


Come fa un backend developer a capire se una query SQL funzionerà bene in produzione? Nelle grandi o rapidamente crescenti aziende, l'accesso alla produzione non è per tutti. E anche con l'accesso, non tutte le query possono essere testate senza rischi, e creare una copia del database richiede spesso ore. Per affrontare questi problemi, abbiamo creato un DBA artificiale - Joe. È già stato implementato con successo in diverse aziende e aiuta decine di sviluppatori.
Video:

Ciao a tutti! Mi chiamo Anatolij Stansler. Lavoro presso . Ci occupiamo di accelerare il processo di sviluppo, eliminando i ritardi legati all'uso di Postgres per sviluppatori, DBA e QA.
Abbiamo clienti fantastici e oggi parte della presentazione sarà dedicata ai casi studio che abbiamo incontrato lavorando con loro. Vi parlerò di come li abbiamo aiutati a risolvere problemi piuttosto seri.

Quando conduciamo uno sviluppo e facciamo migrazioni complesse e caricate, ci poniamo la domanda: "Questa migrazione andrà a buon fine?" Facciamo uso delle revisioni, affidandoci alle conoscenze di colleghi più esperti, esperti DBA. E loro possono dirci se va a buon fine o meno.
Tuttavia, potrebbe essere meglio se potessimo testarlo noi stessi su copie a grandezza naturale. Oggi parleremo dei vari approcci ai test, di come possiamo farlo meglio e degli strumenti a disposizione. Discuteremo anche i pro e i contro di questi approcci e cosa possiamo migliorare.
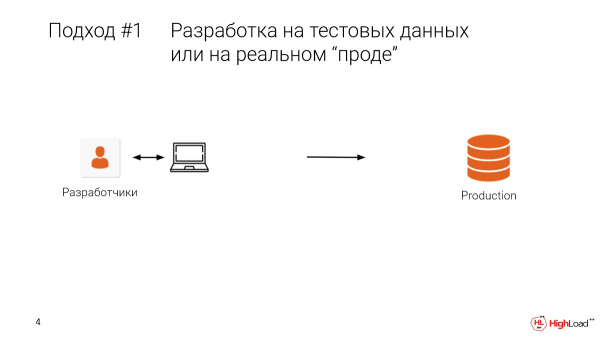
Chi ha mai fatto modifiche direttamente in prod, come la creazione di indici? È successo a molti. E a chi di voi è capitato di perdere dati o avere periodi di inattività? Allora questa situazione vi sarà familiare. Per fortuna ci sono i backup.

Il primo approccio è il test in prod. Oppure, quando lo sviluppatore lavora da una macchina locale con dati di test, ha un campione limitato. Lo implementiamo in prod e ci troviamo in questa situazione.

È frustrante e costoso. Probabilmente non è la scelta migliore.
Come possiamo farlo meglio?
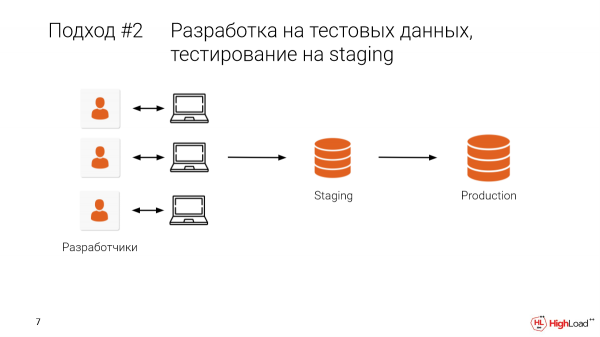
Prendiamo in considerazione lo staging e dirotta una parte di prod. O, nella soluzione migliore, utilizziamo realmente prod con tutti i dati. Una volta sviluppato localmente, dobbiamo anche verificare ulteriormente su staging.
Questo ci permetterà di eliminare alcune errori, ovvero di evitarli in prod.
Quali problemi ci sono?
- Il problema è che questo staging lo condividiamo con i colleghi. E molto spesso capita che tu faccia qualche modifica, bam – e non ci sono più dati, tutto il lavoro sprecato. Lo staging era multi-terabyte. E ci vuole molto tempo affinché si riavvii. E decidiamo di lavorarci domani. Ormai, lo sviluppo si è bloccato.
- E, ovviamente, ci sono molti colleghi che lavorano lì, molte squadre. E dobbiamo coordinare manualmente. Ed è scomodo.

E va detto che abbiamo solo un tentativo, un colpo, se vogliamo fare delle modifiche al database, toccare i dati, cambiare la struttura. E se qualcosa va storto, se c’è stato un errore nella migrazione, non possiamo tornare indietro rapidamente.
È meglio rispetto all'approccio precedente, ma c'è comunque una grande probabilità che qualche errore finisca in produzione.
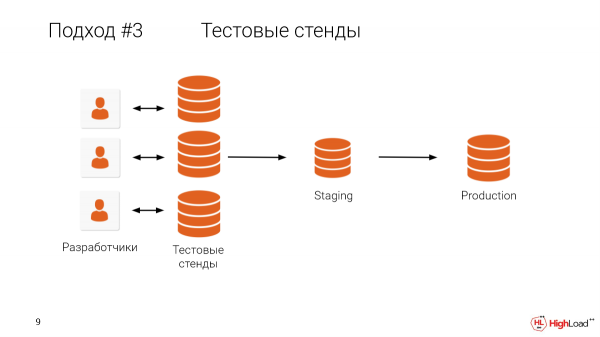
Cosa ci impedisce di dare a ogni sviluppatore un ambiente di test, una copia a grandezza naturale? Penso sia chiaro cosa ci frena.
Chi ha un database più grande di un terabyte? Più della metà della sala.
E chiaramente, mantenere macchine per ogni sviluppatore, quando c'è una produzione così grande, è molto costoso e, inoltre, richiede molto tempo.
Abbiamo clienti che hanno compreso l'importanza di testare tutte le modifiche su copie a grandezza naturale, ma hanno un database inferiore a un terabyte e non dispongono delle risorse per mantenere un ambiente di test per ogni sviluppatore. Pertanto, devono scaricare i dump localmente sul proprio computer e testare in questo modo. Questo richiede un sacco di tempo.

