

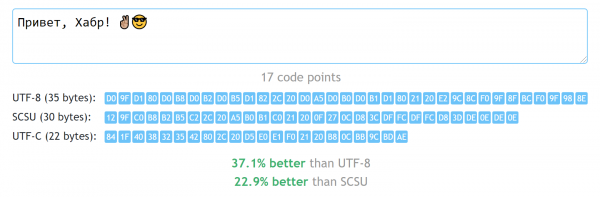
Se sei uno sviluppatore e ti trovi di fronte al compito di scegliere una codifica, quasi sempre la scelta giusta sarà Unicode. Il modo specifico di rappresentazione dipende dal contesto, ma molto spesso c'è una risposta universale: UTF-8. È vantaggioso perché permette di utilizzare tutti i caratteri Unicode senza sprecare troppi byte nella maggior parte dei casi. Tuttavia, per le lingue che non usano solo l'alfabeto latino, "non troppi" corrisponde a almeno due byte per carattere. È possibile fare meglio senza tornare a codifiche preistoriche che ci limitano a sole 256 lettere disponibili?
Di seguito, propongo di esaminare il mio tentativo di fornire una risposta a questa domanda e una realizzazione di un algoritmo relativamente semplice che permette di memorizzare stringhe nella maggior parte delle lingue del mondo, senza aggiungere l'eccesso di dati presente in UTF-8.
Dichiarazione di non responsabilità. Farò subito alcune importanti precisazioni: la soluzione descritta non è proposta come un sostituto universale di UTF-8., si adatta solo a un elenco ristretto di casi (di cui parlerò dopo), e non deve mai essere utilizzato per interagire con API esterne (di cui non sanno nemmeno nulla). Più frequentemente, per la memorizzazione compatta di grandi volumi di dati testuali, si adattano algoritmi di compressione generali (come deflate). Inoltre, già nella fase di creazione della mia soluzione, ho trovato uno standard esistente nello stesso Unicode, che risolve lo stesso problema — è un po' più complesso (e spesso meno efficace), ma rimane uno standard accettato, anziché qualcosa creato frettolosamente. Di questo parlerò anche.
Su Unicode e UTF-8
Per cominciare, alcune parole su cosa sia in generale Unicode e UTF-8.
Come è noto, in passato erano popolari le codifiche a 8 bit. Con esse era tutto semplice: 256 caratteri possono essere numerati con i numeri da 0 a 255, e i numeri da 0 a 255 sono ovviamente rappresentabili in un byte. Se torniamo alle origini, la codifica ASCII è limitata a 7 bit, quindi il bit più significativo nella sua rappresentazione byte è zero, e la maggior parte delle codifiche a 8 bit è compatibile con essa (si differenziano solo nella parte 'superiore', dove il bit più significativo è uno).
Cosa differenzia Unicode da quelle codifiche e perché con esso sono associate molte rappresentazioni specifiche — UTF-8, UTF-16 (BE e LE), UTF-32? Analizziamo per ordine.
Lo standard principale di Unicode descrive solo la corrispondenza tra i caratteri (e in alcuni casi — singoli componenti dei caratteri) e i loro numeri. E i numeri possibili in questo standard sono moltissimi — da 0x00 fino a 0x10FFFF (1 114 112 pezzi). Se volessimo memorizzare un numero in questo intervallo in una variabile, né 1 né 2 byte sarebbero sufficienti. E poiché i nostri processori non sono progettati per lavorare con numeri a tre byte, saremmo costretti a utilizzare ben 4 byte per ogni simbolo! Questo è UTF-32, ma proprio a causa di questa "sprecatezza" questo formato non è molto popolare.
