


Ciao a tutti! Mi chiamo Oleg Sidorenkov e sono il responsabile del team infrastruttura presso DomKlik. Gestiamo "Cubik" in produzione da oltre tre anni e in questo periodo abbiamo vissuto molte esperienze interessanti. Oggi vi racconterò come, con il giusto approccio, sia possibile ottenere ancora più prestazioni dal vostro cluster utilizzando Kubernetes "vanilla". Pronti, partenza, via!
Sapete tutti che Kubernetes è un sistema scalabile open source per l'orchestrazione dei contenitori; oppure sono 5 binari che compiono magia gestendo il ciclo di vita dei vostri microservizi nell'ambiente server. Inoltre, è uno strumento abbastanza flessibile, che può essere assemblato come un costruttore Lego per una massima personalizzazione in base a diverse esigenze.
E sembra tutto bene: inserisci i server nel cluster come legna da ardere nel camino e non ti preoccupi. Ma se sei attento all'ambiente, ti chiederai: "Come posso mantenere il fuoco nel camino e risparmiare la foresta?". In altre parole, come trovare modi per migliorare l'infrastruttura e ridurre i costi.
1. Monitora le risorse dei team e delle applicazioni

Uno dei metodi più semplici ed efficaci è l'introduzione di requests/limits. Suddividete le applicazioni in namespace e i namespace in team di sviluppo. Assegnate ai vostri applicativi valori per il consumo di tempo di CPU, memoria e storage effimero prima del deploy.
resources:
requests:
memory: 2Gi
cpu: 250m
limits:
memory: 4Gi
cpu: 500mDalla nostra esperienza, abbiamo concluso che non è consigliabile gonfiare i requests oltre il doppio dei limits. La dimensione del cluster si basa sui requests, e se designate differenze nelle risorse delle applicazioni, ad esempio di 5-10 volte, immaginate cosa accadrà al vostro nodo quando si riempirà di pod e riceverà improvvisamente un carico. Niente di buono. Al minimo, throttling; al massimo, dovrete dire addio al worker e affrontare un carico ciclico sugli altri nodi dopo che i pod inizieranno a migrare.
Inoltre, grazie a limitranges potete impostare per il container valori delle risorse — minimi, massimi e predefiniti:
➜ ~ kubectl describe limitranges --namespace ops
Nome: limit-range
Namespace: ops
Tipo Risorsa Min Max Richiesta predefinita Limite predefinito Massimo rapporto Limite/Richiesta
---- -------- --- --- ------------------ --------------- -------------------------
Container cpu 50m 10 100m 100m 2
Container ephemeral-storage 12Mi 8Gi 128Mi 4Gi -
Container memory 64Mi 40Gi 128Mi 128Mi 2Non dimenticate di limitare le risorse del namespace affinché un singolo team non possa utilizzare tutte le risorse del cluster:
➜ ~ kubectl describe resourcequotas --namespace ops
Nome: resource-quota
Namespace: ops
Risorsa Utilizzato Massimo
-------- ----- -----
limits.cpu 77250m 80
limits.memory 124814367488 150Gi
pods 31 45
requests.cpu 53850m 80
requests.memory 75613234944 150Gi
services 26 50
services.loadbalancers 0 0
services.nodeports 0 0Come si può vedere dalla descrizione resourcequotas, se il team ops desidera distribuire pod che consumeranno altri 10 cpu, il pianificatore non permetterà di farlo e restituirà un errore:
Errore nella creazione: pods "nginx-proxy-9967d8d78-nh4fs" è vietato: superato il limite: resource-quota, richiesto: limits.cpu=5, requests.cpu=5, utilizzato: limits.cpu=77250m, requests.cpu=53850m, limitato: limits.cpu=10, requests.cpu=10Per risolvere un problema simile, si può scrivere uno strumento, ad esempio, come , in grado di memorizzare e confermare lo stato delle risorse dei team.
