


Ciao lettori di Habr! Nell'articolo precedente abbiamo parlato di un semplice metodo per la resilienza ai disastri nei sistemi di storage AERODISK ENGINE: la replica. In questo articolo ci tufferemo in un argomento più complesso e interessante: il metrocluster, ovvero un sistema di protezione automatizzata contro i disastri per due datacenter, che consente il funzionamento dei datacenter in modalità active-active. Racconteremo, mostreremo, rompiamo e ripariamo.
Come al solito, iniziamo con la teoria
Il metrocluster è un cluster distribuito su più sedi all'interno di una città o di un'area. La parola "cluster" ci suggerisce chiaramente che il complesso è automatizzato, il che significa che il passaggio dei nodi del cluster in caso di guasti (failover) avviene automaticamente.
Qui si trova la principale differenza tra un metrocluster e una replica standard. Automazione delle operazioni. In caso di eventi problematici (guasto del data center, interruzione dei collegamenti, ecc.), il sistema di storage eseguirà autonomamente le azioni necessarie per garantire la disponibilità dei dati. Con le repliche tradizionali, queste azioni sono eseguite interamente o parzialmente a mano dall'amministratore.
A cosa serve?
L'obiettivo principale che i clienti perseguono usando le varie implementazioni del metrocluster è ridurre al minimo l'RTO (Recovery Time Objective). In altre parole, ridurre il tempo per il ripristino dei servizi IT dopo un'interruzione. Se si utilizza una replica standard, il tempo di ripristino sarà sempre superiore a quello richiesto da un metrocluster. Perché? È molto semplice. L'amministratore deve essere presente e commutare la replica manualmente, mentre il metrocluster lo fa automaticamente.
Se non avete un amministratore dedicato che monitori 24 ore su 24, 7 giorni su 7, senza mangiare, bere, fumare o ammalarsi, non è possibile garantire che un amministratore sarà disponibile per il passaggio manuale durante un guasto.
Di conseguenza, il RTO in assenza di un metrocluster o di un amministratore immortale di livello 99 sarà pari alla somma dei tempi di switch di tutti i sistemi e al massimo intervallo di tempo dopo il quale l'amministratore inizierà a lavorare garantito con il sistema di archiviazione e i sistemi ad esso collegati.
Pertanto, giungiamo alla conclusione evidente che il metrocluster deve essere utilizzato nel caso in cui il requisito per il RTO sia in minuti, e non in ore o giorni. Cioè, quando, in caso del peggior crollo del data center, il dipartimento IT deve assicurare all'azienda il ripristino dell'accesso ai servizi IT entro pochi minuti o addirittura secondi.
Come funziona?
A livello inferiore, il metrocluster utilizza un meccanismo di replica dati sincronizzata, che abbiamo descritto nel precedente articolo (vedi ). Poiché la replica è sincronizzata, anche i requisiti sono corrispondenti e, per essere più precisi:
- fibra ottica come fisica, Ethernet da 10 gigabit (o superiore);
- la distanza tra i data center non supera i 40 chilometri;
- la latenza del canale ottico tra i data center (tra gli storage) fino a 5 millisecondi (ottimale 2).
Tutti questi requisiti sono raccomandati, il che significa che il metrocluster funzionerà anche se non vengono rispettati, ma è importante comprendere che le conseguenze della non osservanza di questi requisiti equivalgono a un rallentamento delle prestazioni di entrambi gli storage nel metrocluster.
Quindi, per trasferire dati tra gli storage, si utilizza la replica sincronizzata; ma come avviene il passaggio automatico delle repliche e, soprattutto, come evitare il problema dello split-brain? A questo livello, viene utilizzata un'entità aggiuntiva: l'arbitro.
Come funziona l'arbitro e qual è il suo compito?
L'arbitro è una piccola macchina virtuale o un cluster hardware che deve essere avviato in una terza posizione (ad esempio, in ufficio) e deve garantire l'accesso agli storage tramite ICMP e SSH. Dopo l'avvio, l'arbitro deve impostare l'IP, e poi, dal lato degli storage, indicare il suo indirizzo, più gli indirizzi dei controller remoti che partecipano al metrocluster. Dopo questo, l'arbitro è pronto per il lavoro.
