

Forsaga
Við höfum sjálfsala sem við hönnuðum sjálf. Inni í þeim er Raspberry Pi og einhver vélbúnaður á sérstakri borðplötu. Myntmóttakari, seðlamóttakari og hraðbanki eru öll tengd. Sérsmíðað forrit stjórnar öllu. Öll rekstrarsaga er skráð í skrá á USB-lykli (MicroSD), sem síðan er send yfir internetið (með USB-mótald) á netþjóninn, þar sem hún er geymd í gagnagrunni. Söluupplýsingar eru hlaðið inn í 1C, og þar er líka einfalt vefviðmót fyrir eftirlit o.s.frv.
Það er að segja, dagbókin er afar mikilvæg fyrir bókhald (tekjur, sölu o.s.frv.), eftirlit (alls kyns bilanir og aðrar óviðráðanlegar aðstæður); þetta, mætti segja, eru allar upplýsingar sem við höfum um þessa vél.
vandamálið
Minnislyklar hafa reynst mjög óáreiðanlegir tæki. Þeir bila með ógnvekjandi regluleika. Þetta leiðir bæði til niðurtíma véla og (ef af einhverjum ástæðum var ekki hægt að senda skráninguna á netið) gagnataps.
Þetta er ekki í fyrsta skipti sem við notum USB-lykla. Við unnum áður að öðru verkefni með yfir hundrað tækjum þar sem skráningin var geymd á USB-lykla. Þar komu einnig upp áreiðanleikavandamál, þar sem tugir diska biluðu stundum á mánuði. Við prófuðum ýmsar USB-lykla, þar á meðal vörumerkjalykla með SLC-minni, og sumar gerðir eru áreiðanlegri en aðrar, en að skipta um diskana leysti ekki vandamálið að fullu.
Attention! Langlesning! Ef þú hefur ekki áhuga á „hvers vegna“ heldur aðeins „hvernig“ geturðu sleppt lengra. greinar.
ákvörðun
Það fyrsta sem kemur upp í hugann er að losa sig við microSD kortið og, til dæmis, setja upp SSD disk og ræsa af honum. Fræðilega séð er það líklega mögulegt, en það er tiltölulega dýrt og ekki sérstaklega áreiðanlegt (USB-í-SATA millistykki er nauðsynlegt; bilanatíðnin fyrir ódýrar SSD diska er líka vonbrigði).
USB harður diskur virðist ekki vera sérstaklega aðlaðandi lausn heldur.
Við fundum því upp þennan möguleika: sleppum að ræsa af MicroSD-kortum, en notum þau í lesaðgangi og geymum aðgerðaskrána (og aðrar upplýsingar sem eru einstakar fyrir tiltekna vélbúnaðareiningu - raðnúmer, kvörðun skynjara o.s.frv.) einhvers staðar annars staðar.
Efnið skrifvarinn FS fyrir Raspberry Pi hefur þegar verið skoðað ítarlega, ég mun ekki dvelja mikið um útfærsluna í þessari grein. (en ef áhugi er fyrir hendi, þá skrifa ég kannski stutta grein um þetta efni)Eina atriðið sem ég vil koma á framfæri er að, bæði byggt á persónulegri reynslu og endurgjöf frá þeim sem hafa þegar innleitt þetta, þá er áreiðanleikaaukning í för með sér. Þótt ómögulegt sé að útrýma bilunum alveg er fullkomlega mögulegt að draga verulega úr tíðni þeirra. Þar að auki eru kortin að verða stöðluð, sem gerir viðhaldsfólki mun auðveldara að skipta þeim út.
Vélbúnaður
Það var enginn sérstakur vafi á vali á minnistegund - NOR Flash.
Rök:
- einföld tenging (oftast SPI-rútan, sem hefur þegar verið notuð, þannig að ekki er búist við neinum vélbúnaðarvandamálum);
- fáránlegt verð;
- staðlað stýrikerfi (innleiðing er þegar í kjarnanum) Linux, ef þú vilt geturðu tekið þriðja aðila, sem eru einnig til staðar, eða jafnvel skrifað þína eigin, sem betur fer er allt einfalt);
- áreiðanleiki og endingartími:
úr dæmigerðu gagnablaði: gögn eru geymd í 20 ár, 100000 eyðingarlotur fyrir hverja blokk;
frá þriðja aðila: afar lágt BER, engin þörf á villuleiðréttingarkóðum er talin vera tilgáta (Sumar greinar fjalla um ECC fyrir NOR, en þær eiga yfirleitt við MLC NOR, og það gerist líka).
Við skulum meta kröfur um rúmmál og auðlindir.
Við viljum tryggja að hægt sé að vista gögn í nokkra daga. Þetta er nauðsynlegt til að tryggja að söluferill glatist ekki ef upp koma vandamál með tenginguna. Við stefnum að því að það gildi í 5 daga. (jafnvel með hliðsjón af helgum og frídögum) vandamálið er hægt að leysa.
Við söfnum nú um 100 KB af skráningargögnum á dag (3-4 þúsund færslur), en þessi tala er smám saman að aukast eftir því sem nákvæmnin eykst og nýir atburðir bætast við. Auk þess verða einstaka toppar (til dæmis þegar skynjari byrjar að senda okkur falskar jákvæðar niðurstöður). Við munum reikna með 10 færslum sem eru 100 bæti hver — megabæti á dag.
Samtals eru þetta 5MB af hreinum (vel þjöppuðum) gögnum. Og svo eru það (gróft mat) 1 MB af þjónustugögnum.
Það þýðir að við þurfum 8MB örgjörva án þjöppunar, eða 4MB með þjöppun. Þetta eru nokkuð raunhæfar tölur fyrir þessa tegund minnis.
Hvað varðar auðlindina: ef við áætlum að minnið verði endurskrifað að fullu ekki oftar en einu sinni á 5 daga fresti, þá fáum við færri en þúsund endurskrifunarlotur á 10 ára þjónustu.
Leyfið mér að minna ykkur á að framleiðandinn lofar hundrað þúsund.
Lítið um NOR vs. NAND
NAND minni er vissulega vinsælla þessa dagana, en ég myndi ekki nota það í þetta verkefni: NAND, ólíkt NOR, krefst villuleiðréttingarkóða, gallaðra blokkatöflur o.s.frv., og NAND flísar hafa venjulega mun fleiri pinna.
Ókostir NOR eru meðal annars:
- lítið magn (og þar af leiðandi hátt verð á megabæti);
- lágur skiptihraði (aðallega vegna þess að notað er raðtengi, oftast SPI eða I2C);
- hæg eyðing (það tekur allt frá broti úr sekúndu upp í nokkrar sekúndur, allt eftir stærð blokkarinnar).
Það virðist sem ekkert sé aðkallandi fyrir okkur, svo við höldum áfram.
Ef þú hefur áhuga á smáatriðunum var örrás valin (Þetta skiptir þó ekki máli; það eru til fullt af svipuðum örgjörvum á markaðnum sem eru samhæfðar hvað varðar pinout og stjórnkerfi; jafnvel þótt við viljum setja upp örgjörva frá öðrum framleiðanda og/eða með aðra afkastagetu, þá mun allt virka án þess að breyta kóðanum).
