


Mi chiamo Denis Rozhkov, sono il capo dello sviluppo software presso "Gazinformservice", nel team del prodotto. . Le leggi e le normative aziendali pongono requisiti specifici sulla sicurezza della conservazione dei dati. Nessuno vuole che terzi abbiano accesso alle informazioni riservate, quindi per ogni progetto è fondamentale affrontare le seguenti questioni: identificazione e autenticazione, gestione degli accessi ai dati, garanzia dell'integrità delle informazioni nel sistema e registrazione degli eventi di sicurezza. Pertanto, voglio parlare di alcuni aspetti interessanti sulla sicurezza dei sistemi di gestione dei database.
L'articolo è stato redatto in base a un intervento tenuto su organizzato . Se non vuoi leggere, puoi guardare:

L'articolo avrà tre parti:
- Come proteggere le connessioni.
- Cosa sono gli audit delle azioni e come registrare cosa succede lato database e connessione a esso.
- Come proteggere i dati all'interno del database stesso e quali tecnologie ci sono a tal fine.
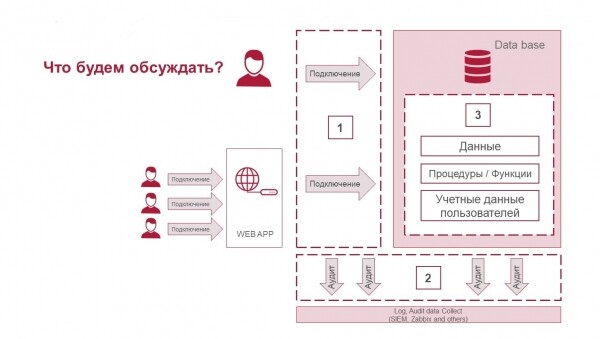
Tre componenti della sicurezza dei sistemi di gestione dei database: protezione delle connessioni, audit delle azioni e protezione dei dati.
Protezione delle connessioni
È possibile connettersi al database sia direttamente sia tramite applicazioni web. Di norma, l'utente aziendale, ovvero la persona che lavora con il DBMS, interagisce con esso non direttamente.
Prima di parlare della protezione delle connessioni, è necessario rispondere a importanti domande che determinano come verranno implementate le misure di sicurezza:
- un utente aziendale equivale a un utente del DBMS;
- l'accesso ai dati del DBMS è garantito solo tramite un'API che controllate, oppure ci sono accessi diretti alle tabelle;
- il DBMS è stato collocato in un segmento protetto separato, chi e come interagisce con esso;
- viene utilizzato il pooling/proxy e strati intermedi che possono modificare le informazioni su come è costruita la connessione e chi utilizza il database.
Ora vediamo quali strumenti possono essere applicati per proteggere le connessioni:
- Utilizzate soluzioni di tipo database firewall. Un ulteriore strato di protezione, almeno, aumenterà la trasparenza di ciò che accade nel DBMS, al massimo — potrete garantire una protezione aggiuntiva dei dati.
- Utilizza le politiche di password. La loro applicazione dipende da come è strutturata la tua architettura. In ogni caso, una sola password nel file di configurazione dell'applicazione web che si collega al DBMS non è sufficiente per garantire la protezione. Esistono diversi strumenti DBMS che consentono di monitorare quando è necessario aggiornare l'utente e la password.
Puoi leggere ulteriori informazioni sulle funzionalità di valutazione degli utenti , e puoi anche scoprire di MS SQL Vulnerability Assessment .
- Arricchisci il contesto della sessione con le informazioni necessarie. Se la sessione è opaca e non comprendi chi sta operando nel DBMS, puoi completare le informazioni sull'operazione in corso, specificando chi sta facendo cosa e perché. Queste informazioni possono essere visualizzate nell'audit.
- Configura SSL se non hai una separazione di rete del DBMS dagli utenti finali, e non è in una VLAN separata. In questi casi, è fondamentale proteggere il canale tra il consumatore e il DBMS stesso. Esistono strumenti di protezione anche tra le soluzioni open source.
Come influenzerà le prestazioni del DBMS?
Guardiamo come SSL influisce sul carico della CPU, l'aumento dei tempi di risposta e la riduzione del TPS usando PostgreSQL, e se l'attivazione di SSL possa consumare troppe risorse.