Fortunatamente, i simboli all'interno di Unicode non sono ordinati a caso. La loro moltitudine è suddivisa in 17 "piani", ognuno dei quali contiene 65536 (0x10000) «punti codice"). Il concetto di "punto codice" qui è semplicemente il numero di simbolo, assegnato a lui da Unicode. Ma, come già detto, in Unicode non sono numerati solo i singoli simboli, ma anche i loro componenti e i segni di controllo (e a volte non corrispondono affatto a un numero — forse fino a un certo punto, ma per noi questo non è così importante), quindi è più corretto parlare sempre del numero stesso dei numeri, piuttosto che dei simboli. Tuttavia, per brevità, in seguito userò spesso la parola "simbolo", riferendomi al termine "punto codice".
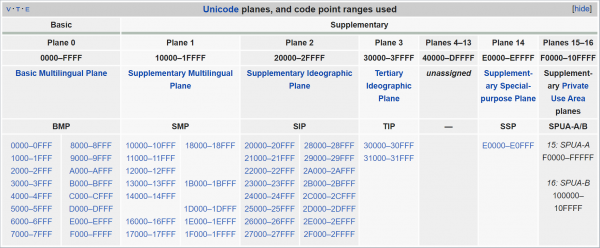
Piani di Unicode. Come si può vedere, la maggior parte (i piani da 4 a 13) non è ancora utilizzata.
La cosa sorprendente è che tutta la «polpa» principale si trova nel piano zero, chiamato "Piano Multilingue di Base". Se la riga contiene testo in una delle lingue moderne (incluso il cinese), non uscirai oltre questo piano. Ma non puoi escludere anche il resto del Unicode — per esempio, le emoji si trovano principalmente alla fine del piano successivo, "Piano Multilingue Supplementare" (si estende da 0x10000 fino a 0x1FFFF). Pertanto, UTF-16 funziona così: tutti i caratteri che rientrano in Piano Multilingue di Base, vengono codificati «così come sono», con il corrispondente numero a due byte. Tuttavia, alcuni numeri in questo intervallo non rappresentano affatto caratteri specifici, ma indicano che dopo questa coppia di byte deve essere considerata un'altra — combinando i valori di questi quattro byte insieme, otteniamo un numero che copre l'intero intervallo consentito di Unicode. Questa rappresentazione è chiamata «coppie surrogative» — forse ne hai sentito parlare.
In questo modo, UTF-16 richiede due o (in rari casi) quattro byte per un singolo "punto di codice". Questo è meglio che utilizzare costantemente quattro byte, ma l'ASCII (e altri caratteri ASCII) in questa codifica consumano metà dello spazio utilizzato per gli zeri. UTF-8 intende correggere questo: in esso, l'ASCII occupa, come prima, solo un byte; i codici da 0x80 fino a 0x7FF — due byte; da 0x800 fino a 0xFFFF — tre, e da 0x10000 fino a 0x10FFFF — quattro. Da un lato, l'ASCII sta meglio: è tornata la compatibilità con ASCII, e la distribuzione è più uniformemente "distribuita" da 1 a 4 byte. Ma gli alfabeti diversi da quello latino, ahimè, non guadagnano affatto rispetto a UTF-16, e molti richiedono addirittura tre byte invece di due — l'intervallo coperto dalla registrazione a due byte si è ristretto di 32 volte, da 0xFFFF fino a 0x7FF, e non comprende più né il cinese né, ad esempio, il georgiano. La scrittura cirillica e altri cinque alfabeti — hurray — hanno avuto fortuna, 2 byte per simbolo.
Perché succede questo? Diamo un'occhiata a come UTF-8 rappresenta i codici dei caratteri:

Per rappresentare direttamente i numeri, qui sono stati utilizzati bit contrassegnati dal simbolo x. È evidente che nella codifica a due byte ci sono solo 11 bit (su 16). I bit più significativi qui svolgono solo una funzione di servizio. Nel caso della codifica a quattro byte, addirittura 21 bit su 32 sono riservati al numero del punto codificato — a prima vista, sembrerebbe che tre byte (che forniscono un totale di 24 bit) sarebbero sufficienti, ma i marcatori di servizio consumano troppi.
