

Athugið. þýð.: Í þessari grein deilir Banzai Cloud dæmi um hvernig hægt er að nota sérsniðin verkfæri þess til að gera Kafka auðveldari í notkun innan Kubernetes. Eftirfarandi leiðbeiningar sýna hvernig þú getur ákvarðað bestu stærð innviða þíns og stillt Kafka sjálft til að ná nauðsynlegri afköstum.

Apache Kafka er dreifður streymisvettvangur til að búa til áreiðanleg, stigstærð og afkastamikil rauntíma streymiskerfi. Hægt er að útvíkka glæsilega getu þess með Kubernetes. Fyrir þetta höfum við þróað og tól sem heitir . Þeir gera þér kleift að keyra Kafka á Kubernetes og nota ýmsa eiginleika þess, svo sem að fínstilla miðlarastillingar, mælikvarða byggða á mælikvarða með endurjafnvægi, meðvitund um rekki, „mjúk“ (tignarlegt) rúlla út uppfærslur o.s.frv.
Prófaðu Supertubes í klasanum þínum:
curl https://getsupertubes.sh | sh и supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>Eða hafðu samband . Þú getur líka lesið um nokkra möguleika Kafka, en vinnan með því er sjálfvirk með Supertubes og Kafka rekstraraðila. Við höfum þegar skrifað um þá á blogginu:
- ;
- ;
- ;
- ;
- ;
- ;
- .
Þegar þú ákveður að setja Kafka þyrping á Kubernetes muntu líklega standa frammi fyrir þeirri áskorun að ákvarða bestu stærð undirliggjandi innviða og þörfina á að fínstilla Kafka stillingar þínar til að mæta afköstum. Hámarksafköst hvers miðlara ræðst af frammistöðu undirliggjandi innviðahluta, svo sem minni, örgjörva, diskhraða, netbandbreidd osfrv.
Helst ætti uppsetning miðlara að vera þannig að allir innviðaþættir séu notaðir til að hámarks getu þeirra. Hins vegar, í raunveruleikanum, er þessi uppsetning nokkuð flókin. Líklegra er að notendur stilli miðlara til að hámarka notkun eins eða tveggja íhluta (diskur, minni eða örgjörva). Almennt séð sýnir miðlari hámarksafköst þegar uppsetning hans gerir kleift að nota hægasta íhlutinn að fullu. Þannig getum við fengið grófa hugmynd um álagið sem einn miðlari ræður við.
Fræðilega séð getum við líka áætlað fjölda miðlara sem þarf til að takast á við tiltekið álag. Hins vegar, í reynd, eru svo margir stillingarvalkostir á mismunandi stigum að það er mjög erfitt (ef ekki ómögulegt) að meta hugsanlega frammistöðu tiltekinnar uppsetningar. Með öðrum orðum, það er mjög erfitt að skipuleggja uppsetningu sem byggir á ákveðinni frammistöðu.
Fyrir Supertubes notendur tökum við venjulega eftirfarandi nálgun: við byrjum með einhverri stillingu (innviði + stillingar), mælum síðan frammistöðu þess, stillum miðlarastillingarnar og endurtakum ferlið aftur. Þetta gerist þar til hægasti hluti innviðanna er fullnýttur.
Þannig fáum við skýrari hugmynd um hversu marga miðlara þyrping þarf til að takast á við ákveðið álag (fjöldi miðlara fer einnig eftir öðrum þáttum, svo sem lágmarksfjölda afrita skilaboða til að tryggja seiglu, fjölda skiptinga leiðtogar osfrv.). Að auki fáum við innsýn í hvaða innviðaíhlutir þurfa lóðrétta skala.
Þessi grein mun fjalla um skrefin sem við tökum til að fá sem mest út úr hægustu íhlutunum í upphaflegum stillingum og mæla afköst Kafka klasa. Mjög seigur uppsetning krefst að minnsta kosti þriggja hlaupandi miðlara (min.insync.replicas=3), dreift yfir þrjú mismunandi aðgengissvæði. Til að stilla, skala og fylgjast með Kubernetes innviðum notum við okkar eigin gámastjórnunarvettvang fyrir blendingsský - . Það styður á staðnum (ber málmur, VMware) og fimm tegundir af skýjum (Fjarvistarsönnun, AWS, Azure, Google, Oracle), auk hvers kyns samsetningar þeirra.