Sottoponiamo PostgreSQL a un carico utilizzando pgbench, un programma semplice per eseguire test di prestazioni. Esso esegue ripetutamente una sequenza di comandi, possibilmente in sessioni parallele del database, e quindi calcola la velocità media delle transazioni.
Test 1 senza SSL e con SSL attivo — la connessione viene stabilita ad ogni transazione:
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"vs
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Test 2 senza SSL e con SSL attivo — tutte le transazioni vengono eseguite su una sola connessione:
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"vs
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Altre impostazioni:
fattore di scalabilità: 1
modalità query: semplice
numero di client: 10
numero di thread: 1
numero di transazioni per client: 5000
numero di transazioni effettivamente elaborate: 50000/50000Risultati dei test:
NO SSL
SSL
La connessione viene stabilita ad ogni transazione
latenza media
171.915 ms
187.695 ms
tps inclusi stabilimenti di connessione
58.168112
53.278062
tps escluse stabilimenti di connessione
64.084546
58.725846
CPU
24%
28%
Tutte le transazioni vengono eseguite in una sola connessione
latenza media
6,722 ms
6,342 ms
tps inclusi stabilimenti delle connessioni
1587.657278
1576.792883
tps escluse stabilimenti di connessione
1588.380574
1577.694766
CPU
17%
21%
Con carichi ridotti, l'impatto di SSL è comparabile con l'errore di misurazione. Se la quantità di dati trasferiti è molto grande, la situazione potrebbe essere diversa. Se stabilisse una connessione per ogni transazione (cosa rara, di solito le connessioni vengono condivise tra gli utenti), avresti un numero elevato di connessioni/disconnessioni, l'impatto potrebbe essere un po' maggiore. Quindi ci possono essere rischi di riduzione delle prestazioni, tuttavia la differenza non è così grande da non usare la protezione.
Si prega di notare: c'è una forte differenza se si confrontano i modi di funzionamento: all'interno di una sessione si lavora o separatamente. Questo è chiaro: ad ogni connessione vengono spesi delle risorse.
Abbiamo avuto un caso in cui abbiamo collegato Zabbix in modalità trust, quindi non abbiamo controllato l'md5, non c'era bisogno di autenticazione. Poi il cliente ha chiesto di attivare la modalità di autenticazione md5. Questo ha provocato un carico elevato sulla CPU e le prestazioni ne hanno risentito. Abbiamo iniziato a cercare soluzioni per ottimizzare. Una delle possibili soluzioni al problema è implementare una limitazione di rete, creare VLAN separate per il DBMS, aggiungere impostazioni per chiarire chi e da dove si connette ed eliminare l'autenticazione. È possibile ottimizzare anche le impostazioni di autenticazione per ridurre i costi quando l'autenticazione è attivata, ma in generale, l'uso di diversi metodi di autenticazione influisce sulla performance e richiede di considerare questi fattori quando si progettano le capacità di calcolo dei server (hardware) per il DBMS.
Conclusione: in alcune soluzioni, anche piccoli dettagli sull'autenticazione possono avere un forte impatto sul progetto, ed è problematico quando questo diventa evidente solo durante l'implementazione in produzione.
Audit delle azioni
L'audit non si limita solo ai DBMS. L'audit è l'acquisizione di informazioni su cosa accade nei vari segmenti. Può includere sia il database firewall che il sistema operativo su cui è costruito il DBMS.
Negli DBMS commerciali di livello Enterprise l'audit funziona bene, mentre negli open source non sempre. Ecco cosa c'è in PostgreSQL:
- log predefinito - logging integrato;
- estensioni: pgaudit - se il logging predefinito non è sufficiente, puoi utilizzare impostazioni separate che risolvono parte dei problemi.
Integrazione alla relazione nel video:
«La registrazione di base degli operatori può essere garantita dallo strumento di logging standard con log_statement = all.
Questo è accettabile per il monitoraggio e altri usi, ma non garantisce il livello di dettaglio generalmente necessario per l'audit.
È insufficiente avere un elenco di tutte le operazioni eseguite sul database.
Dev'essere anche possibile rintracciare affermazioni specifiche che siano di interesse per l'auditor.
Lo strumento di logging standard mostra ciò che è richiesto dall'utente, mentre pgAudit si concentra sui dettagli di ciò che è accaduto quando il database ha eseguito la query.
