

Ciao Habr! I dataset per il Big Data e l'apprendimento automatico stanno crescendo esponenzialmente e dobbiamo essere in grado di elaborarli. Il nostro post tratta di un'altra tecnologia innovativa nel campo del computing ad alte prestazioni (HPC, High Performance Computing), presentata allo stand di Kingston al . Questo riguarda l'uso di sistemi di archiviazione dati Hi-End (SASD) nei server con unità di elaborazione grafica (GPU) e tecnologia GPUDirect Storage. Grazie allo scambio diretto di dati tra il SASD e le GPU, evitando la CPU, il caricamento dei dati negli acceleratori GPU avviene con una velocità notevolmente maggiore, quindi le applicazioni Big Data raggiungono il massimo delle prestazioni fornite dalle GPU. Allo stesso tempo, gli sviluppatori di sistemi HPC sono interessati ai progressi nel campo dei SASD con la più alta velocità di input/output — come quelli prodotti da Kingston.

Le prestazioni delle GPU superano il caricamento dei dati
Dal 2007, anno in cui è stata introdotta CUDA — un'architettura software e hardware per il calcolo parallelo basata su GPU per lo sviluppo di applicazioni di uso generale, le capacità stesse delle GPU sono cresciute in modo incredibile. Oggi le GPU trovano un'applicazione sempre più ampia nel campo delle applicazioni HPC, come i big data, il machine learning (ML) e il deep learning (DL).
Va notato che, nonostante la somiglianza dei termini, le ultime due sono compiti algoritmicamente diversi. Il ML addestra il computer basandosi su dati strutturati, mentre il DL si basa sulle risposte di una rete neurale. Un esempio che aiuta a comprendere le differenze è piuttosto semplice. Supponiamo che un computer debba distinguere foto di gatti e cani caricate da uno storage. Per il ML è necessario fornire un insieme di immagini con diversi tag, ognuno dei quali definisce una particolarità specifica dell'animale. Per il DL, è sufficiente caricare un numero molto maggiore di immagini, ma con un solo tag che dice "questo è un gatto" o "questo è un cane". Il DL è molto simile a come si insegnano le cose ai bambini piccoli: vengono semplicemente mostrati immagini di cani e gatti nei libri e nella vita reale (spesso senza nemmeno spiegare le differenze dettagliate), e il cervello del bambino inizia a riconoscere il tipo di animale dopo un certo numero critico di immagini da confrontare (si stima che si tratti solo di un centinaio di visualizzazioni durante l'infanzia). Gli algoritmi DL non sono ancora così sofisticati: affinché una rete neurale possa lavorare altrettanto bene nella identificazione delle immagini, è necessario fornire e elaborare tramite GPU milioni di immagini.
Introduzione: sulla base della GPU è possibile costruire applicazioni HPC nel campo dei Big Data, ML e DL, ma esiste un problema: gli insiemi di dati sono così grandi che il tempo necessario per caricare i dati dal sistema di archiviazione nella GPU inizia a ridurre le prestazioni complessive dell'applicazione. In altre parole, le potenti schede grafiche rimangono sottoutilizzate a causa della lenta I/O dei dati provenienti da altre sottosistemi. La differenza nella velocità di I/O della GPU e della bus verso la CPU/storage può essere anche di un ordine di grandezza.
Come funziona la tecnologia GPUDirect Storage?
Il processo di I/O è controllato dalla CPU, così come il processo di caricamento dei dati dallo storage nelle schede grafiche per la successiva elaborazione. Da qui nasce la richiesta di una tecnologia che fornisca accesso diretto tra GPU e dischi NVMe per un'interazione rapida. La prima tecnologia di questo tipo è stata proposta da NVIDIA e denominata GPUDirect Storage. In sostanza, si tratta di una variante della tecnologia GPUDirect RDMA (Remote Direct Memory Address) precedentemente sviluppata da loro.
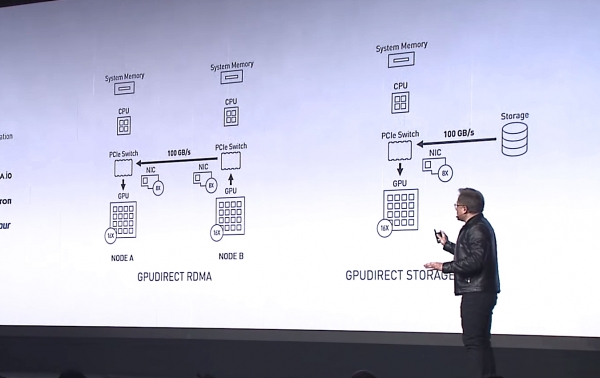
Jensen Huang, CEO di NVIDIA, presenta GPUDirect Storage come una variante di GPUDirect RDMA alla mostra SC-19. Fonte: NVIDIA
La differenza tra GPUDirect RDMA e GPUDirect Storage riguarda i dispositivi tra cui avviene l'indirizzamento. La tecnologia GPUDirect RDMA è progettata per spostare i dati direttamente tra l'adattatore di rete (NIC) e la memoria GPU, mentre GPUDirect Storage fornisce un percorso diretto per il trasferimento dei dati tra uno storage locale o remoto, come NVMe o NVMe over Fabrics (NVMe-oF), e la memoria GPU.
Entrambe le opzioni, GPUDirect RDMA e GPUDirect Storage, evitano spostamenti superflui dei dati attraverso il buffer nella memoria CPU e permettono al meccanismo di accesso diretto alla memoria (DMA) di trasferire dati dall'adattatore di rete o dallo storage direttamente nella memoria GPU o viceversa, il tutto senza carico sul processore centrale. Per GPUDirect Storage, la posizione dello storage non ha importanza: può essere un disco NVME all'interno della unità GPU, all'interno di un rack o connesso in rete come NVMe-oF.
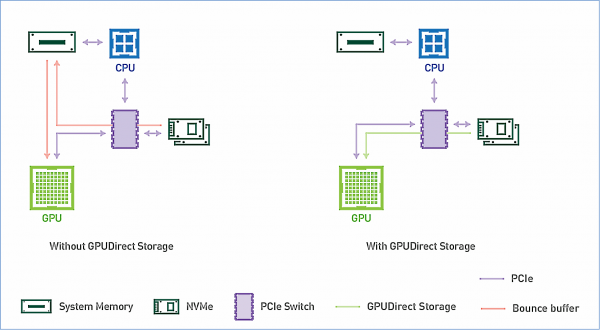
Schema di funzionamento di GPUDirect Storage. Fonte: NVIDIA
Le soluzioni di archiviazione hi-end basate su NVMe sono richieste nel mercato delle applicazioni HPC.
Comprendendo che con l'arrivo di GPUDirect Storage l'interesse dei grandi clienti si sta rivolgendo verso soluzioni di storage con velocità di input/output compatibili con la capacità della GPU, durante la fiera SC-19, Kingston ha presentato una demo di un sistema composto da uno storage basato su dischi NVMe e un'unità GPU, che analizzava migliaia di immagini satellitari al secondo. Di questo storage basato su 10 dischi DC1000M U.2 NVMe ne abbiamo già parlato. .