L'arbitro esegue un monitoraggio costante di tutti i sistemi di archiviazione nel metrocluster e, in caso di indisponibilità di un dato sistema di archiviazione, dopo aver confermato l'indisponibilità da un altro partecipante al cluster (uno dei sistemi di archiviazione "attivi"), decide di avviare la procedura di commutazione delle regole di replica e di mappatura.
Un aspetto molto importante. L'arbitro deve sempre trovarsi in un'area diversa da quella in cui si trovano i sistemi di archiviazione, quindi né nel Centro dati 1, dove si trova il sistema di archiviazione 1, né nel Centro dati 2, dove è installato il sistema di archiviazione 2.
Perché? Perché solo così l'arbitro, utilizzando uno dei sistemi di archiviazione rimasti attivi, può identificare in modo chiaro e senza errori il fallimento di uno dei due siti in cui si trovano i sistemi di archiviazione. Qualsiasi altro modo di posizionare l'arbitro potrebbe portare a un problema di split-brain.
Ora immergiamoci nei dettagli del funzionamento dell'arbitro.
Sull'arbitro sono attivi diversi servizi che interrogano costantemente tutti i controller dei sistemi di archiviazione. Se il risultato dell'interrogazione differisce da quello precedente (disponibile/non disponibile), viene registrato in un piccolo database che funziona anch'esso sull'arbitro.
Esaminiamo più dettagliatamente la logica di funzionamento dell'arbitro.
Passaggio 1. Identificazione dell'indisponibilità. Un evento di segnalazione di guasto del sistema di archiviazione è l'assenza di ping da entrambi i controller di un sistema di archiviazione per un periodo di 5 secondi.
Passo 2. Avvio della procedura di commutazione. Dopo che l'arbitro ha compreso che uno dei sistemi di archiviazione non è disponibile, invia una richiesta al sistema di archiviazione 'vivo' per accertarsi che quello 'morto' sia effettivamente non operativo.
Dopo aver ricevuto tale comando dall'arbitro, il secondo sistema di archiviazione (quello vivo) verifica ulteriormente la disponibilità del primo sistema di archiviazione che è andato giù e, se non è disponibile, invia all'arbitro una conferma della sua supposizione. Il sistema di archiviazione non è effettivamente disponibile.
Dopo aver ricevuto tale conferma, l'arbitro avvia la procedura remota di commutazione della replica e di attivazione della mappatura su quelle repliche che erano attive (primary) sul sistema di archiviazione che è andato giù, e invia un comando al secondo sistema di archiviazione per trasformare queste repliche da secondary a primary e attivare la mappatura. Il secondo sistema di archiviazione esegue quindi tali procedure, dopo di che garantisce l'accesso agli LUN persi da esso.
Perché è necessaria una verifica aggiuntiva? Per il quorum. Questo significa che la maggioranza del numero dispari totale (3) di partecipanti al cluster deve confermare il guasto di uno dei nodi del cluster. Solo allora questa decisione sarà veramente corretta. È necessario per evitare commutazioni errate e, di conseguenza, il problema dello split-brain.
Il Passo 2 richiede circa 5-10 secondi, quindi, tenendo conto del tempo necessario per determinare l'indisponibilità (5 secondi), entro 10-15 secondi dopo il guasto della LUN, il sistema di archiviazione che è andato in down sarà automaticamente disponibile per collaborare con il sistema di archiviazione attivo.
È chiaro che per evitare interruzioni della connessione con gli host, è anche necessario prendersi cura della corretta configurazione dei timeout sugli host. Il timeout raccomandato è di almeno 30 secondi. Ciò impedirà all'host di interrompere la connessione con il sistema di archiviazione durante il passaggio del carico in caso di guasto e garantirà l'assenza di interruzioni nella scrittura e lettura.
Aspetta un attimo, quindi se il metrocluster funziona così bene, a cosa serve la replica normale?
In realtà, le cose non sono così semplici.
Esaminiamo i pro e i contro del metrocluster.
Quindi, abbiamo capito che i vantaggi evidenti del metrocluster rispetto alla replica tradizionale sono:
- Automazione completa, garantendo un tempo di recupero minimo in caso di disastro;
- E tutto :-).
