

In Ho descritto un framework per l'automazione della rete. Dai feedback di alcune persone, anche questo primo approccio al problema ha già chiarito alcune questioni. Questo mi rende molto felice, perché il nostro obiettivo nel ciclo non è semplicemente coprire Ansible con script Python, ma costruire un sistema.
Questo stesso framework definisce l'ordine con cui affronteremo la questione.
E la virtualizzazione della rete, di cui si parla in questo numero, non si inserisce particolarmente nel tema dell'ADSM, dove trattiamo l'automazione.
Ma diamo un'occhiata da un'altra prospettiva.
Già da tempo molteplici servizi utilizzano una sola rete. Nel caso di un operatore di telecomunicazioni, si parla di 2G, 3G, LTE, banda larga fissa e B2B, ad esempio. Nel caso di un data center: connettività per diversi clienti, Internet, archiviazione a blocchi, archiviazione a oggetti.
E tutti i servizi richiedono isolamento reciproco. Così sono nate le reti overlay.
E tutti i servizi non vogliono aspettare che una persona li configuri manualmente. Così sono nati gli orchestratori e il SDN.
Un primo approccio all'automazione sistematica della rete, più precisamente di una sua parte, è stato intrapreso da tempo ed è stato implementato in molti contesti: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Oggi ci concentreremo su di esso.
Contenuto
- Motivi
- Terminologia
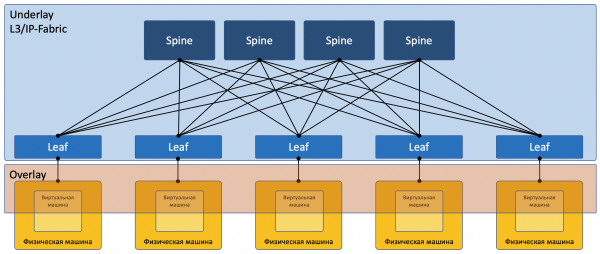
- Underlay — rete fisica
- Overlay — rete virtuale
- Overlay da ToR
- Overlay da host
- Prendiamo come esempio Tungsten Fabric
- Comunicazione all'interno di una macchina fisica
- Comunicazione tra VM situate su macchine fisiche diverse
- Uscita nel mondo esterno
- FAQ
- Conclusione
- Link utili
Motivi
E dato che stiamo parlando di questo, è opportuno menzionare le premesse per la virtualizzazione di rete. In realtà, questo processo è iniziato da un bel po'.
Probabilmente avrete sentito dire più volte che la rete è sempre stata la parte più inerte di qualsiasi sistema. E in ogni senso è vero. La rete è la base su cui si regge tutto, e apportare modifiche ad essa è piuttosto complicato: i servizi non tollerano che la rete sia inattiva. Spesso la disattivazione di un nodo può influenzare gran parte delle applicazioni e colpire molti clienti. È in parte per questo che il team di rete potrebbe resistere a qualsiasi cambiamento — perché ora funziona in un certo modo (potremmo anche non sapere come), e ora bisogna configurare qualcosa di nuovo, e non è chiaro come influenzerà la rete.
Per evitare di attendere che gli operatori di rete configurino il VLAN e di non dover configurare ogni servizio su ciascun nodo della rete, le persone hanno inventato di utilizzare overlay — reti sovrapposte — di cui esiste un'ampia varietà: GRE, IPinIP, MPLS, MPLS L2/L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE, ecc.
La loro attrattiva risiede in due semplici aspetti:
- Si configurano solo i nodi finali — i nodi di transito non devono essere toccati. Questo accelera notevolmente il processo e a volte consente di escludere del tutto il team dell'infrastruttura di rete dal processo di attivazione di nuovi servizi.
- Il carico è nascosto profondamente all'interno degli header — i nodi di transito non hanno bisogno di sapere nulla al riguardo, né sull'indirizzamento degli host, né sulle rotte della rete sovrapposta. Ciò significa che si deve memorizzare meno informazione nelle tabelle, il che consente di utilizzare dispositivi più semplici/economici.
In questa emissione non del tutto completa, non intendo analizzare tutte le tecnologie possibili, ma piuttosto descrivere il framework del funzionamento delle reti overlay nei data center.
L'intera serie descriverà un data center composto da file di rack omogenei, all'interno dei quali è installato lo stesso tipo di hardware server.
Su questa attrezzatura vengono eseguite macchine virtuali/container/serve-less che implementano servizi.

Terminologia
Nel ciclo server mi riferirò al programma che gestisce il lato server della comunicazione client-server.
Le macchine fisiche nei rack vengono chiamate server non lo faremo.
Macchina fisica è un computer x86 installato in un rack. Il termine più comunemente usato è host. E così la chiameremo «macchina» oppure host.
Ipervisore è un'applicazione eseguita su una macchina fisica che emula le risorse fisiche su cui vengono avviate le Macchine Virtuali. A volte nella letteratura e in rete la parola «ipervisore» viene usata come sinonimo di «host».
