

Ciao, sono Dmitrij Logvinenko — Data Engineer del dipartimento di analytics del gruppo Vezet.
Vi parlerò di uno strumento eccezionale per lo sviluppo di processi ETL — Apache Airflow. Ma Airflow è così versatile e multifunzionale che dovreste considerarlo anche se non gestite flussi di dati, ma avete bisogno di avviare periodicamente qualche processo e monitorarne l'esecuzione.
E sì, non mi limiterò a raccontare, ma mostrerò anche: il programma contiene molto codice, screenshot e raccomandazioni.
Cosa si vede solitamente quando si cerca la parola Airflow / Wikimedia Commons
Indice
Introduzione
Apache Airflow — è proprio come Django:
- scritto in Python,
- ha una fantastica interfaccia di amministrazione,
- estremamente estensibile,
— solo il meglio, ed è stato realizzato per scopi completamente diversi, cioè (come scritto prima):
- l'avvio e il monitoraggio di attività su un numero illimitato di macchine (quante ne consente Celery/Kubernetes e la vostra coscienza)
- con generazione dinamica di workflow da codice Python molto semplice da scrivere e comprendere
- e la possibilità di collegare tra loro qualsiasi database e API usando sia componenti predefiniti che plugin fai-da-te (facilissimi da realizzare).
Noi utilizziamo Apache Airflow in questo modo:
- raccogliendo dati da diverse fonti (numerosi istanze di SQL Server e PostgreSQL, varie API con metriche delle applicazioni, persino 1C) in DWH e ODS (per noi sono Vertica e Clickhouse).
- come un avanzato
cron, che avvia processi di consolidamento dati su ODS e ne monitora anche la manutenzione.
Fino a poco tempo fa, le nostre esigenze erano soddisfatte da un piccolo server con 32 core e 50 GB di RAM. In Airflow, ci sono:
- più di 200 DAG (cioè workflow, in cui abbiamo inserito le attività),
- ogni uno in media con 70 task,
- questo buono viene avviato (anche in media) una volta all'ora.
E su come ci siamo espansi, scriverò più avanti, ora definiamo l'über-compito che intendiamo risolvere:
Ci sono tre SQL Server sorgenti, ognuno con 50 database — istanze di un progetto, quindi la loro struttura è praticamente identica (quasi ovunque, muahahaha), e in ognuna c'è una tabella Orders (fortunatamente, una tabella con questo nome può essere inserita in qualsiasi attività). Estraiamo i dati, aggiungendo campi ausiliari (server di origine, database di origine, identificatore del compito ETL) e li mettiamo naïf in, diciamo, Vertica.
Andiamo!
Parte principale, pratica (e un po' teorica)
Perché ci serve (e a voi)
Quando gli alberi erano grandi, e io ero un semplice SQL-operatore in una catena della distribuzione russa, gestivamo i processi ETL aka flussi di dati utilizzando due strumenti che avevamo a disposizione:
- Informatica Power Center — un sistema estremamente complesso e altamente performante, con il proprio hardware e versioning. Ho utilizzato neanche l'1% delle sue potenzialità. Perché? Beh, innanzitutto, quell'interfaccia risalente agli anni 2000 psicologicamente ci opprimeva. In secondo luogo, questo marchingegno è progettato per processi estremamente sofisticati, riutilizzo aggressivo dei componenti e altre importantissime chicche da enterprise. Dire che costa come un'ala di un Airbus A380/anno, lo tralasciamo.
Attenzione, uno screenshot potrebbe far provare un po' di dolore a chi ha meno di 30 anni.

- SQL Server Integration Server — abbiamo utilizzato questo strumento nei nostri flussi interni. In effetti: stiamo già utilizzando SQL Server e non utilizzare i suoi strumenti ETL sarebbe un po' irrazionale. Ha tutto: un'interfaccia bella, report di esecuzione… Ma non è per questo che amiamo i prodotti software, oh no. Possiamo versionare il suo
dtsx(che è un XML con nodi misti quando viene salvato), ma a che serve? Creare un pacchetto di attività che trasferisca centinaia di tabelle da un server all'altro? E non solo centinaia, dopo venti vi si staccherà il dito indice dal cliccare il pulsante del mouse. Esteticamente, però, è decisamente più alla moda:
Cercavamo senza dubbio delle soluzioni. La situazione è persino quasi arrivata a un generatore di pacchetti SSIS fatto in casa…
… poi ho trovato un nuovo lavoro. E qui mi ha raggiunto Apache Airflow.
Quando ho scoperto che le descrizioni dei processi ETL sono semplicemente codice Python, quasi ballavo di gioia. Così i flussi di dati sono stati sottoposti a versionamento e differenze, e scaricare tabelle con una struttura uniforme da cento database in un unico target è diventato un compito di codice Python su uno schermo da 13” a uno o due.
Colleghiamo il cluster
Evitare di creare una situazione infantile, non parliamo di cose ovvie come l'installazione di Airflow, del database che hai scelto, di Celery e di altre questioni già descritte nella documentazione.
Affinché possiamo subito iniziare gli esperimenti, ho abbozzato docker-compose.yml in cui:
- Avviamo effettivamente Airflow: Scheduler, Webserver. Qui funzionerà anche Flower per il monitoraggio dei task Celery (poiché è già stato integrato in
apache/airflow:1.10.10-python3.7, e noi non abbiamo obiezioni); - PostgreSQL, nel quale Airflow registrerà le sue informazioni operative (dati del pianificatore, statistiche di esecuzione, ecc.), e Celery registrerà i task completati;
- Redis, che fungerà da broker per i task di Celery;
- Celery worker, che si occuperà dell'esecuzione effettiva dei task.
- Nella cartella
./dagsposteremo i nostri file di descrizione dei DAG. Saranno caricati al volo, quindi non c'è bisogno di riavviare l'intero stack ogni volta che si verifica un piccolo cambiamento.
In alcuni casi il codice negli esempi non è completo (per non appesantire il testo), mentre in altri viene modificato durante il processo. Esempi di codice funzionanti e completi possono essere consultati nel repository. .
docker-compose.yml
version: '3.4'
x-airflow-config: &airflow-config
AIRFLOW__CORE__DAGS_FOLDER: /dags
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__FERNET_KEY: MJNz36Q8222VOQhBOmBROFrmeSxNOgTCMaVp2_HOtE0=
AIRFLOW__CORE__HOSTNAME_CALLABLE: airflow.utils.net:get_host_ip_address
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgres+psycopg2://airflow:airflow@airflow-db:5432/airflow
AIRFLOW__CORE__PARALLELISM: 128
AIRFLOW__CORE__DAG_CONCURRENCY: 16
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_RETRY: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_FAILURE: 'False'
AIRFLOW__CELERY__BROKER_URL: redis://broker:6379/0
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@airflow-db/airflow
x-airflow-base: &airflow-base
image: apache/airflow:1.10.10-python3.7
entrypoint: /bin/bash
restart: always
volumes:
- ./dags:/dags
- ./requirements.txt:/requirements.txt
services:
# Redis come broker per Celery
broker:
image: redis:6.0.5-alpine
# DB per i metadati di Airflow
airflow-db:
image: postgres:10.13-alpine
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
volumes:
- ./db:/var/lib/postgresql/data
# Contenitore principale con Webserver, Scheduler, Celery Flower
airflow:
<<: *airflow-base
environment:
<
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint initdb &&
(/entrypoint webserver &) &&
(/entrypoint flower &) &&
/entrypoint scheduler"
ports:
# Celery Flower
- 5555:5555
# Webserver di Airflow
- 8080:8080
# Worker Celery, sarà scalato utilizzando `--scale=n`
worker:
<<: *airflow-base
environment:
<
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint worker"
depends_on:
- airflow
- airflow-db
- brokerNote:
- Nella costruzione del composo mi sono molto basato su un'immagine nota – assicurati di dare un'occhiata. Forse non ti servirà nient'altro nella vita.
