

Góðan daginn Ég heiti Danil Lipovoy, teymið okkar hjá Sbertech byrjaði að nota HBase sem geymslu fyrir rekstrargögn. Við námið hefur safnast upp reynsla sem mig langaði að setja í kerfi og lýsa (við vonum að hún nýtist mörgum). Allar tilraunir hér að neðan voru gerðar með HBase útgáfum 1.2.0-cdh5.14.2 og 2.0.0-cdh6.0.0-beta1.
- Almennur byggingarlist
- Að skrifa gögn í HBASE
- Að lesa gögn frá HBASE
- Skyndiminni gagna
- Lotugagnavinnsla MultiGet/MultiPut
- Stefna til að skipta töflum í svæði (skipting)
- Bilunarþol, þjöppun og staðsetning gagna
- Stillingar og árangur
- Streitupróf
- Niðurstöður
1. Almennur byggingarlist
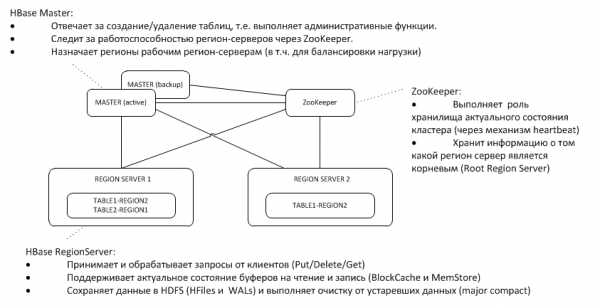
Varameistarinn hlustar á hjartslátt þess virka á ZooKeeper hnútnum og, ef hann hverfur, tekur við hlutverkum skipstjórans.
2. Skrifaðu gögn í HBASE
Í fyrsta lagi skulum við skoða einfaldasta tilvikið - að skrifa lykilgildishlut í töflu með því að nota put(rowkey). Viðskiptavinurinn verður fyrst að finna út hvar Root Region Server (RRS), sem geymir hbase:meta töfluna, er staðsettur. Hann fær þessar upplýsingar frá ZooKeeper. Eftir það opnar það RRS og les hbase:meta töfluna, þaðan sem það dregur upplýsingar um hvaða RegionServer (RS) ber ábyrgð á að geyma gögn fyrir tiltekinn línulykil í áhugatöflunni. Til notkunar í framtíðinni er meta taflan í skyndiminni af viðskiptavininum og því fara síðari símtöl hraðar, beint til RS.
Næst, eftir að hafa fengið beiðni, skrifar RS hana fyrst og fremst á WriteAheadLog (WAL), sem er nauðsynlegt til að endurheimta ef hrun verður. Vistar síðan gögnin í MemStore. Þetta er biðminni í minni sem inniheldur flokkað sett af lyklum fyrir tiltekið svæði. Hægt er að skipta töflu í svæði (skilrúm), sem hvert um sig inniheldur ósamræmt sett af lyklum. Þetta gerir þér kleift að setja svæði á mismunandi netþjóna til að ná meiri afköstum. En þrátt fyrir að þessi yfirlýsing sé augljós, munum við sjá síðar að þetta virkar ekki í öllum tilvikum.
Eftir að færslu hefur verið sett í MemStore er svari skilað til viðskiptavinarins um að færslan hafi verið vistuð með góðum árangri. Hins vegar er það í raun aðeins geymt í biðminni og kemst aðeins á diskinn eftir að ákveðinn tími er liðinn eða þegar hann er fylltur með nýjum gögnum.
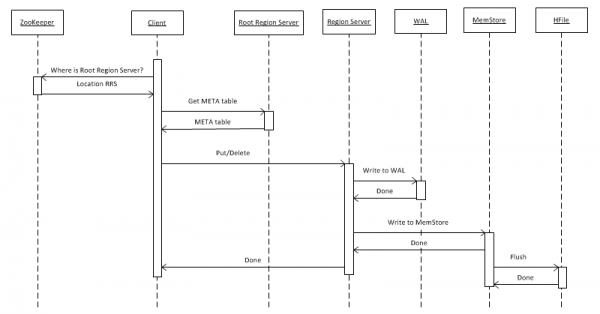
Þegar aðgerðin „Eyða“ er framkvæmd er gögnum ekki eytt líkamlega. Þær eru einfaldlega merktar sem eytt og eyðileggingin sjálf á sér stað á því augnabliki sem kallar er á stóra samningsaðgerðina, sem lýst er nánar í 7. mgr.