Anche se lo fai all'interno dell'infrastruttura, scaricare un terabyte di dati all'ora è già un ottimo risultato. Ma utilizzano dump logici, scaricano localmente dal cloud. Per loro, la velocità è di circa 200 gigabyte all'ora. E ci vuole anche tempo per ripristinare dai dump logici, applicare gli indici, ecc.
Ma usano questo approccio perché consente di mantenere il prod affidabile.
Cosa possiamo fare qui? Facciamo in modo che gli ambienti di test siano economici e diamo a ciascun sviluppatore il proprio ambiente di test.
È possibile.
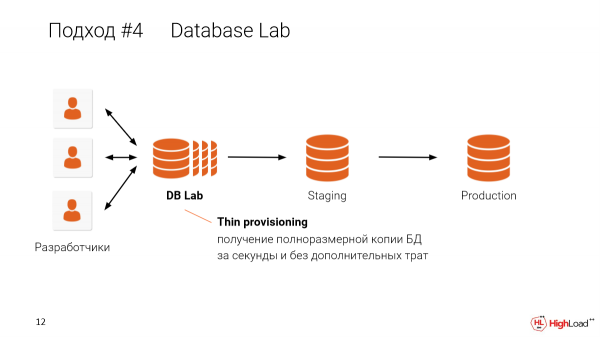
In this approach, where we create thin clones for each developer, we can share it on a single machine. For instance, if you have a four-terabyte database and you want to provide it to 10 developers, you don't need to have 10 times four terabytes of databases. One machine is sufficient to create thin isolated copies for each developer, using just one machine. I will explain how this works shortly.

A real example:
DB – 4.5 terabytes.
We can obtain independent copies in 30 seconds.
You don't need to wait for a test environment or depend on its size. You can get it in seconds. These will be completely isolated environments, but they share data among themselves.
This is amazing. Here we're talking about magic and a parallel universe.

In our case, it works with the OpenZFS system.

OpenZFS is a copy-on-write file system that natively supports snapshots and clones out of the box. It's reliable and scalable. It's very easy to manage. You can literally deploy it with just two commands.
There are other options:
LVM,
SAN (for example, Pure Storage).
Il Database Lab di cui parlo è modulare. Può essere implementato utilizzando diverse opzioni. Ma per il momento ci siamo concentrati su OpenZFS, poiché abbiamo riscontrato problemi specifici con LVM.
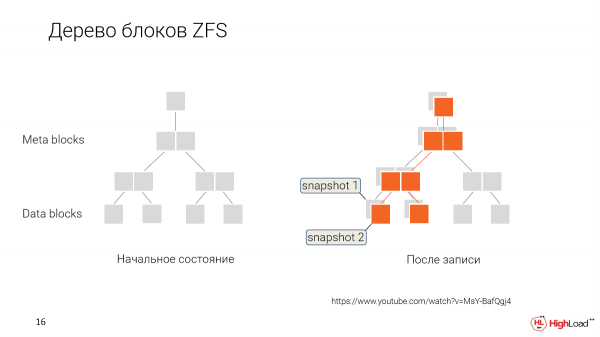
Come funziona? Invece di riscrivere i dati ogni volta che li modifichiamo, li memorizziamo semplicemente, etichettando che questi nuovi dati appartengono a un nuovo punto nel tempo, a un nuovo snapshot.
E in seguito, quando vogliamo tornare indietro o creare un nuovo clone da una versione precedente, diciamo semplicemente: «Ok, fornisceteci questi blocchi di dati che sono contrassegnati in questo modo».
E questo utente lavorerà con un set di dati del genere. Lo modificherà progressivamente creando i propri snapshot.
E avremo diramazioni. Ogni sviluppatore, nel nostro caso, avrà la possibilità di avere il proprio clone da modificare, mentre i dati condivisi saranno accessibili a tutti.
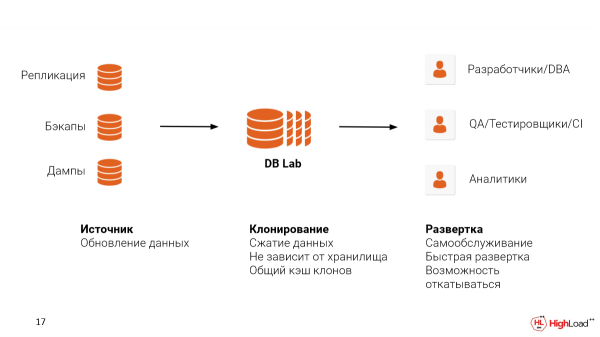
Per implementare un sistema del genere, è necessario affrontare due problemi:
La prima è la fonte dei dati da cui li preleverai. Puoi configurare la replica da production. Puoi utilizzare i backup già configurati, spero. WAL-E, WAL-G o Barman. E anche se stai utilizzando una soluzione Cloud, come RDS o Cloud SQL, puoi usare dump logici. Tuttavia, ti consigliamo di utilizzare backup, perché in questo modo manterrai anche la struttura fisica dei file, il che ti permetterà di essere ancora più vicino alle metriche che vedresti in produzione, per rilevare i problemi esistenti.
La seconda è il luogo in cui desideri ospitare Database Lab. Può essere Cloud o On-premise. È importante menzionare che ZFS supporta la compressione dei dati. E lo fa in modo abbastanza efficace.
Immagina che ognuno di questi cloni, a seconda delle operazioni che eseguiamo sul database, crescerà in qualche modo. Anche per questo dev sarà necessario spazio. Ma grazie al fatto che abbiamo preso una base di 4,5 terabyte, ZFS la comprimerà a 3,5 terabyte. A seconda delle impostazioni, questo può variare. E ci sarà ancora spazio per dev.
Un tale sistema può essere utilizzato per diversi casi d'uso.
Questi sono sviluppatori, DBA per la verifica delle query, per l'ottimizzazione.
Questo può essere utilizzato nei test QA per verificare una migrazione specifica prima di implementarla in prod. Possiamo anche creare ambienti speciali per QA con dati reali, in cui possono testare nuove funzionalità. E questo richiederà secondi invece di ore, e forse anche giorni in altri casi, dove non vengono utilizzate copie sottili.
E un altro caso. Se l'azienda non ha un sistema di analisi configurato, possiamo estrarre una copia sottile del database di produzione e fornire a lungo termine per richieste specifiche o indici speciali che possono essere utilizzati nell'analisi.

