

Я продолжаю свой рассказ о том, как подружить Exchange и ELK (начало ). Напомню, что эта комбинация способна без колебаний обрабатывать очень большое количество логов. На это раз мы поговорим о том, как наладить работу Exchange с компонентами Logstash и Kibana.
Logstash в стеке ELK используется для интеллектуальной обработки логов и их подготовки к размещению в Elastic в виде документов, на основе которых удобно строить различные визуализации в Kibana.
Installazione
Состоит из двух этапов:
- Установка и настройка пакета OpenJDK.
- Установка и настройка пакета Logstash.
Установка и настройка пакета OpenJDK
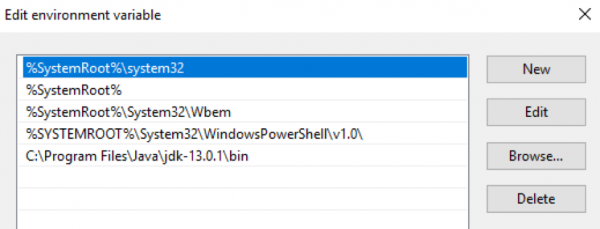
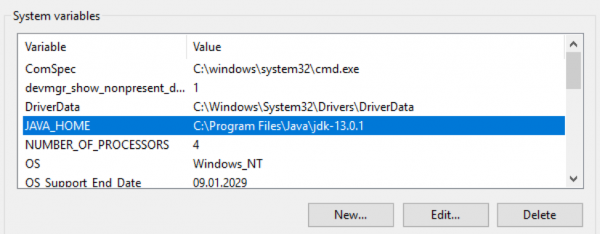
Пакет OpenJDK необходимо скачать и распаковать в определённую директорию. Затем путь до этой директории необходимо внести в переменные $env:Path и $env:JAVA_HOME операционной системы Windows:
Проверим версию Java:
PS C:> java -version
openjdk version "13.0.1" 2019-10-15
OpenJDK Runtime Environment (build 13.0.1+9)
OpenJDK 64-Bit Server VM (build 13.0.1+9, mixed mode, sharing)
Установка и настройка пакета Logstash
Файл-архив с дистрибутивом Logstash скачайте . Архив нужно распаковать в корень диска. Распаковывать в папку C:Program Files не стоит, Logstash откажется нормально запускаться. Затем необходимо внести в файл jvm.options правки, отвечающие за выделение оперативной памяти для процесса Java. Рекомендую указать половину оперативной памяти сервера. Если у него на борту 16 Гб оперативки, то ключи по умолчанию:
-Xms1g
-Xmx1g
необходимо заменить на:
-Xms8g
-Xmx8g
Кроме этого, целесообразно закомментировать строку -XX:+UseConcMarkSweepGC. Подробнее об этом . Следующий шаг — создание конфигурации по умолчанию в файле logstash.conf:
input {
stdin{}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
При использовании этой конфигурации Logstash считывает данные из консоли, пропускает через пустой фильтр и выводит обратно в консоль. Применение этой конфигурации позволит проверить работоспособность Logstash. Для этого запустим его в интерактивном режиме:
PS C:...bin> .logstash.bat -f .logstash.conf
...
[2019-12-19T11:15:27,769][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
The stdin plugin is now waiting for input:
[2019-12-19T11:15:27,847][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-12-19T11:15:28,113][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash успешно запустился на порту 9600.
Финальный шаг установки: запуск Logstash в виде сервиса Windows. Это можно сделать, например, с помощью пакета :
PS C:...bin> .nssm.exe install logstash
Service "logstash" installed successfully!
Affidabilità
Сохранность логов при передаче с исходного сервера обеспечивается механизмом Persistent Queues.
Как работает
Схема расположения очередей в процессе обработки логов: input → queue → filter + output.
Плагин input получает данные от источника логов, записывает их в очередь и отправляет источнику подтверждение получения данных.
Сообщения из очереди обрабатываются Logstash, проходят фильтр и плагин output. При получении от output подтверждения отправки лога Logstash удаляет обработанный лог из очереди. Если Logstash останавливается, то все необработанные сообщения и сообщения, по которым не получено подтверждение об отправке, остаются в очереди, и Logstash продолжит их обработку при следующем запуске.
Impostazione
Регулируется ключами в файле C:Logstashconfiglogstash.yml:
queue.type: (возможные значения —persistedememory (default)).path.queue: (путь до папки с файлами очередей, которые по умолчанию хранятся в C:Logstashqueue).queue.page_capacity: (максимальный размер страницы очереди, значение по умолчанию — 64mb).queue.drain: (true/false — включает/выключает остановку обработки очереди перед выключением Logstash. Не рекомендую включать, потому что это прямо скажется на скорости выключения сервера).queue.max_events: (максимально число событий в очереди, по умолчанию — 0 (не ограничено)).queue.max_bytes: (максимальный размер очереди в байтах, по умолчанию — 1024mb (1gb)).
Если настроены queue.max_events e queue.max_bytes, то сообщения перестают приниматься в очередь при достижении значения любой из этих настроек. Подробнее про Persistent Queues рассказано .
Пример части logstash.yml, отвечающей за настройку очереди:
queue.type: persisted
queue.max_bytes: 10gb
Impostazione
Конфигурация Logstash обычно состоит из трёх частей, отвечающих за разные фазы обработки входящий логов: приём (секция input), парсинг (секция filter) и отправка в Elastic (секция output). Ниже мы подробнее рассмотрим каждую из них.
