


Привет, Хабр! В этой статье я хочу рассказать об одном замечательном инструменте для разработки batch-процессов обработки данных, например, в инфраструктуре корпоративного DWH или вашего DataLake. Речь пойдет об Apache Airflow (далее Airflow). Он несправедливо обделен вниманием на Хабре, и в основной части я попытаюсь убедить вас в том, что как минимум на Airflow стоит смотреть при выборе планировщика для ваших ETL/ELT-процессов.
Ранее я писал серию статей на тему DWH, когда работал в Тинькофф Банке. Теперь я стал частью команды Mail.Ru Group и занимаюсь развитием платформы для анализа данных на игровом направлении. Собственно, по мере появления новостей и интересных решений мы с командой будем рассказывать тут о нашей платформе для аналитики данных.
Prologo
Итак, начнем. Что такое Airflow? Это библиотека (ну или ) для разработки, планирования и мониторинга рабочих процессов. Основная особенность Airflow: для описания (разработки) процессов используется код на языке Python. Отсюда вытекает масса преимуществ для организации вашего проекта и разработки: по сути, ваш (например) ETL-проект — это просто Python-проект, и вы можете его организовывать как вам удобно, учитывая особенности инфраструктуры, размер команды и другие требования. Инструментально всё просто. Используйте, например, PyCharm + Git. Это прекрасно и очень удобно!
Теперь рассмотрим основные сущности Airflow. Поняв их суть и назначение, вы оптимально организуете архитектуру процессов. Пожалуй, основная сущность — это Directed Acyclic Graph (далее DAG).
DAG
DAG — это некоторое смысловое объединение ваших задач, которые вы хотите выполнить в строго определенной последовательности по определенному расписанию. Airflow представляет удобный web-интерфейс для работы с DAG’ами и другими сущностями:
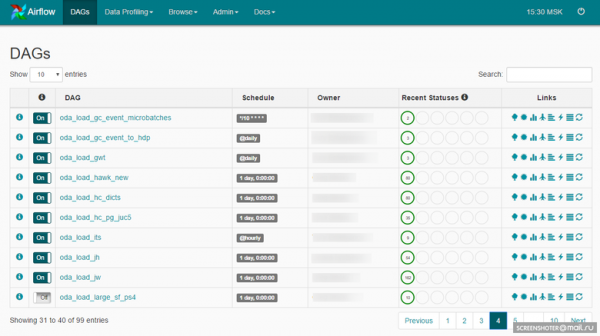
DAG может выглядеть таким образом:
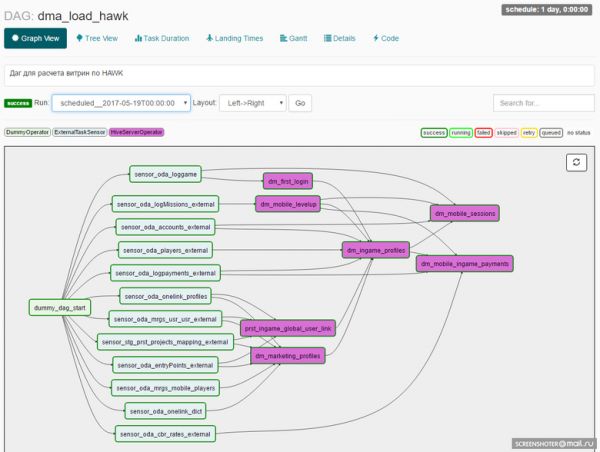
Разработчик, проектируя DAG, закладывает набор операторов, на которых будут построены задачи внутри DAG’а. Тут мы приходим еще к одной важной сущности: Airflow Operator.
Операторы
Оператор — это сущность, на основании которой создаются экземпляры заданий, где описывается, что будет происходить во время исполнения экземпляра задания. уже содержат набор операторов, готовых к использованию. Примеры:
- BashOperator — оператор для выполнения bash-команды.
- PythonOperator — оператор для вызова Python-кода.
