

Un sistema per l'analisi del traffico senza la sua decrittazione. Questo metodo è semplicemente chiamato 'apprendimento automatico'. È emerso che, se si alimenta un classificatore speciale con un grande volume di traffico vario, il sistema può rilevare con un'alta probabilità le attività di codice dannoso all'interno del traffico crittografato.

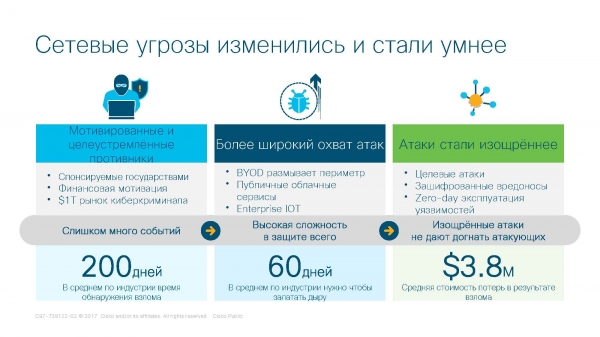
Le minacce informatiche sono cambiate e sono diventate 'più intelligenti'. Recentemente è cambiata la stessa concezione di attacco e difesa. Il numero di eventi in rete è aumentato drasticamente. Gli attacchi sono diventati più complessi e i criminali informatici hanno un raggio d'azione più ampio.
Secondo le statistiche di Cisco, nel corso dell'ultimo anno i criminali hanno triplicato il numero di malware utilizzati per le loro attività, in particolare per la loro occultazione — la crittografia. Teoricamente, un 'corretto' algoritmo di crittografia non può essere violato. Per capire cosa si nasconde all'interno del traffico crittografato, è necessario decrittarlo conoscendo la chiave, tentare di decifrarlo con vari trucchi, o attaccarlo frontalmente, oppure sfruttare delle vulnerabilità nei protocolli crittografici.
Il quadro delle minacce informatiche del nostro tempo
Machine Learning
Conosci la tecnologia a menadito! Prima di discutere di come funziona la tecnologia di decodifica basata sull'apprendimento automatico, è necessario esaminare come funziona la tecnologia delle reti neurali.
L'apprendimento automatico (Machine Learning) è un ampio sottoinsieme dell'intelligenza artificiale che studia i metodi per costruire algoritmi in grado di apprendere. Questa disciplina si concentra sulla creazione di modelli matematici di 'apprendimento' per il computer. L'obiettivo dell'apprendimento è fare previsioni su qualcosa. Nel linguaggio umano, chiamiamo questo processo «saggezza». La saggezza si manifesta nelle persone che hanno vissuto abbastanza a lungo (un bambino di 2 anni non può essere saggio). Quando ci rivolgiamo a persone più esperte per ricevere consigli, forniamo loro alcune informazioni sull'evento (dati in ingresso) e chiediamo aiuto. Loro, a loro volta, ricordano tutte le situazioni della vita che in qualche modo sono collegate al tuo problema (base di conoscenze) e, sulla base di queste conoscenze (dati), ci forniscono, in un certo senso, una predizione (consiglio). Questo tipo di consigli è stato chiamato predizione perché la persona che dà il consiglio non sa con certezza cosa accadrà, ma solo suppone. L'esperienza di vita dimostra che una persona può avere ragione, ma può anche sbagliarsi.
Non bisognerebbe confrontare le reti neurali con l'algoritmo di branching (if-else). Si tratta di cose diverse e hanno differenze fondamentali. L'algoritmo di branching ha una chiara "comprensione" di cosa fare. Lo dimostrerò con degli esempi.
Compito. Determinare la distanza di frenata di un'automobile in base alla sua marca e all'anno di produzione.
Esempio di funzionamento dell'algoritmo di branching. Se l'automobile è del marchio 1 e prodotta nel 2012, la sua distanza di frenata è di 10 metri, altrimenti, se l'automobile è del marchio 2 e prodotta nel 2011 e così via.
Esempio di funzionamento di una rete neurale. Raccogliamo dati sui percorsi di frenata delle automobili degli ultimi 20 anni. Creiamo una tabella del tipo "marca-anno di produzione-percorso di frenata" in base alla marca e all'anno. Forniamo questa tabella alla rete neurale e iniziamo a insegnarle. L'addestramento avviene nel seguente modo: fornendo dati alla rete neurale, ma senza il percorso di frenata. La rete neurale cerca di prevedere quale sarà il percorso di frenata, sulla base della tabella caricata. Fa una previsione e pone la domanda all'utente: "Ho ragione?". Prima della domanda, crea una quarta colonna - la colonna delle previsioni. Se ha ragione, inserisce 1 nella quarta colonna, se sbaglia, 0. La rete neurale passa quindi al prossimo evento (anche se ha sbagliato). Così la rete impara e quando l'addestramento è completo (raggiunto un certo criterio di convergenza), forniamo i dati dell'automobile di nostro interesse e alla fine otteniamo una risposta.