Ora, attenzione, gli svantaggi:
- Costo della soluzione. Sebbene il metrocluster nei sistemi Aerodisks non richieda ulteriori licenze (si utilizza la stessa licenza della replica), il costo sarà comunque superiore rispetto all'uso della replica sincronizzata. Sarà necessario implementare tutti i requisiti per la replica sincronizzata, oltre ai requisiti per il metrocluster, che riguardano la commutazione aggiuntiva e un'ulteriore posizione (vedi pianificazione del metrocluster);
- Complesso da gestire. Il metrocluster è strutturato in modo significativamente più complesso rispetto a una replica tradizionale e richiede molta più attenzione e risorse per la pianificazione, la configurazione e la documentazione.
In conclusione. Il metrocluster è sicuramente una soluzione molto tecnologica e di alta qualità quando è realmente necessario garantire un RTO in secondi o minuti. Tuttavia, se non è questo il caso e un RTO nell'arco di ore è accettabile per l'azienda, non ha senso usare un cannone per colpire un passero. È sufficiente una normale replica di tipo lavorativo, dato che un metrocluster comporterebbe costi aggiuntivi e una complessità maggiore per l'infrastruttura IT.
Pianificazione del metrocluster
Questa sezione non pretende di essere una guida esaustiva alla progettazione di un metrocluster, ma mostra solo le principali direzioni da esplorare se desiderate costruire un sistema di questo tipo. Pertanto, durante l'implementazione reale del metrocluster, è fondamentale consultarsi con il produttore della soluzione di archiviazione (cioè noi) e altri sistemi correlati.
Siti
Come menzionato sopra, per un metrocluster sono necessarie almeno tre sedi. Due data center dove opereranno le soluzioni di archiviazione e i sistemi correlati, e una terza sede dove opererà l'arbitro.
La distanza raccomandata tra i data center è di non oltre 40 chilometri. Distanze maggiori comporteranno molto probabilmente ritardi aggiuntivi, che in un metrocluster sono estremamente indesiderabili. Ricordiamo che i ritardi devono essere fino a 5 millisecondi, anche se è preferibile rimanere entro 2.
È consigliabile verificare i ritardi anche durante la fase di pianificazione. Qualsiasi provider di rete in fibra ottica di un certo livello può organizzare un controllo di qualità piuttosto rapidamente.
Per quanto riguarda i ritardi fino all'arbitro (ossia tra il terzo soggetto e i due primi), la soglia raccomandata per i ritardi è di 200 millisecondi, quindi è adatta una normale connessione VPN aziendale sopra la rete Internet.
Commuta e rete
A differenza dello schema di replica, dove è sufficiente connettere le SAN di diversi siti, lo schema del metrocluster richiede la connessione degli host a entrambe le SAN in siti diversi. Per chiarire la differenza, entrambi gli schemi sono indicati di seguito.
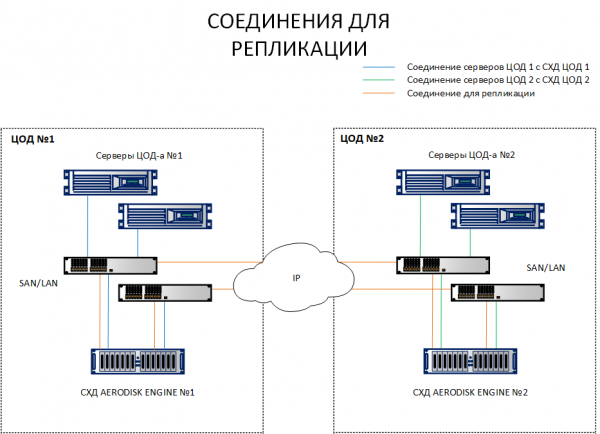
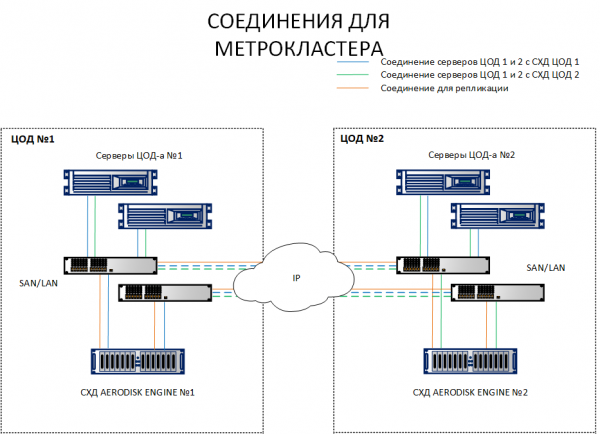
Come si può vedere dallo schema, gli host del sito 1 si connettono sia alla SAN1 che alla SAN2. Viceversa, anche gli host del sito 2 si connettono sia alla SAN2 che alla SAN1. Ogni host può vedere entrambe le SAN. Questo è un requisito fondamentale per il funzionamento del metrocluster.