- Tutte le impostazioni di Airflow sono disponibili non solo tramite
airflow.cfg, ma anche attraverso le variabili ambientali (grazie agli sviluppatori), e ne ho approfittato in modo sfacciato. - Naturalmente, non è pronto per la produzione: ho volutamente evitato di impostare i heartbeats sui container e non mi sono preoccupato della sicurezza. Ma ho creato un minimo adatto per i nostri esperimenti.
- Si prega di notare che:
- La cartella con i DAG deve essere accessibile sia allo scheduler che ai worker.
- Lo stesso vale per tutte le librerie esterne: devono essere tutte installate sulle macchine con lo scheduler e i worker.
E ora, semplicemente:
$ docker-compose up --scale worker=3Una volta che tutto è avviato, puoi guardare le interfacce web:
- Airflow:
- Flower:
Concetti di base
Se non hai capito nulla di tutti questi "DAG", ecco un breve glossario:
- Scheduler — il tizio più importante in Airflow, che controlla che siano i robot a lavorare, non gli esseri umani: si occupa dell'orario, aggiorna i DAG, avvia i task.
In passato, nelle versioni più vecchie, aveva problemi di memoria (no, non amnesia, ma perdite) e nei file di configurazione era rimasto un parametro legacy.
run_duration— l'intervallo di riavvio. Ma ora va tutto bene. - DAG (detto anche «dag») — «grafo aciclico diretto», ma questa definizione dirà poco a chiunque; in sostanza, è un contenitore per task interconnessi (vedi sotto) o un analogo di Package in SSIS e Workflow in Informatica.
Oltre ai dag, possono esserci anche subdag, ma probabilmente non ci arriveremo.
- DAG Run — un dag inizializzato a cui è assegnato il suo
execution_date. I dag run di un singolo dag possono funzionare in parallelo (se, ovviamente, hai reso i tuoi task idempotenti). - Operator — sono porzioni di codice responsabili dell'esecuzione di un'azione specifica. Ci sono tre tipi di operatori:
- action, come il nostro preferito
PythonOperator, che può eseguire qualsiasi codice Python (valido); - transfer, che spostano dati da un luogo all'altro, ad esempio,
MsSqlToHiveTransfer; - sensor permetterà di reagire o rallentare l'esecuzione del dag fino al verificarsi di un evento.
HttpSensorpuò interrogare l'endopoint specificato, e quando riceve la risposta desiderata, avviare il trasferimentoGoogleCloudStorageToS3Operator. Una mente curiosa potrebbe chiedere: «perché? Si possono fare i ritardi direttamente nell'operatore!» E poi, per non sovraccaricare il pool di task con operatori in attesa. Il sensore si attiva, controlla e poi si spegne fino al prossimo tentativo.
- action, come il nostro preferito
- Compito — gli operatori dichiarati indipendentemente dal tipo e collegati al dag vengono elevati a compiti.
- Istanza del compito — quando il pianificatore principale decide che è ora di inviare i compiti ai lavoratori esecutori (proprio sul posto, se utilizziamo
LocalExecutoro su una nodo remoto nel caso diCeleryExecutor), assegna loro un contesto (cioè un insieme di variabili - parametri di esecuzione), espande i modelli di comandi o richieste e li raccoglie nel pool.
Generiamo task
Iniziamo definendo lo schema generale del nostro dag, e poi ci immergeremo sempre più nei dettagli, perché stiamo applicando alcune soluzioni non banali.
Quindi, in forma più semplice, un dag simile apparirebbe così:
from datetime import timedelta, datetime
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from commons.datasources import sql_server_ds
dag = DAG('orders',
schedule_interval=timedelta(hours=6),
start_date=datetime(2020, 7, 8, 0))
def workflow(**context):
print(context)
for conn_id, schema in sql_server_ds:
PythonOperator(
task_id=schema,
python_callable=workflow,
provide_context=True,
dag=dag)Prendiamo il necessario:
- Iniziamo importando le librerie e qualcos'altro;
sql_server_ds— rappresentaList[namedtuple[str, str]]con i nomi delle connessioni da Airflow Connections e le basi dati da cui preleveremo la nostra tabella;dagè la dichiarazione del nostro DAG, che deve necessariamente trovarsi inglobals(), altrimenti Airflow non lo troverà. Dobbiamo anche dire al DAG:- come si chiama
ordersquesto nome apparirà poi nell'interfaccia web, - che inizierà a funzionare dalla mezzanotte dell'otto luglio,
- e dovrà essere eseguito circa ogni 6 ore (per chi è più esperto, qui al posto di
timedelta()è consentitacronla stringa0 0 0/6 ? * * *, per chi è meno esperto – un'espressione del tipo@daily);
- come si chiama
workflow()eseguirà il lavoro principale, ma non ora. Adesso stamperemo semplicemente il nostro contesto nel log.- E adesso la semplice magia della creazione di task:
- iteriamo sui nostri sorgenti;
- inizializziamo
PythonOperator, che eseguirà la nostra funzione vuotaworkflow(). Non dimenticate di specificare un nome univoco (nell'ambito del DAG) per il task e di associare il DAG stesso. Flagprovide_contextfornirà a sua volta argomenti aggiuntivi alla funzione, che raccoglieremo con cura grazie a**context.
Per ora è tutto. Cosa abbiamo ottenuto:
- un nuovo DAG nell'interfaccia web,
- circa cento cinquanta task che verranno eseguiti in parallelo (se le impostazioni di Airflow, Celery e le potenze dei server lo consentiranno).
Beh, quasi ottenuto.
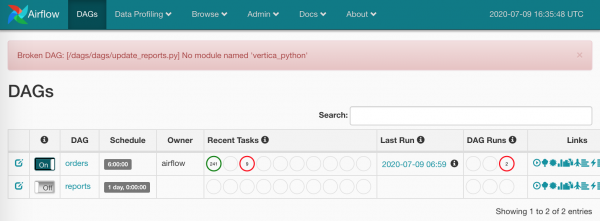
Chi si occuperà delle dipendenze?
Per semplificare tutto questo, ho integrato nel docker-compose.yml processamento requirements.txt su tutti i nodi.
