


Í vor höfum við þegar rætt nokkur inngangsefni, t.d. и . Í annarri þeirra lofuðum við meira að segja að halda áfram að rannsaka frammistöðu ýmissa fjöldiska svæðisfræði í ZFS. Þetta er næstu kynslóðar skráarkerfi sem nú er verið að innleiða alls staðar: frá í .
Jæja, í dag er besti dagurinn til að kynnast ZFS, fróðleiksfúsum lesendum. Veistu bara að í auðmjúku áliti OpenZFS þróunaraðila Matt Ahrens, "er það mjög erfitt."
En áður en við komum að tölunum - og þær munu, ég lofa - fyrir alla valkosti fyrir átta diska ZFS uppsetningu, þurfum við að tala um sem Almennt séð geymir ZFS gögn á diski.
Zpool, vdev og tæki
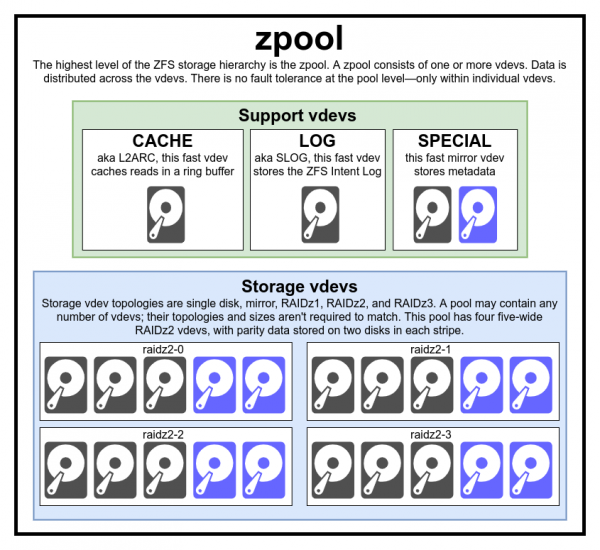
Þessi heildarskýringarmynd inniheldur þrjú auka vdev, einn af hverjum flokki og fjórir fyrir RAIDz2

Það er venjulega engin ástæða til að búa til hóp af ósamræmdum vdev gerðum og stærðum - en það er ekkert sem hindrar þig í að gera það ef þú vilt.
Til að skilja ZFS skráarkerfið virkilega þarftu að skoða raunverulega uppbyggingu þess. Í fyrsta lagi sameinar ZFS hefðbundin stig hljóðstyrks og skráarkerfisstjórnunar. Í öðru lagi notar það viðskiptaafritunar-í-skrifa kerfi. Þessir eiginleikar þýða að kerfið er mjög frábrugðið venjulegum skráarkerfum og RAID fylkjum. Fyrsta settið af grunnbyggingareiningum til að skilja eru geymslupottur (zpool), sýndartæki (vdev) og raunverulegt tæki (tæki).
zpool
Zpool geymslulaugin er efsta ZFS uppbyggingin. Hver laug inniheldur eitt eða fleiri sýndartæki. Aftur á móti inniheldur hvert þeirra eitt eða fleiri raunveruleg tæki (tæki). Sýndarlaugar eru sjálfstæðar blokkir. Ein líkamleg tölva getur innihaldið tvær eða fleiri aðskildar laugar, en hver er algjörlega óháð hinum. Laugar geta ekki deilt sýndartækjum.
Offramboð ZFS er á sýndartækjastigi, ekki á laugarstigi. Það er nákvæmlega engin offramboð á sundlaugarstigi - ef einhver drif vdev eða sérstakur vdev tapast, þá tapast öll sundlaugin ásamt því.
Nútíma geymslulaugar geta lifað af tap á skyndiminni eða sýndartækjaskrá - þó að þeir geti tapað litlu magni af óhreinum gögnum ef þeir missa vdev-skrána við rafmagnsleysi eða kerfishrun.
Það er algengur misskilningur að ZFS „gagnarönd“ séu skrifaðar yfir alla laugina. Þetta er ekki satt. Zpool er alls ekki fyndið RAID0, það er frekar fyndið með flóknu breytilegu dreifingarkerfi.
Að mestu leyti er færslunum dreift á tiltæk sýndartæki í samræmi við tiltækt laust pláss, þannig að í orði verða þær allar fylltar á sama tíma. Í síðari útgáfum af ZFS er núverandi vdev notkun (nýting) tekin með í reikninginn - ef eitt sýndartæki er umtalsvert uppteknara en annað (til dæmis vegna lestrarálags) verður því sleppt tímabundið til að skrifa, þrátt fyrir að hafa mesta ókeypis rúmhlutfall.
Nýtingarskynjunarbúnaðurinn sem er innbyggður í nútíma ZFS ritúthlutunaraðferðir getur dregið úr leynd og aukið afköst á tímabilum með óvenju mikið álag - en það er ekki carte blanche um ósjálfráða blöndun á hægum HDD og hröðum SSD diskum í einni laug. Slík ójöfn laug mun samt starfa á hraða hægasta tækisins, það er eins og það væri alfarið samsett úr slíkum tækjum.
vdev
Hver geymsluhópur samanstendur af einu eða fleiri sýndartækjum (sýndartæki, vdev). Aftur á móti inniheldur hver vdev eitt eða fleiri raunveruleg tæki. Flest sýndartæki eru notuð fyrir einfalda gagnageymslu, en það eru nokkrir vdev hjálparflokkar, þar á meðal CACHE, LOG og SPECIAL. Hver af þessum vdev gerðum getur haft eina af fimm staðfræði: stakt tæki (eitt tæki), RAIDz1, RAIDz2, RAIDz3 eða spegill (spegill).
