

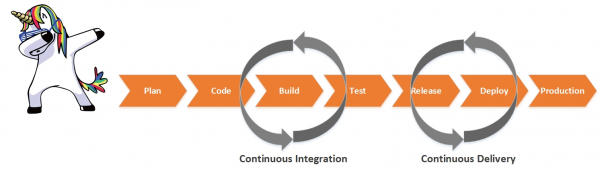
Attualmente, il tema DevOps è molto in voga. Le pipeline di integrazione e consegna continua vengono adottate da molti, ma non tutti prestano la dovuta attenzione alla garanzia dell'affidabilità dei sistemi informativi in diverse fasi del CI/CD Pipeline. In questo articolo, vorrei condividere la mia esperienza nell'automazione dei controlli di qualità del software e nell'implementazione di scenari per il suo "auto-ripristino".

Lavoro come ingegnere nel dipartimento di gestione dei servizi IT presso . Il mio campo di specializzazione è l'implementazione di diversi sistemi di monitoraggio delle prestazioni e della disponibilità delle applicazioni. Spesso interagisco con clienti IT di vari settori riguardo alle questioni attuali sul monitoraggio della qualità dei loro servizi IT. L'obiettivo principale è minimizzare il tempo di ciclo delle release e aumentare la frequenza delle stesse. Questo, ovviamente, è tutto bello: più release - più nuove funzionalità - più utenti soddisfatti - più profitti. Ma nella realtà, non sempre tutto va per il meglio. Con tassi di distribuzione molto elevati, emergono immediatamente questioni relative alla qualità delle nostre release. Anche con un pipeline completamente automatizzato, uno dei più grandi problemi è il passaggio dei servizi da testing a produzione, senza influenzare il tempo di uptime e l'interazione degli utenti con l'applicazione.
A seguito di numerose conversazioni con i clienti, posso affermare che il controllo della qualità delle release, il problema dell'affidabilità dell'applicazione e la possibilità di 'autosalvataggio' (ad esempio, il rollback a una versione stabile) in diverse fasi del pipeline CI/CD sono tra i temi più inquietanti e attuali.
Di recente ho lavorato come cliente — nel servizio di supporto software di una banca online. L'architettura della nostra applicazione utilizzava un gran numero di microservizi personalizzati. La cosa più triste è che non tutti gli sviluppatori riuscivano a tenere il passo con i ritmi elevati di sviluppo; la qualità di alcuni microservizi ne risentiva, dando origine a soprannomi divertenti per loro e i loro creatori. Si diffondevano racconti su quali materiali venissero usati per produrre questi prodotti.

«Definizione del compito»
L'alta frequenza di rilascio e il gran numero di microservizi rendono difficile comprendere come funziona l'applicazione nel suo complesso, sia durante la fase di test che durante l'operatività. I cambiamenti sono costanti e monitorarli senza buoni strumenti è molto complicato. Spesso, dopo un rilascio notturno, i programmatori si siedono come su una polveriera al mattino e aspettano che nulla si rompa, anche se durante il test tutte le verifiche erano state superate.
C'è un altro aspetto da considerare. Durante la fase di test si verifica il funzionamento del software: l'esecuzione delle funzioni principali dell'applicazione e l'assenza di errori. Le valutazioni qualitative delle prestazioni sono spesso assenti o non considerano tutti gli aspetti del funzionamento dell'applicazione e del layer di integrazione. Alcune metriche potrebbero non essere nemmeno verificate. Di conseguenza, in caso di malfunzionamenti nell'ambiente di produzione, il team di supporto tecnico viene informato soltanto quando gli utenti reali iniziano a lamentarsi. È fondamentale minimizzare l'impatto di un software di scarsa qualità sugli utenti finali.
Una delle soluzioni è implementare processi di verifica della qualità del software in diverse fasi del CI/CD Pipeline, aggiungendo vari scenari di ripristino del sistema in caso di guasti. Ricordiamo anche che adottiamo DevOps. Il business si aspetta di ricevere il nuovo prodotto nel minor tempo possibile. Pertanto, tutte le nostre verifiche e scenari devono essere automatizzati.
Il compito si suddivide in due parti:
- controllo della qualità delle build durante la fase di test (automatizzare il processo di identificazione delle build di scarsa qualità);
- controllo della qualità del software in ambiente produttivo (meccanismi di rilevamento automatico dei problemi e possibili scenari di auto-ripristino).
