

Уважаемое сообщество, эта статья будет посвящена эффективному хранению и выдаче сотен миллионов маленьких файлов. На данном этапе предлагается конечное решение для POSIX совместимых файловых систем с полноценной поддержкой блокировок, в том числе кластерных, и вроде бы даже уже без костылей.
Поэтому для этой цели я написал свой собственный специализированный сервер.
По ходу реализации этой задачи удалось решить основную проблему, попутно добиться экономии дискового пространства и оперативной памяти, которую нещадно потребляла наша кластерная файловая система. Собственно такое количество файлов вредно для любой кластерной файловой системы.
Идея такая:
Простыми словами, через сервер заливают мелкие файлы, они сохраняются напрямую в архив, и так же считываются из него, а большие файлы кладутся рядом. Схема: 1 папка = 1 архив, итого имеем несколько миллионов архивов с мелкими файлами, а не несколько сотен миллионов файлов. И все это реализовано полноценно, без всяких скриптов и раскладывания файлов по tar/zip архивам.
Постараюсь изложить покороче, заранее приношу извинения если пост будет емким.
Началось все с того, что я не смог найти подходящего сервера в мире, который мог бы сохранять данные, полученные через HTTP протокол напрямую в архивы, так чтобы не было недостатков присущих обычным архивам и объектным хранилищам. А причиной поисков стал разросшийся до больших масштабов Origin кластер из 10 серверов, в котором скопилось уже 250,000,000 мелких файлов, а тенденция роста и не собиралась прекращаться.
Тем, кто читать статьи не любит и небольшая документация проще:
e .
И docker заодно, сейчас есть вариант только вместе с nginx внутри на всякий случай:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdAvanti:
Если файлов очень много, необходимы значительные ресурсы, причём, самое обидное, часть их пропадает впустую. К примеру, при использовании кластерной файловой системы (в рассматриваемом случае — MooseFS) файл, независимо от фактического размера, занимает всегда минимум 64 KB. То есть для файлов размером 3, 10 или 30 KB на диске требуется по 64 KB. Если файлов четверть миллиарда, мы теряем от 2 до 10 терабайт. До бесконечности создавать новые файлы не удастся, так как в той же MooseFS есть ограничение: не более 1 миллиарда при одной реплике каждого файла.
По мере увеличения количества файлов, нужно много оперативной памяти для метаданных. Так же частые большие дампы метаданных способствуют износу SSD-накопителей.
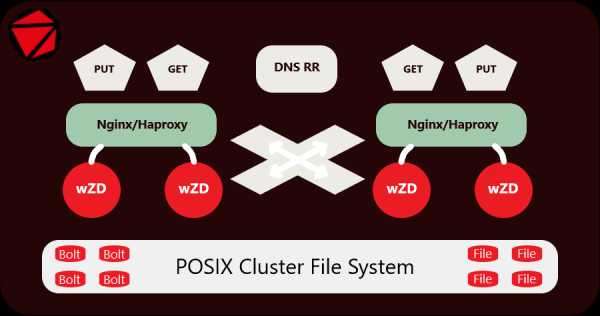
Сервер wZD. Наводим порядок на дисках.
Сервер написан на языке Go. Прежде всего мне нужно было уменьшить количество файлов. Как это сделать? За счёт архивирования, но в данном случае без компрессии, так как у меня файлы это сплошные ужатые картинки. На помощь пришла BoltDB, которую еще пришлось лишать недостатков, это отражено в документации.
Итого вместо четверти миллиарда файлов в моем случае осталось только 10 миллионов Bolt архивов. Если бы у меня была возможность изменить текущую структуру наполнения файлами директорий, то возможно было бы сократить примерно и до 1 миллиона файлов.
Все мелкие файлы упаковываются в Bolt архивы, автоматически получающие имена директорий, в которых они лежат, а все крупные файлы остаются рядышком с архивами, их нет смысла упаковывать, это настраиваемо. Маленькие — архивируем, большие — оставляем без изменений. Сервер работает прозрачно и с теми, и с другими.
Архитектура и особенности сервера wZD.

Сервер функционирует под управлением операционных систем Linux, BSD, Solaris и OSX. Я тестировал только для архитектуры AMD64 под Linux, но он должен подойти и для ARM64, PPC64, MIPS64.
Основные фишки:
- Multithreading;
- Мультисерверность, обеспечивающая отказоустойчивость и сбалансированность нагрузки;
- Максимальная прозрачность для пользователя или разработчика;
- Поддерживаемые HTTP-методы: GET, HEAD, PUT и DELETE;
- Управление поведением при чтении и записи через клиентские заголовки;
- Поддержка гибко настраиваемых виртуальных хостов;
- Поддержка CRC целостности данных при записи/чтении;
- Полудинамические буферы для минимального потребления памяти и оптимальной настройки сетевой производительности;
- Отложенная компакция данных;
- В дополнение предлагается многопоточный архиватор wZA для миграции файлов без остановки сервиса.
Реальный опыт:
Я разрабатывал и тестировал сервер и архиватор на живых данных довольно долгое время, сейчас он успешно функционирует на кластере включающем 250,000,000 мелких файлов (картинок), расположенных в 15,000,000 директорий на раздельных SATA-дисках. Кластер из 10 серверов представляет собой Origin-сервер, установленный за CDN-сетью. Для его обслуживания используется 2 сервера Nginx + 2 сервера wZD.