Macchina virtuale è un sistema operativo in esecuzione su una macchina fisica sopra l'ipervisore. Per noi, nell'ambito di questo ciclo, non è così importante se si tratta realmente di una macchina virtuale o semplicemente di un container. La chiameremo «VM«
Tenant è un concetto ampio, che definirò in questo articolo come un servizio separato o un cliente separato.
Multi-tenancy o multi-tenancy — utilizzo della stessa applicazione da parte di diversi clienti/servizi. In questo caso, l'isolamento tra i clienti è raggiunto grazie all'architettura dell'applicazione, e non tramite istanze separate.
ToR — switch Top of the Rack — uno switch installato nell'armadio, al quale sono collegate tutte le macchine fisiche.
Oltre alla topologia ToR, diversi fornitori praticano l'End of Row (EoR) oppure il Middle of Row (anche se quest'ultimo è raramente utilizzato e non ho mai incontrato l'abbreviazione MoR).
rete Underlay o rete fisica o underlay — infrastruttura di rete fisica: switch, router, cavi.
rete Overlay o rete virtuale o overlay — rete virtuale di tunnel che funziona sopra quella fisica.
fabbrica L3 o fabbrica IP — un'invenzione straordinaria dell'umanità, che consente di non ripetere STP e di non studiare TRILL durante i colloqui. Concetto in cui tutta la rete, fino al livello di accesso, è puramente L3, senza VLAN e di conseguenza enormi domini di broadcast allungati. Spiegheremo il termine «fabbrica» nella parte successiva.
SDN — Software Defined Network. Non ha bisogno di presentazioni. È un approccio alla gestione della rete in cui le modifiche vengono apportate non da una persona, ma da un programma. Di solito implica il trasferimento del Control Plane al di fuori dei dispositivi di rete finali a un controller.
NFV — Network Function Virtualization — virtualizzazione dei dispositivi di rete, che implica che alcune funzioni della rete possono essere eseguite come macchine virtuali o contenitori per accelerare l'implementazione di nuovi servizi, organizzare Service Chaining e garantire una scalabilità orizzontale più semplice.
VNF — Virtual Network Function. Un dispositivo virtuale specifico: router, switch, firewall, NAT, IPS/IDS, ecc.
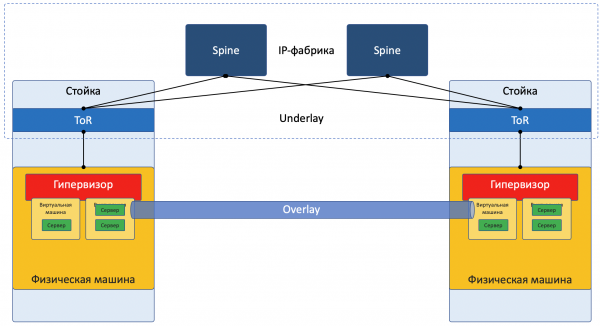
Sto semplificando intenzionalmente la descrizione a una realizzazione specifica per non confondere troppo il lettore. Per una lettura più approfondita, rimando alla sezione . Inoltre, Roma Gorge, che critica questo articolo per imprecisioni, promette di scrivere un numero separato sulle tecnologie di virtualizzazione dei server e delle reti, con maggiore attenzione ai dettagli.
La maggior parte delle reti oggi può essere chiaramente divisa in due parti:
Underlay — rete fisica con configurazione stabile.
Overlay — astrazione sopra l'Underlay per l'isolamento dei tenant.
Questo è vero sia per il caso del DC (che analizzeremo in questo articolo), sia per l'ISP (che non tratteremo, perché già affrontato in ). Con le reti enterprise, ovviamente, la situazione è un po' diversa.
Immagine con focus sulla rete:
Underlay
L'Underlay è una rete fisica: switch hardware e cavi. I dispositivi nell'Underlay sanno come raggiungere le macchine fisiche.
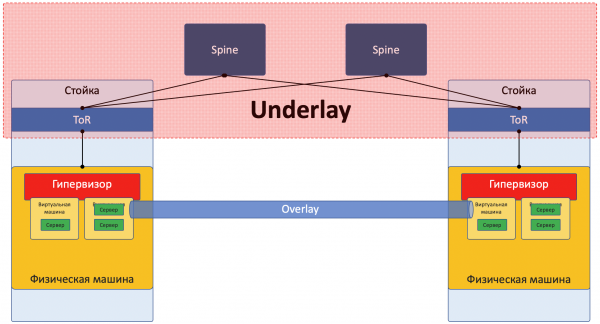
Si basa su protocolli e tecnologie standard. Non da ultimo perché i dispositivi hardware continuano a utilizzare software proprietario, che non consente né la programmazione dei chip né l'implementazione dei propri protocolli; pertanto, è necessaria la compatibilità con altri fornitori e la standardizzazione.