2. Seleziona lo storage file più adatto
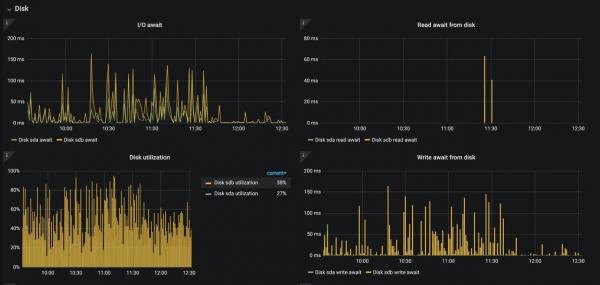
Vorrei affrontare il tema dei volumi persistenti e del sistema di archiviazione delle nodi worker di Kubernetes. Spero che nessuno usi "Kube" su HDD in produzione, ma a volte anche un comune SSD non è più sufficiente. Ci siamo trovati di fronte al problema per cui i log sovraccaricavano il disco in termini di operazioni di input/output, e qui le opzioni di soluzione sono piuttosto limitate:
Utilizzare SSD ad alte prestazioni o passare a NVMe (se gestisci il tuo hardware).
Ridurre il livello di logging.
Effettuare un bilanciamento "intelligente" dei pod che sovraccaricano il disco (
podAntiAffinity).
Lo screenshot sopra mostra cosa succede con il disco del nginx-ingress-controller quando il logging access_logs è attivato (~12.000 log/sec). Una situazione del genere può naturalmente portare a una degradazione di tutte le applicazioni su quel nodo.
Per quanto riguarda i PV, purtroppo non ho provato tutti Volumi Persistenti. Utilizza l'opzione migliore che fa per te. Storicamente, una piccola parte dei servizi ha bisogno di volumi RWX, e per questa esigenza si è iniziato a utilizzare l'archiviazione NFS. Economico e… sufficiente. Certo, abbiamo avuto le nostre difficoltà — ma abbiamo imparato a ottimizzarlo, e ora non abbiamo più mal di testa. E se possibile, passa a un'archiviazione a oggetti S3.
3. Raccogli immagini ottimizzate

È consigliabile utilizzare immagini ottimizzate per container, in modo che Kubernetes possa recuperarle più rapidamente ed eseguirle in modo più efficiente.
L'ottimizzazione significa che le immagini:
contengono solo una singola applicazione o svolgono solo una funzione;
sono di dimensioni ridotte, poiché le immagini più grandi si trasferiscono peggio sulla rete;
hanno endpoint per il controllo della salute e della prontezza, tramite i quali Kubernetes può intraprendere azioni in caso di inattività;
utilizzano sistemi operativi friendly per i container (come Alpine o CoreOS), che sono più resilienti agli errori di configurazione;
utilizzano build a più fasi, in modo da poter distribuire solo applicazioni compilate, anziché i relativi sorgenti.
Ci sono molti strumenti e servizi che permettono di controllare e ottimizzare le immagini al volo. È importante mantenerli sempre aggiornati e testati per la sicurezza. In questo modo ottieni:
Riduzione del carico di rete su tutto il cluster.
Diminuzione del tempo di avvio del contenitore.
Un minore volume del tuo intero registro Docker.
4. Utilizza la cache DNS

Parlando di carichi elevati, vivere senza ottimizzazione del sistema DNS del cluster può essere piuttosto difficile. In passato, gli sviluppatori di Kubernetes supportavano la loro soluzione kube-dns. È stata implementata anche da noi, ma questo software non è stato particolarmente ottimizzato e non forniva le prestazioni richieste, anche se la missione sembrava semplice. Successivamente, è emerso coredns, sul quale siamo passati e non abbiamo più avuto problemi; successivamente è diventato il servizio DNS predefinito in K8s. A un certo punto abbiamo raggiunto le 40.000 rps al sistema DNS, e anche questa soluzione ha cominciato a non bastare. Ma, per una felice coincidenza, è uscito Nodelocaldns, noto anche come cache locale del nodo, che è .
Perché lo usiamo? Nel kernel di Linux c'è un bug che, con più richieste tramite conntrack NAT su UDP, porta a una condizione di race per la scrittura nelle tabelle conntrack, causando la perdita di una parte del traffico attraverso il NAT (ogni passaggio attraverso il Service è un NAT). Nodelocaldns risolve questo problema eliminando il NAT e aggiornando la connessione a TCP con i DNS upstream, oltre a eseguire caching locale delle query DNS per gli upstream (incluso un breve caching negativo di 5 secondi).
5. Scala i pod orizzontalmente e verticalmente in modo automatico
Puoi dire con certezza che tutti i tuoi microservizi sono pronti per una crescita da due a tre volte del carico? Come allocare correttamente le risorse per le tue applicazioni? Mantenere in esecuzione un paio di pod oltre il carico di lavoro può risultare eccessivo, mentre operare al limite espone al rischio di inattività a causa di una crescita improvvisa del traffico sul servizio. La soluzione al giusto bilanciamento è fornita da servizi come e .
