

Дмитрий Казаков, Data Analytics Team Lead в Kolesa Group, делится инсайтами из первого казахстанского опроса специалистов по работе с данными.

На фото: Дмитрий Казаков
Помните популярную фразу о том, что Big Data больше всего напоминает подростковый секс – все о нем говорят, но никто не знает, есть ли он на самом деле. То же самое можно было сказать и о рынке специалистов по работе с данными (в Казахстане) – хайп есть, а кто за ним стоит (и есть ли там вообще хоть кто-то), не было до конца понятно – ни эйчарам, ни менеджерам, ни самим дата-сайентистам.
Мы провели , в рамках которого опросили более 300 специалистов об их зарплатах, функциях, скиллах, инструментах и много еще о чем.
Spoiler: да, они точно существуют, но все не так однозначно.
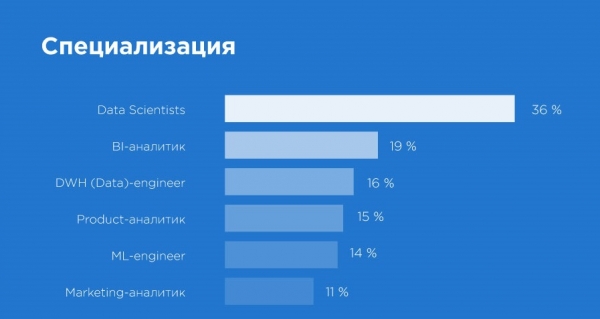
Приятный инсайт. Во-первых, специалистов по работе с данными больше чем мы ожидали. Нам удалось опросить 300 человек, среди которых есть не только product-, marketing- и BI-аналитики, но и ML-, DWH-инженеры, что особенно порадовало. В самой большой группе оказались все те, кто называет себя дата-сайентистами – это 36% опрошенных. Покрывает это запрос рынка или нет, сказать сложно, потому что сам рынок только формируется.
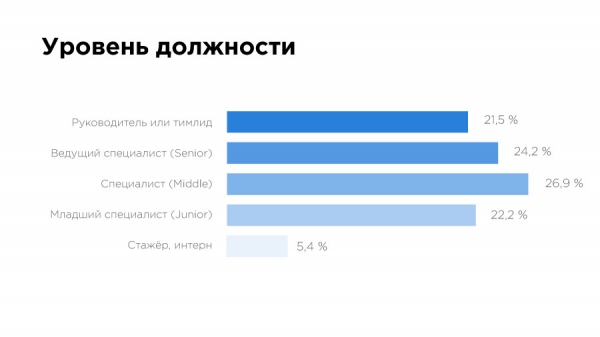
Смущает распределение уровней должности – тимлидов и руководителей почти столько же, сколько джунов. Причин тому может быть несколько. Например, большое количество маленьких команд по 2-3 человека, в которых руководителем может быть специалист уровня миддла или сениора.
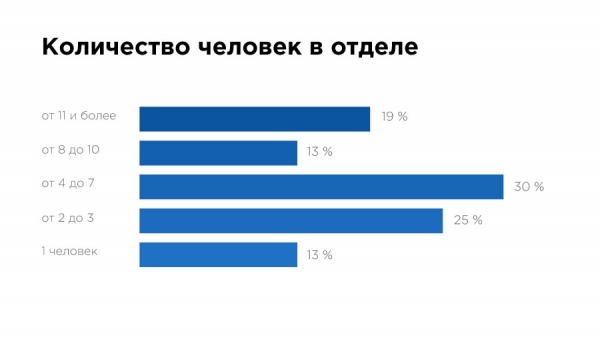
Еще одной причиной может быть царящий пока на рынке хаос по части стандартов в распределении ролей и функционала. Тимлидами порой назначают тех, кто просто работает на год-два дольше других, без привязки к уровню скиллов и знаний. Мы видим это и в распределении функций по должностям — 38% руководителей и тимлидов занимаются предобработкой и еще 33% базовым стат.анализом.
