


Buongiorno, amici! Oggi continuerò il ciclo dedicato a un articolo sulla progettazione della rete enterprise.
In questo articolo cercherò di essere il più conciso possibile:
- descrivere l'approccio modulare alla progettazione della rete Enterprise
- esaminare i tipi di costruzione di uno dei moduli più importanti della rete aziendale — la rete backbone (ip-campus)
- descrivere i pro e i contro delle opzioni di ridondanza dei nodi critici della rete
- progettare/aggiornare una piccola rete Enterprise tramite un esempio astratto
- selezionare switch Extreme per implementare la rete progettata
- lavorare con i cavi in fibra e con l'indirizzamento IP
Questo articolo sarà di maggior interesse per ingegneri di rete e amministratori di reti aziendali che stanno appena iniziando il loro percorso da "networker", piuttosto che per ingegneri esperti che hanno lavorato per molti anni in operatori di telecomunicazioni o in grandi aziende con reti geograficamente distribuite.
In ogni caso, chi è interessato è pregato di continuare a leggere.
Approccio modulare alla progettazione della rete
Inizierò il mio articolo con un approccio modulare piuttosto popolare nella progettazione della rete, che consente di assemblare i pezzi della rete in un'immagine unica.
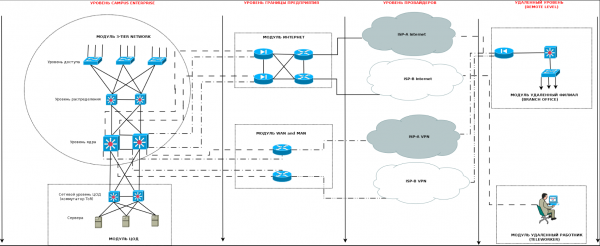
Per prima cosa, un po' di astrazione: spesso rappresento questo approccio come uno zoom su mappe geografiche, dove in una prima approssimazione si vede il paese, nella seconda i regioni, nella terza le città, e così via.
Prendiamo come esempio il seguente caso:
- Primo livello — l'intera rete aziendale è composta da vari livelli:
- rete backbone o campus
- livello di confine
- livello degli operatori di telecomunicazione
- zone remote
- Secondo livello — ciascuno di questi livelli si dettaglia in moduli separati.
- la rete backbone o campus è composta da:
- moduli a 3 o 2 livelli, che descrivono la rete aziendale e i suoi livelli — accesso, distribuzione e/o core
- un modulo che descrive il DC — centro dati (essenzialmente la parte server dell'infrastruttura)
- il livello di confine si compone a sua volta di:
- un modulo di connessione a Internet
- un modulo WAN e MAN, responsabile della connessione di oggetti aziendali distribuiti geograficamente
- un modulo per costruire tunnel VPN e accesso remoto
- molti piccoli imprenditori hanno spesso diversi moduli o addirittura tutti raggruppati in uno solo
- livello dei fornitori:
- in questo livello sono inclusi i collegamenti "al mondo esterno" — fibre ottiche scure (affitto delle fibre dai provider), canali di comunicazione (Ethernet, G.703, ecc.), accesso a Internet.
- livello remoto:
- questo riguarda principalmente le filiali dell'azienda distribuite all'interno della città, della regione, del paese o addirittura dei continenti.
- può anche includere un data center secondario che replica il lavoro principale
- e naturalmente i telelavoratori — posti di lavoro remoti che stanno guadagnando popolarità.
- la rete backbone o campus è composta da:
- Il terzo approccio — ogni modulo viene suddiviso in moduli o livelli più piccoli. Ad esempio, in una rete campus:
- una rete a 3 livelli è divisa in:
- livello di accesso
- livello di distribuzione
- livello core
- Un data center in casi più complessi può essere suddiviso in:
- una parte di rete a 2 o 3 livelli
- una parte server
Tutto quanto sopra cercherò di rappresentare nel seguente schema semplificato:

Come si può vedere nell'immagine sopra, l'approccio modulare aiuta a chiarire e strutturare il quadro generale in elementi costitutivi, con cui poi è possibile lavorare.In questo articolo parlerò del livello Campus Enterprise e lo descriverò in dettaglio.
Tipi di reti IP-CAMPUS
Durante la mia esperienza in un fornitore e soprattutto più tardi, nella mia attività di integratore, mi sono imbattuto in diverse 'maturità' delle reti dei clienti. Non uso il termine 'maturità' a caso, poiché molto spesso si riscontrano casi in cui la struttura della rete cresce con la crescita stessa dell'azienda ed è in questo senso prevedibile.
In una piccola azienda situata all'interno di un unico edificio, la rete aziendale può consistere in un solo router di confine che funge da firewall, alcuni switch di accesso e un paio di server.
Chiamo questa rete per me una rete 'monolivello' — non c'è un livello chiaro del nucleo della rete, il livello di distribuzione è spostato sul router di confine (con funzioni di firewall, VPN e forse proxy), e gli switch di accesso servono sia i computer dei dipendenti sia i server.

In caso di crescita dell’azienda — con l’aumento del numero di dipendenti, servizi e server, spesso è necessario:- aumentare il numero di switch nella rete e le porte di accesso
- incrementare le risorse dei server
- gestire i domini di broadcasting — implementare la segmentazione della rete e il routing tra i segmenti
- affrontare i guasti di rete, che causano inattività tra i dipendenti, comportando così ulteriori spese per la direzione (i dipendenti sono inattivi, lo stipendio è pagato, ma il lavoro non viene svolto)
- nella lotta contro i guasti, considerare il backup dei nodi critici della rete — router, switch, server e servizi
- inasprire le politiche di sicurezza, poiché possono sorgere rischi commerciali e, ancora una volta, per un funzionamento della rete più stabile
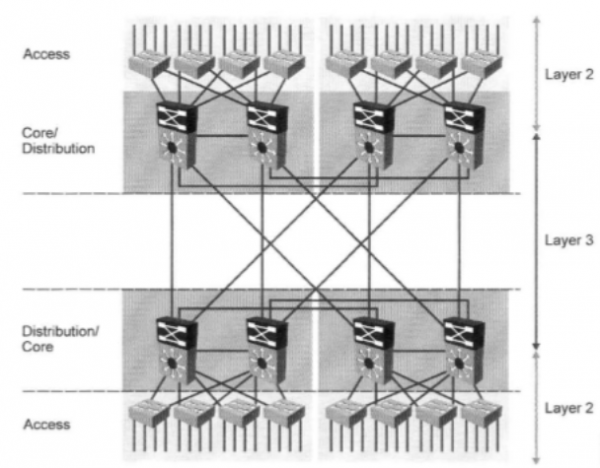
Tutto ciò porta al fatto che l'ingegnere (amministratore di rete) alla fine si interroga sulla corretta costruzione della rete e arriva già a un modello a 2 livelli.
Questo modello evidenzia chiaramente 2 livelli: il livello di accesso e il livello di distribuzione, che è anche il livello del nucleo (collapsed-core).