VPA consente di aumentare automaticamente le risorse richieste/limate dei tuoi container nel pod in base all'utilizzo effettivo. In che modo può esserti utile? Se hai pod che per qualche motivo non possono essere scalati orizzontalmente (il che non è del tutto affidabile), puoi provare a lasciare che il VPA gestisca le risorse. La sua caratteristica distintiva è il sistema di raccomandazioni basato su dati storici e attuali del metric-server, quindi, se non desideri modificare automaticamente richieste/lime, puoi semplicemente monitorare le risorse raccomandate per i tuoi container e ottimizzare le impostazioni per risparmiare CPU e memoria nel cluster.
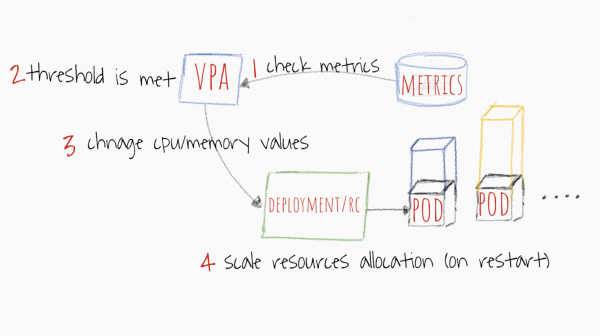 Immagine presa da https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Immagine presa da https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Il pianificatore in Kubernetes si basa sempre sui requests. Qualunque valore tu inserisca, il pianificatore cercherà un nodo adatto in base a esso. I valori dei limits servono al kubelet per comprendere quando limitare o terminare un pod. E poiché l'unico parametro importante è il valore dei requests, il VPA lavorerà con esso. Ogni volta che definisci il ridimensionamento verticale di un'applicazione, stai specificando quale dovrebbe essere il requests. E cosa succede ai limits? Questo parametro sarà anche scalato proporzionalmente.
Ad esempio, ecco le impostazioni tipiche di un pod:
resources:
requests:
memory: 250Mi
cpu: 200m
limits:
memory: 500Mi
cpu: 350mIl meccanismo di raccomandazione determina che la tua applicazione ha bisogno di 300m di CPU e 500Mi per funzionare correttamente. Riceverai queste impostazioni:
resources:
requests:
memory: 500Mi
cpu: 300m
limits:
memory: 1000Mi
cpu: 525mCome accennato in precedenza, questo è un ridimensionamento proporzionale basato sul rapporto requests/limits nel manifesto:
CPU: 200m → 300m: rapporto 1:1.75;
Memory: 250Mi → 500Mi: rapporto 1:2.
Per quanto riguarda HPA, qui qui rende il meccanismo di funzionamento più trasparente. Vengono stabiliti i valori di soglia delle metriche, come ad esempio della CPU e della memoria, e se il valore medio di tutte le repliche supera la soglia, l'applicazione viene scalata di +1 pod fino a quando il valore non scende sotto la soglia, o fino a quando non viene raggiunto il numero massimo di repliche.
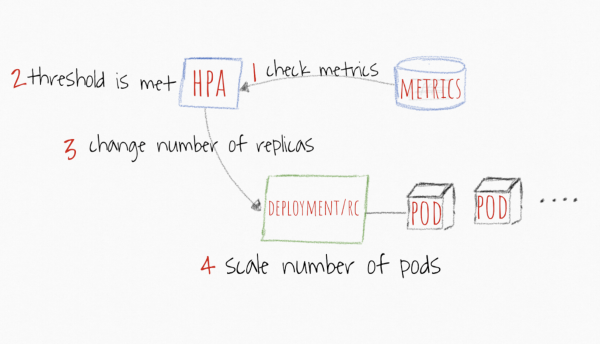 Immagine presa da https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Immagine presa da https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Oltre alle metriche standard come CPU e memoria, puoi configurare soglie per le tue metriche personalizzate da Prometheus e lavorarci, se ritieni che sia la definizione più accurata per decidere quando scalare la tua applicazione. Una volta che l'applicazione si stabilizza al di sotto del limite di metrica impostato, l'HPA inizierà a scalare i pod verso il basso fino al numero minimo di repliche o fino a quando il carico soddisferà la soglia impostata.