Ég nota þann sem er innbyggður í kjarnanum Linux Rekstrarforrit, á Raspberry Pi, þökk sé stuðningi við yfirlagningu tækjatrésins, er allt mjög einfalt - þú þarft að setja þýdda yfirlagið í /boot/overlays og breyta /boot/config.txt örlítið.
Dæmi um dts skrá
Satt best að segja er ég ekki viss um að þetta sé skrifað án villna, en það virkar.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};Og önnur lína í config.txt
dtoverlay=at25:spimaxfrequency=50000000Ég sleppi því að vísa í tenginguna milli örgjörvans og Raspberry Pi. Annars vegar er ég enginn rafeindatæknifræðingur, en hins vegar er þetta allt frekar einfalt, jafnvel fyrir mig: örgjörvinn hefur aðeins 8 pinna, og af þeim þurfum við jarðtengingu, aflgjafa og SPI (CS, SI, SO, SCK). Stigin eru þau sömu og á Raspberry Pi og engin viðbótarvírun er nauðsynleg — tengdu einfaldlega sex pinnana sem eru tilgreindir.
Samsetning vandans
Eins og venjulega fer vandamálslýsingin í gegnum nokkrar endurtekningar og ég held að það sé kominn tími á aðra. Við skulum því staldra við, taka saman það sem þegar hefur verið skrifað og skýra öll óljós atriði sem eftir eru.
Við höfum því ákveðið að skráin verði geymd í SPI NOR Flash.
Hvað er NOR Flash fyrir þá sem ekki vita?
Þetta er óstöðugt minni sem hægt er að nota í þrjár aðgerðir:
- Lestur:
Algengasta lesturinn: við sendum vistfangið og lesum eins marga bæti og við þurfum; - Met:
Að skrifa í NOR flass lítur út eins og venjuleg aðgerð, en það hefur einn sérkenni: þú getur aðeins breytt 1 í 0, en ekki öfugt. Til dæmis, ef við höfðum 0x55 í minnisreit, þá eftir að hafa skrifað 0x0f í hann, mun hann nú innihalda 0x05. (sjá töflu hér að neðan); - Eyða:
Auðvitað þurfum við líka að geta framkvæmt öfuga aðgerð — að breyta 0 í 1. Þetta er einmitt það sem eyðingaraðgerðin er fyrir. Ólíkt fyrstu tveimur virkar hún á blokkum frekar en bætum (lágmarks eyðingarblokk í völdu örgjörva er 4 KB). Eyðing eyðir öllum blokkinni og þetta er eina leiðin til að breyta 0 í 1. Þess vegna, þegar unnið er með glampaminni, er oft nauðsynlegt að samræma gagnaskipan við mörk eyðingarblokkar.
Að skrifa í NOR Flash:
Tvíundargögn
Var
01010101
Upptekið
00001111
Hefur orðið
00000101
Skráin sjálf er röð færslna af breytilegri lengd. Algeng færsla er um 30 bæti (þó stundum séu færslur sem eru nokkur kílóbæti að lengd). Í þessu tilfelli erum við bara að vinna með þau sem safn af bætum, en ef þú hefur áhuga, þá er CBOR notað inni í færslunum.
Auk skrárinnar þurfum við að geyma nokkrar „stillingar“-upplýsingar, bæði uppfærðar og ekki: ákveðið auðkenni tækis, kvörðun skynjara, fánann „tæki er tímabundið óvirkt“ o.s.frv.
Þessar upplýsingar eru safn af lykilgildisfærslum, einnig geymdar í CBOR. Við höfum ekki mikið af þessum upplýsingum (í mesta lagi nokkur kílóbæt) og þær eru uppfærðar sjaldan.
Í framtíðinni munum við kalla það samhengi.
Ef þú manst hvernig þessi grein byrjaði, þá er mjög mikilvægt að tryggja áreiðanlega gagnageymslu og, ef mögulegt er, ótruflaðan rekstur jafnvel þótt bilun í vélbúnaði/gögnum verði spillt.
Hvaða uppsprettur vandamála má íhuga?
- Rafmagnsleysi á meðan á skrif-/eyðingaraðgerðum stendur. Þetta er tilfelli þar sem „engin vörn gegn kúbeini“ er til staðar.
Upplýsingar frá á stackexchange: þegar slökkt er á tækinu á meðan unnið er með flash, þá leiða bæði eyða (stillt á 1) og skrifa (stillt á 0) til óskilgreindrar hegðunar: gögn geta verið skrifuð, að hluta til skrifuð (segjum að við höfum flutt 10 bæti/80 bita, en aðeins 45 bitar voru skrifaðir), það er einnig mögulegt að sumir bitanna lendi í „millistigi“ (lestur getur gefið annað hvort 0 eða 1); - Villur í sjálfu flassminni.
BER, þótt mjög lágt, getur ekki verið jafnt núlli; - Strætóvillur
Gögn sem send eru með SPI eru ekki varin á nokkurn hátt; villur í einstökum bita og samstillingarvillur — tap eða innsetning bita (sem leiðir til mikillar gagnaskaðunar) — geta vel komið fyrir; - Aðrar villur/galla
Kóðavillur, hindberja-"gallar", inngrip geimvera...
Ég hef sett fram þær kröfur sem, að mínu mati, verður að uppfylla til að tryggja áreiðanleika:
- Skrár verða að vera skrifaðar í flassminni tafarlaust, seinkað skrif er ekki tekið með í reikninginn; - ef villa kemur upp verður að greina hana og vinna úr henni eins fljótt og auðið er; - kerfið verður, þegar mögulegt er, að jafna sig eftir villur.
(Dæmi úr raunveruleikanum um „hvernig það ætti ekki að vera“, sem ég held að allir hafi rekist á: eftir neyðarendurræsingu er skráarkerfið „bilað“ og stýrikerfið ræsist ekki)
Hugmyndir, aðferðir, vangaveltur
Þegar ég fór að hugsa um þetta vandamál komu upp nokkrar hugmyndir í hausinn á mér, til dæmis:
- nota gagnaþjöppun;
- nota snjallar gagnaskipanir, eins og að geyma færsluhausa aðskilda frá færslunum sjálfum, þannig að ef villa er í einni færslu sé hægt að lesa restina án vandræða;
- nota bitasvið til að stjórna skriflokum þegar slökkt er á rafmagninu;
- geyma tékkasummur fyrir allt og alla;
- nota einhvers konar villuleiðréttingarkóðun.
Sumar af þessum hugmyndum voru notaðar, aðrar voru yfirgefnar. Við skulum skoða þær í réttri röð.
Gagnaþjöppun
Atburðirnir sem við skráum í skránni eru nokkuð einsleitir og endurtakanlegir („kasta 5 rúblum,“ „ýta á skiptihnappinn“ o.s.frv.). Þess vegna ætti þjöppunin að vera nokkuð áhrifarík.