Il livello di distribuzione e nucleo combinato svolge le seguenti funzioni:
- aggregando i link dai switch di accesso
- introduce la segmentazione della rete — ci sono così tanti utenti e dispositivi che non possono tutti rientrare in una rete /24 e, se ci riescono, le tempeste di broadcast causano interruzioni continue (soprattutto se gli utenti aiutano creando loop)
- assicura la comunicazione tra i segmenti adiacenti degli switch (su link più veloci)
- assicura la comunicazione tra gli utenti e i loro dispositivi e il calcolo dei server, che a questo punto comincia anche a identificarsi come un segmento separato della rete — il data center.
- inizia a garantire, insieme agli switch di accesso, in una certa misura, una politica di sicurezza che inizia a emergere nell'azienda a questo punto. L'azienda cresce, i rischi commerciali aumentano (qui intendo non solo le disposizioni sulla riservatezza commerciale, la definizione delle politiche di accesso, ecc., ma anche i semplici tempi di inattività della rete e del personale).
Pertanto, la rete cresce inevitabilmente verso un modello a 2 livelli:

In questo modello emergono requisiti speciali sia per gli switch di accesso, che aggregano i collegamenti dagli utenti e dai dispositivi di rete (stampanti, punti di accesso, dispositivi VoIP, telefoni IP, telecamere IP, ecc.), sia per gli switch di distribuzione e core.Gli switch di accesso devono già essere più intelligenti e funzionali per soddisfare le esigenze di prestazioni, sicurezza e flessibilità della rete, e devono:
- avere diversi tipi di porte di accesso e porte trunk — preferibilmente con capacità di espansione sia per l'aumento del traffico che per il numero di porte
- avere una capacità di commutazione sufficiente e una larghezza di banda adeguata
- disporre delle funzionalità di sicurezza necessarie che soddisfino le attuali politiche di sicurezza (e idealmente anche la crescita delle loro future esigenze)
- avere la possibilità di alimentare dispositivi di rete difficilmente accessibili con opzioni di riavvio remoto (PoE, PoE+)
- essere in grado di riservare la propria alimentazione elettrica per utilizzarla nei luoghi in cui è necessaria
- avere (se possibile) ulteriori potenzialità di crescita delle funzionalità — un esempio comune è il passaggio di uno switch di accesso a uno switch di distribuzione nel tempo
Gli switch di distribuzione devono anche rispettare requisiti specifici:
- sia per quanto riguarda le porte trunk discendenti verso gli switch di accesso, sia verso le interfacce peer degli switch di distribuzione vicini (e in futuro anche per le possibili interfacce uplink verso il core)
- in termini di funzionalità L2 e L3
- in termini di funzionalità di sicurezza
- in termini di garanzia di resilienza (ridondanza, clustering e riserva di alimentazione elettrica)
- in termini di flessibilità nella gestione del traffico
- avere (se possibile) un ulteriore potenziale di crescita delle funzionalità (trasformazione nel tempo del dispositivo di aggregazione in nucleo)
- in alcuni casi, potrebbe essere opportuno utilizzare porte PoE e PoE+ sugli switch di distribuzione.
Dopo — c'è di più: se la direzione attua una politica attiva di crescita e sviluppo dell'azienda, la rete continuerà a svilupparsi — l'azienda potrebbe iniziare ad affittare edifici vicini, costruire proprie strutture o acquisire concorrenti più piccoli, aumentando così il numero di posti di lavoro per i dipendenti. Allo stesso tempo, cresce anche la rete, il che richiede:
- fornire ai dipendenti posti di lavoro — sono necessari nuovi switch di accesso con porte di accesso
- la presenza di nuovi switch di distribuzione per aggregare i link dagli switch di accesso
- la costruzione di nuove linee di comunicazione e la modernizzazione di quelle esistenti
Di conseguenza, aumenta il traffico per le seguenti ragioni:
- a causa dell'aumento delle porte di accesso e quindi degli utenti della rete
- a causa dell'aumento del traffico delle sottosistemi adiacenti, che scelgono come rete di trasporto quella aziendale — telefonia, sicurezza, sistemi ingegneristici, ecc.
- a causa dell'implementazione di servizi aggiuntivi — con l'aumento del personale emergono nuovi reparti che richiedono software specifico.
- aumentano le capacità di calcolo del Data Center per soddisfare le esigenze di infrastruttura e applicazioni.
- crescono i requisiti di sicurezza per la rete e le informazioni — la famosa triade CIA (un gioco di parole), ma seriamente, CIA — Confidentiality, Integrity and Availability:
- conseguentemente, ai livelli critici della rete — distribuzione e Data Center, si aggiungono requisiti supplementari per la resilienza e la ridondanza.
- ancora una volta si verifica un aumento del traffico a causa dell'implementazione di nuovi sistemi di sicurezza — come i RKVIs, ecc.
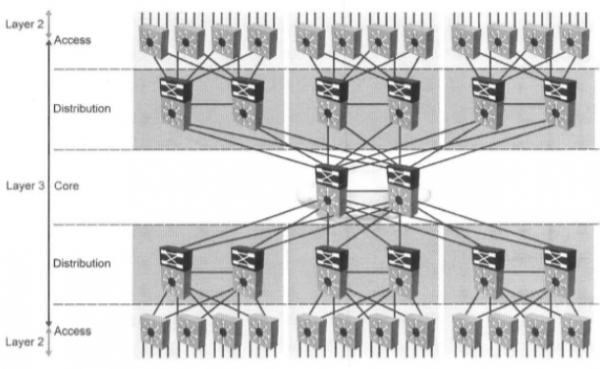
prima o poi, l'aumento di traffico, servizi e numero di utenti porterà alla necessità di implementare un ulteriore livello di rete — un nucleo che eseguirà un'alta velocità di commutazione/routing dei pacchetti utilizzando collegamenti di comunicazione ad alta velocità.
In questo momento, l'azienda può passare a un modello di rete a 3 livelli:

Come si può vedere nell'immagine sopra, in una tale rete è presente un livello di core, che aggrega i link ad alta velocità dai commutatori di distribuzione. Pertanto, anche i commutatori core devono soddisfare requisiti relativi a:- larghezza di banda delle interfacce — 1GE, 2.5GE, 10GE, 40GE, 100GE
- prestazioni del commutatore (capacità di switching e prestazioni di forwarding)
- tipologia delle interfacce — 1000BASE-T, SFP, SFP+, QSFP, QSFP+
- numero e tipo di interfacce
- capacità di ridondanza (stacking, clustering, ridondanza delle schede di controllo, applicabile ai commutatori modulari, ridondanza dell'alimentazione, ecc.)
- funzionalità
A questo livello della rete è sicuramente necessaria una modifica tecnica:
- ridondanza dei nodi e delle connessioni core (molto, molto, molto desiderabile)
- ridondanza dei nodi e dei link delle connessioni di livello di distribuzione (a seconda della criticità)
- ridondanza dei link tra i commutatori di accesso e il livello di distribuzione (se necessario)
- introduzione di protocolli di instradamento dinamico
- bilanciamento del traffico sia a livello di kernel che a livello di distribuzione e accesso (se necessario)
- implementazione di servizi aggiuntivi — sia di trasporto che di sicurezza (se necessario)
e la legislazione, che definisce la politica di sicurezza della rete dell'azienda, che integra la politica di sicurezza generale in termini di:
- richieste per l'implementazione e la configurazione di varie funzionalità di sicurezza sugli switch di accesso e di distribuzione
- requisiti di accesso, monitoraggio e gestione dell'hardware di rete (protocollo di accesso remoto, segmenti di rete autorizzati per la gestione, configurazioni di logging, ecc.)