Adesso si parte:
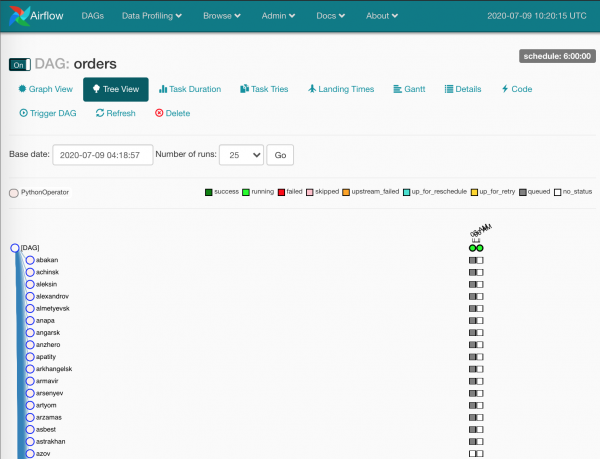
I quadrati grigi sono le istanze dei task lavorate dallo scheduler.
Aspettiamo un po', i worker vanno a prendersi i task:
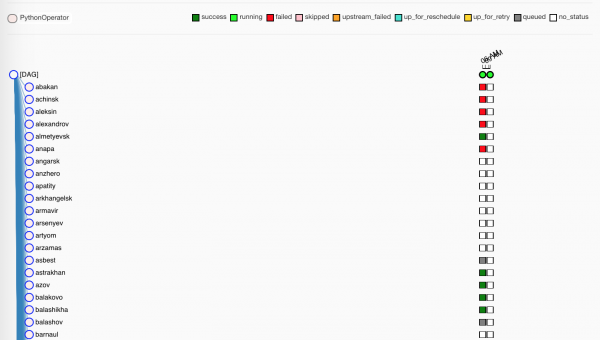
I verdi, ovviamente, sono quelli completati con successo. I rossi — non proprio con successo.
A proposito, nel nostro ambiente produttivo non esiste alcuna cartella
./dags, sincronizzata tra le macchine — tutti i DAG sono memorizzati ingitnel nostro Gitlab, e Gitlab CI distribuisce gli aggiornamenti sulle macchine al momento della fusione inmaster.
Un po' su Flower
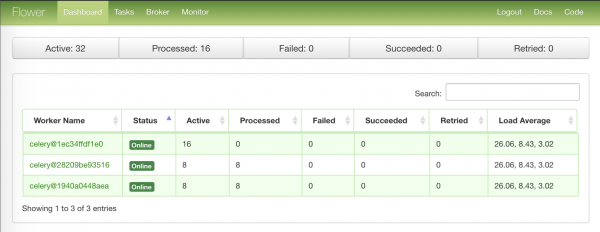
Mentre i worker elaborano i nostri task vuoti, ricordiamo un altro strumento che può mostrarci qualcosa — Flower.
La prima pagina con un riepilogo delle informazioni sui nodi-worker:
La pagina più ricca di attività inviate al lavoro:
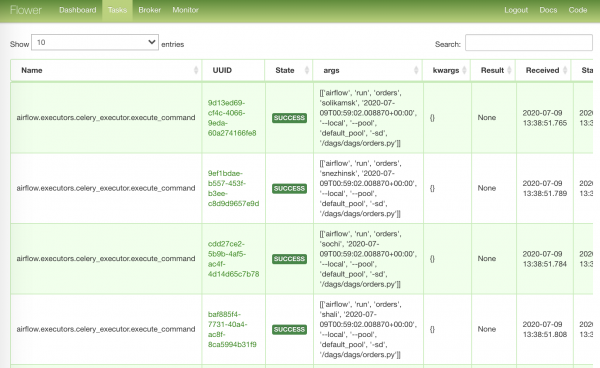
La pagina più noiosa sullo stato del nostro broker:
La pagina più colorata - con grafici sullo stato dei task e i loro tempi di esecuzione:
Carichiamo il non caricato
Ecco, tutti i task hanno lavorato, possiamo portare via i feriti.
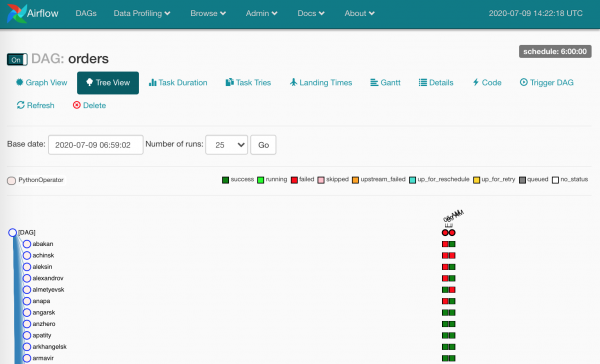
E i feriti si sono rivelati essere molti - per motivi vari. In caso di utilizzo corretto di Airflow, questi quadrati indicano sicuramente che i dati non sono arrivati.
Dobbiamo controllare il log e riavviare le istanze di task che sono cadute.
Cliccando su qualsiasi quadrato, vedremo le azioni disponibili:
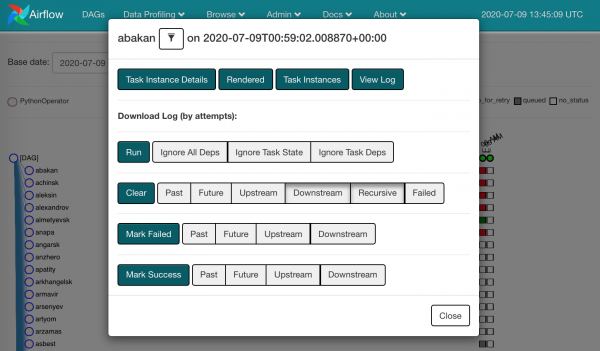
Possiamo selezionare e fare Clear a quello caduto. In altre parole, dimentichiamo che c'è stato un guasto, e la stessa istanza del task tornerà al pianificatore.

