


Ciao a tutti. Lavoro come amministratore di sistema senior in OK e mi occupo del funzionamento stabile del portale. Voglio raccontarvi come abbiamo organizzato il processo di sostituzione automatica dei dischi e come abbiamo escluso l'amministratore da questo processo, sostituendolo con un bot.
Questo articolo è una sorta di traslitterazione a HighLoad+ 2018
Costruzione del processo di sostituzione dei dischi
Iniziamo con qualche numero
OK è un gigantesco servizio utilizzato da milioni di persone. È supportato da circa 7.000 server situati in 4 diversi data center. I server ospitano oltre 70.000 dischi. Se impilati, formerebbero una torre alta oltre 1 km.
I dischi rigidi sono il componente del server che si guasta più spesso. Con questi volumi, dobbiamo sostituire circa 30 dischi a settimana, e questa procedura è diventata una routine piuttosto spiacevole.

Incidenti
Nella nostra azienda è stato implementato un completo sistema di gestione degli incidenti. Ogni incidente viene registrato in Jira e poi risolto e analizzato. Se l'incidente ha avuto un impatto sugli utenti, ci riuniamo per riflettere su come reagire più rapidamente in tali situazioni, ridurre l'impatto e, naturalmente, prevenire ripetizioni.
I drive non fanno eccezione. Il loro stato è monitorato da Zabbix. Controlliamo i messaggi nel Syslog per errori di scrittura/lettura, analizziamo lo stato dei RAID HW/SW e monitoriamo il valore SMART; per gli SSD calcoliamo l'usura.
Come cambiavano i dischi in passato
Quando in Zabbix si attiva un trigger, viene creato un incidente in Jira e automaticamente assegnato agli ingegneri pertinenti nei data center. Facciamo così con tutti gli incidenti HW, cioè quelli che richiedono qualche lavoro fisico con l'attrezzatura nel data center.
L'ingegnere del data center è la persona che si occupa delle questioni relative all'hardware, responsabile dell'installazione, della manutenzione e della rimozione dei server. Appena riceve un ticket, l'ingegnere inizia a lavorare. Nelle unità di disco, sostituisce i dischi da solo. Se non ha accesso al dispositivo necessario, si rivolge agli amministratori di sistema di turno per ricevere aiuto. In primo luogo, è necessario rimuovere il disco dalla rotazione. Per fare ciò, è necessario apportare le modifiche necessarie al server, fermare le applicazioni e smontare il disco.
L'amministratore di sistema di turno, durante il proprio turno di lavoro, è responsabile del funzionamento dell'intero portale. Indaga sugli incidenti, si occupa delle riparazioni e aiuta gli sviluppatori a completare piccole attività. Non si occupa solo dei dischi rigidi.
In passato, gli ingegneri dei data center comunicavano con gli amministratori di sistema tramite chat. Gli ingegneri inviavano link ai ticket Jira, l'amministratore li esaminava e teneva un registro del lavoro in un blocco note. Tuttavia, per tali compiti le chat sono scomode: le informazioni non sono strutturate e si perdono rapidamente. Inoltre, l'amministratore poteva semplicemente allontanarsi dal computer e non rispondere alle richieste per un certo periodo, mentre l'ingegnere aspettava accanto al server con un pacco di dischi.
Ma la cosa peggiore era che gli amministratori non vedevano il quadro generale: quali incidenti relativi ai dischi esistevano e dove potevano potenzialmente sorgere problemi. Questo è dovuto al fatto che tutti gli incidenti HW vengono gestiti dagli ingegneri. Sì, sarebbe stato possibile visualizzare tutti gli incidenti nella dashboard dell'amministratore. Ma ce ne sono troppi, e l'amministratore veniva coinvolto solo in alcuni di essi.
Inoltre, l'ingegnere non poteva stabilire correttamente le priorità, perché non sapeva nulla riguardo allo scopo dei singoli server e alla distribuzione delle informazioni sui dischi.
Nuova procedura di sostituzione
La prima cosa che abbiamo fatto è stata separare tutti gli incidenti relativi ai disco in un tipo specifico chiamato «HW-disco» e aggiungere i campi «nome del dispositivo a blocchi», «dimensione» e «tipo di disco», in modo che queste informazioni vengano conservate nel ticket, evitando di doverle continuamente scambiare in chat.