Con questo approccio:
Bassa probabilità di errori in produzione, poiché tutte le modifiche sono state testate su dati di dimensioni complete.
Si instaura una cultura del testing, poiché ora non è necessario attendere ore il proprio stand.
E non ci sono ostacoli, non ci sono attese tra i test. Puoi davvero andare e verificare. E sarà migliore, poiché accelereremo lo sviluppo.
Ci sarà meno refactoring. Ci saranno meno bug in produzione. Li rifattorizzeremo meno in seguito.
Possiamo annullare modifiche irreversibili. Questo non è previsto negli approcci standard.
- È vantaggioso, perché condividiamo le risorse degli ambienti di test.
È già un buon inizio, ma cosa si potrebbe accelerare ulteriormente?

Grazie a questo sistema possiamo abbattere notevolmente la barriera all'ingresso per tale tipo di test.
Attualmente c'è un circolo vizioso, in cui lo sviluppatore, per accedere a dati reali su larga scala, deve diventare un esperto. Deve essere affidato un tale accesso.
Ma come crescere se questo accesso non c'è? E se puoi accedere solo a un insieme di dati di test molto ridotto? Allora non si riesce a ottenere una vera esperienza.
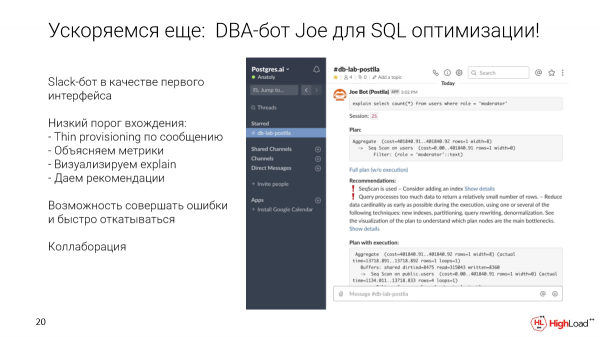
Come uscire da questo circolo? Come primo interfaccia amichevole per sviluppatori di qualsiasi livello, abbiamo scelto un bot per Slack. Ma potrebbe essere qualsiasi altro tipo di interfaccia.
Cosa permette di fare? Puoi prendere una richiesta specifica e inviarla in un canale specializzato per il database. Creeremo automaticamente un clone leggero in pochi secondi. Eseguiremo questa richiesta. Raccoglieremo metriche e raccomandazioni. Mostreremo una visualizzazione. E quel clone rimarrà per ottimizzare successivamente la richiesta, aggiungendo indici ecc.
Inoltre, Slack ci offre opportunità di collaborazione pronte all'uso. Poiché è semplicemente un canale, puoi iniziare a discutere quella richiesta direttamente lì nel thread, pingando i tuoi colleghi, i DBA all'interno dell'azienda.