È chiaro che fare così con tutti i quadrati rossi non è molto umano - non è ciò che ci aspettiamo da Airflow. Naturalmente, abbiamo un'arma di distruzione di massa: Browse/Task Instances
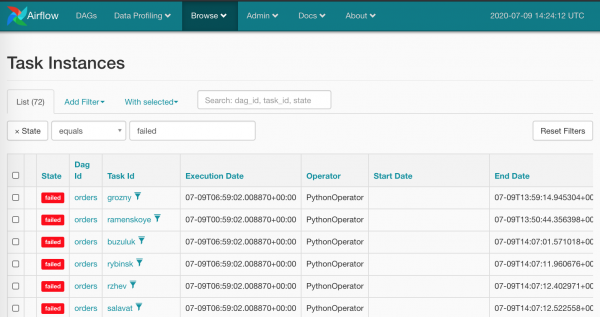
Selezioniamo tutto insieme e azzeriamo, premiamo il punto giusto:
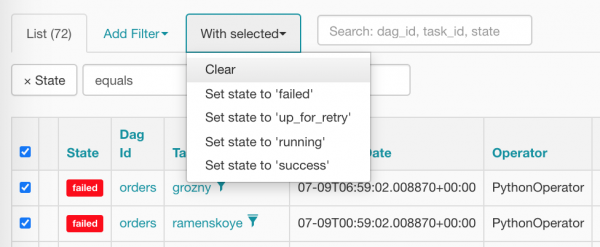
Dopo la pulizia, i nostri task appaiono così (stanno già aspettando con ansia che il planner li programmi):

Connessioni, hook e altre variabili
È il momento giusto per guardare il prossimo DAG, update_reports.py:
from collections import namedtuple
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.contrib.operators.vertica_operator import VerticaOperator
from airflow.operators.email_operator import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
from commons.operators import TelegramBotSendMessage
dag = DAG('update_reports',
start_date=datetime(2020, 6, 7, 6),
schedule_interval=timedelta(days=1),
default_args={'retries': 3, 'retry_delay': timedelta(seconds=10)})
Report = namedtuple('Report', 'source target')
reports = [Report(f'{table}_view', table) for table in [
'reports.city_orders',
'reports.client_calls',
'reports.client_rates',
'reports.daily_orders',
'reports.order_duration']]
email = EmailOperator(
task_id='email_success', dag=dag,
to='{{ var.value.all_the_kings_men }}',
subject='DWH Reports updated',
html_content=dedent("""Gentili signori, i rapporti sono stati aggiornati"""),
trigger_rule=TriggerRule.ALL_SUCCESS)
tg = TelegramBotSendMessage(
task_id='telegram_fail', dag=dag,
tg_bot_conn_id='tg_main',
chat_id='{{ var.value.failures_chat }}',
message=dedent("""
Natasha, svegliati, abbiamo perso {{ dag.dag_id }}
"""),
trigger_rule=TriggerRule.ONE_FAILED)
for source, target in reports:
queries = [f"TRUNCATE TABLE {target}",
f"INSERT INTO {target} SELECT * FROM {source}"]
report_update = VerticaOperator(
task_id=target.replace('reports.', ''),
sql=queries, vertica_conn_id='dwh',
task_concurrency=1, dag=dag)
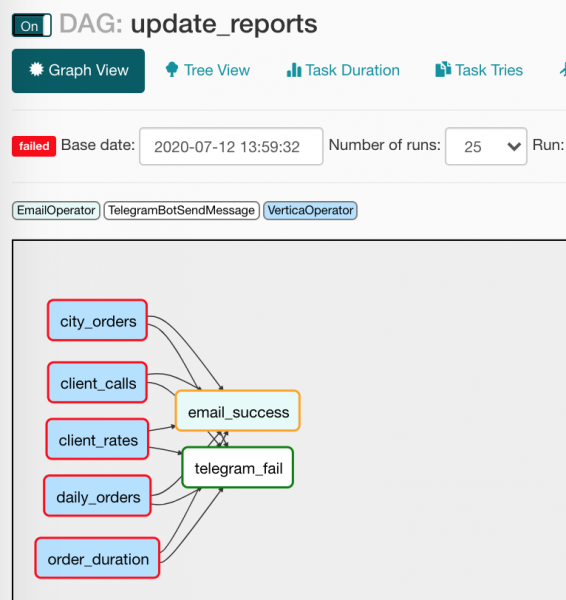
report_update >> [email, tg]Tutti hanno mai aggiornato un report, giusto? Eccola di nuovo: c'è un elenco di fonti da cui prelevare i dati; c'è un elenco dove metterli; non dimentichiamo di segnalare quando tutto è successo o si è rotto (beh, questo non riguarda noi, giusto?).
Procediamo di nuovo attraverso il file e diamo uno sguardo alle nuove cose poco chiare:
from commons.operators import TelegramBotSendMessage— non c'è niente che ci impedisca di creare i nostri operatori, e infatti abbiamo fatto una piccola avvolgente per inviare messaggi a Unblocked. (Di questo operatore ne parleremo più avanti);default_args={}— il DAG può distribuire gli stessi argomenti a tutti i suoi operatori;to='{{ var.value.all_the_kings_men }}'— campotoci sarà generato dinamicamente tramite Jinja e una variabile con la lista di email che ho sapientemente posizionato inAdmin/Variables;trigger_rule=TriggerRule.ALL_SUCCESS— condizione di attivazione dell'operatore. Nel nostro caso, l'email verrà inviata ai boss solo se tutte le dipendenze sono state eseguite con successo;tg_bot_conn_id='tg_main'— argomenticonn_idsono identificatori di connessioni che creiamo inAdmin/Connections;trigger_rule=TriggerRule.ONE_FAILED— i messaggi su Telegram verranno inviati solo se ci sono task falliti;task_concurrency=1— vietiamo l'esecuzione simultanea di più istanze di task dello stesso task. Altrimenti, avremo un avvio simultaneo di piùVerticaOperator(che guardano alla stessa tabella);report_update >> [email, tg]— tuttiVerticaOperatorsi ritroveranno nell'invio di email e messaggi, in questo modo:

Ma poiché gli operatori di notifica hanno condizioni di avvio diverse, funzionerà solo uno. In Tree View appare un po' meno chiaro:


Dico due parole sui macro e i loro amici — variabili.
Le macro sono segnaposto Jinja che possono inserire varie informazioni utili negli argomenti degli operatori. Ad esempio:
SELECT
id,
payment_dtm,
payment_type,
client_id
FROM orders.payments
WHERE
payment_dtm::DATE = '{{ ds }}'::DATE{{ ds }} si espanderà nel contenuto della variabile di contesto execution_date nel formato YYYY-MM-DD: 2020-07-14. La cosa più bella è che le variabili di contesto sono legate a un'istanza specifica del task (un quadratino in Tree View), e al riavvio i segnaposto si apriranno negli stessi valori.
I valori assegnati possono essere visualizzati tramite il pulsante Rendered su ogni istanza del task. Ecco come appare per il task che invia email:
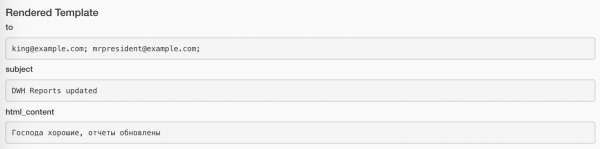
E così per il task che invia messaggi:

L'elenco completo delle macro incorporate per l'ultima versione disponibile è disponibile qui:
Inoltre, tramite i plugin, possiamo dichiarare le nostre macro personalizzate, ma questa è un'altra storia.