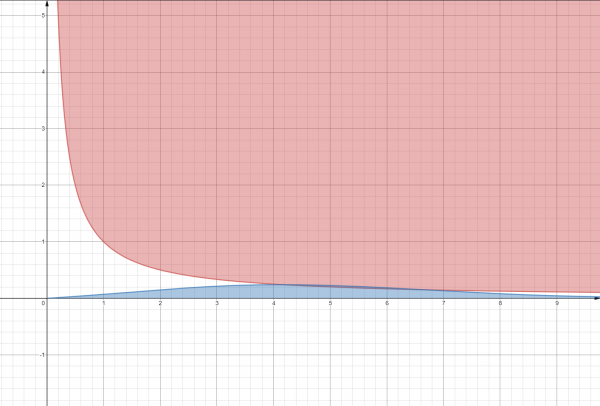
Per chiarire la questione del criterio di convergenza, spiego che si tratta di una formula matematicamente derivata per la statistica. Un esempio lampante di 2 diverse formule di convergenza. La rossa rappresenta la convergenza binaria, la blu rappresenta la convergenza normale.
Distribuzioni binomiale e normale della probabilità
Per chiarire, poniti la domanda: «Qual è la probabilità di incontrare un dinosauro?» Ci sono 2 possibili risposte. Risposta 1 – molto bassa (grafico blu). Risposta 2 – o incontro, o non incontro (grafico rosso).
Certo, il computer non è un essere umano e apprende in modo diverso. Si distinguono 2 tipi di apprendimento per la macchina: apprendimento per casi e apprendimento deduttivo.
L'apprendimento per casi è un metodo di apprendimento basato su leggi matematiche. I matematici raccolgono tabelle statistiche, traggono conclusioni e caricano nella rete neurale il risultato – una formula per il calcolo.
L'apprendimento deduttivo avviene interamente nella rete neurale (dalla raccolta dei dati fino alla loro analisi). Qui si forma una tabella senza formula, ma con statistica.
Una panoramica dettagliata della tecnologia richiederebbe altre decine di articoli. Per ora, questo è sufficiente per una comprensione generale.
Neuroplasticità
In biologia c'è un concetto chiamato neuroplasticità. La neuroplasticità è la capacità dei neuroni (cellule cerebrali) di agire "in base alla situazione". Ad esempio, una persona che ha perso la vista sente meglio i suoni, percepisce gli odori e tocca gli oggetti. Questo avviene perché una parte del cervello (una parte dei neuroni) dedicata alla vista ridistribuisce le sue funzioni su altre abilità.
Un esempio chiaro di neuroplasticità nella vita è il lecca-lecca BrainPort.
Nel 2009, l'Università del Wisconsin-Madison ha annunciato l'uscita di un nuovo dispositivo che sviluppa le idee del "display linguistico", chiamato BrainPort. BrainPort funziona secondo un algoritmo: il segnale video viene inviato da una telecamera a un processore, che gestisce lo zoom, la luminosità e altri parametri dell'immagine. Trasforma inoltre segnali digitali in impulsi elettrici, assumendo di fatto le funzioni della retina.
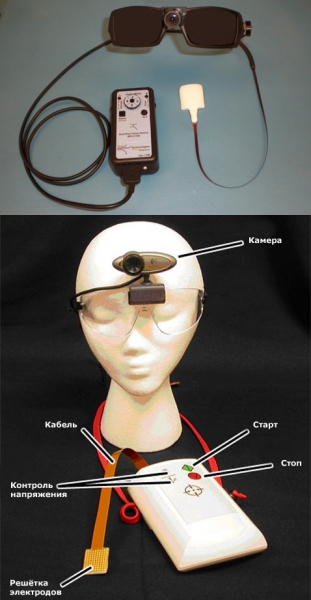
Lecca-lecca BrainPort con occhiali e telecamera

BrainPort in azione

Lo stesso vale per i computer. Se la rete neurale percepisce un cambiamento nel processo, si adatta ad esso. Questo è il vantaggio chiave delle reti neurali rispetto ad altri algoritmi: l'autonomia. Una sorta di umanità.
Analisi del Traffico Crittografato
L'Analisi del Traffico Crittografato fa parte del sistema Stealthwatch. Stealthwatch è una soluzione sviluppata da Cisco nel settore del monitoraggio e dell'analisi della sicurezza, che utilizza i dati di telemetria aziendale provenienti dall'infrastruttura di rete esistente.
La base di Stealthwatch Enterprise è costituita dagli strumenti Flow Rate License, Flow Collector, Management Console e Flow Sensor.