Ingresso
Входящий поток с сырыми логами принимаем от агентов filebeat. Именно этот плагин мы и указываем в секции input:
input {
beats {
port => 5044
}
}
После такой настройки Logstash начинает прослушивать порт 5044, и при получении логов обрабатывает их согласно настройкам секции filter. При необходимости можно канал получения логов от filebit завернуть в SSL. Подробнее о настройках плагина beats написано .
Filter
Все интересные для обработки текстовые логи, которые генерирует Exchange, имеют csv-формат с описанными в самом файле логов полями. Для парсинга csv-записей Logstash предлагает нам три плагина: , csv и grok. Первый — самый , но справляется с парсингом только самых простых логов.
Например, следующую запись он разобьёт на две (из-за наличия внутри поля запятой), из-за чего лог будет разобран неправильно:
…,"MDB:GUID1, Mailbox:GUID2, Event:526545791, MessageClass:IPM.Note, CreationTime:2020-05-15T12:01:56.457Z, ClientType:MOMT, SubmissionAssistant:MailboxTransportSubmissionEmailAssistant",…
Его можно использовать при парсинге логов, например, IIS. В этом случае секция filter может выглядеть следующим образом:
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
}
}
}
Конфигурация Logstash позволяет использовать , поэтому мы в плагин dissect можем направить только логи, которые были помечены filebeat тэгом IIS. Внутри плагина мы сопоставляем значения полей с их названиями, удаляем исходное поле message, которое содержало запись из лога, и можем добавить произвольное поле, которое будет, например, содержать имя приложения из которого мы собираем логи.
В случае с логами трэкинга лучше использовать плагин csv, он умеет корректно обрабатывать сложные поля:
filter {
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
}
Внутри плагина мы сопоставляем значения полей с их названиями, удаляем исходное поле message (а также поля tenant-id e schema-version), которое содержало запись из лога, и можем добавить произвольное поле, которое будет, например, содержать имя приложения из которого мы собираем логи.
На выходе из стадии фильтрации мы получим документы в первом приближении готовые к визуализации в Kibana. Не хватать нам будет следующего:
- Числовые поля будут распознаны как текст, что не позволяет выполнять операции с ними. А именно, поля
time-takenлога IIS, а также поляrecipient-countetotal-bitesлога Tracking. - Стандартный временной штамп документа будет содержать время обработки лога, а не время записи его на стороне сервера.
- Campo
recipient-addressбудет выглядеть одной стройкой, что не позволяет проводить анализ с подсчётом получателей писем.
Настало время добавить немного магии в процесс обработки логов.
Конвертация числовых полей
Плагин dissect имеет опцию convert_datatype, которую можно использовать для конвертации текстового поля в цифровой формат. Например, так:
dissect {
…
convert_datatype => { "time-taken" => "int" }
…
}
Стоит помнить, что этот метод подходит только в том случае, если поле точно будет содержать строку. Null-значения из полей опция не обрабатывает и вываливается в исключение.
Для логов трэкинга аналогичный метод convert лучше не использовать, так как поля recipient-count e total-bites могут быть пустыми. Для конвертации этих полей лучше использовать плагин :
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
}
Разбиение recipient_address на отдельных получателей
Эту задачу можно также решить с помощью плагина mutate:
mutate {
split => ["recipient_address", ";"]
}
Изменяем timestamp
В случае с логами трэкинга задача очень просто решается плагином , который поможет прописать в поле timestamp дату и время в нужном формате из поля date-time:
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
В случае с логами IIS нам будет необходимо объединить данные полей date e ora с помощью плагина mutate, прописать нужную нам временную зону и поместить этот временной штамп в timestamp с помощью плагина date:
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
Uscita
Секция output используется для отправки обработанных логов в приёмник логов. В случае отправки напрямую в Elastic используется плагин , в котором указывается адрес сервера и шаблон имени индекса для отправки сформированного документа:
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Configurazione finale
Итоговая конфигурация будет выглядеть следующим образом:
input {
beats {
port => 5044
}
}
filter {
if "IIS" in [tags] {
dissect {
mapping => {
"message" => "%{date} %{time} %{s-ip} %{cs-method} %{cs-uri-stem} %{cs-uri-query} %{s-port} %{cs-username} %{c-ip} %{cs(User-Agent)} %{cs(Referer)} %{sc-status} %{sc-substatus} %{sc-win32-status} %{time-taken}"
}
remove_field => ["message"]
add_field => { "application" => "exchange" }
convert_datatype => { "time-taken" => "int" }
}
mutate {
add_field => { "data-time" => "%{date} %{time}" }
remove_field => [ "date", "time" ]
}
date {
match => [ "data-time", "YYYY-MM-dd HH:mm:ss" ]
timezone => "UTC"
remove_field => [ "data-time" ]
}
}
if "Tracking" in [tags] {
csv {
columns => ["date-time","client-ip","client-hostname","server-ip","server-hostname","source-context","connector-id","source","event-id","internal-message-id","message-id","network-message-id","recipient-address","recipient-status","total-bytes","recipient-count","related-recipient-address","reference","message-subject","sender-address","return-path","message-info","directionality","tenant-id","original-client-ip","original-server-ip","custom-data","transport-traffic-type","log-id","schema-version"]
remove_field => ["message", "tenant-id", "schema-version"]
add_field => { "application" => "exchange" }
}
mutate {
convert => [ "total-bytes", "integer" ]
convert => [ "recipient-count", "integer" ]
split => ["recipient_address", ";"]
}
date {
match => [ "date-time", "ISO8601" ]
timezone => "Europe/Moscow"
remove_field => [ "date-time" ]
}
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200", "127.0.0.2:9200"]
manage_template => false
index => "Exchange-%{+YYYY.MM.dd}"
}
}
Link utili:
Fonte: habr.com