- requisiti di ridondanza
- requisiti per la formazione di un kit ZIP minimamente necessario
In questa sezione ho descritto brevemente l'evoluzione della rete e dell'azienda da alcuni switch e una manciata di dipendenti a diverse decine (e forse centinaia) di switch e diverse centinaia (o addirittura migliaia) di soli dipendenti che lavorano direttamente nella rete dell'azienda (senza contare i dipartimenti produttivi e le reti ingegneristiche).
È chiaro che nella realtà uno sviluppo "miracoloso" e rapido dell'impresa non si verifica.
In genere ci vogliono anni affinché l'impresa e la rete crescano dal loro livello iniziale 1 al livello 3 che descrivo.Perché scrivo tutte queste verità ovvie? Perché voglio menzionare un termine come ROI — ritorno sugli investimenti e considerare l'aspetto che riguarda direttamente la scelta delle apparecchiature di rete.
Quando si sceglie l'attrezzatura, gli ingegneri di rete e i loro manager spesso selezionano l'attrezzatura in base a due fattori: il prezzo attuale dell'attrezzatura e le funzionalità tecniche minime necessarie al momento per risolvere un compito specifico, o compiti (parlerò più avanti dell'acquisto di attrezzature per la riserva).
Tuttavia, le possibilità di ulteriore "crescita" dell'hardware sono raramente considerate. Quando si presenta la situazione in cui l'hardware esaurisce le sue funzionalità o prestazioni, si acquista quindi un dispositivo più potente e funzionale, mentre il vecchio viene messo in magazzino o in qualche rete per il principio del "tenere in deposito" (questo, tra l'altro, contribuisce anche alla creazione di un grande zoo di hardware e all'acquisto di una miriade di sistemi informativi che lavorano con esso).
Così, anziché acquistare licenze per le funzionalità aggiuntive e le prestazioni, che costano molto meno rispetto all'acquisto di una nuova attrezzatura più performante, ci si trova costretti a comprare un nuovo hardware e a pagare di più per le seguenti ragioni:
- la rete cresce spesso lentamente e l'espansione delle funzionalità, o le prestazioni dello switch della tua rete, possono durare ancora a lungo.
- Non è un segreto che l'attrezzatura dei fornitori stranieri sia legata a valute estere (dollaro o euro). A essere sinceri, l'aumento del dollaro o dell'euro (o la periodica mini-devalutazione del rublo, a seconda dei punti di vista) porta al fatto che il dollaro di dieci anni fa e il dollaro attuale sono due cose molto diverse in termini di rublo.
Riassumendo quanto detto sopra, vorrei notare che l'acquisto di attrezzature di rete con funzionalità più ampie ora potrebbe portare a risparmi in futuro.
Qui considero i costi per l'acquisto di equipaggiamento nel contesto dell'investimento nella mia rete e infrastruttura.Pertanto, molti fornitori (non solo Extreme) seguono il principio pay-as-you-grow, integrando nell'attrezzatura una vasta gamma di funzionalità e possibilità di aumentare le prestazioni delle interfacce, che vengono attivate successivamente con l'acquisto di licenze separate. Offrono anche switch modulari con una vasta gamma di schede per interfacce e processori, e la possibilità di aumentare progressivamente sia il numero che le prestazioni.
Riserva di nodi critici
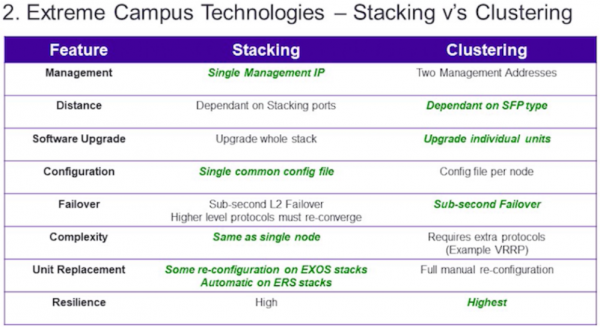
In questa parte dell'articolo desidero descrivere brevemente i principi fondamentali della ridondanza di nodi di rete così importanti come gli switch core, i data center o quelli di distribuzione. E voglio iniziare esaminando le modalità generali di ridondanza: lo stacking e il clustering.
Ognuno di questi metodi ha i suoi vantaggi e svantaggi, di cui vorrei discutere.
Di seguito è riportata una tabella riassuntiva comparativa dei due metodi:

- gestione — come si può vedere dalla tabella, qui lo stacking ha un vantaggio, poiché dal punto di vista della gestione, uno stack di diversi switch appare come un singolo switch con un gran numero di porte. Invece di gestire ad esempio 8 diversi switch nel caso del clustering, è possibile gestirne solo uno nello stacking.
- distanza Attualmente, a dire il vero, il vantaggio della clustering non è così evidente, poiché sono emerse tecnologie di stacking degli switch attraverso porte di stacking o porte dual-purpose (ad esempio, SummitStack-V di Extreme, VSS di Cisco, ecc.), che dipendono anche dai tipi di transceiver. Qui il vantaggio è dato dalla clustering in base al fatto che nello stacking ci sono opzioni in cui si devono utilizzare porte di stacking standard, che spesso sono collegate tramite cavi speciali di lunghezza limitata — 0,5, 1, 1,5, 3 o 5 metri.
- aggiornamento del software — qui vediamo che la clustering ha un vantaggio rispetto allo stacking, ed è il seguente: durante l'aggiornamento della versione del software dell'hardware nello stacking, aggiorni il software sullo switch principale, il quale poi si occupa di distribuire il nuovo software sugli switch standby del stack. Da un lato, questo semplifica il tuo lavoro, ma l'aggiornamento del software richiede spesso un riavvio hardware, che porta al riavvio dell'intero stack e quindi a un'interruzione del suo funzionamento e di tutti i servizi connessi durante il tempo = il tempo di riavvio. Di solito, questo è molto critico per il core e il data center. Con la clustering, hai due dispositivi indipendenti tra loro, sui quali puoi aggiornare il software uno dopo l'altro. In questo modo, si possono evitare interruzioni nei servizi.
- configurazione delle impostazioni — qui il vantaggio è sicuramente dello stacking, poiché anche nella gestione devi modificare le impostazioni solo per un dispositivo e il suo file di configurazione. Con la clustering, invece, il numero di file di configurazione sarà pari al numero di nodi del cluster.