RAIDz1, RAIDz2 og RAIDz3 eru sérstök afbrigði af því sem fornaldarmenn myndu kalla tvöfalt (ská) jöfnunar-RAID. 1, 2 og 3 vísa til þess hversu mörgum jöfnunarreitum er úthlutað fyrir hverja gagnaræmu. Í staðinn fyrir aðskilda diska fyrir jöfnuð, dreifa RAIDz sýndartækjum þessum jöfnuði hálfjafnt yfir diska. RAIDz fylki getur tapað jafn mörgum diskum og það hefur jöfnunarblokkir; ef það týnir öðrum þá mun það hrynja og taka geymslulaugina með sér.
Í spegluðum sýndartækjum (mirror vdev) er hver blokk geymd á hverju tæki í vdev. Þrátt fyrir að tvíbreiðir speglar séu algengastir, getur hvaða geðþótta fjöldi tækja verið í spegli - þrefaldir eru oft notaðir í stórum uppsetningum til að bæta lestrarafköst og bilanaþol. Vdev spegill getur lifað af hvaða bilun sem er svo lengi sem að minnsta kosti eitt tæki í vdev heldur áfram að virka.
Stakir vdevs eru í eðli sínu hættulegir. Slík sýndartæki mun ekki lifa af eina bilun - og ef það er notað sem geymsla eða sérstakt vdev, þá mun bilun þess leiða til eyðileggingar á allri sundlauginni. Vertu mjög, mjög varkár hér.
Hægt er að búa til skyndiminni, LOG og SÉRSTÖK VA með því að nota hvaða ofangreindu svæðisfræði sem er - en mundu að tap á SÉRSTÖKUM VA þýðir tap á lauginni, svo óþarfa staðfræði er mjög mælt með.
tæki
Þetta er líklega auðveldasta hugtakið til að skilja í ZFS - það er bókstaflega slembiaðgangstæki. Mundu að sýndartæki eru samsett úr einstökum tækjum en laug samanstendur af sýndartækjum.
Diskar - annaðhvort segulmagnaðir eða solid state - eru algengustu blokkartækin sem eru notuð sem byggingareiningar vdev. Hins vegar mun hvaða tæki sem er með lýsingu í /dev gera það, þannig að hægt er að nota heilar vélbúnaðar RAID fylki sem aðskilin tæki.
Einföld hrá skrá er eitt mikilvægasta valblokkatækið sem hægt er að byggja vdev úr. Próflaugar frá er mjög handhæg leið til að athuga laugarskipanir og sjá hversu mikið pláss er til í laug eða sýndartæki með tiltekinni staðfræði.
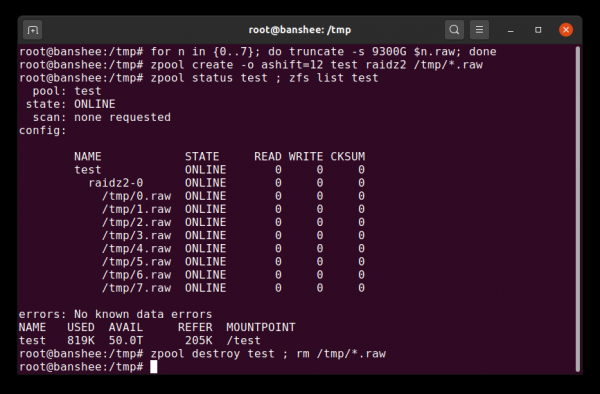
Þú getur búið til prufulaug úr dreifðum skrám á örfáum sekúndum - en ekki gleyma að eyða allri sundlauginni og íhlutum hennar eftir það
Segjum að þú viljir setja miðlara á átta diska og ætlar að nota 10 TB diska (~9300 GiB) - en þú ert ekki viss um hvaða staðfræði hentar þínum þörfum best. Í dæminu hér að ofan byggjum við upp prófunarlaug úr fáum skrám á nokkrum sekúndum - og nú vitum við að RAIDz2 vdev með átta 10 TB diskum veitir 50 TiB af nothæfri getu.
Annar sérstakur flokkur tækja er SPARE (vara). Hot-swap tæki, ólíkt venjulegum tækjum, tilheyra allri lauginni, en ekki einu sýndartæki. Ef vdev í sundlauginni bilar og varatæki er tengt við sundlaugina og tiltækt, þá mun það sjálfkrafa ganga í viðkomandi vdev.
Eftir tengingu við viðkomandi vdev byrjar varatækið að taka við afritum eða endurgerðum gagna sem ættu að vera á tækinu sem vantar. Í hefðbundnu RAID er þetta kallað endurbygging, en í ZFS er það kallað resilvering.
Það er mikilvægt að hafa í huga að varatæki koma ekki varanlega í staðinn fyrir biluð tæki. Þetta er aðeins tímabundin skipti til að draga úr þeim tíma sem vdev er rýrnað. Eftir að kerfisstjórinn skiptir um bilaða vdev, er offramboð endurheimt í það varanlega tæki, og SPARE er aftengt vdev og aftur til að vinna sem vara fyrir alla sundlaugina.
Gagnasöfn, blokkir og geirar
Næsta sett af byggingareiningum til að skilja á ZFS ferð okkar snýst minna um vélbúnaðinn og meira um hvernig gögnin sjálf eru skipulögð og geymd. Við erum að sleppa nokkrum stigum hér - eins og metaslab - til að rugla ekki smáatriðunum á meðan við viðhaldum skilningi á heildarskipulaginu.
Gagnasett (gagnasett)
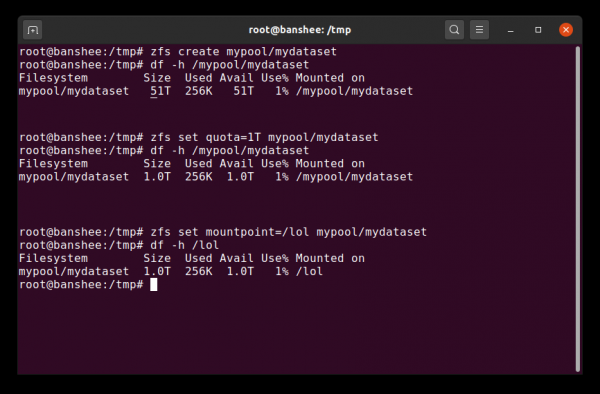
Þegar við búum til gagnasafn fyrst sýnir það allt tiltækt sundlaugarrými. Síðan setjum við kvótann - og breytum festingarpunktinum. Galdur!