Hugleiðingar um innviði og uppsetningu Kafka klasa
Fyrir dæmin hér að neðan völdum við AWS sem skýjaveituna og EKS sem Kubernetes dreifinguna. Svipaða uppsetningu er hægt að útfæra með því að nota - Kubernetes dreifing frá Banzai Cloud, vottað af CNCF.
diskur
Amazon býður upp á ýmislegt . Í kjarnanum gp2 и io1 það eru þó SSD drif til að tryggja mikið afköst gp2 eyðir uppsöfnuðum inneignum (I/O einingar), þannig að við vildum frekar gerðina io1, sem býður upp á stöðugt mikið afköst.
Tilviksgerðir
Frammistaða Kafka er mjög háð síðuskyndiminni stýrikerfisins, svo við þurfum tilvik með nægilegt minni fyrir miðlara (JVM) og síðuskyndiminni. Dæmi c5.2xstór - góð byrjun, þar sem það hefur 16 GB af minni og . Ókostur þess er að hann er aðeins fær um að veita hámarksafköst í ekki meira en 30 mínútur á 24 klukkustunda fresti. Ef vinnuálag þitt krefst hámarksárangurs yfir lengri tíma gætirðu viljað íhuga aðrar tegundir tilvika. Það var einmitt það sem við gerðum, stoppuðum kl c5.4xstór. Það veitir hámarks afköst inn 593,75 Mb/s. Hámarks afköst EBS rúmmáls io1 hærri en dæmið c5.4xstór, þannig að hægasti þátturinn í innviði er líklega I/O afköst þessarar tilvikstegundar (sem hleðsluprófin okkar ættu líka að staðfesta).
Сеть
Netafköst verða að vera nógu stór miðað við frammistöðu VM dæmisins og disksins, annars verður netið flöskuháls. Í okkar tilviki, netviðmótið c5.4xstór styður allt að 10 Gb/s hraða, sem er umtalsvert hærra en I/O afköst VM tilviks.
Miðlari dreifing
Miðlari ætti að vera dreift (áætlað í Kubernetes) á sérstaka hnúta til að forðast samkeppni við aðra ferla fyrir örgjörva, minni, netkerfi og diskaauðlindir.
Java útgáfa
Rökrétt val er Java 11 vegna þess að það er samhæft við Docker í þeim skilningi að JVM ákvarðar rétt örgjörva og minni sem er tiltækt fyrir ílátið sem miðlarinn er í gangi. Með því að vita að CPU takmörk eru mikilvæg, stillir JVM innra og gagnsæjan fjölda GC þráða og JIT þráða. Við notuðum Kafka myndina banzaicloud/kafka:2.13-2.4.0, sem inniheldur Kafka útgáfu 2.4.0 (Scala 2.13) á Java 11.
Ef þú vilt læra meira um Java/JVM á Kubernetes, skoðaðu eftirfarandi færslur okkar:
- ;
- .
Minni stillingar miðlara
Það eru tveir lykilþættir við að stilla miðlaraminni: stillingar fyrir JVM og fyrir Kubernetes pod. Minnimörkin sem sett eru fyrir pod verða að vera stærri en hámarks hrúgustærð þannig að JVM hafi pláss fyrir Java metaspace sem er í eigin minni og fyrir stýrikerfissíðu skyndiminni sem Kafka notar virkan. Í prófunum okkar hófum við Kafka miðlara með breytum -Xmx4G -Xms2G, og minnistakmarkið fyrir belginn var 10 Gi. Vinsamlegast athugaðu að minnisstillingar fyrir JVM er hægt að fá sjálfkrafa með því að nota -XX:MaxRAMPercentage и -X:MinRAMPercentage, byggt á minnismörkum fyrir belg.
Stillingar miðlara örgjörva
Almennt séð geturðu bætt frammistöðu með því að auka samsvörun með því að fjölga þráðum sem Kafka notar. Því fleiri örgjörvar sem eru í boði fyrir Kafka, því betra. Í prófinu okkar byrjuðum við með 6 örgjörva takmörk og hækkuðum smám saman (með endurtekningu) fjölda þeirra í 15. Að auki settum við num.network.threads=12 í miðlarastillingunum til að fjölga þráðum sem taka við gögnum frá netinu og senda þau. Þegar þeir uppgötvaðu að fylgjendur miðlari gátu ekki fengið eftirlíkingar nógu fljótt, hækkuðu þeir num.replica.fetchers til 4 til að auka hraðann sem fylgjendamiðlarar endurtaka skilaboð frá leiðtogum.