Ad esempio, un revisore potrebbe voler assicurarsi che una tabella specifica sia stata creata nella finestra di manutenzione documentata.
Questo potrebbe sembrare un compito semplice per una revisione di base e grep, ma cosa succede se ti trovi di fronte a qualcosa come questo (intenzionalmente confuso) esempio:
DO $$
BEGIN
EXECUTE ‘CREATE TABLE import’ || ‘ant_table (id INT)’;
END $$;
La registrazione standard ti darà questo:
LOG: statement: DO $$
BEGIN
EXECUTE ‘CREATE TABLE import’ || ‘ant_table (id INT)’;
END $$;
Sembra che per trovare la tabella di interesse potrebbe essere necessaria una certa conoscenza del codice nei casi in cui le tabelle siano create dinamicamente.
Non è l'ideale, poiché sarebbe preferibile cercare semplicemente per nome della tabella.
È qui che pgAudit sarà utile.
Per lo stesso input produrrà questa uscita nel registro:
AUDIT: SESSION,33,1,FUNCTION,DO,,,«DO $$
BEGIN
EXECUTE ‘CREATE TABLE import’ || ‘ant_table (id INT)’;
END $$;"
AUDIT: SESSION,33,2,DDL,CREATE TABLE,TABLE,public.important_table,CREATE TABLE important_table (id INT)
Non viene registrato solo il blocco DO, ma anche il testo completo di CREATE TABLE con il tipo di operazione, il tipo di oggetto e il nome completo, il che rende più semplice la ricerca.
Quando si registrano operatori SELECT e DML, pgAudit può essere configurato per registrare un'entrata separata per ogni relazione menzionata nell'operatore.
Non è necessaria un'analisi sintattica per trovare tutti gli operatori riguardanti una specifica tabella,)».
Come influenzerà le prestazioni del DBMS?
Eseguiamo dei test attivando il controllo completo e vediamo come influisce sulle prestazioni di PostgreSQL. Attiviamo la registrazione massima del database per tutti i parametri.
Nel file di configurazione non cambiamo quasi nulla, l'importante è attivare la modalità debug5 per ottenere il massimo delle informazioni.
postgresql.conf
log_destination = 'stderr'
logging_collector = on
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 10MB
log_min_messages = debug5
log_min_error_statement = debug5
log_min_duration_statement = 0
debug_print_parse = on
debug_print_rewritten = on
debug_print_plan = on
debug_pretty_print = on
log_checkpoints = on
log_connections = on
log_disconnections = on
log_duration = on
log_hostname = on
log_lock_waits = on
log_replication_commands = on
log_temp_files = 0
log_timezone = 'Europe/Moscow'
Sulla DBMS PostgreSQL con parametri 1 CPU, 2,8 GHz, 2 GB RAM, 40 GB HDD eseguiamo tre test di carico utilizzando i comandi:
$ pgbench -p 3389 -U postgres -i -s 150 benchmark
$ pgbench -p 3389 -U postgres -c 50 -j 2 -P 60 -T 600 benchmark
$ pgbench -p 3389 -U postgres -c 150 -j 2 -P 60 -T 600 benchmarkRisultati del test:
Senza registrazione
Con registrazione
Tempo totale di riempimento del DB
43,74 sec
53,23 sec
RAM
24%
40%
CPU
72%
91%
Test 1 (50 connessioni)
Numero di transazioni in 10 minuti
74169
32445
Transazioni/sec
123
54
Ritardo medio
405 ms
925 ms
Test 2 (150 connessioni su 100 disponibili)
Numero di transazioni in 10 minuti
81727
31429
Transazioni/sec
136
52
Ritardo medio
550 ms
1432 ms
Informazioni sulle dimensioni
Dimensione del DB
2251 MB
2262 MB
Dimensione dei log del DB
0 MB
4587 MB
In sintesi: un audit completo non è molto utile. I dati provenienti dall'audit saranno di volume pari a quelli presenti nel database stesso, se non di più. Un volume di log generato durante l'uso di un DBMS è un problema comune in produzione.
Analizziamo altri parametri:
- La velocità non cambia molto: senza logging — 43,74 secondi, con logging — 53,23 secondi.
- Le prestazioni della RAM e della CPU saranno inferiori, poiché è necessario generare un file per l'audit. Questo è anche evidente in produzione.