Ma qualcuno come Google può permettersi di sviluppare switch propri e rinunciare ai protocolli standard. Ma LAN_DC non è Google.
L'Underlay cambia relativamente raramente, perché il suo compito è la connettività IP di base tra macchine fisiche. L'Underlay non sa nulla dei servizi, clienti o tenant in esecuzione sopra di esso: deve solo consegnare il pacchetto da una macchina all'altra.
L'Underlay può essere ad esempio così:
- IPv4+OSPF
- IPv6+ISIS+BGP+L3VPN
- L2+TRILL
- L2+STP
La rete Underlay si configura in modo classico: CLI/GUI/NETCONF.
Manualmente, tramite script o strumenti proprietari.
La prossima articolo del ciclo sarà dedicata in maniera più approfondita all'underlay.
Overlay
L'Overlay è una rete virtuale di tunnel stesa sopra l'Underlay, che consente alle VM di un cliente di comunicare tra di loro, garantendo al contempo l'isolamento dagli altri clienti.
I dati del cliente sono incapsulati in intestazioni di tunneling per essere trasmessi attraverso la rete condivisa.
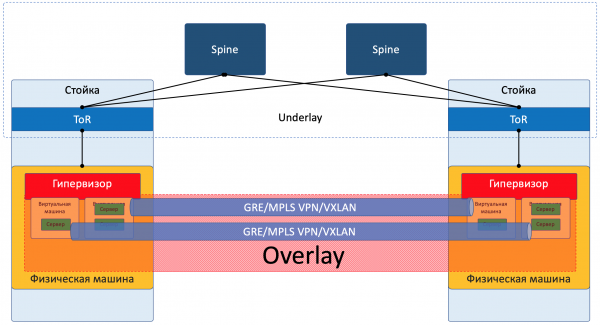
In questo modo, le VM di un cliente (di un servizio) possono comunicare tra loro tramite l'Overlay, senza nemmeno sospettare quale percorso stia realmente seguendo il pacchetto.
L'Overlay può essere ad esempio tale, come ho già accennato sopra:
- Tunnel GRE
- VXLAN
- EVPN
- L3VPN
- GENEVE
La rete Overlay è di solito configurata e gestita attraverso un controller centrale. Da lì, la configurazione, il Control Plane e il Data Plane vengono inviati ai dispositivi che si occupano della routing e dell'incapsulamento del traffico del cliente. Un po' analizziamo questo con degli esempi.
Sì, questo è SDN in puro.
Esistono due approcci fondamentalmente diversi per organizzare una rete Overlay:
- Overlay da ToR
- Overlay da host
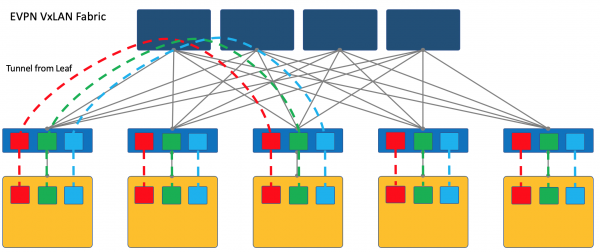
Overlay da ToR
L'overlay può iniziare su uno switch di accesso (ToR) montato in rack, come avviene nel caso di una fabbrica VXLAN.
Questo è un meccanismo collaudato nelle reti ISP e tutti i fornitori di apparecchiature di rete lo supportano.
Tuttavia, in questo caso, lo switch ToR deve essere in grado di separare i vari servizi, e l'amministratore di rete deve collaborare in qualche modo con gli amministratori delle macchine virtuali e apportare modifiche (anche automaticamente) alla configurazione dei dispositivi.
Qui rimando il lettore all'articolo su del nostro vecchio amico .
In questo dove sono descritti in dettaglio gli approcci alla costruzione di una rete DC con una fabbrica EVPN VXLAN.
Per un immersione più completa nella realtà, si può leggere il libro di Cisco .
Osservo che VXLAN è solo un metodo di incapsulamento e la terminazione dei tunnel può avvenire non sul ToR, ma sull'host, come avviene nel caso di OpenStack, per esempio.
Tuttavia, una fabbrica VXLAN dove l'overlay inizia sul ToR è uno dei design consolidati per la rete overlay.
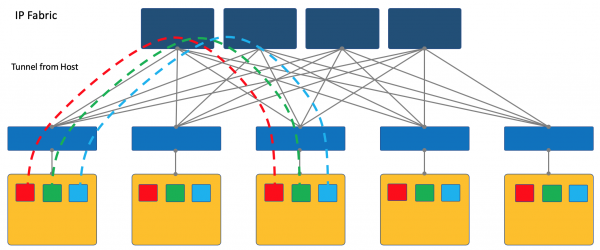
Overlay da host
Un altro approccio è iniziare e terminare i tunnel sugli host finali.
In questo caso, la rete (Underlay) rimane il più semplice e statica possibile.
