

Í framhaldi af umræðuefninu um vélanámskeppnir á Habr viljum við kynna lesendum tvær aðrar vettvangar. Þótt þær séu ekki eins stórar og Kaggle, þá er það klárlega þess virði að skoða þær.

Persónulega líkar mér ekki mjög vel við Kaggle af nokkrum ástæðum:
- Í fyrsta lagi standa keppnir þar oft yfir í nokkra mánuði og virk þátttaka krefst mikillar fyrirhafnar;
- Í öðru lagi, opinberir kjarnar (opinberar lausnir). Kaggle-fylgjendur ráðleggja að meðhöndla þá með rósemi tíbetskra munka, en í raun er það frekar vonbrigði þegar eitthvað sem þú hefur eytt mánuði eða tveimur í að vinna að er skyndilega lagt á fat fyrir alla að sjá.
Sem betur fer eru vélanámskeppnir einnig haldnar á öðrum kerfum og við munum ræða nokkrar af þessum keppnum.
| Opinbert tungumál: Enska, Skipuleggjendur: Yandex, Sberbank, HSE | Opinbert tungumál: Rússneska, skipuleggjendur: Mail.ru Group |
| Netumferð: 15. janúar — 11. febrúar 2019; Lokakeppni á staðnum: 4.-6. apríl 2019 | á netinu - frá 7. febrúar til 15. mars; án nettengingar - frá 30. mars til 1. apríl. |
| Gefin eru ákveðin gögn um ögn í Stóra Hadron-hröðlinum (um braut hennar, skriðþunga og aðra frekar flókna eðlisfræðilega breytur), til að ákvarða hvort hún er múon eða ekki. Út frá þessari yfirlýsingu voru tvö verkefni skilgreind: - í einu þurftirðu bara að senda spá þína, — og í hinu tilfellinu var allur kóðinn og líkanið fyrir spár, og frekar strangar takmarkanir á keyrslutíma og minnisnotkun voru settar á keyrsluna. | Fyrir SNA Hackathon keppnina voru skrár yfir birtingar á efni frá opinberum hópum í fréttaveitum notenda safnaðar fyrir febrúar og mars 2018. Prófunarsettið náði yfir síðustu eina og hálfa vikuna í mars. Hver færsla í skránni inniheldur upplýsingar um hvað var sýnt og hverjum, sem og hvernig notandinn brást við efninu: líkaði það, skrifaði athugasemd, hunsaði það eða faldi það fyrir fréttaveitunni. Markmið SNA Hackathon er að raða færslum hvers notanda á samfélagsmiðlinum Odnoklassniki og færa þær færslur sem fá „læk“ eins ofarlega og mögulegt er. Á netstigi var verkefninu skipt í þrjá hluta: 1. raða færslum eftir ýmsum samstarfsviðmiðum 2. raða færslum eftir myndunum sem þær innihalda 3. raða færslum eftir textanum sem þær innihalda |
| Flókin sérsniðin mælikvarði, eitthvað eins og ROC-AUC | Meðaltal ROC-AUC eftir notanda |
| Verðlaun fyrir fyrsta áfanga voru bolir fyrir N sæti, aðgangur að öðru áfanga, þar sem gisting og máltíðir á meðan keppni stendur voru greidd. Annað stigið var ??? (Af einhverri ástæðu var ég ekki viðstaddur verðlaunaafhendinguna og gat því ekki fundið út hver verðlaunin voru.) Öllum í sigurliðinu var lofað fartölvum. | Verðlaunin í fyrsta áfanga voru meðal annars boli fyrir 100 efstu þátttakendurna og aðgangur