkt áður en svarið hefst:
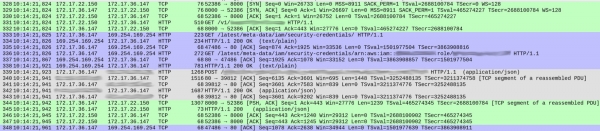
Pakkanúmer eru sýnd í fyrsta dálki. Til glöggvunar hef ég litakóða mismunandi TCP strauma.
Græni straumurinn sem byrjar á pakka 328 sýnir hvernig biðlarinn (172.17.22.150) kom á TCP tengingu við ílátið (172.17.36.147). Eftir upphaflegt handaband (328-330) kom pakki 331 HTTP GET /v1/.. — beiðni sem berst til þjónustu okkar. Allt ferlið tók 1 ms.
Grái straumurinn (úr pakka 339) sýnir að þjónustan okkar sendi HTTP beiðni til Elasticsearch tilviksins (það er ekkert TCP handtak vegna þess að það notar núverandi tengingu). Þetta tók 18 ms.
Enn sem komið er er allt í lagi og tímarnir samsvara nokkurn veginn væntanlegum töfum (20-30 ms miðað við viðskiptavininn).
Hins vegar tekur blái kaflinn 86 ms. Hvað er að gerast í því? Með pakka 333 sendi þjónusta okkar HTTP GET beiðni til /latest/meta-data/iam/security-credentials, og strax á eftir henni, yfir sömu TCP tengingu, önnur GET beiðni til /latest/meta-data/iam/security-credentials/arn:...
Við komumst að því að þetta endurtók sig við hverja beiðni í gegnum rakninguna. DNS upplausn er örugglega aðeins hægari í gámunum okkar (skýringin á þessu fyrirbæri er nokkuð áhugaverð, en ég geymi hana fyrir sérstaka grein). Í ljós kom að orsök löngu seinkana var símtöl í AWS Instance Metadata þjónustuna við hverja beiðni.
Tilgáta 2: óþarfa símtöl til AWS
Báðir endapunktar tilheyra . Örþjónusta okkar notar þessa þjónustu á meðan Elasticsearch keyrir. Bæði símtölin eru hluti af grunnheimildarferlinu. Endapunkturinn sem er opnaður í fyrstu beiðni gefur út IAM hlutverkið sem tengist tilvikinu.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleÖnnur beiðnin biður seinni endapunktinn um tímabundnar heimildir fyrir þetta tilvik:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Viðskiptavinurinn getur notað þau í stuttan tíma og verður reglulega að fá ný vottorð (áður en þau eru það Expiration). Líkanið er einfalt: AWS snýr tímabundnum lyklum oft af öryggisástæðum, en viðskiptavinir geta vistað þá í nokkrar mínútur til að bæta upp fyrir árangurssektina sem fylgir því að fá ný vottorð.
AWS Java SDK ætti að taka við ábyrgðinni á að skipuleggja þetta ferli, en af einhverjum ástæðum gerist það ekki.
Eftir að hafa leitað að vandamálum á GitHub, fundum við vandamál . Hún hjálpaði okkur að ákveða í hvaða átt við ættum að „grafa“ frekar.
AWS SDK uppfærir vottorð þegar eitt af eftirfarandi skilyrðum kemur upp:
- Gildistími (
Expiration) Detta íEXPIRATION_THRESHOLD, harðkóða í 15 mínútur. - Lengri tími er liðinn frá síðustu tilraun til endurnýjunar skírteina en
REFRESH_THRESHOLD, harðkóða í 60 mínútur.
Til að sjá raunverulega fyrningardagsetningu skírteina sem við fáum, keyrðum við ofangreindar cURL skipanir frá bæði ílátinu og EC2 tilvikinu. Gildistími vottorðsins sem barst frá gámnum reyndist vera mun styttri: nákvæmlega 15 mínútur.
