

Di solito, per monitorare e analizzare il funzionamento di Nginx si utilizzano prodotti commerciali o alternative open-source pronte, come Prometheus + Grafana. Questa è una buona opzione per la sorveglianza o l'analisi in tempo reale, ma non è molto comoda per l'analisi storica. Su qualsiasi risorsa popolare, il volume dei dati dai log di Nginx cresce rapidamente, e per analizzare grandi volumi di dati è logico utilizzare qualcosa di più specializzato.
In questo articolo parlerò di come utilizzare per l'analisi dei log, prendendo come esempio Nginx, e mostrerò come raccogliere un dashboard analitico a partire da questi dati, utilizzando il framework open-source cube.js. Ecco l'architettura completa della soluzione:

TL:DR;
.
Per raccogliere informazioni utilizziamo , per l'elaborazione — e , per lo stoccaggio — . Con questo insieme è possibile memorizzare non solo i log di Nginx, ma anche altri eventi, così come i log di altri servizi. È possibile sostituire alcune parti con analoghe per il proprio stack, ad esempio, è possibile scrivere direttamente i log in Kinesis da Nginx, bypassando fluentd, o utilizzare Logstash per questo.
Raccogliamo i log di Nginx
Per impostazione predefinita, i log di Nginx appaiono in questo modo:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"È possibile analizzarli, ma è molto più semplice modificare la configurazione di Nginx per far sì che emetta i log in JSON:
log_format json_combined escape=json '{ "created_at": "$msec", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"request": "$request", '
'"status": $status, '
'"bytes_sent": $bytes_sent, '
'"request_length": $request_length, '
'"request_time": $request_time, '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_user_agent": "$http_user_agent" }';
access_log /var/log/nginx/access.log json_combined;S3 per l'archiviazione
Per memorizzare i log, utilizzeremo S3. Questo consente di archiviare e analizzare i log in un unico posto, poiché Athena può lavorare direttamente con i dati in S3. Nel seguito dell'articolo spiegherò come organizzare e processare i log, ma per prima cosa abbiamo bisogno di un bucket vuoto in S3, in cui non sarà memorizzato nient'altro. È utile pensare in anticipo a quale regione creerai il bucket, poiché Athena non è disponibile in tutte le regioni.
Creiamo uno schema nella console Athena
Creiamo una tabella in Athena per i log. È necessaria sia per la registrazione che per la lettura, se intendi utilizzare Kinesis Firehose. Apri la console Athena e crea la tabella:
SQL per la creazione della tabella
CREATE EXTERNAL TABLE `kinesis_logs_nginx`(
`created_at` double,
`remote_addr` string,
`remote_user` string,
`request` string,
`status` int,
`bytes_sent` int,
`request_length` int,
`request_time` double,
`http_referrer` string,
`http_x_forwarded_for` string,
`http_user_agent` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
's3://'
TBLPROPERTIES ('has_encrypted_data'='false');Creiamo un Kinesis Firehose Stream
Kinesis Firehose registrerà i dati ricevuti da Nginx in S3 nel formato scelto, organizzandoli in directory nel formato YYYY/MM/DD/HH. Questo sarà utile per la lettura dei dati. Certo, si può anche scrivere direttamente in S3 da fluentd, ma in tal caso dovrà essere scritto in JSON, il che non è efficiente a causa delle grandi dimensioni dei file. Inoltre, quando si utilizza PrestoDB o Athena, il JSON è il formato di dati più lento. Quindi apriamo la console Kinesis Firehose, clicchiamo su "Create delivery stream", e selezioniamo "direct PUT" nel campo "delivery":
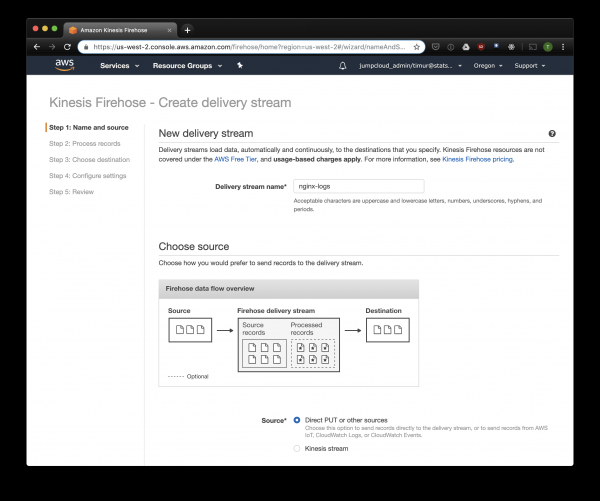
Nella scheda successiva selezioniamo "Record format conversion" — "Enabled" e scegliamo "Apache ORC" come formato di registrazione. Secondo alcune ricerche , questo è il formato ottimale per PrestoDB e Athena. Come schema, indichiamo la tabella che abbiamo creato in precedenza. Si noti che la posizione S3 in Kinesis può essere qualsiasi, poiché dalla tabella viene utilizzato solo lo schema. Ma se si indica una posizione S3 diversa, non sarà possibile leggere quelle registrazioni da questa tabella.