Skrár á HFile sniði safnast saman í HDFS og af og til fer smávægilegt ferli af stað, sem einfaldlega sameinar litlar skrár í stærri án þess að eyða neinu. Með tímanum breytist þetta í vandamál sem birtist aðeins við lestur gagna (við munum koma aftur að þessu aðeins síðar).
Til viðbótar við hleðsluferlið sem lýst er hér að ofan, er mun skilvirkari aðferð, sem er kannski sterkasta hlið þessa gagnagrunns - BulkLoad. Það liggur í þeirri staðreynd að við myndum sjálfstætt HFiles og setjum þær á disk, sem gerir okkur kleift að skala fullkomlega og ná mjög viðeigandi hraða. Reyndar er takmörkunin hér ekki HBase, heldur getu vélbúnaðarins. Hér að neðan eru ræsingarniðurstöður á klasa sem samanstendur af 16 RegionServers og 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 þræðir), HBase útgáfa 1.2.0-cdh5.14.2.
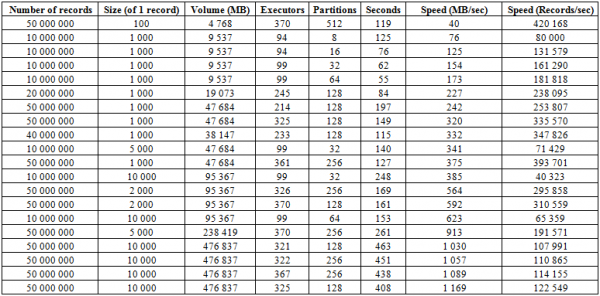
Hér má sjá að með því að fjölga skiptingum (svæðum) í töflunni, sem og Spark executors, fáum við aukinn niðurhalshraða. Einnig fer hraðinn eftir hljóðstyrk upptökunnar. Stórir kubbar gefa aukningu í MB/sek, litlar kubbar í fjölda settra færslur á tímaeiningu að öðru óbreyttu.
Þú getur líka byrjað að hlaða inn í tvö borð á sama tíma og fengið tvöfaldan hraða. Hér að neðan má sjá að ritun 10 KB blokka í tvær töflur í einu á sér stað á um 600 MB/sek. nr. 1275 hér að ofan)

En seinni keyrslan með 50 KB met sýnir að niðurhalshraðinn eykst lítillega, sem bendir til þess að hann sé að nálgast viðmiðunarmörkin. Á sama tíma þarftu að hafa í huga að það er nánast ekkert álag búið til á HBASE sjálfu, allt sem þarf til þess er að gefa fyrst gögn úr hbase:meta og eftir að hafa fóðrað HFiles, endurstilla BlockCache gögnin og vista MemStore biðminni á diskinn, ef hann er ekki tómur.
3. Að lesa gögn frá HBASE
Ef við gerum ráð fyrir að viðskiptavinurinn hafi nú þegar allar upplýsingar frá hbase:meta (sjá lið 2), þá fer beiðnin beint til RS þar sem nauðsynlegur lykill er geymdur. Fyrst er leitin framkvæmd í MemCache. Burtséð frá því hvort gögn eru þar eða ekki, þá fer leitin einnig fram í BlockCache biðminni og, ef þörf krefur, í HFiles. Ef gögn fundust í skránni eru þau sett í BlockCache og verður skilað hraðar við næstu beiðni. Leit í HFile er tiltölulega hröð þökk sé notkun Bloom síunnar, þ.e. eftir að hafa lesið lítið magn af gögnum, ákvarðar það strax hvort þessi skrá inniheldur nauðsynlegan lykil og ef ekki, heldur hún áfram í þann næsta.
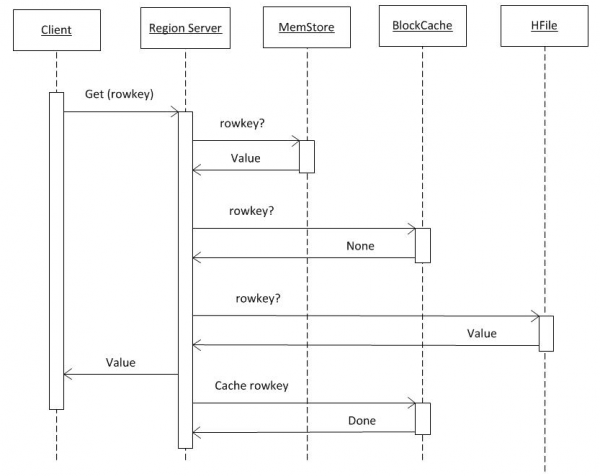
Eftir að hafa fengið gögn frá þessum þremur aðilum myndar RS svar. Sérstaklega getur það flutt nokkrar fundnar útgáfur af hlut í einu ef viðskiptavinurinn óskaði eftir útgáfu.