6. Non dimenticare l'Node Affinity e il Pod Affinity

Non tutti i nodi funzionano su hardware identico, né tutti i pod devono eseguire applicazioni intensive in termini di calcolo. Kubernetes consente di definire la specializzazione dei nodi e dei pod attraverso Node Affinity e Pod Affinity.
Se hai nodi adatti per operazioni ad alta intensità di calcolo, per massimizzare l'efficienza è meglio associare le applicazioni ai nodi corrispondenti. A tal fine, utilizza nodeSelector con un'etichetta del nodo.
Supponiamo che tu abbia due nodi: uno con CPUType=HIGHFREQ e un numero elevato di core veloci, l'altro con MemoryType=HIGHMEMORY un'elevata quantità di memoria e prestazioni superiori. La soluzione più semplice è assegnare il deployment del pod al nodo HIGHFREQ, aggiungendo nella sezione spec un selettore come questo:
…
nodeSelector:
CPUType: HIGHFREQUn modo più costoso e specifico per farlo è utilizzare nodeAffinity nel campo affinity nella sezione spec. Ci sono due opzioni:
requiredDuringSchedulingIgnoredDuringExecution: impostazione rigida (il planner farà il deployment dei pod solo su nodi specifici (e non altrove));preferredDuringSchedulingIgnoredDuringExecution: impostazione morbida (il planner cercherà di fare il deployment su nodi specifici e, se non ci riesce, proverà su un altro nodo disponibile).
Puoi definire una certa sintassi per gestire le etichette dei nodi, ad esempio, In, NotIn, Exists, DoesNotExist, Gt o Lt. Tuttavia, ricorda che metodi complessi in lunghe liste di etichette rallenteranno il processo decisionale in situazioni critiche. In altre parole, non complicare.
Come accennato in precedenza, Kubernetes consente di definire l'affinità dei pod. Ciò significa che puoi fare in modo che determinati pod lavorino insieme ad altri pod nella stessa zona di disponibilità (rilevante per i cloud) o nodi.
In podAffinity campi affinity nella sezione spec sono disponibili gli stessi campi che nel caso di nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution e preferredDuringSchedulingIgnoredDuringExecution. L'unica differenza è che matchExpressions collegherà i pod al nodo su cui è già in esecuzione un pod con quella specifica etichetta.
Inoltre, Kubernetes offre il campo podAntiAffinity, che, al contrario, non collega il pod a un nodo con determinati pod.
Per quanto riguarda le espressioni nodeAffinity si possono dare gli stessi consigli: cerca di mantenere la semplicità e la coerenza delle regole, non cercare di sovraccaricare la specifica dei pod con un insieme complesso di regole. È molto facile creare una regola che non soddisfi i requisiti del cluster, creando un carico extra per lo scheduler e riducendo le prestazioni complessive.
7. Taints & Tolerations
C'è un altro modo per gestire lo scheduler. Se hai un grande cluster con centinaia di nodi e migliaia di microservizi, è molto difficile non permettere a determinati pod di essere posizionati su nodi specifici.
A questo ci aiuta il meccanismo dei taint — regole restrittive. Ad esempio, in determinati scenari puoi vietare a determinati nodi di eseguire pod al loro interno. Per applicare un taint a un nodo specifico, devi utilizzare l'opzione taint in kubectl. Specifica la chiave e il valore, e poi il taint come NoSchedule o NoExecute:
$ kubectl taint nodes node10 node-role.kubernetes.io/ingress=true:NoScheduleVale la pena notare che il meccanismo dei taint supporta tre effetti principali: NoSchedule, NoExecute e PreferNoSchedule.
NoSchedulesignifica che finché nella specifica del pod non c'è una registrazione corrispondentetolerations, non potrà essere distribuito su un nodo (in questo esempionode10).PreferNoSchedule— una versione semplificataNoSchedule. In questo caso, lo scheduler cercherà di non distribuire pod che non hanno una registrazione corrispondentetolerationssu quel nodo, ma non è un vincolo rigido. Se non ci sono risorse nel cluster, i pod inizieranno a essere distribuiti su quel nodo.NoExecute— questo effetto avvia un'evacuazione immediata dei pod che non hanno una registrazione corrispondente.tolerations.
È interessante notare che un comportamento del genere può essere annullato tramite il meccanismo delle tolleranze. Questo è utile quando c'è un nodo "vietato" e hai bisogno di posizionare solo servizi infrastrutturali su di esso. Come farlo? Consentire solo i pod per i quali esiste una tolleranza appropriata.