È davvero un problema? In realtà, non molto. Da un lato, se ci preoccupiamo molto dello spazio occupato, abbiamo algoritmi di compressione che possono facilmente eliminare tutta l'entropia e la ridondanza superflue. Dall'altro, l'obiettivo di Unicode era fornire una codifica il più universale possibile. Ad esempio, una stringa codificata in UTF-8 può essere affidata a un codice che prima lavorava solo con ASCII, senza temere che possa incontrare un carattere dell'intervallo ASCII che in realtà non è presente (poiché in UTF-8 tutti i byte che iniziano con il bit zero sono proprio ASCII). E se vogliamo improvvisamente tagliare una piccola parte da una grande stringa, senza decodificarla dall'inizio (o recuperare parte delle informazioni dopo un'area danneggiata), non è difficile trovare l'offset dove inizia un certo carattere (è sufficiente saltare i byte che hanno un prefisso di bit) 10).
Perché dunque inventare qualcosa di nuovo?
D'altra parte, ci sono rare situazioni in cui algoritmi di compressione come deflate sono poco applicabili, ma si desidera comunque ottenere una memorizzazione compatta delle stringhe. Personalmente, mi sono trovato di fronte a una tale sfida mentre riflettevo sulla costruzione per un ampio vocabolario che include parole in lingue arbitrarie. Da un lato, ogni parola è molto breve, quindi comprimerla sarebbe inefficace. Dall'altro, l'implementazione dell'albero che ho considerato era progettata affinché ogni byte della stringa archiviata generasse un nodo dell'albero separato, quindi era molto utile minimizzare il loro numero. Nella mia libreria (come in , su cui si basa) un problema simile viene risolto semplicemente: le stringhe imballate in -dizionari sono memorizzate lì in . Ma, come è facile capire, questo funziona bene solo per un alfabeto limitato — una stringa in cinese non può essere inserita in un tale dizionario.
Segnalo anche un altro spiacevole inconveniente che si presenta quando si utilizza UTF-8 in una tale struttura dati. Nell'immagine sopra si può vedere che, quando un carattere viene scritto come due byte, i bit relativi al suo numero non sono contigui, ma interrotti da un paio di bit 10 in mezzo: 110xxxxx 10xxxxxx. A causa di ciò, quando nei codici dei caratteri si sovraccaricano i 6 bit inferiori del secondo byte (ossia si verifica un passaggio 10111111 → 10000000), cambia anche il primo byte. Risultando nel fatto che la lettera «п» è rappresentata dai byte 0xD0 0xBF, e la successiva «р» è già 0xD1 0x80. Nell'albero dei prefissi, questo porta a una divisione del nodo genitore in due: uno per il prefisso 0xD0, e l'altro per 0xD1 (anche se tutta la scrittura in cirillico potrebbe essere codificata solo con il secondo byte).
Cosa ho ottenuto
Affrontando questo compito, ho deciso di esercitarmi con i giochi di bit, e allo stesso tempo conoscere meglio la struttura del Unicode in generale. Il risultato è stato il formato di codifica UTF-C («C» sta per compatto), che non spende più di 3 byte per un singolo punto di codice, e molto spesso permette di utilizzare solo un byte extra per l'intera riga codificata. Questo porta al fatto che per molti alfabeti non ASCII, tale codifica risulta 30-60% più compatta di UTF-8.
Ho presentato esempi di implementazione degli algoritmi di codifica e decodifica sotto forma di , potete usarle liberamente nel vostro codice. Ma sottolineo comunque che in un certo senso questo formato rimane un «bici», e non lo consiglio di utilizzare senza essere consapevoli di ciò che vi serve. Si tratta più di un esperimento che di un serio "miglioramento di UTF-8". Tuttavia, il codice è scritto in modo ordinato, conciso, con un gran numero di commenti e coperto da test.