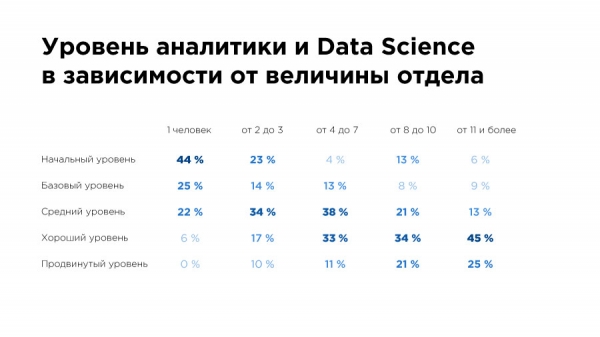
Здесь мы попросили респондентов субъективно оценить уровень аналитики в их компаниях. Если присмотреться, можно увидеть, что 10% респондентов, которые работают в отделах аналитики из 2-3 человек, считают что у них “продвинутый уровень”.
А что такое “продвинутый уровень”? BI-система работает отлично. Есть DWH и Big Data. Регулярно проводятся A/B-тесты. Есть работающие системы ML и DS в production. Решения принимаются только по данным. Отдел работы с данными и Data Science – один из ключевых в компании.
Всего перечисленного практически невозможно добиться отделом из 2-3 человек. Считаю, что такой результат опроса – это небольшая болезнь роста – ребятам пока не с кем себя сравнивать, чтобы определить свой уровень более объективно.
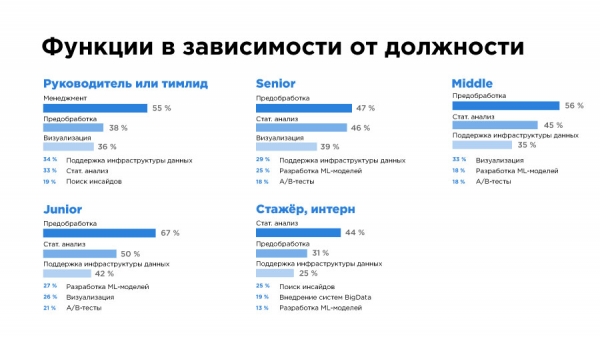

Ожидаемо, больше всего времени специалисты по работе с данными тратят не на супер сложную математику или инженерию, а на предобработку, выгрузку, очистку данных. В каждой специализации мы видим предобработку в топ-3. А вот сложные вещи типа разработки ML-моделей или работы с Big Data, в топ-3 мы видим крайне редко – только у ML- и DWH-инженеров.
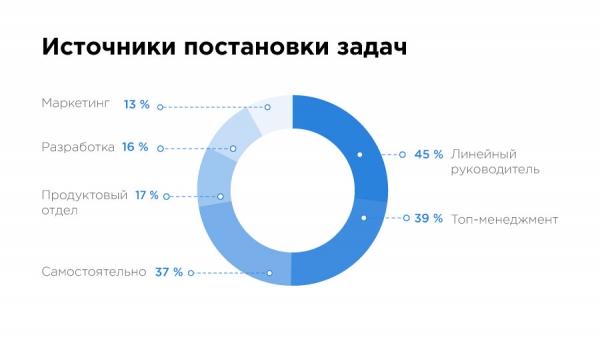
Есть и парочка грустных инсайтов. 40% задач специалисты ставят себе самостоятельно. В Казахстане пока только топовые компании-единороги распробовали преимущества работы с большими данными и научились делать это грамотно. Они транслируют на рынок, что Big Data и Machine Learning – это круто, а второй эшелон тянется следом, но далеко не всегда понимает, как устроена работа с данными. Поэтому мы видим, что задачи специалисты себе ставят сами, а бизнес не всегда знает, чего хочет.
