

По мотивам дискуссии в чате
В последнее время разгораются настоящие битвы на предмет определения понятия DevOps и SRE.
Несмотря на то, что уже во многом дискуссии на эту тему уже набили оскомину, в том числе и мне, решил вынести на суд хабра-сообщества и свой взгляд на эту тему. Тем, кому интересно, добро пожаловать под кат. И да начнется все по новой!
Contesto
Итак, в стародавние времена жила отдельно команда разработчиков ПО и администраторов серверов. Первые благополучно писали код, вторые, употребляя различные теплые ласковые слова в адрес первых, настраивали сервера, периодически приходя к разработчикам и получая в ответ исчерпывающее «на моей машине все работает». Бизнес ждал программное обеспечение, все простаивало, периодически ломалось, все нервничали. Особенно тот, кто за весь этот бардак платил. Славная ламповая эпоха. Ну да вы и так в курсе, откуда растут ноги у DevOps.
Рождение DevOps практик
Затем пришли серьезные дяди и сказали — это не индустрия, так работать нельзя. И притащили модели жизненного цикла. Вот, например, V-модель.
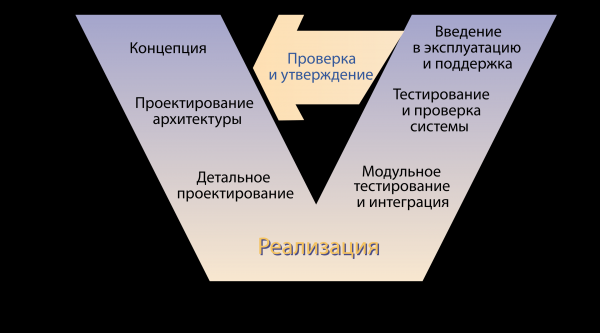
Итак, что мы видим? Бизнес приходит с концепцией, архитекторы проектируют решения, разработчики пишут код, дальше — провал. Кто-то как-то тестирует продукт, кто-то как-то его доставляет конечному пользователю и где-то на выходе этой чудо-модели сидит одинокий бизнес-заказчик и ждет обещанной у моря погоды. Пришли к выводу — нужны методы, которые позволят этот процесс наладить. И решили создать практики, которые бы их реализовывали.
Лирическое отступление на предмет, что такое практика
Под практикой я понимаю связку технологии и дисциплины. Пример — практика описания инфраструктуры кодом на terraform. Дисциплина — это то, как описывать кодом инфраструктуру, она у разработчика в голове, а технология — это собственно terraform.
И решили они назвать их DevOps практиками — думаю имели в виду from Development to Operations. Придумали разные мудреные штуки — CI/CD практики, практики, основывающиеся на IaC принципе, тысячи их. И понеслась, разработчики пишут код, DevOps инженеры трансформируют описание системы в виде кода в работающие системы (да, код это к сожалению, всего лишь описание, но никак не воплощение системы), доставка крутится, ну и так далее. Вчерашние администраторы, освоив новые практики, гордо переквалифицировались в DevOps инженеров, и все понеслось. И был вечер, и было утро… извините, не оттуда.
Все опять не слава богу
Только все улеглось, и разные хитрые «методологи» начали писать толстенные книги по DevOps практикам, тихо разгорались споры, кто же такой все-таки пресловутый DevOps инженер и что DevOps — это культура производства, опять назрело недовольство. Внезапно обнаружилось, что доставка ПО — абсолютно нетривиальная задача. У каждой инфраструктуры разработки свой стек, где-то собирать надо, где-то разворачивать environment, тут нужен tomcat, тут нужен еще хитровымученный способ запуска — в общем, голова трещит. А еще проблема, как ни странно, оказалась в первую очередь в организации процессов — вот эта функция доставки, как бутылочное горлышко, стало блокировать процессы. К тому же эксплуатацию (Operations) никто не отменял. Ее в V-модели не видно, а там еще весь жизненный цикл справа. По итогу надо и как-то инфраструктуру поддерживать, и в мониторинг смотреть, и инциденты разруливать, да еще и доставкой заниматься. Т.е. сидеть одной ногой и в разработке, и в эксплуатации — и вдруг получился такой Development & Operations. А тут еще и повальный хайп на микросервисы подъехал. А с ними еще и разработка с локальных машин начала в клауд переезжать — попробуй что-то отладить локально, если микросервисов десятки и сотни, тут уже постоянная доставка становится средством выживания. Для «маленькой скромной компании» еще куда ни шло, но все же? А Google?
SRE от Google
Пришел Google, съел самые крупные кактусы и решил — нам такое не надо, нам надежность нужна. А надежностью надо управлять. И решил — нам нужны специалисты, которые будут управлять надежностью. Назвал их SR-инженерами и сказал, вот вам все, сделайте, как обычно, хорошо. Вот вам SLI, вот вам SLO, вот вам мониторинг. И ткнул носом в operations. И назвал свой «надежный DevOps» SRE. Вроде бы все хорошо, но есть один грязный хак, который Google мог себе позволить — на позиции SR инженеров нанимать людей, которые имели квалификацию разработчиков и еще немного шили на дому разбирались в функционировании работающих систем. Причем с наймом таких людей и у самого Google проблемы — главным образом потому, что тут он сам с собой конкурирует — надо же и бизнес-логику кому-то описывать. Доставку развесил на релиз-инженеров, SR — инженеры управляют надежностью (ясное дело, не напрямую, а влияя на инфраструктуру, меняя архитектуру, отслеживая изменения и показатели, разбираясь с инцидентами). Красиво, можно . А что делать, если вы не Google, а надежность все же как-то беспокоит?
Развитие идей DevOps
Тут как раз подоспел Docker, выросший из lxc, а затем и различные системы оркестрации типа Docker Swarm и Kubernetes, и DevOps инженеры выдохнули — унификация практик упростила доставку. Упростила до такой степени, что стало возможным даже отдать доставку разработчикам — что там deployment.yaml. Контейнеризация проблему решает. Да и зрелость систем CI/CD уже на уровне один файл написал и все понеслось — разработчики сами справятся. И тут мы начинаем говорить, как нам сделать свой SRE, с… да хоть с кем-нибудь.
SRE не в Google
Ну ок, доставку мы отдали, вроде бы можем выдохнуть, вернуться к старым добрым временам, когда админы смотрели загрузку процессоров, тюнили системы и тихо потягивали из кружек что-то непонятное в тишине и спокойствии… Стоп. Мы не ради этого все затевали (а жаль!). Внезапно оказывается, что в подходе Google мы вполне можем взять отличные практики — не загрузка процессоров важна, и не то, насколько часто мы диски там меняем, или там в клауде стоимость оптимизируем, а бизнес-метрики — все те же пресловутые SLx. И управление инфраструктурой с них никто не снимал, и инциденты разруливать надо, и дежурить на посту периодически, и вообще в теме бизнес-процессов быть. И парни, начинайте уже понемногу программировать на хорошем уровне, вас Google уже заждался.
Резюмируя. Внезапно, но вы уже устали читать и вам не терпится плюнуть написать автору в комментарии к статье. DevOps как практики доставки, был есть и будет. И никуда не денется. SRE как набор практик эксплуатации делает эту самую доставку успешной.
Fonte: habr.com