4. Skyndiminni gagna
MemStore og BlockCache biðminni taka allt að 80% af úthlutað RS minni á haugnum (afgangurinn er frátekinn fyrir RS þjónustuverkefni). Ef dæmigerður notkunarhamur er þannig að ferlar skrifa og lesa strax sömu gögnin, þá er skynsamlegt að minnka BlockCache og auka MemStore, vegna þess að Þegar ritun gagna kemst ekki inn í skyndiminni til lestrar verður BlockCache notað sjaldnar. BlockCache biðminni samanstendur af tveimur hlutum: LruBlockCache (alltaf on-heap) og BucketCache (venjulega off-heap eða á SSD). BucketCache ætti að nota þegar það er mikið af lestrarbeiðnum og þær passa ekki inn í LruBlockCache, sem leiðir til virkrar vinnu Garbage Collector. Á sama tíma ættir þú ekki að búast við róttækri frammistöðuaukningu af notkun lesskyndiminni, en við munum koma aftur að þessu í 8. mgr.
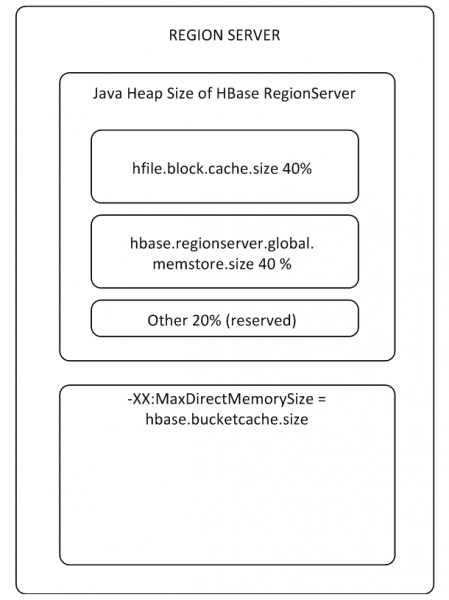
Það er eitt BlockCache fyrir allt RS og það er eitt MemStore fyrir hvert borð (eitt fyrir hverja dálkafjölskyldu).
Как í orði, þegar skrifað er, fara gögn ekki inn í skyndiminni og reyndar eru slíkar breytur CACHE_DATA_ON_WRITE fyrir töfluna og "Cache DATA on Write" fyrir RS stilltar á falskar. Hins vegar, í reynd, ef við skrifum gögn í MemStore, skolum þeim síðan á diskinn (þar með hreinsað þau), eyðum síðan skránni sem myndast og með því að framkvæma get beiðni munum við taka á móti gögnunum. Þar að auki, jafnvel þótt þú slökkvi algjörlega á BlockCache og fyllir töfluna með nýjum gögnum, endurstillir síðan MemStore á diskinn, eyðir þeim og biður um þau úr annarri lotu, þá verða þau samt sótt einhvers staðar frá. Svo HBase geymir ekki aðeins gögn, heldur einnig dularfulla leyndardóma.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
„Cache DATA on Read“ færibreytan er stillt á falskt. Ef þú hefur einhverjar hugmyndir, velkomið að ræða þær í athugasemdum.
5. Hópgagnavinnsla MultiGet/MultiPut
Að vinna úr stakum beiðnum (Fá/Setja/Eyða) er frekar dýr aðgerð, svo ef mögulegt er ættirðu að sameina þær í lista eða lista, sem gerir þér kleift að fá verulegan árangur. Þetta á sérstaklega við um skrifaaðgerðina, en við lestur er eftirfarandi gryfja. Grafið hér að neðan sýnir tímann til að lesa 50 færslur úr MemStore. Lestur fór fram í einum þræði og sýnir lárétti ásinn fjölda lykla í beiðninni. Hér má sjá að þegar stækkað er í þúsund lykla í einni beiðni fellur framkvæmdartíminn niður, þ.e. hraði eykst. Hins vegar, með MSLAB stillingu virkan sjálfgefið, eftir þennan þröskuld byrjar róttæk lækkun á frammistöðu, og því meira sem gagnamagnið er í skránni, því lengri er notkunartíminn.
