

27 aprile alla conferenza , nel corso della sezione «DevOps», è stata presentata la relazione «Autoscaling e gestione delle risorse in Kubernetes». Qui si discute di come garantire alta disponibilità delle applicazioni e massimizzarne le prestazioni con K8s.

Seguendo la tradizione, siamo lieti di presentare (44 minuti, molto più informativo di un articolo) e il riassunto principale in formato testuale. Andiamo!
Analizziamo il tema della relazione parola per parola e iniziamo dalla fine.
Kubernetes
Immaginiamo di avere contenitori Docker sul nostro host. Perché? Per garantire ripetibilità e isolamento, che a loro volta permettono una distribuzione, CI/CD semplice e ben organizzata. Abbiamo molte di queste macchine con contenitori.
Qual è il vantaggio di Kubernetes in questo caso?
- Smettiamo di pensare a queste macchine e cominciamo a lavorare con il «cloud», un cluster di contenitori o pod (gruppi di contenitori).
- Inoltre, non pensiamo nemmeno ai singoli pod, ma gestiamo gruppi ancora più grandi. Questiunsono primitivi di alto livello primitivi di alto livello ci consentono di dire che esiste un modello per avviare un certo carico di lavoro, e il numero necessario di istanze per farlo. Se in seguito modifichiamo il modello, cambieranno anche tutte le istanze.
- Con API dichiarativa anziché eseguire una sequenza di comandi specifici, descriviamo «l'assetto del mondo» (in YAML), che viene creato da Kubernetes. E ancora: con le modifiche alla descrizione cambierà anche la rappresentazione reale.
Gestione delle risorse
CPU
Supponiamo di avviare nginx, php-fpm e mysql su un server. Questi servizi avranno in realtà anche più processi attivi, ognuno dei quali richiede risorse computazionali:
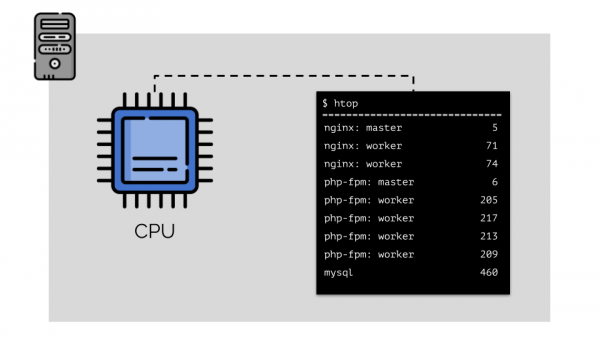
(i numeri sulla diapositiva sono «pappagalli», l'astratta necessità di ciascun processo in termini di potenza di calcolo)
Per gestirlo in modo conveniente, è logico raggruppare i processi (ad esempio, tutti i processi nginx in un gruppo «nginx»). Un modo semplice e ovvio per farlo è mettere ogni gruppo in un contenitore:
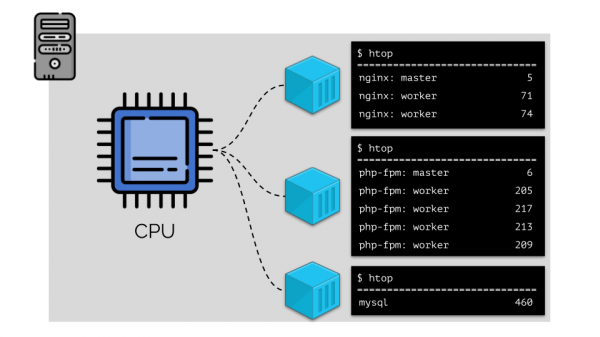
Per proseguire, è necessario ricordare cosa sia un contenitore (in Linux). La loro nascita è stata possibile grazie a tre funzionalità chiave nel kernel, implementate già da tempo: , e . E lo sviluppo successivo è stato facilitato da altre tecnologie (inclusi i comodi "wrapper" come Docker):
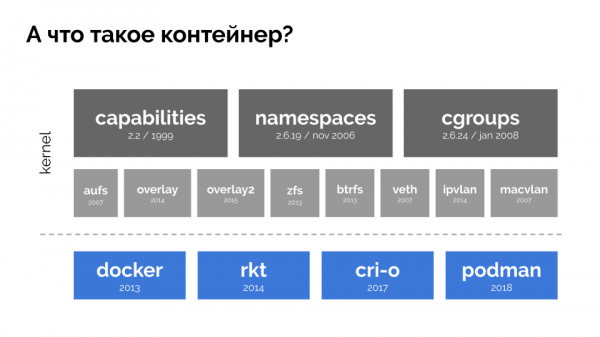
Nel contesto della relazione ci interessa solo cgroups, perché i gruppi di controllo rappresentano quella parte delle funzionalità dei contenitori (di Docker, ecc.) che implementa la gestione delle risorse. I processi raggruppati, come desideravamo, sono proprio i gruppi di controllo.