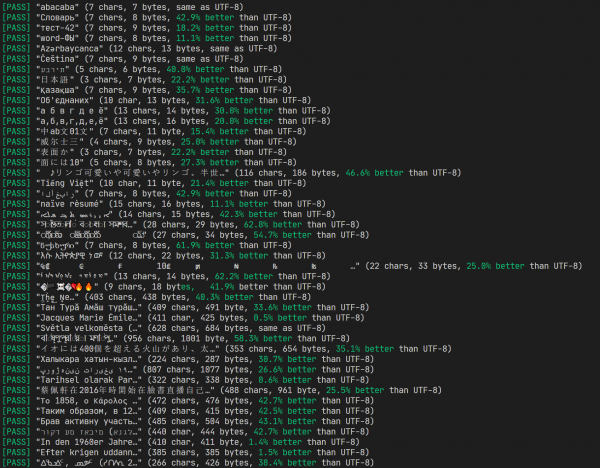
Risultato dell'esecuzione dei test e confronto con UTF-8
Inoltre, ho creato , dove è possibile valutare il funzionamento dell'algoritmo, e poi spiegherò più dettagliatamente i suoi principi e il processo di sviluppo.
Eliminazione dei bit ridondanti
Ho preso, naturalmente, UTF-8 come base. La prima e più ovvia cosa che si può cambiare è ridurre il numero di bit di controllo in ogni byte. Ad esempio, il primo byte in UTF-8 inizia sempre o con 0, o con 11 — e il prefisso 10 è presente solo nei byte successivi. Sostituiamo il prefisso 11 con 1, e nei byte successivi eliminiamo del tutto i prefissi. Cosa otteniamo?
0xxxxxxx — 1 byte
10xxxxxx xxxxxxxx — 2 byte
110xxxxx xxxxxxxx xxxxxxxx — 3 byte
Aspetta, dov'è la registrazione a quattro byte? Non è più necessaria — con la registrazione di tre byte abbiamo ora accesso a 21 bit e questo è più che sufficiente per tutti i numeri fino a 0x10FFFF.
Cosa abbiamo sacrificato qui? La cosa più importante è la rilevazione dei confini dei caratteri da una posizione arbitraria del buffer. Non possiamo colpire un byte arbitrario e trovare l'inizio del carattere successivo. Questa è una limitazione del nostro formato, ma nella pratica la necessità di farlo non si presenta spesso. Di solito possiamo scorrere il buffer dall'inizio (soprattutto quando si tratta di stringhe brevi).
La situazione con la copertura delle lingue a 2 byte è anche migliorata: ora il formato a due byte offre un intervallo di 14 bit, che corrisponde a codici fino a 0x3FFF. Ai cinesi non va bene (i loro ideogrammi sono principalmente nel range da 0x4E00 fino a 0x9FFF), ma ai georgiani e a molte altre nazioni va meglio: le loro lingue rientrano anch'esse in 2 byte per carattere.
Introduciamo lo stato dell'encoder
Ora pensiamo alle proprietà delle stesse stringhe. Nel dizionario di solito ci sono parole scritte con caratteri di un solo alfabeto, e questo è vero anche per molti altri testi. Sarebbe utile specificare un alfabeto una sola volta e poi indicare solo il numero della lettera al suo interno. Vediamo se la disposizione dei caratteri nella tabella Unicode ci aiuta.
Come detto sopra, Unicode è diviso in piani per 65536 codici ciascuna. Ma questa suddivisione non è molto utile (come già detto, ci troviamo più spesso nel piano zero). Più interessante è la suddivisione in blocchi. Questi intervalli non hanno più una lunghezza fissa e hanno più significato — di solito, ciascuno riunisce simboli di un unico alfabeto.
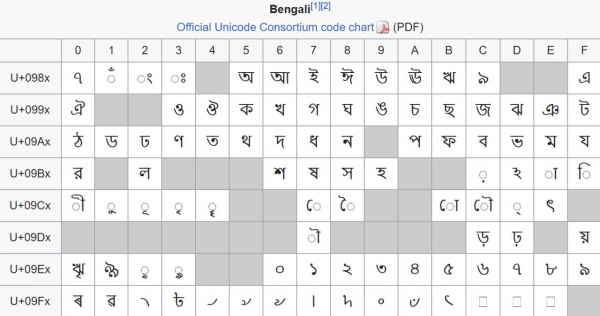
Blocco contenente i caratteri dell'alfabeto bengalese. Purtroppo, per ragioni storiche, questo è un esempio di imballaggio non molto denso — 96 caratteri sono sparsi casualmente su 128 punti di codice del blocco.