Tuttavia, ci sono anche delle problematiche. Poiché siamo nel mondo reale e utilizziamo un server che ospita molti cloni contemporaneamente, dobbiamo ridurre la quantità di memoria e potenza di elaborazione disponibili per i cloni.
Ma per garantire che questi test siano credibili, dobbiamo trovare una soluzione a questo problema.
È chiaro che un aspetto importante sono i dati identici. Ma questo lo abbiamo già. Vogliamo ottenere una configurazione uniforme. E possiamo fornire una configurazione praticamente identica.
Sarebbe fantastico avere hardware identico a quello di produzione, ma potrebbe differire.
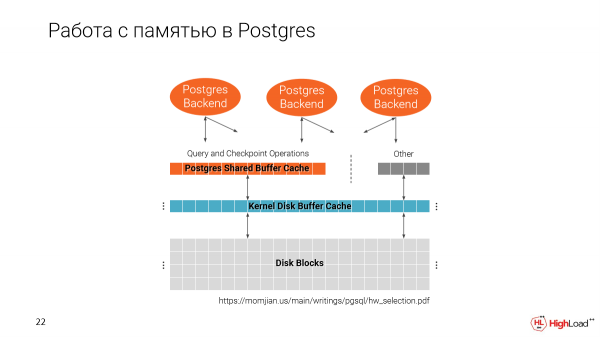
Ricordiamo come funziona Postgres con la memoria. Abbiamo due cache. Una è quella del file system e l'altra è la cache del buffer condiviso di Postgres.
È importante notare che la cache del buffer condiviso viene allocata all'avvio di Postgres a seconda delle dimensioni impostate nella configurazione.
La seconda cache utilizza tutto lo spazio disponibile.
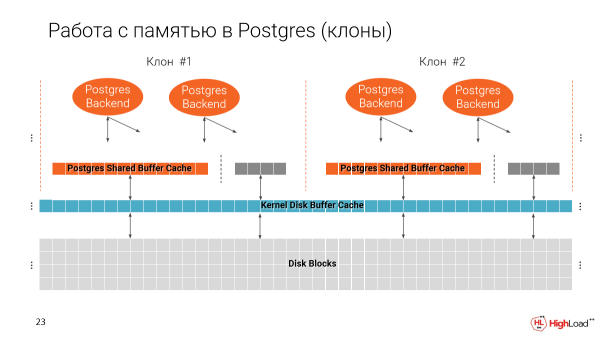
Quando creiamo più cloni su una sola macchina, riempiamo gradualmente la memoria. Idealmente, la cache del buffer condiviso dovrebbe essere il 25% dell'intero volume di memoria disponibile sulla macchina.
Se non modifichiamo questo parametro, possiamo avviare solo 4 istanze sulla stessa macchina, ovvero solo 4 cloni leggeri. Questo è un problema, poiché vorremmo averne molti di più.
D'altro canto, la cache del buffer viene utilizzata per eseguire query e per gli indici, quindi il piano dipende dalle dimensioni delle nostre cache. Se riduciamo questo parametro all'improvviso, i nostri piani potrebbero cambiare notevolmente.
Ad esempio, se su prod abbiamo una cache grande, Postgres preferirà utilizzare l'indice. Se non è così, allora verrà utilizzato SeqScan. E quale sarebbe il senso se questi piani non coincidessero?
Ma qui arriviamo a una soluzione, cioè il piano in Postgres non dipende dalla dimensione specifica impostata nel Shared Buffer, ma dipende da effective_cache_size.