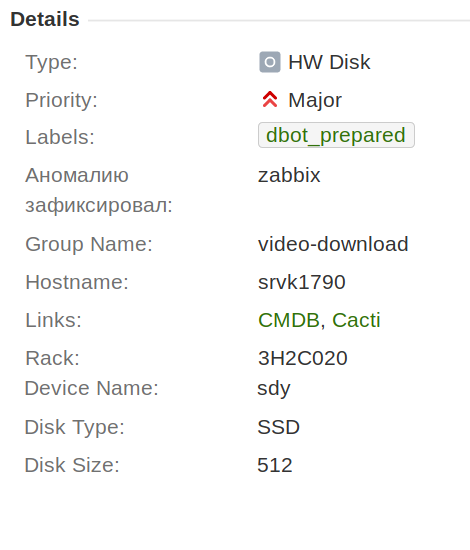
Inoltre, abbiamo concordato che all'interno di un singolo incidente verrà sostituito solo un disco. Questo ha semplificato notevolmente in seguito il processo di automazione, la raccolta di statistiche e il lavoro.
In aggiunta, abbiamo aggiunto il campo «amministratore responsabile». In questo campo viene automaticamente inserito il sistemista di turno. È molto comodo, perché ora l'ingegnere vede sempre chi è responsabile. Non è necessario controllare il calendario alla ricerca. Proprio questo campo ha permesso di portare nella dashboard dell'amministratore i ticket in cui potrebbe essere necessaria la sua assistenza.
Per garantire che tutti i partecipanti possano trarre il massimo beneficio dalle innovazioni, abbiamo creato filtri e dashboard, e li abbiamo presentati ai ragazzi. Quando le persone comprendono i cambiamenti, non si allontanano da essi come da qualcosa di superfluo. Per un ingegnere è importante sapere il numero del rack in cui si trova il server, le dimensioni e il tipo di disco. Un amministratore deve prima di tutto capire di che gruppo di server si tratta e quale può essere l'effetto della sostituzione del disco.
Avere dei campi e la loro visualizzazione è comodo, ma non ci ha liberato dalla necessità di utilizzare le chat. Per questo abbiamo dovuto modificare il flusso di lavoro.
Prima era così:
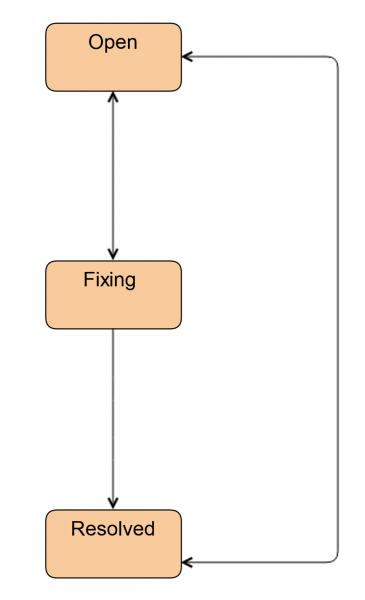
Oggi gli ingegneri continuano a lavorare in questo modo, quando non hanno bisogno dell'aiuto di un amministratore.
La prima cosa che abbiamo fatto è stata introdurre un nuovo stato Investigate. In questo stato il ticket si trova Quando l'ingegnere non ha ancora deciso se avrà bisogno di un amministratore o meno. Attraverso questo stato, l'ingegnere può trasferire il ticket all'amministratore. Inoltre, usiamo questo stato per contrassegnare i ticket quando è necessaria la sostituzione del disco, ma il disco stesso non è disponibile in sede. Questo accade nel caso di CDN e sites remoti.
Abbiamo anche aggiunto uno stato Pronto. Il ticket viene trasferito dopo la sostituzione del disco. Cioè, tutto è già stato fatto, ma il RAID HW/SW è in sincronizzazione sul server. Questo può richiedere parecchio tempo.
Se è coinvolto un amministratore, lo schema diventa un po' più complesso.
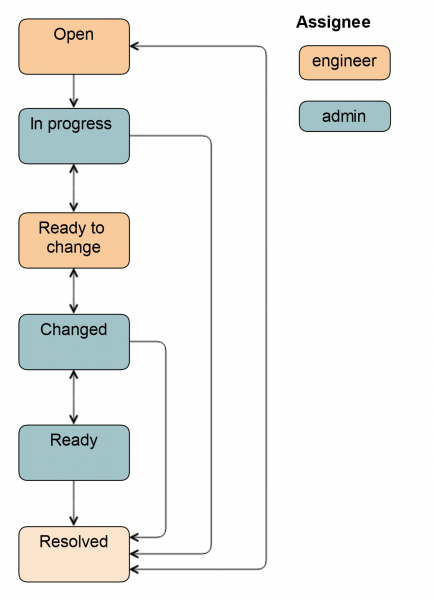
Dallo stato Aperto il ticket può essere trasferito sia da un amministratore di sistema che da un ingegnere. Nell stato In corso l'amministratore estrae il disco dalla rotazione in modo che l'ingegnere possa semplicemente rimuoverlo: attiva l'illuminazione, smonta il disco, ferma le applicazioni, a seconda del particolare gruppo di server.