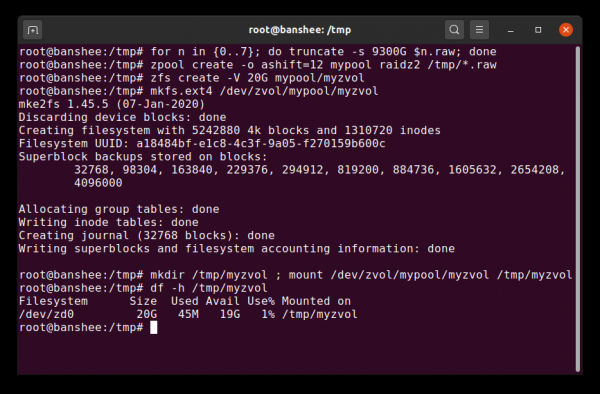
Zvol er að mestu leyti bara gagnasafn svipt skráakerfislagi sínu, sem við erum að skipta hér út fyrir fullkomlega eðlilegt ext4 skráarkerfi.
ZFS gagnasafn er nokkurn veginn það sama og venjulegt uppsett skráarkerfi. Eins og venjulegt skráarkerfi lítur það við fyrstu sýn út eins og „bara önnur mappa“. En rétt eins og venjuleg skráarkerfi sem hægt er að setja upp, hefur hvert ZFS gagnasafn sitt eigið sett af grunneiginleikum.
Í fyrsta lagi getur gagnasafn fengið úthlutaðan kvóta. Ef stillt er zfs set quota=100G poolname/datasetname, þá muntu ekki geta skrifað í uppsettu möppuna /poolname/datasetname meira en 100 GiB.
Taktu eftir tilvist - og fjarveru - af skástrikum í upphafi hverrar línu? Hvert gagnasafn hefur sinn stað bæði í ZFS stigveldinu og kerfisfestingarstigveldinu. Það er engin skástrik í ZFS stigveldinu - þú byrjar á heiti laugarinnar og síðan slóðinni frá einu gagnasafni til þess næsta. Til dæmis, pool/parent/child fyrir gagnasafn sem heitir child undir foreldri gagnasafni parent í laug með skapandi nafni pool.
Sjálfgefið er að tengipunktur gagnasafnsins jafngildir nafni þess í ZFS stigveldinu, með skástrik á undan - laugin sem heitir pool fest sem /pool, gagnasett parent fest í /pool/parent, og barngagnagagnasafnið child fest í /pool/parent/child. Hins vegar er hægt að breyta kerfisfestingarpunkti gagnasafnsins.
Ef við tilgreinum zfs set mountpoint=/lol pool/parent/child, síðan gagnasettið pool/parent/child fest á kerfið sem /lol.
Auk gagnasafna ættum við að nefna bindi (zvols). Rúmmál er nokkurn veginn það sama og gagnapakka, nema að það er í raun ekki með skráarkerfi - það er bara blokkartæki. Þú getur til dæmis búið til zvol Með nafni mypool/myzvol, forsníða það síðan með ext4 skráarkerfi og festu síðan það skráarkerfi - þú ert núna með ext4 skráarkerfi, en með öllum öryggiseiginleikum ZFS! Þetta kann að virðast kjánalegt á einni vél, en er miklu skynsamlegra sem bakendi þegar íSCSI tæki er flutt út.
Blokkir
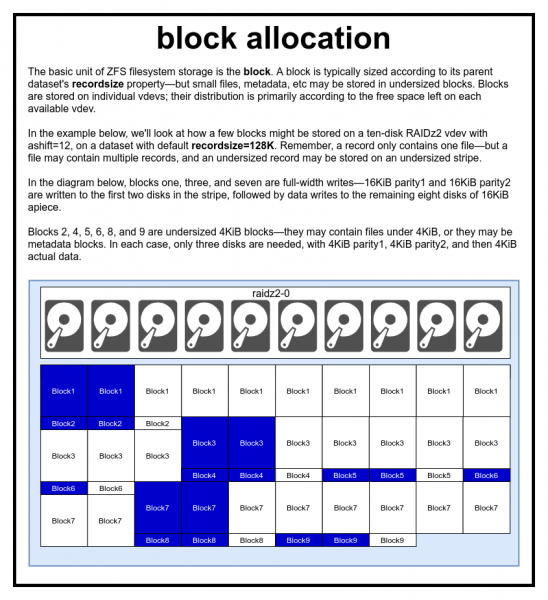
Skráin er táknuð með einum eða fleiri blokkum. Hver blokk er geymd á einu sýndartæki. Stærð blokkarinnar er venjulega jöfn færibreytunni metstærð, en hægt er að lækka í 2^skiptief það inniheldur lýsigögn eða litla skrá.

Við í alvöru virkilega ekki að grínast með risastóra frammistöðuvítið ef þú stillir of lítið á
Í ZFS laug eru öll gögn, þar á meðal lýsigögn, geymd í blokkum. Hámarksstærð blokkar fyrir hvert gagnasett er skilgreind í eigninni recordsize (metastærð). Hægt er að breyta færslustærðinni, en þetta mun ekki breyta stærð eða staðsetningu neinna blokka sem þegar hafa verið skrifaðar í gagnasafnið - það hefur aðeins áhrif á nýja blokkir þegar þær eru skrifaðar.