Nú er allt orðið ljóst: fyrir fyrstu beiðni fékk þjónustan okkar tímabundin vottorð. Þar sem þær giltu ekki lengur en í 15 mínútur myndi AWS SDK ákveða að uppfæra þær við síðari beiðni. Og þetta gerðist við hverja beiðni.
Hvers vegna er gildistími skírteina styttri?
AWS Instance Metadata eru hönnuð til að vinna með EC2 tilvik, ekki Kubernetes. Aftur á móti vildum við ekki breyta forritaviðmótinu. Fyrir þetta notuðum við - tól sem, með því að nota umboðsmenn á hverjum Kubernetes hnút, gerir notendum (verkfræðingum sem senda forrit í klasa) kleift að úthluta IAM hlutverkum til gáma í belgjum eins og um EC2 tilvik væri að ræða. KIAM hlerar símtöl í AWS Instance Metadata þjónustuna og vinnur úr þeim úr skyndiminni, eftir að hafa áður fengið þau frá AWS. Frá sjónarhóli umsóknar breytist ekkert.
KIAM veitir belgjum skammtímavottorð. Þetta er skynsamlegt í ljósi þess að meðallíftími fræbelgs er styttri en EC2 tilvik. Sjálfgefinn gildistími skírteina .
Þar af leiðandi, ef þú leggur bæði sjálfgefna gildin ofan á hvort annað, kemur upp vandamál. Hvert vottorð sem veitt er fyrir umsókn rennur út eftir 15 mínútur. Hins vegar þvingar AWS Java SDK fram endurnýjun á hvaða vottorði sem á minna en 15 mínútur eftir fyrir gildistíma þess.
Þess vegna neyðist til að endurnýja tímabundna vottorðið með hverri beiðni, sem felur í sér nokkur símtöl í AWS API og veldur verulegri aukningu á leynd. Í AWS Java SDK fundum við , sem nefnir svipað vandamál.
Lausnin reyndist einföld. Við endurstilltum einfaldlega KIAM til að biðja um skírteini með lengri gildistíma. Þegar þetta gerðist fóru beiðnir að streyma án þátttöku AWS lýsigagnaþjónustunnar og töfin fór niður í enn lægri stig en í EC2.
Niðurstöður
Byggt á reynslu okkar af flutningum er ein algengasta uppspretta vandamála ekki villur í Kubernetes eða öðrum þáttum pallsins. Það tekur heldur ekki á neinum grundvallargöllum í örþjónustunni sem við erum að flytja. Vandamál koma oft einfaldlega vegna þess að við setjum saman mismunandi þætti.
Við blandum saman flóknum kerfum sem hafa aldrei haft samskipti sín á milli áður, og gerum ráð fyrir að saman muni þau mynda eitt, stærra kerfi. Því miður, því fleiri þættir, því meira pláss fyrir villur, því meiri óreiðu.
Í okkar tilviki var mikil leynd ekki afleiðing af villum eða slæmum ákvörðunum í Kubernetes, KIAM, AWS Java SDK eða örþjónustu okkar. Það var afleiðing þess að sameina tvær sjálfstæðar sjálfgefnar stillingar: önnur í KIAM, hin í AWS Java SDK. Báðar færibreyturnar eru teknar í sitthvoru lagi skynsamlegar: virka endurnýjunarstefnan í AWS Java SDK og stuttur gildistími skírteina í KAIM. En þegar þú setur þær saman verða niðurstöðurnar ófyrirsjáanlegar. Tvær sjálfstæðar og rökréttar lausnir þurfa ekki að vera skynsamlegar þegar þær eru sameinaðar.
PS frá þýðanda
Þú getur lært meira um arkitektúr KIAM tólsins til að samþætta AWS IAM við Kubernetes á frá höfundum þess.
Lestu líka á blogginu okkar:
- «»;
- «»;
- «»;
- «'.
Heimild: www.habr.com