að öðru áfanganum, sem innihélt ferðalag til Moskvu, gistingu og máltíðir á meðan keppninni stóð. Einnig, undir lok fyrsta áfangans, voru verðlaun tilkynnt fyrir þrjú efstu verkefnin í fyrsta áfanganum: hver þátttakandi vann RTX 2080 TI skjákort! Annað stigið var liðakeppni, með liðum sem samanstóðu af 2 til 5 manns og verðlaun: 1. sæti - 100.000 rúblur 2. sæti - 100.000 rúblur 3. sæti - 100.000 rúblur Verðlaun dómnefndar - 100.000 rúblur |
| Opinber Telegram hópur, ~190 meðlimir, samskipti á ensku, spurningum tók nokkra daga að svara | Opinber Telegram hópur, ~1500 meðlimir, virk umræða um verkefni milli þátttakenda og skipuleggjenda |
| Skipuleggjendur kynntu tvær grunnlausnir, einfalda og háþróaða. Sú einfalda krafðist minna en 16 GB af vinnsluminni, en sú háþróaða fór yfir 16 GB. Þó þátttakendurnir hefðu gripið aðeins lengra, tókst þeim ekki að standa sig marktækt betur en háþróaða lausnin. Það komu upp engir erfiðleikar við að koma þessum lausnum af stað. Það er vert að taka fram að ítarlega dæminu var athugasemd með vísbendingum um hvar hægt væri að byrja að bæta lausnina. | Grunnlausnir fyrir hvert vandamál voru kynntar, sem þátttakendur náðu auðveldlega að yfirstíga. Á fyrstu dögum keppninnar lentu þátttakendur í nokkrum erfiðleikum: Í fyrsta lagi voru gögnin afhent á Apache Parquet sniði og ekki virkuðu allar samsetningar af Python og Parquet pakkanum villulaust. Önnur áskorun var að hlaða niður myndum úr Mail skýinu; það er engin einföld leið til að hlaða niður miklu magni af gögnum í einu. Þessi vandamál tafðu að lokum þátttakendur í nokkra daga. |
IDAO. Fyrsta stig
Verkefnið var að flokka múónagnir/ekki-múónagnir eftir eiginleikum þeirra. Lykilatriði í þessu verkefni var tilvist „þyngdar“-dálks í þjálfunargögnunum, sem skipuleggjendurnir sjálfir túlkuðu sem öryggisstig fyrir svarið í þeirri röð. Vandamálið var að allnokkrar raðir innihéldu neikvæðar þyngdir.
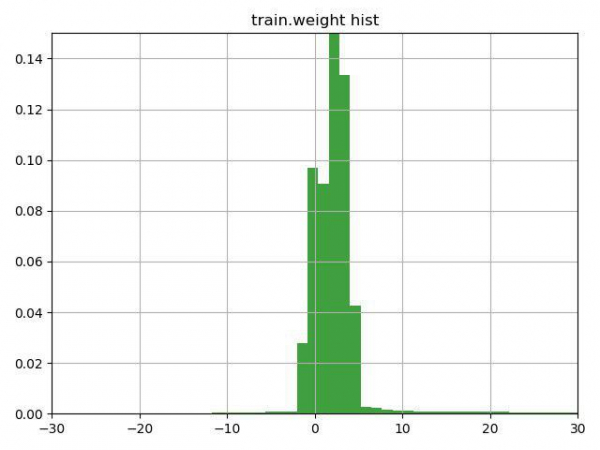
Eftir að hafa hugsað í nokkrar mínútur um línuna með vísbendingunni (vísbendingin vakti einfaldlega athygli á þessum eiginleika þyngdardálksins) og teiknað þetta graf, ákváðum við að prófa þrjá möguleika:
1) snúa markmiðinu við fyrir raðir með neikvæða þyngd (og þyngd í samræmi við það)
2) færið lóðin að lágmarksgildinu þannig að þau byrji frá 0
3) ekki nota þyngdir fyrir raðir
Þriðji kosturinn reyndist vera sá versti, en tveir fyrstu bættu niðurstöðuna; sá besti var kostur númer eitt, sem kom okkur strax í annað sætið fyrir fyrsta verkefnið og fyrsta sætið fyrir það annað.

Næsta skref okkar var að fara yfir gögnin í leit að gildum sem vantaði. Skipuleggjendurnir létu okkur í té forunnin gögn, sem sýndu tiltölulega fá gildi sem vantaði, og þeim var skipt út fyrir -9999.