Strumento per il monitoraggio e la raccolta di metriche
Per realizzare gli obiettivi prefissati, è necessaria una sistema di monitoraggio in grado di rilevare problemi e comunicarli ai sistemi di automazione in diverse fasi del processo CI/CD. Sarebbe inoltre utile se questo sistema fornisse metriche utili per vari team: sviluppo, testing, operazioni. E sarebbe fantastico se queste metriche fossero anche utili per il business.
Per la raccolta delle metriche si possono utilizzare diverse soluzioni (Prometheus, ELK Stack, Zabbix, ecc.), ma, secondo il mio parere, le soluzioni di tipo APM () sono le più adatte per queste esigenze, in grado di semplificarti notevolmente la vita.
Nel mio lavoro nel servizio di supporto, ho iniziato a sviluppare un progetto simile utilizzando una soluzione APM della compagnia Dynatrace. Ora, lavorando come integratore, conosco abbastanza bene il mercato dei sistemi di monitoraggio. La mia opinione soggettiva è che Dynatrace sia la soluzione migliore per affrontare tali compiti.
La soluzione Dynatrace fornisce una visualizzazione orizzontale di ogni operazione utente con un alto grado di dettaglio fino al livello di esecuzione del codice. È possibile tracciare l'intera catena di interazioni tra diversi servizi informativi: dai livelli delle applicazioni web e mobili frontend, ai server backend delle applicazioni, al bus di integrazione, fino a una specifica chiamata nel database.
 . Creazione automatica di tutte le dipendenze tra i componenti del sistema
. Creazione automatica di tutte le dipendenze tra i componenti del sistema
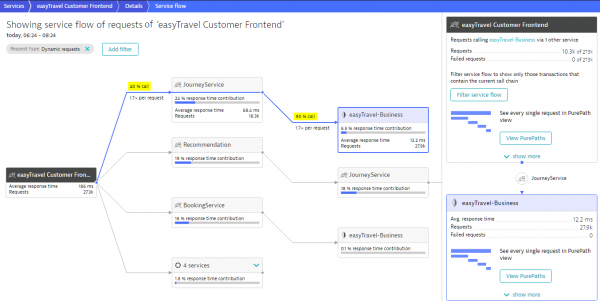 . Identificazione automatica e creazione del percorso di esecuzione dell'operazione del servizio
. Identificazione automatica e creazione del percorso di esecuzione dell'operazione del servizio
Ricordiamo anche che dobbiamo integrare diversi strumenti di automazione. Qui la soluzione offre un'API comoda che permette di inviare e ricevere varie metriche ed eventi.
Passiamo ora a un'analisi più dettagliata su come risolvere le problematiche stabilite utilizzando il sistema Dynatrace.
Compito 1. Automazione del controllo qualità delle build nella fase di test
La prima cosa da fare è identificare i problemi il prima possibile nelle fasi di consegna dell'applicazione. Solo le «buone» versioni del codice dovrebbero raggiungere l'ambiente di produzione. A tal fine, nel vostro pipeline, durante la fase di testing, devono essere inclusi monitor aggiuntivi per verificare la qualità dei vostri servizi.
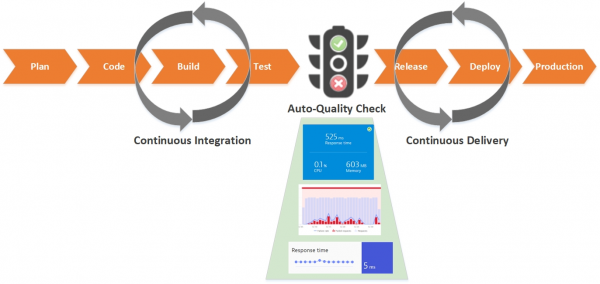
Esaminiamo passo dopo passo come implementare e automatizzare questo processo:
Nella figura è mostrato il flusso dei passaggi automatizzati per il controllo della qualità del software:
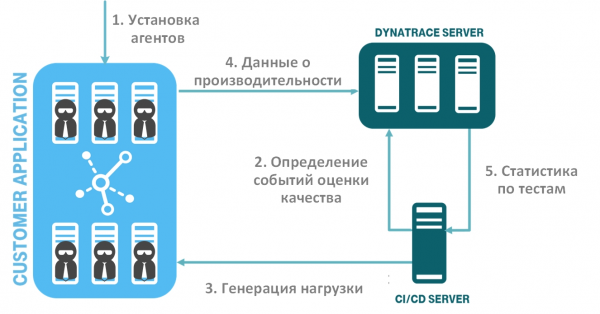
- implementazione del sistema di monitoraggio (installazione degli agenti);
- definizione degli eventi di valutazione della qualità del vostro software (metrica e soglie) e inviarli al sistema di monitoraggio;
- generazione di carico e test delle performance;
- raccolta dei dati sulle performance e sull’accessibilità nel sistema di monitoraggio;
- trasferimento dei dati sui test, basati sugli eventi di valutazione della qualità del software, dal sistema di monitoraggio al sistema CI/CD. Analisi automatica delle build.