Torniamo alle esigenze di CPU di questi processi, e ora — di gruppi di processi:
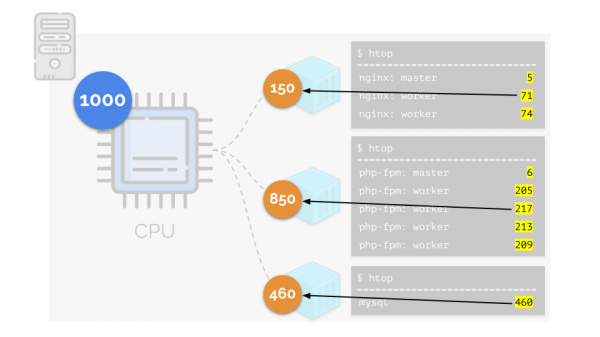
(ripeto, che tutti i numeri sono espressioni astratte delle necessità di risorse)
A questo punto, la CPU ha una certa risorsa finita (nell'esempio sono 1000), che potrebbe non bastare a tutti (la somma delle necessità di tutti i gruppi è 150+850+460=1460). Cosa succede in questo caso?
Il kernel inizia a distribuire le risorse e lo fa in modo "equo", assegnando la stessa quantità di risorse a ciascun gruppo. Ma nel primo caso ce ne sono più del necessario (333>150), quindi l'eccedenza (333-150=183) rimane in riserva, che viene poi distribuita equamente tra gli altri due contenitori:
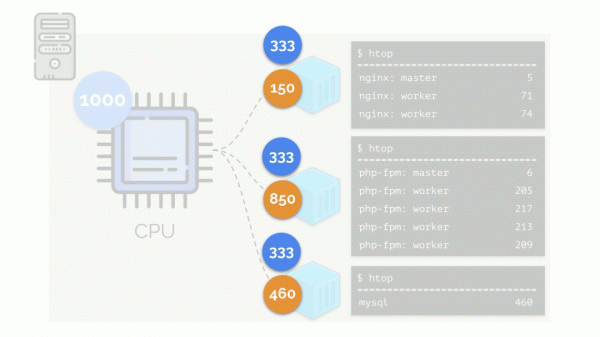
Di conseguenza: il primo contenitore ha avuto risorse sufficienti, al secondo sono mancate considerevolmente, mentre al terzo ne sono mancate lievemente. Questo è il risultato delle azioni. del pianificatore "equo" in Linux — . Il suo funzionamento può essere regolato tramite l'assegnazione di pesi a ciascuno dei contenitori. Ad esempio, in questo modo:
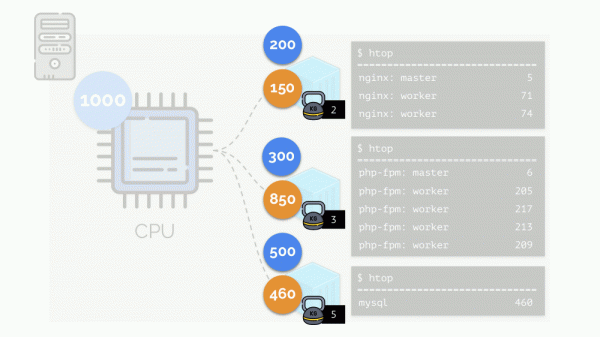
Esaminiamo il caso di mancanza di risorse nel secondo contenitore (php-fpm). Tutte le risorse del contenitore vengono distribuite uniformemente tra i processi. Di conseguenza, il processo master funziona bene, mentre tutti i worker vanno in stallo, ricevendo meno della metà di quanto necessario:
Questo è il funzionamento del pianificatore CFS. I pesi che assegniamo ai contenitori verranno successivamente chiamati request. Il motivo di questa denominazione — si veda più avanti.