- tolleranza ai guasti — qui le due tecnologie sono abbastanza equivalenti, ma c'è comunque un piccolo vantaggio per la clusterizzazione. La ragione risiede nel fatto che, considerando lo stack dal punto di vista dei processi e dei protocolli in esecuzione, vediamo quanto segue:
- c'è uno switch master, su cui sono in esecuzione tutti i principali processi e protocolli (ad esempio, il protocollo di routing dinamico — OSPF)
- ci sono altri switch slave, su cui sono in esecuzione i processi principali necessari per il funzionamento nello stack e per la gestione del traffico che vi passa attraverso
- se il master switch fallisce, il successivo slave switch ha il compito di rilevare il guasto del master
- esso si auto-initia come master e avvia tutti i processi che erano in esecuzione sul master (incluso il protocollo OSPF che stiamo osservando)
- dopo un breve periodo di avvio dei processi (solitamente piuttosto breve), inizia a funzionare il protocollo OSPF stesso
- In questo modo, OSPF si comporta un po' più rapidamente in caso di guasto di uno dei nodi durante la clustering rispetto allo stacking (per il tempo necessario per avviare e inizializzare i processi e i protocolli sullo switch slave dello stack). Tuttavia, devo notare che i protocolli di stacking e gli switch moderni operano molto rapidamente; spesso la durata dell'interruzione del traffico durante il passaggio da uno stack all'altro è inferiore a un secondo, anche se nominalmente la clustering vince su questo parametro.
- complessità — come si può vedere dalla tabella, lo stacking vince in termini di complessità. Questo è il risultato diretto dei punti "gestione" e "configurazione delle impostazioni". Un nodo singolo richiede molto meno tempo per la configurazione e la gestione. Inoltre, nella clustering è spesso necessario configurare protocolli di routing aggiuntivi o protocolli di failover - VRRP, HSRP e altri.
- sostituzione dei nodi — qui lo stacking ha un vantaggio chiaro. Spesso, per sostituire uno switch in uno stack, sono necessarie solo le impostazioni minime dell'hardware, ad esempio:
- aggiornare il software del nuovo switch alla versione del sistema (e questo può essere fatto immediatamente al ricevimento degli switch nel magazzino)
- configurare alcuni comandi di base per il concatenamento (e per alcuni tipi di switch, questo potrebbe anche non essere necessario)
- sostituire lo switch guasto del sistema e collegare il nuovo
- collegare l'alimentazione e i patch cord
- elasticità — considero l'elasticità come uno dei parametri principali. In generale, l'elasticità è una caratteristica complessa che indica la capacità di un oggetto di modificarsi sotto carico e di tornare alla forma originale una volta scomparsa la forza. Stranamente, per la clusterizzazione, questa sarà superiore anche con un punteggio di 4:3 a favore della concatenazione. Il tutto è riconducibile al fattore umano. Sì, non sorprendetevi — nella forza di parametri di concatenazione come la gestione unificata, la configurazione delle impostazioni e la complessità semplificata risiede la debolezza del concatenamento, quando entra in gioco il fattore umano.
Nel mio lavoro nel settore IT, ho incontrato molte volte situazioni (e, a dire il vero, ci sono inciampato anch'io, specialmente all'inizio) in cui, durante la configurazione dello stack, un ingegnere si sbagliava nell'inserire un comando o nell'attivare/disattivare una funzione su un dispositivo, portando al fallimento dell'intero stack e alla necessità di un riavvio manuale. Vale la pena menzionare gli appassionati dell'applicazione Putty per Windows (ah, quel copia e incolla con il tasto destro).
In realtà, entrambe le tecnologie sono piuttosto buone (specialmente rispetto all'assenza di backup) e ognuna ha i suoi punti di forza e debolezza, ma per il livello di core e per un data center ad alta capacità, preferirei comunque utilizzare la clusterizzazione.
Tuttavia, questa è solo la mia opinione. Molti ingegneri professionisti che da anni si occupano di supporto di rete a livello professionale possono usare entrambe le tecnologie con la stessa facilità — dipende dall'esperienza e dalle qualifiche.
Oltre alle tecnologie di stacking e backup dei nodi di rete, esistono anche principi generali per il backup di parti del nodo di rete stesso e delle connessioni tra i nodi:
Con riserva all'interno della rete intendo:
- la ridondanza delle alimentazioni — l'installazione di 2 alimentatori che si duplicano a vicenda (e sarebbe preferibile siano collegati alla prima categoria di alimentazione) può semplificarvi notevolmente la vita.
- la ridondanza delle schede di controllo — si riferisce maggiormente agli switch modulari, che prevedono il collegamento di più schede di controllo ridondanti.
- la ridondanza delle schede interfaccia — si applica principalmente anche agli switch modulari.
Con la ridondanza dei collegamenti si intende principalmente la presenza di percorsi cablati duplicati (o collegamenti radio in spazi aperti) con:
- distribuzione su diversi tray di cablaggio e canali all'interno dell'edificio
- distribuzione geografica sul territorio a livello di 2 o più edifici, città, regione o nazione (cosiddetti anelli volumetrici)
Inoltre, nella costruzione di collegamenti di riserva, è necessario seguire alcune raccomandazioni per l'equipaggiamento:
- In caso di duplicazione delle schede interfaccia dello switch modulare, o in presenza di uno stack, è necessario distribuire i collegamenti tra le unità — schede interfaccia nel caso degli switch modulari e switch nel caso di stack.
- È consigliabile utilizzare protocolli di aggregazione dei collegamenti (LACP, MLT, PAgP, ecc.) per combinare i collegamenti in gruppi e bilanciare il carico tra di essi.
- Utilizzare router che supportano protocolli ECMP (Equal-Cost-Multi-Path) — quando diversi pacchetti vengono inviati su un percorso, questi non passano attraverso un solo best path (e interfaccia), ma vengono distribuiti tra diversi best-path (e più interfacce), determinati dall'uguaglianza delle metriche del protocollo di instradamento, che a sua volta si occupa di riempire la tabella di routing finale.
Ora, come promesso, descriverò un caso reale della mia pratica e il principio di risparmio nel riservare nodi critici, che è accaduto alcuni anni fa:
- in un'azienda, la chiamerò X, c'era un modello di rete standard a 3 livelli:
- con alcuni core
- alcune decine di aggregazioni
- migliaia di switch di accesso
- decine di migliaia di utenti
- la rete era piuttosto complessa da costruire:
- con un sacco di protocolli di routing dinamici e protocolli — OSPF, MP-BGP, MPLS, PIM, IGMP, IPv6, ecc.
- un insieme di servizi — accesso a Internet, VPN L2 e L3, VoIP, IPTV, linee dedicate, ecc.
- ma c'era un collo di bottiglia nella rete — il router di confine, che combinava le funzioni di BGP-border e terminava alcuni servizi per gli utenti
- sì, costava quanto un'ala di un aereo (alcuni milioni di rubli)
- sì, a quel tempo era uno dei dispositivi di punta della gamma del fornitore di rete più rinomato
- sì, doveva essere molto affidabile — con un eccellente indicatore MTBF
- sì, aveva 4 alimentatori configurati in modo 2x2 e alimentati da diverse fonti di alimentazione e ingressi.
Ma tutto ciò non eliminava il fatto che fosse un unico punto di guasto nella rete.
E in un giorno che non era affatto ideale per me e i miei colleghi, questo router ha smesso di funzionare (in seguito abbiamo scoperto che c'era stata una qualche anomalia nella linea di alimentazione attraverso l'UPS, che ha causato il guasto simultaneo di due alimentatori, bruciando anche il modulo RP del router e la scheda di interfaccia, che erano collegate al bus dati dell'apparecchio).
Non avevamo schede di ricambio – RP e la scheda di interfaccia, ma avevamo un contratto per la sostituzione dell'attrezzatura o dei suoi componenti con uno dei partner secondo lo schema NBD.