Passo 1. Implementazione del sistema di monitoraggio
Prima di tutto, è necessario installare gli agenti nel vostro ambiente di test. A questo proposito, la soluzione Dynatrace offre un vantaggio interessante: utilizza un agente universale, OneAgent, che si installa sull'istanza OS (Windows, Linux, AIX), rileva automaticamente i vostri servizi e inizia a raccogliere dati di monitoraggio su di essi. Non è necessario configurare un agente separato per ogni processo. La stessa cosa vale per le piattaforme cloud e container. Inoltre, il processo di installazione degli agenti può essere anche automatizzato. Dynatrace si integra perfettamente nel concetto di «infrastruttura come codice» (): sono già disponibili script e istruzioni per tutte le piattaforme più popolari. Integrare l'agente nella configurazione del vostro servizio significa che durante il suo deployment riceverete subito un nuovo servizio con l'agente già attivo.
Passo 2. Definizione degli eventi di valutazione della qualità del vostro software
Ora è necessario definire l'elenco dei servizi e delle operazioni aziendali. È importante prendere in considerazione precisamente quelle operazioni degli utenti che sono critiche per il vostro servizio. Qui consiglio di consultare analisti di business e sistemici.
In seguito, è necessario definire quali metriche si desidera includere nel monitoraggio per ciascun livello. Ad esempio, queste possono includere il tempo di risposta (con suddivisione in media, mediana, percentili, ecc.), errori (logici, di servizio, infrastrutturali, ecc.) e varie metriche infrastrutturali (memory heap, garbage collector, thread count, ecc.).
Per automatizzare e semplificare l'utilizzo da parte del team DevOps, emerge il concetto di "Monitoring as Code". Con questo intendo che uno sviluppatore/tester può scrivere un semplice file JSON che definisce le metriche di controllo della qualità del software.
Consideriamo un esempio di un tale file JSON. Come coppie chiave/valore vengono utilizzati oggetti dall'API di Dynatrace (la descrizione dell'API può essere visualizzata qui ).
{
"timeseries": [
{
"timeseriesId": "service.ResponseTime",
"aggregation": "avg",
"tags": "Frontend",
"severe": 250000,
"warning": 1000000
},
{
"timeseriesId": "service.ResponseTime",
"aggregation": "avg",
"tags": "Backend",
"severe": 4000000,
"warning": 8000000
},
{
"timeseriesId": "docker.Container.Cpu",
"aggregation": "avg",
"severe": 50,
"warning": 70
}
]
}Il file è un array di definizioni dei series temporali (timeseries):
- timeseriesId – metrica da monitorare, ad esempio, Response Time, Error count, Memory used, ecc.;
- aggregazione – livello di aggregazione delle metriche, nel nostro caso avg, ma puoi utilizzare qualsiasi sia necessaria per te (avg, min, max, sum, count, percentile);
- tags – etichetta dell'oggetto nel sistema di monitoraggio, oppure puoi specificare un identificatore specifico dell'oggetto;
- severe e warning – questi valori regolano le soglie delle nostre metriche; se il valore dei test supera la soglia severe, la nostra build viene contrassegnata come non riuscita.
Nell'immagine seguente, è presentato un esempio di utilizzo di tali soglie.
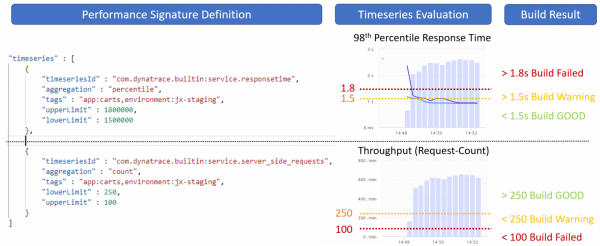
Passo 3. Generazione del carico
Dopo aver definito i livelli di qualità del nostro servizio, è necessario generare un carico di test. Puoi utilizzare uno qualsiasi degli strumenti di test a te più comodi, come Jmeter, Selenium, Neotys, Gatling, ecc.