Þjöppunarkostnaður er hverfandi (örgjörvinn okkar er nokkuð öflugur; jafnvel upprunalegi Pi-inn hafði einn 700 MHz kjarna, en núverandi gerðir hafa marga kjarna sem keyra á yfir gígahertz), flutningshraðinn í geymslunni er lágur (nokkrir megabæt á sekúndu) og stærð gagnaskrárinnar er lítil. Í heildina litið, ef þjöppun hefur einhver áhrif á afköst, þá verða þau aðeins jákvæð. (algjörlega gagnrýnin, bara að segja það)Auk þess höfum við ekki raunverulegan innbyggðan, heldur venjulegan. Linux — þannig að útfærslan ætti ekki að krefjast mikillar fyrirhafnar (það er nóg að tengja bara bókasafnið og nota nokkur föll úr því).
Gögn úr skráningu voru tekin af virku tæki (1.7 MB, 70 þúsund færslur) og fyrst kannað hvort þau væru þjappanleg með því að nota gzip, lz4, lzop, bzip2, xz, zstd sem eru tiltæk á tölvunni.
- gzip, xz og zstd sýndu svipaðar niðurstöður (40Kb).
Ég var hissa á því að tískufyrirbærið xz birtist hér á stigi gzip eða zstd; - lzip með sjálfgefnum stillingum gaf aðeins verri niðurstöður;
- lz4 og lzop sýndu ekki mjög góðar niðurstöður (150Kb);
- bzip2 sýndi ótrúlega góða niðurstöðu (18Kb).
Þannig að gögnin þjappast mjög vel saman.
Svo (nema við finnum einhverja alvarlega galla) þá verður þjöppun möguleg! Einfaldlega vegna þess að sama USB-lykillinn geymir meiri gögn.
Við skulum hugsa um ókostina.
Fyrsta vandamálið: við höfum þegar komið okkur saman um að hver skrif skuli strax skrifuð á flash-disk. Venjulega safnar skjalasafnari gögnum úr inntaksstraumnum þar til hann ákveður að tími sé kominn til að skrifa í úttaksstrauminn. Við þurfum strax að sækja þjappaðan gagnablokk og geyma hann í stöðugu minni.
Ég sé þrjár leiðir:
- Þjappaðu hverri færslu með orðabókarþjöppun í stað reiknirita sem rætt er um hér að ofan.
Þetta er fullkomlega raunhæfur kostur, en mér líkar það ekki. Til að ná sæmilegri þjöppun verður orðabókin að vera sniðin að tilteknum gögnum; allar breytingar munu leiða til stórkostlegrar lækkunar á þjöppun. Já, að búa til nýja útgáfu af orðabókinni leysir vandamálið, en það er mikill höfuðverkur - við þyrftum að geyma allar útgáfur orðabókarinnar; hver færsla þyrfti að tilgreina með hvaða orðabókarútgáfu hún var þjappuð... - Þjappa hverri færslu með „hefðbundnum“ reikniritum, en óháð öðrum.
Þjöppunarreikniritin sem hér eru til skoðunar eru ekki hönnuð til að vinna með færslur af þessari stærð (tugir bæta); þjöppunarhlutfallið verður greinilega minna en 1 (þ.e. aukning á gagnamagni í stað þjöppunar); - SKOLAÐU eftir hverja færslu.
Margar þjöppunarbókasöfn styðja FLUSH. Þetta er skipun (eða breyta fyrir þjöppunarferlið) sem, þegar hún er móttekin, býr skjalasafnsforritið til þjappaðan straum svo hægt sé að nota hann til endurheimtar. allt óþjöppuð gögn sem þegar hafa borist. Þessi hliðstæðasyncí skráarkerfum eðacommití SQL.
Það sem skiptir máli er að síðari þjöppunaraðgerðir geta notað uppsafnaða orðabókina og þjöppunarhlutfallið mun ekki þjást eins mikið og í fyrri útgáfu.
Ég held að það sé augljóst að ég valdi þriðja kostinn, við skulum skoða hann nánar.
Fundið um FLUSH í zlib.
Ég gerði hnjápróf byggt á greininni og tók 70 færslur í færslubók úr raunverulegu tæki, með síðustærð upp á 60 KB. (Við komum aftur að síðustærð síðar) móttekið:
Upphafleg gögn
Gzip -9 þjöppun (engin FLUSH)
zlib með Z_PARTIAL_FLUSH
zlib með Z_SYNC_FLUSH
Rúmmál, KB
1692
40
352
604
Við fyrstu sýn virðist kostnaðurinn við FLUSH óhóflegur, en í raun höfum við takmarkaðan kost: annað hvort enga þjöppun yfirleitt eða þjöppun (og nokkuð áhrifarík) með FLUSH. Hafðu í huga að við höfum 70 færslur og afritunin sem Z_PARTIAL_FLUSH kynnir er aðeins 4-5 bæti á hverja færslu. Og þjöppunarhlutfallið reyndist vera næstum 5:1, sem er meira en frábært.
Það kann að virðast óvænt, en Z_SYNC_FLUSH er í raun skilvirkari leið til að framkvæma FLUSH.
Þegar Z_SYNC_FLUSH er notað verða síðustu fjórir bætirnir í hverri færslu alltaf 0x00, 0x00, 0xff, 0xff. Ef við þekkjum þessi gildi þurfum við ekki að geyma þau, þannig að lokastærðin er aðeins 324 KB.
Greinin sem ég vísaði á útskýrir þetta:
Nýrri blokk af gerð 0 með tómu innihaldi er bætt við.
Blokk af gerð 0 með tómu innihaldi samanstendur af:
- þriggja bita blokkarhausinn;
- 0 til 7 bitar jafngildir núlli, til að ná bætijöfnun;
- fjögurra bæti röðin 00 00 FF FF.
Eins og þú sérð, þá eru á milli 3 og 10 núllbitar á undan þessum 4 bætum í síðasta blokkinni. Hins vegar hefur reynslan sýnt að það eru í raun að minnsta kosti 10 núllbitar.
Það kemur í ljós að slíkir stuttir gagnablokkir eru venjulega (alltaf?) kóðaðir með blokk af gerð 1 (föstum blokkum), sem endar alltaf með 7 núllbitum, sem leiðir til 10-17 tryggðra núllbita (og restin verður núll með um 50% líkindum).
Þannig að í prófunargögnunum, í 100% tilfella, fyrir 0x00, 0x00, 0xff, 0xff er eitt núllbæti, og í meira en þriðjungi tilfella eru tvö núllbæti. (kannski er vandamálið að ég er að nota tvíundakóða í CBOR, og ef ég væri að nota texta-JSON, myndi ég oftar rekast á blokkir af gerðinni 2 - kraftmiklar blokkir, og því myndi ég rekast á blokkir án viðbótar núllbæta fyrir 0x00, 0x00, 0xff, 0xff).
Í heildina, með því að nota tiltæk prófunargögn, er hægt að passa inn í minna en 250 KB af þjöppuðum gögnum.