Oltre agli elementi predefiniti, possiamo sostituire i valori delle nostre variabili (nel codice sopra l'ho già fatto). Creiamo un Admin/Variables paio di elementi:
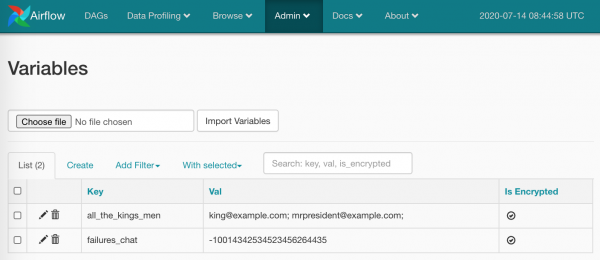
Tutto, è pronto per essere utilizzato:
TelegramBotSendMessage(chat_id='{{ var.value.failures_chat }}')Nel valore può esserci uno scalare, ma può anche esserci un JSON. Nel caso del JSON:
bot_config
{
"bot": {
"token": 881hskdfASDA16641,
"name": "Verter"
},
"service": "TG"
}basta utilizzare il percorso della chiave necessaria: {{ var.json.bot_config.bot.token }}.
Dirò parola per parola e mostrerò uno screenshot riguardo connessioni. Qui è tutto elementare: sulla pagina Admin/Connections creiamo una connessione, mettiamo le nostre credenziali e parametri più specifici. Ecco come:
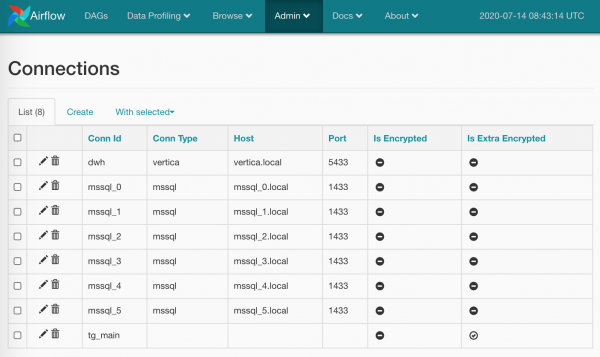
Le password possono essere cifrate (in modo più rigoroso rispetto all'opzione predefinita), oppure è possibile non specificare il tipo di connessione (come ho fatto per tg_main) — il punto è che l'elenco dei tipi è incorporato nei modelli di Airflow e non può essere esteso senza modificare il codice sorgente (se per caso non ho trovato qualcosa, vi prego di correggermi), ma ottenere le credenziali semplicemente per nome non ci è di ostacolo.
Inoltre, è possibile creare più connessioni con lo stesso nome: in tal caso, il metodo BaseHook.get_connection(), che ci fornisce le connessioni per nome, restituirà una casuale delle varie omonime (sarebbe più logico implementare un Round Robin, ma lasciamo questo ai programmatori di Airflow).
Le Variabili e le Connessioni sono senza dubbio ottimi strumenti, ma è importante non perdere l'equilibrio: quali parti dei vostri flussi tenete effettivamente nel codice e quali affidate alla conservazione di Airflow. Da un lato, cambiare rapidamente un valore, ad esempio, la casella di posta, può essere conveniente tramite l'interfaccia utente. Dall'altro — stiamo tornando all'uso del mouse, da cui (io) volevamo liberarci.
Lavorare con le connessioni è uno dei compiti hook. In generale, gli hook di Airflow sono i punti di connessione ai servizi e librerie esterni. Ad esempio, JiraHook ci aprirà un client per interagire con Jira (è possibile spostare le task da una parte all'altra), mentre con SambaHook è possibile caricare un file locale su smb-punti.
Analizziamo un operatore personalizzato
E ci stiamo avvicinando a vedere come è fatto TelegramBotSendMessage
Codice commons/operators.py con l'operatore stesso:
from typing import Union
from airflow.operators import BaseOperator
from commons.hooks import TelegramBotHook, TelegramBot
class TelegramBotSendMessage(BaseOperator):
"""Invia un messaggio a chat_id utilizzando TelegramBotHook
Esempio:
>>> TelegramBotSendMessage(
... task_id='telegram_fail', dag=dag,
... tg_bot_conn_id='tg_bot_default',
... chat_id='{{ var.value.all_the_young_dudes_chat }}',
... message='{{ dag.dag_id }} failed :(',
... trigger_rule=TriggerRule.ONE_FAILED)
"""
template_fields = ['chat_id', 'message']
def __init__(self,
chat_id: Union[int, str],
message: str,
tg_bot_conn_id: str = 'tg_bot_default',
*args, **kwargs):
super().__init__(*args, **kwargs)
self._hook = TelegramBotHook(tg_bot_conn_id)
self.client: TelegramBot = self._hook.client
self.chat_id = chat_id
self.message = message
def execute(self, context):
print(f'Invio "{self.message}" alla chat {self.chat_id}')
self.client.send_message(chat_id=self.chat_id,
message=self.message)Qui, come il resto in Airflow, è tutto molto semplice:
- Abbiamo ereditato da
BaseOperator, che implementa molte cose specifiche di Airflow (dai un'occhiata quando hai tempo) - Abbiamo dichiarato i campi
template_fields, in cui Jinja cercherà macro da elaborare. - Abbiamo organizzato gli argomenti corretti per
__init__(), abbiamo impostato i valori predefiniti dove necessario. - Non abbiamo dimenticato l'inizializzazione del genitore.
- Abbiamo aperto il relativo hook
TelegramBotHook, abbiamo ricevuto da lui un oggetto client. - Abbiamo sovrascritto il metodo
BaseOperator.execute(), che Airflow chiamerà quando sarà il momento di avviare l'operatore — qui implementiamo l'azione principale, ricordandoci di registrarla. (Registriamo, tra l'altro, direttamente instdoutestderr— Airflow catturerà tutto, lo incapsulerà in modo elegante e lo organizzerà dove necessario.)
Diamo un'occhiata a cosa abbiamo in commons/hooks.py. Prima parte del file, con l'hook stesso:
from typing import Union
from airflow.hooks.base_hook import BaseHook
from requests_toolbelt.sessions import BaseUrlSession
class TelegramBotHook(BaseHook):
"""Telegram Bot API hook
Nota: aggiungi una connessione con Conn Type vuoto e non dimenticare
di riempire Extra:
{"bot_token": "YOuRAwEsomeBOtToKen"}
"""
def __init__(self,
tg_bot_conn_id='tg_bot_default'):
super().__init__(tg_bot_conn_id)
self.tg_bot_conn_id = tg_bot_conn_id
self.tg_bot_token = None
self.client = None
self.get_conn()
def get_conn(self):
extra = self.get_connection(self.tg_bot_conn_id).extra_dejson
self.tg_bot_token = extra['bot_token']
self.client = TelegramBot(self.tg_bot_token)
return self.clientNon so nemmeno cosa si possa spiegare qui, segnalerò solo i punti importanti:
- Ereditiamo, riflettiamo sugli argomenti — nella maggior parte dei casi sarà uno solo:
conn_id; - Ridefinisco i metodi standard: mi sono limitato
get_conn(), nel quale recupero i parametri di connessione per nome e semplicemente estraggo la sezioneextra(questo è il campo per JSON), in cui ho (seguendo le mie stesse istruzioni!) messo il token del bot Telegram:{"bot_token": "YOuRAwEsomeBOtToKen"}. - Creo un'istanza del nostro
TelegramBot, passando già il token specifico.