- EmailOperator — оператор для отправки email’а.
- HTTPOperator — оператор для работы с http-запросами.
- SqlOperator — оператор для выполнения SQL-кода.
- Sensor — оператор ожидания события (наступления нужного времени, появления требуемого файла, строки в базе БД, ответа из API — и т. д., и т. п.).
Есть более специфические операторы: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
Вы также можете разрабатывать операторы, ориентируясь на свои особенности, и использовать их в проекте. Например, мы создали MongoDBToHiveViaHdfsTransfer, оператор экспорта документов из MongoDB в Hive, и несколько операторов для работы с : CHLoadFromHiveOperator и CHTableLoaderOperator. По сути, как только в проекте возникает часто используемый код, построенный на базовых операторах, можно задуматься о том, чтобы собрать его в новый оператор. Это упростит дальнейшую разработку, и вы пополните свою библиотеку операторов в проекте.
Далее все эти экземпляры задачек нужно выполнять, и теперь речь пойдет о планировщике.
Pianificatore
Планировщик задач в Airflow построен на . Celery — это Python-библиотека, позволяющая организовать очередь плюс асинхронное и распределенное исполнение задач. Со стороны Airflow все задачи делятся на пулы. Пулы создаются вручную. Как правило, их цель — ограничить нагрузку на работу с источником или типизировать задачи внутри DWH. Пулами можно управлять через web-интерфейс:
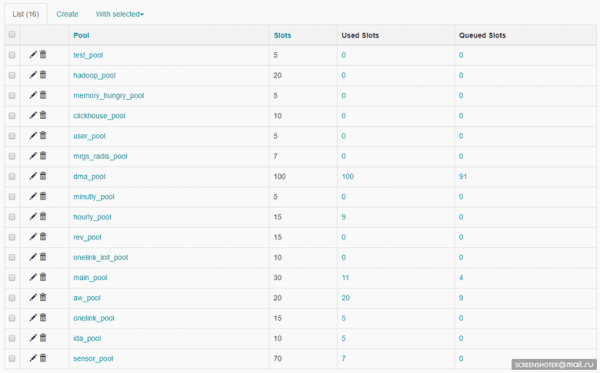
Каждый пул имеет ограничение по количеству слотов. При создании DAG’а ему задается пул:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh")
DAG_NAME = 'dma_load'
OWNER = 'Vasya Pupkin'
DEPENDS_ON_PAST = True
EMAIL_ON_FAILURE = True
EMAIL_ON_RETRY = True
RETRIES = int(Variable.get('gv_dag_retries'))
POOL = 'dma_pool'
PRIORITY_WEIGHT = 10
start_dt = datetime.today() - timedelta(1)
start_dt = datetime(start_dt.year, start_dt.month, start_dt.day)
default_args = {
'owner': OWNER,
'depends_on_past': DEPENDS_ON_PAST,
'start_date': start_dt,
'email': ALERT_MAILS,
'email_on_failure': EMAIL_ON_FAILURE,
'email_on_retry': EMAIL_ON_RETRY,
'retries': RETRIES,
'pool': POOL,
'priority_weight': PRIORITY_WEIGHT
}
dag = DAG(DAG_NAME, default_args=default_args)
dag.doc_md = __doc__Пул, заданный на уровне DAG’а, можно переопределить на уровне задачи.
За планировку всех задач в Airflow отвечает отдельный процесс — Scheduler. Собственно, Scheduler занимается всей механикой постановки задачек на исполнение. Задача, прежде чем попасть на исполнение, проходит несколько этапов:
- В DAG’е выполнены предыдущие задачи, новую можно поставить в очередь.
- Очередь сортируется в зависимости от приоритета задач (приоритетами тоже можно управлять), и, если в пуле есть свободный слот, задачу можно взять в работу.
- Если есть свободный worker celery, задача направляется в него; начинается работа, которую вы запрограммировали в задачке, используя тот или иной оператор.
Достаточно просто.
