


Se gestisci un'infrastruttura virtuale basata su VMware vSphere (o su un altro stack tecnologico), sicuramente ricevi frequentemente dai tuoi utenti lamentele come: «La macchina virtuale è lenta!». In questo ciclo di articoli analizzerò le metriche di prestazione e spiegherò cosa e perché «rallenta» e come fare affinché non «rallenti».
Esaminerò i seguenti aspetti delle prestazioni delle macchine virtuali:
- CPU,
- RAM,
- DISK,
- Rete.
Iniziamo dalla CPU.
Per analizzare le prestazioni abbiamo bisogno di:
- vCenter Performance Counters – contatori di prestazione, i cui grafici possono essere visualizzati tramite vSphere Client. Le informazioni su questi contatori sono disponibili in qualsiasi versione del client (il client “fat” in C#, il client web in Flex e il client web in HTML5). In questi articoli utilizzeremo schermate del client C# solo perché presentano una resa migliore in miniatura :)
- ESXTOP – uno strumento che viene eseguito dalla riga di comando di ESXi. Con esso, è possibile ottenere i valori dei contatori delle prestazioni in tempo reale o esportarli per un determinato periodo in un file .csv per analisi successive. Di seguito parlerò di questo strumento in modo più dettagliato e fornirò alcuni link utili alla documentazione e ad articoli sull'argomento.
Un po' di teoria
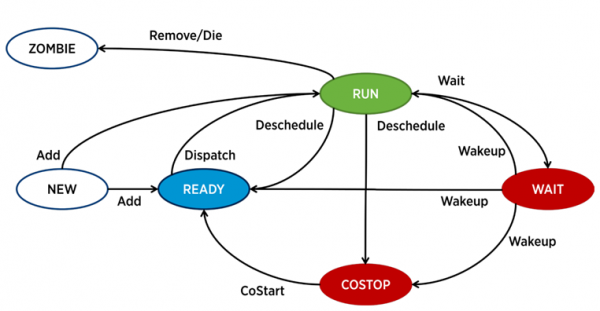
In ESXi, ogni vCPU (core della macchina virtuale) è gestito da un processo separato – chiamato world nella terminologia VMware. Ci sono anche processi di servizio, ma in termini di analisi delle prestazioni delle VM, sono meno interessanti.
Un processo in ESXi può trovarsi in uno dei quattro stati:
- Esegui – il processo sta eseguendo un lavoro utile.
- Attendere – il processo non sta eseguendo alcun lavoro (idle) oppure sta aspettando input/output.
- Costop – uno stato che si verifica nelle macchine virtuali multi-core. Si manifesta quando lo scheduler CPU dell'iperparallore (ESXi CPU Scheduler) non riesce a pianificare l'esecuzione simultanea di tutti i core attivi della macchina virtuale sui core fisici del server. Nel mondo fisico, tutti i core della CPU operano in parallelo, e il sistema operativo guest all'interno della VM si aspetta un comportamento analogo; pertanto, l'iperparallore deve rallentare i core della VM che hanno la possibilità di completare il ciclo più rapidamente. Nelle versioni moderne di ESXi, lo scheduler CPU utilizza un meccanismo chiamato co-scheduling rilassato: l'iperparallore calcola la differenza tra il core della VM "più veloce" e quello "più lento" (skew). Se la differenza supera una certa soglia, il core "veloce" entra nello stato di costop. Se i core della VM trascorrono molto tempo in questo stato, ciò può causare problemi di prestazioni.
- Pronto – un processo entra in questo stato quando l'iperparallore non è in grado di allocare risorse per la sua esecuzione. Valori elevati di ready possono causare problemi di prestazioni nella VM.
Contatori principali delle prestazioni della CPU della macchina virtuale
Utilizzo della CPU, % Mostra la percentuale di utilizzo della CPU per un periodo specificato.