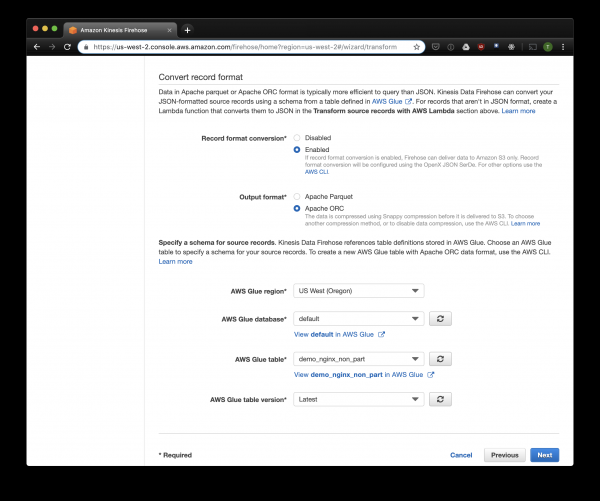
Selezioniamo S3 per lo storage e il bucket che abbiamo creato in precedenza. Aws Glue Crawler, di cui parlerò tra poco, non sa gestire i prefissi nel bucket S3, quindi è importante lasciarlo vuoto.
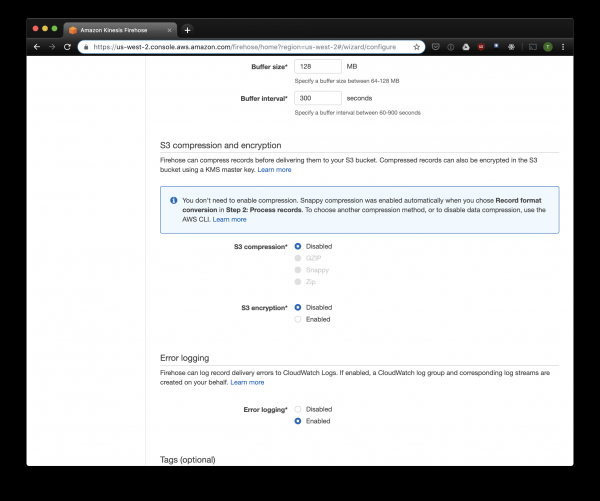
Le altre opzioni possono essere modificate a seconda del vostro carico, io di solito utilizzo quelle predefinite. Nota che la compressione S3 non è disponibile, ma ORC utilizza la propria compressione di default.
Fluentd
Adesso che abbiamo impostato la memorizzazione e il recupero dei log, dobbiamo configurare l'invio. Useremo , perché mi piace Ruby, ma puoi usare Logstash o inviare direttamente i log a Kinesis. Il server Fluentd può essere avviato in vari modi, parlerò di Docker perché è semplice e conveniente.
Per iniziare, abbiamo bisogno di un file di configurazione fluent.conf. Crealo e aggiungi il source:
forward
port 24224
bind 0.0.0.0
Adesso possiamo avviare il server Fluentd. Se hai bisogno di una configurazione più avanzata, su c'è una guida dettagliata, compresa quella su come costruire la tua immagine.
$ docker run
-d
-p 24224:24224
-p 24224:24224/udp
-v /data:/fluentd/log
-v :/fluentd/etc fluentd
-c /fluentd/etc/fluent.conf
fluent/fluentd:stableQuesta configurazione utilizza il percorso /fluentd/log per la memorizzazione dei log prima dell'invio. Puoi farne a meno, ma in quel caso potresti perdere tutto ciò che è stato memorizzato in cache dopo un riavvio. Puoi usare qualsiasi porta, 24224 è la porta predefinita di Fluentd.
Ora che abbiamo avviato Fluentd, possiamo inviare i log di Nginx. Di solito eseguiamo Nginx in un contenitore Docker, e in questo caso Docker ha un driver di log nativo per Fluentd:
$ docker run
--log-driver=fluentd
--log-opt fluentd-address=
--log-opt tag="{{.Name}}"
-v /some/content:/usr/share/nginx/html:ro
-d
nginxSe stai eseguendo Nginx in un altro modo, puoi utilizzare i log, in Fluentd c'è .