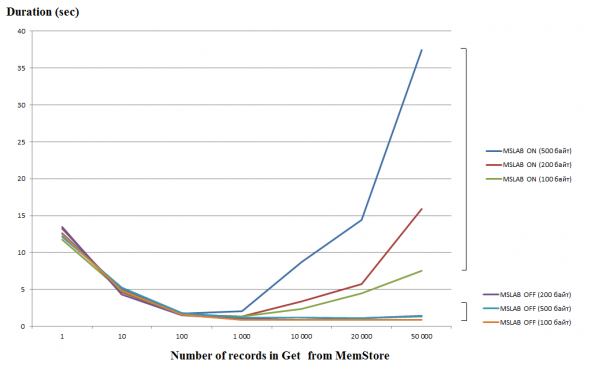
Próf voru gerðar á sýndarvél, 8 kjarna, útgáfu HBase 2.0.0-cdh6.0.0-beta1.
MSLAB stillingin er hönnuð til að draga úr hrúgu sundrun, sem á sér stað vegna blöndunar nýrrar og gamallar kynslóðar gagna. Sem lausn, þegar MSLAB er virkt, eru gögnin sett í tiltölulega litlar frumur (klumpar) og unnin í klumpur. Þar af leiðandi, þegar magn í umbeðnum gagnapakka fer yfir úthlutaðri stærð, lækkar afköst verulega. Aftur á móti er heldur ekki ráðlegt að slökkva á þessari stillingu, þar sem það mun leiða til stöðvunar vegna GC á augnablikum mikillar gagnavinnslu. Góð lausn er að auka rúmmál frumunnar ef um er að ræða virka ritun í gegnum putta á sama tíma og lestri. Það er athyglisvert að vandamálið kemur ekki upp ef þú keyrir skolunarskipunina eftir upptöku, sem endurstillir MemStore á diskinn, eða ef þú hleður með BulkLoad. Taflan hér að neðan sýnir að fyrirspurnir frá MemStore um stærri (og sama magn) gagna leiða til hægfara. Hins vegar, með því að auka bitastærðina, komum við vinnslutímanum í eðlilegt horf.
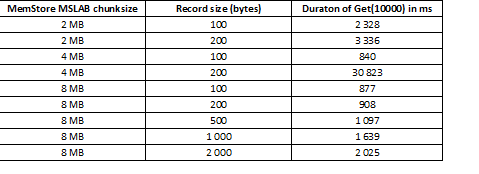
Auk þess að auka bitastærðina hjálpar að skipta gögnunum eftir svæðum, þ.e. borðskipting. Þetta leiðir til þess að færri beiðnir berast til hvers svæðis og ef þær passa inn í klefa haldast viðbrögðin góð.
6. Stefna til að skipta töflum í svæði (skipting)
Þar sem HBase er lykilgildi geymsla og skipting fer fram eftir lyklum, er afar mikilvægt að skipta gögnunum jafnt yfir öll svæði. Til dæmis, skipting slíkrar töflu í þrjá hluta mun leiða til þess að gögnunum er skipt í þrjú svæði:
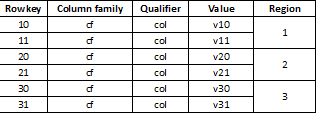
Það gerist að þetta leiðir til mikillar hægingar ef gögnin sem hlaðið er seinna líta út eins og til dæmis löng gildi, sem flest byrja á sama tölustaf, til dæmis:
1000001
1000002
...
1100003
Þar sem lyklarnir eru geymdir sem bætafylki munu þeir allir byrja eins og tilheyra sama svæði #1 sem geymir þetta lyklasvið. Það eru nokkrar skiptingaraðferðir:
HexStringSplit – Breytir lyklinum í sextándakóðaðan streng á bilinu "00000000" => "FFFFFFFF" og fyllir þann vinstri með núllum.
UniformSplit – Breytir lyklinum í bætafylki með sextándakóðun á bilinu "00" => "FF" og fyllingu hægra megin með núllum.
Að auki geturðu tilgreint hvaða svið eða sett af lyklum sem er fyrir skiptingu og stillt sjálfvirka skiptingu. Hins vegar er ein einfaldasta og áhrifaríkasta aðferðin UniformSplit og notkun kjötkássasamtengingar, til dæmis mikilvægasta parið af bæti frá því að keyra lykilinn í gegnum CRC32(rowkey) aðgerðina og röðtakkann sjálfan:
kjötkássa + línulykill
Þá verður öllum gögnum dreift jafnt yfir svæði. Við lestur er fyrstu tveimur bætunum einfaldlega hent og upprunalegi lykillinn er eftir. RS stjórnar einnig magni gagna og lykla á svæðinu og ef farið er yfir mörkin skiptir það sjálfkrafa niður í hluta.