Nema annað sé tekið fram er núverandi sjálfgefna færslustærð 128 KiB. Það er svona erfiður málamiðlun þar sem frammistaða er ekki fullkomin, en það er ekki hræðilegt í flestum tilfellum heldur. Recordsize hægt að stilla á hvaða gildi sem er frá 4K til 1M (með háþróuðum stillingum recordsize þú getur sett upp enn meira, en þetta er sjaldan góð hugmynd).
Hvaða blokk sem er vísar til gagna um eina skrá - þú getur ekki troðið tveimur mismunandi skrám í eina blokk. Hver skrá samanstendur af einum eða fleiri blokkum, allt eftir stærð. Ef skráarstærðin er minni en skráastærðin verður hún geymd í minni blokkastærð - til dæmis mun blokk með 2 KiB skrá aðeins taka einn 4 KiB geira á disknum.
Ef skráin er nógu stór og þarfnast nokkurra blokka, þá verða allar færslur með þessari skrá af stærð recordsize - þar á meðal síðasta færslan, en meginhluti hennar kann að vera .
zvols hafa ekki eign recordsize — í staðinn eiga þeir jafngilda eign volblocksize.
Geirar
Síðasti, grunnsteinninn er geirinn. Það er minnsta líkamlega einingin sem hægt er að skrifa í eða lesa úr undirliggjandi tæki. Í nokkra áratugi notuðu flestir diskar 512-bæta geira. Nýlega hafa flestir diskar verið stilltir á 4 KiB geira, og sumir - sérstaklega SSDs - hafa 8 KiB geira eða jafnvel meira.
ZFS kerfið hefur eiginleika sem gerir þér kleift að stilla geirastærðina handvirkt. Þessi eign ashift. Nokkuð ruglingslegt, shift er máttur tveggja. Til dæmis, ashift=9 þýðir geirastærð 2^9, eða 512 bæti.
ZFS biður stýrikerfið um ítarlegar upplýsingar um hvert blokkartæki þegar það er bætt við nýja vdev og stillir í orði kveðnu sjálfkrafa ashift á viðeigandi hátt út frá þessum upplýsingum. Því miður ljúga margir diskar um stærð geira sinna til að viðhalda samhæfni við ... Windows XP (sem gat ekki skilið diska með mismunandi geirastærðum).
Þetta þýðir að ZFS stjórnanda er eindregið ráðlagt að vita raunverulega geirastærð tækja sinna og stilla handvirkt ashift. Ef ashift er stillt of lágt, þá eykst fjöldi les-/skrifaðgerða stjarnfræðilega. Svo að skrifa 512-bæta „geira“ í alvöru 4 KiB-geira þýðir að þurfa að skrifa fyrsta „geirann“, lesa síðan 4 KiB-geirann, breyta honum með öðrum 512-bæta „geira“, skrifa það aftur í nýja 4 KiB geira og svo framvegis fyrir hverja færslu.
Í hinum raunverulega heimi lendir slík refsing á Samsung EVO SSD, fyrir það ashift=13, en þessar SSD-diskar ljúga um geirastærð þeirra og því er sjálfgefið stillt á ashift=9. Ef reyndur kerfisstjóri breytir ekki þessari stillingu, þá virkar þessi SSD hægar hefðbundinn segulmagnaður HDD.
Til samanburðar, fyrir of stóra stærð ashift það er nánast engin refsing. Það er engin raunveruleg frammistöðu refsing, og aukning á ónotuðu plássi er óendanlega lítil (eða núll með samþjöppun virkjuð). Þess vegna mælum við eindregið með því að jafnvel þessir drif sem nota 512-bæta geira setji upp ashift=12 eða jafnvel ashift=13að takast á við framtíðina með sjálfstrausti.
Eign ashift er stillt fyrir hvert vdev sýndartæki, og ekki fyrir sundlaugina, eins og margir halda ranglega - og breytist ekki eftir uppsetningu. Ef þú slærð óvart ashift þegar þú bætir nýjum vdev við sundlaug, hefurðu óafturkræfan mengað þá sundlaug með litlum afköstum og það er yfirleitt ekkert annað val en að eyðileggja sundlaugina og byrja upp á nýtt. Jafnvel að fjarlægja vdev mun ekki bjarga þér frá biluðum stillingum ashift!
Afrita-í-skrifa vélbúnaður
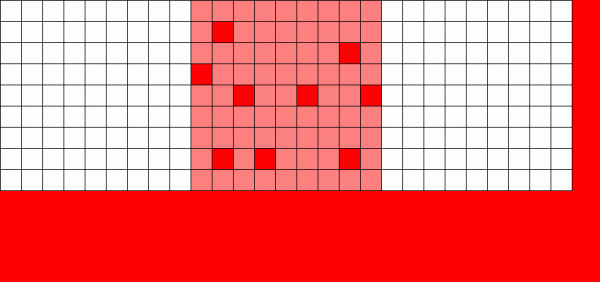
Ef venjulegt skráarkerfi þarf að skrifa yfir gögn breytir það hverri blokk þar sem hann er
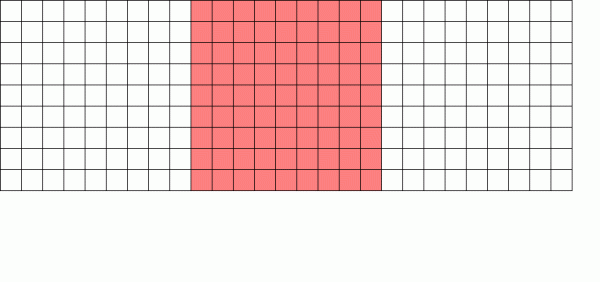
Afrita-í-skrifa skráarkerfi skrifar nýja blokkarútgáfu og opnar síðan gömlu útgáfuna

Í ágripinu, ef við hunsum raunverulega líkamlega staðsetningu blokkanna, þá er „gagnahalastjarnan“ okkar einfölduð í „gagnaormur“ sem færist frá vinstri til hægri yfir kortið af lausu rými.