Scheduler работает на множестве всех DAG’ов и всех задач внутри DAG’ов.
Чтобы Scheduler начал работу с DAG’ом, DAG’у нужно задать расписание:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')Есть набор готовых preset’ов: @once, @hourly, @daily, @weekly, @monthly, @yearly.
Также можно использовать cron-выражения:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')Execution Date
Чтобы разобраться в том, как работает Airflow, важно понимать, что такое Execution Date для DAG’а. В Airflow DAG имеет измерение Execution Date, т. е. в зависимости от расписания работы DAG’а создаются экземпляры задачек на каждую Execution Date. И за каждую Execution Date задачи можно выполнить повторно — или, например, DAG может работать одновременно в нескольких Execution Date. Это наглядно отображено здесь:
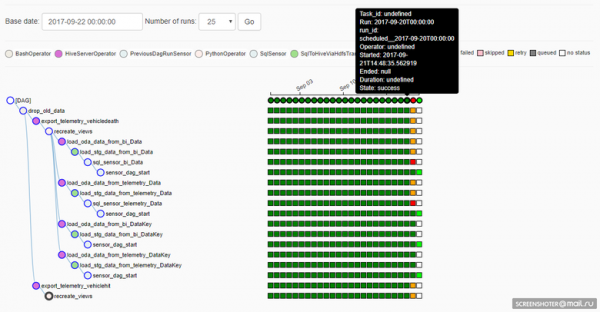
К сожалению (а может быть, и к счастью: зависит от ситуации), если правится реализация задачки в DAG’е, то выполнение в предыдущих Execution Date пойдет уже с учетом корректировок. Это хорошо, если нужно пересчитать данные в прошлых периодах новым алгоритмом, но плохо, потому что теряется воспроизводимость результата (конечно, никто не мешает вернуть из Git’а нужную версию исходника и разово посчитать то, что нужно, так, как нужно).
Генерация задач
Реализация DAG’а — код на Python, поэтому у нас есть очень удобный способ сократить объем кода при работе, например, с шардированными источниками. Пускай у вас в качестве источника три шарда MySQL, вам нужно слазить в каждый и забрать какие-то данные. Причем независимо и параллельно. Код на Python в DAG’е может выглядеть так:
connection_list = lv.get('connection_list')
export_profiles_sql = '''
SELECT
id,
user_id,
nickname,
gender,
{{params.shard_id}} as shard_id
FROM profiles
'''
for conn_id in connection_list:
export_profiles = SqlToHiveViaHdfsTransfer(
task_id='export_profiles_from_' + conn_id,
sql=export_profiles_sql,
hive_table='stg.profiles',
overwrite=False,
tmpdir='/data/tmp',
conn_id=conn_id,
params={'shard_id': conn_id[-1:], },
compress=None,
dag=dag
)
export_profiles.set_upstream(exec_truncate_stg)
export_profiles.set_downstream(load_profiles)DAG получается таким:
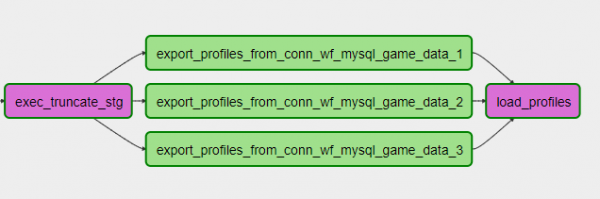
При этом можно добавить или убрать шард, просто скорректировав настройку и обновив DAG. Удобно!
Можно использовать и более сложную генерацию кода, например работать с источниками в виде БД или описывать табличную структуру, алгоритм работы с таблицей и с учетом особенностей инфраструктуры DWH генерировать процесс загрузки N таблиц к вам в хранилище. Или же, например, работу с API, которое не поддерживает работу с параметром в виде списка, вы можете сгенерировать по этому списку N задач в DAG’е, ограничить параллельность запросов в API пулом и выгрести из API необходимые данные. Гибко!