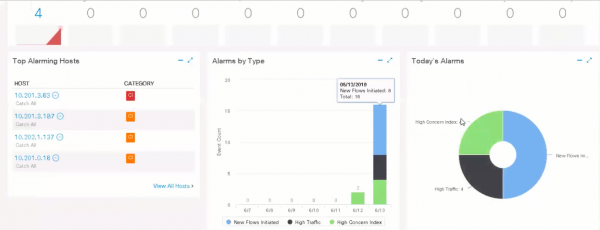
Interfaccia Cisco Stealthwatch
Il problema della crittografia è diventato molto serio, poiché una quantità significativamente maggiore di traffico è stata crittografata. In passato si crittografavano solo i codici (principalmente), mentre ora viene crittografato l'intero traffico e separare i dati 'puliti' dai virus è diventato di gran lunga più difficile. Un esempio lampante è WannaCry, che ha utilizzato Tor per nascondere la propria presenza in rete.
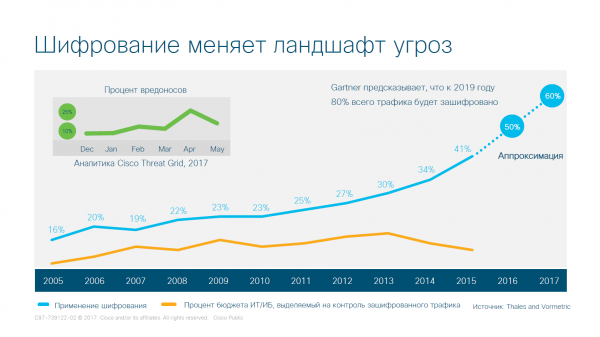
Visualizzazione della crescita della criptazione del traffico in rete
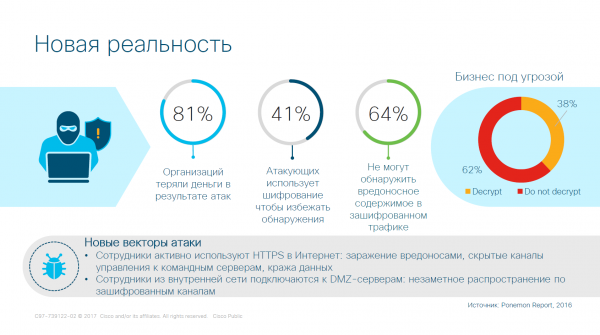
Crittografia nella macroeconomia
Il sistema Encrypted Traffic Analytics (ETA) è necessario per gestire il traffico crittografato senza doverlo decriptare. Gli aggressori sono astuti e utilizzano algoritmi di crittografia robusti, e violarli non è solo un problema, ma comporta anche costi enormi per le organizzazioni.
Il sistema funziona nel seguente modo. Un certo tipo di traffico arriva all'azienda. Questo traffico entra nel TLS (transport layer security — protocollo di sicurezza del trasporto). Supponiamo che il traffico sia crittografato. Cerchiamo di rispondere a una serie di domande su quale tipo di connessione sia stata stabilita.
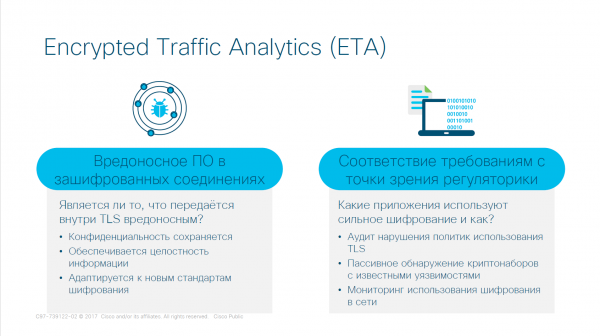
Il principio di funzionamento del sistema Encrypted Traffic Analytics (ETA)
Per rispondere a queste domande, utilizziamo l'apprendimento automatico in questo sistema. Vengono utilizzati studi della Cisco e, basandosi su questi studi, viene creata una tabella con due risultati: traffico dannoso e "buono". Certamente, non sappiamo con certezza quale traffico sia entrato nel sistema in quel momento specifico, ma possiamo tracciare la cronologia del traffico sia all'interno dell'azienda sia a livello globale, utilizzando dati provenienti da tutto il mondo. Alla fine di questa fase, otteniamo una tabella enorme con i dati.
Dallo studio emergono segni distintivi – regole specifiche che possono essere espresse in forma matematica. Queste regole variano notevolmente in base a vari criteri: dimensioni dei file trasferiti, tipo di connessione, paese da cui proviene il traffico, e così via. Così, un'ampia tabella si è trasformata in un insieme di formule. Sono diminuite, ma non è sufficiente per un funzionamento ottimale.