Naturalmente, non è necessario connettere ogni host tramite un cavo in fibra ottica a un altro data center; non ci sarebbero abbastanza porte e cavi. Tutte queste connessioni devono essere realizzate tramite switch Ethernet 10G+ o FibreChannel 8G+ (FC è utilizzato solo per il collegamento degli host con l'SAN per IO, mentre il canale di replica è attualmente disponibile solo tramite IP (Ethernet 10G+).
Ora qualche parola sulla topologia di rete. Un punto importante è la corretta configurazione delle sottoreti. È necessario definire fin da subito diverse sottoreti per i seguenti tipi di traffico:
- Sottorete per la replica, attraverso la quale verranno sincronizzati i dati tra gli SAN. Possono essercene più di una; in questo caso, dipende dalla topologia di rete attuale (già implementata). Se ce ne sono due, ovviamente deve essere configurato il routing tra di esse;
- Sottoreti di archiviazione dei dati, tramite le quali gli host accederanno alle risorse SAN (se si tratta di iSCSI). Deve esserci una sottorete in ciascun data center;
- Sottoreti di gestione, ovvero tre sottoreti instradabili in tre località, da cui viene gestito l'SAN e dove si trova anche l'arbitro.
Le sottoreti per accedere alle risorse degli host non sono oggetto di questo nostro esame, poiché dipendono fortemente dai requisiti specifici.
La separazione del traffico diverso in sottoreti distinte è cruciale (soprattutto è importante isolare le repliche dall'I/O), poiché mescolare tutto il traffico in un'unica sottorete "grassa" rende impossibile la gestione di questo flusso, e in un contesto di due data center questo può anche causare diversi tipi di collisioni di rete. Non approfondiremo ulteriormente questo aspetto in questo articolo, poiché per la pianificazione di una rete estesa tra i data center si può consultare la documentazione dei produttori di apparecchiature di rete, dove è trattato in dettaglio.
Configurazione dell'arbitro
L'arbitro deve garantire l'accesso a tutte le interfacce di gestione dello storage secondo i protocolli ICMP e SSH. È inoltre importante considerare la resilienza dell'arbitro. Qui c'è un aspetto da considerare.
La resilienza dell'arbitro è molto auspicabile, ma non obbligatoria. E se l'arbitro fallisse in modo imprevisto?
- Il funzionamento del metro-cluster rimarrà inalterato, poiché l'arbitro non influisce assolutamente sul funzionamento del metro-cluster (il suo compito è quello di indirizzare il carico tra i datacenter in modo tempestivo).
- Tuttavia, nel caso in cui l'arbitro, per qualsiasi motivo, dovesse cadere e «perdere» l'emergenza nel datacenter, non ci sarebbe alcun cambio, perché non ci sarebbero ordini da dare per effettuare la commutazione e organizzare il quorum. In questo caso, il metro-cluster si trasformerebbe in un normale schema di replica, che dovrà essere commutato manualmente durante un'emergenza, con un impatto sull'RTO.
Cosa ne deriva da tutto ciò? Se è davvero necessario garantire un RTO minimo, è necessario assicurare l'affidabilità dell'arbitro. Ci sono due opzioni per farlo:
- Eseguire una virtual machine con l'arbitro su un hypervisor a elevate prestazioni, dal momento che tutti gli hypervisor moderni supportano la tolleranza ai guasti.