Repository
В Airflow есть свой бекенд-репозиторий, БД (может быть MySQL или Postgres, у нас Postgres), в которой хранятся состояния задач, DAG’ов, настройки соединений, глобальные переменные и т. д., и т. п. Здесь хотелось бы сказать, что репозиторий в Airflow очень простой (около 20 таблиц) и удобный, если вы хотите построить какой-либо свой процесс над ним. Вспоминается 100500 таблиц в репозитории Informatica, которые нужно было долго вкуривать, прежде чем понять, как построить запрос.
Monitoraggio
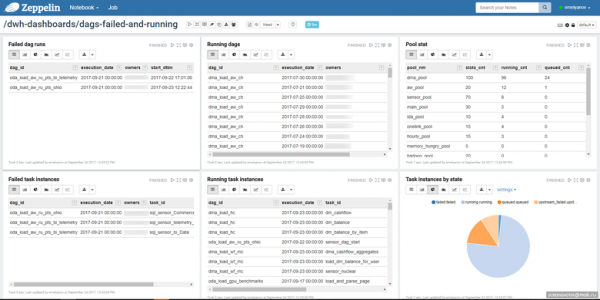
Учитывая простоту репозитория, вы можете сами построить удобный для вас процесс мониторинга задачек. Мы используем блокнот в Zeppelin, где смотрим состояние задач:
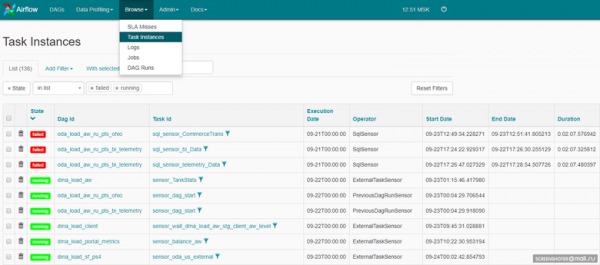
Это может быть и web-интерфейс самого Airflow:
Код Airflow открыт, поэтому мы у себя добавили алертинг в Telegram. Каждый работающий инстанс задачи, если происходит ошибка, спамит в группу в Telegram, где состоит вся команда разработки и поддержки.
Получаем через Telegram оперативное реагирование (если такое требуется), через Zeppelin — общую картину по задачам в Airflow.
Totale
Airflow в первую очередь open source, и не нужно ждать от него чудес. Будьте готовы потратить время и силы на то, чтобы выстроить работающее решение. Цель из разряда достижимых, поверьте, оно того стоит. Скорость разработки, гибкость, простота добавления новых процессов — вам понравится. Конечно, нужно уделять много внимания организации проекта, стабильности работы самого Airflow: чудес не бывает.
Сейчас у нас Airflow ежедневно отрабатывает около 6,5 тысячи задач. По характеру они достаточно разные. Есть задачи загрузки данных в основное DWH из множества разных и очень специфических источников, есть задачи расчета витрин внутри основного DWH, есть задачи публикации данных в быстрое DWH, есть много-много разных задач — и Airflow все их пережевывает день за днем. Если же говорить цифрами, то это 2,3 тысячи ELT задач различной сложности внутри DWH (Hadoop), около 2,5 сотен баз данных источников, это команда из 4-ёх ETL разработчиков, которые делятся на ETL процессинг данных в DWH и на ELT процессинг данных внутри DWH и конечно ещё одного админа, который занимается инфраструктурой сервиса.
Piani per il futuro
Количество процессов неизбежно растет, и основное, чем мы будем заниматься в части инфраструктуры Airflow, — это масштабирование. Мы хотим построить кластер Airflow, выделить пару ног для worker’ов Celery и сделать дублирующую себя голову с процессами планировки заданий и репозиторием.
Epilogo
Это, конечно, далеко не всё, что хотелось бы рассказать об Airflow, но основные моменты я постарался осветить. Аппетит приходит во время еды, попробуйте — и вам понравится 🙂
Fonte: habr.com