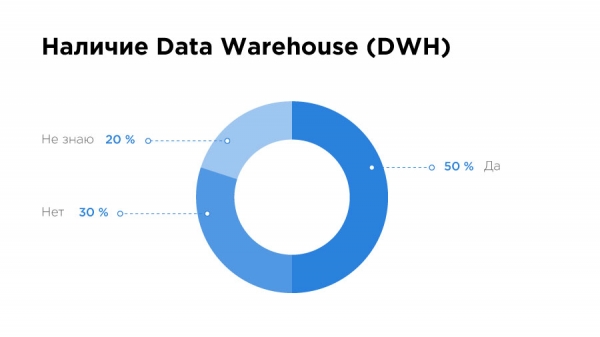
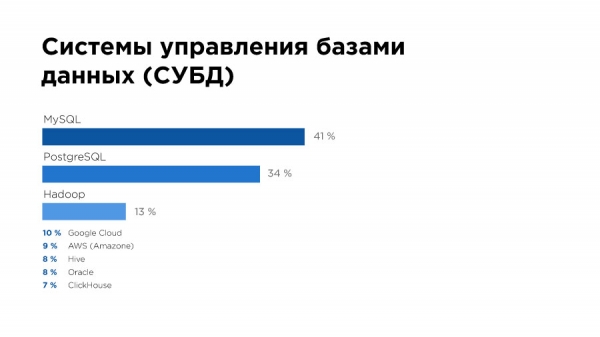
Удивило, что 20% специалистов вообще не знают, есть ли в их компании Data Warehouse. Да, и с системами gestione delle basi di dati не все так хорошо – 41% используют MySQL, а еще 34% – PostgreSQL. О чем это может говорить? Они работают скорее со small data.
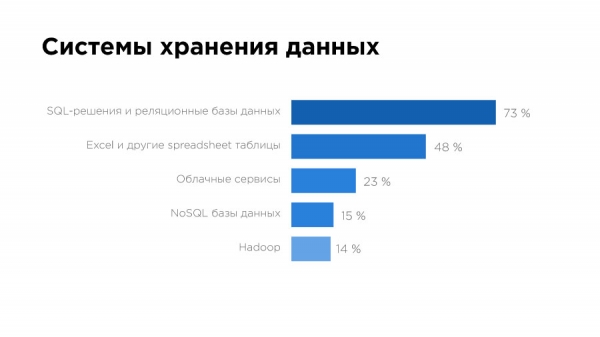
В вопросе про системы хранения мы снова видим MySQL и даже (!) Excel. Но это может говорить, например, о том, что у большинства компаний просто-напросто еще нет запроса на работу с большими данными.
Здесь все снова неоднозначно. В целом зарплаты оказались чуть ниже, чем я ожидал.
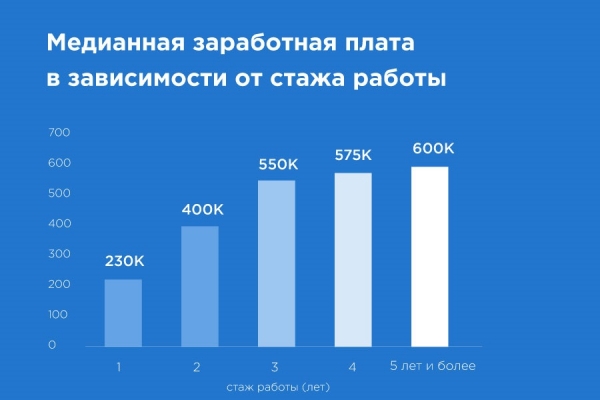
Лично мне сложно представить ML-инженера, который готов работать за 200 тысяч тенге – наверное, это стажер. Либо, компетенции у таких специалистов совсем слабые, либо компаниям пока сложно адекватно оценить работу Data Science. Но возможно это также говорит о том, что рынок пока в самом начале своего взросления. И со временем уровень зарплат установится на более адекватном уровне.
Fonte: habr.com