Ecco come apparirà la specifica del pod:
spec:
tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Equal"
value: "true"
effect: "NoSchedule"Ciò non significa che al prossimo ridistribuzione il pod andrà su questo nodo; non si tratta di un meccanismo di affinità del nodo e nodeSelector. Ma combinando più funzionalità, puoi ottenere una configurazione molto flessibile per lo scheduler.
8. Configura la priorità di distribuzione dei pod
Il fatto che hai configurato il vincolo dei pod ai nodi non significa che tutti i pod debbano essere gestiti con la stessa priorità. Ad esempio, potresti voler distribuire alcuni pod prima degli altri.
Kubernetes offre vari modi per configurare la priorità dei pod (Pod Priority and Preemption). La configurazione consiste in diverse parti: l'oggetto PriorityClass e la descrizione del campo priorityClassName nella specifica del pod. Consideriamo un esempio:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 99999
globalDefault: false
description: "Questa classe di priorità dovrebbe essere utilizzata solo per i pod molto importanti"Creiamo PriorityClass, assegnandole un nome, una descrizione e un valore. Più alto value, maggiore è la priorità. Il valore può essere qualsiasi numero intero a 32 bit, minore o uguale a 1.000.000.000. Valori più elevati sono riservati per i pod system critici, che di solito non possono essere espulsi. L'espulsione avverrà solo se non c'è spazio per l'esecuzione del pod ad alta priorità, allora alcuni pod di un certo nodo verranno evacuati. Se questo meccanismo è troppo rigido per te, puoi aggiungere l'opzione preemptionPolicy: Never, e allora non ci sarà espulsione, il pod sarà il primo in coda e attenderà che il pianificatore trovi risorse disponibili per lui.
Successivamente creiamo un pod, nel quale specifichiamo il nome priorityClassName:
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
priorityClassName: high-priority
È possibile creare un numero illimitato di classi di priorità, anche se si consiglia di non esagerare (ad esempio, limitarsi a priorità bassa, media e alta).
In questo modo, se necessario, potrai aumentare l'efficienza del dispiegamento di servizi critici come nginx-ingress-controller, coredns, ecc.
9. Ottimizza il cluster ETCD

L'ETCD può essere considerato il cervello dell'intero cluster. È molto importante mantenere questa base di dati ad un alto livello operativo, in quanto da essa dipende la velocità delle operazioni nel "Kube". Una soluzione piuttosto standard e comunque valida è mantenere il cluster ETCD sui nodi master, per avere una latenza minima rispetto al kube-apiserver. Se ciò non è possibile, colloca l'ETCD il più vicino possibile, assicurandoti di avere una buona larghezza di banda tra i nodi. Fai attenzione anche a quante nodi ETCD possono essere rimossi senza danneggiare il cluster.
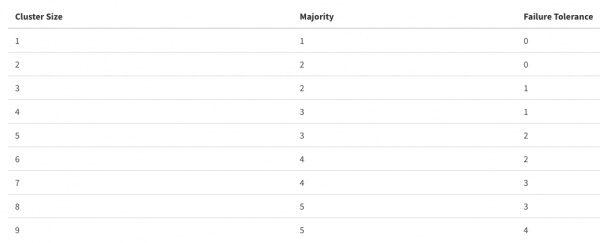
Tieni presente che un numero eccessivo di partecipanti nel cluster può aumentare la tolleranza ai guasti a spese delle prestazioni; tutto deve essere mantenuto in equilibrio.
Per quanto riguarda la configurazione del servizio, ci sono poche raccomandazioni:
Avere una buona hardware, in base alle dimensioni del cluster (puoi leggere ).
Regolare alcuni parametri se hai distribuito il cluster tra un paio di datacenter, oppure se la tua rete e i dischi lasciano a desiderare (puoi leggere ).
Conclusione
In questo articolo vengono descritti i punti che il nostro team cerca di seguire. Non è una descrizione passo-passo delle azioni, ma piuttosto opzioni che possono essere utili per ottimizzare i costi operativi del cluster. È chiaro che ogni cluster è unico e le soluzioni di configurazione possono variare notevolmente, quindi sarebbe interessante ricevere il tuo feedback: come monitori il tuo cluster Kubernetes e quali strumenti utilizzi per migliorarne le prestazioni. Condividi la tua esperienza nei commenti, sarà interessante conoscerla.
Fonte: habr.com