Il sistema di monitoraggio Dynatrace consente di catturare diversi metadati dai tuoi test e di riconoscere a quale ciclo di rilascio e a quale servizio si riferisce ciascun test. Si consiglia di aggiungere intestazioni aggiuntive nelle richieste HTTP del test.
Nell'immagine seguente è presentato un esempio in cui, utilizzando l'intestazione aggiuntiva X-Dynatrace-Test, etichettiamo che questo test è relativo al collaudo dell'operazione di aggiunta di un prodotto al carrello.

All'avvio di ciascun test di carico, inviate ulteriori informazioni contestuali a Dynatrace tramite l'API degli eventi dal server CI/CD. In questo modo, il sistema può distinguere i diversi test tra loro.
 . Evento nel sistema di monitoraggio relativo all'avvio del test di carico.
. Evento nel sistema di monitoraggio relativo all'avvio del test di carico.
Fase 4-5. Raccolta dei dati sulle prestazioni e trasmissione dei dati al sistema CI/CD.
Insieme al test generato, nel sistema di monitoraggio viene trasmesso un evento che richiede la raccolta dei dati per la verifica delle prestazioni del servizio. Viene inoltre indicato il nostro file JSON, nel quale sono definite le metriche chiave.
 Evento di richiesta di verifica della qualità del software generato sul server CI/CD per l'invio al sistema di monitoraggio.
Evento di richiesta di verifica della qualità del software generato sul server CI/CD per l'invio al sistema di monitoraggio.
Nel nostro esempio, l'evento di verifica della qualità è chiamato perfSigDynatraceReport (Performance_Signature) – è pronto per l'integrazione con Jenkins, sviluppato dai ragazzi di T-Systems Multimedia Solutions. Ogni evento di avvio della verifica contiene informazioni sul servizio, sul numero della build e sull'orario del test. Il plugin raccoglie i valori delle prestazioni durante la build, li valuta e confronta il risultato con le build precedenti e con i requisiti non funzionali.
 Evento nel sistema di monitoraggio per l'inizio della verifica della qualità della build.
Evento nel sistema di monitoraggio per l'inizio della verifica della qualità della build.
Al termine del test, tutte le metriche di valutazione della qualità del software vengono restituite al sistema di integrazione continua, come Jenkins, che genera un report sui risultati.
 Risultati delle statistiche delle build sul server CI/CD.
Risultati delle statistiche delle build sul server CI/CD.
Per ogni singola build, vediamo le statistiche per ciascuna metrica da noi definita durante l'esecuzione del test. Possiamo anche osservare se ci sono stati superamenti di determinati valori soglia (warning e severe thresholds). Sulla base degli indicatori complessivi, ogni build viene contrassegnata come stabile, instabile o fallita. Inoltre, per comodità, puoi aggiungere al report i dati di confronto con la build precedente.
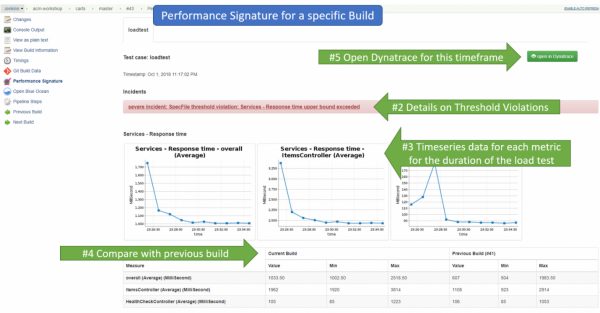 Visualizza statistiche dettagliate sulle build sul server CI/CD.
Visualizza statistiche dettagliate sulle build sul server CI/CD.
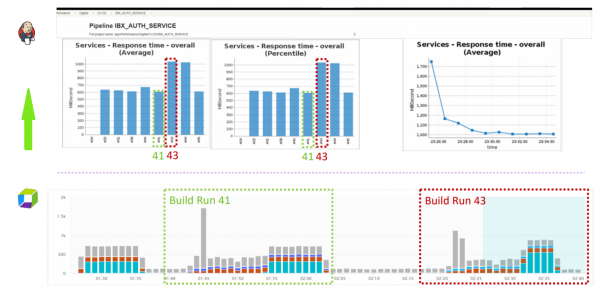
Confronto dettagliato tra due build
Se necessario, è possibile accedere all'interfaccia di Dynatrace per visualizzare più dettagliatamente le statistiche di ciascuna build e confrontarle tra loro.