- Se nella terza sede (nel nostro ufficio simulato) non si desidera configurare un cluster adeguato e non esiste un cluster di hypervisor, abbiamo previsto una soluzione hardware per l'arbitro, disponibile in un'unità da 2U, che ospita due server x86 standard e che può resistere a un guasto locale.
Consigliamo vivamente di garantire la resilienza dell'arbitro, anche se nel funzionamento normale non è necessaria per il metro-cluster. Ma come dimostrano sia la teoria che la pratica, se si costruisce un'infrastruttura realmente affidabile e resistente ai disastri, è meglio non correre rischi. È preferibile proteggere se stessi e la propria attività dalla "legge di Murphy", ovvero evitare il guasto simultaneo dell'arbitro e di uno dei siti in cui è collocato il sistema di storage.
Architettura della soluzione
Tenendo conto dei requisiti sopra menzionati, otteniamo la seguente architettura generale della soluzione.
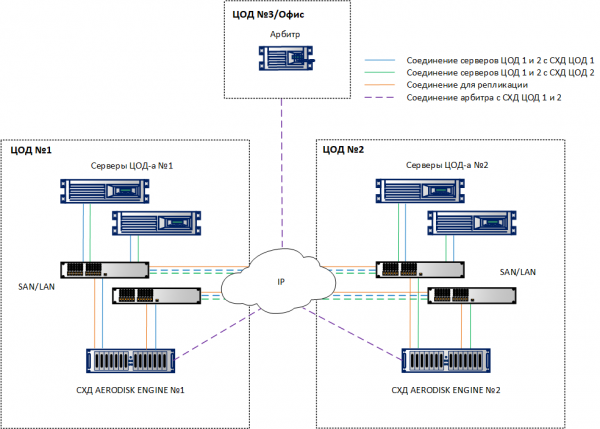
Le LUN devono essere distribuiti uniformemente su due sedi per evitare sovraccarichi eccessivi. Inoltre, nella dimensione di entrambi i data center, è necessario prevedere non solo il doppio della capacità (necessaria per la memorizzazione dei dati contemporaneamente su due sistemi di archiviazione), ma anche il doppio delle prestazioni in IOPS e MB/s, per evitare la degradazione delle applicazioni in caso di guasto di uno dei data center.
È importante sottolineare che, con un approccio corretto alla dimensione (cioè, a condizione che abbiamo previsto adeguati limiti superiori per gli IOPS e i MB/s, nonché le risorse necessarie di CPU e RAM), in caso di guasto di uno dei sistemi di archiviazione nel metro cluster non ci sarà un significativo calo delle prestazioni durante il funzionamento temporaneo su un solo sistema di archiviazione.
Questo è dovuto al fatto che, nel lavoro simultaneo di due piattaforme, la replica sincrona in uso "consuma" metà delle prestazioni in scrittura, poiché ogni transazione deve essere registrata su due sistemi di storage (simile a RAID-1/10). Così, in caso di guasto di uno dei sistemi di storage, l'impatto della replica scompare temporaneamente (fino a quando il sistema di storage guasto non viene ripristinato), e otteniamo un raddoppio delle prestazioni in scrittura. Dopo che i LUN del sistema di storage guasto sono stati riavviati su quello funzionante, questo raddoppio delle prestazioni svanisce a causa del carico proveniente dai LUN dell'altro sistema di storage, e torniamo al livello di prestazioni che avevamo prima del "guasto", ma solo all'interno di una singola piattaforma.
Con un sizing corretto, è possibile garantire condizioni in cui gli utenti non percepiranno affatto il guasto dell'intero sistema di storage. Ripetiamo, però, che ciò richiede un sizing molto attento, al quale, tra l'altro, è possibile contattarci gratuitamente :-).
Configurazione del metrocluster
La configurazione del metrocluster è molto simile alla configurazione della replica ordinaria, che abbiamo descritto in . Perciò, ci concentreremo solo sulle differenze. Abbiamo configurato in laboratorio un banco di prova basato sull'architettura di cui sopra, ma in versione minima: due archiviazioni collegate tramite Ethernet 10G, due switch 10G e un host che si connette tramite gli switch a entrambe le archiviazioni utilizzando porte 10G. L'arbitro funziona su una macchina virtuale.