Purtroppo, al momento i partner avevano solo la scheda di interfaccia in magazzino, ma non c'era la scheda RP, che è arrivata solo dopo alcuni giorni (dopo 3 giorni).
Di conseguenza, la presenza di un'unica punto di fallimento nella rete (anche con un contratto di supporto e sostituzione dell'attrezzatura) ha comportato i seguenti costi finanziari:
- la quota dei servizi dell'azienda associati a questo border ammontava a circa il 60-70%
- come è stato successivamente calcolato, il profitto giornaliero era di circa 900.000 rubli (circa) a quel tempo.
- così in 3 giorni di inattività si sono teoricamente persi guadagni per un importo compreso tra 1 milione e 620 mila rubli e 1 milione e 890 mila rubli
Naturalmente le perdite nette sono state inferiori, poiché i rimborsi per la maggior parte degli utenti sono stati restituiti non in denaro, ma sotto forma di servizi, ma erano comunque presenti:
- parte dei rimborsi agli utenti aziendali
- costi aggiuntivi per il personale dell'azienda che ha lavorato a pieno ritmo per tutti questi 3-4 giorni — straordinari, turni notturni, aumento dei turni, ecc.
- perdite reputazionali, che non sono di poco conto
- e cosa più importante — nervi, sia della dirigenza che del personale, e dei clienti
Di conseguenza, la politica dell'azienda è stata riveduta:
- hanno rinunciato al contratto di sostituzione secondo la condizione NBD
- hanno mantenuto il contratto di servizio ordinario
- hanno acquistato un router duplicato del valore di circa 1 — 1,3 milioni di rubli per riservare il 90% delle funzionalità principali
In futuro, l'acquisto di attrezzature aggiuntive e la riserva delle apparecchiature principali hanno permesso di bilanciare il carico sui link esterni, sul traffico e sugli utenti, e hanno fornito in futuri incidenti una riserva di sicurezza per l'azienda.
Esempio di progettazione della rete Enterprise
In questa parte dell'articolo cercherò di spiegare i punti principali nel calcolo della rete di base dell'azienda. Non vi sommergerò con l'intera metodologia PPDIOO (Prepare-Planning-Design-Implement-Operate-Optimize), ma indicherò solo i suoi aspetti principali:
- Prepare/Preparazione — è necessario concordare con la propria direzione sugli obiettivi di modernizzazione della rete che si desidera raggiungere — aumentare la resilienza, implementare nuovi servizi o tecnologie. Salto le considerazioni sui vincoli — tecnici e organizzativi, poiché presumo che siate dipendenti dell'azienda e abbiate un largo margine di tempo per superarli. Tornerò al tema del budget più avanti.
- Planning/Pianificazione — qui dovrete costruire un'analisi completa della vostra rete attuale (se non la conoscete già), cioè descrivere la rete così com'è ora:
- quantità e tipo di attrezzature
- quantità e tipi di porte
- tracce di cavi esistenti e schemi di commutazione all'interno degli edifici e tra di essi
- schemi di alimentazione elettrica
- indirizzamenti L2 e L3
- creare mappe delle reti Wi-Fi indicando i punti di accesso e i controllori
- descrivere il proprio data center
- è consigliabile descrivere tutti i propri servizi e le connessioni tra di essi
- se hai già implementato in qualche modo una politica di sicurezza della rete e di controllo degli accessi, assicurati di tenerla presente durante la progettazione
- Nota subito che il secondo passo consiste essenzialmente in un'inventario completo della rete, partendo dall'infrastruttura dei cavi e dagli schemi di alimentazione, fino ai servizi (applicazioni e le loro porte). Questo passo è molto laborioso e a volte noioso. Se tu o il tuo predecessore non avete tenuto documentazione o anche un semplice sistema di monitoraggio, è il momento di pensarci. La rete tende a cambiare nel tempo a una certa velocità e solo la tenuta di documentazione aggiornata o di un sistema di monitoraggio può aiutarti a tenerne traccia e semplificare la gestione. Ma questo riguarda già il passo operate.
- Design/Progettazione — armato delle conoscenze complete sulla tua rete, ottenute nel passo precedente, finalmente ti siedi e pensi a come modernizzare la tua rete. Qui cercherò di dimostrare un piccolo esempio di calcolo della rete.
Ho creato una piccola lista di dati di base che utilizzerò per il calcolo e la progettazione della rete di supporto.
Immaginiamo il passo Prepare come un elenco di ciò che abbiamo a disposizione e di ciò che intendiamo fare:
- c'è una grande azienda con un numero approssimativo di postazioni di lavoro, intorno a 700-800 unità (qui mi riferisco ai dipendenti che necessitano di accesso alla rete aziendale)
- ci sono diversi edifici separati all'interno del territorio dell'azienda:
- Edifici principali:
- numero di edifici — 2 unità
- numero di piani nell'edificio — 7 unità
- numero di armadi per telecomunicazioni per piano in un edificio — 3 (totale 21) unità
- numero di dipendenti nell'edificio =~ 250 persone
- Edifici aggiuntivi:
- numero di edifici — 10 unità
- numero di piani nell'edificio/capannone — 2 unità
- numero di armadi per telecomunicazioni nell'edificio — 3 unità
- numero di dipendenti nell'edificio =~ 20 persone
- Il livello attuale del nucleo della rete (tra l'altro, uno schema molto comune che ho incontrato più volte in varie forme e composizioni di porte) è presentato:
- da 2 switch L2:
- porte 1Gb di tipo RJ-45 — 24 unità
- porte 1Gb SFP — 4 unità
- 1° switch L2:
- 24 porte SFP 1Gb
- topologia del nucleo — anello
- link peer-to-peer tra gli switch attivati tramite fibra ottica
- gli switch sono situati in piccole sale server con armadi
- da 2 switch L2:
- Livello di distribuzione attuale:
- combinato con il livello del nucleo della rete per aggregazione dei link dagli switch di accesso
- L'indirizzamento L3 è gestito dal router di frontiera e/o dal firewall
- Livello di accesso attuale:
- switch L2 con 16 porte di accesso 100 Mb RJ-45 e 2 uplink combo da un gigabit RJ-45/SFP
- gli switch sono installati negli armadi ai piani
- topologia degli switch di accesso:
- stella (hub-and-spoke) con lo switch di nucleo/distribuzione al centro
- il ramo/spoke è composto da una catena di 3 switch per piano
- sono presenti switch di accesso non gestiti
- gli switch in 9 chassis aggiuntivi sono connessi tramite media converter (convertitori da segnale ottico a elettrico)
- Infrastruttura cablata attuale:
- Sistema cablato tra gli edifici:
- disponibile cavo ottico tra i 2 edifici principali con capacità di 8 fibre
- c'è un cavo ottico tra uno dei corpi aggiuntivi (dove è installato lo switch di core) e ciascuno degli edifici principali, con una capacità di 8 fibre ciascuno
- c'è un cavo ottico tra i corpi aggiuntivi e i corpi con switch di core installati, con una capacità di 4 fibre (la loro distribuzione è mostrata nell'immagine sottostante)
- il tipo di fibre in tutti i cavi è monomodale/SMF
- si utilizzano transceiver SFP monomodali a 2 fibre
- alcuni cavi sono terminati su crocette ottiche (ODF) in stanze separate (sale di raccordo/server), mentre alcuni cavi sono nelle armadi di piano
- Sistema di cablaggio all'interno degli edifici:
- c'è una struttura di cablaggio misto tra le sale server e i primi armadi sui piani:
- cavi in rame Cat5e — 10 pz (oppure 100 cavi a coppie)
- cavo ottico multimodale/MMF da 4 o 8 fibre — 1 pz
- cavo ottico multimodale/MMF da 4 fibre tra gli armadi di piano
- cavi in rame Cat5e tra gli armadi di piano e le prese di accesso
- centro dati attuale:
- ci sono diversi server, ad esempio 6 unità
- inclusi porte 1Gb nello switch di core nel 1° edificio principale
- tutte le applicazioni aziendali sono trasferite sui server
- indirizzamento L2, L3 e instradamento:
- nella rete ci sono diverse VLAN — 2 o 3 per edificio
- i server sono assegnati a una rete separata /24
- per le esigenze interne vengono utilizzate reti grigie di classe B, comprese nell'intervallo — 172.16.0.0/16
- gli indirizzi L3 vengono terminati sul router di confine e/o sul firewall
- viene utilizzato l'instradamento statico
- informazioni aggiuntive:
- telefonia:
- negli edifici e in alcuni corpi è stata implementata la telefonia tradizionale utilizzando centraline digitali di vecchio tipo (non centralini IP)
- è necessario telefonizzare i nuovi edifici, senza costi per l'installazione di costose linee di cablaggio in rame di capacità specifica e per la costruzione di una rete cablata duplicata per la telefonia all'interno degli edifici
- nel tempo si prevede di implementare la telefonia IP in tutto il territorio dell'azienda, integrandola con i sistemi CRM e migrando tutti i dipendenti su di essa
- capacità delle porte:
- è necessario analizzare l'attuale capacità delle porte principali e delle porte di accesso, e riservare almeno il 25-30% per le esigenze future
- analizzare l'adeguatezza della capacità attuale delle porte di accesso e dei link Backbone
- prevedere la disponibilità di porte di accesso PoE/PoE+ per dispositivi di sistemi affini — videosorveglianza e telefonia
- videosorveglianza:
- si prevede di utilizzare la rete aziendale come trasporto per la rete di videosorveglianza
- è necessario prevedere la disponibilità di porte PoE per le telecamere di videosorveglianza
- sistemi wireless:
- si prevede di implementare in futuro un'infrastruttura wireless per la mobilità dei dipendenti
- è necessario prevedere la disponibilità di porte PoE per i punti di accesso
- budget, tempistiche e requisiti per le attrezzature:
- utilizzare al massimo l'attrezzatura esistente
- nella progettazione della rete considerare la possibilità di espandere la capacità della rete per i prossimi N anni
- nella progettazione della rete considerare il supporto per tutte le funzionalità di sicurezza — qui l'elenco delle funzionalità, che va dalla port-security all'autenticazione e autorizzazione degli utenti tramite 802.1x.
- è possibile riservare al massimo i nodi critici di rete di primaria importanza — il nucleo e il Data Center, e prevedere la possibilità di riservare nodi di secondaria importanza — nodi di distribuzione
- il budget del progetto deve prevedere un finanziamento graduale su più fasi
- l'importo del budget — qui ogni azienda stabilisce per sé stessa, basandosi sui propri indicatori finanziari
- le tempistiche — nel caso ideale non ci saranno scadenze definite, poiché si tratta di un progetto interno dell'azienda, realizzato con il contributo dei propri dipendenti, oppure saranno relativamente confortevoli — ad esempio, 1 anno (o più). Nel caso peggiore — potrebbero variare da 3 mesi a sei mesi.
- risolvere i problemi attuali nella rete:
- perdite di pacchetti
- problemi con DHCP su switch di accesso più o meno intelligenti, legati all'uso della famiglia di protocollo STP per combattere i loop sulle porte di accesso.
- eliminare la presenza dell'interfaccia del server DHCP in ciascun VLAN dei dipendenti
- emergenza di loop di commutazione, legata all'accensione non autorizzata di switch gestiti/non gestiti negli armadi e alla connessione ad essi di vari dispositivi
- l'elenco può continuare all'infinito…
Passaggio Planning — la caratteristica dello stato attuale della tua rete, come ho già scritto, dipende dalla presenza di un buon sistema di monitoraggio e dal livello di documentazione. In questo passaggio dovrai:
- almeno disegnare la rete esistente per ulteriori analisi
- raccogliere dati dall'attrezzatura:
- traffico sulle porte principali
- errori sulle porte
- carico della CPU e consumo di memoria negli switch e nei router
- elaborare schemi L2-L3 per VLAN e indirizzi IP
- alzare schemi delle vie di cablaggio:
- schemi in fibra ottica e schemi di terminazione dei crossover ottici
- schemi di distribuzione dei cavi in rame tra server e piani
- schemi di distribuzione dei cavi in rame tra piani e armadi
- verificare la presenza di crossover ottici e patch panel nei server e negli armadi
- verificare gli schemi di alimentazione negli armadi server e ai piani
- controllare la presenza di UPS e batterie sui nodi critici
- analizzare tutti i dati
Seguendo i dati della fase di preparazione, ho ottenuto un'approximate schema logico:

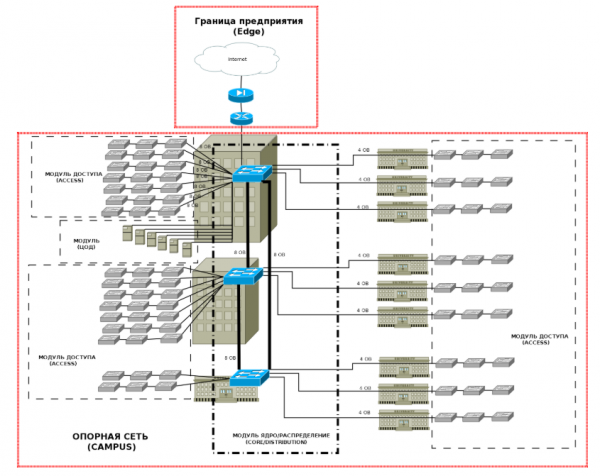
Successivamente, seguendo un approccio modulare, è necessario identificare i livelli e i moduli dell'azienda:
Non tratterò i confini (Edge) in questo articolo, ma fornirò brevemente i punti chiave su ciascun modulo Campus:- Accesso — a questo livello deve garantire:
- il numero necessario di porte per l'accesso degli utenti alla rete
- l'applicazione delle politiche di sicurezza — filtraggio del traffico e dei protocolli
- compressione dei domini di broadcast e segmentazione della rete tramite VLAN
- implementazione di VLAN dedicate per il traffico vocale
- supporto per QoS
- supporto per porte di accesso PoE
- supporto per IP multicast
- ridondanza dei link ascendente in combinazione con il livello di distribuzione (preferibilmente)
- Distribuzione — a questo livello deve essere garantito:
- il numero necessario di porte per il collegamento degli switch di accesso
- aggregazione e riserva dei link degli switch di accesso
- routing IP
- filtraggio dei pacchetti
- supporto per QoS
- ridondanza a livello di link, attrezzature e alimentazione (molto desiderabile)
- Nucleo — deve garantire:
- alta velocità di commutazione e instradamento dei pacchetti
- numero necessario di porte per la connessione degli switch di distribuzione
- supporto per l'instradamento IP e protocolli di instradamento dinamici con rapida convergenza della rete
- supporto per QoS
- funzionalità di sicurezza per proteggere l'accesso all'hardware e al control plane
- ridondanza a livello hardware e di alimentazione (obbligatoria)
- Il data center — il livello di rete di questo modulo deve garantire:
- collegamenti ad alta velocità
- numero necessario di porte per collegare i server
- riserva dei collegamenti sia tra i server e gli switch del data center, sia tra gli switch del data center e il core della rete (obbligatoria)
- riserva di hardware e alimentazione (obbligatoria)
- supporto per QoS
Dobbiamo quindi calcolare le nostre porte e i collegamenti e definire i requisiti.