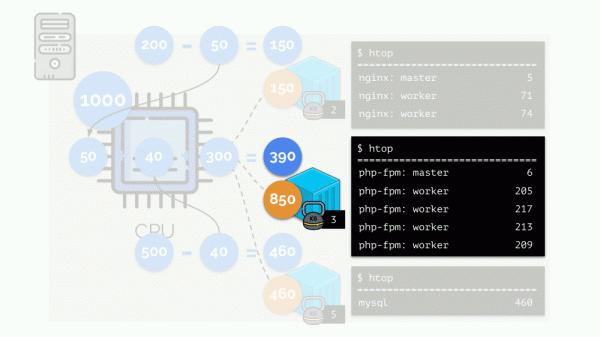
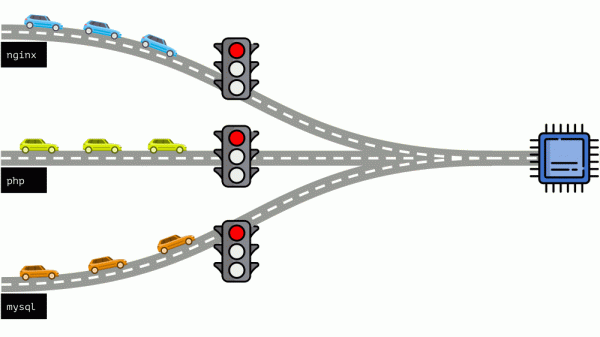
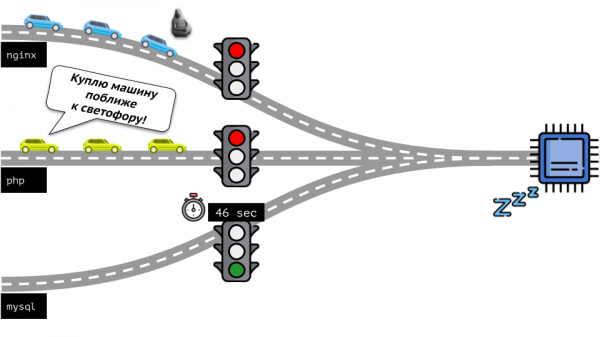
Guardiamo tutta la situazione da un'altra prospettiva. Come si suol dire, tutte le strade portano a Roma, e nel caso di un computer — alla CPU. La CPU è una, ci sono molte attività — è necessario un semaforo. Il modo più semplice per gestire le risorse è il metodo "semaforo": assegniamo a un processo un tempo fisso di accesso alla CPU, poi al successivo e così via.
Questo approccio è chiamato quotazione rigida (hard limiting). Ricordiamolo come limiti. Tuttavia, se si distribuiscono i limiti a tutti i container, si presenta un problema: MySQL ha percorso la strada e a un certo punto la sua richiesta di CPU è terminata, ma tutti gli altri processi devono attendere finché la CPU è inattiva.