Við getum sparað meira með því að jonglera með bitum: nú hunsum við tilvist nokkurra núllbita í lok blokkar og nokkrir bitar í upphafi blokkar eru einnig óbreyttir…
En hér tók ég staðfasta ákvörðun um að hætta, annars gæti ég á þessum hraða endað með að þróa minn eigin skjalavörpu.
Í heildina fékk ég 3-4 bæti á hverja færslu úr prófunargögnunum mínum, sem leiddi til þjöppunarhlutfalls upp á yfir 6:1. Heiðarlega, ég bjóst ekki við slíkri niðurstöðu; að mínu mati er allt betra en 2:1 þegar niðurstaða sem réttlætir notkun þjöppunar.
Allt er frábært, en zlib (deflate) er ennþá gamaldags, vel skilið og nokkuð gamaldags þjöppunarreiknirit. Sú staðreynd að það notar síðustu 32 KB af óþjöppuðu gagnastraumnum sem orðabók virðist undarleg í dag (þ.e. ef gagnablokk er mjög lík því sem var í inntaksstraumnum fyrir 40 KB síðan, þá byrjar hún að þjappa aftur frekar en að vísa í fyrri færsluna). Í nútíma skjalasafnsforritum er stærð orðabókar oft mæld í megabætum frekar en kílóbætum.
Svo skulum við halda áfram með litla rannsókn okkar á skjalasafnsfyrirtækjum.
Næst prófaði ég bzip2 (munið að án FLUSH sýndi það frábært þjöppunarhlutfall, næstum 100:1). Því miður virkaði það mjög illa með FLUSH; þjappaða gögnin enduðu á að vera stærri en þau óþjöppuðu.
Vangaveltur mínar um ástæður bilunarinnar
Libbz2 býður aðeins upp á einn hreinsunarmöguleika, sem virðist hreinsa orðabókina (svipað og Z_FULL_FLUSH í zlib), svo það er enginn tilgangur að tala um neina virka þjöppun eftir það.
Og að lokum prófaði ég zstd. Það þjappar annað hvort á sama stigi og gzip, en miklu hraðar, eða betur en gzip, allt eftir stillingum.
Því miður, með FLUSH gekk það heldur ekki mjög vel: þjappaða gagnastærðin var um 700 KB.
Я Á Github síðu verkefnisins fékk ég svarið að búast mætti við allt að 10 bæti af þjónustugögnum fyrir hvern blokk af þjöppuðum gögnum, sem er nálægt þeim niðurstöðum sem fengust; það verður ekki hægt að ná í deflate.
Á þessum tímapunkti ákvað ég að hætta að gera tilraunir með skjalasafnsforrit (leyfið mér að minna ykkur á að xz, lzip, lzo og lz4 sýndu ekki gildi sitt jafnvel á prófunarstigi án FLUSH, og ég íhugaði ekki fleiri framandi þjöppunaralgrím).
Við skulum snúa okkur aftur að vandamálunum við skjalavörslu.
Annað vandamálið (eins og fram kemur í röð, ekki mikilvægi) er að þjöppuð gögn eru ein straumur sem vísar stöðugt til fyrri hluta. Þess vegna, ef hluti af þjöppuðum gögnum skemmist, týnum við ekki aðeins tengdum blokk af óþjöppuðum gögnum, heldur einnig öllum síðari blokkum.
Það eru til aðferðir til að leysa þetta vandamál:
- Að koma í veg fyrir vandamál þýðir að bæta við afritun í þjappaða gögnin til að gera kleift að greina og leiðrétta villur; við munum ræða þetta síðar;
- Lágmarka afleiðingar ef vandamál koma upp
Við höfum þegar nefnt að hægt er að þjappa hverjum gagnablokk fyrir sig, sem myndi útrýma vandamálinu (gagnaspilling í einum blokk myndi aðeins leiða til þess að sá blokk tapast). Hins vegar er þetta öfgatilvik, sem gerir gagnaþjöppun óvirka. Hin öfgakennda: að nota öll 4 MB af örgjörvanum okkar sem eitt skjalasafn, sem myndi veita framúrskarandi þjöppun en hafa skelfilegar afleiðingar ef gagnaspilling á sér stað.
Já, það þarf að gera málamiðlun hvað varðar áreiðanleika. En við verðum að muna að við erum að þróa gagnageymsluform fyrir stöðugt minni með afar lágu BER og yfirlýstum gagnageymslutíma upp á 20 ár.
Í tilraunum mínum uppgötvaði ég að meira og minna áberandi tap á þjöppunarstigi byrjar með blokkum af þjöppuðum gögnum sem eru minni en 10 KB að stærð.
Það var áður nefnt að minnið sem notað er er síðubundið, ég sé enga ástæðu til að nota ekki vörpunina „ein síða - einn blokk af þjöppuðum gögnum“.
Þetta þýðir að lágmarksstærð síðunnar er 16 KB (með einhverjum kostnaðarliðum). Hins vegar setur svo lítil síðustærð miklar takmarkanir á hámarksstærð færslunnar.
Þó að ég búist ekki við að hafa neinar færslur stærri en nokkur kílóbæt í þjappaðri mynd, ákvað ég að nota 32 KB síður (sem gefur mér 128 síður á hverja flís).
Yfirlit:
- Við geymum þjöppuð gögn með zlib (deflate);
- Fyrir hverja færslu setjum við Z_SYNC_FLUSH;
- Fyrir hverja þjappaða færslu klippum við út bæti sem fylgja. (til dæmis, 0x00, 0x00, 0xff, 0xff); í hausnum tilgreinum við hversu mörg bæti við klippum burt;
- Við geymum gögn á 32 KB síðum; innan hverrar síðu er einn straumur af þjöppuðum gögnum; þjöppunin er endurræst á hverri síðu.
Og áður en ég lýk þjöppuninni vil ég benda á að við fáum aðeins nokkur bæti af þjöppuðum gögnum í hverri færslu, svo það er afar mikilvægt að blása ekki upp þjónustuupplýsingarnar; hvert bæti skiptir máli hér.
Geymsla gagnahausa
Þar sem við höfum færslur af breytilegri lengd þurfum við einhvern veginn að ákvarða staðsetningu/mörk færslnanna.
Ég þekki þrjár aðferðir:
- Allar færslur eru geymdar í samfelldum straumi, fyrst kemur færsluhausinn sem inniheldur lengdina og síðan færslan sjálf.
Í þessari útgáfu geta bæði hausar og gögn verið af breytilegri lengd.
Í meginatriðum fáum við einn tengdan lista sem er notaður allan tímann; - Hausar og færslur sjálfar eru geymdar í aðskildum straumum.
Með því að nota hausa með fastri lengd tryggjum við að spilling eins hauss hafi ekki áhrif á aðra.
Svipuð aðferð er notuð, til dæmis, í mörgum skráarkerfum; - Skrár eru geymdar í samfelldum straumi, þar sem færslumörk eru skilgreind með merki (stafur eða röð af stöfum sem er bannaður innan gagnablokka). Ef merki finnst innan færslu, skiptum við því út fyrir ákveðna röð (escape-merki).
Svipuð aðferð er notuð til dæmis í PPP-samskiptareglunum.