Poi il ticket viene trasferito in Pronto per la sostituzione: questo è un segnale per l'ingegnere che il disco può essere estratto. Tutti i campi in Jira sono già compilati, e l'ingegnere sa quale tipo e dimensione di disco. Questi dati vengono inseriti automaticamente nello stato precedente o dall'amministratore.
Dopo la sostituzione del disco, il ticket viene trasferito nello stato Modificato. Si verifica che sia stato inserito il disco corretto, vengono effettuate le etichette, viene avviata l'applicazione e alcune attività di ripristino dei dati. Inoltre, il ticket può essere trasferito nello stato Pronto, in questo caso l'amministratore rimarrà responsabile, poiché è stato lui a inserire il disco nella rotazione. Lo schema completo appare così.
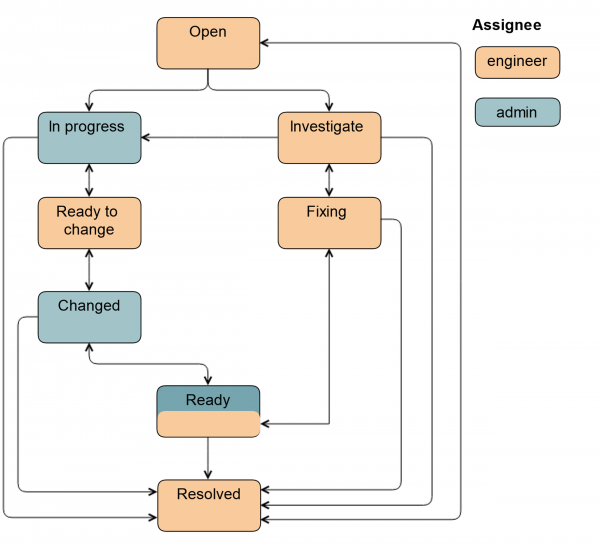
L'aggiunta di nuovi campi ha reso la nostra vita molto più facile. I ragazzi ora lavorano con informazioni strutturate, ed è chiaro cosa e in quale fase deve essere fatto. Le priorità sono diventate molto più rilevanti, poiché ora vengono stabilite dall'amministratore.
Non c'è più bisogno di chat. Certo, l'amministratore può chiedere all'ingegnere "qui bisogna sostituire più rapidamente" o "è già sera, riesci a sostituire?". Ma non ci comunichiamo più quotidianamente su queste questioni nelle chat.
I dischi sono stati sostituiti in blocchi. Se l'amministratore arriva al lavoro un po' prima, ha del tempo libero e non è successo nulla, può preparare una serie di server per la sostituzione: impostare i campi, rimuovere i dischi dalla rotazione e trasferire il compito all'ingegnere. L'ingegnere arriva un po' dopo nel data center, vede il compito, prende i necessari dispositivi dal magazzino e li sostituisce immediatamente. Di conseguenza, la velocità della sostituzione è aumentata.
Le esperienze acquisite nella costruzione del Workflow
- Nella costruzione della procedura è necessario raccogliere informazioni da fonti diverse.
Alcuni dei nostri amministratori non sapevano che l'ingegnere cambiava i dischi da solo. Alcuni pensavano che la sincronizzazione del RAID MD fosse monitorata dagli ingegneri, anche se alcuni di loro non avevano nemmeno accesso a questo. Alcuni ingegneri senior lo facevano, ma non sempre, perché il processo non era documentato da nessuna parte. - La procedura deve essere semplice e comprensibile.
È difficile per una persona tenere a mente molti passaggi. Gli stati più importanti e vicini in Jira devono essere visualizzati sulla schermata principale. Possono essere rinominati, ad esempio, In progress lo chiamiamo Pronto per cambiare. Gli altri stati possono essere nascosti in un menu a discesa, in modo che non siano di disturbo. Ma è meglio non limitare le persone e dare loro la possibilità di fare transizioni.
Spiegate il valore delle innovazioni. Quando le persone capiscono, accettano meglio la nuova procedura. Per noi era molto importante che le persone non cliccassero tutto il processo, ma lo seguissero. Poi abbiamo costruito l'automazione su questo. - Aspettare, analizzare, capire.