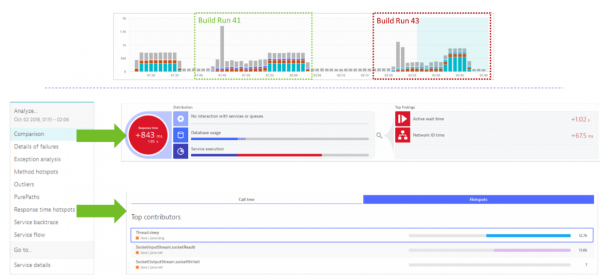 Confronto delle statistiche delle build in Dynatrace.
Confronto delle statistiche delle build in Dynatrace.
Conclusioni
Otteniamo così un servizio di 'monitoraggio come servizio', automatizzato nel processo di integrazione continua. Lo sviluppatore o il tester deve solo definire l'elenco delle metriche in un file JSON, mentre tutto il resto avviene automaticamente. Risultiamo così con un controllo trasparente della qualità delle versioni: tutte le notifiche sulle prestazioni, sul consumo delle risorse o sulle regressioni architetturali.
Compito 2. Automazione del controllo qualità del software in produzione
Quindi, abbiamo risolto il problema di come automatizzare il processo di monitoraggio nella fase di test nel Pipeline. In questo modo minimizziamo la percentuale di build non conformi che arrivano in produzione.
Ma cosa fare se il software difettoso arriva comunque in produzione, o semplicemente qualcosa si rompe? Per un'utopia, ci piacerebbe avere meccanismi di rilevamento automatico dei problemi e, se possibile, un sistema che riacquisti autonomamente la propria funzionalità, almeno di notte.
Per questo, dobbiamo, analogamente alla sezione precedente, prevedere controlli automatici della qualità del software in ambiente di produzione e pianificare scenari per il ripristino automatico del sistema.
Correzione automatica come codice
Nella maggior parte delle aziende esiste già una base di conoscenza accumulata su diversi tipi di problemi comuni e un elenco di azioni per la loro risoluzione, ad esempio, il riavvio di processi, la pulizia delle risorse, il rollback delle versioni, il ripristino di modifiche di configurazione errate, l'aumento o la diminuzione del numero di componenti nel cluster, il passaggio a un circuito blu o verde, e altro ancora.
Nonostante questi casi d'uso siano noti da molti anni a molti team con cui parlo, solo pochi hanno considerato e investito nella loro automazione.
Se ci pensi, nell'implementazione dei processi di auto-ripristino delle applicazioni non c'è nulla di eccessivamente complesso. È necessario rappresentare gli scenari di lavoro già noti dei tuoi amministratori sotto forma di script di codice (la concezione di "auto-correzione come codice"), che hai già scritto in anticipo per ogni singolo caso. Gli scenari di correzione automatica devono essere orientati ad affrontare la causa principale del problema. Sei tu a stabilire le azioni di risposta corrette agli incidenti.
Qualsiasi metrica del tuo sistema di monitoraggio può fungere da trigger per avviare lo script, l'importante è che queste metriche definiscano con precisione che la situazione è critica, poiché non vorresti ricevere falsi allarmi in un ambiente di produzione.
Puoi utilizzare qualsiasi sistema o combinazione di sistemi: Prometheus, ELK Stack, Zabbix, ecc. Ma fornirò alcuni esempi basati sulla soluzione APM (prendendo come esempio di nuovo Dynatrace), che contribuirà anche a semplificare la tua vita.
In primo luogo, qui troverai tutto ciò che riguarda le prestazioni dal punto di vista dell'applicazione. La soluzione offre centinaia di metriche a vari livelli che puoi utilizzare come trigger:
- livello utenti (browser, app mobili, dispositivi IoT, comportamento degli utenti, conversioni, ecc.);
- livello del servizio e delle operazioni (prestazioni, disponibilità, errori, ecc.);
- livello dell'infrastruttura dell'applicazione (metriche OS dell'host, JMX, MQ, web server, ecc.);
- livello delle piattaforme (virtualizzazione, cloud, container, ecc.).