Successivamente, viene applicata la tecnologia del machine learning – la convergenza della formula e, in base ai risultati di questa convergenza, otteniamo un trigger – un interruttore che, al verificarsi di determinati dati, attiva un flag che può essere alzato o abbassato.
Il risultato finale è un insieme di trigger che coprono il 99% del traffico.
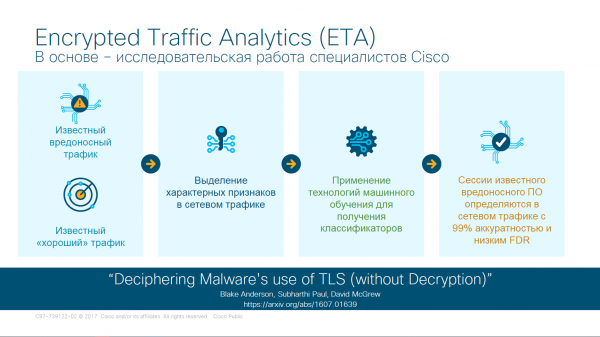
Fasi di verifica del traffico in ETA
Grazie al nostro lavoro, affrontiamo anche un altro problema: l'attacco dall'interno. Non sono più necessarie persone in mezzo che filtrano manualmente il traffico (in questo momento mi contraddico). In primo luogo, non è più necessario spendere molti soldi per un abile amministratore di sistema (continuo a contraddirmi). In secondo luogo, non c'è più il rischio di hacking dall'interno (almeno, in parte).
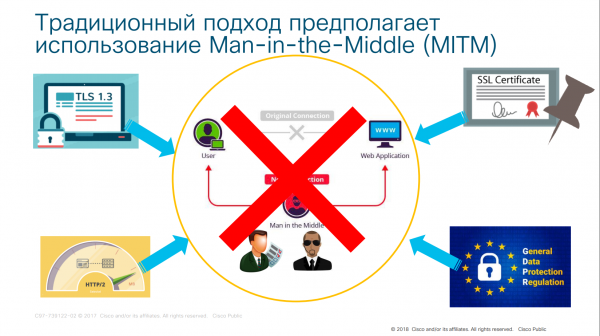
Concetto obsoleto del Man-in-the-Middle
Ora, vediamo su cosa si basa il sistema.
Il sistema si basa su 4 protocolli di comunicazione: TCP/IP – protocollo di trasmissione dei dati su internet, DNS – server dei nomi di dominio, TLS – protocollo di sicurezza del livello di trasporto, SPLT (SpaceWire Physical Layer Tester) – tester del livello fisico della comunicazione.

Protocolli che lavorano con l'ETA
Il confronto avviene attraverso il confronto dei dati. I protocolli TCP/IP controllano la reputazione dei siti (storia delle visite, obiettivo della creazione del sito, ecc.), grazie al protocollo DNS possiamo escludere gli indirizzi «cattivi» dei siti. Il protocollo TLS lavora con le «impronte» del sito (fingerprint) e verifica il sito attraverso il database del Computer Emergency Response Team (cert). L'ultima fase del controllo della connessione è la verifica a livello fisico. I dettagli di funzionalità di questa fase non sono specificati, ma il concetto è il seguente: controllo delle sinusoide e cosinusoide delle curve di trasmissione dati su impianti oscillografici, cioè grazie alla struttura della richiesta a livello fisico, definiamo l'obiettivo della connessione.
Grazie al funzionamento del sistema, possiamo estrarre dati dal traffico crittografato. Analizzando i pacchetti, possiamo leggere il massimo delle informazioni dai campi non crittografati all'interno del pacchetto. Attraverso l'ispezione del pacchetto a livello fisico, scopriamo le caratteristiche del pacchetto (parzialmente o completamente). Inoltre, non dobbiamo dimenticare la reputazione dei siti. Se la richiesta proviene da una fonte .onion, non è saggio fidarsi. Per facilitare il lavoro con questo tipo di dati, è stata creata una mappa dei rischi.
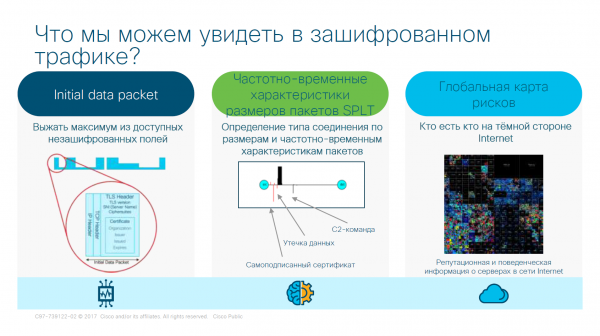
Risultato del lavoro ETA
E tutto sembrerebbe a posto, ma parliamo del dispiegamento della rete.
