


Introduzione
Il sistema informativo, dal punto di vista dell'utente, è ben definito nella norma GOST RV 51987 come «sistema automatizzato il cui risultato è la presentazione di informazioni in uscita per un uso successivo». Se consideriamo la struttura interna, in sostanza qualsiasi SI è un sistema di algoritmi interconnessi implementati nel codice. In un senso ampio, secondo il teorema di Turing-Church, un algoritmo (e di conseguenza un SI) esegue la trasformazione di un insieme di dati in ingresso in un insieme di dati in uscita.
Si può dire che il significato dell'esistenza di un sistema informativo risieda proprio nella trasformazione dei dati in ingresso. Di conseguenza, il valore del SI e dell'intero complesso di SI è determinato attraverso il valore dei dati in ingresso e in uscita.
Da ciò, la progettazione deve iniziare prendendo come base i dati, adattando l'architettura e i metodi alla struttura e all'importanza dei dati.
Dati memorizzati
Una fase chiave nella preparazione alla progettazione è l'ottenimento delle caratteristiche di tutti i set di dati previsti per l'elaborazione e la memorizzazione. Queste caratteristiche includono:
— Volume dei dati;
— Informazioni sul ciclo di vita dei dati (incremento dei nuovi dati, durata, gestione dei dati obsoleti);
— Classificazione dei dati dal punto di vista dell'impatto sul business principale dell'azienda (trifoglio riservatezza, integrità, disponibilità) insieme agli indicatori finanziari (es. costo della perdita di dati nell'ultima ora);
— Geografia del trattamento dei dati (posizione fisica dei sistemi di trattamento);
— Requisiti normativi per ciascuna classe di dati (es. legge federale 152, PCI DSS).
Sistemi informativi
I dati non solo vengono memorizzati, ma anche elaborati (trasformati) dai sistemi informativi. Il passaggio successivo dopo aver ottenuto le caratteristiche dei dati è un'inventarizzazione quanto più completa possibile dei sistemi informativi, delle loro caratteristiche architettoniche, delle dipendenze reciproche e dei requisiti infrastrutturali in unità nominali per quattro tipi di risorse:
— Potenza di calcolo del processore;
— Dimensione della memoria RAM;
— Requisiti relativi alla dimensione e alle prestazioni del sistema di archiviazione dati;
— Requisiti per la rete di trasmissione dati (canali esterni, canali tra i componenti dei sistemi informativi).
I requisiti devono essere specificati per ogni servizio/microservizio all'interno del sistema informativo.
È fondamentale sottolineare che per una progettazione corretta è necessario disporre di dati sull'impatto del sistema informativo sul core business dell'azienda, in termini di costo di inattività del sistema informativo (rubli all'ora).
Modello di minacce
Deve necessariamente essere presente un modello formale di minacce da cui si intende proteggere dati/servizi. Questo modello di minacce include non solo aspetti di riservatezza, ma anche di integrità e disponibilità. Ad esempio:
— Guasto di un server fisico;
— Guasto di uno switch top-of-the-rack;
— Interruzione del canale ottico di comunicazione tra i data center;
— Guasto completo di uno storage di rete.
In alcuni casi, i modelli di minacce vengono redatti non solo per componenti infrastrutturali, ma anche per sistemi informativi specifici o per i loro componenti, come ad esempio il guasto di un SGBD con distruzione logica della struttura dei dati.
Tutte le decisioni all'interno del progetto per proteggersi da minacce non descritte sono superflue.
Requisiti dei regolatori
Se i dati trattati rientrano sotto regole speciali stabilite dai regolatori, è obbligatoria l'informazione sui set di dati e le regole di elaborazione / conservazione.
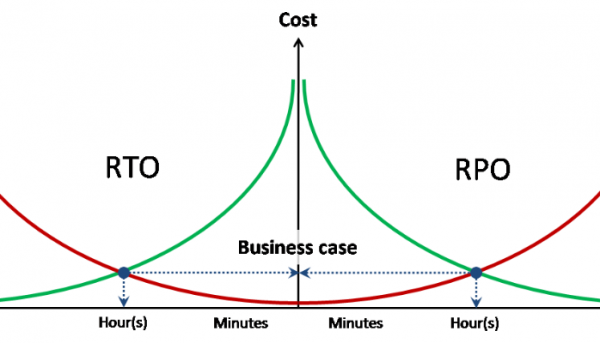
Obiettivi RPO / RTO
La progettazione di qualsiasi tipo di protezione richiede la presenza di indicatori di perdita dati target e tempo di ripristino del servizio per ciascuna delle minacce descritte.