Torniamo al kernel Linux e al suo rapporto con la CPU: la situazione generale è la seguente:
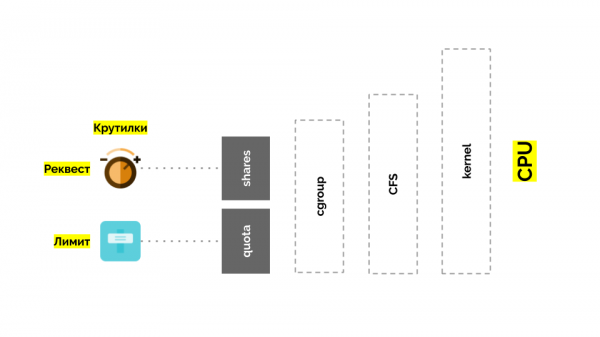
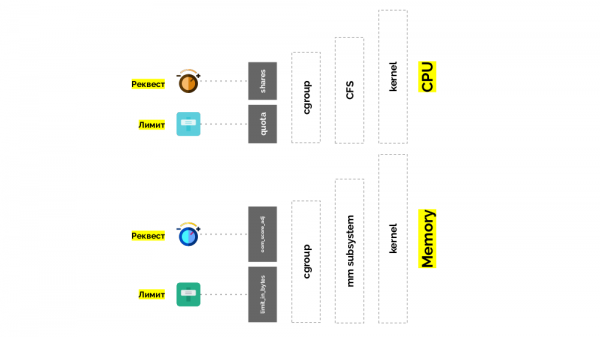
Cgroup ha due impostazioni: fondamentalmente sono due semplici "manopole" che consentono di definire:
- il peso per il container (request) — si tratta di shares;
- la percentuale del tempo totale della CPU per lavorare sui compiti del container (limits) — si tratta di quota.
Come misurare la CPU?
Ci sono diversi modi:
- Che cos'è pappagalli, nessuno lo sa: bisogna sempre accordarsi.
- Percentuali sono più chiare, ma relative: il 50% di un server con 4 core e di uno con 20 core sono cose completamente diverse.
- Si possono utilizzare già menzionati di pesi, che Linux conosce, ma anche questi sono relativi.
- L'opzione più adeguata è misurare le risorse computazionali in secondi. Cioè, in secondi di tempo di CPU rispetto ai secondi di tempo reale: se si fornisce 1 secondo di tempo di CPU in 1 secondo reale— questo è un core CPU interamente.
Per semplificare ulteriormente, si misura direttamente in core, intendendo con questo il tempo della CPU reale. Poiché Linux comprende i pesi e non il tempo della CPU/core, è stato necessario un meccanismo di conversione da uno all'altro.
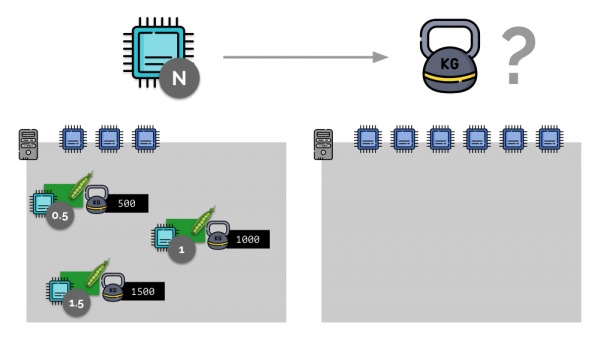
Consideriamo un semplice esempio con un server con 3 core CPU, dove ai tre pod vengono assegnati pesi (500, 1000 e 1500) che si convertono facilmente in parti corrispondenti dei core assegnati (0,5, 1 e 1,5).
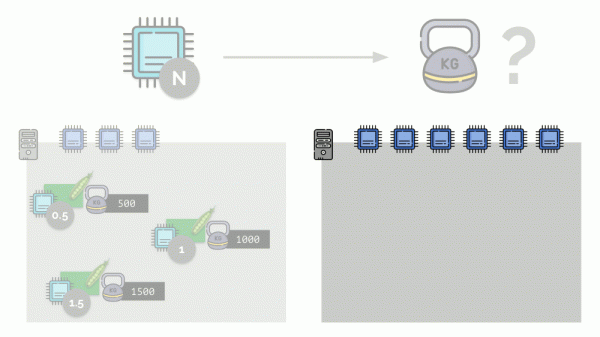
Se prendiamo un secondo server, dove i core saranno doppio (6), e posizioniamo gli stessi pod, la distribuzione dei core può essere facilmente calcolata moltiplicando per 2 (1, 2 e 3 rispettivamente). Ma un aspetto importante si verifica quando su questo server appare un quarto pod, il cui peso, per comodità, sarà 3000. Questo prende parte delle risorse CPU (metà dei core), e gli altri pod vengono ricalcolati (ridotti della metà):
Kubernetes e risorse CPU
In Kubernetes, le risorse CPU sono misurate in milliardi, cioè come peso di base si usa 0,001 core. (Lo stesso nella terminologia di Linux/cgroups è chiamato CPU share, anche se, per essere più precisi, 1000 miliardi = 1024 CPU shares.) K8s si assicura di non posizionare più pod su un server di quanti siano le risorse CPU disponibili per la somma dei pesi di tutti i pod.