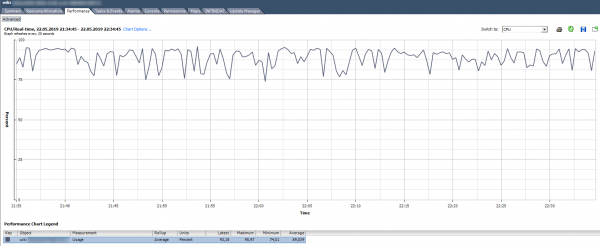
Come analizzare? Se la VM utilizza stabilmente la CPU al 90% o ci sono picchi fino al 100%, abbiamo un problema. I problemi possono manifestarsi non solo in una prestazione 'lenta' dell'applicazione all'interno della VM, ma anche nella sua accessibilità tramite rete. Se il sistema di monitoraggio mostra che la VM si disconnette periodicamente, presta attenzione ai picchi nel grafico di utilizzo della CPU.
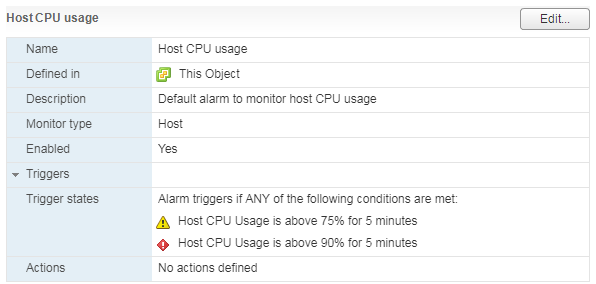
C'è un allarme standard che mostra il caricamento della CPU della macchina virtuale:

Cosa fare? Se l'utilizzo della CPU della VM è costantemente alle stelle, si può considerare di aumentare il numero di vCPU (sfortunatamente, ciò non aiuta sempre) o di spostare la VM su un server con processori più performanti.
Utilizzo della CPU in MHz
Nei grafici di utilizzo su vCenter in % si può vedere solo per l'intera macchina virtuale, non ci sono grafici per singoli core (in Esxtop sono disponibili valori in % per i core). Per ogni core si può vedere l'utilizzo in MHz.
Come analizzare? Può capitare che l'applicazione non sia ottimizzata per un'architettura multicore: utilizza al 100% solo un core, mentre gli altri rimangono inattivi. Ad esempio, con le impostazioni di default, il backup di MS SQL avvia il processo solo su un core. Di conseguenza, il backup è lento non a causa della bassa velocità dei dischi (è proprio su questo che si è lamentato l'utente), ma perché il processore non riesce a gestirlo. Il problema è stato risolto modificando le impostazioni: il backup ora viene eseguito in parallelo su più file (di conseguenza, in più processi).
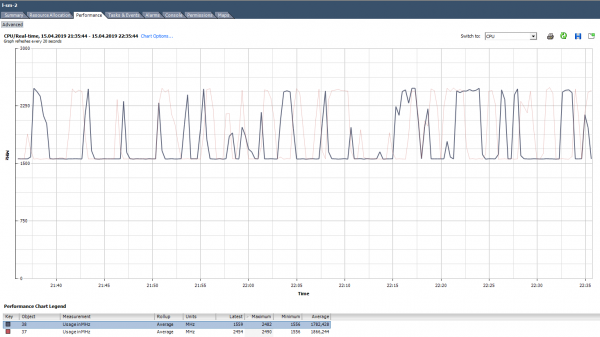
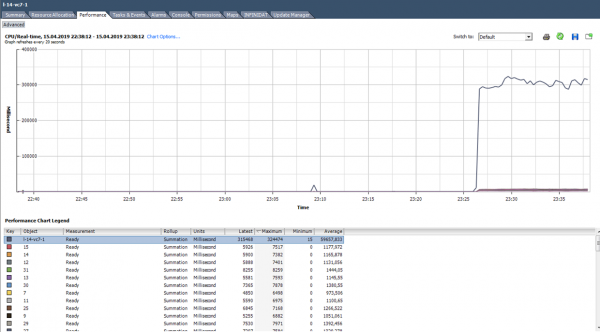
Esempio di carico non uniforme dei core.
Può anche verificarsi una situazione (come nel grafico sopra) in cui i core sono caricati in modo non uniforme e alcuni di essi presentano picchi al 100%. Come nel caso del carico su un solo core, l'allerta per l'uso della CPU non si attiverà (è su tutta la VM), ma ci saranno problemi di prestazioni.