Ed è l'host stesso a gestire tutte le necessarie incapsulazioni.
Per questo, sarà senza dubbio necessario eseguire un'applicazione speciale sugli host, ma ne vale la pena.
In primo luogo, avviare il client su una macchina Linux è più semplice o, diciamo, - è addirittura possibile - mentre su uno switch, probabilmente sarà necessario affidarsi a soluzioni SDN proprietarie, il che mina l'idea di multivendor.
In secondo luogo, lo switch ToR in questo caso può rimanere il più semplice possibile, sia dal punto di vista del Control Plane che del Data Plane. Infatti, con un controller SDN non deve comunicare, e non è necessario memorizzare le reti/ARP di tutti i clienti connessi - è sufficiente conoscere l'indirizzo IP della macchina fisica, il che semplifica notevolmente le tabelle di commutazione/routing.
Nella serie ADS-M, opto per l'approccio overlay dall'host - da qui in poi parleremo solo di questo e non torneremo più alla fabbrica VXLAN.
È più semplice considerarlo con esempi. E come soggetto di prova prenderemo la piattaforma SDN OpenSource OpenContrail, ora nota come .
Alla fine dell'articolo fornirò alcune riflessioni sull'analogia con OpenFlow e OpenvSwitch.
Prendiamo come esempio Tungsten Fabric
Su ogni macchina fisica ci sono vRouter — un router virtuale che è a conoscenza delle reti collegate e a quali clienti appartengono — essenzialmente — un router PE. Per ogni cliente mantiene una tabella di routing isolata (leggi VRF). E il vRouter gestisce il tunneling overlay.
Un po' più in dettaglio su vRouter — alla fine dell'articolo.
Ogni VM situata sull'ipercomprensore si connette al vRouter di quella macchina tramite .
TAP — Terminal Access Point — un'interfaccia virtuale nel kernel Linux, che consente l'interazione di rete.
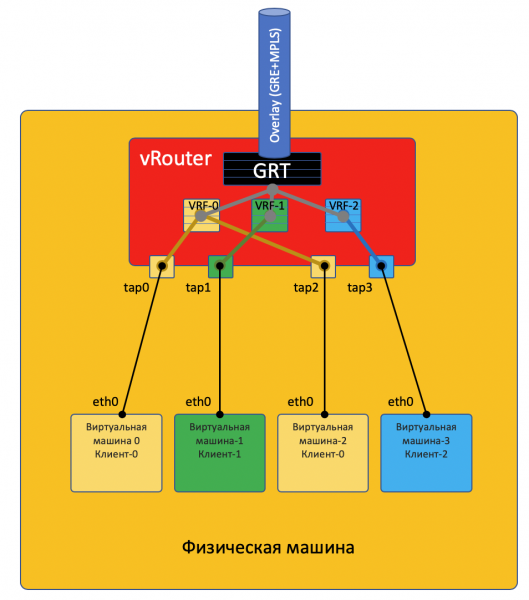
Se dietro il vRouter ci sono più reti, per ognuna di esse viene creata un'interfaccia virtuale, a cui viene assegnato un indirizzo IP — che sarà l'indirizzo del gateway predefinito.
Tutte le reti di un cliente vengono collocate in un VRF (una tabella), quelle diverse in tabelle diverse.
Voglio precisare che non è tutto così semplice, e manderò il lettore curioso alla fine dell'articolo..
Affinché i vRouter possano comunicare tra loro e, di conseguenza, le VM che si trovano dietro di essi, scambiano informazioni di routing tramite SDN-controller.
Per uscire nel mondo esterno, esiste un punto di uscita dalla matrice: il gateway della rete virtuale VNGW — Virtual Network GateWay (termino mio).
Ora consideriamo degli esempi di comunicazione — e sarà chiaro.
Comunicazione all'interno di una macchina fisica
La VM0 desidera inviare un pacchetto alla VM2. Supponiamo per ora che si tratti di VM dello stesso cliente.
Data Plane
- La VM-0 ha una route predefinita sul suo interfaccia eth0. Il pacchetto viene inviato lì.
Questa interfaccia eth0 è in realtà virtualmente connessa al vRouter tramite l'interfaccia TAP tap0. - Il vRouter analizza su quale interfaccia è arrivato il pacchetto, cioè a quale cliente (VRF) appartiene, confronta l'indirizzo del destinatario con la tabella di routing di quel cliente.
- Scoprendo che il ricevente si trova sulla stessa macchina su un'altra porta, il vRouter invia semplicemente il pacchetto a lui senza ulteriori intestazioni — in questo caso, il vRouter ha già una registrazione ARP.