Come funziona? Quando un server viene aggiunto a un cluster Kubernetes, si comunica quante CPU sono disponibili. Quando viene creato un nuovo pod, il programmatore di Kubernetes sa quante CPU serviranno a quel pod. In questo modo, il pod viene assegnato a un server con risorse sufficienti.
Cosa succede se non è specificato un request (cioè il pod non ha un numero definito di CPU necessarie)? Scopriamo come Kubernetes gestisce le risorse.
Un pod può avere sia request (il programmatore CFS) che limiti (ricorda il semaforo?):
- Se sono uguali, il pod riceve una classe QoS guaranteed. Questo numero di CPU è sempre garantito per lui.
- Se il request è inferiore al limite — la classe QoS è burstable. Cioè, ci aspettiamo che il pod utilizzi sempre 1 CPU, ma questo valore non è una limitazione per lui: a volte il pod può utilizzare di più (quando ci sono risorse disponibili sul server).
- C'è anche la classe QoS best effort — a essa appartengono quei pod per cui non è specificato un request. Le risorse vengono assegnate loro per ultime.
Memoria
La situazione con la memoria è simile, ma leggermente diversa — la natura di queste risorse è diversa. In generale, l'analogia è la seguente:
Vediamo come vengono implementate le richieste in memoria. Supponiamo che i pod vivano su un server, modificando la memoria utilizzata finché uno di essi non diventa così grande da esaurire la memoria. In questo caso, entra in azione l'OOM killer e termina il processo più grande:
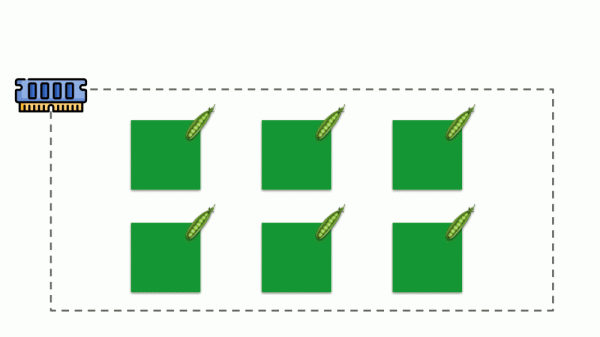
Non è sempre ciò che desideriamo, quindi abbiamo la possibilità di regolare quali processi sono importanti per noi e non dovrebbero essere terminati. A tal fine si utilizza il parametro oom_score_adj.
Torniamo alle classi QoS della CPU e facciamo un'analogia con i valori di oom_score_adj, che determinano le priorità di consumo di memoria per i pod:
- Il valore più basso di oom_score_adj per un pod è -998, il che significa che quel pod deve essere terminato per ultimo; questo è guaranteed.
- Il valore più alto, 1000, è best effort, tali pod vengono terminati per primi.
- Per calcolare i restanti valori (burstable) existe una formula, il cui principio è che più risorse richiede un pod, minori sono le probabilità che venga terminato.

La seconda "manopola" è limit_in_bytes — per i limiti. Qui è tutto più semplice: dobbiamo solo assegnare la quantità massima di memoria fornita, e qui (a differenza della CPU) non c'è la questione di come misurarla (memoria).
Totale
Ogni pod in Kubernetes riceve requests e limits — entrambi i parametri per CPU e memoria:
- il pianificatore Kubernetes opera in base alle richieste, distribuendo i pod sui server;
- in base a tutti i parametri si determina la classe QoS del pod;
- in base alle richieste CPU si calcolano i pesi relativi;
- in base alle richieste CPU si configura il pianificatore CFS;
- in base alle richieste di memoria si configura l'OOM killer;
- in base ai limiti di CPU si imposta il "semaforo";
- in base ai limiti di memoria si imposta il limite sulla cgroup.