Cosa fare? Se il software nella macchina virtuale sovraccarica i core in modo non uniforme (utilizza solo un core o alcuni core), non ha senso aumentarne il numero. In tal caso, è meglio spostare la VM su un server con processori più potenti.
Si può anche provare a controllare le impostazioni di risparmio energetico nel BIOS del server. Molti amministratori abilitano la modalità High Performance nel BIOS, disattivando così le tecnologie di risparmio energetico C-states e P-states. Nei moderni processori Intel viene utilizzata la tecnologia Turbo Boost, che aumenta la frequenza di alcuni core del processore a spese di altri core. Tuttavia, ciò funziona solo quando sono attive le tecnologie di risparmio energetico. Se le disattiviamo, il processore non può diminuire il consumo energetico dei core non utilizzati.
VMware consiglia di non disattivare le tecnologie di risparmio energetico sui server, ma di scegliere modalità che massimizzino il controllo del risparmio energetico al hypervisor. Nelle impostazioni di risparmio energetico del hypervisor, è necessario selezionare High Performance.
Se nella vostra infrastruttura ci sono VM separate (o core VM) che richiedono una maggiore frequenza della CPU, una corretta configurazione del risparmio energetico può migliorare significativamente le loro prestazioni.
CPU Ready (Readiness)
Se il core della VM (vCPU) è in stato Ready, non sta svolgendo lavoro utile. Questo stato si verifica quando l'ipervisore non riesce a trovare un core fisico libero su cui assegnare il processo vCPU della macchina virtuale.
Come analizzare? In generale, se i core della macchina virtuale sono in stato Ready per oltre il 10% del tempo, noterai problemi di prestazioni. In parole semplici, se una VM è in attesa di risorse fisiche per più del 10% del tempo.
In vCenter puoi visualizzare due contatori relativi al CPU Ready:
- Readiness,
- Ready.
I valori di entrambi i contatori possono essere visualizzati sia per l'intera VM che per i singoli core.
Readiness mostra il valore immediatamente in percentuale, ma solo in tempo reale (dati dell'ultima ora, intervallo di misurazione di 20 secondi). Questo contatore è meglio utilizzarlo solo per identificare problemi "in tempo reale".
I valori del contatore Ready possono essere visualizzati anche in una prospettiva storica. Questo è utile per identificare schemi e per un'analisi più approfondita del problema. Ad esempio, se una macchina virtuale inizia a riscontrare problemi di prestazioni in un momento specifico, è possibile confrontare gli intervalli di valore elevato del CPU Ready con il carico totale sul server in cui questa VM opera e prendere misure per ridurre il carico (se DRS non è riuscito).
A differenza del Readiness, il Ready non è mostrato in percentuale, ma in millisecondi. Questo è un contatore di tipo Summation, il che significa che mostra quanto tempo il core della VM è stato in stato di Ready durante il periodo di misurazione. È possibile convertire questo valore in percentuale mediante una semplice formula:
(valore di sommazione del CPU ready / (intervallo di aggiornamento predefinito del grafico in secondi * 1000)) * 100 = % CPU ready
Ad esempio, per la VM nel grafico qui sotto, il valore di picco del Ready per l'intera macchina virtuale risulterà come segue:

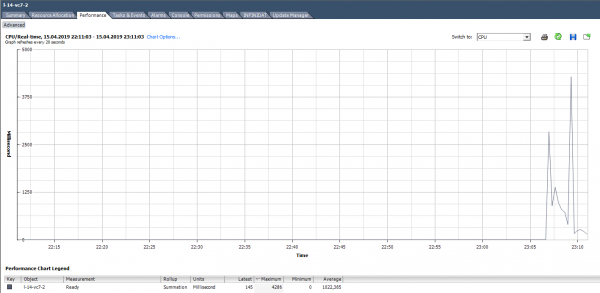
Nel calcolare il valore di Ready in percentuale, è importante prestare attenzione a due aspetti:
- Il valore Ready per l'intera VM è la somma dei Ready dei core.