Lo storage basato su 10 dischi DC1000M U.2 NVMe integra perfettamente un server con acceleratori grafici. Fonte: Kingston
Questo storage si presenta come un'unità rack 1U o superiore e può scalare a seconda del numero di dischi DC1000M U.2 NVMe, ciascuno con capacità di 3.84-7.68 TB. Il DC1000M è il primo modello di SSD NVMe nel formato U.2 della linea di dischi Kingston per i data center. Ha un rating di resistenza (DWPD, Drive writes per day) che consente di riscrivere i dati a piena capacità una volta al giorno per tutta la durata garantita dell'unità.
Nel test fio v3.13 su Ubuntu 18.04.3 LTS, con il kernel Linux 5.0.0-31-generic, il campione di storage ha mostrato una velocità di lettura (Sustained Read) di 5,8 milioni di IOPS con una larghezza di banda sostenuta (Sustained Bandwidth) di 23,8 Gbit/s.
Ariël Perez, business manager SSD in Kingston, ha descritto così i nuovi sistemi di storage: «Siamo pronti a fornire la prossima generazione di server con soluzioni SSD U.2 NVMe, per eliminare molti dei colli di bottiglia nella trasmissione dei dati che storicamente sono stati associati ai sistemi di storage. La combinazione di unità NVMe SSD e della nostra memoria DRAM Server Premier fa di Kingston uno dei fornitori di soluzioni complete per l'elaborazione dei dati più completi nel settore».
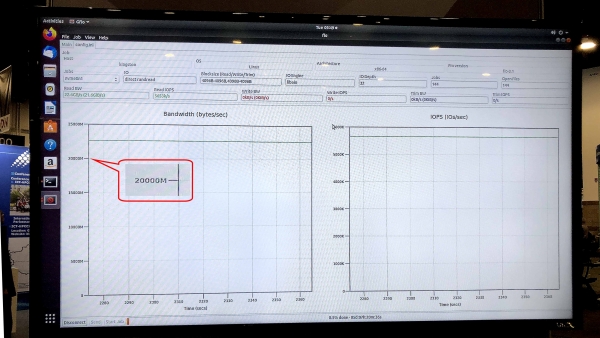
Il test gfio v3.13 ha mostrato una larghezza di banda di 23,8 Gbit/s per il sistema di storage dimostrativo basato su dischi DC1000M U.2 NVMe. Fonte: Kingston
Come sarà una tipica architettura per applicazioni HPC, dove è implementata la tecnologia GPUDirect Storage o un'alternativa simile? Sarà un'architettura con una separazione fisica dei blocchi funzionali all'interno di un rack: uno o due unità per la memoria, alcune per i nodi di calcolo GPU e CPU e una o più unità per il sistema di storage.
Con l'annuncio di GPUDirect Storage e il possibile arrivo di tecnologie simili da altri fornitori GPU, cresce la domanda per le soluzioni di storage basate su Kingston, progettate per l'uso in calcoli ad alte prestazioni. Un indicatore chiave sarà la velocità di lettura dei dati dallo storage, paragonabile alla capacità di rete delle schede da 40 o 100 Gbit al servizio dell'unità di calcolo con GPU. Pertanto, gli storage ultra-veloci, compresi gli NVMe esterni tramite Fabric, si trasformeranno da nicchia a mainstream per le applicazioni HPC. Oltre alla ricerca e ai calcoli finanziari, troveranno applicazione in molti altri ambiti pratici, come i sistemi di sicurezza a livello metropolitano nel progetto Safe City o nei centri di monitoraggio del trasporto, dove è richiesta una velocità di riconoscimento e identificazione nell'ordine di milioni di immagini HD al secondo”, ha evidenziato la nicchia di mercato delle soluzioni di storage di fascia alta.
Ulteriori informazioni sui prodotti Kingston sono disponibili su dell'azienda.
Fonte: habr.com