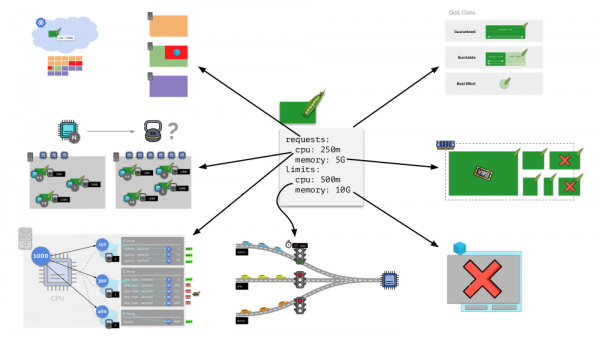
In generale, questa immagine risponde a tutte le domande su come avviene la gestione delle risorse in Kubernetes.
Autoscalamento
K8s cluster-autoscaler
Immaginiamo che l'intero cluster sia già occupato e che debba essere creato un nuovo pod. Finché il pod non può apparire, rimane in stato Pending. Per farlo apparire, possiamo collegare un nuovo server al cluster o… installare il cluster-autoscaler, che farà questo per noi: richiederà una macchina virtuale a un fornitore di servizi cloud (tramite una richiesta API) e la collegherà al cluster, dopo di che il pod sarà aggiunto.
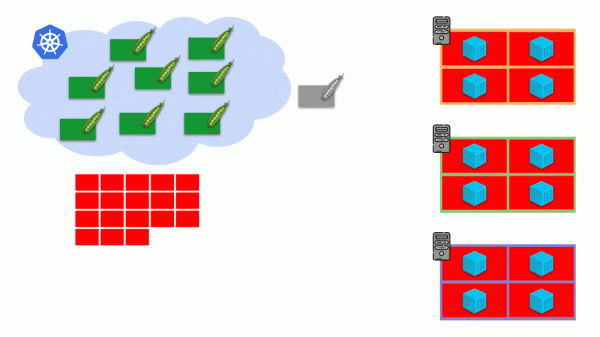
Questo è l'autoscalamento del cluster Kubernetes, che funziona magnificamente (per la nostra esperienza). Tuttavia, come in ogni cosa, ci sono delle sfide...
Mentre aumentavamo le dimensioni del cluster, tutto andava bene, ma cosa succede quando il cluster inizia a liberarsi? Проблема в том, что мигрировать pod’ы (для освобождения хостов) очень технически сложно и дорого по ресурсам. В Kubernetes работает совсем другой подход.
Consideriamo un cluster di 3 server, nel quale è presente un Deployment. Ha 6 pod: attualmente ce ne sono 2 per ciascun server. Per qualche motivo, decidiamo di spegnere uno dei server. Per farlo, utilizziamo il comando kubectl drain, che:
- vieterebbe l'invio di nuovi pod a questo server;
- eliminerebbe i pod esistenti sul server.
Poiché Kubernetes tiene traccia del mantenimento del numero di pod (6), semplicemente li ricreerà su altri nodi, ma non su quello disattivato, poiché è già contrassegnato come non disponibile per l'allocazione di nuovi pod. Questa è la meccanica fondamentale per Kubernetes.
Tuttavia, anche qui c'è un'eccezione. In una situazione simile per un StatefulSet (anziché per un Deployment), le azioni sarebbero diverse. Ora abbiamo un'applicazione stateful — ad esempio, tre pod con MongoDB, uno dei quali ha riscontrato qualche problema (i dati sono corrotti o un altro errore che impedisce il corretto avvio del pod). E decidiamo di spegnere di nuovo un server. Cosa succederà?