- Intervallo di misurazione. Per il Real-time – è di 20 secondi, mentre, ad esempio, nei grafici giornalieri – è di 300 secondi.
Durante la risoluzione dei problemi, è facile trascurare questi dettagli e sprecare tempo prezioso a cercare soluzioni per questioni inesistenti.
Calcoliamo il valore di Ready basandoci sui dati riportati nel grafico qui sotto. (324474/(20*1000))*100 = 1622% per l'intera VM. Se consideriamo i core, la situazione appare meno allarmante: 1622/64 = 25% per core. In questo caso, è abbastanza semplice identificare l'anomalia: un valore di Ready così alto è irrealistico. Tuttavia, se si parla di un valore compreso tra il 10% e il 20% per l'intera VM con più core, i valori per singolo core potrebbero essere normali.
Cosa fare? Un valore elevato di Ready indica che il server ha carenza di risorse CPU per garantire il corretto funzionamento delle macchine virtuali. In tal caso, l'unica soluzione è ridurre l'overcommitting della CPU (vCPU:pCPU). È evidente che questo può essere realizzato diminuendo le allocazioni delle VM esistenti o migrando alcune VM su altri server.
Co-stop
Come analizzare? Questo contatore ha anche un tipo di Summation e viene tradotto in percentuali allo stesso modo di Ready:
(valore di somma co-stop CPU / (intervallo di aggiornamento predefinito del grafico in secondi * 1000)) * 100 = % co-stop CPU
In questo caso, è importante prestare attenzione al numero di core sulla VM e all'intervallo di misurazione.
In idle state, co-stop does not perform useful work. With the proper VM size and normal server load, the co-stop counter should be close to zero.
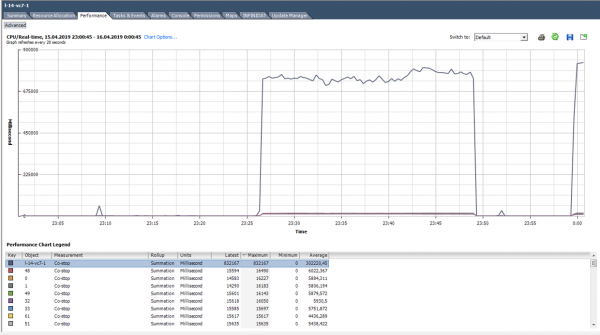
In this case, the load is clearly abnormal:)
Cosa fare? If several VMs with a large number of cores are running on a single hypervisor and there is CPU oversubscription, the co-stop counter may increase, leading to performance issues for those VMs.
Additionally, co-stop will increase if active cores of one VM utilize threads on the same physical core of the server with hyper-threading enabled. This situation can occur, for example, if a VM has more cores than are physically available on the server it operates on, or if the 'preferHT' setting is enabled for the VM. More information on this setting can be found. .
To avoid performance issues in a VM due to high co-stop, select the VM size according to the recommendations of the software provider that operates on this VM, and based on the capabilities of the physical server where the VM is running.
Do not add cores as a reserve, as this can cause performance problems not only for the VM itself but also for its neighboring VMs on the server.
Other useful CPU metrics
Esegui – quanto tempo (ms) nel periodo di misurazione il vCPU è stato in stato di RUN, cioè ha effettivamente svolto lavoro utile.
Idle – quanto tempo (ms) nel periodo di misurazione il vCPU è stato in stato di inattività. Valori elevati di Idle non sono un problema, semplicemente il vCPU non aveva 'nulla da fare'.
Attendere – quanto tempo (ms) nel periodo di misurazione il vCPU è stato in stato di Wait. Poiché in questo contatore è incluso IDLE, valori elevati di Wait non indicano necessariamente un problema. Tuttavia, se durante un elevato Wait l'IDLE è basso, significa che la VM stava aspettando il completamento delle operazioni di input/output, il che potrebbe segnalare un problema con le prestazioni del disco rigido o di qualche dispositivo virtuale della VM.