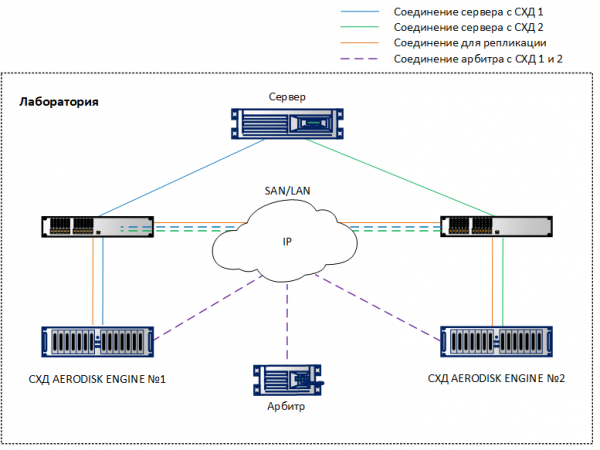
Quando si configurano gli IP virtuali (VIP) per la replica, è necessario scegliere il tipo di VIP – per il metrocluster.
Abbiamo creato due collegamenti di replica per due LUN e li abbiamo distribuiti su due archiviazioni: LUN TEST Primary su Archiviazione 1 (collegamento METRO), LUN TEST2 Primary per Archiviazione 2 (collegamento METRO2).
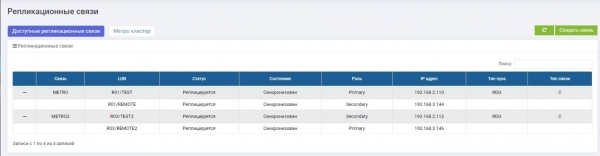
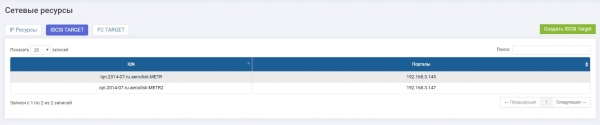
Per queste abbiamo configurato due target identici (nel nostro caso iSCSI, ma è supportato anche FC, la logica di configurazione è la stessa).
Archiviazione 1:

Archiviazione 2:
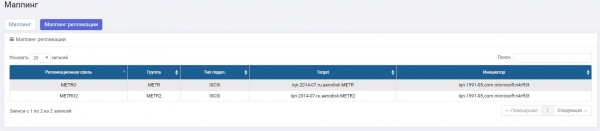
Per i collegamenti di replica abbiamo effettuato il mapping su ciascuna archiviazione.
Archiviazione 1:
Archiviazione 2:
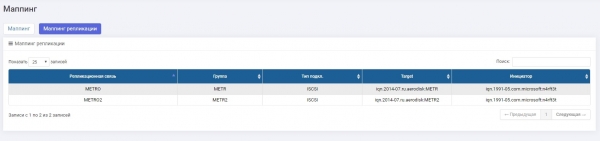
Abbiamo configurato il multipath e lo abbiamo presentato sull'host.
Configuriamo l'arbitro
Con l'arbitro non bisogna fare particolari operazioni, basta attivarlo sul terzo controller, assegnargli un IP e configurare l'accesso tramite ICMP e SSH. La configurazione vera e propria viene eseguita sulle unità di storage. È sufficiente configurare l'arbitro una sola volta su uno qualsiasi dei controller delle unità di storage nel metrocluster, queste impostazioni saranno propagate automaticamente a tutti i controller.
Nella sezione Replica remota >> Metrocluster (su qualsiasi controller) >> pulsante "Configura".
Inseriamo l'IP dell'arbitro, così come le interfacce di gestione dei due controller dell'unità di storage remota.
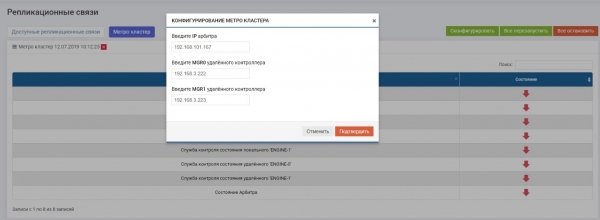
Dopo ciò, è necessario attivare tutti i servizi (pulsante "Riavvia tutto"). In caso di riconfigurazione in futuro, è fondamentale riavviare i servizi affinché le impostazioni abbiano effetto.