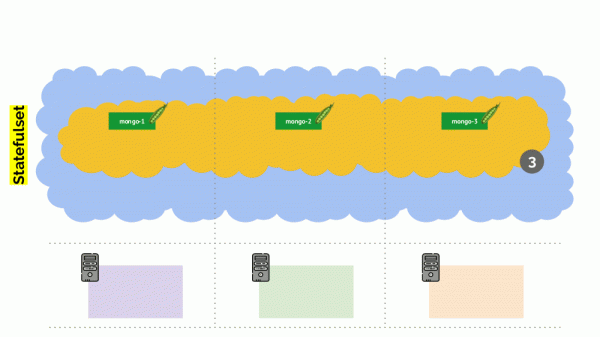
MongoDB potrebbe morire, poiché è necessario un quorum: per un cluster di tre installazioni almeno due devono funzionare. Tuttavia questo non avviene — grazie a Budget per l'Interruzione dei Pod. Questo parametro determina il numero minimo necessario di pod attivi. Sapendo che uno dei pod con MongoDB non funziona già più, e vedendo che per MongoDB nel PodDisruptionBudget è impostato minAvailable: 2, Kubernetes non permetterà di rimuovere il pod.
Conclusione: per garantire il corretto funzionamento del movimento (in realtà la ricreazione) dei pod durante il rilascio del cluster, è necessario configurare il PodDisruptionBudget.
Scalabilità orizzontale
Consideriamo un'altra situazione. C'è un'applicazione in esecuzione come Deployment in Kubernetes. I suoi pod (ad esempio, tre) ricevono traffico degli utenti e noi misuriamo un certo indicatore (diciamo, il carico della CPU) in essi. Quando il carico aumenta, lo registriamo sul grafico e aumentiamo il numero di pod per distribuire le richieste.
Oggi in Kubernetes non è necessario fare questo manualmente: si imposta un aumento/diminuzione automatico del numero di pod a seconda dei valori degli indicatori misurati del carico.
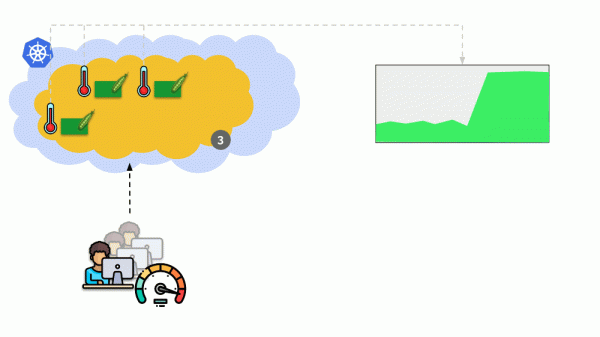
Le domande principali qui sono: cosa misurare e come interpretare valori ottenuti (per decidere se cambiare il numero di pod). Si possono misurare molte cose:

Come fare questo tecnicamente — raccogliere metriche, ecc. — l'ho spiegato in dettaglio nella mia presentazione su . E il consiglio principale per scegliere i parametri ottimali è sperimentate!
Sì (Utilization Saturation and Errors), il cui significato è il seguente. Su quale base ha senso scalare, per esempio, php-fpm? Sulla base del fatto che i worker stanno finendo — questo è utilization. E se i worker sono esauriti e non vengono accettate nuove connessioni — questo è già saturation. Entrambi questi parametri devono essere misurati e, a seconda dei loro valori, procede la scalabilità.
In conclusion
La presentazione ha un seguito: riguarda la scalabilità verticale e come selezionare correttamente le risorse. Ne parlerò in futuri video su — iscriviti per non perdere nulla!
Video e slide
Video con l'intervento (44 minuti):

Presentazione della relazione:
P.S.
Altre relazioni su Kubernetes nel nostro blog:
- «» (Andrey Polovov; 8 aprile 2019 a Saint HighLoad++);
- «» (Dmitry Stolyarov; 8 novembre 2018 a HighLoad++);
- «» (Dmitry Stolyarov; 28 maggio 2018 a RootConf);
- «» (Dmitry Stolyarov; 7 novembre 2017 a HighLoad++);
- «» (Dmitry Stolyarov; 6 giugno 2017 a RootConf).
Fonte: habr.com