Quindi, abbiamo ottenuto i dati sulla distribuzione delle porte di accesso negli edifici. Ora è necessario analizzare i requisiti per il livello di accesso e le osservazioni e delineare le possibili soluzioni.
Proseguiamo a calcolare le porte e i link di connessione per i seguenti livelli:
Dal calcolo abbiamo ottenuto quanto segue:
- livello di accesso — sono necessari switch di accesso a 24 e 48 porte, preferibilmente con porte di accesso a 1Gb e porte uplink ottiche SFP con supporto PoE e ampie funzionalità:
- in totale forniranno 504 porte di accesso, che in realtà copriranno i requisiti per le porte di riserva, nel caso si decida di utilizzare 2 porte per postazione — un telefono IP e una porta dati.
- è possibile utilizzare un switch a 48 porte con funzionalità PoE su ogni piano, fornendo porte di accesso per i requisiti:
- riserva — circa 102 porte di riserva (22%) negli edifici principali. Per i corpi aggiuntivi un po' più — 25%.
- videosorveglianza
- rete wireless
- livello di distribuzione — sono necessari switch con un numero di porte SFP da 12 a 48, con almeno 2 porte SFP+, con possibilità di impilamento e funzionalità avanzate, nonché con unità di alimentazione di riserva.
- livello core — sono richiesti switch ad alta velocità da 12 a 24 porte SFP/SFP+ con supporto per stacking e clustering con MC-LAG. È importante notare che è possibile utilizzare anche strumenti di routing per il bilanciamento del traffico. Le ultime generazioni di switch e router L3 supportano ECMP con bilanciamento del traffico su 4 o più percorsi con la stessa metrica.
- livello del Data Center — sono richiesti switch da 8 a 24 porte SFP/SFP+ con supporto per stacking e clustering con MC-LAG.
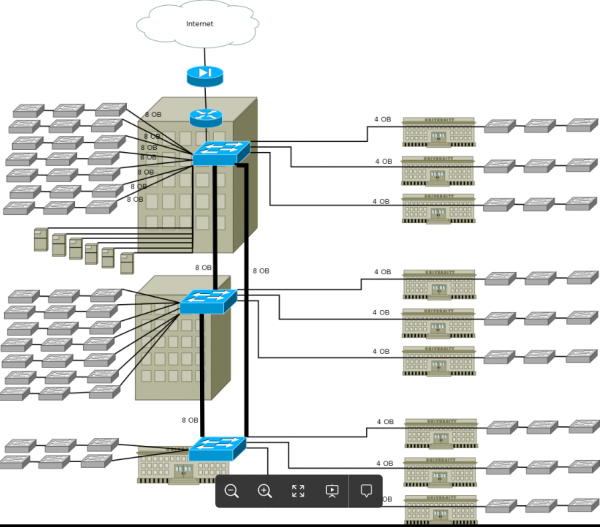
Alla fine, lo schema di rete risultante è diventato
Scelta degli switch Extreme per l'implementazione del progetto
Ecco, siamo arrivati al punto cruciale: il momento di scegliere gli switch per implementare il nostro progetto. Gli switch Extreme seguenti sono adatti per lo schema di rete risultante:
Livello
Modello
Porte
Descrizionenucleo
x620-16x-Base *x670-G2-48x-4q-Base*
16 x 10GE SFP+
48x10GE SFP+ e 4×40 GE QSFP+
Per le esigenze principali del nucleo:- collegamenti ad alta velocità
- funzionalità avanzata di routing e sicurezza
- ridondanza dell'alimentazione con unità di alimentazione aggiuntive
- supporto per stacking e clustering
Con requisiti minimi, lo switch della serie x620 è adatto.
In caso di esigenze avanzate riguardo al numero di porte e funzionalità più ampie, si dovrebbe considerare gli switch della serie x670-G2.Centro Dati
x620-16x-Base*
x590-24x-1q-2c*
x670-G2-48x-4q-Base*
16 x 10GE SFP+
24x10GE SFP, 1xQSFP+, 2xQSFP28
48x10GE SFP+ e 4×40 GE QSFP+Per le esigenze principali del Centro Dati:
- collegamenti ad alta velocità
- ridondanza dell'alimentazione con unità di alimentazione aggiuntive
- supporto per stacking e clustering
Con requisiti minimi, lo switch della serie x620 è adatto.
In caso di esigenze avanzate riguardo al numero di porte e funzionalità più ampie, si dovrebbe considerare gli switch della serie x670-G2 e x590-24x-1q-2c.distribuzione
X460-G2-24x-10GE4-Base*
X460-G2-48x-10GE4-Base*
24x1GE SFP, 8×1000 RJ-45, 4x10GE SFP+
48x1GE SFP, 4x10GE SFP+Per le esigenze principali di distribuzione:
- numero necessario di porte ottiche
- ridondanza dell'alimentazione con unità di alimentazione aggiuntive
- supporto per stacking e clustering
- funzionalità L3 necessaria
Gli switch della serie x460-G2 sono ideali. La presenza di alimentatori ridondanti con possibilità di espansione e aggiunta di porte 10G, CX (per stacking) e QSFP+ li rende switch ideali per il livello di distribuzione con porte fino a 1 Gb.
accesso
X440-G2-24p-10GE4*
X440-G2-24t-10GE4*
X440-G2-48t-10GE4*
X440-G2-48p-10GE4*
24x1000BASE-T(4 x SFP combo), 4x10GE SFP+ (budget PoE 380 W)
24x1000BASE-T(4 x SFP combo), 4x10GE SFP+
24x1000BASE-T(4 x SFP combo), 4x10GE SFP+ porte combo
48x1000BASE-T(4 x SFP combo), 4x10GE SFP+ porte combo (budget PoE 740 W)Per le esigenze di accesso:
- numero necessario di porte di accesso
- supporto PoE/PoE+
- funzionalità e possibilità di espansione porte
- un bonus aggiuntivo sotto forma di supporto per la connessione in stacking con porte 10Gb 'out of the box'
Consiglio di prestare attenzione a questa gamma per la sua flessibilità in termini di porte, prestazioni e funzionalità.