Ecco fatto. Puoi ottenere il client dall'hook usando TelegramBotHook().client o TelegramBotHook().get_conn().
E nella seconda parte del file, in cui faccio un micro-wrapper per Telegram REST API, per non dover portare lo stesso per un solo metodo sendMessage.
class TelegramBot:
"""Wrapper per l'API di Telegram Bot
Esempi:
>>> TelegramBot('YOuRAwEsomeBOtToKen', '@myprettydebugchat').send_message('Ciao, cara')
>>> TelegramBot('YOuRAwEsomeBOtToKen').send_message('Ciao, cara', chat_id=-1762374628374)
"""
API_ENDPOINT = 'https://api.telegram.org/bot{}/'
def __init__(self, tg_bot_token: str, chat_id: Union[int, str] = None):
self._base_url = TelegramBot.API_ENDPOINT.format(tg_bot_token)
self.session = BaseUrlSession(self._base_url)
self.chat_id = chat_id
def send_message(self, message: str, chat_id: Union[int, str] = None):
method = 'sendMessage'
payload = {'chat_id': chat_id or self.chat_id,
'text': message,
'parse_mode': 'MarkdownV2'}
response = self.session.post(method, data=payload).json()
if not response.get('ok'):
raise TelegramBotException(response)
class TelegramBotException(Exception):
def __init__(self, *args, **kwargs):
super().__init__((args, kwargs))Il modo corretto è mettere tutto questo insieme:
TelegramBotSendMessage,TelegramBotHook,TelegramBot— in un plugin, caricarlo in un repository pubblico e renderlo Open Source.
Mentre studiavamo tutto questo, i nostri aggiornamenti dei report sono riusciti a bloccarsi e mi hanno inviato un messaggio di errore nel canale. Vado a controllare cosa non va di nuovo…
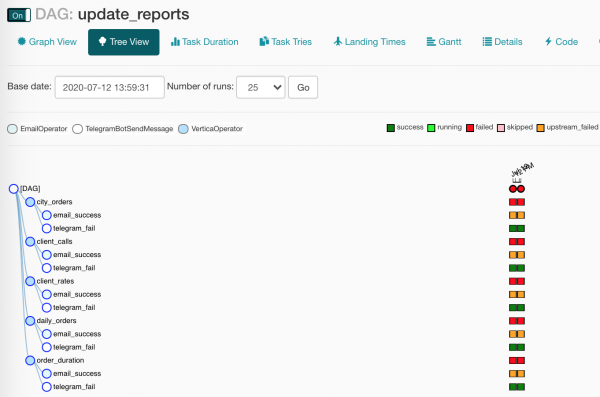
Qualcosa si è rotto nel nostro DAG! Era esattamente quello che aspettavamo? Esatto!
Stai per versare?
Hai la sensazione che mi sia perso qualcosa? A quanto pare avevo promesso di trasferire i dati da SQL Server a Vertica e qui ho cambiato argomento, che birbante!
L'atto era intenzionale, dovevo semplicemente spiegarvi un po' di terminologia. Ora possiamo andare avanti.
Il nostro piano era questo:
- Creare un DAG
- Generare i task
- Vedere tutto in modo bello
- Assegnare ai caricamenti i numeri delle sessioni
- Prelevare i dati da SQL Server
- Inserire i dati in Vertica
- Raccogliere statistiche
Quindi, per avviare tutto questo, ho fatto un piccolo aggiustamento al nostro docker-compose.yml:
docker-compose.db.yml
version: '3.4'
x-mssql-base: &mssql-base
image: mcr.microsoft.com/mssql/server:2017-CU21-ubuntu-16.04
restart: always
environment:
ACCEPT_EULA: Y
MSSQL_PID: Express
SA_PASSWORD: SayThanksToSatiaAt2020
MSSQL_MEMORY_LIMIT_MB: 1024
services:
dwh:
image: jbfavre/vertica:9.2.0-7_ubuntu-16.04
mssql_0:
<<: *mssql-base
mssql_1:
<<: *mssql-base
mssql_2:
<<: *mssql-base
mssql_init:
image: mio101/py3-sql-db-client-base
command: python3 ./mssql_init.py
depends_on:
- mssql_0
- mssql_1
- mssql_2
environment:
SA_PASSWORD: SayThanksToSatiaAt2020
volumes:
- ./mssql_init.py:/mssql_init.py
- ./dags/commons/datasources.py:/commons/datasources.pyLì stiamo sollevando:
- Vertica come host
dwhcon le impostazioni predefinite - tre istanze di SQL Server,
- riempiamo i database con alcune ultime informazioni (non guardate mai dentro
mssql_init.py!)
Avviamo tutto con un comando leggermente più complesso rispetto all'ultima volta:
$ docker-compose -f docker-compose.yml -f docker-compose.db.yml up --scale worker=3Cosa ha generato il nostro meraviglioso randomizzatore può essere visto usando l'opzione Data Profiling/Ad Hoc Query:
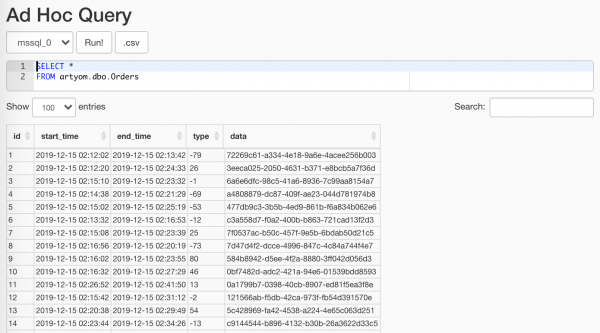
La cosa principale è non mostrarlo agli analisti
Di cui non mi soffermerò sulle sessioni ETL non lo farò, è tutto banale: creiamo una base, all'interno una tabella, tutto avvolto in un gestore di contesto, e ora procediamo così:
with Session(task_name) as session:
print('Load', session.id, 'started')
# Load workflow
...