Ci sono voluti circa un mese per costruire la procedura, realizzare l'implementazione tecnica, incontrarci e discutere. L'implementazione ha richiesto più di tre mesi. Ho visto come le persone hanno iniziato lentamente a utilizzare la novità. All'inizio c'era molta negatività. Ma ciò non dipendeva affatto dalla procedura stessa o dalla sua implementazione tecnica. Ad esempio, un amministratore utilizzava non Jira, ma un plugin di Jira in Confluence, e alcune funzionalità non gli erano accessibili. Gli abbiamo mostrato Jira, e la produttività dell'amministratore è aumentata sia nei compiti generali che nella sostituzione dei dischi.
Automazione della sostituzione dei dischi
Ci siamo avvicinati all'automazione della sostituzione dei dischi diverse volte. Avevamo già delle bozze, degli script, ma tutti lavoravano in modalità interattiva o manuale, richiedevano un avvio. Solo dopo aver implementato la nuova procedura abbiamo capito che proprio quella ci mancava.
Poiché il processo di sostituzione è ora suddiviso in fasi, ciascuna con un responsabile e un elenco di azioni, possiamo implementare l'automazione gradualmente invece di farlo tutto in una volta. Ad esempio, la fase più semplice — Ready (verifica della sincronizzazione RAID/dati) può facilmente essere delegata a un bot. Quando il bot avrà qualche esperienza, potrà affrontare un compito più responsabilizzante — l'introduzione di un disco in rotazione, ecc.
Zoo delle configurazioni
Prima di parlare del bot, facciamo una breve escursione nel nostro zoo delle installazioni. In primo luogo, ciò è dovuto all'enorme dimensione della nostra infrastruttura. In secondo luogo, cerchiamo di selezionare la configurazione hardware ottimale per ciascun servizio. Abbiamo circa 20 modelli di hardware RAID, principalmente LSI e Adaptec, ma ci sono anche HP e DELL di diverse versioni. Ogni controller RAID ha il proprio strumento di gestione. L'insieme dei comandi e le relative uscite possono variare da versione a versione per ogni controller RAID. Dove non vengono utilizzati HW-RAID, potrebbe esserci mdraid.
Praticamente tutte le nuove installazioni vengono realizzate senza riserva disco. Cerchiamo di non utilizzare più RAID hardware e software, poiché riserviamo i nostri sistemi a livello di data center, non di server. Tuttavia, ci sono molti server legacy che devono essere supportati.
In alcuni casi, i dischi nei controller RAID vengono utilizzati come dispositivi raw, in altri si utilizza JBOD. Ci sono configurazioni con un solo disco di sistema nel server, e se deve essere sostituito, è necessario reinstallare il server con l'installazione del sistema operativo e delle applicazioni, utilizzando le stesse versioni, poi aggiungere i file di configurazione e avviare le applicazioni. Ci sono anche molti gruppi di server dove la riserva viene effettuata non a livello del subsistema disco, ma direttamente all'interno delle applicazioni stesse.
In totale, abbiamo oltre 400 gruppi unici di server, su cui operano circa 100 applicazioni diverse. Per coprire un numero così enorme di varianti, avevamo bisogno di uno strumento di automazione multifunzionale. Preferibilmente con un DSL semplice, in modo che potesse essere mantenuto non solo da chi lo ha scritto.
Abbiamo scelto Ansible perché è senza agenti: non è stato necessario preparare l'infrastruttura, avvio veloce. Inoltre, è scritto in Python, che è considerato lo standard nel team.
Schema generale
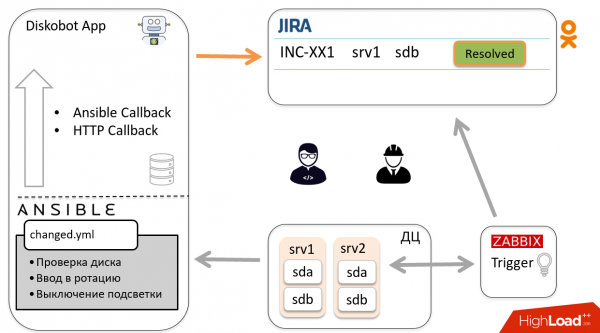
Esaminiamo lo schema generale di automazione attraverso un esempio di un incidente. Zabbix rileva che il disco sdb è guasto, si attiva il trigger e viene creato un ticket in Jira. L'amministratore lo controlla, capisce che non è un duplicato né un falso positivo, quindi è necessario sostituire il disco e sposta il ticket in In progress.