Leyfðu mér að útskýra þetta.
Valkostur 1:

Þetta er allt mjög einfalt: með því að vita lengd færslunnar getum við reiknað út vistfang næsta haus. Við förum í gegnum hausana þar til við rekumst á svæði fyllt með 0xff (lausu plássi) eða enda síðunnar.
Valkostur 2:

Vegna breytilegrar færslulengdar getum við ekki spáð fyrir um hversu margar færslur (og þar með hausa) við þurfum á hverri síðu. Við gætum skipt hausunum og gögnunum yfir mismunandi síður, en ég kýs aðra nálgun: við setjum bæði hausa og gögn á eina síðu, en hausarnir (með fastri lengd) byrja efst á síðunni og gögnin (með breytilegri lengd) byrja neðst. Um leið og þeir „mætast“ (það er ekki nóg pláss fyrir nýja færslu) teljum við síðan vera full.
Valkostur 3:

Það er engin þörf á að geyma lengd eða aðrar upplýsingar um staðsetningu gagna í hausnum; merki sem gefa til kynna mörk færslna eru nægjanleg. Hins vegar verður að vinna úr gögnunum þegar þau eru skrifuð/lesin.
Ég myndi nota 0xff (sem er það sem síðan fyllist með eftir eyðingu) sem merki, þannig að laust svæði verði alls ekki meðhöndlað sem gögn.
Samanburðartafla:
Valkostur 1
Valkostur 2
Valkostur 3
Villuþol
-
+
+
Samkvæmni
+
-
+
Erfiðleikar við framkvæmd
*
**
**
Valkostur 1 hefur alvarlegan galla: ef einhver haus skemmist, þá eyðileggst öll síðari keðjan. Hinir valkostir leyfa að hluta til endurheimt gagna, jafnvel þótt umfangsmikil skemmd sé að ræða.
En hér er rétt að hafa í huga að við ákváðum að geyma gögnin í þjappaðri mynd, og samt sem áður týnum við öllum gögnum á síðunni eftir „brotna“ skrá, svo jafnvel þótt það sé mínus í töflunni, þá tökum við það ekki með í reikninginn.
Þéttleiki:
- Í fyrsta valkostinum þurfum við aðeins að geyma lengdina í hausnum; ef við notum heiltölur með breytilegri lengd, þá getum við í flestum tilfellum komist af með eitt bæti;
- Í seinni valkostinum þurfum við að geyma upphafsvistfangið og lengdina; færslan verður að vera af fastri stærð, ég áætla 4 bæti á hverja færslu (tvö bæti fyrir offsetið og tvö bæti fyrir lengdina);
- Þriðji kosturinn krefst aðeins eins stafs til að gefa til kynna upphaf færslu, auk þess sem færslan sjálf mun stækka um 1-2% vegna escape. Í heildina er þetta nokkurn veginn sambærilegt við fyrsta kostinn.
Í fyrstu leit ég á seinni kostinn sem aðalkostinn (og skrifaði jafnvel útfærslu). Ég hætti ekki við hann fyrr en ég ákvað loksins að nota þjöppun.
Kannski nota ég svipaðan valkost einhvern tímann. Til dæmis, ef ég þarf að geyma gögn fyrir geimfar sem ferðast milli Jarðar og Mars — gjörólíkar áreiðanleikakröfur, geimgeislun, ...
Hvað varðar þriðja valkostinn: Ég gaf honum tvær stjörnur fyrir flækjustig útfærslunnar einfaldlega vegna þess að mér líkar ekki að fikta í að nota „escape“, breyta lengdinni mitt í ferli o.s.frv. Já, ég gæti verið hlutdrægur, en ég verð að skrifa kóðann - af hverju að neyða mig til að gera eitthvað sem mér líkar ekki.
Yfirlit: Við veljum geymsluvalkostinn í formi keðja „haus með lengd - gögn af breytilegri lengd“ vegna skilvirkni hans og auðveldrar útfærslu.
Notkun bitareita til að fylgjast með árangri skrifaðgerða
Ég man ekki núna hvaðan ég fékk hugmyndina, en hún lítur einhvern veginn svona út:
Fyrir hverja færslu úthlutum við nokkrum bita til að geyma fána.
Eins og við sögðum áðan, eftir eyðingu eru allir bitar fylltir með 1, og við getum breytt 1 í 0, en ekki öfugt. Svo fyrir „fáni ekki settur“ notum við 1, fyrir „fáni settur“ notum við 0.
Svona gæti það litið út að setja inn breytilega lengdar færslu í flash:
- Settu fánann „lengdarupptaka hafin“;
- Við skrifum niður lengdina;
- Við setjum fánann „gagnaskráning hefur hafist“;
- Við skrifum gögn;
- Við settum fánann „upptöku lokið“.
Að auki munum við hafa fána sem segir „villa kom upp“, fyrir samtals 4 bita fána.
Í þessu tilviki höfum við tvær stöðugar stöður: „1111“ (upptaka hefur ekki hafist) og „1000“ (upptaka tókst). Ef óvænt truflun verður á upptökuferlinu fáum við millistöður sem við getum síðan greint og unnið úr.
Aðferðin er áhugaverð, en hún verndar aðeins gegn skyndilegum rafmagnsleysi og svipuðum bilunum, sem er auðvitað mikilvægt, en þetta er langt frá því að vera eina (og ekki einu sinni aðal) ástæðan fyrir hugsanlegum bilunum.
Yfirlit: Höldum áfram í leit að góðri lausn.
Tékkafjárhæðir
Eftirlitssummur veita einnig leið til að staðfesta (með nokkuð vissu) að við séum að lesa nákvæmlega það sem hefði átt að vera skrifað. Og ólíkt bitreitunum sem rætt var um hér að ofan virka þær alltaf.
Ef við skoðum listann yfir mögulegar uppsprettur vandamála sem við ræddum hér að ofan, þá er eftirlitssumman fær um að greina villu óháð uppruna hennar. (nema kannski illgjarnir geimverur - þeir geta líka falsað eftirlitssummuna).
Svo ef markmið okkar er að staðfesta að gögnin séu óskemmd, þá eru eftirlitssummur frábær hugmynd.
Valið á reikniritinu fyrir útreikning á eftirlitsummu var einfalt — CRC. Annars vegar leyfa stærðfræðilegir eiginleikar þess 100% greiningu á ákveðnum tegundum villna; hins vegar sýnir þetta reiknirit yfirleitt árekstrarlíkur sem eru ekki mikið hærri en fræðileg mörk á tilviljunarkenndum gögnum.  Þetta er kannski ekki hraðasta reikniritið, eða alltaf það með fæstu árekstrana, en það hefur einn mjög mikilvægan eiginleika: í þeim prófunum sem ég hef rekist á hef ég ekki rekist á nein mynstur sem greinilega ollu því að það bilaði. Stöðugleiki er lykilatriðið hér.
Þetta er kannski ekki hraðasta reikniritið, eða alltaf það með fæstu árekstrana, en það hefur einn mjög mikilvægan eiginleika: í þeim prófunum sem ég hef rekist á hef ég ekki rekist á nein mynstur sem greinilega ollu því að það bilaði. Stöðugleiki er lykilatriðið hér.