Við fundum gildi sem vantaði í dálkana MatchedHit_{X,Y,Z}[N] og MatchedHit_D{X,Y,Z}[N] aðeins þegar N = 2 eða 3. Við skiljum að sumar agnir fóru ekki í gegnum alla 4 skynjarana og stöðvuðust annað hvort á plötu 3 eða 4. Gögnin innihéldu einnig Lextra_{X,Y}[N] dálka, sem lýsa greinilega því sama og MatchedHit_{X,Y,Z}[N], en með því að nota einhverja útvíkkun. Þessar fáu ágiskanir gerðu okkur kleift að gera ráð fyrir að hægt væri að setja Lextra_{X,Y}[N] í staðinn fyrir gildin sem vantaði í MatchedHit_{X,Y,Z}[N] (aðeins fyrir X og Y hnitin). MatchedHit_Z[N] var vel fyllt af miðgildinu. Þessar aðferðir gerðu okkur kleift að ná einum millistigi fyrir bæði verkefnin.

Þar sem engin verðlaun voru í boði fyrir að vinna fyrsta áfangann hefðum við getað hætt þar, en við héldum áfram, teiknuðum nokkrar fallegar myndir og fundum upp nýja eiginleika.
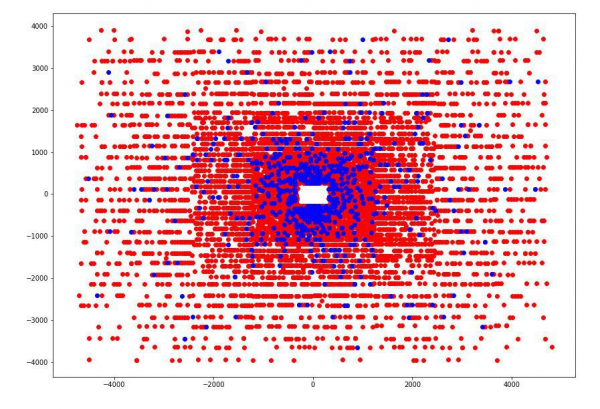
Til dæmis komumst við að því að ef við teiknum skurðpunkta agnar við hverja af fjórum skynjaraplötunum, sjáum við að punktarnir á hverri plötu eru flokkaðir í 5 rétthyrninga með 4:5 hlutfallslegan hlutföll og miðjuð í (0,0), og það eru engir punktar í fyrsta rétthyrningnum.
| Plata nr. / rétthyrningsmál | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Plata 1 | 500 × 625 | 1000 × 1250 | 2000 × 2500 | 4000 × 5000 | 8000 × 10000 |
| Plata 2 | 520 × 650 | 1040 × 1300 | 2080 × 2600 | 4160 × 5200 | 8320 × 10400 |
| Plata 3 | 560 × 700 | 1120 × 1400 | 2240 × 2800 | 4480 × 5600 | 8960 × 11200 |
| Plata 4 | 600 × 750 | 1200 × 1500 | 2400 × 3000 | 4800 × 6000 | 9600 × 12000 |
Eftir að hafa ákvarðað þessar víddir bættum við við fjórum nýjum flokkunareiginleikum fyrir hverja agn — númer rétthyrningsins þar sem hún sker hverja plötu.