7. Bilanaþol og staðsetning gagna
Þar sem aðeins eitt svæði er ábyrgt fyrir hverju setti lykla, er lausnin á vandamálum sem tengjast RS-hruni eða úreldingu að geyma öll nauðsynleg gögn í HDFS. Þegar RS fellur, skynjar meistarinn þetta með því að hjartsláttur er ekki á ZooKeeper hnútnum. Síðan úthlutar það þjónustusvæðinu til annars RS og þar sem HF-skrárnar eru geymdar í dreifðu skráarkerfi, les nýi eigandinn þær og heldur áfram að þjóna gögnunum. Hins vegar, þar sem sum gagnanna kunna að vera í MemStore og hafði ekki tíma til að komast inn í HFiles, er WAL, sem er einnig geymt í HDFS, notað til að endurheimta feril aðgerða. Eftir að breytingunum hefur verið beitt getur RS brugðist við beiðnum en flutningurinn leiðir til þess að sum gagna og ferla sem þjónusta þau lenda á mismunandi hnútum, þ.e. byggðarlagi fer fækkandi.
Lausnin á vandamálinu er mikil þjöppun - þessi aðferð færir skrár til þeirra hnúta sem bera ábyrgð á þeim (þar sem svæði þeirra eru staðsett), sem leiðir til þess að á meðan á þessari aðferð stendur eykst álagið á netið og diskana verulega. Hins vegar, í framtíðinni, er aðgengi að gögnum verulega flýtt. Að auki framkvæmir major_compaction að sameina allar HFiles í eina skrá innan svæðis og hreinsar einnig gögn eftir töflustillingum. Til dæmis er hægt að tilgreina fjölda útgáfur af hlut sem verður að geyma eða líftíma eftir sem hlutnum er eytt líkamlega.
Þessi aðferð getur haft mjög jákvæð áhrif á rekstur HBase. Myndin hér að neðan sýnir hvernig árangur minnkaði vegna virkrar gagnaskráningar. Hér má sjá hvernig 40 þræðir skrifuðu í eina töflu og 40 þræðir lesa gögn samtímis. Að skrifa þræði mynda fleiri og fleiri HFiles, sem eru lesnar af öðrum þráðum. Fyrir vikið þarf að fjarlægja sífellt fleiri gögn úr minni og að lokum fer GC að virka, sem nánast lamar alla vinnu. Hleypt af stokkunum meiriháttar þjöppun leiddi til hreinsunar á ruslinu sem leiddi til og endurreisnar framleiðni.
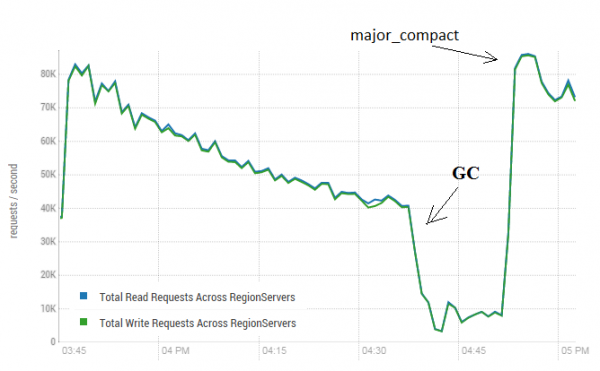
Prófið var gert á 3 DataNodes og 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 þræðir). HBase útgáfa 1.2.0-cdh5.14.2
Þess má geta að meiriháttar þjöppun var hleypt af stokkunum á „lifandi“ töflu, þar sem gögn voru skrifuð og lesin á virkan hátt. Fullyrðing var á netinu um að þetta gæti leitt til rangra svara við lestur gagna. Til að athuga, var sett af stað ferli sem myndaði ný gögn og skrifaði þau í töflu. Eftir það las ég strax og athugaði hvort gildið sem myndast félli saman við það sem skrifað var niður. Á meðan þetta ferli var í gangi var meiriháttar þjöppun keyrð um 200 sinnum og ekki ein ein bilun var skráð. Kannski kemur vandamálið sjaldan fyrir og aðeins við mikið álag, þannig að það er öruggara að stöðva skrif- og lestrarferlið eins og áætlað var og framkvæma hreinsun til að koma í veg fyrir slíka GC-samdrátt.