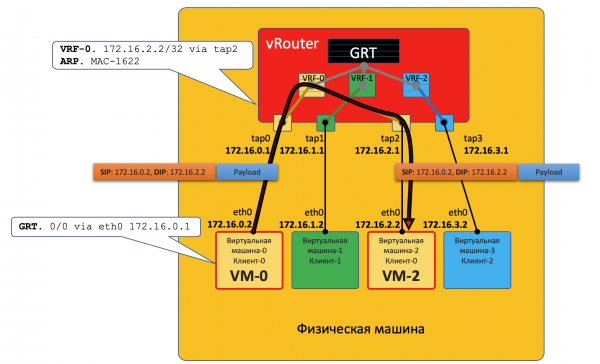
Il pacchetto, in questo caso, non entra nella rete fisica: viene instradato all'interno del vRouter.
Control Plane
Il hypervisor, al momento dell'avvio della macchina virtuale, le comunica:
- Il suo indirizzo IP.
- Il percorso predefinito passa attraverso l'indirizzo IP del vRouter in questa rete.
Il hypervisor comunica al vRouter tramite una API speciale:
- Di creare un'interfaccia virtuale.
- Quale Virtual Network deve creare per essa (VM).
- A quale VRF associarla (VN).
- Una registrazione ARP statica per questa VM — dietro quale interfaccia si trova il suo indirizzo IP e a quale indirizzo MAC è collegato.
E ancora, la reale procedura di interazione è semplificata a favore della comprensione del concetto.
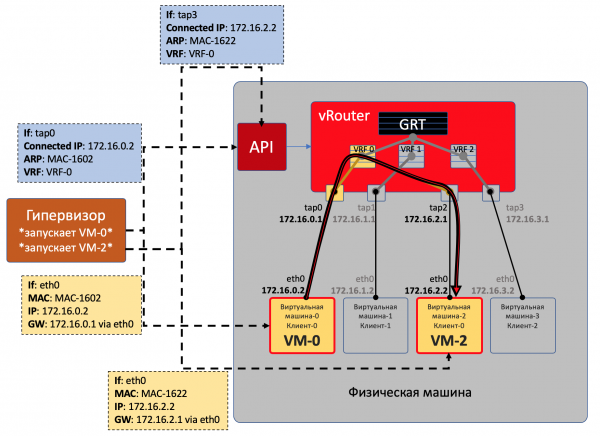
In questo modo, tutte le VM di un cliente sulla macchina vedono vRouter come reti direttamente collegate e possono instradare tra di loro.
Ma VM0 e VM1 appartengono a clienti diversi, pertanto si trovano in tabelle vRouter diverse.
Se possono comunicare direttamente dipende dalle impostazioni del vRouter e dal design della rete.
Ad esempio, se entrambe le VM dei clienti utilizzano indirizzi pubblici, o se il NAT avviene direttamente sul vRouter, può essere effettuato un instradamento diretto sul vRouter.
Nella situazione opposta, potrebbe esserci una sovrapposizione degli spazi indirizzo — è necessario passare attraverso un server NAT per ottenere un indirizzo pubblico — questo è simile a uscire verso reti esterne, come descritto sotto.
Comunicazione tra VM situate su macchine fisiche diverse
Data Plane
- L'inizio è esattamente lo stesso: VM-0 invia un pacchetto all'indirizzo VM-7 (172.17.3.2) seguendo il proprio default.
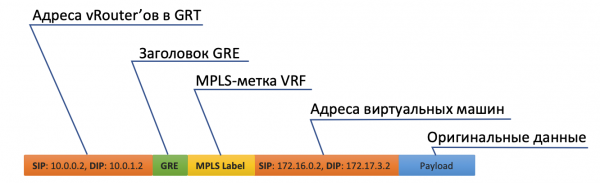
- vRouter lo riceve e questa volta vede che l'indirizzo destinatario si trova su un'altra macchina ed è accessibile tramite il tunnel Tunnel0.
- Per prima cosa, applica un'etichetta MPLS, identificando l'interfaccia remota, in modo che dall'altra parte vRouter possa determinare dove posizionare questo pacchetto senza ulteriori giri.
- Il Tunnel0 ha come sorgente 10.0.0.2 e come destinatario: 10.0.1.2.
vRouter aggiunge intestazioni GRE (o UDP) e un nuovo IP al pacchetto originale. - Nella tabella di routing, vRouter ha una route predefinita tramite l'indirizzo ToR1 10.0.0.1. È lì che lo invia.

- ToR1, come partecipante della rete Underlay, sa (ad esempio, tramite OSPF) come raggiungere 10.0.1.2 e invia il pacchetto lungo il percorso. Si noti che qui viene abilitato l'ECMP. Nell'illustrazione ci sono due next hop, e diversi flussi verranno distribuiti in essi tramite l'hash. In una vera fabbrica, ci sarebbero probabilmente 4 next hop.
Inoltre, non è necessario sapere cosa si trova sotto l'intestazione IP esterna. Cioè, di fatto, sotto l'IP potrebbero esserci stadio di IPv6 su MPLS su Ethernet su MPLS su GRE.
- Sul lato ricevente, il vRouter rimuove GRE e, in base al tag MPLS, comprende a quale interfaccia deve inviare questo pacchetto, lo decomprime e lo manda al destinatario nella sua forma originale.