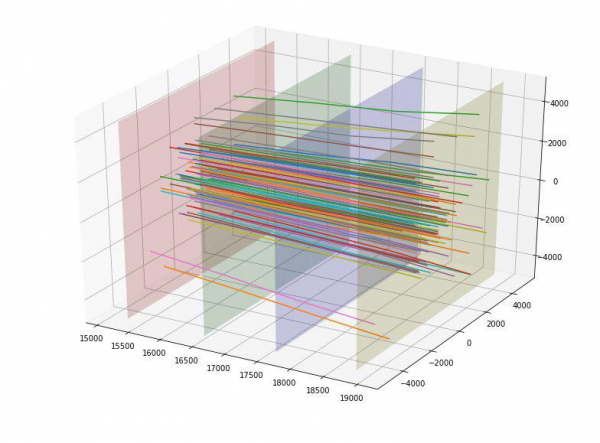
Við tókum líka eftir því að agnirnar virtust dreifast út á við frá miðjunni og hugmyndin kom upp að meta einhvern veginn „gæði“ þessarar dreifingar. Helst gætum við líklega búið til einhvers konar „fullkomna“ parabólu byggða á innkomupunktinum og metið frávikið frá honum, en við völdum „fullkomna“ beina línu. Með því að smíða slíkar fullkomnar línur fyrir hvern innkomupunkt gátum við reiknað staðalfrávik brautar hverrar agnar út frá þessari línu. Þar sem meðalfrávikið fyrir skotmark = 1 var 152 og fyrir skotmark = 0 var það 390, þá mátum við þennan eiginleika sem góðan með fyrirvara. Reyndar varð þessi eiginleiki strax einn sá gagnlegasti.
Við vorum himinlifandi og bættum við fráviki allra fjögurra skurðpunkta hvers agnar frá hugsjónarlínunni sem fjórum viðbótareiginleikum (og þeir virkuðu líka vel).
Tenglar á vísindagreinar um keppnisefnið sem skipuleggjendur gáfu bentu til þess að við værum ekki fyrst til að takast á við þetta vandamál og að sérhæfður hugbúnaður gæti verið til. Eftir að hafa uppgötvað GitHub gagnagrunn sem útfærir IsMuonSimple, IsMuon og IsMuonLoose aðferðirnar, fluttum við þær yfir með minniháttar breytingum. Aðferðirnar sjálfar voru mjög einfaldar: til dæmis, ef orkan er undir ákveðnu þröskuldi, þá er það ekki múon; annars er það múon. Slíkir einfaldir eiginleikar gátu greinilega ekki veitt neinn ávinning þegar stigulshækkun var notuð, svo við bættum við merktu „fjarlægð“ við þröskuldinn. Þessir eiginleikar voru einnig lítillega bættir. Kannski hefði ítarlegri greining á núverandi aðferðum gert okkur kleift að finna öflugri aðferðir og bæta þeim við eiginleikana.
Undir lok keppninnar fínstilltum við örlítið „fljótlegu“ lausnina fyrir annað dæmið, sem endaði á að vera frábrugðin grunnlínunni á eftirfarandi hátt:
- Í röðum með neikvæða þyngd var markmiðinu snúið við
- Fyllti út gildi sem vantar í MatchedHit_{X,Y,Z}[N]
- Minnkuð dýpt niður í 7
- Lækkaði námstíðnina niður í 0.1 (var 0.19)
Að lokum prófuðum við aðra eiginleika (ekki með miklum árangri), völdum breytur og þjálfuðum catboost, lightgbm og xgboost, prófuðum mismunandi spáblöndur og áður en einkalotan hófst vorum við örugglega að vinna annað verkefnið og meðal leiðtoganna í því fyrsta.
Eftir að einkaspjallið opnaði vorum við í 10. sæti fyrir vandamál 1 og í 3. sæti fyrir vandamál 2. Allir leiðtogarnir voru ruglaðir saman og stigin í einkaspjallinu voru hærri en á Liberboard. Það virðist sem gögnin hafi ekki verið vel lagskipt (eða til dæmis voru engar raðir með neikvæðri þyngd í einkaspjallinu) og það var svolítið vonbrigði.
SNA Hackathon 2019 — Textar. 1. áfangi
Verkefnið var að raða færslum notenda á samfélagsmiðlinum Odnoklassniki eftir texta þeirra. Auk textans voru einnig nokkrir aðrir eiginleikar færslunnar (tungumál, eigandi, dagsetning og tími stofnunar, dagsetning og tími skoðunar).