Dæmi um rúmmálsrannsókn: , (tenglar á narod.ru, afsakið).
Hins vegar er verkið við að velja eftirlitsummu ekki lokið; CRC er heil fjölskylda eftirlitsumma. Við þurfum að ákveða lengdina og velja síðan margliðu.
Að velja lengd eftirlitssummu er ekki eins einfalt mál og það virðist við fyrstu sýn.
Leyfðu mér að útskýra þetta:
Við skulum hafa líkurnar á villu í hverjum bæti  og hugsjónarprófsumman, reiknum út meðalfjölda villna á hverja milljón færslna:
og hugsjónarprófsumman, reiknum út meðalfjölda villna á hverja milljón færslna:
Gögn, bæti
Eftirlitssumma, bæti
Óuppgötvuð villur
Falskar villugreiningar
Heildarfjöldi rangra svara
1
0
1000
0
1000
1
1
4
999
1003
1
2
0
1997
1997
1
4
0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
0
1979
1979
10
4
0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
0
1469
1469
Það virðist einfalt: veldu lengd eftirlitssummu með lágmarki falskra jákvæðra niðurstaðna miðað við lengd gagnanna sem verið er að vernda, og þú ert búinn.
Hins vegar eru stuttar eftirlitsummur vandamál: þótt þær séu góðar í að greina villur í einstökum bita, geta þær, með frekar mikilli líkindum, rangfært algjörlega handahófskenndar upplýsingar sem gildar. Það var þegar grein á Habr sem lýsti þessu. .
Þess vegna, til að gera handahófskennda pörun á eftirlitssummum nánast ómögulega, ætti að nota eftirlitssummur sem eru 32 bita eða fleiri. (fyrir lengdir sem eru lengri en 64 bitar eru dulritunar-kjöltunarföll venjulega notuð).
Þrátt fyrir að ég hafi skrifað áðan að við þurfum að spara pláss hvað sem það kostar, munum við samt nota 32-bita eftirlitssummu (16 bitar eru ekki nóg, líkurnar á árekstri eru meiri en 0.01%; og 24 bitar, eins og sagt er, eru hvorki hér né þar).
Hér gæti komið upp mótbára: vistuðum við virkilega hvert einasta bæti þegar við völdum þjöppun, bara til að þurfa nú að gefa frá okkur fjögur bæti í einu? Hefði ekki verið betra að þjappa ekki eða bæta við eftirlitssummu? Auðvitað ekki, engin þjöppun. þýðir ekki, að við þurfum ekki heiðarleikaeftirlit.
Varðandi val á margliðu, þá munum við ekki finna upp hjólið á ný, heldur taka vinsæla CRC-32C sem er nú til dags.
Þessi kóði greinir 6 bita villur í pökkum allt að 22 bæti (líklega algengasta tilfellið hjá okkur), 4 bita villur í pökkum allt að 655 bæti (einnig algengt tilfelli hjá okkur), 2 eða hvaða oddatölu sem er af bitavillum í pökkum af hvaða hæfilegri lengd sem er.
Ef einhver hefur áhuga á smáatriðunum
um CRC.
á — kannski fremsti sérfræðingur í CRC á jörðinni.
В есть , sem veitir aðeins betri breytur fyrir pakkalengdirnar sem skipta okkur máli, en ég taldi muninn ekki mikinn og ég taldi mig ekki nógu hæfan til að velja sérsniðinn kóða frekar en staðlaðan og vel rannsakaðan kóða.
Þar sem gögnin okkar eru þjöppuð vaknar spurningin: ættum við að reikna út eftirlitssummu þjappaðra eða óþjappaðra gagna?
Rök fyrir því að reikna út eftirlitsummu óþjappaðra gagna:
- Við þurfum að lokum að athuga heilleika gagnageymslunnar - þannig að við athugum hana beint (á sama tíma verða mögulegar villur í framkvæmd þjöppunar/afþjöppunar, skemmdir af völdum lélegs minnis o.s.frv. athugaðar);
- Reikniritið fyrir deflate í zlib hefur frekar þroskaða útfærslu og ætti ekki hrun með „skökkum“ inntaksgögnum, auk þess er það oft fært um að greina sjálfstætt villur í inntaksstraumnum, sem dregur úr heildarlíkum á að villa verði ekki greind (ég framkvæmdi próf með umsnúningu á einum bita í stuttri skrá, zlib greindi villu í um þriðjungi tilfella).
Rök gegn því að reikna út eftirlitsummu óþjappaðra gagna:
- CRC er sérstaklega hannað fyrir þær fáu bitavillur sem eru dæmigerðar fyrir flassminni (bitavilla í þjöppuðum straumi getur valdið mikilli breytingu á úttaksstraumnum, sem við getum, eingöngu fræðilega séð, „gripið“ árekstur á);
- Mér líkar ekki hugmyndin um að senda hugsanlega skemmd gögn í þjöppunartækið, , hvernig hann mun bregðast við.
Í þessu verkefni ákvað ég að víkja frá almennt viðurkenndri venju að geyma eftirlitssummu óþjöppuð gögn.
Yfirlit: Við notum CRC-32C, við reiknum út eftirlitssummu út frá gögnunum á því formi sem þau eru skrifuð á flassið (eftir þjöppun).
Offramboð
Notkun afritunarkóðunar útilokar auðvitað ekki gagnatap; hins vegar getur hún dregið verulega (oft um margar stærðargráður) úr líkum á óbætanlegu gagnatapi.
Við getum notað mismunandi gerðir af afritun til að leiðrétta villur.
Hamming kóðar geta leiðrétt villur í einstökum bita, Reed-Solomon kóðar geta verið táknrænir, margar eintök af gögnum ásamt eftirlitssummum, eða kóðun eins og RAID-6 getur hjálpað til við að endurheimta gögn jafnvel þótt um mikla spillingu sé að ræða.
Í fyrstu var ég tilhneigður til að nota villuleiðréttingarkóðun víða, en svo áttaði ég mig á því að fyrst þyrftum við að hafa hugmynd um hvaða villur við viljum verjast og síðan velja kóðunina.
Við nefndum áðan að villur þurfa að vera greind eins fljótt og auðið er. Hvenær er líklegt að við rekumst á villur?
- Ókláruð upptaka (af einhverri ástæðu fór rafmagnið af meðan á upptöku stóð, Raspberry Pi fraus o.s.frv.)
Því miður, ef slík villa kemur upp, er eini kosturinn að hunsa ógildar færslur og líta svo á að gögnin hafi glatast; - Skrifvillur (af einhverri ástæðu var eitthvað annað en það sem var skrifað skrifað í flassminnið)
Við getum strax greint slíkar villur ef við gerum samanburðarmælingu strax eftir upptöku; - Gögn spillt í minni við geymslu;
- Lestrarvillur
Til að leiðrétta villuna, ef eftirlitssumman passar ekki, er nóg að endurtaka lesturinn nokkrum sinnum.