Hlaða kynslóðarverkfæri
Þú ættir að tryggja að hleðslugjafinn sem valinn er klárast ekki áður en Kafka þyrpingin (sem verið er að mæla) nær hámarksálagi. Með öðrum orðum, það er nauðsynlegt að framkvæma bráðabirgðamat á getu hleðsluverkfærsins og velja einnig tilviksgerðir fyrir það með nægjanlegum fjölda örgjörva og minni. Í þessu tilviki mun tólið okkar framleiða meira álag en Kafka þyrpingin ræður við. Eftir margar tilraunir settumst við upp á þrjú eintök c5.4xstór, sem hver um sig var með rafal í gangi.
Viðmiðun
Árangursmæling er endurtekið ferli sem felur í sér eftirfarandi stig:
- setja upp innviði (EKS þyrping, Kafka þyrping, hleðsluverkfæri, auk Prometheus og Grafana);
- búa til álag í ákveðið tímabil til að sía tilviljunarkenndar frávik í söfnuðum frammistöðuvísum;
- að stilla innviði og uppsetningu miðlarans á grundvelli frammistöðuvísa sem mælst hafa;
- endurtaka ferlið þar til tilskildu magni af afköstum Kafka klasa er náð. Á sama tíma verður það að vera stöðugt endurgeranlegt og sýna lágmarksbreytingar í afköstum.
Næsti kafli lýsir skrefunum sem voru framkvæmd í prófunarklasaviðmiðunarferlinu.
Verkfæri
Eftirfarandi verkfæri voru notuð til að dreifa grunnstillingu fljótt, búa til álag og mæla frammistöðu:
- fyrir að skipuleggja EKS klasa frá Amazon c (til að safna Kafka og innviðamælingum) og (til að sjá þessa mælikvarða). Við fórum á kostum samþætt в þjónustu sem veitir sambandseftirlit, miðlæga annálasöfnun, varnarleysisskönnun, hamfarabata, öryggi fyrirtækja og margt fleira.
- - tól til að prófa álag á Kafka þyrpingu.
- Grafana mælaborð til að sjá Kafka mælikvarða og innviði: , .
- Supertubes CLI fyrir auðveldustu leiðina til að setja upp Kafka þyrping á Kubernetes. Zookeeper, Kafka rekstraraðili, Envoy og margir aðrir íhlutir eru settir upp og rétt stilltir til að keyra framleiðslu-tilbúinn Kafka þyrping á Kubernetes.
- Til að setja upp supertubes CLI nota leiðbeiningarnar sem fylgja með .
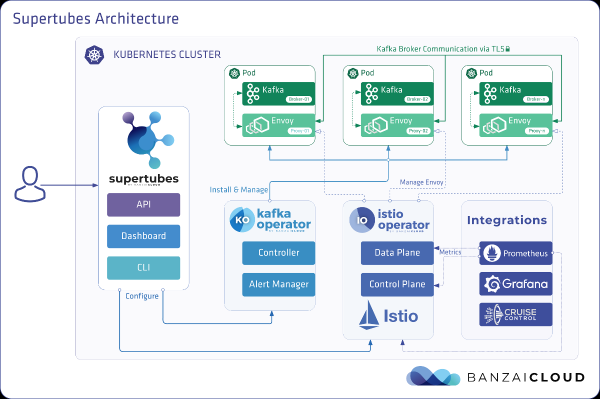
EKS þyrping
Undirbúa EKS klasa með sérstökum starfshnútum c5.4xstór á mismunandi framboðssvæðum fyrir belg með Kafka miðlara, auk sérstakra hnúta fyrir álagsframleiðandann og vöktunarinnviði.
banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.jsonÞegar EKS þyrpingin er komin í gang skaltu virkja samþættingu hans — hún mun senda Prometheus og Grafana í þyrpingu.
