

Nell'autunno del 2019, nel team iOS di Mail.ru Cloud è avvenuto un evento atteso. Il database principale per la memorizzazione persistente dello stato dell'applicazione è diventato piuttosto esotico per il mondo mobile. (LMDB). Di seguito, vi proponiamo una dettagliata panoramica in quattro parti. Iniziamo a discutere le ragioni di una scelta così non banale e difficile. Poi passeremo all'analisi dei tre pilastri dell'architettura LMDB: file mappati in memoria, B+-albero, approccio copy-on-write per l'implementazione della transazionalità e della multiversione. Infine, un tocco pratico: vedremo come progettare e implementare uno schema di database con più tabelle, incluso l'indice, sopra una API key-value di basso livello.
Contenuto
3.1.
3.2.
3.3.
4.1.
4.2.
4.3.
1. Motivazione per l'implementazione
Un giorno, nel 2015, ci siamo preoccupati di monitorare quanto spesso l'interfaccia della nostra applicazione laggava. Ci siamo messi a farlo per un motivo. Abbiamo ricevuto molte lamentele sul fatto che a volte l'applicazione smetteva di rispondere alle azioni dell'utente: i pulsanti non si cliccavano, le liste non scorrevano, ecc. Riguardo alla meccanica delle misurazioni ho su AvitoTech, quindi qui fornisco solo l'ordine di grandezza.
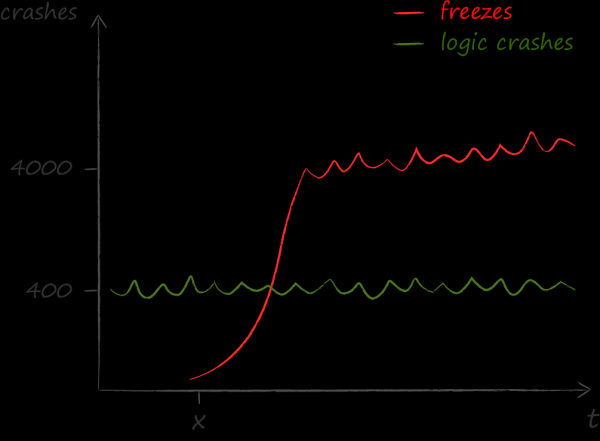
I risultati delle misurazioni sono stati per noi una doccia fredda. Si è scoperto che i problemi causati dai freeze sono molti più di quelli di altri tipi. Se prima della consapevolezza di questo fatto il principale indicatore tecnico di qualità era il crash free, dopo il focus sul freeze free.
Costruendo e conducendo e delle loro cause, è diventato chiaro quale fosse il nostro principale nemico: la complessa logica di business che viene eseguita nel thread principale dell'applicazione. La reazione naturale a questo disastro è stata un'immediata volontà di smistare questa logica attraverso i thread di lavoro. Per risolvere sistematicamente questa questione abbiamo adottato un'architettura multithread basata su attori leggeri. Ho dedicato al tema su Twitter collettivo e . Nel contesto della narrativa attuale, voglio sottolineare quegli aspetti della soluzione che hanno influenzato la scelta del database.
Il modello attoriale nell'organizzazione del sistema implica che il multithreading diventi la sua seconda essenza. Gli oggetti del modello amano attraversare i confini dei thread. E lo fanno non solo occasionalmente e in alcuni luoghi, ma praticamente costantemente e ovunque.
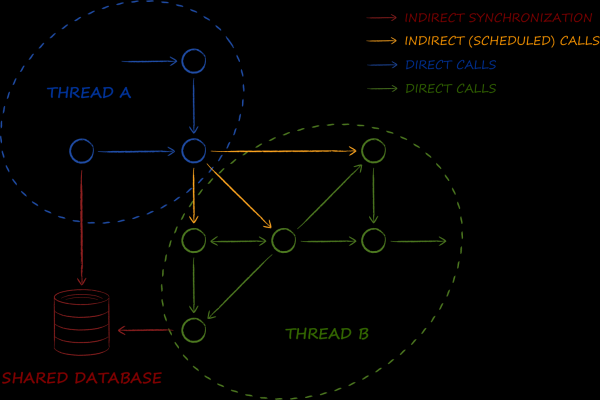
Il database è uno dei componenti fondamentali nello schema presentato. Il suo compito principale è l'implementazione del macropattern . Se nel mondo enterprise viene utilizzato per organizzare la sincronizzazione dei dati tra i servizi, nell'architettura ad attori — per i dati tra i flussi. Pertanto, abbiamo avuto bisogno di un database che operi senza alcuna difficoltà anche in un ambiente multithread. Questo significa, in particolare, che gli oggetti ottenuti devono essere almeno thread-safe e, idealmente, del tutto immutabili. Come è risaputo, gli ultimi possono essere utilizzati simultaneamente da più flussi senza la necessità di alcun blocco, il che ha un impatto positivo sulle performance.
 Un altro fattore significativo che ha influenzato la scelta del database è stata la nostra API cloud. È stata ispirata all'approccio alla sincronizzazione adottato in git. Proprio come questo, ci siamo fissati l'obiettivo di , che per i clienti del cloud risulta più che appropriato. Si presumeva che avrebbero scaricato completamente lo stato del cloud una sola volta, dopodiché la sincronizzazione nella maggior parte dei casi sarebbe avvenuta attraverso l'applicazione delle modifiche. Purtroppo, questa possibilità è ancora in una fase puramente teorica, e nella pratica i clienti non hanno ancora imparato a gestire le patch. Ci sono varie ragioni oggettive per questo, che lasceremo da parte per non allungare l'introduzione. Ma attualmente, ciò che suscita un interesse maggiore sono le lezioni insegnate su cosa succede quando un'API dice «A», mentre il suo consumatore non risponde con «B».
Un altro fattore significativo che ha influenzato la scelta del database è stata la nostra API cloud. È stata ispirata all'approccio alla sincronizzazione adottato in git. Proprio come questo, ci siamo fissati l'obiettivo di , che per i clienti del cloud risulta più che appropriato. Si presumeva che avrebbero scaricato completamente lo stato del cloud una sola volta, dopodiché la sincronizzazione nella maggior parte dei casi sarebbe avvenuta attraverso l'applicazione delle modifiche. Purtroppo, questa possibilità è ancora in una fase puramente teorica, e nella pratica i clienti non hanno ancora imparato a gestire le patch. Ci sono varie ragioni oggettive per questo, che lasceremo da parte per non allungare l'introduzione. Ma attualmente, ciò che suscita un interesse maggiore sono le lezioni insegnate su cosa succede quando un'API dice «A», mentre il suo consumatore non risponde con «B».
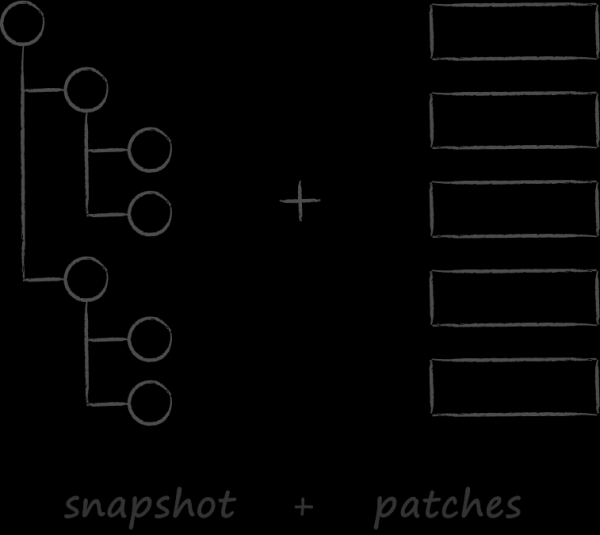
Immaginate un sistema git che, quando eseguite il comando pull, invece di applicare patch a uno snapshot locale, confronta il suo stato completo con quello del server. Avrete così un’idea piuttosto precisa di come avviene la sincronizzazione nei clienti cloud. Non è difficile intuire che per realizzarla sia necessario allocare in memoria due alberi DOM contenenti metainformazioni su tutti i file server e locali. Se l’utente conserva nel cloud 500.000 file, si rende necessario ricreare e distruggere due alberi con 1 milione di nodi. E ogni nodo è un aggregato che comprende un grafo di sotto-oggetti. In questo contesto, i risultati della profilazione si sono rivelati attesi. È emerso che, anche senza considerare la logica di unione, il processo stesso di creazione e distruzione di un grande numero di piccoli oggetti comporta già un costo significativo. La situazione è aggravata dal fatto che l’operazione di sincronizzazione di base è inclusa in un gran numero di scenari utente. È così che registriamo il secondo criterio importante nella scelta di un database: la possibilità di implementare operazioni CRUD senza allocazione dinamica di oggetti.
Altri requisiti sono più tradizionali e il loro elenco completo è il seguente.
- Sicurezza dei thread.
- Multiprocesso. Desidero utilizzare la stessa istanza del database per sincronizzare lo stato non solo tra i thread, ma anche tra l'applicazione principale e le estensioni iOS.
- Possibilità di rappresentare entità persistenti come oggetti immutabili.
- Assenza di allocazioni dinamiche nelle operazioni CRUD.
- Supporto per le transazioni delle proprietà fondamentali : atomicità, coerenza, isolamento e affidabilità.
- Velocità nei casi d'uso più comuni.
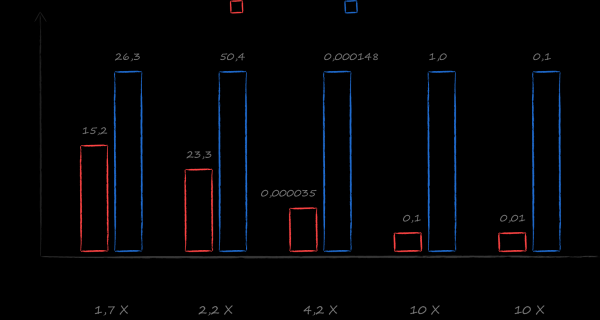
Una buona scelta con questo insieme di requisiti è stata e rimane SQLite. Tuttavia, nell'ambito dell'esplorazione di alternative, mi è capitato tra le mani un libro . Sotto la sua guida è stato realizzato un benchmark che confronta le prestazioni con diversi database in scenari cloud reali. I risultati hanno superato le aspettative più audaci. Nei casi più popolari — ottenere un cursore su un elenco ordinato di tutti i file e un elenco ordinato di tutti i file per una directory specifica — LMDB è risultato dieci volte più veloce di SQLite. La scelta è diventata ovvia.