session.successful = True
session.loaded_rows = 15session.py
from sys import stderr
class Session:
"""Session di lavoro ETL
Esempio:
con Session(task_name) as session:
print(session.id)
session.successful = True
session.loaded_rows = 15
session.comment = 'Ben fatto'
"""
def __init__(self, connection, task_name):
self.connection = connection
self.connection.autocommit = True
self._task_name = task_name
self._id = None
self.loaded_rows = None
self.successful = None
self.comment = None
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_val, exc_tb):
if any(exc_type, exc_val, exc_tb):
self.successful = False
self.comment = f'{exc_type}: {exc_val}n{exc_tb}'
print(exc_type, exc_val, exc_tb, file=stderr)
self.close()
def __repr__(self):
return (f'')
@property
def task_name(self):
return self._task_name
@property
def id(self):
return self._id
def _execute(self, query, *args):
with self.connection.cursor() as cursor:
cursor.execute(query, args)
return cursor.fetchone()[0]
def _create(self):
query = """
CREATE TABLE IF NOT EXISTS sessions (
id SERIAL NOT NULL PRIMARY KEY,
task_name VARCHAR(200) NOT NULL,
started TIMESTAMPTZ NOT NULL DEFAULT current_timestamp,
finished TIMESTAMPTZ DEFAULT current_timestamp,
successful BOOL,
loaded_rows INT,
comment VARCHAR(500)
);
"""
self._execute(query)
def open(self):
query = """
INSERT INTO sessions (task_name, finished)
VALUES (%s, NULL)
RETURNING id;
"""
self._id = self._execute(query, self.task_name)
print(self, 'aperto')
return self
def close(self):
if not self._id:
raise SessionClosedError('La sessione non è aperta')
query = """
UPDATE sessions
SET
finished = DEFAULT,
successful = %s,
loaded_rows = %s,
comment = %s
WHERE
id = %s
RETURNING id;
"""
self._execute(query, self.successful, self.loaded_rows,
self.comment, self.id)
print(self, 'chiuso',
', riuscito: ', self.successful,
', Caricato: ', self.loaded_rows,
', commento:', self.comment)
class SessionError(Exception):
pass
class SessionClosedError(SessionError):
passÈ il momento di recuperare i nostri dati da un centinaio di tabelle. Lo faremo con delle righe molto semplici:
source_conn = MsSqlHook(mssql_conn_id=src_conn_id, schema=src_schema).get_conn()
query = f"""
SELECT
id, start_time, end_time, type, data
FROM dbo.Orders
WHERE
CONVERT(DATE, start_time) = '{dt}'
"""
df = pd.read_sql_query(query, source_conn)- Con il hook otteniamo da Airflow
pymssql-connettore - Nel query applichiamo una limitazione in forma di data — il template la passerà alla funzione.
- Inseriamo il nostro query
pandas, che ci porteràDataFrame— ci sarà utile in seguito.
Utilizzo la sostituzione
{dt}al posto del parametro di query%snon perché io sia un Burattino maligno, ma perchépandasnon riesce a gestirepymssqle lo passa aparams: List, anche se lui vorrebbe tantotuple.
Nota anche che lo sviluppatorepymssqlha deciso di non supportarlo più, ed è tempo di passare apyodbc.
Vediamo cosa ha riempito Airflow negli argomenti delle nostre funzioni:
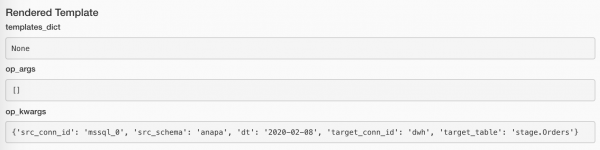
Se non ci sono dati, non ha senso continuare. Ma è anche strano considerare il caricamento riuscito. Ma non è un errore. A-a-a, cosa fare?! Ecco cosa:
if df.empty:
raise AirflowSkipException('No rows to load')AirflowSkipException Airflow dirà che non ci sono errori, e quindi saltiamo il task. Nell'interfaccia non ci sarà un quadrato verde né rosso, ma color pink.
Aggiungeremo ai nostri dati alcune colonne:
df['etl_source'] = src_schema
df['etl_id'] = session.id
df['hash_id'] = hash_pandas_object(df[['etl_source', 'id']])Cioè:
- Il database da cui abbiamo prelevato gli ordini,
- L'identificativo della nostra sessione di caricamento (questo sarà diverso per ogni task),
- Hash dell'origine e dell'identificativo dell'ordine — affinché nella base finale (dove tutto confluirebbe in un'unica tabella) abbiamo un identificatore unico dell'ordine.
Resta il penultimo passo: caricare tutto in Vertica. E, stranamente, uno dei modi più efficaci per farlo è attraverso CSV!
# Export data to CSV buffer
buffer = StringIO()
df.to_csv(buffer,
index=False, sep='|', na_rep='NUL', quoting=csv.QUOTE_MINIMAL,
header=False, float_format='%.8f', doublequote=False, escapechar='\')
buffer.seek(0)
# Push CSV
target_conn = VerticaHook(vertica_conn_id=target_conn_id).get_conn()
copy_stmt = f"""
COPY {target_table}({df.columns.to_list()})
FROM STDIN
DELIMITER '|'
ENCLOSED '"'
ABORT ON ERROR
NULL 'NUL'
"""
cursor = target_conn.cursor()
cursor.copy(copy_stmt, buffer)- Creiamo un ricevitore speciale
StringIO. pandasmetterà gentilmente dentro il nostroDataFramein forma diCSV-righe.- Apriamo una connessione con il nostro amato Vertica tramite un hook.
- E ora, con l'aiuto di
copy()invieremo i nostri dati direttamente in Vertica!
Dal driver prenderemo quante righe sono state caricate e informeremo il manager della sessione che è tutto OK:
session.loaded_rows = cursor.rowcount
session.successful = TrueEcco fatto.
In produzione creiamo manualmente la tabella di destinazione. Qui mi sono concesso un piccolo automatismo:
create_schema_query = f'CREATE SCHEMA IF NOT EXISTS {target_schema};'
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {target_schema}.{target_table} (
id INT,
start_time TIMESTAMP,
end_time TIMESTAMP,
type INT,
data VARCHAR(32),
etl_source VARCHAR(200),
etl_id INT,
hash_id INT PRIMARY KEY
);"""
create_table = VerticaOperator(
task_id='create_target',
sql=[create_schema_query,
create_table_query],
vertica_conn_id=target_conn_id,
task_concurrency=1,
dag=dag)Io con
VerticaOperator()sto creando uno schema di database e una tabella (se non esistono già, naturalmente). La cosa importante è impostare correttamente le dipendenze:
for conn_id, schema in sql_server_ds:
load = PythonOperator(
task_id=schema,
python_callable=workflow,
op_kwargs={
'src_conn_id': conn_id,
'src_schema': schema,
'dt': '{{ ds }}',
'target_conn_id': target_conn_id,
'target_table': f'{target_schema}.{target_table}'},
dag=dag)
create_table >> loadTiriamo le somme
— Ecco, — disse il topino, — non è vero che adesso
Ti sei convinto che nel bosco sono io la creatura più temibile?
Julia Donaldson, «Il Gruffalo»
Penso che se io e i miei colleghi organizzassimo una gara su chi riesce a predisporre e avviare il processo ETL da zero più in fretta: loro con i loro SSIS e il mouse e io con Airflow… E poi comparassimo anche la facilità di manutenzione… Uffa, penso che sarete d'accordo che li supererei su tutti i fronti!
Se si vuole essere un po' più seri, Apache Airflow ha reso il mio lavoro molto più semplice e gradevole grazie alla descrizione dei processi in forma di codice sorgente. molto più comodo e piacevole.
La sua espandibilità illimitata, sia in termini di plugin sia per la predisposizione alla scalabilità, consente di utilizzare Airflow in praticamente qualsiasi settore: sia nel ciclo completo di raccolta, preparazione e elaborazione dei dati, sia nel lancio di razzi (su Marte, ovviamente).