Kafka kerfishlutir
Settu Kafka kerfishluta (Zookeeper, kafka-operator) upp í EKS með því að nota supertubes CLI:
supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>Kafka þyrping
Sjálfgefið er að EKS notar EBS magn af gerðinni gp2, þannig að þú þarft að búa til sérstakan geymsluflokk byggt á rúmmáli io1 fyrir Kafka þyrpinguna:
kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF Stilltu færibreytuna fyrir miðlara min.insync.replicas=3 og settu miðlarabelg á hnúta á þremur mismunandi framboðssvæðum:
supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600Efni
Við keyrðum þrjú hleðslutæki samhliða. Hver þeirra skrifar við sitt eigið efni, það er, við þurfum þrjú efni alls:
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOFFyrir hvert efni er afritunarstuðullinn 3—lægsta ráðlagt gildi fyrir framleiðslukerfi sem eru mjög fáanleg.
Hlaða kynslóðarverkfæri
Við settum af stað þrjú eintök af hleðslugjafanum (hver og einn skrifaði í sérstakt efni). Fyrir hleðslugjafabelg þarftu að stilla hnútsækni þannig að þeir séu aðeins tímasettir á hnútunum sem þeim er úthlutað:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30Nokkrir punktar til að hafa í huga:
- Álagsframleiðandinn býr til skilaboð sem eru 512 bæti að lengd og birtir þau til Kafka í lotum með 500 skilaboðum.
- Að nota rök
-required-acks=allÚtgáfan telst vel heppnuð þegar allar samstilltar eftirlíkingar af skilaboðunum eru mótteknar og staðfestar af Kafka miðlarum. Þetta þýðir að í viðmiðinu mældum við ekki aðeins hraða leiðtoga sem fá skilaboð, heldur einnig fylgjenda þeirra sem endurtaka skilaboð. Tilgangur þessa prófs er ekki að meta lestrarhraða neytenda (neytendur) nýlega móttekin skilaboð sem enn eru eftir í skyndiminni stýrikerfissíðunnar og samanburður þeirra við leshraða skilaboða sem geymd eru á diski. - Álagsframleiðandinn rekur 20 starfsmenn samhliða (
-workers=20). Hver starfsmaður inniheldur 5 framleiðendur sem deila tengingu starfsmannsins við Kafka klasann. Fyrir vikið eru 100 framleiðendur í hverjum rafalli og allir senda þeir skilaboð til Kafka-klasans.
Eftirlit með heilsu klasans
Við hleðsluprófun á Kafka þyrpingunni fylgdumst við líka með heilsu hans til að tryggja að engin endurræsing hólfs væri, engar eftirmyndir sem eru ósamstilltar og hámarksafköst með lágmarks sveiflum:
- Álagsframleiðandinn skrifar staðlaða tölfræði um fjölda birtra skilaboða og villuhlutfall. Villuhlutfallið ætti að vera það sama
0,00%. - , dreift af kafka-rekstraraðila, býður upp á mælaborð þar sem við getum líka fylgst með ástandi klasans. Til að skoða þetta spjald skaltu gera:
supertubes cluster cruisecontrol show -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> - ISR stig (fjöldi „samstilltra“ eftirmynda) skreppa saman og stækkun eru jöfn 0.
Niðurstöður mælinga
3 miðlarar, skilaboðastærð - 512 bæti
Með skiptingum jafnt yfir þrjá miðlara gátum við náð árangri ~500 Mb/s (u.þ.b. 990 þúsund skilaboð á sekúndu):



Minnisnotkun JVM sýndarvélarinnar fór ekki yfir 2 GB:



Afköst disks náðu hámarks afköstum I/O hnúts í öllum þremur tilvikunum sem miðlararnir voru að keyra á:
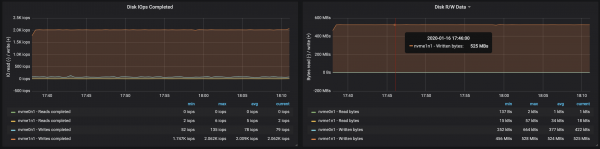
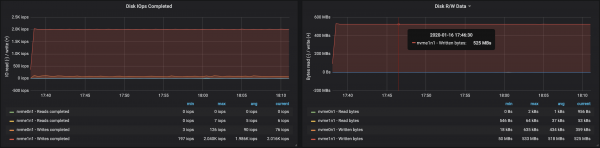
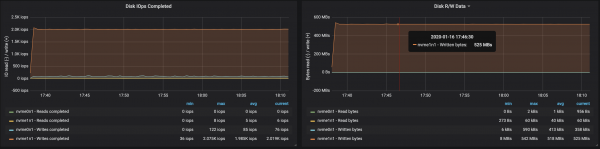
Af gögnum um minnisnotkun eftir hnútum leiðir að kerfisbuff og skyndiminni tók ~10-15 GB:



3 miðlarar, skilaboðastærð - 100 bæti
Eftir því sem skilaboðastærðin minnkar minnkar afköst um það bil 15-20%: tíminn sem fer í vinnslu hvers skeytis hefur áhrif á það. Auk þess hefur álag örgjörva næstum tvöfaldast.