Einnig hefur meiriháttar þjöppun ekki áhrif á stöðu MemStore; til að skola það á diskinn og þétta það þarftu að nota flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Stillingar og árangur
Eins og áður hefur komið fram sýnir HBase mesta velgengni sína þar sem það þarf ekki að gera neitt, þegar það keyrir BulkLoad. Þetta á þó við um flest kerfi og fólk. Hins vegar er þetta tól hentugra til að geyma gögn í lausu í stórum blokkum, en ef ferlið krefst margra samkeppnisbeiðna um lestur og ritun eru Get og Set skipanirnar sem lýst er hér að ofan notaðar. Til að ákvarða bestu færibreyturnar voru ræsingar framkvæmdar með ýmsum samsetningum af töflubreytum og stillingum:
- 10 þræðir voru settir af stað samtímis 3 sinnum í röð (köllum þetta þræðiblokk).
- Notkunartími allra þráða í blokk var meðaltal og var lokaniðurstaðan af rekstri blokkarinnar.
- Allir þræðir unnu með sömu töflunni.
- Fyrir hverja byrjun á þræðiblokkinni var gerð meiriháttar þjöppun.
- Hver blokk framkvæmdi aðeins eina af eftirfarandi aðgerðum:
—Settu
— Fáðu
—Fá+Settu
- Hver blokk framkvæmdi 50 endurtekningar á aðgerð sinni.
- Blokkstærð færslu er 100 bæti, 1000 bæti eða 10000 bæti (handahófi).
- Blokkir voru settir af stað með mismunandi fjölda lykla sem óskað var eftir (annaðhvort einum lykli eða 10).
- Kubbarnir voru keyrðir undir mismunandi borðstillingum. Færibreytum breytt:
— BlockCache = kveikt eða slökkt
— BlockSize = 65 KB eða 16 KB
— Skipting = 1, 5 eða 30
— MSLAB = virkt eða óvirkt
Svo lítur blokkin svona út:
a. Kveikt/slökkt var á MSLAB stillingu.
b. Tafla var búin til þar sem eftirfarandi færibreytur voru stilltar: BlockCache = true/none, BlockSize = 65/16 Kb, Skipting = 1/5/30.
c. Þjöppun var stillt á GZ.
d. 10 þræðir voru ræstir samtímis með 1/10 setja/geta/geta+setja aðgerðir inn í þessa töflu með færslum upp á 100/1000/10000 bæti og framkvæma 50 fyrirspurnir í röð (slembilyklar).
e. D-liður var endurtekinn þrisvar sinnum.
f. Notkunartími allra þráða var að meðaltali.
Allar mögulegar samsetningar voru prófaðar. Það er fyrirsjáanlegt að hraðinn lækki eftir því sem færslustærðin eykst, eða að slökkt sé á skyndiminni mun hægja á. Markmiðið var hins vegar að skilja hversu og marktæk áhrif hverrar færibreytu hefur, þannig að söfnuð gögn voru færð inn í inntak línulegrar aðhvarfsfalls, sem gerir kleift að meta marktektina með t-tölfræði. Hér að neðan eru niðurstöður kubbanna sem framkvæma Put-aðgerðir. Fullt sett af samsetningum 2*2*3*2*3 = 144 valkostir + 72 tk. sumt var gert tvisvar. Þess vegna eru 216 keyrslur alls:
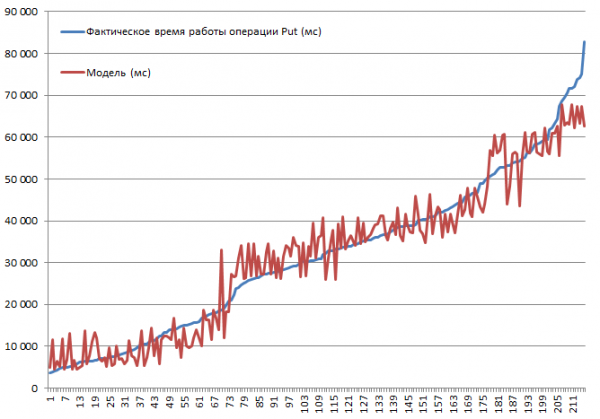
Prófun fór fram á smáþyrping sem samanstóð af 3 DataNodes og 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 þræðir). HBase útgáfa 1.2.0-cdh5.14.2.
Hæsti innsetningarhraði, 3.7 sekúndur, fékkst með slökkt á MSLAB stillingu, á borði með einni skiptingu, með BlockCache virkt, BlockSize = 16, færslur upp á 100 bæti, 10 stykki í pakka.