Con l'aumento del numero di connessioni, naturalmente, i risultati peggioreranno leggermente.
Nelle aziende, la situazione con l'audit è ancora più complessa:
- ci sono molti dati;
- l'audit è necessario non solo tramite syslog in SIEM, ma anche nei file: nel caso accada qualcosa con syslog, ci dovrebbe essere un file vicino al database in cui conservare i dati;
- per l'audit è necessaria una sezione separata, per non far crollare le prestazioni I/O dei dischi, poiché occupa molto spazio;
- è possibile che i dipendenti della sicurezza informatica richiedano standard GOST ovunque, richiedono identificazione conforme agli standard.
Limitazione dell'accesso ai dati
Esaminiamo le tecnologie utilizzate per la protezione dei dati e l'accesso a questi nelle basi di dati commerciali e open source.
Cosa possiamo utilizzare in generale:
- Crittografia e offuscamento di procedure e funzioni (Wrapping) — cioè strumenti e utilità specifiche che rendono il codice leggibile illeggibile. Tuttavia, non può essere né modificato né rifattorizzato. Questo approccio è talvolta necessario, almeno a livello di database — la logica delle limitazioni di licenza o la logica dell'autorizzazione viene crittografata proprio a livello di procedura e funzione.
- Limitazione della visibilità dei dati per righe (RLS) — è quando diversi utenti vedono una tabella, ma con composizioni di righe diverse, quindi ad alcune persone non possono essere mostrati certi dati a livello di righe.
- Modifica dei dati visualizzati (Masking) — è quando gli utenti in una colonna di una tabella vedono o i dati o solo asterischi, cioè per alcuni utenti l'informazione sarà nascosta. La tecnologia definisce quali dati mostrare a ciascun utente in base al livello di accesso.
- La distinzione dell'accesso Security DBA/Application DBA/DBA riguarda principalmente la restrizione dell'accesso al database stesso, il che significa che il personale della sicurezza informatica può essere separato dagli amministratori del database e dagli amministratori delle applicazioni. Esistono poche tecnologie open source in questo campo, mentre le soluzioni commerciali sono abbondanti. Sono necessarie quando ci sono molti utenti con accesso ai server stessi.
- Restrizione dell'accesso ai file a livello di file system. È possibile concedere diritti e privilegi di accesso alle cartelle, in modo che ogni amministratore possa accedere solo ai dati necessari.
- L'accesso a mandato e la pulizia della memoria sono tecnologie raramente utilizzate.
- La crittografia end-to-end direttamente nel database — è una crittografia client-side con gestione delle chiavi sul lato server.
- Crittografia dei dati. Ad esempio, la crittografia per colonne — quando si utilizza un meccanismo che crittografa una singola colonna del database.
Come influisce sulle prestazioni del database?
Prendiamo come esempio la crittografia colonnare in PostgreSQL. Esiste un modulo pgcrypto, che consente di memorizzare alcuni campi in forma crittografata. Questo è utile quando solo alcuni dati hanno valore. Per leggere i campi crittografati, il client invia la chiave di decrittazione, il server decifra i dati e li restituisce al client. Senza la chiave, nessuno può fare nulla con i tuoi dati.
Eseguiamo un test con pgcrypto. Creiamo una tabella con dati crittografati e con dati normali. Di seguito i comandi per creare le tabelle, nella prima riga c'è un comando utile: la creazione dell'estensione con la registrazione del DBMS:
CREATE EXTENSION pgcrypto;
CREATE TABLE t1 (id integer, text1 text, text2 text);
CREATE TABLE t2 (id integer, text1 bytea, text2 bytea);
INSERT INTO t1 (id, text1, text2)
VALUES (generate_series(1,10000000), generate_series(1,10000000)::text, generate_series(1,10000000)::text);
INSERT INTO t2 (id, text1, text2) VALUES (
generate_series(1,10000000),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'));Successivamente proveremo a fare una selezione di dati da ciascuna tabella e osserveremo i tempi di esecuzione.