Ideale sarebbe che RPO e RTO avessero costi associati alla perdita di dati e ai fermi nell'unità di tempo.
Separazione in pool di risorse
Dopo aver raccolto tutte le informazioni iniziali, il primo passo consiste nella raggruppamento dei set di dati e dei sistemi informativi in pool, in base ai modelli di minaccia e ai requisiti dei regolatori. Viene definito il tipo di separazione dei vari pool: a livello software, nel sistema operativo, oppure fisicamente.
Esempi:
— Il contorno che gestisce i dati personali è completamente isolato fisicamente dagli altri sistemi;
— Le copie di riserva sono conservate su uno storage dedicato separato.
In questo caso, i pool possono avere una parziale indipendenza, ad esempio, si definiscono due pool di risorse computazionali (potenza della CPU + memoria RAM) che utilizzano un unico pool di storage e un unico pool di risorse di rete.
Potenza della CPU

Le esigenze astratte di potenza della CPU di un datacenter virtualizzato vengono misurate in termini di numero di processori virtuali (vCPU) e del loro coefficiente di consolidamento sui processori fisici (pCPU). In questo caso specifico, 1 pCPU = 1 core fisico della CPU (senza considerare l'Hyper-Threading). Il numero di vCPU viene sommato su tutti i pool di risorse definiti (ognuno dei quali può avere il proprio coefficiente di consolidamento).
Il coefficiente di consolidamento per sistemi ad alto carico viene ottenuto empiricamente, basandosi sull'infrastruttura esistente, oppure durante l'installazione pilota e i test di carico. Per i sistemi a basso carico si applicano le «best practice». In particolare, VMware indica un coefficiente medio di 8:1.
Memoria RAM
Il fabbisogno totale di memoria RAM viene calcolato tramite semplice somma. L'uso della sovrascrittura della memoria non è raccomandato.
Risorse di archiviazione
I requisiti delle risorse di archiviazione sono ottenuti sommando semplicemente tutti i pool per volume e prestazioni.
I requisiti prestazionali sono espressi in IOPS insieme al rapporto medio di lettura/scrittura e, se necessario, alla latenza massima.
I requisiti per la qualità del servizio (QoS) devono essere specificati separatamente per specifici pool o sistemi.
Risorse di rete
I requisiti della rete sono ottenuti sommando semplicemente tutti i pool di larghezza di banda.
I requisiti di QoS e latenza (RTT) devono essere specificati separatamente per specifici pool o sistemi.
Nell'ambito dei requisiti per le risorse di rete devono essere indicate anche le necessità di isolamento e/o crittografia del traffico e i meccanismi preferiti (802.1q, IPSec, ecc.)
Scelta dell'architettura
In questo documento non viene considerata alcuna scelta diversa dall'architettura x86 e dalla virtualizzazione server al 100%. Pertanto, la scelta dell'architettura del sistema di calcolo si riduce alla scelta della piattaforma di virtualizzazione del server, del fattore di forma dei server e dei requisiti generali per la configurazione dei server.
Un aspetto chiave della scelta è la certezza nell'applicazione dell'approccio classico con separazione delle funzioni di elaborazione, archiviazione e trasmissione dei dati o convergente.
Architettura classica implica l'uso di sistemi di archiviazione e trasmissione dei dati esterni intelligenti, mentre i server contribuiscono al pool generale delle risorse fisiche solo con potenza di elaborazione e memoria RAM. In alcuni casi, i server diventano completamente anonimi, privi non solo di dischi propri, ma anche di un identificatore di sistema. In questo caso viene utilizzato il boot del sistema operativo o dell'ipervisore da dispositivi flash integrati o da un sistema di archiviazione dati esterno (boot from SAN).