Parte conclusiva, informativa
Guaio, raccolto per voi
start_date. Sì, è già un meme locale. Attraverso l'argomento principale del DAGstart_datepassano tutti. In breve, se si specifica nellastart_datedata corrente, e nelschedule_interval— un giorno, il DAG si avvierà domani non prima.start_date = datetime(2020, 7, 7, 0, 1, 2)E non ci saranno più problemi.
È collegata anche a un'altra errore di esecuzione:
Task is missing the start_date parameter, che di solito indica che hai dimenticato di legare il DAG all'operatore.- Tutto su una sola macchina. Sì, sia il database (di Airflow e della nostra interfaccia), sia il server web, il pianificatore e i worker. E funzionava anche. Ma col tempo, il numero di compiti nei servizi è aumentato, e quando PostgreSQL ha iniziato a rispondere per indice in 20 ms invece di 5 ms, lo abbiamo rimosso.
- LocalExecutor. Sì, lo utilizziamo ancora, e siamo già arrivati al limite. Fino ad ora ci sono bastati i LocalExecutor, ma ora è tempo di espandersi con almeno un worker e dovremo imbarcarci in un viaggio per passare a CeleryExecutor. Poiché con questo è possibile lavorare anche su una sola macchina, nulla ci impedisce di utilizzare Celery anche su un server che, "naturalmente, non andrà mai in produzione, parola d'onore!"
- Non utilizzo strumenti integrati:
- Connections per memorizzare le credenziali dei servizi,
- SLA Misses per rispondere ai task che non sono stati eseguiti in tempo,
- XCom per lo scambio di metadati (ho detto metadati!) tra i task del DAG.
- Abuso della posta. E cosa dire? Erano state impostate notifiche per ogni ripetizione dei task falliti. Ora nella mia Gmail lavorativa ho più di 90k email da Airflow, e l'interfaccia web della posta si rifiuta di prenderne e rimuoverne più di 100 alla volta.
Ulteriori insidie:
Strumenti per una maggiore automazione
Per farci lavorare ancora di più con la testa e non con le mani, Airflow ha preparato per noi questo:
- — ha ancora lo status di Experimental, ma questo non impedisce il suo funzionamento. Con esso, è possibile non solo ottenere informazioni su DAG e task, ma anche fermare/avviare un DAG, creare un DAG Run o un pool.
- — tramite la riga di comando sono disponibili molti strumenti, che non sono solo scomodi da usare tramite WebUI, ma che non esistono affatto. Ad esempio:
backfillè necessario per riavviare le istanze dei task.
Ad esempio, gli analisti arrivano e dicono: «Ehi, c'è un problema con i dati dal 1 al 13 gennaio! Fai qualcosa, fai qualcosa, fai qualcosa!». E tu fai così:airflow backfill -s '2020-01-01' -e '2020-01-13' ordini- Manutenzione del database:
initdb,resetdb,upgradedb,checkdb. run, che consente di avviare un'istanza di un task, ignorando tutte le dipendenze. Inoltre, è possibile avviarlo anche tramiteLocalExecutor, anche se hai un cluster Celery.- Fa più o meno la stessa cosa
test, solo che non scrive affatto nel database. connectionspermette di creare collegamenti in massa dalla shell.
- — un modo piuttosto hardcore di interagire, che è destinato ai plugin, e non a maneggiare manualmente. Ma chi ci impedisce di andare in
/home/airflow/dags, lanciareipythone iniziare a divertirci? Ad esempio, puoi esportare tutte le connessioni con questo codice:from airflow import settings from airflow.models import Connection fields = 'conn_id conn_type host port schema login password extra'.split() session = settings.Session() for conn in session.query(Connection).order_by(Connection.conn_id): d = {field: getattr(conn, field) for field in fields} print(conn.conn_id, '=', d) - Connessione al database dei metadati di Airflow. Non consiglio di scriverci, ma recuperare gli stati dei task per metriche specifiche può essere significativamente più veloce e semplice rispetto a qualsiasi API.
Diciamo che non tutti i nostri task sono idempotenti e possono cadere talvolta, e questo è normale. Ma diversi fallimenti sono già sospetti e andrebbero verificati.
Attenzione, SQL!
WITH last_executions AS ( SELECT task_id, dag_id, execution_date, state, row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) AS rn FROM public.task_instance WHERE execution_date > now() - INTERVAL '2' DAY ), failed AS ( SELECT task_id, dag_id, execution_date, state, CASE WHEN rn = row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) THEN TRUE END AS last_fail_seq FROM last_executions WHERE state IN ('failed', 'up_for_retry') ) SELECT task_id, dag_id, count(last_fail_seq) AS unsuccessful, count(CASE WHEN last_fail_seq AND state = 'failed' THEN 1 END) AS failed, count(CASE WHEN last_fail_seq AND state = 'up_for_retry' THEN 1 END) AS up_for_retry FROM failed GROUP BY task_id, dag_id HAVING count(last_fail_seq) > 0
Link
Naturalmente, i primi dieci risultati di Google riguardano i contenuti della cartella Airflow nei miei segnalibri.
- — certo, bisogna iniziare dalla documentazione ufficiale, ma chi legge le istruzioni?
- — ma almeno leggete le raccomandazioni degli autori.
- — il punto di partenza: interfaccia utente in immagini
- — fondamentali ben descritti, nel caso (mai!) non aveste capito qualcosa da me.
- — una breve guida per configurare un cluster Airflow.
- — un articolo quasi altrettanto interessante, solo un po' più formale e con meno esempi.
- — sul lavoro in sinergia con Celery.
- — sull'idempotenza dei task, caricamento per ID invece di data, trasformazioni, struttura dei file e altre curiosità.
- — dipendenze dei task e regole di attivazione, che ho menzionato solo di sfuggita.
- — come affrontare alcuni 'funziona come previsto' del pianificatore, caricare dati mancanti e impostare le priorità dei task.
- — utili SQL query per i metadati di Airflow.
- — c'è una sezione utile sulla creazione di sensori personalizzati.
- — una nota interessante sulla costruzione di infrastrutture su AWS per Data Science.
- — errori comuni (quando qualcuno non legge le istruzioni).
- — sorridi, mentre le persone cercano soluzioni alternative per la memorizzazione delle password, mentre è possibile semplicemente usare Connections.
- — passaggio implicito del DAG, passaggio del contesto alle funzioni, di nuovo sulle dipendenze e anche sul salto delle esecuzioni delle attività.
- — sull'uso di
default argumentseparamsnei modelli, così come su Variables e Connections. - — un racconto su come il pianificatore viene preparato per Airflow 2.0.
- — un articolo leggermente datato sul deployment del nostro cluster in
docker-compose. - — attività dinamiche utilizzando modelli e passaggio di contesto.
- — avvisi standard e personalizzati via email e Slack.
- — ramificazioni delle attività, macro e XCom.
E i collegamenti utilizzati nell'articolo:
- — segnaposto disponibili per l'utilizzo nei modelli.
- — Errori frequenti nella creazione di DAG.
- —
docker-composeper esperimenti, debug e non solo. - — Wrapper Python per l'API REST di Telegram.
Fonte: habr.com