2. Posizionamento di LMDB
LMDB è una libreria molto piccola (solo 10K righe) che implementa il livello più fondamentale dei database — lo storage.
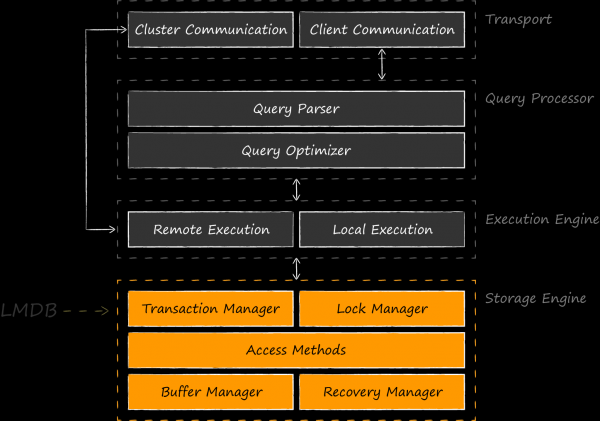
Lo schema fornito mostra che confrontare LMDB con SQLite, che implementa anche livelli più alti, non è del tutto corretto, proprio come non lo è paragonare SQLite con Core Data. Come concorrenti alla pari, sarebbe più giusto menzionare motori di archiviazione simili — BerkeleyDB, LevelDB, Sophia, RocksDB e altri. Ci sono anche sviluppi in cui LMDB viene utilizzato come componente dello storage engine per SQLite. Il primo di questi esperimenti è stato condotto nel 2012 l'autore di LMDB . , sono risultati così intriganti che la sua iniziativa è stata ripresa dagli appassionati dell'OSS e ha trovato la sua continuazione nel progetto . Nel gennaio 2020, l'autore di questo progetto, Den Shearer a LinuxConfAu.
L'uso principale di LMDB è come motore per database applicativi. La libreria deve il suo esordio agli sviluppatori di , che erano molto insoddisfatti di BerkeleyDB come base per il loro progetto. Partendo da una piccola libreria , Howard Chu è riuscito a creare una delle alternative più popolari al giorno d'oggi. Questa storia e la struttura interna di LMDB hanno ispirato il suo incredibile discorso . Un buon esempio di come conquistare uno storage è stato condiviso da Leonid Yuriev (aka ) di Positive Technologies nel suo intervento al Highload 2015 . In esso, parla di LMDB nel contesto di una simile sfida di implementazione di ReOpenLDAP, mentre LevelDB è stato oggetto di una critica comparativa. A seguito dell'implementazione, Positive Technologies ha anche creato un fork in rapida evoluzione con funzioni, ottimizzazioni e .
LMDB è spesso utilizzato anche come storage così com'è. Ad esempio, il browser Mozilla Firefox LMDB per una serie di esigenze, mentre, a partire dalla versione 9, Xcode LMDB a SQLite per la memorizzazione degli indici.
Il motore è emerso nel mondo dello sviluppo mobile. Le tracce del suo utilizzo si possono nell'app iOS di Telegram. LinkedIn è andato oltre e ha scelto LMDB come archivio predefinito per il framework interno di caching dei dati Rocket Data, di cui nel suo articolo del 2016.
LMDB si fa spazio nel settore lasciato da BerkeleyDB dopo il passaggio sotto il controllo di Oracle. La libreria è apprezzata per la sua velocità e affidabilità, anche rispetto a soluzioni simili. Come si suol dire, non ci sono pasti gratuiti, ed è importante sottolineare il trade-off che si dovrà affrontare nella scelta tra LMDB e SQLite. Lo schema sopra illustra chiaramente come si raggiunge una maggiore velocità. Innanzitutto, non paghiamo per strati di astrazione aggiuntivi oltre al sistema di archiviazione su disco. È chiaro che in una buona architettura non si può comunque prescindere da essi, e inevitabilmente appariranno nel codice dell'applicazione, tuttavia saranno molto più sottili. Non includeranno funzionalità non necessarie per l'applicazione specifica, come il supporto per le query in SQL. In secondo luogo, si ha la possibilità di mappare in modo ottimale le operazioni applicative su richieste verso l'archiviazione su disco. Se SQLite Si parte dalle esigenze medie di un'applicazione tipica, come sviluppatore applicativo sei ben consapevole degli scenari di carico fondamentali. Una soluzione più performante comporterà un costo maggiore sia per lo sviluppo della soluzione iniziale che per il suo successivo supporto.
3. I tre pilastri di LMDB
Guardando a LMDB da un punto di vista panoramico, è giunto il momento di scendere più a fondo. I prossimi tre sezioni saranno dedicate all'analisi dei principali pilastri su cui si basa l'architettura del database:
- File mappati in memoria come meccanismo di interazione con il disco e sincronizzazione delle strutture dati interne.
- B+-albero come organizzazione della struttura dei dati memorizzati.
- Copy-on-write come approccio per garantire le proprietà ACID delle transazioni e la multilivello.
3.1. Pilastro n. 1. File mappati in memoria
I file mappati in memoria sono un elemento architettonico così importante che compaiono persino nel nome del database. Le questioni relative alla memorizzazione nella cache e alla sincronizzazione dell'accesso alle informazioni memorizzate sono completamente affidate al sistema operativo. LMDB non contiene alcuna cache interna. Questa è una decisione consapevole dell'autore, poiché la lettura dei dati direttamente dai file mappati consente di risparmiare risorse nella realizzazione del motore. Di seguito presento un elenco, sebbene non completo, di alcuni di questi aspetti.
- Mantenere la coerenza dei dati nel database mentre viene utilizzato da più processi diventa responsabilità del sistema operativo. Nel prossimo paragrafo, questa meccanica è descritta in dettaglio con immagini.
- L'assenza di cache libera completamente LMDB dai costi associati alle allocazioni dinamiche. In pratica, la lettura dei dati equivale a impostare un puntatore sull'indirizzo corretto nella memoria virtuale e nient'altro. Sembra fantascienza, ma nel codice sorgente del database tutte le chiamate a salloc sono concentrate nella funzione di configurazione del database.
- L'assenza di cache significa anche assenza di blocchi legati alla sincronizzazione per l'accesso. I lettori, di cui possono esistere un numero arbitrario contemporaneamente, non incontrano alcun mutex nel loro cammino verso i dati. Questo garantisce una velocità di lettura con una scalabilità lineare ideale in base al numero di CPU. In LMDB, solo le operazioni modificative sono soggette a sincronizzazione. In un dato momento, può esserci solo uno scrittore.
- Un minimo di logica di caching e di sincronizzazione libera il codice da errori estremamente complessi legati al funzionamento in un ambiente multi-thread. Alla conferenza Usenix OSDI 2014 ci sono stati due interessanti studi sui database: e . Da essi si possono trarre informazioni sia sull'affidabilità senza precedenti di LMDB, sia su una realizzazione praticamente impeccabile delle proprietà ACID delle transazioni, superando la corrispondente implementazione in SQLite.
- La minimalismo di LMDB permette che la rappresentazione del suo codice possa essere interamente collocata nella cache L1 del processore, con le conseguenti caratteristiche di velocità.
Sfortunatamente, in iOS la gestione dei file mappati in memoria non è così semplice come si spererebbe. Per discutere in modo più consapevole degli svantaggi ad essi legati, è necessario ricordare i principi generali di implementazione di questo meccanismo nei sistemi operativi.
Informazioni sui file mappati in memoria
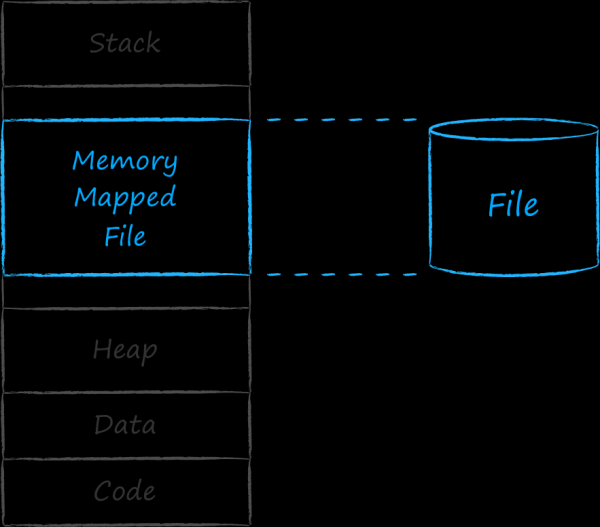 Ogni applicazione eseguita è associata a un'entità chiamata processo dal sistema operativo. A ciascun processo viene assegnato un intervallo continuo di indirizzi, nel quale posiziona tutto il necessario per il funzionamento. Nella parte inferiore degli indirizzi si trovano le sezioni con il codice e i dati e risorse hardcoded. Seguendo c'è un blocco crescente di spazio di indirizzamento dinamico, noto con il nome di heap. Qui si trovano gli indirizzi delle entità che appaiono durante l'esecuzione del programma. Nella parte superiore c'è l'area di memoria utilizzata dallo stack dell'applicazione. Essa cresce e si restringe, in altre parole, la sua dimensione ha anche una natura dinamica. Per evitare che lo stack e l'heap si scontrino e si disturbino a vicenda, sono separati agli estremi opposti dello spazio di indirizzamento. Tra le due sezioni dinamiche, in alto e in basso, c'è un intervallo vuoto. Gli indirizzi in quest'area centrale sono utilizzati dal sistema operativo per associare al processo le entità più varie. In particolare, può associare a un continuo insieme di indirizzi un file sul disco. Tale file è chiamato file mappato in memoria.