Massimo limitato – quanto tempo (ms) nel periodo di misurazione il vCPU è stato in stato di Ready a causa di un limite di risorse impostato. Se le prestazioni sono inspiegabilmente basse, è utile controllare il valore di questo contatore e il limite della CPU nelle impostazioni della VM. Potrebbero esserci limiti impostati nella VM di cui non sei a conoscenza. Ad esempio, ciò accade quando la VM è stata clonata da un modello in cui era stato impostato un limite di CPU.
Attesa dello swap – quanto tempo ha atteso un'operazione con VMkernel Swap per il periodo di misurazione vCPU. Se i valori di questo contatore sono superiori a zero, allora la VM ha sicuramente problemi di prestazioni. Parleremo di SWAP nell'articolo sui contatori della memoria.
ESXTOP
Se i contatori delle prestazioni in vCenter sono utili per l'analisi dei dati storici, l'analisi rapida dei problemi è meglio eseguirla in ESXTOP. Qui tutti i valori sono presentati in un formato pronto all'uso (non è necessario tradurre nulla), e il periodo minimo di misurazione è di 2 secondi.
Lo schermo ESXTOP per la CPU viene attivato premendo il tasto «c» e appare come segue:

Per comodità, puoi mostrare solo i processi delle macchine virtuali premendo Shift-V.
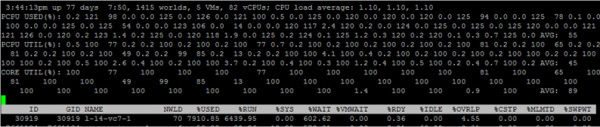
Per visualizzare le metriche dei singoli core della VM, premi «e» e inserisci il GID della VM di interesse (30919 nello screenshot qui sotto):
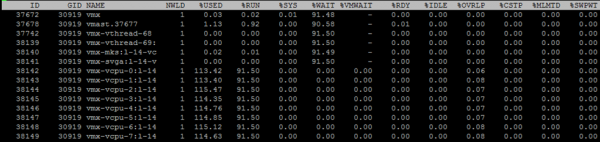
Farò una breve panoramica delle colonne che sono presentate per impostazione predefinita. È possibile aggiungere colonne aggiuntive premendo «f».
NWLD (Numero di Mondi) – numero di processi nel gruppo. Per espandere il gruppo e vedere le metriche per ogni processo (ad esempio, per ogni nucleo di una VM multicore), premi “e”. Se ci sono più di un processo nel gruppo, i valori delle metriche per il gruppo sono uguali alla somma delle metriche per i singoli processi.
%USATO – quante cicli CPU del server utilizza un processo o un gruppo di processi.
%RUN – quanto tempo durante il periodo di misurazione il processo è stato in stato RUN, cioè ha eseguito lavoro utile. Si differenzia da %USATO in quanto non tiene conto dell'hyper-threading, della scalabilità della frequenza e del tempo speso per compiti di sistema (%SYS).
%SYS – tempo speso per compiti di sistema, ad esempio: gestione delle interruzioni, input/output, attività di rete, ecc. Il valore può essere alto se la VM ha un elevato input/output.
%OVRLP – quanto tempo il nucleo fisico su cui viene eseguito il processo VM ha speso per compiti di altri processi.
Queste metriche sono correlate tra loro nel seguente modo:
%USATO = %RUN + %SYS — %OVRLP.
In genere, la metrica %USATO è più informativa.
%ATTESA – quanto tempo durante il periodo di misurazione il processo è stato in stato di Attesa. Include IDLE.
%IDLE – tempo totale in cui il processo è stato in stato IDLE durante il periodo di misurazione.
%SWPWT – tempo totale in cui il vCPU ha atteso operazioni con il VMkernel Swap durante il periodo di misurazione.
%VMWAIT – tempo totale in cui il vCPU è stato in stato di attesa di un evento (solitamente I/O) durante il periodo di misurazione. Non esiste un contatore equivalente in vCenter. Valori elevati indicano problemi di I/O sulla VM.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Se la VM non utilizza il VMkernel Swap, è utile esaminare %VMWAIT quando si analizzano i problemi di prestazioni, poiché questa metrica non considera il tempo in cui la VM non ha fatto nulla (%IDLE).
%RDY – tempo totale in cui il processo è stato in stato Ready durante il periodo di misurazione.