Nú getum við fengið góða hugmynd um hvernig afrita-í-skrifa skyndimyndir virka - hver blokk getur verið í eigu margra skyndimynda og mun haldast þar til öllum tengdum skyndimyndum er eytt
Copy on Write (CoW) vélbúnaðurinn er grunnurinn að því sem gerir ZFS svo ótrúlegt kerfi. Grunnhugmyndin er einföld - ef þú biður hefðbundið skráarkerfi að breyta skrá mun það gera nákvæmlega það sem þú baðst um. Ef þú biður afrita-í-skrifa skráarkerfi að gera slíkt hið sama, mun það segja "ok" en ljúga að þér.
Þess í stað skrifar afrita-í-skrifa skráarkerfi nýja útgáfu af breyttu blokkinni og uppfærir síðan lýsigögn skráarinnar til að aftengja gamla blokkina og tengja nýja blokkina sem þú skrifaðir við hana.
Að aftengja gamla blokkina og tengja þann nýja er gert í einni aðgerð, svo það er ekki hægt að trufla hana - ef þú slekkur á eftir að þetta gerist ertu með nýja útgáfu af skránni og ef þú slekkur á snemma, þá ertu með gömlu útgáfuna . Í öllum tilvikum verða engir árekstrar í skráarkerfinu.
Copy-on-write í ZFS á sér ekki aðeins stað á skráarkerfisstigi heldur einnig á diskastjórnunarstigi. Þetta þýðir að ZFS hefur ekki áhrif á hvítt bil () - fyrirbæri þegar ræman hafði tíma til að taka aðeins upp að hluta áður en kerfið hrundi, með fylkisskemmdum eftir endurræsingu. Hér er röndin skrifuð atómfræðilega, vdev er alltaf í röð, og .
ZIL: ZFS ásetningsskrá
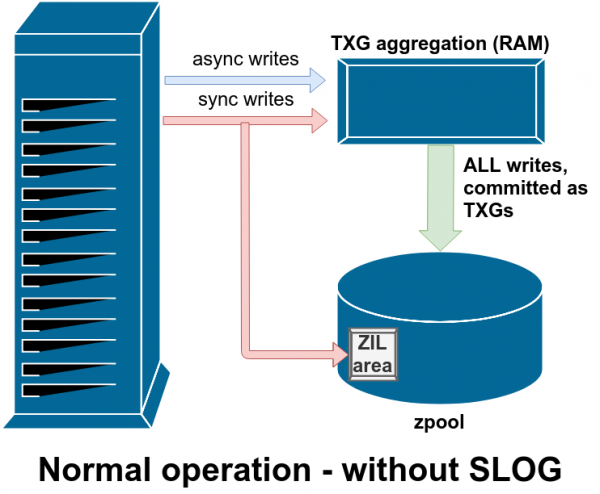
ZFS kerfið meðhöndlar samstilltar skriftir á sérstakan hátt - það geymir þær tímabundið en geymir þær strax í ZIL áður en þær eru skrifaðar varanlega síðar ásamt ósamstilltum skrifum.
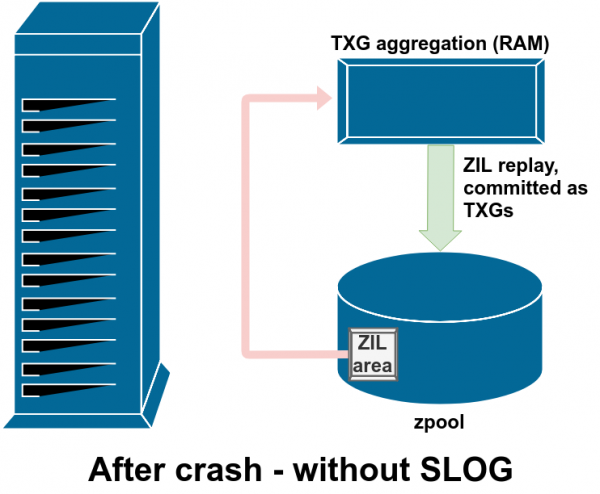
Venjulega eru gögn sem eru skrifuð í ZIL aldrei lesin aftur. En það er mögulegt eftir kerfishrun
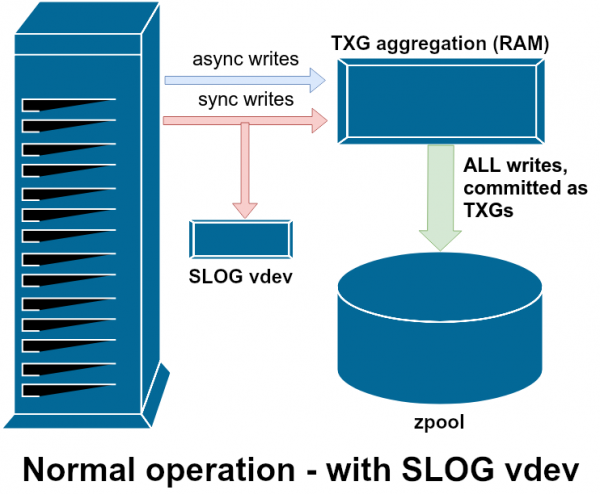
SLOG, eða auka LOG tæki, er bara sérstakt - og helst mjög hratt - vdev, þar sem hægt er að geyma ZIL aðskilið frá aðalgeymslunni.