Ogni applicazione eseguita è associata a un'entità chiamata processo dal sistema operativo. A ciascun processo viene assegnato un intervallo continuo di indirizzi, nel quale posiziona tutto il necessario per il funzionamento. Nella parte inferiore degli indirizzi si trovano le sezioni con il codice e i dati e risorse hardcoded. Seguendo c'è un blocco crescente di spazio di indirizzamento dinamico, noto con il nome di heap. Qui si trovano gli indirizzi delle entità che appaiono durante l'esecuzione del programma. Nella parte superiore c'è l'area di memoria utilizzata dallo stack dell'applicazione. Essa cresce e si restringe, in altre parole, la sua dimensione ha anche una natura dinamica. Per evitare che lo stack e l'heap si scontrino e si disturbino a vicenda, sono separati agli estremi opposti dello spazio di indirizzamento. Tra le due sezioni dinamiche, in alto e in basso, c'è un intervallo vuoto. Gli indirizzi in quest'area centrale sono utilizzati dal sistema operativo per associare al processo le entità più varie. In particolare, può associare a un continuo insieme di indirizzi un file sul disco. Tale file è chiamato file mappato in memoria.
Lo spazio di indirizzamento del processo è enorme. Teoricamente, il numero di indirizzi è limitato solo dalla dimensione del puntatore, che è determinata dalla bitness del sistema. Se fosse associata 1 a 1 alla memoria fisica, il primo processo mangerebbe tutta la RAM e non ci sarebbe alcuna possibilità di multitasking.
Tuttavia, dalla nostra esperienza sappiamo che i moderni sistemi operativi possono eseguire simultaneamente un numero qualsiasi di processi. Questo è possibile perché allocano solo sulla carta un sacco di memoria ai processi, mentre in realtà caricano nella memoria fisica principale solo la parte che è richiesta qui e ora. Pertanto, la memoria associata al processo è chiamata virtuale.
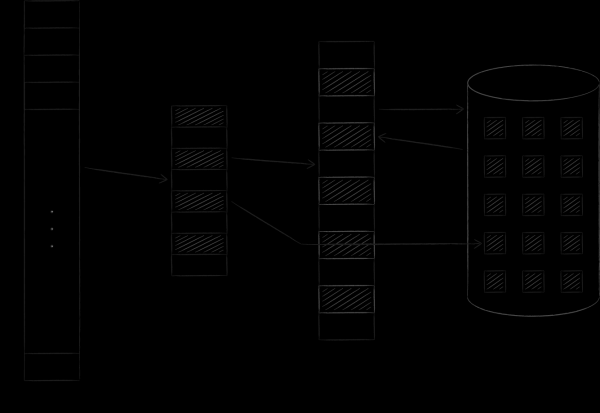
Il sistema operativo organizza la memoria virtuale e fisica in pagine di dimensioni specifiche. Quando una pagina di memoria virtuale viene richiesta, il sistema operativo la carica nella memoria fisica e stabilisce il corrispondente in una tabella speciale. Se non ci sono slot liberi, una delle pagine precedentemente caricate viene copiata su disco, mentre la pagina richiesta occupa il suo posto. Questa procedura, a cui torneremo a breve, è chiamata swapping. L'immagine sottostante illustra il processo descritto. Essa mostra la pagina A con indirizzo 0 che è stata caricata e posizionata nella pagina della memoria principale con indirizzo 4. Questo fatto è riflesso nella tabella di corrispondenze nella cella numero 0.
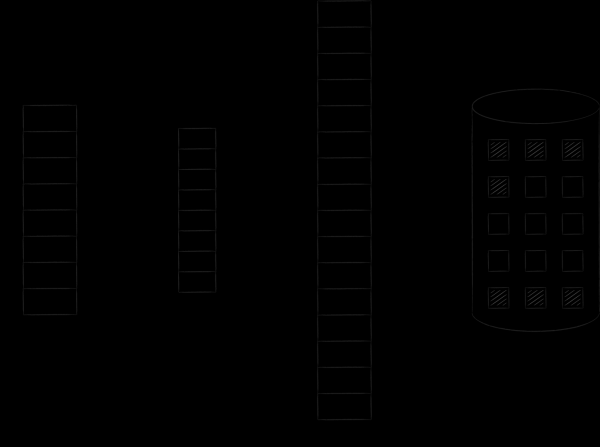
La storia dei file in memoria è esattamente la stessa. Logicamente, sono presunti essere continuamente e completamente posizionati nello spazio degli indirizzi virtuali. Tuttavia, entrano nella memoria fisica pagina per pagina e solo su richiesta. La modifica di queste pagine viene sincronizzata con il file sul disco. In questo modo, è possibile eseguire operazioni di input/output sui file semplicemente lavorando con i byte in memoria: tutte le modifiche verranno automaticamente trasferite dal kernel del sistema operativo al file originale.
L'immagine sottostante illustra come LMDB sincronizza il proprio stato quando lavora con un database da diversi processi. Mappando la memoria virtuale di diversi processi su un unico file, di fatto obblighiamo il sistema operativo a sincronizzare transitivamente tra loro alcuni blocchi dei loro spazi di indirizzi, dove poi LMDB effettua le letture.
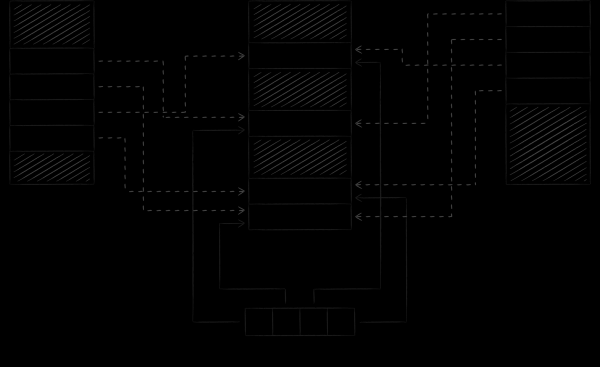
Un punto importante è che LMDB modifica per impostazione predefinita il file contenente i dati attraverso il meccanismo della chiamata di sistema write, mentre il file stesso viene visualizzato in modalità di sola lettura. Questo approccio ha due importanti conseguenze.
La prima conseguenza è comune a tutti i sistemi operativi. Essa consiste nell'aggiunta di una protezione contro la modifica involontaria del database a causa di codice errato. Come è noto, le istruzioni eseguibili di un processo possono accedere ai dati da qualsiasi punto del proprio spazio di indirizzamento. Allo stesso tempo, come abbiamo appena ricordato, l'assegnazione di un file in modalità read-write significa che qualsiasi istruzione può anche modificarlo. Se dovesse farlo erroneamente, cercando ad esempio di sovrascrivere un elemento dell'array a un indice inesistente, potrebbe incidentalmente cambiare il file mappato su quell'indirizzo, causando la corruzione del database. Se invece il file è assegnato in modalità read-only, il tentativo di modificare lo spazio di indirizzamento corrispondente porterà a un'interruzione del programma con il segnale SIGSEGV, e il file rimarrà integro.
La seconda conseguenza è già specifica per iOS. Né l'autore né altre fonti lo menzionano esplicitamente, ma senza di essa LMDB non sarebbe utilizzabile su questo sistema operativo mobile. La sua discussione è l'argomento della sezione successiva.
Specificità dei file mappati in memoria su iOS
Nel 2018, c'è stata una presentazione eccezionale alla WWDC . Spiega che su iOS tutte le pagine presenti nella memoria fisica appartengono a uno dei 3 tipi: dirty, compressed e clean.

La clean memory è l'insieme delle pagine che possono essere scaricate dalla memoria fisica senza problemi. I dati in esse possono essere ricaricati dai loro fonti originali all'occorrenza. I file mappati in memoria di sola lettura rientrano precisamente in questa categoria. iOS non teme di scaricare dalla memoria le pagine mappate su file in qualsiasi momento, poiché sono garantite per essere sincronizzate con il file sul disco.
La dirty memory include tutte le pagine modificate, indipendentemente da dove si trovassero originariamente. In particolare, anche i file mappati in memoria che sono stati modificati tramite scrittura nella memoria virtuale associata verranno classificati in questo modo. Aprendo LMDB con il flag MDB_WRITEMAP, dopo aver apportato modifiche, puoi verificarlo di persona.
Quando un'applicazione inizia a occupare troppa memoria fisica, iOS ne sottopone le pagine sporche a compressione. La somma di memoria occupata dalle pagine sporche e compresse costituisce quello che si chiama il memory footprint dell'applicazione. Una volta raggiunta una certa soglia, il demone di sistema OOM killer interviene e termina forzatamente il processo. Questa è una caratteristica di iOS rispetto ai sistemi operativi desktop. A differenza di questi ultimi, la riduzione del memory footprint tramite lo swapping delle pagine dalla memoria fisica al disco non è prevista in iOS. I motivi possono solo essere ipotizzati. Forse la procedura di spostamento intensivo delle pagine su disco e viceversa è troppo dispendiosa in termini di energia per i dispositivi mobili, oppure iOS risparmia le risorse per la riscrittura delle celle sui dischi SSD, o forse i progettisti non erano soddisfatti delle prestazioni generali del sistema, in cui tutto viene continuamente scambiato. In ogni caso, il fatto rimane.
Buona notizia, già menzionata in precedenza, è che LMDB di default non utilizza il meccanismo mmap per aggiornare i file. Di conseguenza, i dati mappati sono classificati da iOS come clean memory e non contribuiscono al memory footprint. Questo può essere verificato usando uno strumento di Xcode chiamato VM Tracker. Nello screenshot qui sotto è mostrato lo stato della memoria virtuale dell'app iOS Obcloud durante il funzionamento. All'avvio sono stati inizializzati 2 istanze di LMDB. Alla prima è stato consentito di mappare il proprio file su 1 GiB di memoria virtuale, mentre alla seconda su 512 MiB. Nonostante entrambi i depositi occupino un certo volume di memoria residente, nessuno di essi contribuisce al dirty size.