Effective_cache_size è il volume di cache previsto che abbiamo a disposizione, cioè la somma del Buffer Cache e della cache del filesystem. Questo è impostato nella configurazione. E questa memoria non viene allocata.
E grazie a questo parametro possiamo ingannare Postgres, affermando che in realtà abbiamo accesso a molti dati, anche se questi dati non sono disponibili. In questo modo, i piani corrisponderanno completamente all'ambiente di produzione.
Ma ciò potrebbe influire sui tempi. Ottimizziamo le richieste in base ai tempi, ma è importante notare che i tempi dipendono da molti fattori:
Dipende dal carico attuale su prod.
Dipende dalle caratteristiche della macchina stessa.
E questo è un parametro indiretto, ma in realtà possiamo ottimizzare in base alla quantità di dati che questa richiesta leggerà per ottenere un risultato.
E se vogliamo che il timing si avvicini a quello che vedremo in prod, dobbiamo utilizzare hardware il più simile possibile e, forse, anche di più, per ospitare tutti i cloni. Ma questo è un compromesso, cioè avrete stessi piani, vedrete quanti dati legge una specifica query e potrete trarre conclusioni: questa query è buona (o migrata) oppure cattiva, e deve essere ottimizzata ulteriormente.
Analizziamo come avviene precisamente l'ottimizzazione con Joe.
Prendiamo una query da un sistema reale. In questo caso, il database è di 1 terabyte. E vogliamo calcolare il numero di post recenti che hanno ricevuto più di 10 like.
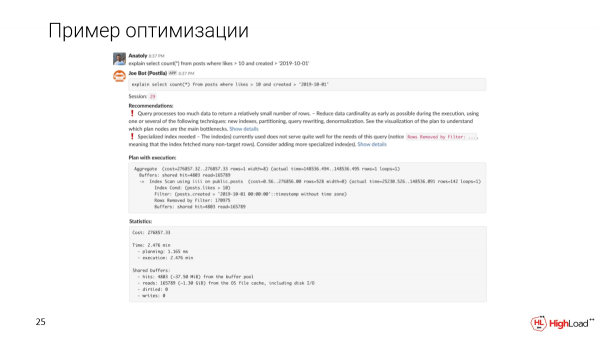
Scriviamo un messaggio nel canale, si è aperto un clone per noi. E vedremo che una tale query si eseguirà in 2,5 minuti. È la prima cosa che noteremo.
Joe mostrerà raccomandazioni automatiche basate sul piano e sulle metriche.
Vedremo che la query sta elaborando troppi dati per ottenere un numero relativamente ridotto di righe. È necessario un indice specializzato, poiché abbiamo notato che nella query ci sono troppe righe filtrate.
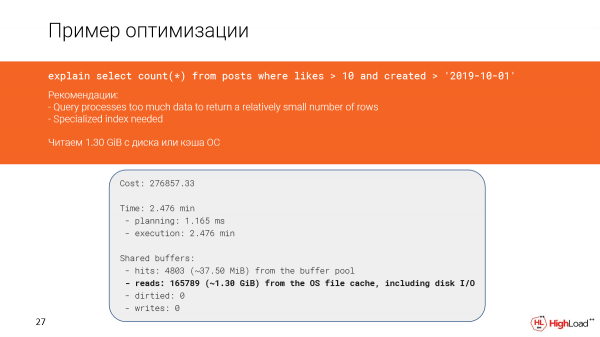
Vediamo più nel dettaglio cosa è successo. In effetti, abbiamo letto quasi un gigabyte e mezzo di dati dalla cache di file o addirittura dal disco. E questo non è positivo, poiché abbiamo recuperato solo 142 righe.
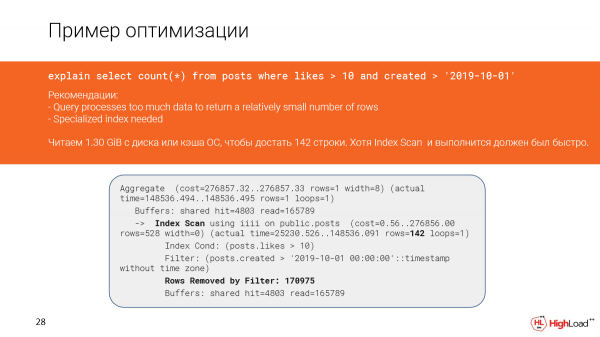
Eppure, qui abbiamo una scansione dell'indice e dovrebbe funzionare rapidamente, ma poiché abbiamo filtrato troppe righe (abbiamo dovuto contarlas), la query è risultata lenta.