Nell'architettura classica, la scelta tra blade e rack è basata principalmente sui seguenti principi:
— Efficienza economica (in media, i server rack sono più economici);
— Densità computazionale (le blade hanno una densità maggiore);
— Consumo energetico e dissipazione di calore (le blade hanno un'efficienza maggiore per unità);
— Scalabilità e gestibilità (le blade richiedono in generale meno sforzi per grandi installazioni);
— Uso di schede di espansione (per le blade c'è una scelta molto limitata).
Architettura convergente (nota anche come iperconvergente) prevede la combinazione di funzioni di elaborazione e archiviazione dei dati, portando all'uso di dischi locali nei server e conseguentemente all'abbandono del fattore di forma delle tradizionali blade. Per i sistemi convergenti vengono utilizzati server rack o sistemi cluster che combinano in un'unica scocca più server blade e dischi locali.
CPU / Memoria
Per un corretto calcolo della configurazione è necessario comprendere il tipo di carico per l'ambiente o per ciascuno dei cluster indipendenti.
Limitato dalla CPU – ambiente limitato dalla potenza di elaborazione della CPU. Aggiungere memoria RAM non cambia nulla in termini di prestazioni (numero di VM sul server).
Limitato dalla memoria – ambiente con RAM limitata. Maggiore quantità di RAM sul server consente di avviare un numero maggiore di VM sul server.
GB / MHz (GB / pCPU) – il rapporto medio di consumo di questa specifica carico di lavoro rispetto alla potenza del processore. Può essere usato per calcolare la quantità necessaria di memoria a una data prestazione e viceversa.
Calcolo della configurazione del server

Per iniziare, è necessario determinare tutti i tipi di carico e decidere se unire o separare diversi pool computazionali in vari cluster.
Successivamente, per ciascuno dei cluster definiti, si determina il rapporto GB / MHz in base a un carico noto in anticipo. Se il carico non è noto in anticipo, ma si ha un'idea approssimativa del livello di utilizzo della potenza del processore, si possono usare coefficienti standard vCPU:pCPU per convertire i requisiti dei pool in fisici.
Per ciascun cluster, si divide la somma delle richieste dell'pool vCPU per il coefficiente:
vCPUsomma / vCPU:pCPU = pCUsomma – numero richiesto di core fisici
pCUsomma / 1.25 = pCUht – numero di core corretto per l'Hyper-Threading
Supponiamo di dover calcolare un cluster con 190 core / 3,5 TB di RAM. Consideriamo un utilizzo target del 50% della potenza di elaborazione e del 75% della memoria operativa.
pCPU
190
Utilizzo CPU
50%
Mem
3500
Utilizzo Mem
75%
Socket
Core
Srv / CPU
Srv Mem
Srv / Mem
2
6
25,3
128
36,5
2
8
19,0
192
24,3
2
10
15,2
256
18,2
2
14
10,9
384
12,2
2
18
8,4
512
9,1
In questo caso si utilizza sempre l'arrotondamento all'intero superiore più vicino (=ROUNDUP(A1;0)).
Dalla tabella è evidente che esistono diverse configurazioni di server bilanciate rispetto agli obiettivi di performance:
— 26 server 2*6c / 192 GB
— 19 server 2*10c / 256 GB
— 10 server 2*18c / 512 GB
La scelta tra queste configurazioni deve essere fatta tenendo conto di ulteriori fattori, come ad esempio il pacchetto termico e il raffreddamento disponibile, i server già in uso o il costo.
Caratteristiche della scelta della configurazione del server
VM larghe. In caso di necessità di posizionare VM larghe (comparabili con 1 nodo NUMA e oltre), è consigliabile, se possibile, scegliere un server con una configurazione che consenta a tali VM di rimanere all'interno del nodo NUMA. Con un grande numero di VM larghe, sussiste il rischio di frammentazione delle risorse del cluster, e in questo caso si scelgono server che permettano di posizionare le VM larghe il più densamente possibile.
Dimensione del dominio di un singolo punto di errore.