Sem hefðbundnar aðferðir við að vinna með texta myndi ég leggja áherslu á tvo möguleika:
- Að varpa hverju orði inn í n-vítt vigurrými þannig að svipuð orð hafi svipaða vigra (nánari upplýsingar er að finna í ), og annað hvort að finna meðaltal orðs í textanum eða nota aðferðir sem taka tillit til hlutfallslegrar stöðu orða (CNN, LSTM/GRU).
- Að nota líkön sem geta meðhöndlað heilar setningar strax, eins og Bert. Í orði kveðnu ætti þessi aðferð að virka betur.
Þar sem þetta var mín fyrsta reynsla af því að vinna með texta væri rangt að kenna einhverjum öðrum, svo ég mun kenna sjálfum mér. Hér eru nokkur ráð sem ég myndi gefa mér sjálfum í upphafi keppninnar:
- Áður en þú flýtir þér að þjálfa eitthvað, skoðaðu gögnin! Gögnin innihéldu nokkra dálka fyrir utan textann sjálfan, og ég hefði getað kreist miklu meira út úr þeim en ég gerði. Einfaldasta leiðin væri að nota meðalmarkmiðskóðun fyrir suma dálkana.
- Ekki læra af öllum gögnunum! Það voru mikil gögn (um það bil 17 milljónir raða) og það var algjörlega óþarfi að nota þau öll til að prófa tilgáturnar. Þjálfun og forvinnsla var mjög hæg og ég hefði greinilega getað prófað áhugaverðari tilgátur.
- <Umdeild ráð> Það er engin þörf á að leita að frábærum líkani. Ég eyddi löngum tíma í að fikta við Elmo og Bert í von um að þeir myndu strax koma mér ofarlega í röðun, en í staðinn notaði ég fyrirfram þjálfaðar innfellingarforrit FastText fyrir rússnesku. Ég náði ekki bestu einkunn með Elmo og ég komst aldrei í það með Bert.
- <Umdeild ráð> Engin þörf á að leita að einum frábærum eiginleika. Eftir að hafa skoðað gögnin tók ég eftir því að um 1 prósent textanna innihéldu í raun engan texta! En þeir innihéldu tengla á nokkrar heimildir, svo ég skrifaði einfaldan greiningarforrit sem opnaði síðuna og dró út titilinn og lýsinguna. Það virtist góð hugmynd, en svo lét ég mig hafa og ákvað að greina alla tenglana fyrir alla textana, og aftur sóaði ég miklum tíma. Þetta bætti ekki lokaniðurstöðuna verulega (þó ég hafi til dæmis fundið út hvernig á að nota stofnun texta).
- Klassískir eiginleikar virka. Við googlum til dæmis „kaggle text features“, lesum í gegnum þá og bætum öllu við. TF-IDF skilaði úrbótum, eins og tölfræðilegir eiginleikar eins og textalengd, orðafjöldi og greinarmerkjafjöldi.
- Ef það eru DateTime dálkar er þess virði að brjóta þá niður í nokkra aðskilda eiginleika (klukkustundir, daga vikunnar o.s.frv.). Hvaða eiginleika ætti að vera áberandi ætti að greina með gröfum eða öðrum mælikvörðum. Hér gerði ég allt rétt og benti á nauðsynlega eiginleika, en rétt greining hefði verið gagnleg (til dæmis eins og við gerðum í lokaútgáfunni).
Eftir keppnina þjálfaði ég eitt Keras líkan með orðaskiptum fellingum og annað byggt á LSTM og GRU. Báðar gerðirnar notuðu fyrirfram þjálfaðar FastText innfellingar fyrir rússnesku (ég prófaði nokkrar aðrar innfellingar en þær virkuðu best). Eftir að hafa reiknað meðaltal spánna lenti ég í 7. sæti af 76 þátttakendum.
Strax eftir fyrsta áfanga var það gefið út , sem lenti í öðru sæti (hann tók þátt utan keppninnar), og lausn hans endurtók mína upp að vissu marki, en hann komst lengra þökk sé fyrirspurnar-lykill-gildi athygliskerfinu.
