

Af og til þarf verktaki framsenda sett af breytum eða jafnvel heilu úrvali til beiðninnar "við innganginn". Stundum rekst maður á mjög undarlegar lausnir á þessu vandamáli.
Við skulum fara aftur á bak og sjá hvað á ekki að gera, hvers vegna og hvernig við getum gert það betur.
Bein innsetning gilda í beiðnina
Það lítur venjulega einhvern veginn svona út:
query = "SELECT * FROM tbl WHERE id = " + value...eða svona:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Þessi aðferð hefur verið sögð, skrifuð og nóg:

Næstum alltaf er þetta bein leið að SQL innspýtingum og óþarfa álag á viðskiptarökfræði, sem neyðist til að „líma“ fyrirspurnarlínuna þína.
Aðeins er hægt að réttlæta þessa nálgun að hluta ef þörf krefur með því að nota skipting í PostgreSQL útgáfum 10 og hér að neðan til að fá skilvirkari áætlun. Í þessum útgáfum er listi yfir skannaðar hluta ákvarðaður án þess að taka tillit til sendra breytu, aðeins á grundvelli beiðninnar.
$n-rök
Nota breytur er góð, það gerir þér kleift að nota , sem dregur úr álagi bæði á viðskiptarökfræðinni (fyrirspurnarstrengurinn er myndaður og sendur aðeins einu sinni) og á gagnagrunnsþjóninum (ekki krafist endurþáttunar og tímasetningar fyrir hvert fyrirspurnartilvik).
Breytilegur fjöldi röka
Vandamál munu bíða okkar þegar við viljum senda óþekktan fjölda röka:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Ef við skiljum beiðnina eftir á þessu formi, þó það verndar okkur fyrir hugsanlegum inndælingum, mun það samt leiða til þess að sameina/þátta beiðnina fyrir hvern valmöguleika eftir fjölda röksemda. Það er betra en að gera það í hvert skipti, en þú getur verið án þess.
Það er nóg að senda aðeins eina færibreytu sem inniheldur serialized array framsetning:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'Eini munurinn er nauðsyn þess að breyta röksemdinni beinlínis í þá fylkisgerð sem óskað er eftir. En þetta veldur ekki vandamálum, þar sem við vitum þegar fyrirfram hvert við erum að fara.
Að flytja sýni (fylki)
Venjulega eru þetta alls kyns möguleikar til að flytja gagnasett til innsetningar í gagnagrunninn „í einni beiðni“:
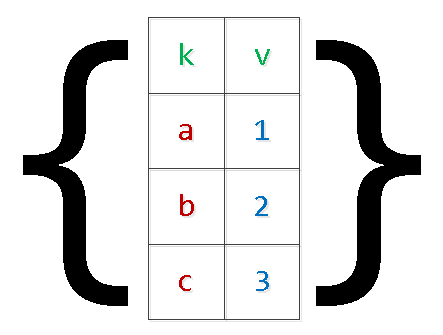
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Til viðbótar við vandamálin sem lýst er hér að ofan við að „líma aftur“ beiðnina getur þetta einnig leitt okkur til búinn með minni og netþjónshrun. Ástæðan er einföld - PG áskilur sér viðbótarminni fyrir rök, og fjöldi skráa í settinu takmarkast aðeins af umsóknarþörfum viðskiptarökfræðinnar. Í sérstaklega klínískum tilfellum þurfti ég að sjá „númer“ rök eru meira en $9000 - ekki gera þetta svona.
Við skulum endurskrifa beiðnina með því að nota nú þegar „tveggja stiga“ raðgreiningu:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Já, ef um er að ræða „flókin“ gildi inni í fylki, verða þau að vera umkringd gæsalöppum.
Það er ljóst að á þennan hátt er hægt að „stækka“ úrval með handahófskenndum fjölda reita.
óþægindi, óþægindi, …
Af og til eru valmöguleikar til að fara framhjá í stað „fylkis fylkja“ nokkra „fylki af dálkum“ sem ég nefndi :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Með þessari aðferð, ef þú gerir mistök þegar þú býrð til lista yfir gildi fyrir mismunandi dálka, er mjög auðvelt að fá óvænt úrslit, sem fer einnig eftir útgáfu netþjónsins:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
Frá útgáfu 9.3 hefur PostgreSQL haft fullgildar aðgerðir til að vinna með json gerðinni. Þess vegna, ef skilgreining á inntaksbreytum kemur fram í vafranum þínum, geturðu myndað hana þar json hlutur fyrir SQL fyrirspurn:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Fyrir fyrri útgáfur er hægt að nota sömu aðferð til að hver (hstore), en rétt "convolution" með flóknum hlutum sem sleppur í hstore getur valdið vandamálum.
json_populate_recordset
Ef þú veist fyrirfram að gögnin úr „inntak“ json fylkinu verða notuð til að fylla út einhverja töflu, geturðu sparað mikið í „frávísunar“ reitum og varpað þeim í þær tegundir sem krafist er með því að nota json_populate_recordset aðgerðina:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
Og þessi aðgerð mun einfaldlega „stækka“ yfirgefinn fjölda hluta í val, án þess að treysta á töflusniðið:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2TÍMABUNDIN BORÐ
En ef gagnamagnið í yfirfærða sýninu er mjög mikið, þá er erfitt og stundum ómögulegt að henda því í eina raðbreytu þar sem það krefst einu sinni úthluta miklu minni. Til dæmis þarf að safna stórum pakka af gögnum um atburði úr utanaðkomandi kerfi í langan, langan tíma, og síðan á að vinna það einu sinni á gagnagrunnsmegin.
Í þessu tilviki væri besta lausnin að nota :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
Aðferðin er góð fyrir einstaka flutninga á miklu magni gögn.
Frá sjónarhóli þess að lýsa uppbyggingu gagna sinna, er tímabundin tafla frábrugðin „venjulegri“ á aðeins einn hátt í pg_class kerfistöflunni, og inn pg_type, pg_depend, pg_attribute, pg_attrdef, ... - ekki neitt.
Þess vegna mun slík tafla í vefkerfum með miklum fjölda skammtímatenginga fyrir hvert þeirra búa til nýjar kerfisfærslur í hvert sinn sem eyðast þegar tengingu við gagnagrunninn er lokað. Að lokum, stjórnlaus notkun á TEMP TABLE leiðir til „bólgunar“ á töflum í pg_catalog og hægja á mörgum aðgerðum sem nota þær.
Auðvitað er hægt að takast á við þetta með því að nota reglubundin leið VACUUM FULL samkvæmt kerfisskráartöflum.
Session breytur
Gerum ráð fyrir að vinnsla gagna frá fyrra tilviki sé nokkuð flókið fyrir eina SQL fyrirspurn, en þú vilt gera það frekar oft. Það er að segja að við viljum nota málsmeðferð í , en það verður of dýrt að nota gagnaflutning í gegnum tímabundnar töflur.
Við munum heldur ekki geta notað $n-færibreytur til að fara í nafnlausa blokk. Setubreytur og aðgerðin munu hjálpa okkur að komast út úr þessum aðstæðum núverandi_stilling.
Fyrir útgáfu 9.2 var nauðsynlegt að forstilla sérsniðnar_breytuflokkar fyrir "þínar" lotubreytur. Á núverandi útgáfum geturðu skrifað eitthvað á þessa leið:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3Aðrar lausnir má finna á öðrum studdum málsmeðferðartungumálum.
Kanntu einhverjar aðrar leiðir? Deildu í athugasemdum!
Heimild: www.habr.com