Aggiungiamo alla configurazione Fluent il parsing dei log configurato in precedenza:
@type parser
key_name log
emit_invalid_record_to_error false
@type jsonE inviare i log a Kinesis, utilizzando :
@type kinesis_firehose
region region
delivery_stream_name
aws_key_id
aws_sec_keyAthena
Se hai configurato tutto correttamente, dopo un po' (per impostazione predefinita Kinesis registra i dati ricevuti ogni 10 minuti) dovresti vedere i file di log in S3. Nel menu "monitoring" di Kinesis Firehose puoi vedere quanti dati sono stati registrati in S3 e anche eventuali errori. Non dimenticare di concedere accesso in scrittura al bucket S3 per il ruolo Kinesis. Se Kinesis non riesce a decifrare qualcosa, registrerà gli errori nello stesso bucket.
Ora puoi visualizzare i dati in Athena. Troviamo le query recenti per le quali abbiamo restituito errori:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;Scansione di tutte le registrazioni per ogni query
Ora i nostri log sono stati elaborati e archiviati in S3 in ORC, compressi e pronti per l'analisi. Kinesis Firehose li ha anche suddivisi in directory per ogni ora. Tuttavia, finché la tabella non è partizionata, Athena caricherà i dati di tutto il tempo per ogni query, salvo rare eccezioni. Questo è un problema significativo per due motivi:
- Il volume dei dati cresce costantemente, rallentando le query;
- Il costo di Athena è calcolato in base al volume di dati scansionati, con un minimo di 10 MB per ogni query.
Per risolvere questo problema, utilizziamo AWS Glue Crawler, che scansionerà i dati in S3 e registrerà le informazioni sulle partizioni nel Glue Metastore. Questo ci permetterà di utilizzare le partizioni come filtro durante le query in Athena, scansionando solo le directory specificate nella query.
Configuriamo Amazon Glue Crawler
Amazon Glue Crawler scans all data in the S3 bucket and creates tables with partitions. Create a Glue Crawler from the AWS Glue console and add the bucket where you store your data. You can use one crawler for multiple buckets; in this case, it will create tables in the specified database with names matching the bucket names. If you plan to use this data regularly, be sure to set up a schedule for the crawler according to your needs. We use one crawler for all tables, which runs every hour.
Tabelle partizionate
After the crawler's first run in the database specified in the settings, tables for each scanned bucket should appear. Open the Athena console and look for the table with Nginx logs. Let's try to read something:
SELECT * FROM "default"."part_demo_kinesis_bucket"
WHERE(
partition_0 = '2019' AND
partition_1 = '04' AND
partition_2 = '08' AND
partition_3 = '06'
);This query will select all records received from 6 to 7 AM on April 8, 2019. But how much more efficient is this compared to simply reading from a non-partitioned table? Let's find out and select the same records, filtering them by timestamp:

3.59 secondi e 244.34 megabyte di dati su un dataset con solo una settimana di log. Proviamo un filtro per partizioni:
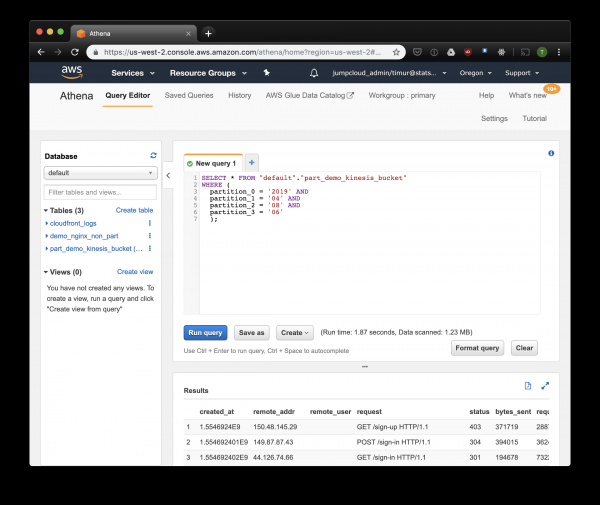
Un po' più veloce, ma la cosa più importante è che si tratta di soli 1.23 megabyte di dati! Sarebbe stato molto più economico se non ci fosse il minimo di 10 megabyte per richiesta nel pricing. Ma è comunque molto meglio, e su dataset più grandi la differenza sarà decisamente più impressionante.
