

I sistemi di backup sono vari, ma cosa si fa quando i server gestiti sono distribuiti in diverse regioni e clienti, e si deve fare affidamento sugli strumenti del sistema operativo?

Buongiorno, Habr!
Mi chiamo Natalya. Sono il team leader del gruppo di amministratori delle applicazioni presso NPO "Krista". Siamo il team Ops per il gruppo di progetti della nostra azienda. La nostra situazione è piuttosto peculiare: installiamo e supportiamo il nostro software sia sui server della nostra azienda che su quelli situati presso i clienti. Non è necessario fare il backup dell'intero server. Sono importanti solo i "dati essenziali": i database e alcune directory del file system. Naturalmente, i clienti hanno (o non hanno) le loro normative di backup e spesso forniscono qualche tipo di deposito esterno per ricevere le copie di backup. In questo caso, dopo la creazione del backup, garantiamo l'invio al deposito esterno.
Per un certo periodo, per le esigenze di backup ci siamo affidati a uno script bash, ma man mano che aumentavano le opzioni di configurazione, cresceva anche la complessità di questo script, e a un certo punto ci siamo trovati nella necessità di "distruggerlo fino all'osso, e poi....".
Le soluzioni pronte non erano adatte per vari motivi: a causa della necessità di decentralizzare i backup, dell'obbligo di conservare i backup localmente presso il cliente, della complessità di configurazione, della sostituzione delle importazioni e delle limitazioni di accesso.
Ci è sembrato più semplice creare qualcosa di nostro. Volevamo ottenere qualcosa che fosse sufficiente per la nostra situazione per i prossimi N anni, ma con la possibilità di potenziale espansione dell'ambito di applicazione.
I requisiti del compito erano i seguenti:
- l'istanza di backup di base è autonoma e funziona localmente
- la conservazione dei backup e dei log deve sempre avvenire all'interno della rete del cliente
- l'istanza è composta da moduli – una sorta di 'costruttore'
- necessaria compatibilità con le distribuzioni Linux utilizzate, comprese quelle obsolete, preferibile una potenziale interoperabilità
- per lavorare con l'istanza è sufficiente l'accesso SSH, non è necessario aprire porte aggiuntive
- massima semplicità di configurazione e utilizzo
- è possibile (ma non obbligatorio) l'esistenza di un'istanza separata che consenta di visualizzare centralmente lo stato dei backup da diversi server
Quello che abbiamo ottenuto può essere visualizzato qui:
Il programma è scritto in python3; funziona su Debian, Ubuntu, CentOS, AstraLinux 1.6.
La documentazione è disponibile nella cartella docs del repository.
Concetti principali utilizzati dal sistema:
action – un'azione che implementa una singola operazione atomica (backup del database, backup di una directory, spostamento da una directory A a una directory B, ecc.). Le azioni esistenti sono nel catalogo core/actions
task – un compito, un insieme di azioni che descrive un'unica "attività di backup" logica
schedule – un programma, un insieme di compiti con facoltà di specificare l'orario di esecuzione dell'attività
La configurazione del backup è memorizzata in un file yaml; la struttura generale del config è:
- impostazioni generali
- sezione actions: descrizione delle azioni utilizzate su questo server
- sezione schedule: descrizione di tutti i compiti (insiemi di azioni) e programma di esecuzione tramite cron, se necessario
Cosa può fare l'applicazione attualmente:
- sono supportate le operazioni principali: backup di PostgreSQL tramite pg_dump, backup di una directory del filesystem tramite tar; operazioni con storage esterno; rsync tra directory; rotazione dei backup (rimozione delle vecchie copie)
- invocazione di uno script esterno
- esecuzione manuale di un singolo compito
/opt/KristaBackup/KristaBackup.py run make_full_dump - è possibile aggiungere (o rimuovere) un'attività specifica o l'intero programma nel crontab
/opt/KristaBackup/KristaBackup.py enable all - generazione di un file trigger in base ai risultati del backup. Questa funzione è utile in combinazione con Zabbix per il monitoraggio dei backup
- può funzionare in background in modalità webapi o web
/opt/KristaBackup/KristaBackup.py web start [--api]
La differenza tra le modalità: in webapi non c'è una vera interfaccia web, ma l'applicazione risponde alle richieste di un'altra istanza. Per la modalità web è necessario installare Flask e alcuni pacchetti aggiuntivi, cosa che non è sempre accettabile, ad esempio in AstraLinux SE certificata.
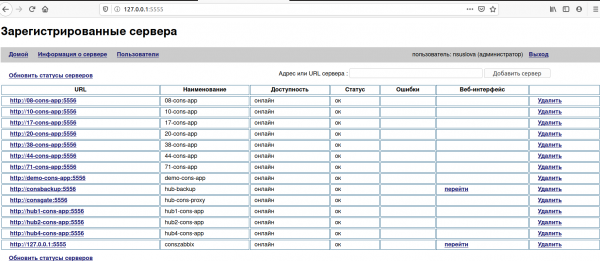
Attraverso l'interfaccia web è possibile vedere lo stato e i log dei backup dei server connessi: il «web-instance» richiede dati dai «backup-instance» tramite API. L'accesso al web richiede autorizzazione, mentre l'accesso al webapi non ne ha bisogno.
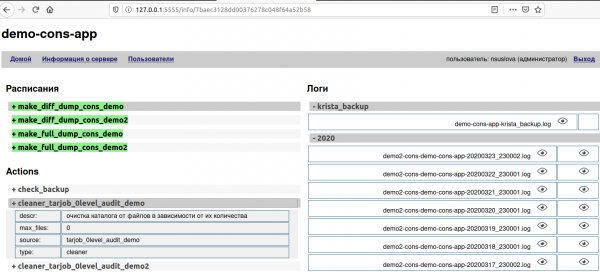
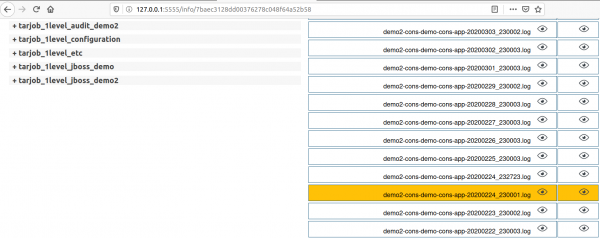
I log dei backup andati male vengono contrassegnati con colori: warning - giallo, error - rosso.
Se l'amministratore non ha bisogno di un promemoria sui parametri e i sistemi operativi dei server sono omogenei, è possibile compilare il file e distribuire un pacchetto già pronto.
Distribuiamo principalmente questo strumento tramite Ansible, inizialmente implementandolo su una parte dei server meno importanti e dopo testandolo su tutti gli altri.
Alla fine abbiamo ottenuto un'utilità di copia compatta e autonoma, automatizzabile e utilizzabile anche da amministratori con poca esperienza. È comodo per noi — potrebbe essere utile anche per te?
Fonte: habr.com