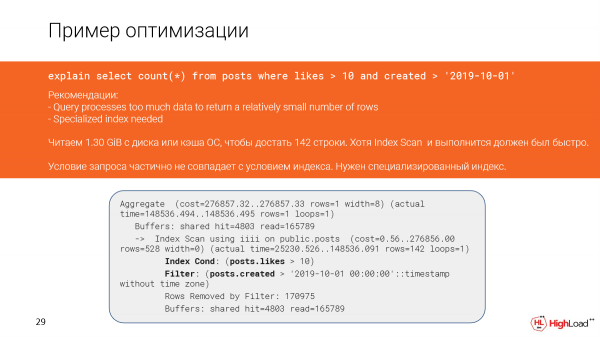
E ciò è avvenuto nel piano a causa del fatto che le condizioni nella query e quelle nell'indice non coincidono completamente.
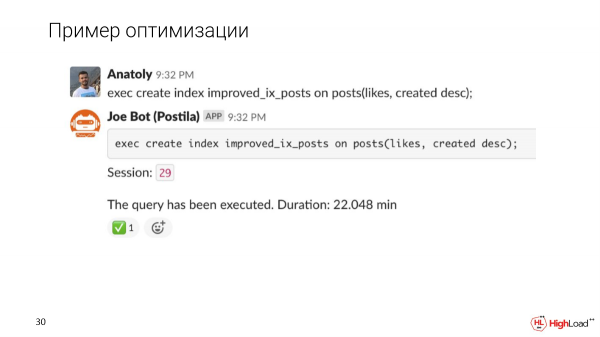
Proviamo a rendere l'indice più preciso e vediamo come cambia l'esecuzione della query dopo questo aggiustamento.
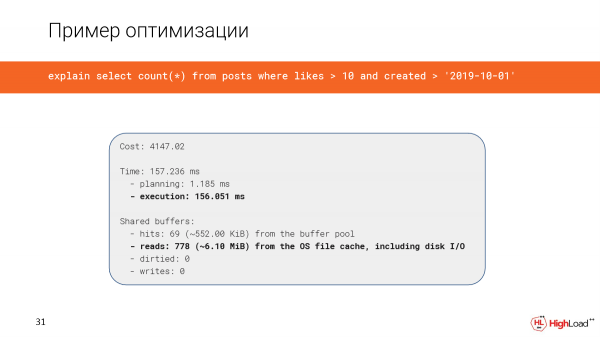
La creazione dell'indice ha richiesto abbastanza tempo, ma ora stiamo verificando la query e osserviamo che il tempo invece di 2,5 minuti è diventato solo 156 millisecondi, il che è piuttosto buono. E leggiamo solo 6 megabyte di dati.
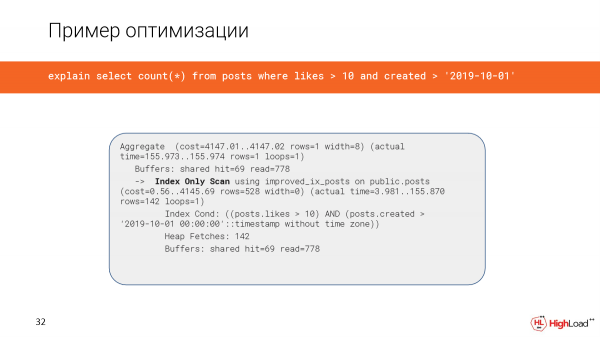
E ora stiamo utilizzando una scansione solo indice.
Un'altra questione importante è che vogliamo presentare il piano in un modo più comprensibile. Abbiamo implementato una visualizzazione tramite Flame Graphs.
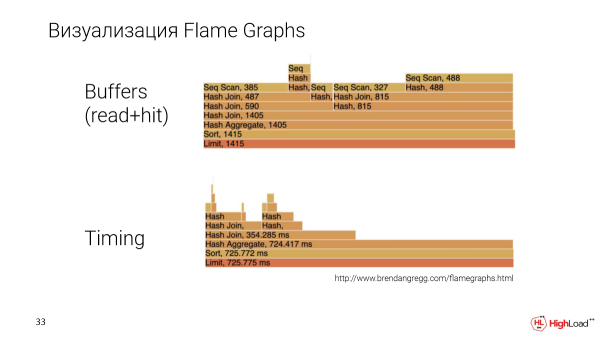
Questa è un'altra richiesta, più complessa. Costruiamo i Flame Graphs su due parametri: la quantità di dati che un nodo specifico ha elaborato e il timing, ovvero il tempo di esecuzione del nodo.
Qui possiamo confrontare specificamente i nodi tra di loro. Sarà chiaro quale consuma di più o di meno, cosa che di solito è difficile da fare con altri metodi di visualizzazione.
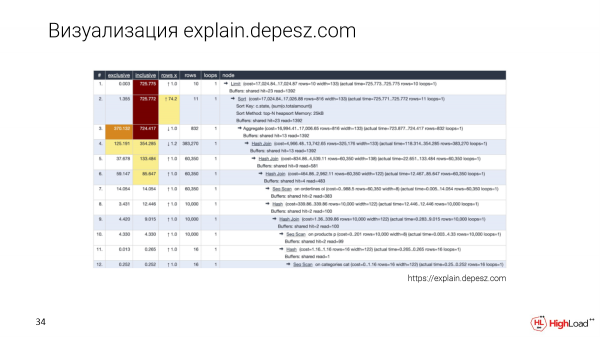
Certo, tutti conoscono explain.depesz.com. Una buona caratteristica di questa visualizzazione è che salviamo il piano testuale e riportiamo alcuni parametri principali in una tabella per poterli ordinare.
E anche gli sviluppatori che non hanno ancora approfondito questo argomento usano explain.depesz.com, perché per loro è più semplice capire quali metriche siano importanti e quali no.
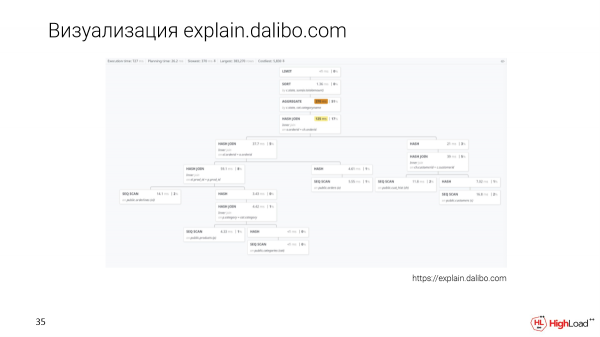
C'è un nuovo approccio alla visualizzazione: explain.dalibo.com. Fanno una visualizzazione ad albero, ma qui è molto difficile confrontare i nodi tra di loro. È possibile capire bene la struttura, ma se c'è una grande richiesta, sarà necessario scorrere avanti e indietro, ma è pur sempre un'opzione.
Collaborazione
E, come ho già detto, Slack ci offre la possibilità di collaborare. Ad esempio, se ci troviamo di fronte a una richiesta complessa che non è chiara da ottimizzare, possiamo chiarire questa questione con i nostri colleghi in un thread su Slack.