Selezione dalla tabella senza funzione di crittografia:
psql -c "timing" -c "select * from t1 limit 1000;" "host=192.168.220.129 dbname=taskdb
user=postgres sslmode=disable" > 1.txtIl cronometro è attivato.
id | testo1 | testo2
——+——-+——-
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
…
997 | 997 | 997
998 | 998 | 998
999 | 999 | 999
1000 | 1000 | 1000
(1000 righe)
Tempo: 1,386 ms
Estrazione dalla tabella con funzione di decrittazione:
psql -c "timing" -c "select id, decrypt(text1, 'key'::bytea, 'bf'),
decrypt(text2, 'key'::bytea, 'bf') from t2 limit 1000;"
"host=192.168.220.129 dbname=taskdb user=postgres sslmode=disable" > 2.txtIl cronometro è attivato.
id | decrittare | decrittare
——+—————+————
1 | x31 | x31
2 | x32 | x32
3 | x33 | x33
…
999 | x393939 | x393939
1000 | x31303030 | x31303030
(1000 righe)
Tempo: 50,203 ms
Risultati dei test:
Senza decrittazione
Pgcrypto (decrittare)
Estrazione 1000 righe
1,386 ms
50,203 ms
CPU
15%
35%
RAM
+5%
La decrittazione ha un forte impatto sulle prestazioni. Si nota che il tempo è aumentato, poiché le operazioni di decrittazione dei dati criptati (e la decrittazione è tipicamente ulteriormente avvolta nella tua logica) richiedono risorse significative. Quindi, l'idea di crittografare tutte le colonne che contengono dati è rischiosa per le prestazioni.
Tuttavia, la crittografia non è una soluzione magica che risolve tutti i problemi. I dati decrittati e la chiave di decrittazione sono sul server durante il processo di decrittazione e trasferimento dei dati. Pertanto, le chiavi possono essere intercettate da chi ha accesso completo al server del database, ad esempio un amministratore di sistema.
Quando un'unica chiave è utilizzata per tutti gli utenti in una colonna (anche se non per tutti, ma per un insieme limitato di clienti), non è sempre una scelta ottimale né corretta. È proprio per questo che si è iniziato a implementare la crittografia end-to-end. Nei sistemi di gestione dei database (SGBD) sono state esplorate opzioni per la crittografia dei dati sia dal lato cliente che server, e sono emersi i cosiddetti key-vault, cioè prodotti distinti che forniscono gestione delle chiavi a livello di SGBD.

Strumenti di sicurezza nei SGBD commerciali e open source
Le funzioni
Tipo
Password Policy
Audit
Protezione del codice sorgente di procedure e funzioni
RLS
Crittografia
Oracle
Commerciale
+
+
+
+
+
MsSql
Commerciale
+
+
+
+
+
Commerciale
+
+
+
+
estensioni
PostgreSQL
Free
estensioni
estensioni
—
+
estensioni
MongoDb
Free
—
+
—
—
Disponibile solo in MongoDB Enterprise
La tabella non è per niente completa, ma la situazione è questa: nei prodotti commerciali le questioni di sicurezza vengono affrontate da tempo, mentre nell'open source, di solito, si utilizzano delle estensioni per la sicurezza, mancano molte funzioni e talvolta è necessario implementarne alcune. Ad esempio, le politiche delle password — in PostgreSQL esistono molte estensioni (, , , , ), che implementano politiche delle password, ma a mio avviso nessuna copre tutte le esigenze del segmento aziendale nazionale.
Cosa fare se non si trova ciò di cui si ha bisogno? Например, хочется использовать определенную СУБД, в которой нет функций, которые требует заказчик.
In questo caso, è possibile utilizzare soluzioni di terze parti compatibili con diversi DBMS, come "Crypto DB" o "Garda DB". Se si parla di soluzioni del settore nazionale, lì conoscono meglio gli standard GOST rispetto all'open source.
La seconda opzione è scrivere autonomamente ciò di cui hai bisogno, implementando a livello di procedure l'accesso ai dati e la crittografia nell'applicazione. Tuttavia, la questione degli standard GOST sarà più complicata. In generale, puoi nascondere i dati come necessario, immagazzinarli nel DBMS e successivamente estrarli e decifrarli in modo adeguato, direttamente a livello di applicazione. Considera subito come proteggere questi algoritmi a livello di applicazione. A nostro avviso, è meglio farlo a livello di DBMS, poiché ciò garantirà prestazioni più rapide.
Questa relazione è stata presentata per la prima volta al da Mail.ru Cloud Solutions. Guardaaltri interventi e iscriviti agli avvisi degli eventi su Telegram .
Ulteriori letture sull'argomento:
- .
- .
Fonte: habr.com