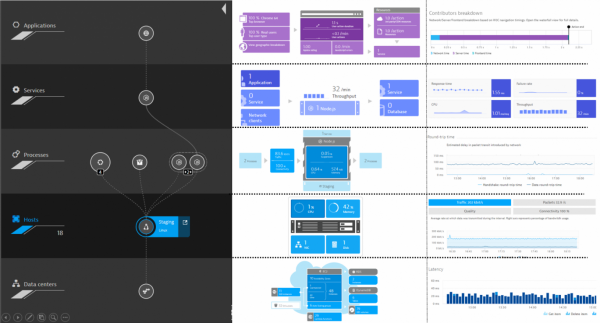 Livelli di monitoraggio in Dynatrace.
Livelli di monitoraggio in Dynatrace.
In secondo luogo, come ho detto in precedenza, Dynatrace dispone di un'API aperta che consente di integrarlo facilmente con vari sistemi di terze parti. Ad esempio, inviare una notifica a un sistema di automazione quando vengono superati i parametri di controllo.
Di seguito è riportato un esempio di interazione con Ansible.
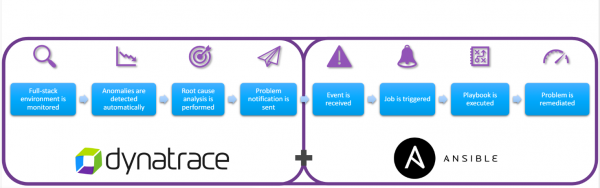
Ora fornirò alcuni esempi di quali automazioni si possono realizzare. Questi sono solo alcuni dei casi, la loro lista nel tuo ambiente può essere limitata solo dalla tua immaginazione e dalle capacità dei tuoi strumenti di monitoraggio.
1. Deploy mal riuscito - rollback della versione
Anche se verifichiamo tutto molto bene nell'ambiente di test, c'è comunque il rischio che una nuova release possa compromettere la vostra applicazione nell'ambiente di produzione. Il fattore umano rimane sempre presente.
Nell'immagine successiva vediamo che si verifica un improvviso picco nel tempo di esecuzione delle operazioni sul servizio. L'inizio di questo picco coincide con il momento del deploy dell'applicazione. Tutte queste informazioni vengono trasmesse come eventi al sistema di automazione. Se la funzionalità del servizio non si normalizza entro il tempo che abbiamo stabilito, viene automaticamente chiamato uno script che esegue il rollback alla versione precedente.
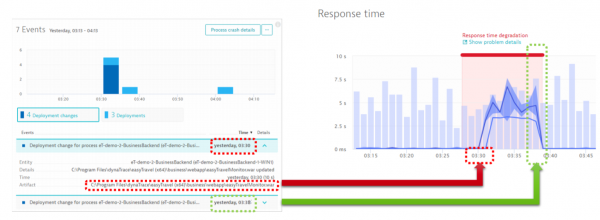 Degradazione delle prestazioni delle operazioni dopo il deploy.
Degradazione delle prestazioni delle operazioni dopo il deploy.
2. Carico delle risorse al 100% — aggiungere un nodo alla routing
Nel seguente esempio, il sistema di monitoraggio rileva che uno dei componenti presenta un utilizzo della CPU al 100%.
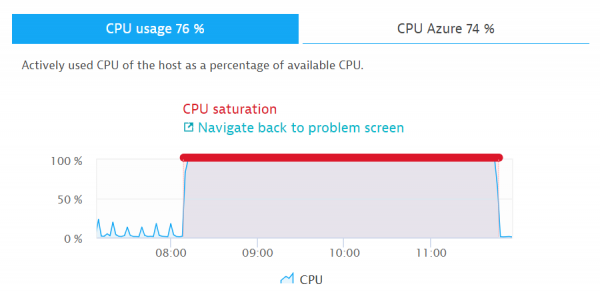 Utilizzo della CPU al 100%
Utilizzo della CPU al 100%
In base a questo evento, potrebbero esserci diversi scenari. Ad esempio, il sistema di monitoraggio verifica se la mancanza di risorse è correlata all'aumento del carico sul servizio. Se sì, viene eseguito uno script che aggiunge automaticamente un nodo nella routing, ripristinando così la funzionalità complessiva del sistema.
 Scalabilità dopo l'incidente
Scalabilità dopo l'incidente
3. Spazio insufficiente su disco rigido - pulizia del disco
Penso che molti di questi processi siano già stati automatizzati. Con APM è possibile monitorare anche lo spazio libero nel sistema di dischi. In caso di spazio insufficiente o prestazioni lente del disco, chiamiamo uno script per la pulizia o aumentiamo lo spazio.