Control Plane
All'avvio della macchina si svolgono tutte le operazioni già descritte sopra.
In aggiunta, ci sono anche le seguenti informazioni:
- Per ciascun cliente, il vRouter assegna un tag MPLS. Questo è un tag di servizio L3VPN, che separa i clienti all'interno della stessa macchina fisica.
In realtà, il tag MPLS viene sempre assegnato dal vRouter — non si sa in anticipo che la macchina interagirà solo con altre macchine dietro lo stesso vRouter, e probabilmente non sarà neppure così.
- Il vRouter stabilisce una connessione con il controller SDN tramite il protocollo BGP (o un protocollo simile; nel caso di TF è XMPP 0_o).
- Attraverso questa sessione, il vRouter comunica al controller SDN le route verso le reti connesse:
- Indirizzo di rete
- Metodo di incapsulamento (MPLSoGRE, MPLSoUDP, VXLAN)
- Tag MPLS del cliente
- Il suo indirizzo IP come nexthop
- Il controller SDN riceve queste route da tutti i vRouter connessi e le riflette agli altri. In altre parole, funge da Route Reflector.
Lo stesso avviene anche in senso inverso.
L'Overlay può cambiare ogni minuto. È più o meno così che funziona nei cloud pubblici, dove i clienti avviano e spengono regolarmente le loro macchine virtuali.
Il controller centrale si occupa di tutte le complessità legate alla manutenzione della configurazione e al controllo delle tabelle di commutazione/routing sul vRouter.
In termini semplici, il controller si connette a tutti i vRouter tramite BGP (o un protocollo simile) e trasmette semplicemente le informazioni di routing. Il BGP, ad esempio, dispone già di un'Address-Family per la trasmissione del metodo di incapsulamento. o .
In questo modo non viene modificata in alcun modo la configurazione della rete Underlay, che tra l'altro è di gran lunga più difficile da automatizzare e più facile da guastare con un movimento maldestro.
Uscita nel mondo esterno
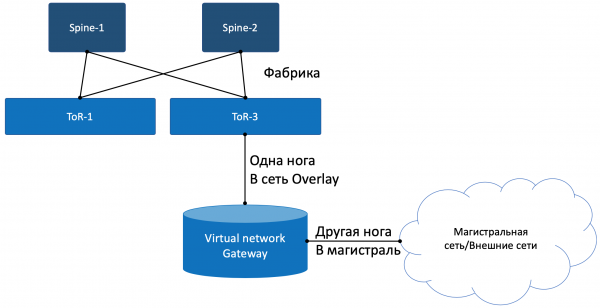
Da qualche parte la simulazione deve finire e bisogna uscire dal mondo virtuale nella realtà. E serve un gateway telefonico.
Si praticano due approcci:
- Si installa un router hardware.
- Si avvia un appliance che implementa le funzioni di un router (sì, proprio dopo l'SDN ci siamo imbattuti anche nel VNF). Lo chiameremo gateway virtuale.
Il vantaggio del secondo approccio è la scalabilità orizzontale a basso costo: se manca potenza, si può avviare un'altra macchina virtuale con un gateway. Su qualsiasi macchina fisica, senza dover cercare rack liberi, unità, uscite di alimentazione, acquistare l'hardware stesso, trasportarlo, installarlo, cablarlo, configurarlo, e poi dover sostituire anche i componenti difettosi.
Gli svantaggi del gateway virtuale sono che un'unità di un router fisico è comunque di gran lunga più potente di una macchina virtuale multicore, e il suo software, adattato alla sua stessa base hardware, funziona in modo significativamente più stabile (no). È difficile negare anche il fatto che il complesso software-hardware funzioni semplicemente, richiedendo solo configurazioni, mentre l'avvio e la manutenzione del gateway virtuale sono attività per ingegneri esperti.
Con un piede, il gateway guarda nella rete virtuale Overlay, come una normale Macchina Virtuale, e può interagire con tutte le altre VM. Può terminare le reti di tutti i clienti e, di conseguenza, effettuare il routing tra di esse.
L'altro lato del gateway è già connesso alla rete backbone e sa come accedere a Internet.
Data Plane
Quindi il processo appare così:
- VM-0, avendo il default impostato sullo stesso vRouter, invia un pacchetto a un destinatario nel mondo esterno (185.147.83.177) attraverso l'interfaccia eth0.
- Il vRouter riceve questo pacchetto e fa un lookup dell'indirizzo di destinazione nella tabella di routing, trovando il percorso predefinito attraverso il gateway VNGW1 tramite Tunnel 1.
Vede anche che si tratta di un tunnel GRE con SIP 10.0.0.2 e DIP 10.0.255.2, e che deve prima applicare il tag MPLS di questo cliente, che VNGW1 si aspetta. - Il vRouter incapsula il pacchetto originale con le intestazioni MPLS, GRE e un nuovo IP, e lo invia all'indirizzo ToR1 10.0.0.1 come predefinito.