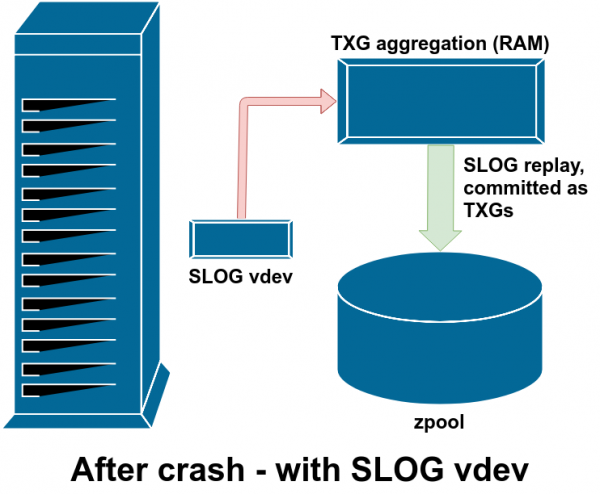
Eftir hrun eru öll óhrein gögn í ZIL endurspiluð - í þessu tilfelli er ZIL á SLOG, svo það er endurspilað þaðan
Það eru tveir meginflokkar skrifaaðgerða - samstilltur (samstilltur) og ósamstilltur (ósamstilltur). Fyrir flest vinnuálag er mikill meirihluti skrifa ósamstilltur - skráarkerfið gerir kleift að safna þeim saman og gefa út í lotum, sem dregur úr sundrungu og eykur afköst til muna.
Samstilltar upptökur eru allt annað mál. Þegar forrit biður um samstillt skrif segir það við skráarkerfið: "Þú þarft að binda þetta í óstöðugt minni núna straxþangað til þá er ekkert annað sem ég get gert." Þess vegna ætti samstilltur skrif að vera skuldbundinn til disks strax - og ef það eykur sundrun eða dregur úr afköstum, þá er það svo.
ZFS meðhöndlar samstilltar skrif á annan hátt en venjuleg skráarkerfi - í stað þess að binda þau strax í venjulega geymslu, skuldbindur ZFS þau á sérstakt geymslusvæði sem kallast ZFS Intent Log, eða ZIL. The bragð er að þessar færslur einnig haldast í minni, safnað saman ásamt venjulegum ósamstilltum skrifbeiðnum, til að verða síðar skolað í geymslu sem fullkomlega eðlilegar TXGs (Transaction Groups).
Í venjulegri notkun er ZIL skrifað til og aldrei lesið aftur. Þegar, eftir nokkur augnablik, eru færslur frá ZIL skuldbundnar til aðalgeymslu í venjulegum TXG frá vinnsluminni, eru þær aftengdar frá ZIL. Einu skiptið sem eitthvað er lesið úr ZIL er þegar sundlaugin er flutt inn.
Ef ZFS bilar - stýrikerfishrun eða rafmagnsleysi - á meðan gögn eru í ZIL, verða þau gögn lesin við næsta innflutning á laug (til dæmis þegar neyðarkerfið er endurræst). Allt í ZIL verður lesið, flokkað í TXG, skuldbundið til aðalgeymslunnar og síðan aftengt frá ZIL meðan á innflutningi stendur.
Einn af vdev hjálparflokkunum er kallaður LOG eða SLOG, aukabúnaður LOG. Það hefur einn tilgang - að útvega sundlauginni sérstakt, og helst mun hraðari, mjög skrifþolið vdev til að geyma ZIL, í stað þess að geyma ZIL í aðal vdev versluninni. ZIL sjálft hegðar sér eins, sama hvar það er geymt, en ef LOG vdev hefur mjög mikla skrifafköst, verður samstillt skrif hraðari.
Að bæta vdev með LOG við sundlaugina virkar ekki getur það ekki bæta ósamstilltur skrifa árangur - jafnvel þótt þú þvingar allar skrif til ZIL með zfs set sync=always, þeir verða samt tengdir við aðalgeymsluna í TXG á sama hátt og á sama hraða og án logsins. Eina beina árangursbótin er töf samstilltra skrifa (vegna þess að hraðari log flýtir fyrir aðgerðum). sync).
Hins vegar, í umhverfi sem nú þegar krefst mikils samstilltra skrifa, getur vdev LOG óbeint flýtt fyrir ósamstilltri skrifum og lestri sem ekki er í skyndiminni. Að hlaða ZIL færslum í sérstakan vdev LOG þýðir minni ágreining fyrir IOPS á aðalgeymslu, sem bætir afköst allra lestra og skrifa að einhverju leyti.
Skyndimyndir
Afritunar-í-skrifa vélbúnaðurinn er einnig nauðsynlegur grunnur fyrir ZFS atómmyndir og stigvaxandi ósamstillta afritun. Virka skráarkerfið er með benditré sem merkir allar færslur með núverandi gögnum - þegar þú tekur skyndimynd gerirðu einfaldlega afrit af þessu benditré.
Þegar skrá er skrifað yfir á virka skráarkerfið, skrifar ZFS nýju blokkarútgáfuna fyrst á ónotað pláss. Það aftengir síðan gömlu útgáfuna af blokkinni frá núverandi skráarkerfi. En ef einhver skyndimynd vísar til gömlu blokkarinnar er hún samt óbreytt. Gamla blokkin verður í raun ekki endurheimt sem laust pláss fyrr en öllum skyndimyndum sem vísa til þessa blokkar er eytt!
Afritun
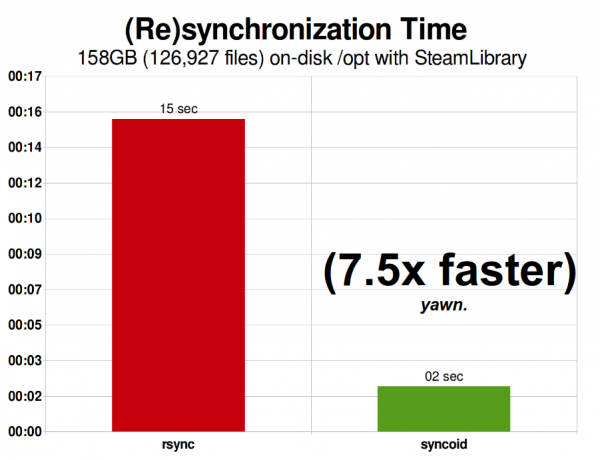
Steam bókasafnið mitt árið 2015 var 158 GiB og innihélt 126 skrár. Þetta er nokkuð nálægt ákjósanlegu ástandi fyrir rsync - ZFS afritun yfir netið var "aðeins" 927% hraðari.