*la specifica degli switch scelti può essere consultata nel primo articolo della serie —
A questo punto potrei concludere l'articolo, ma vorrei evidenziare ulteriori 2 aspetti con cui qualsiasi ingegnere si confronterà nello sviluppo o nell'aggiornamento della propria rete:
- lavorare con i percorsi cablati — fibre e linee in rame
- indirizzamento IP
Lavorare con le fibre
In precedenza ho fornito lo schema obiettivo a cui è necessario arrivare. Per la sua realizzazione sono necessarie le seguenti connessioni per l'attrezzatura:
Come si può vedere dalla tabella, il numero minimo di fibre necessario per garantire l'affidabilità dei livelli di rete (modulo core, data center e distribuzioni in 2 edifici) è 10.
Nella fase di caratterizzazione della rete abbiamo scoperto che nel cavo tra gli edifici ci sono solo 8 fibre. Cosa fare in una situazione del genere?
Elenco alcune soluzioni:
- Il primo passo evidente è utilizzare le fibre libere nel cavo tra l'edificio 1 - corpo 1 e il corpo 1 - edificio 2 (come si può vedere dalla tabella, vengono utilizzate solo 2 delle 8 fibre in ogni cavo). Per questo è sufficiente installare dei connettori ottici tra i connettori nel corpo 1 e, se necessario, utilizzare moduli SFP con un margine di budget ottico.
- Il secondo passo potrebbe essere l'uso della tecnologia CWDM - una densificazione delle lunghezze d'onda all'interno di una singola fibra. Questa tecnologia è molto più economica del DWDM ed è piuttosto semplice da realizzare. Fondamentalmente, vengono posti requisiti sulla qualità delle fibre ottiche e sui trasmettitori SFP/SFP+ di specifiche lunghezze e budget. Come ho già accennato nel precedente articolo, la possibilità che gli switch riconoscano i trasmettitori di terze parti può semplificarci notevolmente la vita e ridurre le spese in conto capitale per la costruzione di ulteriori cavi ottici.
- Il terzo passo è considerare la possibilità di aumentare le fibre tramite la posa di ulteriori cavi ottici.
Successivamente, esaminiamo il numero di fibre tra gli edifici con switch di distribuzione e cabinet supplementari 2-10. Anche qui la situazione non è così chiara.
- In primo luogo, mancano fibre per implementare il nostro schema target: due fibre per ogni switch (come sappiamo, abbiamo cavi con 4 fibre ottiche per ogni cabinet).
- In secondo luogo, anche con un numero sufficiente di fibre tra gli edifici, all'interno dei cabinet vengono utilizzate fibre MMF, che non ci permetteranno di unire semplicemente le fibre SMF e MMF (parlo di distanze tra gli edifici superiori a 300-400 metri).
In questi casi si possono considerare le seguenti opzioni:
- fornire ogni switch con fibre SMF:
- se la distanza lo consente, è possibile stendere cavi patch lunghi tra gli switch. In passato abbiamo utilizzato patch di 30-50 m di lunghezza.
- installare un cavo ottico SMF a bassa capacità relativamente economico tra i rack.
- come ultima opzione, utilizzare vari convertitori SMF-MMF.
- Per minimizzare le fibre utilizzate tra gli edifici, si possono:
- utilizzare la funzionalità di stacking degli switch di accesso x440-G2 — in questo modo utilizzare 1 fibra SMF per ogni switch per piano, permettendo di utilizzare invece di 6 fibre e porte, 3 fibre e porte su ciascun lato
- utilizzare 2 fibre per collegare il primo switch del ramo e l'ultimo. Aggregare i link sugli switch di accesso perimetrali e utilizzare i protocolli STP nel cerchio risultante.
Indirizzamento IP
Qui fornirò un esempio di calcolo dell'indirizzamento per il nostro schema.
Al momento abbiamo diverse reti di classe B — 172.16.0.0/16. Quando calcolo lo spazio indirizzamento IP mi guiderò dai seguenti criteri:
- 4 bit del secondo ottetto rappresenteranno gli edifici — 172.16.0.0/12.
- Il terzo ottetto rappresenterà il numero del piano nell'edificio.
- Il terzo ottetto = 255 sarà riservato per i collegamenti point-to-point delle apparecchiature e la rete di gestione.
- una VLAN di gestione per piano per gestire gli switch.
- una VLAN utente per switch (in media 24 porte).
- una VLAN Voice per switch (in media 24 porte).
- una VLAN per il sistema di videosorveglianza per piano.
- una VLAN per i dispositivi Wi-Fi per piano.
Ho ottenuto tabelle simili a queste:
Nella tabella sopra ho fornito un esempio di distribuzione delle reti per edifici e piani da un lato e reti (utenti, gestione e servizi) dall'altro.
In realtà, la scelta della rete privata 172.16.0.0/12 non è la più ottimale, poiché limita il numero di reti (da 16 a 31) per gli edifici, e ci sono anche uffici remoti che necessitano di segmentazione delle reti; potrebbe essere più vantaggioso utilizzare la rete 10.0.0.0/8, oppure la combinazione delle reti 172.16.0.0/12 (ad esempio per uso aziendale e server) e 10.0.0.0/8 (per reti utente).
In generale, l'approccio alla distribuzione delle reti IP è anche modulare e sarebbe preferibile seguire le regole di aggregazione delle sottoreti in una rete summary a livello di distribuzione, così come sui router di confine negli uffici distaccati. Questo si fa per diverse ragioni:
- per minimizzare le tabelle di routing sui router
- per ridurre il traffico di servizio dei protocolli di routing (in tutti i tipi di messaggi di aggiornamento, in caso di inattività delle sottoreti annidate)
- per semplificare l'amministrazione e migliorare la leggibilità delle reti L3
Va notato che, per i primi due punti, la potenza dei router moderni è molto superiore a quella di 15-20 anni fa, consentendo di gestire tabelle di routing più grandi nella loro memoria operativa. Inoltre, il rapporto prezzo / capacità di banda è diminuito rispetto ai tempi in cui si usavano prevalentemente i flussi E1/T1 (G.703).
Conclusione
Cari amici, in questo articolo ho cercato di raccontare, per quanto possibile, i principi fondamentali del design delle reti campus. Sì, l'argomento è piuttosto vasto e questo senza trattare temi come:
- l'organizzazione del perimetro aziendale (questo è un'altra storia con i suoi switch, border, firewall, sistemi IPS/IDS, DMZ, VPN e altri elementi)
- l'organizzazione delle reti Wi-Fi
- l'organizzazione delle reti VoIP
- l'organizzazione dei data center
- la sicurezza (anche questo è un mondo a sé, che per volume e requisiti non è inferiore alla progettazione di un'infrastruttura di rete pura, a volte superandola)
- l'energia
- l'elenco può continuare e continuare
In effetti, progettare e costruire una rete aziendale è un compito piuttosto impegnativo, che richiede molto tempo e risorse.
Tuttavia, spero che il mio articolo vi aiuti a valutare e comprendere a un livello base come affrontare questo compito.
Questa non è l'ultima articolo su , quindi tenete d'occhio gli aggiornamenti (, , , )!
- telefonia:
- Sistema cablato tra gli edifici:
- una rete a 3 livelli è divisa in:
Fonte: habr.com