Le posizioni dei blocchi e le loro dimensioni sono sempre multipli di 16 — questo è stato fatto semplicemente per comodità. Inoltre, molti blocchi iniziano e finiscono a valori multipli di 128 o anche 256 — ad esempio, il cirillico principale occupa 256 byte da 0x0400 fino a 0x04FF. È piuttosto comodo: se una volta salviamo il prefisso 0x04, allora qualsiasi simbolo cirillico può essere registrato con un byte. Tuttavia, in questo modo perdiamo la possibilità di tornare all'ASCII (e a qualsiasi altro simbolo in generale). Pertanto facciamo così:
- Due byte
10yyyyyy yxxxxxxxnon solo indicano un simbolo con il numeroyyyyyy yxxxxxxx, ma cambiano l'alfabeto corrente conyyyyyy y0000000(cioè ricordiamo tutti i bit tranne i meno significativi 7 bit); - Un byte
0xxxxxxxquesto è il simbolo dell'alfabeto attuale. Deve essere semplicemente sommato con lo spostamento che abbiamo memorizzato al passo 1. Poiché non abbiamo cambiato l'alfabeto, lo spostamento è pari a zero, quindi manteniamo la compatibilità con ASCII.
Analogamente per i codici che richiedono 3 byte:
- Tre byte
110yyyyy yxxxxxxx xxxxxxxxdesignano il simbolo con il numeroyyyyyy yxxxxxxx xxxxxxxx, cambiano l'alfabeto corrente conyyyyyy y0000000 00000000(abbiamo memorizzato tutto tranne i bit inferiori 15 bit), e impostano un flag che ora siamo in modalità lunga (al cambio dell'alfabeto di nuovo in quello a due byte, questo flag lo resetteremo); - Due byte
0xxxxxxx xxxxxxxxin modalità lunga, questo è il simbolo dell'alfabeto attuale. Analogamente, lo sommiamo con lo spostamento dal passo 1. L'unica differenza è che ora leggiamo due byte (perché siamo passati a questa modalità).
Suona bene: ora, finché dobbiamo codificare simboli dello stesso intervallo a 7 bit di Unicode, spendiamo 1 byte extra all'inizio e solo 1 byte per simbolo.
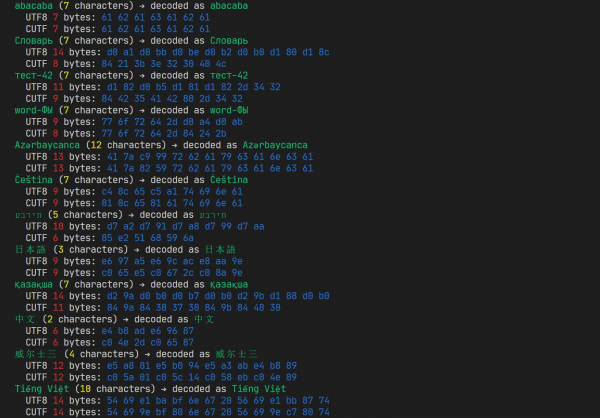
Funzione di una delle prime versioni. Già spesso supera UTF-8, ma c'è ancora margine di miglioramento.
Cosa è peggiorato? Innanzitutto, abbiamo uno stato, ovvero lo spostamento dell'alfabeto attuale e il flag in modalità lunga. Questo ci limita ulteriormente: ora gli stessi caratteri possono essere codificati in modo diverso a seconda dei contesti. La ricerca di sottostringhe, ad esempio, dovrà tenerne conto, e non basarsi solo sul confronto dei byte. In secondo luogo, una volta cambiato l'alfabeto, ci sono stati problemi con la codifica dei caratteri ASCII (e questo non include solo l'alfabeto latino, ma anche la punteggiatura di base, spazi inclusi) — richiedono un cambio dell'alfabeto in 0, cioè un altro byte sovrfluo (e poi un altro per tornare al nostro principale).