Realizzazione fisica dell'ETA
Qui sorgono diversi dettagli e sfumature. In primo luogo, nella creazione di questo tipo di
rete con software di alto livello, è necessaria la raccolta dei dati. Raccogliere dati manualmente è del tutto
insensato, mentre implementare un sistema di risposta diventa già più interessante. In secondo luogo, i dati
devono essere abbondanti, il che significa che i sensori installati nella rete devono funzionare
non solo autonomamente, ma anche in modalità finemente sintonizzata, il che presenta diverse complessità.
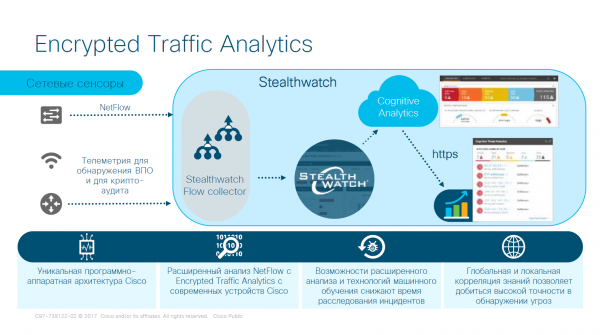
Sensori e sistema Stealthwatch
Installare un sensore è una cosa, ma configurarlo è un'altra questione del tutto diversa. Per la configurazione dei sensori, esiste un insieme che opera sulla seguente topologia: ISR = router con integrazione dei servizi Cisco (Cisco Integrated Services Router); ASR = router con aggregazione dei servizi Cisco (Cisco Aggregation Services Router); CSR = router per servizi cloud Cisco (Cisco Cloud Services Router); WLC = controller delle reti locali wireless Cisco (Cisco Wireless LAN Controller); IE = switch Ethernet industriale Cisco (Cisco Industrial Ethernet); ASA = dispositivo di sicurezza adattativa Cisco (Cisco Adaptive Security Appliance); FTD = soluzione di difesa dalle minacce Cisco Firepower Threat Defense; WSA = dispositivo di protezione del traffico web (Web Security Appliance); ISE = modulo di servizi di identificazione (Identity Services Engine)
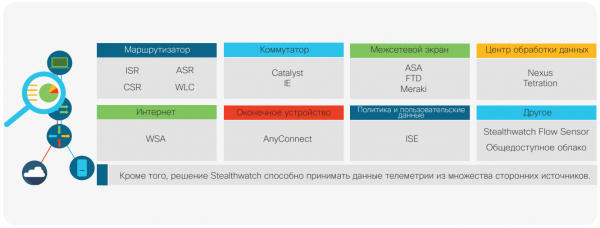
Monitoraggio completo considerando qualsiasi dato di telemetria
Ai network administrator viene l'aritmia per il numero di volte che appare la parola "Cisco" nel paragrafo precedente. Il prezzo di questa meraviglia non è trascurabile, ma non è di questo che parleremo oggi...
La modellazione del comportamento degli hacker avverrà come segue. Stealthwatch monitora attentamente l'attività di ogni dispositivo in rete e riesce a creare un modello di comportamento normale. Inoltre, questa soluzione offre una comprensione approfondita dei comportamenti scorretti noti. A supporto di questa soluzione vengono utilizzati circa 100 diversi algoritmi di analisi o regole euristiche che riguardano diversi tipi di comportamento del traffico, come la scansione, il trasferimento di frame di allerta da un nodo, il tentativo di accesso tramite brute force, la presunta cattura di dati, la presunta fuga di dati, e così via. Gli eventi di sicurezza elencati rientrano nella categoria delle allerte logiche di alto livello. Alcuni eventi di sicurezza possono anche attivare l'allerta autonomamente. In questo modo, il sistema è in grado di correlare numerosi incidenti anomali isolati e raccoglierli insieme per determinare il possibile tipo di attacco, nonché collegarlo a un dispositivo e a un utente specifico (figura 2). L'incidente può poi essere analizzato dinamicamente e considerando i dati telemetrici correlati. Questo costituisce le informazioni contestuali nel loro migliore aspetto. I medici esaminano un paziente per capire cosa sia successo, non considerano i sintomi in isolamento. Studiano l'immagine complessiva per formulare una diagnosi. Analogamente, Stealthwatch registra ogni attività anomala in rete e la analizza nel suo insieme per inviare allerte tenendo conto del contesto, aiutando così gli esperti di sicurezza a dare priorità ai rischi.