Þar sem miðlarahnútar eru enn með ónotaða kjarna, er hægt að bæta árangur með því að breyta Kafka stillingum. Þetta er ekki auðvelt verkefni, svo til að auka afköst er betra að vinna með stærri skilaboð.
4 miðlarar, skilaboðastærð - 512 bæti
Þú getur auðveldlega aukið afköst Kafka klasa með því einfaldlega að bæta við nýjum miðlarum og viðhalda jafnvægi skiptinganna (þetta tryggir að álagið dreifist jafnt á milli miðlara). Í okkar tilviki, eftir að hafa bætt við miðlara, jókst afköst klasans í ~580 Mb/s (~1,1 milljón skilaboða á sekúndu). Vöxturinn reyndist minni en búist var við: þetta skýrist aðallega af ójafnvægi skiptinganna (ekki allir miðlarar vinna í hámarki getu þeirra).




Minnisnotkun JVM vélarinnar hélst undir 2 GB:




Vinna miðlara með drif var fyrir áhrifum af ójafnvægi skiptinganna:
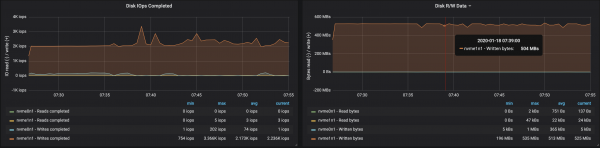
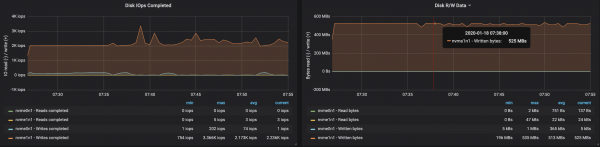
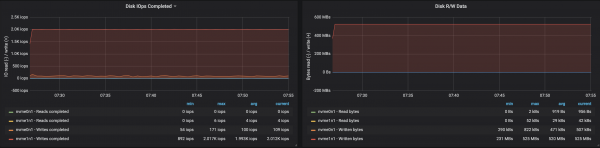
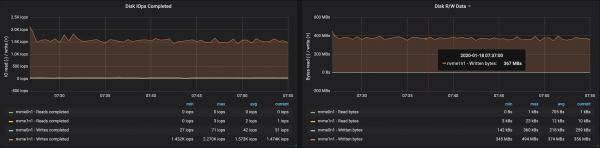
Niðurstöður
Hægt er að útvíkka endurtekna nálgunina sem kynnt er hér að ofan til að ná til flóknari atburðarása sem taka þátt í hundruðum neytenda, endurskipting, rúllandi uppfærslur, endurræsingar á hólf osfrv. Allt þetta gerir okkur kleift að meta takmörk getu Kafka-klasans við ýmsar aðstæður, greina flöskuhálsa í rekstri hans og finna leiðir til að berjast gegn þeim.
Við hönnuðum Supertubes til að dreifa klasa á fljótlegan og auðveldan hátt, stilla hann, bæta við/fjarlægja miðlara og efni, bregðast við tilkynningum og tryggja að Kafka virki almennt rétt á Kubernetes. Markmið okkar er að hjálpa þér að einbeita þér að aðalverkefninu („búa til“ og „neyta“ Kafka-skilaboð), og láta Supertubes og Kafka-rekstraraðilann alla erfiðisvinnuna eftir.
Ef þú hefur áhuga á Banzai Cloud tækni og Open Source verkefnum skaltu gerast áskrifandi að fyrirtækinu á , eða .
PS frá þýðanda
Lestu líka á blogginu okkar:
- «»;
- «»;
- «'.
Heimild: www.habr.com