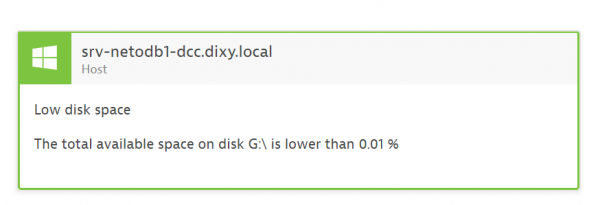
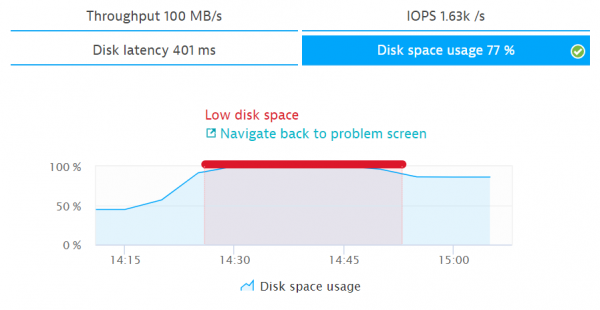 Carico del disco al 100%
Carico del disco al 100%
4. Bassa attività degli utenti o bassa conversione - commutazione tra il ramo blu e il ramo verde
Spesso incontro clienti che utilizzano due ambienti (blue-green deploy) per le applicazioni in produzione. Questo consente di passare rapidamente tra i rami durante la distribuzione di nuove versioni. Spesso, dopo il deployment, possono verificarsi cambiamenti drastici, che non vengono immediatamente notati. Tuttavia, potrebbero non esserci segnali di degrado nelle prestazioni e nella disponibilità. Per rispondere tempestivamente a tali cambiamenti, è meglio utilizzare diverse metriche che riflettono il comportamento degli utenti (numero di sessioni e azioni degli utenti, conversioni, bounce rate). Nell'immagine seguente è mostrato un esempio in cui, a seguito di un calo della conversione, si verifica il passaggio tra i rami del software.
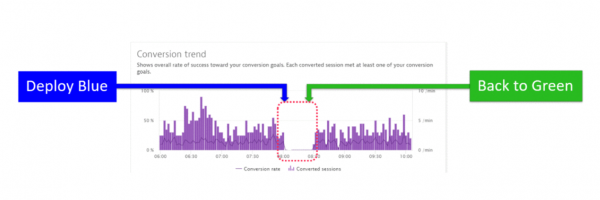 Calano le conversioni dopo il passaggio tra i rami del software.
Calano le conversioni dopo il passaggio tra i rami del software.
Meccanismi di rilevazione automatica dei problemi.
Alla fine, condividerò un altro esempio di ciò che mi piace di più di Dynatrace.
Nella parte della mia esposizione sull'automazione del controllo della qualità delle build in ambiente di test, tutti i valori soglia sono stati definiti manualmente. Questo è normale per l'ambiente di test, dove il tester stabilisce i parametri prima di ogni verifica, a seconda del carico. In produzione, è auspicabile che i problemi vengano rilevati automaticamente considerando i vari meccanismi di baseline.
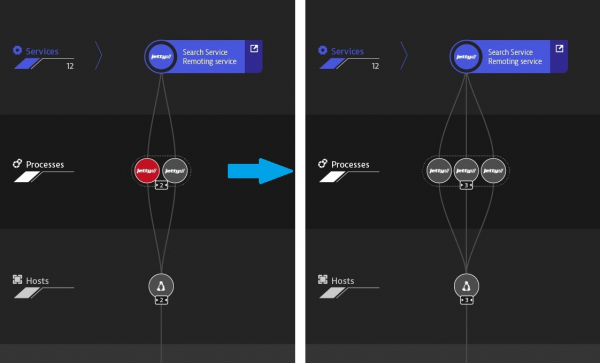
Dynatrace presenta strumenti integrati di intelligenza artificiale interessanti che, attraverso meccanismi di rilevamento delle metriche anomale (baselining) e la costruzione di una mappa di interazione tra tutti i componenti, confrontando e correlando eventi, identificano anomalie nel funzionamento del tuo servizio e forniscono informazioni dettagliate su ciascun problema e sulla sua causa principale.
Analizzando automaticamente le dipendenze tra i componenti, Dynatrace determina non solo se il servizio problematico è la causa principale, ma anche la sua dipendenza da altri servizi. Nell'esempio sottostante, Dynatrace monitora e valuta automaticamente l'affidabilità di ciascun servizio durante l'esecuzione delle transazioni, identificando il servizio Golang come causa principale.