Riteniamo sia importante testare su dati a grandezza naturale. Per questo abbiamo creato lo strumento Update Database Lab, che è disponibile in open source. Puoi usare anche il bot Joe. Puoi prenderlo subito e implementarlo da te. Tutti i guide sono disponibili lì.
È importante anche notare che la soluzione in sé non è rivoluzionaria, poiché esiste Delphix, ma è una soluzione enterprise. È completamente chiusa e costa molto. Noi ci specializziamo su Postgres. Tutti i nostri prodotti sono in open source. Unisciti a noi!
Con questo concludo. Grazie!
Domande
Buongiorno! Grazie per la presentazione! È molto interessante, soprattutto per me, poiché ho affrontato un compito simile qualche tempo fa. Pertanto, ho una serie di domande. Spero di poterne fare almeno alcune.
È interessante sapere come calcolate lo spazio per questo ambiente. La tecnologia implica che, in determinate circostanze, i vostri cloni possano crescere fino a raggiungere la dimensione massima. In termini semplici, se avete un database di dieci terabyte e 10 cloni, è facile immaginare una situazione in cui ogni clone pesi 10 dati unici. Come calcolate quello spazio, cioè quel delta di cui avete parlato, in cui vivranno questi cloni?
Ottima domanda. È importante monitorare i cloni specifici. Se un clone subisce un cambiamento eccessivo, iniziando a crescere, possiamo prima avvisare l'utente di questo, oppure fermare immediatamente quel clone per evitare una situazione di fail.
Sì, ho una domanda correlata. Come garantite il ciclo di vita di questi moduli? È un problema e una storia a parte per noi. Come avviene?
Ogni clone ha un ttl. In linea di principio, abbiamo un ttl fisso.
Qual è, se non è un segreto?
1 ora, cioè idle – 1 ora. Se non viene utilizzato, lo eliminiamo. Ma qui non c'è nulla di sorprendente, poiché possiamo creare un clone in pochi secondi. E se serve di nuovo, allora – prego.
Anch'io sono curioso riguardo alla scelta delle tecnologie, perché, ad esempio, noi utilizziamo parallelamente diversi metodi per vari motivi. Perché proprio ZFS? Perché non hai usato LVM? Hai menzionato che ci sono stati problemi con LVM. Quali erano questi problemi? A mio avviso, la soluzione più ottimale è quella con lo storage condiviso, in termini di prestazioni.
Qual è il principale problema con ZFS? Il fatto che devi eseguirlo su un unico host, cioè tutti gli instances vivranno all'interno di un'unica operatività. E nel caso dello storage condiviso, puoi collegare hardware diverso. E il collo di bottiglia è costituito solo dai blocchi che si trovano nello storage condiviso. E la questione interessante è proprio quella della scelta delle tecnologie. Perché non LVM?
Possiamo discutere specificamente di LVM durante il meetup. Per quanto riguarda lo storage, è semplicemente costoso. Possiamo implementare il sistema ZFS ovunque. Puoi distribuirlo sulla tua macchina. Puoi semplicemente scaricare il repository e installarlo. ZFS è praticamente installabile ovunque, se parliamo di Linux. Cioè, abbiamo una soluzione molto flessibile. E ZFS in sé offre già moltissimo out of the box. Puoi caricare un numero illimitato di dati, collegare un gran numero di dischi, e ci sono snapshot. E, come ho già detto, è molto semplice da amministrare. Cioè, risulta molto piacevole da usare. È collaudato, ha molti anni. Ha una community molto ampia, che continua a crescere. ZFS è una soluzione molto affidabile.
Nikolay Samokhvalov: Posso aggiungere un commento? Mi chiamo Nikolay, lavoro insieme ad Anatoliy. Sono d'accordo, lo storage è fantastico. E alcuni dei nostri clienti hanno Pure Storage, ecc.
Anatoliy ha giustamente sottolineato che puntiamo alla modularità. In futuro, possiamo implementare un'unica interfaccia – crea uno snapshot, crea un clone, distruggi un clone. È tutto molto semplice. E lo storage è fantastico, se disponibile.
Ma ZFS è accessibile a tutti. È tempo che Delphix smetta di monopolizzare, hanno 300 clienti. Di questi, 50 sono nella fortune 100, cioè sono orientati verso la NASA e simili. È ora di rendere questa tecnologia accessibile a tutti. Ecco perché abbiamo il Core open source. Abbiamo una parte dell'interfaccia che non è open source. Questa è la piattaforma che mostreremo. Ma vogliamo che sia disponibile per tutti. Vogliamo fare una rivoluzione affinché tutti i tester smettano di indovinare sui laptop. Dobbiamo scrivere SELECT e vedere immediatamente che è lento. È sufficiente aspettare che il DBA ce ne parli. Questo è l'obiettivo principale. E penso che ci arriveremo tutti. E queste cose le facciamo per renderle accessibili a tutti. Ecco perché ZFS, perché sarà disponibile ovunque. Grazie alla community per la risoluzione dei problemi e per avere la licenza open source, e così via.
Salve! Grazie per la presentazione! Mi chiamo Maxim. Abbiamo affrontato problemi simili. Li abbiamo risolti da noi. Come separate le risorse tra questi cloni? Ogni clone può occuparsi di un compito specifico: uno testa una cosa, un altro un'altra, qualcuno sta costruendo un indice, qualcun altro ha un lavoro pesante in corso. Se per quanto riguarda la CPU si può anche suddividere, per l'IO come lo dividete? Questa è la prima domanda.
E la seconda domanda riguarda la diversità degli ambienti. Supponiamo che qui io abbia ZFS e tutto funzioni alla grande, ma il cliente in produzione non ha ZFS, ma ad esempio ext4. Come possiamo gestire questa situazione?
Le domande sono molto buone. Ho accennato brevemente a questo problema relativo alla condivisione delle risorse. E la soluzione è la seguente. Immaginate di testare in staging. Potreste trovavi anche in una situazione simile, in cui qualcuno sta creando un certo carico di lavoro e qualcun altro un altro. Alla fine, visualizzate metriche poco chiare. Anche un problema simile può verificarsi in produzione. Quando volete controllare una certa query e notate che presenta dei problemi – è lenta nel rispondere, in realtà il problema non era nella query, ma nel carico di lavoro parallelo presente.
E per questo è importante concentrarsi su quale sarà il piano, quali passi seguiremo nel piano e quanti dati apporteremo. Il fatto che i nostri dischi, ad esempio, possano essere sovraccarichi da qualcos'altro influenzerà specificamente il timing. Ma possiamo valutare, in base alla quantità di dati, quanto carico genera questa query. Non è così importante se ci sarà qualcun altro a eseguire operazioni contemporaneamente.
Ho due domande. È una cosa davvero interessante. Ci sono stati casi in cui i dati in produzione sono critici, ad esempio, i numeri delle carte di credito? Esiste già qualcosa di pronto o è un'attività separata? E la seconda domanda: esiste qualcosa del genere per MySQL?