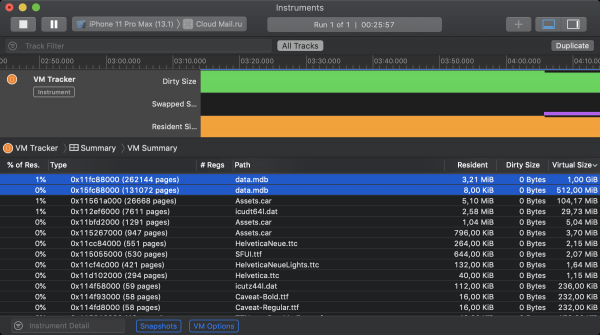
E ora è tempo di brutte notizie. Grazie al meccanismo di swapping nei sistemi operativi desktop a 64 bit, ogni processo può occupare tanto spazio di indirizzo virtuale quanto consente lo spazio libero sul disco rigido per il suo potenziale swap. Sostituire lo swapping con la compressione in iOS riduce drasticamente il limite teorico. Ora, tutti i processi devono entrare nella memoria principale (leggi RAM), e quelli che non riescono sono soggetti a chiusura forzata. Di questo si parla nella , sia in . Di conseguenza, iOS limita rigidamente la quantità di memoria disponibile per l'allocazione tramite mmap. Ecco è possibile esaminare i limiti empirici dei volumi di memoria che sono riusciti ad allocare su diversi dispositivi tramite questa chiamata di sistema. Nei modelli più moderni di smartphone iOS, Apple ha generosamente offerto 2 gigabyte, mentre nelle versioni top di iPad, addirittura 4. Nella pratica, naturalmente, è necessario fare riferimento ai modelli più economici supportati, dove la situazione è piuttosto triste. Peggio ancora, osservando lo stato della memoria dell'applicazione in VM Tracker, si può scoprire che LMDB non è certo l'unico a pretender memoria mappata. Buoni pezzi sono consumati da allocatori di sistema, file di risorse, framework per la gestione delle immagini e altre piccole creature affamate.
Dopo gli esperimenti nel Cloud, siamo arrivati ai seguenti valori di compromesso per la memoria allocata a LMDB: 384 megabyte per dispositivi a 32 bit e 768 per quelli a 64 bit. Dopo aver esaurito questo volume, tutte le operazioni modificative iniziano a terminare con il codice MDB_MAP_FULL. Questi errori li osserviamo nel nostro monitoraggio, ma sono abbastanza rari da poter essere trascurati in questa fase.
Una ragione poco evidente per il consumo eccessivo di memoria da parte del database può essere rappresentata da transazioni a lungo termine. Per capire come siano collegate queste due questioni, ci aiuterà l'analisi degli altri due pilastri di LMDB.
3.2. Pilastro n. 2. B+-Albero
Per emulare tabelle sopra un archivio key-value, è necessario che la sua API supporti le seguenti operazioni:
- Inserimento di un nuovo elemento.
- Ricerca di un elemento con una chiave specificata.
- Rimozione di un elemento.
- Iterazione su intervalli di chiavi in ordine di ordinamento.
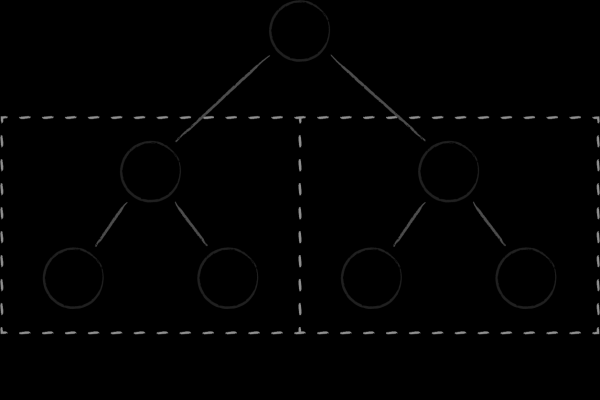 La struttura dati più semplice che permette di implementare facilmente tutte e quattro le operazioni è l'albero di ricerca binario. Ogni nodo rappresenta una chiave, dividendo l'intero insieme di chiavi figlie in due sotto-alberi. A sinistra si raccolgono quelle che sono minori del nodo genitore, mentre a destra si trovano quelle che sono maggiori. Ottenere un insieme ordinato di chiavi si raggiunge tramite una delle classiche esplorazioni dell'albero.
La struttura dati più semplice che permette di implementare facilmente tutte e quattro le operazioni è l'albero di ricerca binario. Ogni nodo rappresenta una chiave, dividendo l'intero insieme di chiavi figlie in due sotto-alberi. A sinistra si raccolgono quelle che sono minori del nodo genitore, mentre a destra si trovano quelle che sono maggiori. Ottenere un insieme ordinato di chiavi si raggiunge tramite una delle classiche esplorazioni dell'albero.
Gli alberi binari presentano due difetti fondamentali che ne compromettono l'efficienza come struttura dati su disco. In primo luogo, il grado di bilanciamento è imprevedibile. Esiste un notevole rischio di avere alberi in cui l'altezza dei vari rami può differire significativamente, il che peggiora notevolmente la complessità algoritmica della ricerca rispetto a quanto atteso. In secondo luogo, l'abbondanza di riferimenti incrociati tra i nodi priva gli alberi binari della località in memoria. Nodi vicini (in termini di collegamenti tra loro) possono trovarsi su pagine completamente diverse nella memoria virtuale. Di conseguenza, persino per una semplice attraversamento di alcuni nodi adiacenti nell'albero, potrebbe essere necessario visitare un numero comparabile di pagine. Questo rappresenta un problema anche quando si considera l'efficienza degli alberi binari come struttura dati in-memory, poiché la continua rotazione delle pagine nella cache del processore non è un'operazione economica. Quando si tratta di dover frequentemente caricare le pagine associate ai nodi dal disco, la situazione diventa veramente critica. .
 Gli B-alberi, essendo un'evoluzione degli alberi binari, risolvono i problemi menzionati nel paragrafo precedente. In primo luogo, sono auto-bilanciati. In secondo luogo, ogni nodo suddivide una serie di chiavi figlie non in 2, ma in M sottoinsiemi ordinati, con M che può essere piuttosto grande, nell'ordine di centinaia o addirittura migliaia.
Gli B-alberi, essendo un'evoluzione degli alberi binari, risolvono i problemi menzionati nel paragrafo precedente. In primo luogo, sono auto-bilanciati. In secondo luogo, ogni nodo suddivide una serie di chiavi figlie non in 2, ma in M sottoinsiemi ordinati, con M che può essere piuttosto grande, nell'ordine di centinaia o addirittura migliaia.
Grazie a ciò:
- In ogni nodo si trova un gran numero di chiavi già ordinate, rendendo gli alberi molto bassi.
- L'albero acquisisce la proprietà di località di memorizzazione, poiché le chiavi di valore simile si trovano naturalmente vicine l'una all'altra nello stesso nodo o in nodi vicini.
- Si riduce il numero di nodi di transito durante la discesa nell'albero durante l'operazione di ricerca.
- Si riduce il numero di nodi target letti durante le query range, poiché ognuno di essi contiene già un gran numero di chiavi ordinate.
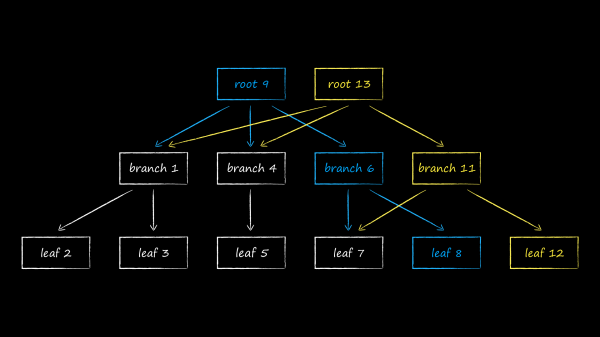
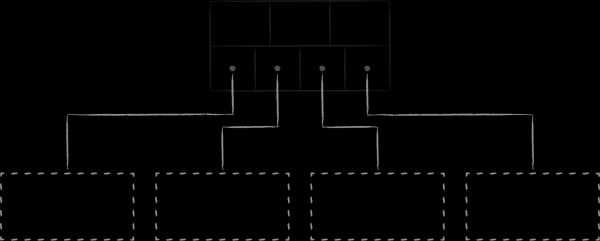
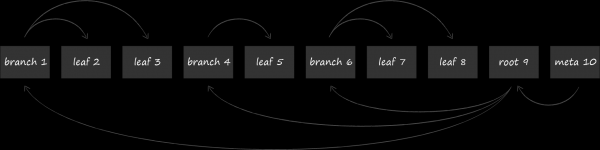
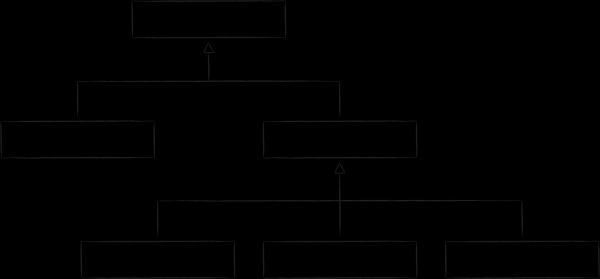
In LMDB, per lo stoccaggio dei dati, viene utilizzata una delle varianti dell'albero B chiamata B+-albero. Nello schema sopra sono rappresentati tre tipi di nodi che possono esserci:
- In cima si trova la radice (root). Essa rappresenta nient'altro che il concetto di database all'interno dello storage. All'interno di un'istanza di LMDB, è possibile creare più database che condividono lo spazio indirizzabile virtuale mappato. Ognuno di essi inizia con la propria radice.
- Al livello più basso si trovano le foglie (leaf). Esse contengono esclusivamente le coppie chiave-valore memorizzate nel database. A proposito, questa è proprio la peculiarità degli alberi B+. Se un albero B standard memorizza le parti value nei nodi di tutti i livelli, la variazione B+ fa ciò solo nel livello più basso. Registrato questo fatto, d'ora in avanti ci riferiremo al sottotipo dell'albero utilizzato in LMDB semplicemente come albero B.
- Tra la radice e le foglie si trovano 0 o più livelli tecnici con nodi di navigazione (branch). Il loro compito è quello di suddividere l'insieme ordinato di chiavi tra le foglie.