Lægsti innsetningarhraði, 82.8 sekúndur, var fenginn með MSLAB stillingu virkan, á borði með einni skiptingu, með BlockCache virkt, BlockSize = 16, færslur upp á 10000 bæti, 1 hver.
Nú skulum við líta á líkanið. Við sjáum góð gæði líkansins sem byggir á R2, en það er alveg ljóst að framreikningur er frábending hér. Raunveruleg hegðun kerfisins þegar breytur breytast verður ekki línuleg; þetta líkan er ekki nauðsynlegt til að spá, heldur til að skilja hvað gerðist innan tiltekinna breytu. Til dæmis, hér sjáum við af viðmiðun nemandans að BlockSize og BlockCache færibreytur skipta ekki máli fyrir Put aðgerðina (sem er almennt nokkuð fyrirsjáanleg):

En sú staðreynd að fjölgun skiptinganna leiðir til lækkunar á afköstum er nokkuð óvænt (við höfum þegar séð jákvæð áhrif þess að fjölga skiptingum með BulkLoad), þó skiljanlegt. Í fyrsta lagi, fyrir vinnslu, þarftu að búa til beiðnir til 30 svæða í stað eins, og gagnamagnið er ekki slíkt að það muni skila hagnaði. Í öðru lagi er heildarrekstrartími ákvarðaður af hægasta RS og þar sem fjöldi DataNodes er minni en fjöldi RS, hafa sum svæði núllstað. Jæja, við skulum líta á topp fimm:

Nú skulum við meta árangurinn af því að framkvæma Get blokkir:

Fjöldi skiptinganna hefur misst marks, sem skýrist líklega af því að gögnin eru vel í skyndiminni og lestur skyndiminni er mikilvægasta (tölfræðilega) færibreytan. Að sjálfsögðu er fjölgun skilaboða í beiðni einnig mjög gagnleg fyrir frammistöðu. Toppskor:

Jæja, að lokum, við skulum líta á líkanið af blokkinni sem fyrst framkvæmdi get og setti síðan:

Allar breytur eru mikilvægar hér. Og niðurstöður leiðtoganna:

9. Álagsprófun
Jæja, loksins munum við setja af stað meira og minna almennilegt hleðslu, en það er alltaf áhugaverðara þegar þú hefur eitthvað til að bera saman við. Á vefsíðu DataStax, lykilhönnuðar Cassöndru, er NT af fjölda NoSQL geymslum, þar á meðal HBase útgáfu 0.98.6-1. Hleðsla fór fram með 40 þráðum, gagnastærð 100 bæti, SSD diskar. Niðurstaða prófunar á lestur-breyta-skrifa aðgerðum sýndi eftirfarandi niðurstöður.
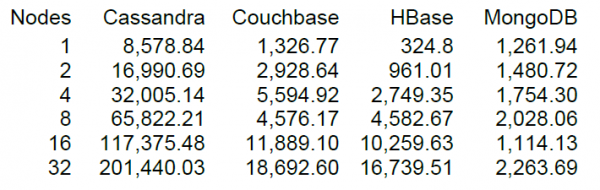
Eftir því sem mér skilst var lestur framkvæmdur í blokkum með 100 færslum og fyrir 16 HBase hnúta sýndi DataStax prófið frammistöðu upp á 10 þúsund aðgerðir á sekúndu.
Það er sem betur fer að þyrpingin okkar hefur líka 16 hnúta, en það er ekki mjög „heppilegt“ að hver þeirra er með 64 kjarna (þræði), en í DataStax prófinu eru þeir aðeins 4. Aftur á móti eru þeir með SSD drif á meðan við erum með HDD diska. eða meira jókst ný útgáfa af HBase og CPU nýtingu við álag nánast ekki marktækt (sjónrænt um 5-10 prósent). Hins vegar skulum við reyna að byrja að nota þessa stillingu. Sjálfgefnar töflustillingar, lestur fer fram á lykilbilinu frá 0 til 50 milljónum af handahófi (þ.e.a.s., í rauninni nýtt í hvert skipti). Taflan inniheldur 50 milljón færslur, skipt í 64 skipting. Lyklarnir eru hashaðir með crc32. Taflastillingar eru sjálfgefnar, MSLAB er virkt. Með því að ræsa 40 þræði, les hver þráður sett af 100 handahófskenndum lyklum og skrifar strax mynduð 100 bæti aftur á þessa lykla.
Standur: 16 DataNode og 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 þræðir). HBase útgáfa 1.2.0-cdh5.14.2.