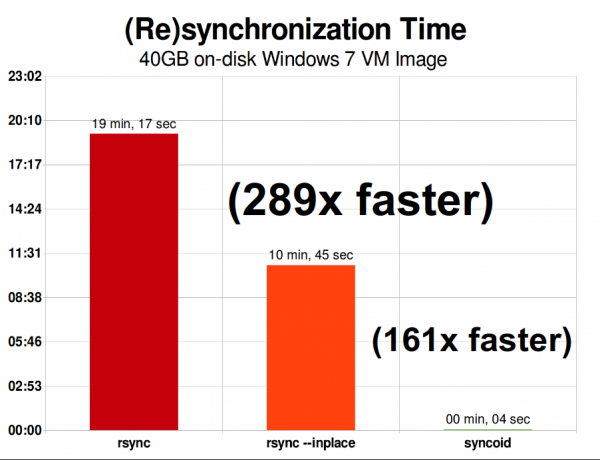
Á sama neti, afritun á einni 40 gígabæta myndskrá af sýndarvél Windows 7 er allt önnur saga. Afritun ZFS er 289 sinnum hraðari en rsync — eða „aðeins“ 161 sinnum hraðari ef þú ert nógu klár til að kalla á rsync með --inplace rofanum.
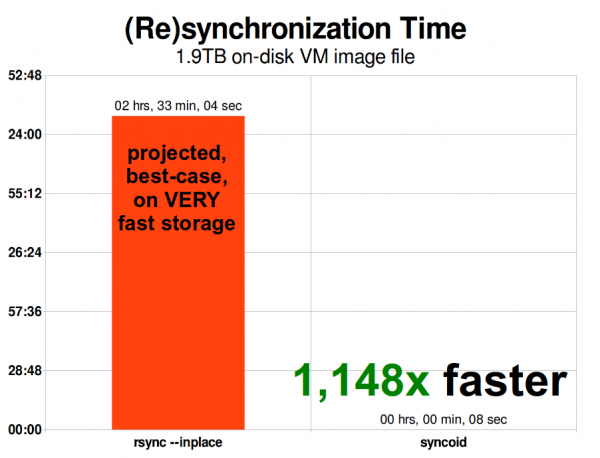
Þegar VM mynd er stækkuð mun rsync stækka hana. 1,9 TiB er ekki það stórt fyrir nútíma VM mynd - en það er nógu stórt til að ZFS afritun er 1148 sinnum hraðari en rsync, jafnvel með --inplace rökum rsync
Þegar þú hefur skilið hvernig skyndimyndir virka ætti að vera auðvelt að átta sig á kjarna afritunar. Þar sem skyndimynd er bara tré af ábendingum á skrár, þá leiðir það af sér að ef við gerum það zfs send skyndimynd, þá sendum við bæði þetta tré og allar færslur sem tengjast því. Þegar við sendum þetta zfs send в zfs receive á skotmarkið skrifar það bæði raunverulegt innihald reitsins og ábendingatréð sem vísar til kubbanna í markgagnagrunninn.
Hlutirnir verða enn áhugaverðari á seinni zfs send. Við höfum nú tvö kerfi, sem hvert inniheldur poolname/datasetname@1, og þú tekur nýja skyndimynd poolname/datasetname@2. Þess vegna, í upprunalegu lauginni sem þú hefur datasetname@1 и datasetname@2, og í marklauginni enn sem komið er aðeins fyrsta skyndimyndin datasetname@1.
Þar sem við höfum sameiginlega skyndimynd á milli upprunans og skotmarksins datasetname@1, við getum gert það stigvaxandi zfs send yfir það. Þegar við segjum við kerfið zfs send -i poolname/datasetname@1 poolname/datasetname@2, það ber saman tvö benditré. Allar ábendingar sem eru aðeins til í @2, vísa augljóslega til nýrra blokka - þannig að við þurfum innihald þessara blokka.
Á ytra kerfi, vinnsla stigvaxandi send alveg jafn einfalt. Fyrst skrifum við allar nýjar færslur sem eru með í straumnum send, og bættu svo bendilum við þær blokkir. Voila, við höfum @2 í nýja kerfinu!
ZFS ósamstilltur stigvaxandi afritun er gríðarleg framför frá fyrri aðferðum sem ekki eru byggðar á skyndimynd eins og rsync. Í báðum tilfellum eru aðeins breytt gögn flutt - en rsync verður fyrst lesa af disknum öll gögn á báðum hliðum til að athuga summan og bera hana saman. Aftur á móti les ZFS afritun ekkert nema benditré - og allar blokkir sem eru ekki til staðar í samnýttu skyndimyndinni.
Innbyggð þjöppun
Afritunar-í-skrifa vélbúnaðurinn einfaldar einnig innbyggða þjöppunarkerfið. Í hefðbundnu skráarkerfi er þjöppun erfið - bæði gamla útgáfan og nýja útgáfan af breyttu gögnunum eru í sama rými.
Ef við lítum á gagnastykki í miðri skrá sem byrjar lífið sem megabæti af núllum frá 0x00000000 og svo framvegis, þá er mjög auðvelt að þjappa því í einn geira á disknum. En hvað gerist ef við skiptum megabætinu af núllum út fyrir megabæti af ósamþjöppanlegum gögnum eins og JPEG eða gervi-handahófi hávaða? Óvænt mun þetta megabæt af gögnum þurfa ekki einn, heldur 256 4 KiB geira, og á þessum stað á disknum er aðeins einn geiri frátekinn.