I nodi fisici sono blocchi di memoria di lunghezza prestabilita. La loro dimensione è un multiplo della dimensione delle pagine di memoria del sistema operativo, di cui abbiamo parlato in precedenza. Di seguito è mostrata la struttura del nodo. Nell'intestazione si trova la metainformazione, la più evidente delle quali è per esempio la somma di controllo. Segue l'informazione sugli offset dove si trovano le celle con i dati. I dati possono essere rappresentati o da chiavi, se si parla di nodi di navigazione, o da coppie chiave-valore complete nel caso delle foglie. Maggiori dettagli sulla struttura delle pagine possono essere letti nel lavoro .
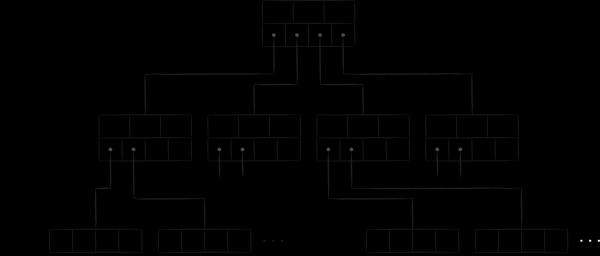
Dopo aver esaminato il contenuto interno dei nodi-pagina, rappresenteremo successivamente in modo semplificato l'albero B LMDB nel seguente modo.
Le pagine con i nodi si trovano consecutivamente sul disco. Le pagine con numeri maggiori sono posizionate più vicino alla fine del file. La cosiddetta pagina meta (meta page) contiene informazioni sugli offset che possono essere utilizzati per trovare le radici di tutti gli alberi. Quando si apre un file LMDB, si esegue una scansione pagina per pagina del file dalla fine all'inizio alla ricerca di una metapagina valida, e attraverso di essa trova i database esistenti.
Adesso, avendo una comprensione della struttura logica e fisica dell'organizzazione dei dati, possiamo passare in rassegna il terzo pilastro di LMDB. È grazie a questo che tutte le modifiche al repository avvengono in modo transazionale e isolate l'una dall'altra, conferendo alla base di dati nel suo complesso anche la proprietà della multi-versioning.
3.3. Pilastro n. 3. Copy-on-write
Alcune operazioni con l'albero B richiedono di apportare una serie di modifiche ai suoi nodi. Un esempio è l'aggiunta di una nuova chiave a un nodo che ha già raggiunto la capacità massima. In questo caso, è necessario, da un lato, dividere il nodo in due e, dall'altro, aggiungere un riferimento al nuovo nodo figlio distaccato nel suo genitore. Questa procedura è potenzialmente molto pericolosa. Se, per qualche motivo (crash, blackout, ecc.), si dovesse verificare solo una parte delle modifiche della serie, l'albero rimarrebbe in uno stato incoerente.
Una delle soluzioni tradizionali per garantire la resilienza dei database ai guasti è l'aggiunta, accanto all'albero B, di una struttura dati su disco aggiuntiva: il log delle transazioni, noto anche come write-ahead log (WAL). Si tratta di un file nel quale vengono registrate le operazioni previste prima della modifica dell'albero B stesso. In questo modo, se durante l'autodiagnosi viene rilevata una corruzione dei dati, il database consulta il log per ripristinarsi.
LMDB ha scelto un altro metodo per garantire la resilienza ai guasti, chiamato copy-on-write. La sua essenza consiste nel fatto che, invece di aggiornare i dati su una pagina esistente, questa viene prima copiata integralmente e tutte le modifiche vengono effettuate già nella copia.
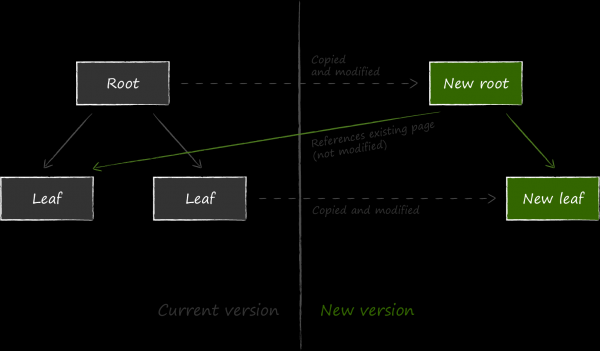
Successivamente, affinché i dati aggiornati siano disponibili, è necessario cambiare il collegamento al nodo aggiornato nel nodo genitore relativo. Poiché anche questo deve essere modificato, viene anch'esso copiato in precedenza. Il processo continua ricorsivamente fino alla radice. Per ultimi, vengono aggiornati i dati nella pagina meta.
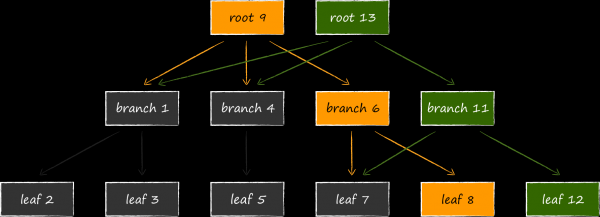
Se durante la procedura di aggiornamento si verifica un'interruzione imprevista del processo, potrebbe non crearsi una nuova meta-pagina o non essere scritta su disco fino alla fine, e il suo checksum risulterà errato. In entrambi i casi, le nuove pagine saranno inaccessibili, mentre le pagine precedenti non subiranno danni. Questo solleva LMDB dall'obbligo di mantenere un write ahead log per garantire la coerenza dei dati. La struttura di archiviazione dei dati su disco sopra descritta svolge contemporaneamente anche questa funzione. L'assenza esplicita di un log delle transazioni è una delle caratteristiche distintive di LMDB che garantisce elevate velocità di lettura dei dati.
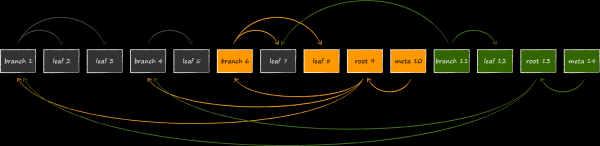
La struttura risultante chiamata append-only B-tree garantisce naturalmente l'isolamento delle transazioni e la multi-versioning. In LMDB, ogni transazione aperta è associata a una radice dell'albero attuale. Finché la transazione non è completata, le pagine dell'albero ad essa collegato non verranno mai modificate o riutilizzate per nuove versioni dei dati. Pertanto, puoi lavorare a lungo con il set di dati che era valido al momento dell'apertura della transazione, anche se lo storage continua ad essere attivamente aggiornato. Questa è l'essenza della multi-versioning, che rende LMDB una fonte di dati ideale per tutti noi amati. UICollectionView. Aprendo una transazione, non è necessario aumentare il footprint di memoria dell'applicazione estraendo frettolosamente i dati aggiornati in una qualche struttura in-memory, temendo di rimanere a mani vuote. Questa caratteristica distingue favorevolmente LMDB da SQLite, che non può vantare una tale totale isolamento. Aprendo due transazioni in quest'ultimo e eliminando un certo record all'interno di una di esse, non sarà più possibile recuperare lo stesso record nell'altra rimanente.
D'altra parte, c'è il potenziale di un consumo virtuale di memoria significativamente maggiore. Nella diapositiva è mostrata la struttura del database se la sua modifica avviene contemporaneamente con 3 transazioni aperte in lettura, che guardano a versioni diverse del database. Poiché LMDB non può riutilizzare i nodi accessibili dalle radici associate alle transazioni attive, lo storage non ha altra scelta che allocare in memoria un quarto nodo e clonare nuovamente le pagine modificabili sotto di esso.
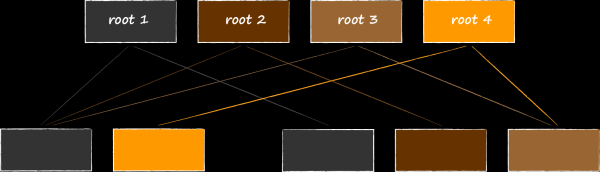
È utile ricordare la sezione sui file mappati in memoria. Sembra che il maggiore utilizzo della memoria virtuale non dovrebbe preoccuparci troppo, poiché non contribuisce in modo significativo al memory footprint dell'applicazione. Tuttavia, è stato notato che iOS è molto parsimonioso nel suo utilizzo e non possiamo semplicemente allocare un'area LMDB di 1 terabyte come su un server o un desktop, senza pensare a questa particolare caratteristica. Dobbiamo cercare di mantenere la durata delle transazioni il più breve possibile.
4. Progettazione dello schema dati sopra l'API key-value
Iniziamo l'analisi dell'API esaminando le astrazioni di base fornite da LMDB: ambienti e database, chiavi e valori, transazioni e cursori.
Nota sui listati di codice
Tutte le funzioni nell'API pubblica di LMDB restituiscono il risultato delle loro operazioni sotto forma di codice di errore, ma nelle successive liste questo controllo è stato omesso per motivi di brevità. In pratica, abbiamo utilizzato il nostro wrapper C++ , in cui gli errori si manifestano sotto forma di eccezioni C++.
Come metodo più rapido per collegare LMDB al tuo progetto per iOS o macOS, ti consiglio il mio CocoaPod. .
4.1. Astrazioni di base
Ambiente (environment)
Struttura MDB_env è un contenitore per lo stato interno di LMDB. La famiglia di funzioni con il prefisso mdb_env consente di configurare alcune delle sue proprietà. Nel caso più semplice, l'inizializzazione del motore appare come segue.
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);Nell'app di Cloud Mail.ru, abbiamo modificato solo due parametri dei valori di default.