- La rete sottesa consegna il pacchetto al gateway VNGW1.
- Il gateway VNGW1 rimuove le intestazioni di tunneling GRE e MPLS, vede l'indirizzo di destinazione, consulta la sua tabella di routing e comprende che è diretto verso Internet, quindi attraverso Full View o Default. Se necessario, esegue la traduzione NAT.
- Tra VNGW e il border potrebbe esserci una rete IP normale, anche se è poco probabile.
Potrebbe esserci una rete MPLS classica (IGP+LDP/RSVP TE), oppure una factory inversa con BGP LU o un tunnel GRE da VNGW al border attraverso una rete IP.
In ogni caso, VNGW1 esegue le necessarie incapsulazioni e invia il pacchetto iniziale verso il border.
Il traffico nella direzione opposta segue gli stessi passaggi in ordine inverso.
- Il border trasferisce il pacchetto a VNGW1
- Quest'ultimo lo smistola, controlla l'indirizzo di destinazione e vede che è accessibile tramite il tunnel Tunnel1 (MPLSoGRE o MPLSoUDP).
- Pertanto, applica un'etichetta MPLS, un'intestazione GRE/UDP e un nuovo IP, inviandolo al suo ToR3 10.0.255.1.
L'indirizzo di destinazione del tunnel è l'indirizzo IP del vRouter, dietro il quale si trova la VM di destinazione: 10.0.0.2. - La rete sottostante consegna il pacchetto al vRouter corretto.
- Il vRouter di destinazione rimuove lo GRE/UDP, determina l'interfaccia tramite l'etichetta MPLS e invia il pacchetto IP puro alla sua interfaccia TAP, collegata ad eth0 della VM.
Control Plane
VNGW1 stabilisce una vicinanza BGP con il controller SDN, dal quale riceve tutte le informazioni di routing sui clienti: quale IP (vRouter) corrisponde a quale cliente e con quale etichetta MPLS viene identificato.
Analogamente, comunica al controller SDN la route predefinita con l'etichetta di quel cliente, indicando se stesso come nexthop. Successivamente, questa rotta predefinita arriva ai vRouter.
Solitamente, su VNGW avviene l'aggregazione delle rotte o la traduzione NAT.
E in un altro senso, nella sessione con border o Route Reflector, fornisce proprio questo percorso aggregato. Da loro riceve un percorso predefinito o Full-View, o qualcos'altro.
In termini di incapsulamento e scambio di traffico, VNGW non si differenzia da vRouter.
Se allarghiamo un po' l'ambito, a VNGW e vRouter possiamo aggiungere altri dispositivi di rete, come firewall, farm di pulizia o arricchimento del traffico, IPS e così via.
E attraverso la creazione sequenziale di VRF e un corretto annuncio dei percorsi, possiamo costringere il traffico a girare come vogliamo, un fenomeno noto come Service Chaining.
Quindi anche qui l'SDN-controller funge da Route-Reflector tra VNGW, vRouter e altri dispositivi di rete.
Ma in realtà il controller fornisce ulteriori informazioni su ACL e PBR (Policy Based Routing), costringendo flussi di traffico specifici a seguire percorsi non determinati dalla rotta.
FAQ
Perché continui a fare il riferimento a GRE/UDP?
Beh, in realtà, questo si può dire essere specifico per Tungsten Fabric — si può anche ignorare del tutto.
Ma se si considera, lo stesso TF, essendo ancora OpenContrail, ha supportato entrambe le incapsulazioni: MPLS in GRE e MPLS in UDP.
UDP è vantaggioso perché nel suo header il Source Port può facilmente codificare una funzione hash derivante da IP+Proto+Port originali, consentendo così il bilanciamento.
Nel caso di GRE, purtroppo, ci sono solo gli header esterni IP e GRE che sono identici per tutto il traffico incapsulato, e quindi non si parla di bilanciamento — pochi possono guardare così in profondità dentro il pacchetto.
Fino a poco tempo fa, i router sapevano gestire tunnel dinamici solo in MPLSoGRE, e solo di recente hanno imparato a gestire MPLSoUDP. Pertanto, è sempre necessario fare una nota sulla possibilità di due diverse incapsulazioni.
A dire il vero, va notato che TF supporta perfettamente anche la connettività L2 tramite VXLAN.
Hai promesso di fare dei parallelismi con OpenFlow.
E in effetti si prestano bene. vSwitch nello stesso OpenStack fa cose molto simili, utilizzando VXLAN, che, tra l'altro, ha anch'esso un header UDP.
Nel Data Plane funzionano più o meno allo stesso modo, mentre il Control Plane differisce significativamente. Tungsten Fabric utilizza XMPP per la consegna delle informazioni sulle rotte al vRouter, mentre in OpenStack funziona Openflow.
Posso avere un po' più di informazioni sul vRouter?