ZFS hefur ekki þetta vandamál, þar sem breyttar færslur eru alltaf skrifaðar í ónotað pláss - upprunalega blokkin tekur aðeins einn 4 KiB geira, og nýja metið mun taka 256, en þetta er ekki vandamál - nýlega breytt brot úr " miðju" skráarinnar væri skrifað í ónotað pláss óháð því hvort stærð hennar hefur breyst eða ekki, þannig að fyrir ZFS er þetta nokkuð venjulegt ástand.
Sjálfgefið er óvirkt fyrir innfædd ZFS-þjöppun og kerfið býður upp á innstunganlega reiknirit - sem stendur LZ4, gzip (1-9), LZJB og ZLE.
- LZ4 er streymisalgrím sem býður upp á mjög hraðvirka þjöppun og afþjöppun og afköst fyrir flest notkunartilvik - jafnvel á frekar hægum örgjörvum.
- GZIP er virðulegt reiknirit sem allir Unix notendur þekkja og elska. Það er hægt að útfæra það með þjöppunarstigum 1-9, þar sem þjöppunarhlutfall og örgjörvanotkun eykst þegar það nálgast þrep 9. Reikniritið hentar vel fyrir alla texta (eða önnur mjög þjappanleg) notkunartilvik, en veldur annars oft örgjörvavandamálum - notaðu það með aðgát, sérstaklega á hærri stigum.
- LZJB er upprunalega reikniritið í ZFS. Hann er úreltur og ætti ekki lengur að nota hann, LZ4 fer fram úr honum á allan hátt.
- ILLA - núllstigi kóðun, núllstig kóðun. Það snertir alls ekki venjuleg gögn heldur þjappar saman stórum röðum af núllum. Gagnlegt fyrir algjörlega ósamþjappanleg gagnasöfn (eins og JPEG, MP4 eða önnur þegar þjöppuð snið) þar sem þau hunsa ósamþjöppuð gögn en þjappa ónotuðu plássi í færslunum sem myndast.
Við mælum með LZ4 þjöppun fyrir næstum öll notkunartilvik; árangursrefsingin þegar lendir í ósamþjöppanlegum gögnum er mjög lítil, og vöxtur Áhrifin á afköst dæmigerðra gagna eru umtalsverð. Afrita mynd af sýndarvél fyrir nýja uppsetningu stýrikerfis. Windows (nýuppsett stýrikerfi, engin gögn inni ennþá) compression=lz4 fór 27% hraðar en með compression=noneÍ .
ARC - aðlagandi skiptiskyndiminni
ZFS er eina nútíma skráarkerfið sem við vitum um sem notar eigin lestur skyndiminni kerfi, frekar en að treysta á síðu skyndiminni stýrikerfisins til að geyma afrit af nýlesnum blokkum í vinnsluminni.
Þó að innfæddur skyndiminni sé ekki vandræðalaus - getur ZFS ekki svarað nýjum minnisúthlutunarbeiðnum eins fljótt og kjarninn, svo nýja áskorunin malloc() á minnisúthlutun gæti mistekist ef það þarf vinnsluminni sem er upptekið af ARC. En það eru góðar ástæður til að nota þitt eigið skyndiminni, að minnsta kosti í bili.
Öll þekkt nútíma stýrikerfi, þar á meðal MacOS, Windows, Linux og BSD nota LRU (Least Recently Used) reiknirit til að útfæra síðuskyndiminnið. Þetta er frumstætt reiknirit sem færir skyndiminnisblokk „efst í biðröðina“ eftir hverja lestur og fjarlægir blokkir „neðst í biðröðina“ eftir þörfum til að bæta við nýjum skyndiminniskortum (blokkir sem hefðu átt að vera lesnar af diski frekar en úr skyndiminninu) efst.
Reikniritið virkar venjulega fínt, en á kerfum með stór vinnandi gagnasöfn, leiðir LRU auðveldlega til þrengingar - útrýmir oft nauðsynlegum blokkum til að gera pláss fyrir blokkir sem verða aldrei lesnar úr skyndiminni aftur.
er mun minna barnalegt reiknirit sem hægt er að hugsa um sem "vegið" skyndiminni. Í hvert sinn sem kubb í skyndiminni er lesin verður hún aðeins „þyngri“ og erfiðara að reka hana út – og jafnvel eftir að kubb hefur verið vísað út fylgst með innan ákveðins tíma. Kubb sem hefur verið rekin út en síðan þarf að lesa aftur inn í skyndiminni verður líka "þyngri".
Lokaniðurstaðan af þessu öllu er skyndiminni með miklu hærra högghlutfalli, hlutfallinu á milli skyndiminnishittinga (lest fram úr skyndiminni) og skyndiminnimissa (les af diski). Þetta er ákaflega mikilvæg tölfræði - ekki aðeins eru skyndiminnishittingarnar sjálfar afgreiddar í stærðargráðum, heldur er einnig hægt að afgreiða skyndiminnismissir hraðar, þar sem því fleiri skyndiminnihits, því færri samhliða diskabeiðnir og lægri leynd fyrir þá sem eftir eru sem verða vera borinn fram með diski.
Ályktun
Eftir að hafa lært grunn merkingarfræði ZFS - hvernig afrita-í-skrifa virkar, sem og tengslin milli geymslupúls, sýndartækja, blokka, geira og skráa - erum við tilbúin að ræða raunverulegan árangur með rauntölum.
Í næsta kafla munum við skoða raunverulega afköst laugar með spegluðum vdevs og RAIDz, samanborið við hvert annað, sem og samanborið við hefðbundnar kjarna RAID-toppfræði. Linuxsem við rannsökuðum .
Í fyrstu vildum við ná aðeins yfir grunnatriðin - ZFS staðfræðina sjálfa - en eftir það slíkt við skulum búa okkur undir að tala um fullkomnari uppsetningu og stillingu ZFS, þar á meðal notkun á auka vdev gerðum eins og L2ARC, SLOG og Special Allocation.
Heimild: www.habr.com