Per quanto riguarda i dati. Stiamo pianificando di fare offuscamento, anche se attualmente non lo facciamo. Ma se stai implementando proprio Joe, se non dai accesso agli sviluppatori, non ci sarà accesso ai dati. Perché? Perché Joe non mostra i dati. Mostra solo metriche, piani e altro. È stato progettato appositamente in quanto è una delle richieste del nostro cliente. Volevano avere la possibilità di ottimizzare, ma senza dare accesso indiscriminato.
Per quanto riguarda MySQL. Questo sistema può essere utilizzato per qualsiasi cosa che memorizzi state su disco. E poiché ci occupiamo di Postgres, stiamo attualmente realizzando l'automazione completa per Postgres. Vogliamo automatizzare l'estrazione dei dati dai backup. Configuriamo correttamente Postgres. Sappiamo come fare in modo che i piani coincidano, e così via.
Ma poiché il sistema è espandibile, sarà possibile utilizzarlo anche per MySQL. E ci sono esempi di questo tipo. Una cosa simile esiste in Yandex, ma non viene pubblicata da nessuna parte. La usano internamente in Yandex.Metrica. E lì si parla proprio di MySQL. Ma le tecnologie sono le stesse, ZFS.
Grazie per la presentazione! Ho anche un paio di domande. Hai menzionato che il cloning può essere utilizzato per l'analisi, ad esempio, per costruire indici aggiuntivi. Puoi spiegare un po' meglio come funziona?
E faccio subito la seconda domanda riguardo alla uniformità dei stand, uniformità dei piani. Il piano dipende anche dalle statistiche raccolte da Postgres. Come affrontate questo problema?
Non abbiamo casi specifici di analisi, perché non l'abbiamo ancora utilizzato in questo modo, ma questa possibilità esiste. Se parliamo di indici, immagina un query su una tabella con centinaia di milioni di record e su una colonna che generalmente non è indicizzata in produzione. E vogliamo calcolare alcuni dati. Se eseguiamo questa query in produzione, c'è la possibilità che ci sia un downtime, perché la query potrebbe impiegare un minuto per eseguire.
Ok, facciamo un clone leggero che possiamo fermare senza problemi per qualche minuto. Per rendere più comoda l'analisi dei dati, aggiungeremo indici per le colonne di nostro interesse.
L'indice verrà creato ogni volta?
Possiamo fare in modo di toccare i dati, creare snapshot, e poi ripristinare da quello snapshot e lanciare nuove query. Cioè, possiamo fare in modo di poter creare nuovi cloni già con gli indici impostati.
Per quanto riguarda la questione delle statistiche, se ci ripristiniamo da un backup e facciamo replica, avremo esattamente le stesse statistiche. Perché porteremo tutta la struttura fisica dei dati, cioè i dati come sono con tutte le metriche statistiche.
Qui c'è un'altra problematica. Se stai utilizzando una soluzione cloud, avrai accesso solo a dump logici, perché Google e Amazon non ti permettono di ottenere una copia fisica. Questo rappresenterà un problema.
Grazie per la relazione. Sono emerse due buone domande su MySQL e sulla divisione delle risorse. Tuttavia, in sostanza, tutto si riduce al fatto che si tratta di un argomento non specifico per i DBMS, ma in generale per i file system. Pertanto, anche le domande sulla divisione delle risorse devono essere affrontate da quel punto di vista, non considerando solo Postgres, ma il file system in server, nell'istanza.
La mia domanda è un po' diversa. Riguarda di più la multilivello del database, dove ci sono diversi strati. Noi, ad esempio, abbiamo configurato l'aggiornamento di un'immagine di dieci terabyte, con la replica in corso. E stiamo utilizzando specificamente questa soluzione per i database. La replica è in atto e i dati vengono aggiornati. Qui lavorano parallelamente 100 dipendenti che eseguono continuamente queste diverse istantanee. Cosa fare? Come fare per evitare conflitti, in cui avviano una cosa e poi il file system cambia, e queste istantanee si rovinano tutte?
Non si rovinano, perché ZFS funziona in questo modo. Possiamo mantenere separatamente in un unico flusso le modifiche al file system, che arrivano grazie alla replica. E mantenere sui vecchi versioni dei dati i cloni che gli sviluppatori utilizzano. E questo per noi funziona, va tutto bene.
Quindi, l'aggiornamento avverrà come uno strato aggiuntivo, e tutte le nuove immagini saranno basate su questo strato, giusto?
Dai livelli precedenti, che provenivano dalle repliche precedenti.
I livelli precedenti verranno rimossi, ma faranno riferimento al vecchio strato, e le nuove immagini verranno prese dall'ultimo strato ottenuto con l'aggiornamento?
In generale, sì.
Allora, come conseguenza, avremo molti strati. E col tempo dovranno essere compressi?
Sì, esatto. C'è una certa finestra. Manteniamo snapshot settimanali. Questo dipende dalle risorse che hai. Se hai la possibilità di conservare molti dati, puoi mantenere gli snapshot per un lungo periodo. Non si eliminano da soli. Non ci sarà corruzione dei dati. Se gli snapshot diventano obsoleti, come ci sembra, cioè dipende dalla policy aziendale, allora possiamo semplicemente eliminarli e liberare spazio.
Buongiorno, grazie per la presentazione! Riguardo alla domanda di Joe. Hai detto che il cliente non voleva dare accesso indiscriminato ai dati. Tecnicalmente, se una persona ha il risultato di Explain Analyze, può monitorare i dati.
Esatto. Ad esempio, possiamo scrivere: «SELECT FROM WHERE email = qualcuno». Cioè, non vedremo i dati stessi, ma possiamo osservare alcuni indizi indiretti. È importante capirlo. D'altra parte, però, tutto questo è visibile. Abbiamo l'audit dei log, abbiamo il controllo degli altri colleghi, che vedono anche cosa fanno gli sviluppatori. E se qualcuno prova a farlo, il servizio di sicurezza arriverà da loro e si occuperà della questione.
Buongiorno! Grazie per la presentazione! Ho una domanda breve. Se Slack non è utilizzato in azienda, c'è attualmente qualche collegamento a esso oppure possiamo lanciare istanze per sviluppatori, in modo da collegare un'app di test ai database?
Attualmente c'è un collegamento a Slack, cioè non esiste nessun altro messaggero, ma sarebbe bello implementare il supporto per altri messaggeri. Cosa puoi fare? Puoi lanciare un DB Lab senza Joe, utilizzare la nostra piattaforma o l'API REST per creare cloni e connetterti tramite PSQL. Ma è fattibile solo se sei disposto a dare ai tuoi sviluppatori accesso ai dati, poiché qui non ci sarà alcuno schermo.
Questa interfaccia non mi serve, ma ho bisogno di questa possibilità.
Allora – sì, si può fare.
Fonte: habr.com