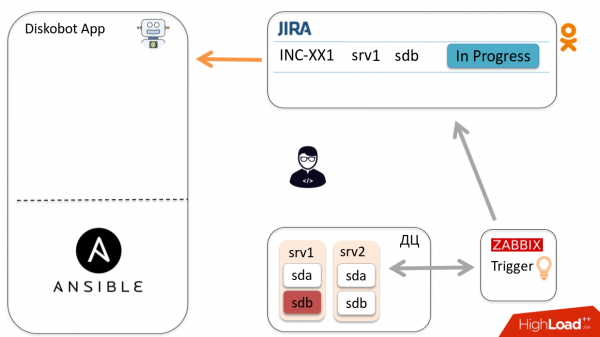
L'applicazione DiskoBot, scritta in Python, interroga periodicamente Jira per nuovi ticket. Nota che è stato creato un nuovo ticket In progress, si attiva il thread corrispondente che avvia il playbook in Ansible (questo è fatto per ogni stato in Jira). In questo caso, viene avviato Prepare2change.
Ansible viene inviato all'host, rimuove il disco dalla rotazione e riporta lo stato all'applicazione tramite Callback.
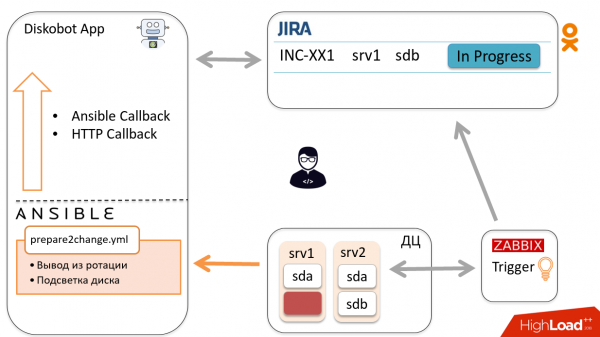
In base ai risultati, il bot sposta automaticamente il ticket in Ready to change. L'ingegnere riceve una notifica e va a sostituire il disco, dopo di che sposta il ticket in Changed.
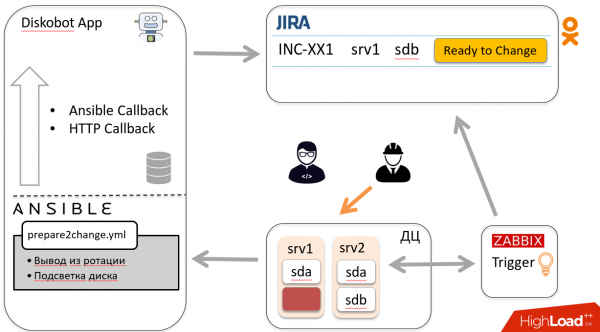
Secondo lo schema descritto sopra, il ticket torna al bot, che avvia un altro playbook, accede all'host e inserisce il disco in rotazione. Il bot chiude il ticket. Evviva!
Ora parliamo di alcuni componenti del sistema.
Diskobot
Questa applicazione è scritta in Python. Seleziona i ticket da Jira in base a JQL. A seconda dello stato del ticket, quest'ultimo viene assegnato al gestore corrispondente, il quale avvia il playbook Ansible adeguato allo stato.
JQL e gli intervalli di polling sono definiti nel file di configurazione dell'applicazione.
jira_states:
investigate:
jql: '… status = Open and "Disk Size" is EMPTY'
interval: 180
inprogress:
jql: '… and "Disk Size" is not EMPTY and "Device Name" is not EMPTY'
ready:
jql: '… and (labels not in ("dbot_ignore") or labels is EMPTY)'
interval: 7200
Ad esempio, tra i ticket nello stato In progress, vengono selezionati solo quelli in cui i campi Disk size e Device name sono compilati. Device name è il nome del dispositivo di blocco necessario per l'esecuzione del playbook. Disk size è necessario affinché l'ingegnere sappia quale dimensione di disco è necessaria.
E tra i ticket con stato Ready, vengono filtrati i ticket con l'etichetta dbot_ignore. A proposito, utilizziamo le etichette di Jira sia per questa filtrazione che per contrassegnare i duplicati dei ticket e raccogliere statistiche.
In caso di fallimento del playbook, Jira assegna l'etichetta dbot_failed, per poter esaminare successivamente il problema.
Interazione con Ansible
L'applicazione interagisce con Ansible tramite . Nel playbook_executor passiamo il nome del file e un insieme di variabili. Questo consente di mantenere il progetto Ansible sotto forma di normali file yml, anziché descriverlo nel codice Python.
Inoltre, in Ansible tramite *extra_vars* vengono passati il nome del dispositivo di blocco, lo stato del ticket e anche callback_url, che contiene la chiave del problema — utilizzata per il callback in HTTP.