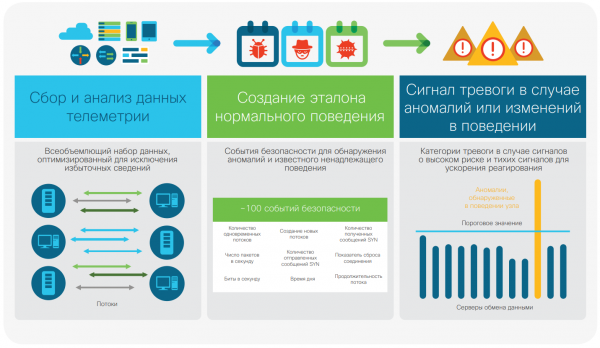
Rilevamento delle anomalie tramite modellazione del comportamento
La distribuzione fisica della rete appare così:
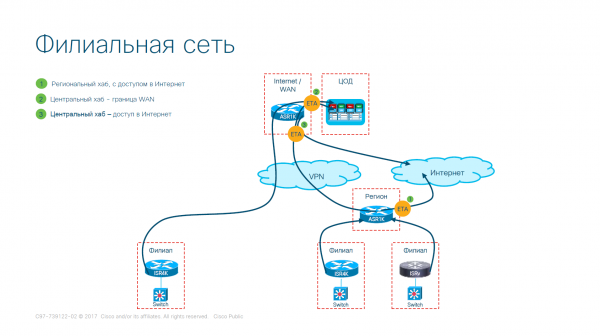
Opzione di distribuzione della rete per una rete filiale (semplificata)
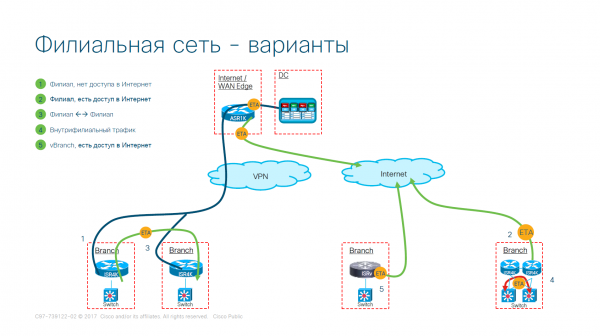
Opzione di distribuzione della rete per una rete filiale
La rete è distribuita, ma rimane un dubbio sulla rete neurale. Abbiamo organizzato una rete di trasmissione dei dati, installato sensori sui portali e avviato un sistema di raccolta delle informazioni, ma la rete neurale non è stata coinvolta. Per ora.
Rete neurale multilivello
Il sistema analizza il comportamento dell'utente e del dispositivo per identificare infezioni dannose, comunicazioni con server di comando, perdite di dati e potenziali applicazioni indesiderate che operano all'interno dell'infrastruttura dell'organizzazione. Ci sono diversi livelli di elaborazione dei dati, nei quali un insieme di metodi di intelligenza artificiale, apprendimento automatico e statistica matematica aiuta la rete a imparare autonomamente la propria attività normale, in modo da poter riconoscere l'attività dannosa.
Il sistema di analisi della sicurezza della rete, che raccoglie dati di telemetria da tutte le parti dell'estesa rete, incluso il traffico crittografato, è una caratteristica unica di Stealthwatch. Esso sviluppa gradualmente una comprensione di ciò che è considerato "anomalo", classificando quindi i singoli elementi di "attività minacciosa" e, infine, prendendo una decisione definitiva sulla possibile compromissione di un dispositivo o di un utente. La capacità di assemblare piccoli pezzi che insieme forniscono la prova per una decisione finale sulla compromissione dell'entità è garantita da un'analisi e correlazione molto approfondite.
Questa capacità è di grande importanza, poiché un'azienda standard può ricevere ogni giorno un'enorme quantità di segnali di allerta, e non è possibile indagare su ognuno di essi — le risorse degli esperti di sicurezza sono limitate. Il modulo di machine learning elabora un'enorme quantità di informazioni praticamente in tempo reale per identificare incidenti critici con un alto grado di fiducia e può anche suggerire un chiaro ordine di azioni per una rapida risoluzione.
Esaminiamo più nel dettaglio i numerosi metodi di machine learning utilizzati da Stealthwatch. Quando un incidente viene inviato al modulo di machine learning di Stealthwatch, passa attraverso un funnel di analisi della sicurezza, dove viene utilizzata una combinazione di metodi di machine learning supervisionati e non supervisionati.
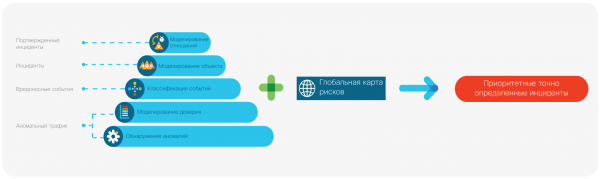
Capacità di machine learning multilivello
Livello 1. Rilevamento delle anomalie e modellazione della fiducia
A questo livello il 99% del traffico viene filtrato utilizzando rilevatori di anomalie statistici. Questi sensori lavorano insieme per creare modelli complessi di ciò che è considerato normale e ciò che, al contrario, è anomalo. Tuttavia, l'anomalia non è necessariamente malevola. Molti eventi nella vostra rete non sono legati a minacce — sono semplicemente strani. È importante quindi classificare tali processi indipendentemente dal comportamento minaccioso. Per questo motivo, i risultati del lavoro di tali rilevatori vengono sottoposti ad ulteriori analisi, per registrare comportamenti strani che possono essere spiegati e ai quali ci si può fidare. Alla fine, solo una piccola parte dei flussi e delle richieste più significativi passa ai livelli 2 e 3. Senza l'uso di tecniche di apprendimento automatico, i costi operativi per separare il segnale dal rumore sarebbero troppo elevati.