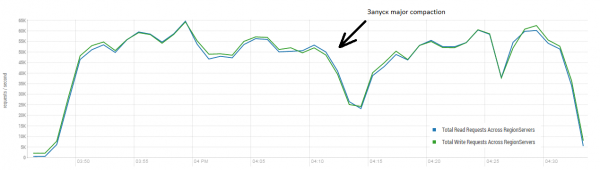
Meðalniðurstaðan er nær 40 þúsund aðgerðum á sekúndu, sem er umtalsvert betra en í DataStax prófinu. Hins vegar, í tilraunaskyni, geturðu breytt skilyrðunum lítillega. Það er alveg ólíklegt að öll vinna fari fram eingöngu á einu borði og einnig aðeins á einstökum lyklum. Gerum ráð fyrir að það sé ákveðið „heitt“ sett af lyklum sem býr til aðalálagið. Þess vegna skulum við reyna að búa til hleðslu með stærri færslum (10 KB), einnig í lotum af 100, í 4 mismunandi töflum og takmarka svið umbeðna lykla við 50 þúsund. Grafið hér að neðan sýnir upphaf 40 þráða, hver þráður les sett af 100 lyklum og skrifar strax af handahófi 10 KB á þessa lykla til baka.
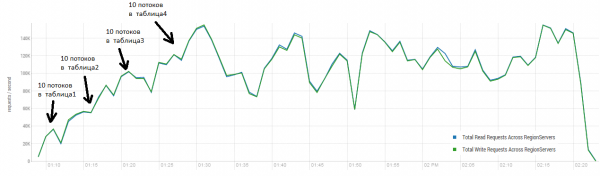
Standur: 16 DataNode og 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 þræðir). HBase útgáfa 1.2.0-cdh5.14.2.
Á meðan á hleðslunni stóð var meiriháttar þjöppun sett í gang nokkrum sinnum, eins og sýnt er hér að ofan, án þessarar aðferðar mun frammistaðan minnka smám saman, hins vegar myndast aukið álag einnig við framkvæmdina. Niðurfellingar eru af ýmsum ástæðum. Stundum luku þræðir að virka og það var hlé á meðan þeir voru endurræstir, stundum bjuggu forrit frá þriðja aðila til álag á klasann.
Að lesa og skrifa strax er ein erfiðasta vinnusviðið fyrir HBase. Ef þú gerir aðeins litlar setja beiðnir, til dæmis 100 bæti, og sameinar þær í pakka með 10-50 þúsund stykki, geturðu fengið hundruð þúsunda aðgerða á sekúndu og staðan er svipuð með skrifbeiðnir. Þess má geta að útkoman er róttækt betri en þær sem DataStax fékk, mest af öllu vegna beiðna í blokkum upp á 50 þús.
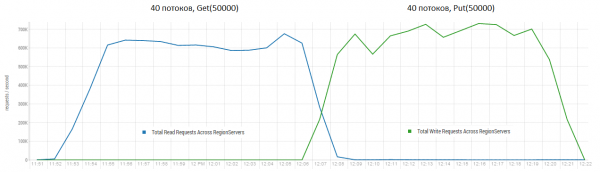
Standur: 16 DataNode og 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 þræðir). HBase útgáfa 1.2.0-cdh5.14.2.
10. Ályktanir
Þetta kerfi er nokkuð sveigjanlega stillt, en áhrif fjölda breytu eru enn óþekkt. Sum þeirra voru prófuð, en voru ekki með í prófunarsettinu sem fékkst. Til dæmis sýndu bráðabirgðatilraunir óverulega þýðingu slíkrar færibreytu eins og DATA_BLOCK_ENCODING, sem kóðar upplýsingar með því að nota gildi frá nálægum frumum, sem er skiljanlegt fyrir gögn sem myndast af handahófi. Ef þú notar mikinn fjölda af tvíteknum hlutum getur ávinningurinn verið verulegur. Almennt má segja að HBase gefur til kynna nokkuð alvarlegan og úthugsaðan gagnagrunn, sem getur verið nokkuð afkastamikill þegar unnið er að aðgerðum með stórum gagnablokkum. Sérstaklega ef hægt er að aðskilja lestrar- og ritferlið í tíma.
Ef það er eitthvað að þínu mati sem er ekki nógu upplýst, þá er ég tilbúinn að segja þér það nánar. Við bjóðum þér að deila reynslu þinni eða ræða ef þú ert ósammála einhverju.
Heimild: www.habr.com