Собираем дэшборд с помощью Cube.js
Per costruire il dashboard, utilizziamo il framework analitico Cube.js. Ha abbastanza funzioni, ma a noi interessano due: la possibilità di utilizzare automaticamente i filtri per partizioni e la pre-aggregazione dei dati. Utilizza uno schema dati , scritto in Javascript, per generare SQL ed eseguire la query sul database. Dobbiamo solo specificare come utilizzare il filtro per partizioni nello schema dati.
Creiamo una nuova applicazione Cube.js. Poiché stiamo già utilizzando lo stack AWS, è logico usare Lambda per il deploy. Puoi utilizzare il template express per generare, se intendi ospitare il backend di Cube.js su Heroku o Docker. La documentazione descrive altri .
$ npm install -g cubejs-cli
$ cubejs create nginx-log-analytics -t serverless -d athenaPer configurare l'accesso al database in cube.js, si utilizzano le variabili d'ambiente. Il generatore creerà un file .env dove puoi specificare le tue chiavi per .
Ora avremo bisogno di , in cui indicheremo come vengono memorizzati i nostri log. Qui è possibile anche specificare come calcolare le metriche per i dashboard.
Nella directory schema, crea un file Logs.js. Ecco un esempio di modello di dati per nginx:
Codice del modello
const partitionFilter = (from, to) => `
date(from_iso8601_timestamp(${from})) = date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d')
`
cube(`Logs`, {
sql: `
select * from part_demo_kinesis_bucket
WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)}
`,
measures: {
count: {
type: `count`,
},
errorCount: {
type: `count`,
filters: [
{ sql: `${CUBE.isError} = 'Yes'` }
]
},
errorRate: {
type: `number`,
sql: `100.0 * ${errorCount} / ${count}`,
format: `percent`
}
},
dimensions: {
status: {
sql: `status`,
type: `number`
},
isError: {
type: `string`,
case: {
when: [{
sql: `${CUBE}.status >= 400`, label: `Yes`
}],
else: { label: `No` }
}
},
createdAt: {
sql: `from_unixtime(created_at)`,
type: `time`
}
}
});Qui utilizziamo la variabile , per generare una query SQL con filtro sulle partizioni.
Impostiamo anche le metriche e i parametri che vogliamo visualizzare nel dashboard e definiamo le pre-aggregazioni. Cube.js creerà tabelle aggiuntive con dati pre-aggregati e aggiornerà automaticamente i dati man mano che arrivano. Questo non solo accelera le query, ma riduce anche i costi di utilizzo di Athena.
Aggiungiamo queste informazioni al file dello schema dei dati:
preAggregations: {
main: {
type: `rollup`,
measureReferences: [count, errorCount],
dimensionReferences: [isError, status],
timeDimensionReference: createdAt,
granularity: `day`,
partitionGranularity: `month`,
refreshKey: {
sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) =>
`select
CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now()
THEN date_trunc('hour', now()) END`
)
}
}
}Specifichiamo in questo modello che è necessario pre-aggregare i dati per tutte le metriche utilizzate e utilizzare il partizionamento per mesi. può accelerare significativamente la raccolta e l'aggiornamento dei dati.
Ora possiamo costruire il dashboard!
Il backend di Cube.js fornisce e un set di librerie client per i popolari framework frontend. Utilizzeremo la versione React del client per costruire il dashboard. Cube.js fornisce solo i dati, quindi avremo bisogno di una libreria per le visualizzazioni — a me piace , ma puoi usare qualsiasi altra.
Il server Cube.js accetta richieste in , in cui sono specifiche le metriche necessarie. Ad esempio, per calcolare quante errori ha restituito Nginx per giorno, è necessario inviare una richiesta del tipo:
{
"measures": ["Logs.errorCount"],
"timeDimensions": [
{
"dimension": "Logs.createdAt",
"dateRange": ["2019-01-01", "2019-01-07"],
"granularity": "day"
}
]
}Installeremo il client Cube.js e la libreria dei componenti React tramite NPM:
$ npm i --save @cubejs-client/core @cubejs-client/reactImportiamo i componenti cubejs e QueryRenderer, per caricare i dati, e costruiamo il dashboard:
Il codice del dashboard
import React from 'react';
import { LineChart, Line, XAxis, YAxis } from 'recharts';
import cubejs from '@cubejs-client/core';
import { QueryRenderer } from '@cubejs-client/react';
const cubejsApi = cubejs(
'YOUR-CUBEJS-API-TOKEN',
{ apiUrl: 'http://localhost:4000/cubejs-api/v1' },
);
export default () => {
return (
{
if (!resultSet) {
return 'Loading...';
}
return (
);
}}
/>
)
}I sorgenti del dashboard sono disponibili su .
Fonte: habr.com