Rilevamento delle anomalie. Nella fase iniziale, quando vengono individuate anomalie, vengono utilizzati metodi statistici di machine learning per separare il traffico statisticamente normale da quello anomalo. Oltre 70 rilevatori separati elaborano i dati di telemetria raccolti da Stealthwatch riguardo al traffico che attraversa il perimetro della tua rete, isolando il traffico interno del sistema dei nomi a dominio (DNS) e i dati del proxy, se presenti. Ogni richiesta viene elaborata da più di 70 rilevatori, ognuno dei quali utilizza il proprio algoritmo statistico, formando una valutazione delle anomalie rilevate. Tali valutazioni vengono integrate e, grazie all'applicazione di diversi metodi statistici, si ottiene un'unica valutazione per ogni singola richiesta. Questa valutazione totale viene poi utilizzata per distinguere il traffico normale da quello anomalo.
Modellazione della fiducia. Successivamente, le richieste simili vengono raggruppate e la valutazione complessiva delle anomalie per tali gruppi è definita come media a lungo termine. Nel tempo, più richieste vengono sottoposte ad analisi con successiva determinazione della media a lungo termine, consentendo di ridurre i falsi positivi e i falsi negativi. I risultati della modellazione della fiducia vengono utilizzati per selezionare un sottoinsieme di traffico, la cui valutazione delle anomalie supera una certa soglia dinamicamente definita, per il suo spostamento al livello successivo di elaborazione.
Livello 2. Classificazione degli eventi e modellazione dell'oggetto
A questo livello avviene la classificazione dei risultati ottenuti nelle fasi precedenti, associando a eventi dannosi specifici. La classificazione degli eventi viene effettuata in base al valore assegnato dai classificatori di machine learning, con l'obiettivo di garantire un tasso di accuratezza costante superiore al 90%. Tra questi:
- modelli lineari basati sul lemma di Neyman-Pearson (legge della distribuzione normale mostrata nel grafico all'inizio dell'articolo)
- macchine a vettori di supporto che utilizzano l'apprendimento multimodale
- reti neurali e algoritmo 'foresta casuale'.
Successivamente, tali eventi di sicurezza isolati vengono collegati nel tempo a un singolo dispositivo finale. È in questa fase che viene formulata la descrizione della minaccia, sulla base della quale si crea un quadro completo di come l'aggressore abbia ottenuto determinati risultati.
Classificazione degli eventi. Un sottoinsieme statisticamente anomalo del livello precedente viene distribuito in oltre 100 categorie utilizzando classificatori. La maggior parte dei classificatori si basa su comportamenti individuali, relazioni di gruppo o comportamenti su scala globale o locale, mentre altri possono essere abbastanza specifici. Ad esempio, un classificatore può indicare il traffico dei server di comando, un'estensione sospetta o un aggiornamento software non autorizzato. Alla fine di questa fase, si forma un insieme di eventi anomali nel sistema di sicurezza, classificati in determinate categorie.
Modellazione dell'oggetto. Se la quantità di prove a sostegno dell'ipotesi sulla pericolosità di un determinato oggetto supera la soglia di significatività, viene definita una minaccia. Gli eventi pertinenti che hanno influenzato la definizione della minaccia vengono associati a tale minaccia e diventano parte di un modello discreto a lungo termine dell'oggetto. Con il passare del tempo, man mano che le prove si accumulano, il sistema identifica nuove minacce al raggiungimento della soglia di significatività. Questa soglia è dinamica e viene corretta in modo intelligente in base al livello di rischio di insorgenza della minaccia e ad altri fattori. Dopodiché, la minaccia appare nel pannello informativo dell'interfaccia web e viene spostata al livello successivo.
3 livello. Modellazione delle relazioni
L'obiettivo della modellazione delle relazioni è sintetizzare i risultati ottenuti nei livelli precedenti, considerando sia il contesto locale che quello globale dell'incidente in questione. Proprio in questa fase puoi determinare quante organizzazioni hanno affrontato un attacco simile, per capire se fosse diretto specificamente verso di te o se fosse parte di una campagna globale, e tu sia stato solo un "danno collaterale".