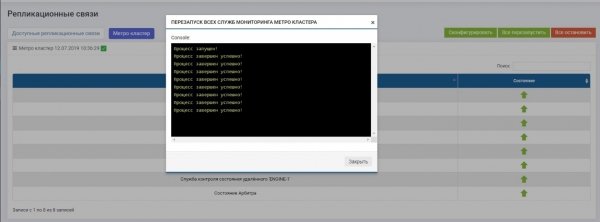
Verifichiamo che tutti i servizi siano attivi.
A questo punto, la configurazione del metrocluster è completa.
Crash test
Il crash test, in questo caso, sarà piuttosto semplice e veloce, poiché la funzionalità di replica (failover, coerenza, ecc.) è stata già esaminata nel . Pertanto, per testare l'affidabilità del metrocluster, dobbiamo semplicemente verificare l'automazione per la rilevazione dei guasti, il failover e l'assenza di perdite durante la scrittura (interruzioni dell'input/output).
A tal fine, emuliamo un guasto totale di uno dei sistemi di archiviazione, spegnendo fisicamente entrambi i suoi controller e avviando prima la copia di un grande file su un LUN, che dovrebbe attivarsi su un altro sistema di archiviazione.
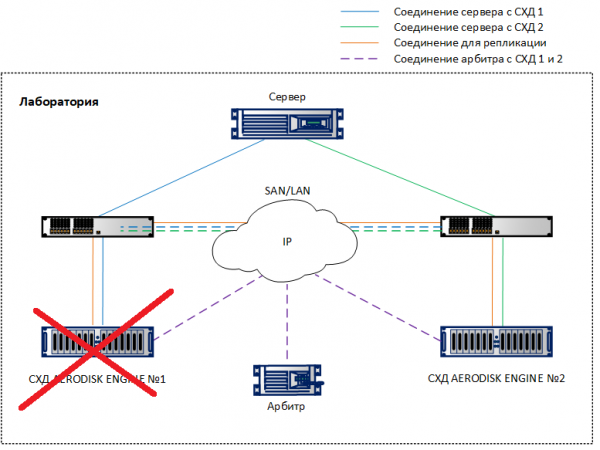
Scolleghiamo un sistema di archiviazione. Sul secondo sistema vediamo avvisi e messaggi nei log che indicano che la connessione con il sistema adiacente è stata persa. Se le notifiche via SMTP o SNMP sono attivate, l'amministratore riceverà notifiche appropriate.
Esattamente dopo 10 secondi (visibile in entrambi gli screenshot) la connessione di replica METRO (quella che era Primary sul sistema di archiviazione guasto) è automaticamente diventata Primary sul sistema di archiviazione funzionante. Utilizzando il mapping esistente, il LUN TEST è rimasto accessibile all'host, con una leggera caduta nell'operatività (entro il promesso 10 percento), ma non si è interrotto.

Il test è stato completato con successo.
In sintesi
L'attuale implementazione del metrocluster nei sistemi di archiviazione AERODISK Engine di serie N consente di affrontare pienamente le sfide in cui è necessario eliminare o ridurre al minimo i tempi di inattività dei servizi IT e garantire il loro funzionamento 24/7/365 con il minimo sforzo lavorativo.
Si potrebbe dire, certo, che tutto ciò è teoria, condizioni di laboratorio ideali e così via... MA abbiamo una serie di progetti realizzati in cui abbiamo implementato la funzionalità di resilienza alle catastrofi, e i sistemi funzionano alla grande. Uno dei nostri clienti abbastanza noti, che utilizza proprio due sistemi di archiviazione in configurazione resiliente, ha già dato il consenso alla pubblicazione delle informazioni sul progetto, quindi nella parte successiva parleremo dell'implementazione in condizioni operative.
Grazie, aspettiamo una discussione produttiva.
Fonte: habr.com