Il primo di questi è la dimensione dello spazio indirizzi virtuali a cui viene mappato il file di archiviazione. Sfortunatamente, anche sullo stesso dispositivo, un valore specifico può differire significativamente da un'esecuzione all'altra. Per tenere conto di questa particolarità di iOS, la dimensione massima dell'archiviazione viene determinata dinamicamente. Iniziando con un certo valore, essa viene successivamente dimezzata fino a quando la funzione mdb_env_open non restituisce un risultato diverso da ENOMEM. In teoria, esiste anche l'approccio opposto: riservare inizialmente al motore il minimo di memoria, e poi, in caso di errori. MDB_MAP_FULL, ma è molto più difficile. La ragione è che la procedura di riproposizione della memoria (remap) tramite la funzione mdb_env_set_map_size invalidates all entities (cursors, transactions, keys, and values) obtained from the engine earlier. Taking such a turn of events into account in the code will significantly complicate it. However, if virtual memory is very important to you, this might be a reason to look at a far-advanced fork , where among the listed features is 'automatic on-the-fly database size adjustment.'
Il secondo parametro, il cui valore predefinito non ci è andato a genio, regola la meccanica della sicurezza dei thread. Sfortunatamente, almeno in iOS 10 ci sono problemi con il supporto dello storage locale dei thread. Per questo motivo, nell'esempio sopra, lo storage viene aperto con il flag MDB_NOTLS. Inoltre, era necessario anche la wrapper C++ , per rimuovere le variabili con questo attributo anche in essa.
Database
Il database è un'istanza separata di un albero B, di cui abbiamo parlato sopra. La sua apertura avviene all'interno di una transazione, il che può sembrare un po' strano inizialmente.
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);In effetti, una transazione in LMDB è un'entità dello storage, non di un singolo database. Questa concezione permette operazioni atomiche su entità che si trovano in database diversi. In teoria, ciò apre la possibilità di modellare le tabelle come database distinti, ma io ho scelto un'altra via, che descriverò nei dettagli qui sotto.
Chiavi e valori
Struttura MDB_val modella sia la chiave che il valore. Lo storage non ha la minima comprensione della loro semantica. Per esso, qualcosa che è un valore, è semplicemente un array di byte di dimensioni definite. La dimensione massima della chiave è di 512 byte.
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;Con il comparatore, il sistema ordina le chiavi in ordine crescente. Se non viene fornito un proprio comparatore, verrà utilizzato il predefinito, che ordina le chiavi byte per byte in ordine lessicografico.
Transazioni
La struttura delle transazioni è descritta in , quindi qui ripeterò brevemente le loro principali proprietà:
- Supporto per tutte le proprietà di base : atomicità, coerenza, isolamento e durabilità. Non posso non notare che, per quanto riguarda la durabilità su macOS e iOS, c'è un bug risolto in MDBX. Puoi leggere di più nel loro .
- L'approccio alla multi-threading è descritto nello schema «scrittore singolo / lettori multipli». Gli scrittori si bloccano a vicenda, ma non bloccano i lettori. I lettori non bloccano né gli scrittori né altri lettori.
- Supporto per transazioni annidate.
- Supporto per la multi-versioning.
La multi-versioning in LMDB è così buona che voglio dimostrarla in azione. Dal codice sottostante si vede che ogni transazione lavora esattamente con quella versione del database che era attiva al momento della sua apertura, essendo completamente isolata da tutte le modifiche successive. L'inizializzazione dello storage e l'aggiunta di un record di test non offrono nulla di interessante, quindi queste operazioni sono state lasciate sotto spoiler.
Aggiunta di un record di test
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Apriamo 2 transazioni, ognuna delle quali guarda
// alla versione del database con un record.
mdb_txn_begin(env, NULL, 0, &txn1); // lettura-scrittura
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // sola lettura
// All'interno della prima transazione, eliminiamo dal database il record esistente.
mdb_del(txn1, dbi, &key, NULL);
// Confermiamo l'eliminazione.
mdb_txn_commit(txn1);
// Apriamo una terza transazione, che guarda
// all'attuale versione del database, dove il record non esiste più.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Ci assicuriamo che il record con la chiave cercata non esista più.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Terminiamo la transazione.
mdb_txn_abort(txn3);
// Ci assicuriamo che all'interno della seconda transazione, aperta al momento
// dell'esistenza del record nel database, sia ancora possibile trovarlo per chiave.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Verifichiamo che per la chiave non si otterrà un dato qualunque, ma dati validi.
assert(*(int *)val.mv_data == 997);
// Terminiamo la transazione, che lavora anche se con un database obsoleto, ma consistente.
mdb_txn_abort(txn2);Consiglio facoltativo di provare a fare lo stesso esperimento con SQLite e vedere cosa ne esce.
La multi-versione offre vantaggi significativi per gli sviluppatori iOS. Grazie a questa funzionalità, è possibile gestire facilmente e senza sforzo la velocità di aggiornamento delle fonti dati per i moduli sullo schermo, tenendo conto dell'esperienza utente. Prendiamo come esempio una funzionalità dell'applicazione Mail.ru Cloud, ovvero il caricamento automatico dei contenuti dalla galleria multimediale di sistema. Con una buona connessione, il cliente può caricare sul server diverse foto al secondo. Se, dopo ogni caricamento, si aggiorna UICollectionView il contenuto multimediale nel cloud dell'utente, si può dimenticare di 60 fps e di uno scorrimento fluido durante questo processo. Per prevenire aggiornamenti frequenti dello schermo, è necessario limitare la velocità di cambiamento dei dati sottostanti UICollectionViewDataSource.
Se il database non supporta la multiversione e consente solo di lavorare con lo stato attuale, per creare un'istantanea stabile nel tempo dei dati è necessario copiarla in una qualche struttura di dati in memoria o in una tabella temporanea. Ognuno di questi approcci è molto gravoso. Nel caso di uno storage in-memory, abbiamo costi sia in termini di memoria, causati dalla conservazione degli oggetti costruiti, sia in termini di tempo, legati a trasformazioni ORM eccessive. Per quanto riguarda la tabella temporanea, si tratta di un piacere ancora più costoso, che ha senso solo in casi non banali.
La multiversione di LMDB risolve il compito di mantenere una fonte di dati stabile in modo molto elegante. È sufficiente aprire una transazione e voilà — finché non la completiamo, il set di dati è garantito come fissato. La logica della sua velocità di aggiornamento ora è interamente nelle mani del layer di presentazione, senza significativi costi aggiuntivi di risorse.
Cursori
I cursori forniscono un meccanismo per l'iterazione ordinata su coppie chiave-valore attraverso la navigazione di un B-albero. Senza di essi, sarebbe impossibile modellare efficacemente le tabelle in un database, per cui ci sposteremo ora a discuterne.
4.2. Modellazione delle tabelle
La proprietà dell'ordinamento delle chiavi consente di costruire, sopra le astrazioni di base, un livello elevato come la tabella. Esaminiamo questo processo mediante l'esempio di una tabella principale di un cliente cloud, che memorizza informazioni su tutti i file e cartelle dell'utente.
Schema della tabella
Uno degli scenari comuni per cui la struttura della tabella deve essere ottimizzata è l'estrazione di tutti gli elementi all'interno di una certa directory. Un buon modello di organizzazione dei dati per richieste di questo tipo è . Per realizzarlo, è necessario ordinare le chiavi dei file e delle cartelle in modo che siano raggruppate in base alla loro appartenenza alla directory genitore, sovrapponendo allo storage key-value. Inoltre, per visualizzare il contenuto della directory così come è abituale per gli utenti di Windows (prima le cartelle, poi i file, con entrambi ordinati alfabeticamente), devono essere inclusi nei rispettivi campi della chiave ulteriori campi informativi.
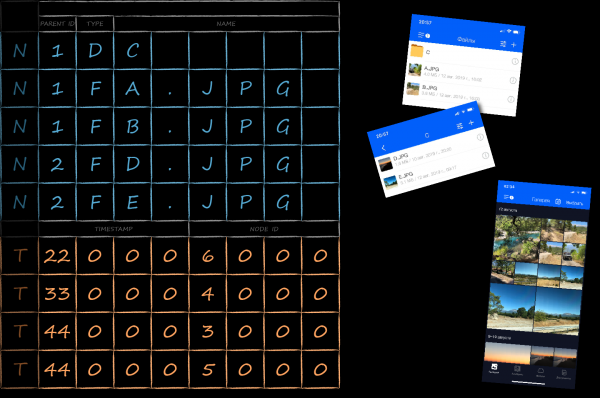
Nell'immagine qui sotto è mostrato come, in base al compito posto, potrebbe apparire la rappresentazione delle chiavi come array di byte. All'inizio si trovano i byte con l'identificativo della directory genitore (rossi), poi quelli con il tipo (verdi) e infine alla fine quelli con il nome (blu). Ordinati con il comparatore predefinito di LMDB in ordine lessicografico, vengono organizzati nel modo richiesto. Una scansione sequenziale delle chiavi con lo stesso prefisso rosso ci dà i valori corrispondenti nell'ordine in cui devono essere mostrati nell'interfaccia utente (a destra), senza richiedere ulteriori post-elaborazioni.

Serializzazione di chiavi e valori
Nel mondo sono stati creati molti metodi per la serializzazione degli oggetti. Poiché non avevamo altre esigenze oltre alla velocità, abbiamo scelto il metodo più veloce disponibile: il dump della memoria occupata dall'istanza di una struttura del linguaggio C. Così, la chiave di un elemento del catalogo può essere modellata dalla seguente struttura NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Per il salvataggio NodeKey nel repository, è necessario posizionare un puntatore ai dati sull'indirizzo di inizio della struttura e calcolarne la dimensione con la funzione MDB_val sizeof MDB_val serialize(NodeKey * const key) { return MDB_val { .mv_size = sizeof(NodeKey), .mv_data = (void *)key }; }.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}Nella prima parte sui criteri di scelta del database, ho menzionato la minimizzazione delle allocazioni dinamiche nelle operazioni CRUD. Il codice della funzione serialize mostra come, nel caso di LMDB, sia possibile evitarle completamente durante l'inserimento di nuovi record nel database. L'array di byte ricevuto dal server viene prima trasformato in strutture stack, e poi vengono dumpate trivialmente nello storage. Considerando che all'interno di LMDB non ci sono allocazioni dinamiche, si può ottenere una situazione fantastica secondo i parametri iOS: utilizzare solo memoria stack per lavorare con i dati lungo tutto il loro percorso dalla rete fino al disco!