Gli incidenti vengono confermati o rilevati. Un incidente confermato implica una certezza dal 99 al 100%, poiché le metodologie e gli strumenti pertinenti sono stati osservati in azione in un contesto più ampio (globale). Gli incidenti rilevati sono unici per te e fanno parte di una campagna mirata. I risultati ottenuti in passato vengono forniti con un ordine di azione conosciuto, il che consente di risparmiare tempo e risorse nella risposta. Vengono forniti insieme agli strumenti di indagine necessari per comprendere chi ti ha attaccato e quale sia il grado di focalizzazione della campagna sul tuo business digitale. Come puoi immaginare, il numero di incidenti confermati supera di gran lunga quello degli incidenti rilevati, semplicemente perché gli incidenti confermati non comportano grandi costi per gli aggressori, mentre gli incidenti rilevati comportano costi.
costoso, poiché devono essere nuovi e personalizzati. Creando la possibilità di identificare incidenti confermati, l'economia del gioco si è finalmente spostata a favore dei difensori, fornendo loro un certo vantaggio.
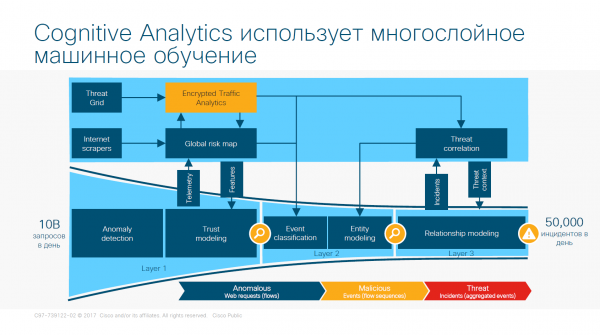
Apprendimento multilivello del sistema delle reti neurali basato su ETA
Mappa globale dei rischi
La mappa globale dei rischi viene creata attraverso l'analisi effettuata dagli algoritmi di apprendimento automatico su uno dei maggiori set di dati del settore. Fornisce ampie statistiche sul comportamento dei server online, anche se non sono noti. Questi server possono essere collegati ad attacchi, potenzialmente sfruttati o utilizzati in future aggressioni. Non è una 'lista nera', ma una visione complessiva del server in esame dal punto di vista della sicurezza. Tali informazioni sull'attività dei server indicati, contestualizzate, permettono ai rilevatori e ai classificatori di apprendimento automatico Stealthwatch di prevedere con precisione il livello di rischio associato alle comunicazioni con tali server.
Puoi visualizzare le mappe disponibili .
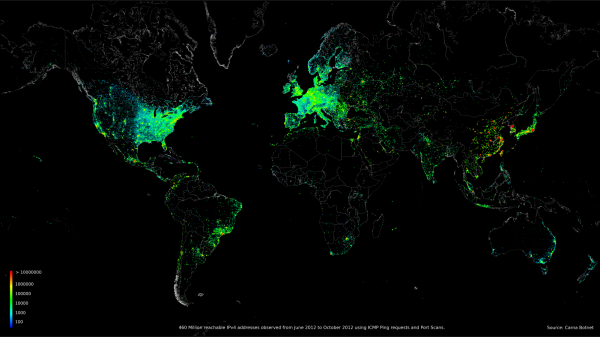
Mappa del mondo che mostra 460 milioni IP addresses
Ora la rete si sta formando e si prepara a proteggere la tua rete.
Finalmente, è stata trovata la panacea?
Sfortunatamente, no. Dall'esperienza con il sistema, posso dire che ci sono 2 problemi principali.
Problema 1. Prezzo. L'intera rete è implementata su un sistema Cisco. Questo ha aspetti sia positivi che negativi. Il lato positivo è che non devi preoccuparti e non devi installare un sacco di dispositivi di tipo D-Link, MikroTik, ecc. Il difetto è il costo elevato del sistema. Considerando la situazione economica delle imprese in Russia, attualmente solo un proprietario benestante di una grande azienda o banca può permettersi questa meraviglia.
Problema 2. Formazione. Non ho scritto nell'articolo il tempo di addestramento della rete neurale, ma non perché non ci sia, ma perché essa è in costante apprendimento e non possiamo prevedere quando apprenderà. Certo, ci sono strumenti di statistica matematica (prendiamo la stessa formulazione del criterio di convergenza di Pearson), ma sono solo misure temporanee. Otteniamo la probabilità di filtrazione del traffico, e solo se l'attacco è già noto e conosciuto.
Nonostante questi 2 problemi, abbiamo compiuto un grande passo avanti nello sviluppo della sicurezza informatica in generale e nella protezione della rete in particolare. Questo fatto può essere motivante per esplorare le tecnologie di rete e le reti neurali, che attualmente rappresentano un'area molto promettente.
Fonte: habr.com