Per ogni esecuzione viene generato un inventario temporaneo, costituito da un singolo host e da un gruppo che include questo host, affinché vengano applicati group_vars.
Ecco un esempio di task in cui è implementato un callback HTTP.
Riceviamo i risultati dell'esecuzione dei playbook tramite callback(-s). Ce ne sono di due tipi:
- , che fornisce i dati sui risultati dell'esecuzione del playbook. Qui sono descritte le attività che sono state avviate, completate con successo o fallite. Questo callback viene chiamato alla fine dell'esecuzione del playbook.
- Callback HTTP per ricevere informazioni durante l'esecuzione del playbook. Nel task Ansible eseguiamo una richiesta POST/GET verso la nostra applicazione.
Con il callback HTTP vengono trasmessi delle variabili definite durante l'esecuzione del playbook che vogliamo mantenere e utilizzare nei successivi avvii. Questi dati vengono scritti in sqlite.
Anche attraverso il callback HTTP possiamo lasciare commenti e cambiare lo stato del ticket.
Callback HTTP
# Make callback to Diskobot App
# Variables:
# callback_post_body: # A dict with follow keys. All keys are optional
# msg: If exist it would be posted to Jira as comment
# data: If exist it would be saved in Incident.variables
# desire_state: Set desire_state for incident
# status: If exist Proceed issue to that status
- name: Callback to Diskobot app (jira comment/status)
uri:
url: "{{ callback_url }}/{{ devname }}"
user: "{{ diskobot_user }}"
password: "{{ diskobot_pass }}"
force_basic_auth: True
method: POST
body: "{{ callback_post_body | to_json }}"
body_format: json
delegate_to: 127.0.0.1
Come molte attività simili, l'abbiamo estratta in un file comune e la includiamo all'occorrenza, per evitare di ripeterci continuamente nei playbook. Qui è presente il callback_url, che include il codice del problema e il nome host. Quando Ansible esegue questa richiesta POST, il bot comprende che è stata ricevuta nell'ambito di un certo incidente.
Ecco un esempio dal playbook in cui abbiamo rimosso un disco da un dispositivo MD:
# Save mdadm configuration
- include: common/callback.yml
vars:
callback_post_body:
status: 'Ready to change'
msg: "Removed disk from mdraid {{ mdadm_remove_disk.msg | comment_jira }}"
data:
mdadm_data: "{{ mdadm_remove_disk.removed }}"
parted_info: "{{ parted_info | default() }}"
when:
- mdadm_remove_disk | changed
- mdadm_remove_disk.removed
Questa attività cambia lo stato del ticket Jira in "Pronto per la modifica" e aggiunge un commento. Inoltre, nella variabile mdam_data viene salvato un elenco dei dispositivi md da cui è stato rimosso il disco, mentre in parted_info si trova un dump della partizione da parted.
Quando l'ingegnere inserirà un nuovo disco, potremo utilizzare queste variabili per ripristinare il dump delle partizioni e anche reinserire il disco nei dispositivi md da cui è stato rimosso.
Modalità di controllo Ansible
Era spaventoso attivare l'automazione. Pertanto, abbiamo deciso di eseguire tutti i playbook in modalità
, in cui Ansible non esegue alcuna azione sui server, ma li emula soltanto.
Tale avvio viene eseguito tramite un modulo di callback separato e il risultato dell'esecuzione del playbook viene salvato in Jira come commento.
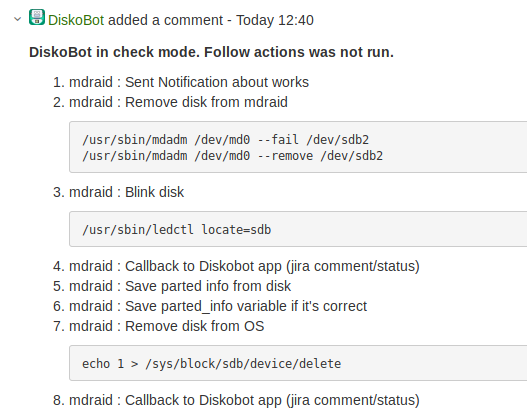
In primo luogo, questo ha permesso di validare il funzionamento del bot e dei playbook. In secondo luogo, ha aumentato la fiducia degli amministratori nel bot.
Quando abbiamo completato la validazione e compreso che era possibile eseguire Ansible non solo in modalità dry run, abbiamo creato in Jira il pulsante 'Run Diskobot' per l'esecuzione dello stesso playbook con le stesse variabili sullo stesso host, ma in modalità normale.