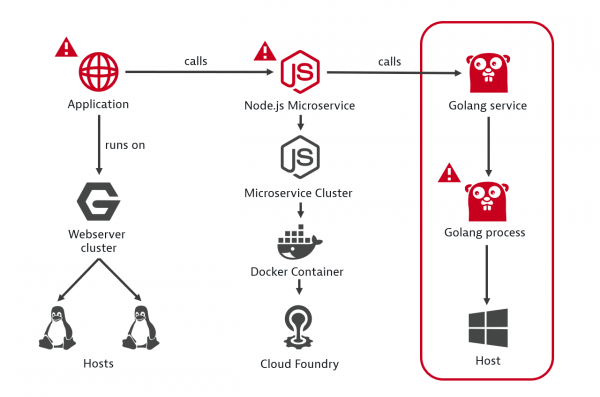 Esempio di individuazione della causa radice di un guasto.
Esempio di individuazione della causa radice di un guasto.
Nell'immagine seguente viene illustrato il processo di monitoraggio dei problemi con la vostra applicazione dall'inizio dell'incidente.
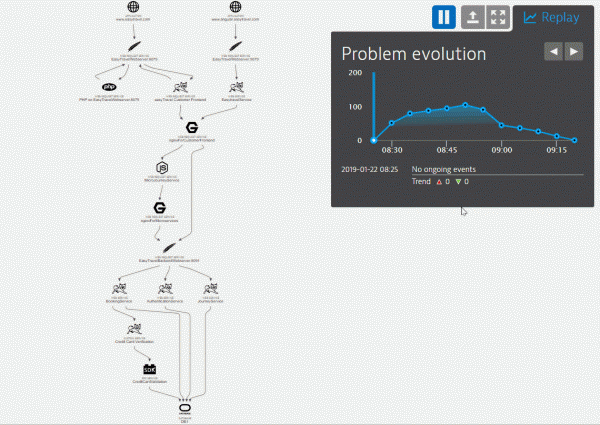 Visualizzazione del problema emergente mostrando tutti i componenti e gli eventi ad essi associati.
Visualizzazione del problema emergente mostrando tutti i componenti e gli eventi ad essi associati.
Il sistema di monitoraggio ha raccolto una cronologia completa degli eventi relativi al problema emerso. Nella finestra sotto il grafico temporale vediamo tutti gli eventi chiave per ciascuno dei componenti. Sulla base di questi eventi, è possibile impostare procedure per la correzione automatica sotto forma di script di codice.
Inoltre, consiglio di integrare il sistema di monitoraggio con Service Desk o un tracker di bug. Quando si verifica un problema, gli sviluppatori ricevono rapidamente tutte le informazioni necessarie per un'analisi a livello di codice nell'ambiente di produzione.
Conclusione
Alla fine siamo riusciti a creare una pipeline CI/CD con controlli di qualità del software automatizzati integrati nel Pipeline. Riduciamo il numero di build di bassa qualità, miglioriamo l'affidabilità del sistema nel suo complesso e, se la funzionalità del sistema viene compromessa, attiviamo meccanismi per il suo ripristino.
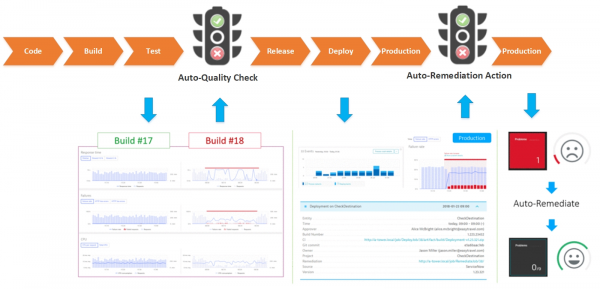
Vale sicuramente la pena investire nell'automazione del monitoraggio della qualità del software; non è sempre un processo rapido, ma col tempo porterà i suoi frutti. Consiglio di pensare subito a quali monitor aggiungere per i controlli nell'ambiente di test dopo aver risolto un nuovo incidente nell'ambiente di produzione, per evitare che una build difettosa arrivi in produzione, e anche di redigere uno script per la correzione automatica di questi problemi.
Spero che i miei esempi possano aiutarvi nei vostri progetti. Sarà anche interessante vedere i vostri esempi di metriche utilizzate per implementare l'auto-ripristino delle funzionalità dei sistemi.

Fonte: habr.com