Ordinamento delle chiavi tramite un comparatore binario
Il rapporto di ordinamento delle chiavi è definito da una funzione speciale, chiamata comparatore. Poiché il motore non sa nulla della semantica dei byte contenuti, al comparatore di default non resta altro da fare che ordinare le chiavi in ordine lessicografico, ricorrendo al confronto byte per byte. Usarlo per ordinare strutture è simile a radere con un grosso accetta. Tuttavia, in casi semplici, trovo questo metodo accettabile. L'alternativa è descritta qui sotto, e qui segnerò un paio di insidie sparse su questo percorso.
La prima cosa da tenere a mente è la rappresentazione in memoria dei tipi di dati primitivi. Infatti, su tutti i dispositivi Apple, le variabili intere sono memorizzate nel formato . Ciò significa che il byte meno significativo sarà a sinistra e non sarà possibile ordinare i numeri interi utilizzando il loro confronto byte per byte. Ad esempio, un tentativo di farlo su un insieme di numeri da 0 a 511 darà il seguente risultato.
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)Per risolvere questo problema, i numeri interi devono essere memorizzati nella chiave in un formato adatto per il comparatore byte. Le funzioni della famiglia hton* aiuteranno a effettuare la conversione necessaria (in particolare htons per i numeri a due byte dell'esempio).
Il formato di rappresentazione delle stringhe nella programmazione è, come si sa, un'intera . Se la semantica delle stringhe e la codifica utilizzata per la loro rappresentazione in memoria prevedono che un simbolo possa richiedere più di un byte, è meglio abbandonare l'idea di utilizzare il comparatore predefinito.
La seconda cosa da tenere a mente è compilatore dei campi della struttura. A causa di essi possono formarsi byte con valori spazzatura nella memoria tra i campi, il che, naturalmente, rovina la scansione byte a byte. Per eliminare la spazzatura è necessario dichiarare i campi in un ordine rigoroso, tenendo a mente le regole di allineamento, oppure utilizzare l'attributo packed.
Ordinamento delle chiavi tramite un comparatore esterno
La logica di confronto delle chiavi può risultare troppo complessa per un comparatore binario. Una delle tante ragioni è la presenza di campi tecnici all'interno delle strutture. Illustro la loro comparsa utilizzando l'esempio della chiave già conosciuta per un elemento della directory.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Nonostante la sua semplicità, nella stragrande maggioranza dei casi consuma troppa memoria. Il buffer per il nome occupa 256 byte, mentre in media i nomi di file e cartelle raramente superano i 20-30 caratteri.
Uno dei metodi standard per ottimizzare la dimensione di un record consiste nel "modificarlo" in base alla dimensione effettiva. La sua essenza è che il contenuto di tutti i campi di lunghezza variabile è memorizzato in un buffer alla fine della struttura, mentre le loro lunghezze sono memorizzate in variabili separate. In conformità con questo approccio, la chiave NodeKey viene trasformata come segue.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Successivamente, durante la serializzazione, viene specificata come dimensione dei dati non MDB_val serialize(NodeKey * const key) { return MDB_val { .mv_size = sizeof(NodeKey), .mv_data = (void *)key }; } l'intera struttura, ma la dimensione di tutti i campi di lunghezza fissa più la dimensione della parte realmente utilizzata del buffer.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength,
.mv_data = (void *)key
};
}Di conseguenza, grazie alla rifattorizzazione, abbiamo ottenuto un notevole risparmio in termini di spazio occupato dalle chiavi. Tuttavia, a causa del campo tecnico nameLength, il comparatore binario predefinito non è più adatto per il confronto delle chiavi. Se non lo sostituiamo con uno nostro, la lunghezza del nome sarà un fattore di priorità superiore rispetto al nome stesso durante l'ordinamento.
LMDB consente di impostare una funzione di confronto delle chiavi per ciascun database. Questo avviene tramite la funzione mdb_set_compare fino all'apertura. Per ovvie ragioni, durante l'intera vita del database non è possibile modificarlo. Il comparatore riceve in input due chiavi in formato binario e restituisce come risultato del confronto: minore (-1), maggiore (1) o uguali (0). Pseudocodice per NodeKey è così.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}Finché tutte le chiavi nel database hanno lo stesso tipo, la conversione incondizionata della loro rappresentazione in byte al tipo della struttura chiave applicativa è legittima. C'è un piccolo dettaglio, ma verrà trattato più avanti nella sezione “Lettura dei record”.
Serializzazione dei valori
Con le chiavi delle voci LMDB, il lavoro è estremamente intenso. Il loro confronto avviene in ogni operazione applicativa, e la velocità del comparatore influisce sulle prestazioni dell'intera soluzione. In un mondo ideale, un comparatore binario predefinito dovrebbe essere sufficiente per il confronto delle chiavi, ma se è necessario utilizzare il proprio, la procedura di deserializzazione delle chiavi deve essere quanto più veloce possibile.
La parte Value della voce (il valore) non interessa particolarmente al database. La sua conversione da rappresentazione byte in oggetto avviene solo quando è già richiesta dal codice applicativo, ad esempio, per la sua visualizzazione sullo schermo. Poiché questa operazione è relativamente rara, le esigenze di velocità non sono così critiche, e nella sua implementazione siamo molto più liberi di orientarci verso la comodità. Ad esempio, per la serializzazione dei metadati di file non ancora caricati, utilizziamo NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};Tuttavia, ci sono casi in cui le prestazioni hanno comunque importanza. Ad esempio, per conservare le metainformazioni sulla struttura di file del cloud utente, utilizziamo sempre lo stesso dump di memoria degli oggetti. Il punto culminante della sfida nella formazione della loro rappresentazione serializzata è il fatto che gli elementi della directory sono modellati da una gerarchia di classi.
Per implementarla in C, i campi specifici degli eredi vengono spostati in strutture separate, e la loro connessione con la base è stabilita tramite un campo di tipo union. Il contenuto attuale dell'unione è definito tramite l'attributo tecnico type.
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;Aggiunta e aggiornamento delle registrazioni
Le chiavi e i valori serializzati possono essere aggiunti allo storage. A tal fine, si utilizza la funzione mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);Nella fase di configurazione, è possibile consentire o vietare la memorizzazione di più registrazioni con la stessa chiave. Se la duplicazione delle chiavi è vietata, durante l'inserimento di una registrazione si può specificare se è consentito aggiornare una registrazione esistente. Se la sovrascrittura può avvenire solo a causa di un errore nel codice, è possibile proteggersi da essa specificando un flag. NOOVERWRITE.
Lettura delle registrazioni
La funzione destinata alla lettura delle registrazioni in LMDB è mdb_get. Se la coppia chiave-valore è stata rappresentata in precedenza da strutture campionate, la procedura appare come segue.
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}Il listing presentato mostra come la serializzazione tramite il dump delle strutture permetta di eliminare le allocazioni dinamiche non solo durante la scrittura, ma anche durante la lettura dei dati. Quello ottenuto dalla funzione mdb_get Il puntatore punta esattamente all'indirizzo di memoria virtuale in cui il database memorizza la rappresentazione in byte dell'oggetto. In effetti, otteniamo una sorta di ORM, che fornisce praticamente gratuitamente una velocità di lettura dei dati molto elevata. Nonostante la bellezza dell'approccio, è importante ricordare alcune caratteristiche correlate.
- Per le transazioni in sola lettura, il puntatore alla struttura-valore rimarrà garantito valido solo fino a quando la transazione non sarà chiusa. Come già accennato, le pagine dell'albero B, su cui si trova l'oggetto, rimangono invariate grazie al principio copy-on-write fino a quando almeno una transazione fa riferimento a esse. Tuttavia, non appena l'ultima transazione associata si conclude, le pagine possono essere riutilizzate per nuovi dati. Se è necessario che gli oggetti sopravvivano alla transazione che li ha generati, dovranno comunque essere copiati.
- Per le transazioni di lettura e scrittura, il puntatore alla struttura-valore ottenuta sarà valido solo fino alla prima procedura di modifica (scrittura o eliminazione dei dati).
- Nonostante la struttura
NodeValuenon è una struttura completa, ma troncata (vedi sezione «Ordinamento delle chiavi tramite un comparatore esterno»), puoi accedere ai suoi campi tranquillamente tramite un puntatore. L'importante è non dereferenziarlo! - In nessun caso si può modificare la struttura tramite il puntatore ottenuto. Tutte le modifiche devono avvenire esclusivamente tramite il metodo
mdb_put. Tuttavia, anche volendo, non sarà possibile farlo, poiché l'area di memoria in cui si trova questa struttura è mappata in modalità di sola lettura. - Remappa il file nello spazio indirizzabile del processo con l'obiettivo, ad esempio, di aumentare la dimensione massima del deposito utilizzando la funzione
mdb_env_set_map_sizeinvalidate completamente tutte le transazioni e le entità associate in generale e i puntatori agli oggetti letti in particolare.
Infine, un'ulteriore caratteristica è così insidiosa che la sua rivelazione non si presta semplicemente a essere aggiunta come un altro punto. Nella sezione sul B-tree, ho fornito uno schema della disposizione delle sue pagine in memoria. Ne consegue che l'indirizzo di inizio del buffer contenente i dati serializzati può essere totalmente arbitrario. Per questo motivo, il puntatore a questi ultimi, ottenuto dalla struttura MDB_val e portato a un puntatore alla struttura, risulta in generale non allineato. Allo stesso tempo, le architetture di alcuni chip (nel caso di iOS, armv7) richiedono che l'indirizzo di qualsiasi dato sia un multiplo della dimensione della parola della macchina o, in altre parole, della bitness di sistema (per armv7 — è 32 bit). In altre parole, un'operazione come *(int *foo)0x800002 a esse è paragonata a una fuga e porta a una condanna con la sentenza EXC_ARM_DA_ALIGN. È possibile evitare tale triste sorte in due modi.
Il primo consiste nel copiare preventivamente i dati in una struttura chiaramente allineata. Ad esempio, in un comparatore personalizzato, ciò si rifletterà nel seguente modo.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}Un approccio alternativo è avvisare in anticipo il compilatore che le strutture con chiave e valore possono non essere allineate utilizzando l'attributo aligned(1). Su ARM è possibile ottenere lo stesso effetto и с помощью атрибута packed. Учитывая, что он к тому же ещё и способствует оптимизации занимаемого структурой места, данный способ мне видится предпочтительным, хоть и alla variazione dei costi di accesso ai dati.