Inoltre, il pulsante viene utilizzato per riavviare il playbook in caso di fallimento.
Struttura dei Playbooks
Ho già menzionato che, a seconda dello stato del ticket Jira, il bot esegue diversi playbook.
In primo luogo, è molto più semplice organizzare l’input.
In secondo luogo, in alcuni casi è semplicemente necessario.
Ad esempio, quando si sostituisce il disco di sistema, è necessario prima accedere al sistema di distribuzione, creare un'attività e, dopo una corretta distribuzione, il server sarà accessibile tramite ssh, e sarà possibile installarvi l'applicazione. Se avessimo fatto tutto ciò in un unico playbook, Ansible non sarebbe stato in grado di eseguirlo a causa dell'indisponibilità dell'host.
Utilizziamo ruoli Ansible per ogni gruppo di server. Qui si può vedere come sono organizzati i playbook in uno di essi.
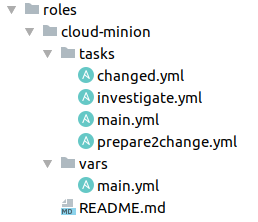
Questo è comodo, perché è immediatamente chiaro dove si trovano quali attività. Nel main.yml, che funge da ingresso per il ruolo Ansible, possiamo semplicemente includere in base allo stato del ticket o attività generali necessarie per tutti, come ad esempio il passaggio dell'identificazione o l'ottenimento del token.
Investigation.yml
Viene eseguito per i ticket nello stato Investigation e Open. La cosa più importante per questo playbook è il nome del dispositivo a blocchi. Queste informazioni non sono sempre disponibili.
Per ottenerlo, analizziamo il riassunto di Jira e l'ultimo valore dal trigger Zabbix. Potrebbe contenere il nome del dispositivo a blocchi — che fortuna. Oppure potrebbe contenere il mount point, in tal caso dobbiamo andare sul server, eseguire il parsing e calcolare il disco necessario. Inoltre, il trigger potrebbe trasmettere l'indirizzo SCSI o qualche altra informazione. Ma a volte non ci sono indizi e dobbiamo analizzare.
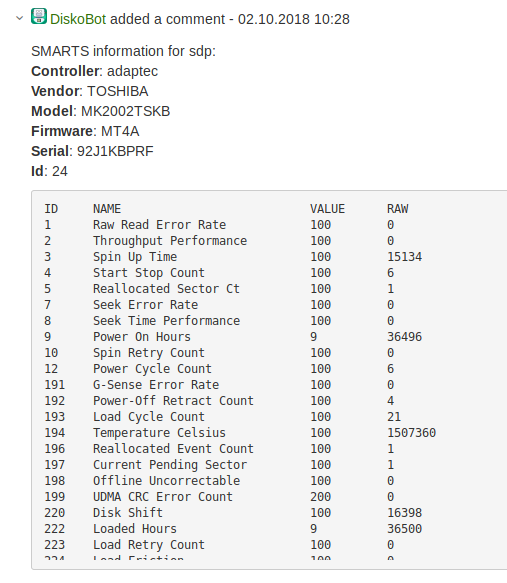
Una volta scoperto il nome del dispositivo a blocchi, raccogliamo informazioni sul tipo e sulla dimensione del disco per riempire i campi in Jira. Raccolta anche delle informazioni sul fornitore, modello, firmware, ID, SMART, e tutto ciò viene inserito nei commenti del ticket Jira. Ora l'amministratore e l'ingegnere non devono più cercare questi dati. 🙂
prepare2change.yml
Rimozione del disco dalla rotazione, preparazione alla sostituzione. Fase la più complessa e delicata. È proprio qui che è possibile fermare l'app quando non può essere arrestata. Oppure rimuovere un disco che mancava di repliche, influenzando così gli utenti e perdendo dati. Qui abbiamo più controlli e notifiche in chat.
Nel caso più semplice, si tratta di rimuovere il disco da HW/MD RAID.
In situazioni più complesse (nei nostri sistemi di archiviazione), quando il backup viene eseguito a livello di applicazione, è necessario accedere all'applicazione tramite API, segnalare l'uscita del disco, disattivarlo e avviare il ripristino.
Stiamo attualmente migrando in massa a , e se il server è cloud, Diskobot si rivolge all'API del cloud, comunica che intende lavorare con questo minion — il server su cui sono in esecuzione i container — e richiede "migra tutti i container da questo minion". E accende anche l'illuminazione del disco affinché l'ingegnere possa vedere subito quale deve essere rimosso.
changed.yml
Dopo la sostituzione del disco, controlliamo innanzitutto la sua disponibilità.