Þetta þýðir að aðeins villur af gerð 3 (sjálfsprottin gagnaskað við geymslu) er ekki hægt að leiðrétta án villuleiðréttingarkóðunar. Það virðist sem slíkar villur séu enn afar ólíklegar.
Yfirlit: Ákveðið var að hætta við óþarfa kóðun, en ef aðgerðin sýnir að sú ákvörðun er röng, þá munum við snúa aftur að því að skoða málið (með þegar safnaðri tölfræði um bilanir, sem gerir okkur kleift að velja bestu gerð kóðunar).
Annað
Að sjálfsögðu leyfir snið greinarinnar ekki að réttlæta alla hluta í sniðinu. (og ég er nú þegar orðinn þreyttur), svo ég mun í stuttu máli fara yfir nokkur atriði sem ekki var minnst á áður.
- Það var ákveðið að gera allar síður „jafnar“
Það er að segja, það verða engar sérstakar síður með lýsigögnum, aðskildir straumar o.s.frv., heldur einn straumur sem endurskrifar allar síður í röð.
Þetta tryggir jafnt slit á síðunum, engan einn bilunarpunkt og það er bara fínt; - Það er nauðsynlegt að sjá fyrir útgáfustjórnun sniða.
Snið án útgáfunúmers í hausnum er illt!
Það er nóg að bæta við reit með ákveðinni töfratölu (undirskrift) í síðuhausinn, sem mun gefa til kynna útgáfu sniðsins sem notuð er. (Ég held ekki að það verði einu sinni tylft af þeim í æfingunni); - Notið haus með breytilegri lengd fyrir færslur (sem eru margar af), og reynið að gera hann 1 bæti að lengd í flestum tilfellum;
- Til að umrita lengd haussins og lengd stytta hluta þjappaða færslunnar skal nota tvíundarkóða með breytilegri lengd.
Það var mjög gagnlegt Huffman kóðar. Á aðeins nokkrum mínútum gátum við fundið nauðsynlega kóða af breytilegri lengd.
Lýsing á gagnageymslusniði
Bætaröð
Reitir stærri en einn bæti eru geymdir í big-endian sniði (netbætaröð), það er að segja, 0x1234 er skrifað sem 0x12, 0x34.
Skipting í síður
Allt flassminni er skipt í jafnstórar síður.
Sjálfgefin síðustærð er 32 KB, en ekki meira en 1/4 af heildarstærð minnisflögunnar (fyrir 4 MB flís þýðir þetta 128 síður).
Hver síða geymir gögn óháð hinum (þ.e. gögnin á einni síðu vísa ekki til gagna á annarri síðu).
Allar síður eru númeraðar í eðlilegri röð (í hækkandi röð eftir heimilisföngum), byrjandi á númerinu 0 (síða núll byrjar á heimilisfangi 0, sú fyrsta á 32 KB, sú seinni á 64 KB, o.s.frv.)
Minnisflísin er notuð sem hringlaga biðminni, það er að segja, fyrst fer upptakan á síðu 0, síðan á síðu 1, ..., þegar við fyllum síðustu síðuna hefst nýr hringur og upptakan heldur áfram frá síðu núll.
Inni á síðunni

Í upphafi síðunnar er 4 bæta síðuhaus geymdur, síðan hausprófunarsumma (CRC-32C) og að lokum eru færslur geymdar á sniðinu „haus, gögn, prófunarsumma“.
Síðuhausinn (óhreinn grænn á myndinni) samanstendur af:
- tveggja bæta töfratölusvið (einnig þekkt sem sniðsútgáfuvísir)
fyrir núverandi útgáfu sniðsins er það talið vera0xed00 ⊕ номер страницы; - tveggja bæta teljari „Síðuútgáfa“ (númer endurskrifunarferlis minnis).
Færslur á síðu eru geymdar í þjappaðri mynd (með því að nota deflate reiknirit). Allar færslur á einni síðu eru þjappaðar í einum straumi (með því að nota sameiginlega orðabók) og þjöppun hefst upp á nýtt á hverri nýrri síðu. Þetta þýðir að til að afþjappa hvaða færslu sem er þarf að nota allar fyrri færslur af þeirri síðu (og aðeins þá síðu).
Hver færsla verður þjöppuð með Z_SYNC_FLUSH fánanum, sem leiðir til þess að þjappaða straumurinn endar með 4 bætum 0x00, 0x00, 0xff, 0xff, hugsanlega á undan einum eða tveimur núllbætum í viðbót.
Við sleppum þessari röð (4, 5 eða 6 bæti að lengd) þegar við skrifum í flassminni.
Færsluhausinn er 1, 2 eða 3 bæti og geymir:
- einn biti (T) sem gefur til kynna gerð færslu: 0 - samhengi, 1 - log;
- Reitur með breytilegri lengd (S) frá 1 til 7 bitum, sem skilgreinir lengd haussins og „halans“ sem á að bæta við færsluna til að pakka upp;
- lengd færslu (L).
Tafla yfir S gildi:
S
Lengd hauss, bæti
Fjarlægt við skrif, bæti
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
Ég reyndi að útskýra þetta en veit ekki hversu skýrt það varð:
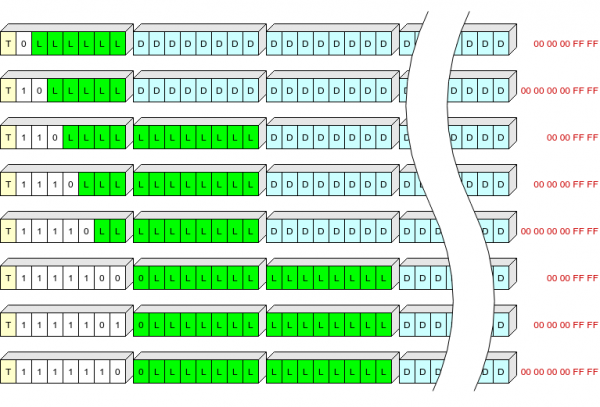
Hér er T reiturinn merktur með gulu, S reiturinn með hvítu, L (lengd þjappaðra gagnanna í bætum) með grænu, þjappað gögnin með bláu og síðustu bætin af þjappaða gagnunum sem eru ekki skrifuð í flassminnið með rauðu.
Þannig getum við skrifað færsluhausa af algengustu lengd (allt að 63+5 bæti í þjappaðri mynd) í einum bæti.
Eftir hverja skrif er CRC-32C prófsumma geymd, sem notar öfugt gildi fyrri prófsummu sem upphafsgildi (init).
CRC hefur eiginleikann „lengd“, eftirfarandi formúla virkar (plús eða mínus bitahringing í ferlinu):  .
.
Það er að segja, við reiknum í raun CRC allra fyrri hausbæta og gagna á þessari síðu.
Strax á eftir eftirlitssummunni er haus næstu færslu.
Hausinn er hannaður þannig að fyrsti bæti hans er alltaf frábrugðinn 0x00 og 0xff (ef við rekumst á 0xff í stað fyrsta bætis haussins þýðir það að þetta er ónotað svæði; 0x00 gefur til kynna villu).