La scelta della dimensione del server si basa anche sul principio di minimizzazione del dominio di un singolo punto di errore. Ad esempio, nella scelta tra:
— 3 x 4*10c / 512 GB
— 6 x 2*10c / 256 GB
Con altre condizioni uguali, è necessario scegliere la seconda opzione, poiché, in caso di guasto di un server (o di manutenzione), non si perde il 33% delle risorse del cluster, ma solo il 17%. Allo stesso modo, il numero di VM e IS colpite dall'incidente viene dimezzato.
Calcolo delle prestazioni della SAN classica

La SAN classica viene sempre calcolata secondo lo scenario peggiore (worst case scenario), escludendo l'influenza della cache di sistema e l'ottimizzazione delle operazioni.
Come indicatori di base delle prestazioni prendiamo la prestazione meccanica dei dischi (IOPSdisk):
— 7.2k – 75 IOPS
— 10k – 125 IOPS
— 15k – 175 IOPS
Successivamente, il numero di dischi nel pool di dischi viene calcolato secondo la seguente formula: = TotalIOPS * ( RW + (1 –RW) * RAIDPen) / IOPSdisk. Dove:
— TotalIOPS – prestazione totale richiesta in IOPS dal pool di dischi
— RW – percentuale di operazioni di lettura
— RAIDpen – penalità RAID per il livello RAID scelto
Maggiore informazione sui RAID e sulla penalità RAID è disponibile qui — e e
Sulla base del numero di dischi ottenuti, vengono calcolate le opzioni disponibili che soddisfano i requisiti di capacità di archiviazione, comprese le opzioni con archiviazione multilivello.
Il calcolo dei sistemi che utilizzano SSD come livello di archiviazione viene considerato separatamente.
Caratteristiche del calcolo dei sistemi con Flash Cache.
Flash Cache è il termine generico per tutte le tecnologie proprietarie che utilizzano la memoria flash come cache di secondo livello. Quando si utilizza la flash cache, lo storage viene generalmente calcolato per sostenere il carico stabilito sui dischi magnetici, mentre il picco è gestito dalla cache.
È importante comprendere il profilo del carico e il grado di localizzazione delle richieste ai blocchi dei volumi di archiviazione. La flash cache è una tecnologia per carichi con alta localizzazione delle richieste, e praticamente non è applicabile per volumi uniformemente caricati (come ad esempio nei sistemi di analisi).
Calcolo dei sistemi ibridi low-end / mid-range.
I sistemi ibridi di fascia bassa e media utilizzano lo storage multistrato con il movimento dei dati tra i livelli programmato. In questo contesto, la dimensione del blocco di storage multistrato nei migliori modelli è di 256 MB. Queste caratteristiche non permettono di considerare la tecnologia dello storage multistrato come una tecnologia per migliorare le prestazioni, come erroneamente pensano in molti. Lo storage multistrato nei sistemi di fascia bassa e media è una tecnologia di ottimizzazione dei costi di storage per sistemi con carico di lavoro chiaramente irregolare.
Per lo storage multistrato, si calcola principalmente la prestazione del livello superiore, mentre il livello inferiore è considerato solo come contributo alla capacità di storage mancante. Per un sistema ibrido a multistrato è necessario l'uso della tecnologia di cache flash per il pool multistrato al fine di compensare il calo di prestazioni per i dati che si scaldano improvvisamente dal livello inferiore.
Utilizzo di SSD nel pool di dischi multistrato

L'uso degli SSD in un pool di dischi a più livelli varia a seconda delle specificità di implementazione degli algoritmi di cache flash di questo produttore.
La pratica comune della politica di archiviazione per un pool di dischi con SSD è SSD first.
Flash Cache in sola lettura. Per la cache flash in sola lettura, il livello di archiviazione su SSD si attiva quando vi è una significativa localizzazione delle operazioni di scrittura al di fuori della cache.
Flash Cache in lettura/scrittura. Nel caso della cache flash in scrittura, prima viene impostato il massimo volume di cache, e il livello di archiviazione su SSD si attiva solo quando la dimensione della cache non è sufficiente a gestire l'intero carico localizzato.
Il calcolo delle prestazioni degli SSD e della cache viene effettuato ogni volta in base alle raccomandazioni del produttore, ma sempre per il worst case.
Fonte: habr.com