Annað stig OK & IDAO
Seinni áfangar keppninnar fóru fram nánast í röð, svo ég ákvað að fara yfir þá saman.
Fyrst komum ég og nýfengið teymi mitt á glæsilega skrifstofu Mail.ru þar sem verkefnið okkar var að sameina líkön þriggja brauta úr fyrstu umferðinni — texta, myndir og samstarfið. Við fengum rétt rúma tvo daga til að klára þetta, sem reyndist vera mjög skammur tími. Í raun tókst okkur aðeins að endurtaka niðurstöður okkar úr fyrstu umferðinni, án þess að hafa nokkurn ávinning af því að sameina þær. Að lokum lentum við í fimmta sæti, en gátum ekki notað textalíkanið. Miðað við lausnir annarra þátttakenda virðist það þess virði að reyna að flokka textana og bæta þeim við samstarfslíkanið. Aukaverkun þessarar umferðar var nýjar upplifanir, að hitta og eiga samskipti við frábæra þátttakendur og skipuleggjendur, sem og alvarlegur svefnskortur, sem kann að hafa haft áhrif á niðurstöður okkar í lokaumferð IDAO.
Verkefnið á staðnum í úrslitakeppni IDAO 2019 var að spá fyrir um biðtíma leigubílstjóra Yandex á flugvellinum. Þremur verkefnum var úthlutað til þriggja flugvalla í öðru stiginu. Fyrir hvern flugvöll voru veittar mínútu-fyrir-mínútu gögn um fjölda leigubílapantana í sex mánuði. Næsta mánuður og mínútu-fyrir-mínútu gögn um pantanir síðustu tvær vikurnar voru notuð sem prófunargögn. Tíminn var naumur (1,5 dagar) og verkefnið var nokkuð sértækt; aðeins einn meðlimur liðsins mætti í keppnina - og þar af leiðandi var lokaniðurstaðan vonbrigði. Meðal áhugaverðra hugmynda voru tilraunir til að nota utanaðkomandi gögn: veður, umferð og tölfræði um leigubílapantanir Yandex. Þó að skipuleggjendur hafi ekki tilgreint hvaða flugvellir þetta væru, giskuðu margir þátttakendur á Sheremetyevo, Domodedovo og Vnukovo. Þó að þessi ályktun hafi verið afsönnuð eftir keppnina, bættu eiginleikar eins og veðurgögn frá Moskvu bæði staðfestingu og niðurstöður á stigatöflunni.
Ályktun
- Vélanámskeppnir eru flottar og spennandi! Þær bjóða upp á tækifæri til að beita færni í gagnagreiningu, háþróaðri líkönum og aðferðum, og jafnvel heilbrigðri skynsemi er hvatt til.
- Vélanám er þegar víðfeðmt þekkingarsvið og virðist vaxa gríðarlega. Ég setti mér það markmið að kynna mér ýmis svið (merki, myndir, töflur, texta) og gerði mér þegar grein fyrir því hversu margt er ólært. Til dæmis, eftir þessar keppnir, ákvað ég að læra um klasamyndunarreiknirit, háþróaðar aðferðir til að vinna með hallamyndunarbókasöfn (sérstaklega vinnu með CatBoost á skjákortum), hylkisnet og athygliskerfi fyrirspurnar-lykil-gildi.
- Kaggle er ekki það eina! Það eru margar aðrar keppnir þar sem auðveldara er að fá að minnsta kosti bol og það eru betri líkur á að vinna önnur verðlaun.
- Hafðu samband! Það er nú þegar stórt samfélag á sviði vélanáms og gagnagreiningar, með sérstökum hópum á Telegram og Slack, og reynslumiklu fólki frá Mail.ru, Yandex og öðrum fyrirtækjum sem svarar spurningum og aðstoðar þá sem eru að byrja og halda áfram á þessu sviði.
- Ég ráðlegg öllum sem fengu innblástur frá fyrri atriðinu að heimsækja — stór ókeypis ráðstefna í Moskvu, sem fer fram dagana 10.-11. maí.
Heimild: www.habr.com