Тем, кто решит использовать этот сервер, имеет смысл перед использованием спланировать структуру директорий, если это применимо. Сразу оговорюсь, что сервер не предназначен для того, чтобы всё запихнуть в 1 Bolt архив.
Тестирование производительности:
Чем меньше размер заархивированного файла, тем быстрее выполняются с ним операции GET и PUT. Сравним полное время записи HTTP клиентом в обычные файлы и в Bolt архивы, и так же чтение. Сравнивается работа с файлами размером 32 KB, 256 KB, 1024 KB, 4096 KB и 32768 KB.
При работе с Bolt архивами проверяется целостность данных каждого файла (используется CRC), до записи и так же после записи происходит считывание на лету и пересчет, это естественно вносит задержки, но главное — безопасность данных.
Тесты производительности я проводил на SSD-накопителях, так как на SATA-дисках тесты не показывают четкой разницы.
Графики по результатам тестирования:
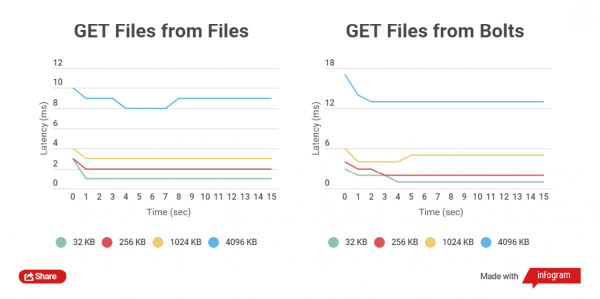
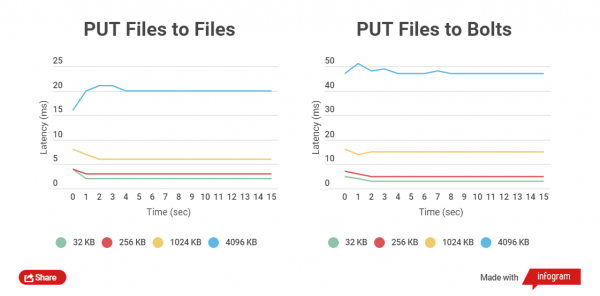
Как видно, для небольших файлов разница во времени чтения и записи между архивированными и не заархивированными файлами невелика.
Совсем иную картину уже получим при тесте чтения и записи файлов размером 32 MB:
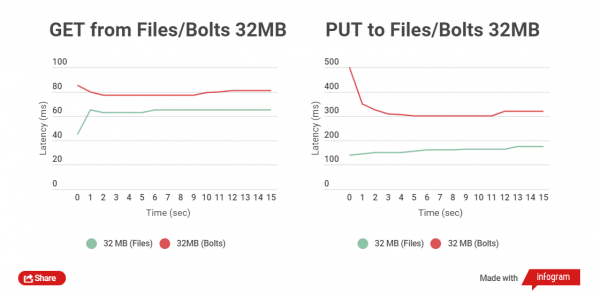
Разница во времени между чтением файлов — в пределах 5-25 мс. С записью дела обстоят хуже, разница составляет около 150 мс. Но в данном случае и не требуется заливать большие файлы, в этом попросту нет смысла, они могут жить отдельно от архивов.
*Технически можно использовать данный сервер и для задач требующих NoSQL.
Основные методы работы с wZD сервером:
Загрузка обычного файла:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgЗагрузка файла в Bolt архив (если не превышен серверный параметр fmaxsize, определяющий максимальный размер файла, который может быть включён в архив, если же превышен, то файл загрузится как обычно рядом с архивом):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgСкачивание файла (если на диске и в архиве есть файлы с одинаковыми именами, то при скачивании приоритет по умолчанию отдаётся не заархивированному файлу):
curl -o test.jpg http://localhost/test/test.jpgСкачивание файла из Bolt архива (принудительно):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgОписание других методов есть в документации.
Сервер пока что поддерживает только протокол HTTP, с HTTPS пока не работает. Также не поддерживается метод POST (еще не решено нужен он или нет).
Кто покопается в исходном коде, обнаружит там ириску, ее не все любят, но я не привязывал основной код к функциям веб фреймворка, кроме обработчика прерываний, так что в дальнейшем могу переписать быстро почти на любой движок.
ToDo:
- Разработка собственного репликатора и дистрибьютора + гео для возможности использования в больших системах без кластерных ФС (Всё по взрослому)
- Возможность полного реверсивного восстановления метаданных при их полной утере(в случае использования дистрибьютора)
- Нативный протокол для возможности использования постоянных сетевых соединений и драйверы к разным языкам программирования
- Расширенные возможности использования NoSQL составляющей
- Компрессии разных типов (gzip, zstd, snappy) для файлов или значений внутри Bolt архивов и для обычных файлов
- Шифрование разных типов для файлов или значений внутри Bolt архивов и для обычных файлов
- Отложенная серверная видео конвертация, в том числе и на GPU
У меня всё, надеюсь этот сервер кому-нибудь пригодится, лицензия BSD-3, копирайт двойной, так как не было бы компании где я работаю, не написал бы и сервер. Разработчик я в единственном числе. Буду признателен за найденные баги и фич реквесты.
Fonte: habr.com