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Richieste Range
Per iterare su un gruppo di record in LMDB, esiste un'astrazione di cursore. Approfondiremo come lavorare con essa usando come esempio la già conosciuta tabella dei metadati del cloud utente.
Nel contesto della visualizzazione dell'elenco dei file in una directory, è necessario trovare tutte le chiavi associate ai suoi file e cartelle figli. Nei precedenti sottoparaboli, abbiamo ordinato le chiavi NodeKey in modo tale da essere prima ordinate per l'identificatore della directory genitore. Pertanto, tecnicamente, ottenere il contenuto della cartella si riduce a impostare il cursore sul confine superiore del gruppo di chiavi con un determinato prefisso e poi iterare fino al confine inferiore.

È possibile trovare il confine superiore in modo "grezzo" attraverso una ricerca sequenziale. Per fare ciò, il cursore viene impostato all'inizio dell'intero elenco delle chiavi nel database e poi viene incrementato finché non si trova sotto una chiave con l'identificatore della directory genitore. Questo approccio ha 2 ovvi svantaggi:
- La complessità lineare della ricerca, sebbene nota, può essere eseguita in tempo logaritmico negli alberi, e in particolare negli alberi B.
- È estremamente costoso caricare in memoria principale tutte le pagine precedenti a quella cercata dal file.
Fortunatamente, l'API LMDB offre un modo efficiente per posizionare inizialmente il cursore. Per questo, è necessario generare una chiave il cui valore sia sicuramento minore o uguale alla chiave presente al limite superiore dell'intervallo. Ad esempio, per la lista mostrata nell'immagine sopra, possiamo creare una chiave in cui il campo parentId è uguale a 2 e tutti gli altri campi sono riempiti con zeri. Questa chiave parzialmente completata viene inserita nella funzione mdb_cursor_get specificando l'operazione MDB_SET_RANGE.
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);Se il limite superiore del gruppo di chiavi è stato trovato, quindi iteriamo su di esso finché ci si imbatte o in una chiave diversa parentId, oppure finché le chiavi non terminano del tutto.
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// processing...
} while (MDB_NOTFOUND != rc && // check end of table
IsTargetKey(key)); // check end of keys groupÈ piacevole notare che durante l'iterazione con mdb_cursor_get otteniamo non solo la chiave, ma anche il valore. Se per soddisfare le condizioni di selezione è necessario controllare anche i campi della parte value del record, questi sono facilmente accessibili senza ulteriori complicazioni.
4.3. Modellazione delle relazioni tra le tabelle
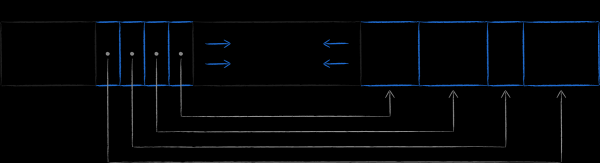
Fino a questo momento abbiamo esaminato tutti gli aspetti della progettazione e del funzionamento con una base di dati a singola tabella. Si può affermare che una tabella è un insieme di record ordinati, composti da coppie chiave-valore omogenee. Se si rappresenta la chiave come un rettangolo e il valore ad essa associato come un parallelepipedo, si ottiene uno schema visivo della base di dati.
![]()
Tuttavia, nella realtà è raro poterci accontentare di così poco. Spesso, in una base di dati è necessario, da un lato, avere più tabelle e, dall'altro, eseguire selezioni in ordine diverso rispetto alla chiave primaria. In questo ultimo capitolo ci dedichiamo alla loro creazione e al collegamento tra di esse.
Tabelle indicizzate
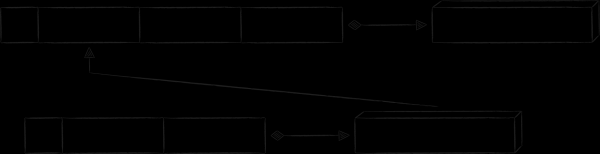
Nell'applicazione cloud c'è una sezione "Galleria". Qui viene visualizzato il contenuto multimediale dall'intero cloud, ordinato per data. Per un'ottimale realizzazione di questa selezione, accanto alla tabella principale è necessario creare un'altra tabella con un nuovo tipo di chiavi. Queste conterranno un campo con la data di creazione del file, che fungerà da criterio primario per l'ordinamento. Poiché le nuove chiavi fanno riferimento agli stessi dati delle chiavi nella tabella principale, si chiamano chiavi indicizzate. Nella figura qui sotto, sono evidenziate in arancione.
Per separare le chiavi di tabelle diverse all'interno di uno stesso database, a tutte è stato aggiunto un campo tecnico supplementare chiamato tableId. Rendendolo il più prioritario per l'ordinamento, otterremo raggruppamenti delle chiavi prima per tabelle e poi all'interno delle tabelle secondo le proprie regole.
La chiave indicizzata fa riferimento agli stessi dati della chiave primaria. L'implementazione diretta di questa proprietà tramite l'associazione con una copia della parte value della chiave primaria non è ottimale per vari aspetti:
- In termini di spazio occupato, poiché i metadati possono essere piuttosto ricchi.
- Dal punto di vista delle prestazioni, poiché l'aggiornamento dei metadati del nodo richiederà una riscrittura su due chiavi.
- Dal punto di vista del supporto del codice, basta dimenticare di aggiornare i dati su una delle chiavi per ottenere un bug difficile da individuare a causa dell'incoerenza dei dati nel repository.
Esaminiamo ora come eliminare questi svantaggi.
Organizzazione delle relazioni tra le tabelle
Per collegare la tabella degli indici con la tabella principale, si adatta bene il pattern "chiave come valore". Come suggerisce il nome, come parte del valore della registrazione dell'indice, viene utilizzata una copia del valore della chiave primaria. Questo approccio neutralizza tutti gli svantaggi sopra elencati relativi alla memorizzazione di una copia della parte del valore della registrazione primaria. L'unico costo è che per ottenere un valore tramite la chiave indice è necessario effettuare 2 richieste al database anziché una. Schematicamente, il diagramma risultante del database appare come segue.
Un altro pattern di organizzazione della relazione tra le tabelle è "chiave ridondante". La sua essenza è nell'aggiunta di ulteriori attributi alla chiave, che non servono per l'ordinamento, ma per ricreare la chiave correlata. Nell'applicazione Cloud di Mail.ru ci sono esempi reali del suo utilizzo, ma per evitare un'immersione profonda nei contesti specifici dei framework iOS, fornirò un esempio fittizio, ma sicuramente più comprensibile.
Nei client mobili cloud c'è una pagina dove vengono visualizzati tutti i file e le cartelle a cui l'utente ha fornito accesso ad altre persone. Poiché ci sono relativamente pochi file di questo tipo, ma molte informazioni specifiche correlate alla loro pubblicità (a chi è stato concesso l'accesso, con quali diritti, ecc.), non sarebbe razionale appesantire la parte value della registrazione nella tabella principale con tali informazioni. Tuttavia, se si desidera visualizzare tali file offline, è comunque necessario conservarli da qualche parte. Una soluzione naturale è quella di creare una tabella separata per essi. Nello schema qui sotto, la sua chiave ha il prefisso «P», e il segnaposto «propname» può essere sostituito da un valore più specifico «public info».
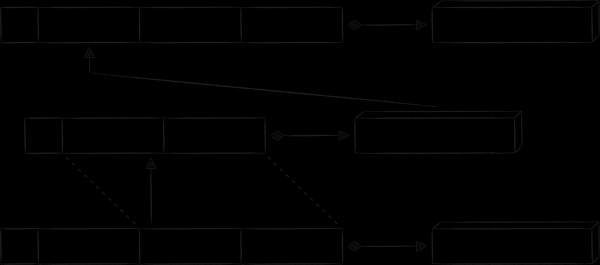
Tutti i metadati unici, per i quali è stata creata una nuova tabella, vengono trasferiti nella parte value della registrazione. Allo stesso tempo, non vogliamo duplicare i dati sui file e le cartelle già memorizzati nella tabella principale. Invece, i dati ridondanti come i campi "node ID" e "timestamp" vengono aggiunti alla chiave "P". Grazie a questi, è possibile costruire una chiave indice che consente di ottenere la chiave primaria e, infine, recuperare i metadati del nodo.
Conclusione
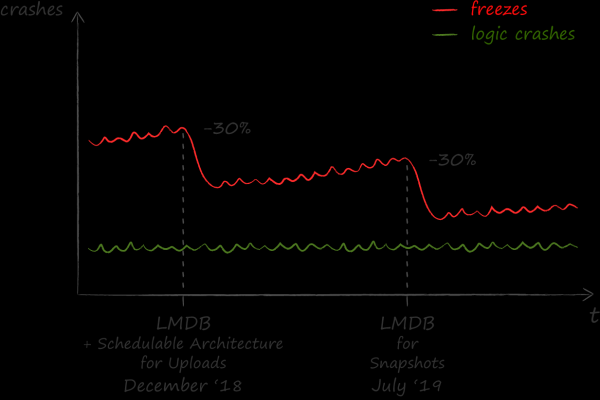
Valutiamo positivamente i risultati dell'implementazione di LMDB. Dopo di essa, il numero di blocchi dell'applicazione è diminuito del 30%.
I risultati del lavoro svolto hanno trovato risonanza al di fuori del team iOS. Attualmente, una delle principali sezioni "File" dell'applicazione Android ha anche adottato LMDB, mentre altre parti sono in fase di transizione. Il linguaggio C, utilizzato per realizzare il database key-value, ha fornito un ottimo supporto per creare inizialmente un'interfaccia applicativa multipiattaforma in C++. Per garantire un'integrazione fluida della libreria C++ con il codice di piattaforma in Objective-C e Kotlin, è stato utilizzato un generatore di codice. di Dropbox, ma questa è già un'altra storia.
Fonte: habr.com