%CSTP – tempo totale in cui il processo è stato in stato costop durante il periodo di misurazione.
%MLMTD – tempo totale in cui il vCPU è stato in stato Ready a causa di un limite imposto sulle risorse durante il periodo di misurazione.
%WAIT + %RDY + %CSTP + %RUN = 100% – il core della VM è sempre in uno di questi quattro stati.
CPU sull'iper-vizor
In vCenter ci sono anche contatori di prestazioni CPU per l'iper-vizor, ma non presentano nulla di interessante: sono semplicemente la somma dei contatori di tutte le VM sul server.
È più comodo controllare lo stato della CPU del server nella scheda Riepilogo:

Per il server, come per la macchina virtuale, esiste una soglia di allerta standard:
Con un alto carico sulla CPU del server, le VM in esecuzione su di esso iniziano a riscontrare problemi di performance.
In ESXTOP i dati sul carico della CPU del server sono presentati nella parte superiore dello schermo. Oltre al carico standard della CPU, che è poco informativo per gli hypervisor, ci sono altre tre metriche:
CORE UTIL(%) – utilizzo del core del server fisico. Questo contatore mostra quanto tempo, durante il periodo di misurazione, il core ha eseguito lavoro.
PCPU UTIL(%) – se l'hyper-threading è attivato, ad ogni core fisico corrispondono due thread (PCPU). Questa metrica mostra quanto tempo ogni thread ha eseguito lavoro.
PCPU USED(%) – è lo stesso di PCPU UTIL(%), ma tiene conto dello scaling della frequenza (sia la riduzione della frequenza del core per risparmiare energia, sia l'aumento della frequenza del core grazie alla tecnologia Turbo Boost) e dell'hyper-threading.
PCPU_USED% = PCPU_UTIL% * frequenza effettiva del core / frequenza nominale del core.
In questo screenshot, per alcuni core, a causa del funzionamento del Turbo Boost, il valore USED supera il 100%, poiché la frequenza del core è superiore a quella nominale.
Una breve introduzione su come viene considerato l'hyper-threading. Se i processi vengono eseguiti al 100% del tempo su entrambi i thread di un core fisico del server, e il core funziona alla frequenza nominale, allora:
- L'UTIL CORE per il core sarà del 100%,
- L'UTIL PCPU per entrambi i thread sarà del 100%,
- Il PCPU USED per entrambi i thread sarà del 50%.
Se entrambi i thread non hanno lavorato al 100% del tempo durante il periodo di misurazione, in quei periodi in cui i thread hanno lavorato in parallelo, il PCPU USED per i core viene diviso per due.
In ESXTOP c'è anche uno schermo con i parametri di consumo energetico della CPU del server. Qui puoi controllare se il server utilizza tecnologie di risparmio energetico: C-states e P-states. Si attiva premendo il tasto «p»:

Problemi di prestazioni standard della CPU
Infine, passerò in rassegna le cause tipiche dei problemi di prestazioni della CPU delle VM e fornirò brevi suggerimenti per risolverli:
Mancanza di frequenza del core. Se non è possibile trasferire la VM a core più performanti, si può provare a modificare le impostazioni di risparmio energetico affinché il Turbo Boost funzioni in modo più efficace.
Dimensionamento errato della VM (troppi/pochi core). Se si utilizzano pochi core, si avrà un'elevata carico sulla CPU della VM. Se troppi, si rischia un alto co-stop.
Elevata sovracapacità della CPU sul server. Se la VM ha un alto Ready, riduci la sovracapacità della CPU.
Topologia NUMA errata su grandi VM. La topologia NUMA vista dalla VM (vNUMA) deve corrispondere alla topologia NUMA del server (pNUMA). La diagnosi e le possibili soluzioni a questo problema sono descritte, ad esempio, nel libro . Se non vuoi approfondire e non hai limitazioni di licenza sul sistema operativo installato sulla VM, utilizza sulla VM molti socket virtuali con un solo core. Non perderai molto 🙂
Per quanto riguarda la CPU, ho finito. Fai domande. Nella prossima parte parlerò della memoria RAM.
Link utili
Fonte: habr.com