Nálægir reiknirit
Að lesa úr glampaminni
Öllum aflestri fylgir eftirlitssumma.
Ef prófsumman stemmir ekki er lesturinn endurtekinn nokkrum sinnum í von um að lokum lesi réttu gögnin.
(það er rökrétt, Linux Geymir ekki mælingar úr NOR Flash skyndiminni, staðfest)
Að skrifa í flassminni
Við skrifum niður gögnin.
Við skulum lesa þau.
Ef lesnu gögnin stemma ekki við skrifuðu gögnin, fyllum við svæðið með núllum og merkjum um villu.
Undirbúningur nýrrar örrásar fyrir notkun
Til frumstillingar er haus með útgáfu 1 skrifaður á fyrstu (nákvæmara sagt, núll) síðuna.
Eftir þetta er upphafssamhengið (sem inniheldur UUID vélarinnar og sjálfgefnar stillingar) skrifað á þessa síðu.
Það er það, glampaminnið er tilbúið til notkunar.
Að hlaða vélina
Við hleðslu eru fyrstu 8 bætin af hverri síðu (haus + CRC) lesin; síður með óþekktri töfratölu eða ógildri CRC eru hunsaðar.
Af „réttu“ síðunum eru síður með hámarksútgáfunni valdar og af þeim er síðan með hæstu tölunni tekin.
Fyrsta færslan er lesin, CRC-skráin er athugað hvort hún sé rétt og „samhengis“-fáninn er til staðar. Ef allt er í lagi telst þessi síða vera uppfærð. Ef ekki, förum við aftur á fyrri síðu þar til við finnum „virka“ síðu.
og á síðunni sem finnst lesum við allar færslurnar, þær sem eru merktar með „samhengi“ notum við.
Við vistum zlib orðabókina (hann þarf til að bæta henni við þessa síðu).
Það er það, niðurhalið er lokið, samhengið er endurheimt, þú getur unnið.
Bæta við færslu í skráningu
Við þjöppum færsluna með réttri orðabók, tilgreindum Z_SYNC_FLUSH. Við athugum hvort þjappaða færslan passi á núverandi síðu.
Ef það passar ekki (eða ef CRC-villur voru á síðunni), byrjaðu þá á nýrri síðu (sjá hér að neðan).
Við skrifum færsluna og CRC-skrána. Ef villa kemur upp byrjum við á nýrri síðu.
Ný síða
Við veljum lausa síðu með lægstu tölunni (við teljum síðu með ógildri prófsummu í hausnum eða útgáfu sem er eldri en sú núverandi) vera lausa. Ef engar slíkar síður eru til staðar veljum við síðuna með lægstu tölunni meðal þeirra sem eru með útgáfu sem er jafngóð og sú núverandi.
Við eyðum út völdu síðuna. Við berum innihaldið saman við 0xff. Ef eitthvað er rangt tökum við næstu lausu síðu og svo framvegis.
Við skrifum hausinn á síðuna sem var eytt, fyrsta færslan er núverandi staða samhengisins og næsta færsla er óskrifaða skráningarfærslan (ef hún er til staðar).
Notkunarsvið sniðsins
Að mínu mati er þetta gott snið til að geyma meira eða minna þjappanlegar upplýsingastrauma (venjulegan texta, JSON, MessagePack, CBOR, hugsanlega protobuf) í NOR Flash.
Auðvitað er sniðið „skerpað“ fyrir SLC NOR Flash.
Það ætti ekki að nota það með háum BER miðla eins og NAND eða MLC NOR. (Er þessi tegund af minni yfirhöfuð til sölu? Ég hef aðeins séð umtal um það í greinum um leiðréttingarkóða.).
Þar að auki ætti það ekki að nota með tækjum sem hafa sitt eigið FTL: USB glampi, SD, MicroSD, o.s.frv. (Fyrir þessa tegund minnis bjó ég til snið með 512 bæti síðustærð, undirskrift í upphafi hverrar síðu og einstökum færslunúmerum — stundum gat ég endurheimt öll gögnin af „biluðu“ USB-lykli með einfaldri raðlestri).
Eftir því hvaða forrit er um að ræða er hægt að nota sniðið án breytinga á glampadrifum frá 128 Kbps (16 Kbps) upp í 1 Gbps (128 Mbps). Ef þess er óskað er einnig hægt að nota það á stærri örgjörvum, þó að líklega þurfi að aðlaga síðustærðina. (En hér kemur upp spurningin um hagkvæmni; verð á stórum NOR Flash er ekki hvetjandi).
Ef einhver finnst þetta snið áhugavert og vill nota það í opnum hugbúnaðarverkefni, látið mig vita. Ég mun reyna að finna tíma til að fínpússa kóðann og birta hann á GitHub.
Ályktun
Eins og við sjáum varð sniðið einfalt. og jafnvel leiðinlegt.
Það er erfitt að endurspegla þróun sjónarmiða minna í grein, en trúið mér: upphaflega vildi ég skapa eitthvað háþróað, óslítandi, sem gæti jafnvel lifað af kjarnorkusprengingu í návígi. Hins vegar (vonandi) sigraði skynsemin að lokum og smám saman færðust áherslurnar í átt að einfaldleika og þéttleika.
Gæti það verið að ég hafi rangt fyrir mér? Já, auðvitað. Það gæti vel verið, til dæmis, að við höfum keypt slatta af örflögum af lélegum gæðum. Eða af einhverri annarri ástæðu uppfyllir búnaðurinn ekki áreiðanleikakröfur.
Hef ég einhverja áætlun fyrir þetta? Ég held að eftir að hafa lesið þessa grein, þá efast þú ekki um að ég hafi hana. Og fleiri en eina.
Alvarlegra er að sniðið var þróað bæði sem vinnumöguleiki og sem „prufublöðra“.
Eins og er gengur allt vel á borðinu; lausnin verður tekin í notkun eftir örfáa daga. (um það bil) Á hundrað tækjum munum við sjá hvað gerist í „bardaga“ notkun (sem betur fer vona ég að sniðið leyfi áreiðanlega bilunargreiningu, svo við getum safnað ítarlegri tölfræði). Eftir nokkra mánuði munum við geta dregið ályktanir. (og ef þú ert óheppinn, jafnvel fyrr).
Ef ég uppgötva einhver alvarleg vandamál eftir að hafa notað það og þarfnast úrbóta, þá mun ég örugglega skrifa um það.
Bókmenntir
Ég vildi ekki taka saman langan og leiðinlegan lista af heimildum; allir nota jú Google.
Hér ákvað ég að skilja eftir lista yfir niðurstöður sem ég fannst sérstaklega áhugaverðar, en smám saman færðust þær beint inn í texta greinarinnar og aðeins eitt atriði varð eftir á listanum:
- Gagnsemi Frá höfundi zlib. Það getur sýnt innihald deflate/zlib/gzip skjalasafna greinilega. Ef þú þarft að skilja innri þætti deflate (eða gzip) sniðsins, þá mæli ég eindregið með því.
Heimild: www.habr.com