Si divide in due parti: vRouter Agent e vRouter Forwarder.
Il primo si avvia nello User Space del sistema operativo host e comunica con il controller SDN, scambiando informazioni su rotte, VRF e ACL.
Il secondo implementa il Data Plane — di solito nello Kernel Space, ma può essere eseguito anche su SmartNIC, schede di rete con CPU e un chip programmabile separato per lo switching, permettendo così di ridurre il carico sulla CPU della macchina host e rendere la rete più veloce e prevedibile.
È inoltre possibile che il vRouter sia un'applicazione DPDK nello User Space.
L'agente vRouter trasferisce le impostazioni al vRouter Forwarder.
Che cos'è una Virtual Network?
Ho menzionato all'inizio dell'articolo il VRF, affermando che ogni tenant è collegato al proprio VRF. E se per una comprensione superficiale del funzionamento della rete overlay questo era sufficiente, già nella successiva iterazione è necessario fare delle precisazioni.
In genere, nelle architetture di virtualizzazione, l'entità Virtual Network (che può essere considerata un nome proprio) è introdotta separatamente dai clienti/tenant/macchine virtuali, diventando in effetti un'entità autonoma. Questa Virtual Network può essere collegata, tramite interfacce, a un tenant, a un altro, a due, o ovunque si desideri. È così, ad esempio, che si realizza il Service Chaining, quando il traffico deve passare attraverso nodi specifici in un ordine prestabilito, creando semplicemente la corretta sequenza e associando le Virtual Network.
Pertanto, non esiste una corrispondenza diretta tra Virtual Network e tenant.
Conclusione
Questa è una descrizione piuttosto superficiale del funzionamento della rete virtuale con overlay dal host e del controller SDN. Ma qualunque piattaforma di virtualizzazione prendiate oggi, funzionerà in modo simile, sia essa VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric o Juniper Contrail. Queste si differenzieranno per i tipi di incapsulamenti e intestazioni, protocollo di consegna delle informazioni ai dispositivi di rete finali, ma il principio di una rete overlay programmabile che opera su una rete sottostante relativamente semplice e statica rimarrà invariato.
Si può dire che nel campo della creazione di un cloud privato, oggi la SDN basata su overlay ha prevalso. Tuttavia, ciò non significa che OpenFlow non abbia un posto nel mondo moderno: viene utilizzato in OpenStack e in VMware NSX, e, per quanto ne so, Google lo utilizza per configurare la rete underlay.
Qui sotto ho fornito link a materiali più dettagliati, se desideri approfondire l'argomento.
E riguardo il nostro Underlay?
In realtà, nulla di che. È rimasto invariato. Tutto ciò che deve fare in caso di overlay da un host è aggiornare le route e gli ARP man mano che i vRouter/VNGW compaiono e scompaiono e instradare i pacchetti tra di essi.
Formuliamo un elenco di requisiti per la rete Underlay.
- Supportare un protocollo di routing, nella nostra situazione — BGP.
- Avere una larghezza di banda ampia, preferibilmente senza sovraccarico, per evitare la perdita di pacchetti a causa di congestioni.
- Supportare ECMP — è parte integrante della fabbrica.
- Essere in grado di garantire QoS, inclusi aspetti complessi come l'ECN.
- Supportare NETCONF — un investimento per il futuro.
Ho dedicato poco tempo al lavoro della rete Underlay qui. Questo perché, più avanti nella serie, mi concentrerò proprio su di essa, mentre toccheremo l'Overlay solo marginalmente.
È evidente che mi sto limitando molto, utilizzando come esempio la rete DC costruita nella fabbrica di Kloza con instradamento IP puro e overlay dall'host.
Tuttavia, sono sicuro che qualsiasi rete con un design può essere descritta in termini formali e automatizzata. La mia intenzione qui è semplicemente quella di comprendere gli approcci all'automazione, e non confondere tutti risolvendo il problema in termini generali.
Nell'ambito dell'ADSM, insieme a Roman Gorge, prevediamo di pubblicare un numero separato sulla virtualizzazione delle risorse computazionali e la sua interazione con la virtualizzazione della rete. Rimanete in contatto.
Link utili
- .
- . 6 ore su Yandex.Cloud, dove si parla anche della rete virtuale su TF.
- .
- . Qui si parla dell'intera rete DC, compresi Underlay, Overlay, approcci al multi-homing e gestione.
Grazie
- — ex-conduttore del podcast linkmeup, ora esperto di piattaforme cloud. Per i commenti e le correzioni. E non vediamo l'ora di leggere presto il suo articolo più approfondito sulla virtualizzazione.
- — mio collega ed esperto nello sviluppo di reti virtuali. Per i commenti e le correzioni.
- — mio collega ed esperto di Tungsten Fabric. Per i commenti e le correzioni.
- — illustratore di linkmeup. Per la KDPV.
- Aleksandr Limonov. Per il meme «automato».
Fonte: habr.com