Gli ingegneri non installano sempre dischi nuovi, quindi abbiamo aggiunto un controllo dei valori SMART che ci soddisfano.
Quali attributi controlliamoReallocated Sectors Count (5) < 100
Current Pending Sector Count (107) == 0
Se il disco non supera il controllo, viene comunicato all'ingegnere di procedere con una nuova sostituzione. Se tutto è in ordine, l'illuminazione si spegne, viene applicata la marcatura e il disco viene inserito in rotazione.
ready.yml
Il caso più semplice: controllo della sincronizzazione HW/SW raid o completamento della sincronizzazione dei dati nell'applicazione.
API delle applicazioni
Ho menzionato diverse volte che spesso il bot interagisce con le API delle applicazioni. Certo, non tutte le applicazioni avevano i metodi necessari, quindi è stato necessario implementarli. Ecco i metodi più importanti che utilizziamo:
- Status. Stato del cluster o del disco per capire se è possibile lavorarci;
- Start/stop. Attivazione/disattivazione del disco;
- Migrate/restore. Migrazione e ripristino dei dati durante e dopo la sostituzione.
Esperienza condivisa su Ansible
Amo molto Ansible. Ma spesso, quando guardo diversi progetti open-source e vedo come le persone scrivono i playbook, mi sento un po' spaventato. Complicati intrecci logici tra when/loop, mancanza di flessibilità e idempotenza a causa dell'uso frequente di shell/command.
Abbiamo deciso di semplificare il tutto al massimo, sfruttando il vantaggio di Ansible: la modularità. Ai livelli più alti ci sono i playbook, che possono essere scritti da qualsiasi amministratore o sviluppatore esterno che ha una minima conoscenza di Ansible.
- name: Blink disk
become: True
register: locate_action
disk_locate:
locate: '{{ locate }}'
devname: '{{ devname }}'
ids: '{{ locate_ids | default(pd_id) | default(omit) }}'
Se una logica è difficile da realizzare nei playbook, la spostiamo in un modulo o in un filtro Ansible. Gli script possono essere scritti sia in Python che in qualsiasi altro linguaggio.
Sono facili e veloci da scrivere. Ad esempio, il modulo di evidenziazione del disco, di cui abbiamo fornito un esempio d'uso, è composto da 265 righe.

Alla base c'è una libreria. Per questo progetto abbiamo scritto un'applicazione separata, una sorta di astrazione su RAID hardware e software, che esegue le richieste corrispondenti.
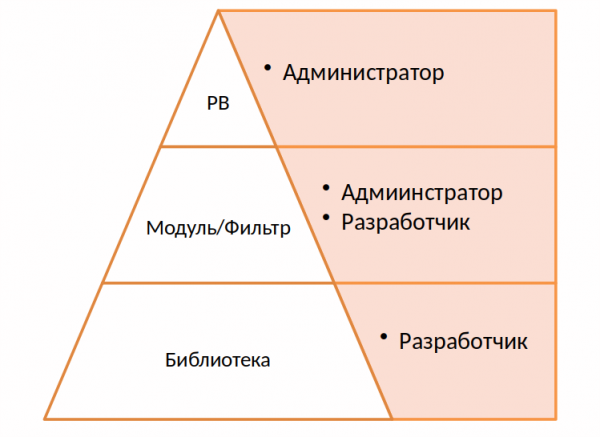
I punti di forza di Ansible sono la semplicità e i playbook chiari. Credo che sia importante sfruttarli e non generare terribili file yaml, con un'enorme quantità di condizioni, codice shell e loop.
Se desiderate replicare la nostra esperienza con l'API Ansible, tenete a mente due cose:
- A playbook_executor e in generale a un playbook non è possibile passare un timeout. Esiste un timeout per le sessioni ssh, ma non per il playbook. Se tentiamo di smontare un disco che non esiste più nel sistema, il playbook verrà eseguito indefinitamente, quindi abbiamo dovuto avvolgere l'esecuzione in un wrapper separato e terminarlo per timeout.
- Ansible opera su base di processi fork, quindi la sua API non è thread-safe. Eseguiamo tutti i nostri playbook in modo singolo.
Siamo riusciti ad automatizzare la sostituzione di circa l'80% dei dischi. In generale, la velocità di sostituzione è raddoppiata. Oggi l'amministratore deve solo guardare l'incidente e decidere se sostituire il disco o meno, e poi fa un clic.
Ma ora iniziamo a affrontare un altro problema: alcuni nuovi amministratori non sanno come sostituire i dischi. 🙂
Fonte: habr.com