Un alfabeto è buono, due sono migliori
Proviamo a cambiare un po' i nostri prefissi binari, aggiungendo un altro ai tre descritti sopra:
0xxxxxxx — 1 byte in modalità normale, 2 in quella lunga
11xxxxxx — 1 byte
100xxxxx xxxxxxxx — 2 byte
101xxxxx xxxxxxxx xxxxxxxx — 3 byte
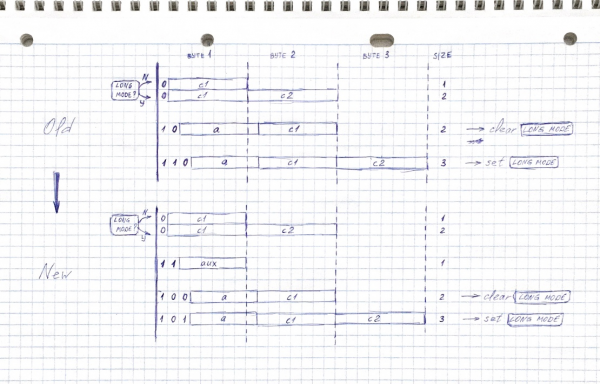
Ora, nella registrazione a due byte, è disponibile un bit in meno — possono essere contenuti punti di codice fino a 0x1FFF, e non 0x3FFF. Tuttavia, è ancora chiaramente di più rispetto ai codici a due byte UTF-8, nella maggior parte dei linguaggi comuni ci si fa ancora spazio, la perdita più evidente è stata e , i giapponesi sono tristi.
Cos'è il nuovo codice 11xxxxxx? Это небольшой «загашник» размером в 64 символа, он дополняет наш основной алфавит, поэтому я назвал его вспомогательным (auxiliary) alfabetico. Quando cambiamo l'alfabeto attuale, un pezzo del vecchio alfabeto diventa ausiliario. Ad esempio, se passiamo da ASCII al cirillico, nel 'ripostiglio' ci sono ora 64 caratteri che contengono latino, numeri, spazio e virgola (le inserzioni più comuni nei testi non-ASCII). Se torniamo di nuovo a ASCII, la parte principale del cirillico diventa l'alfabeto ausiliario.
Grazie all'accesso a due alfabeti, possiamo gestire un numero maggiore di testi, con costi minimi per il cambio di alfabeto (la punteggiatura porterà più frequentemente a tornare in ASCII, ma dopo molti caratteri non-ASCII li estrarremo già dall'alfabeto aggiuntivo, senza riattivare il cambio).
Bonus: designando l'alfabeto supplementare con un prefisso 11xxxxxx e scegliendo il suo offset iniziale uguale a 0xC0, otteniamo una compatibilità parziale con CP1252. In altre parole, molti (ma non tutti) i testi dell'Europa occidentale codificati in CP1252 appariranno allo stesso modo anche in UTF-C.
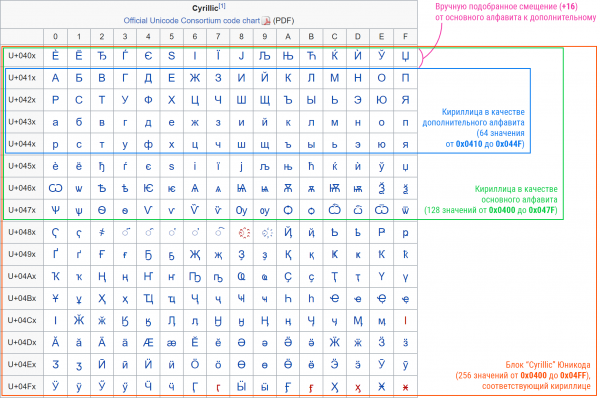
Qui, in effetti, sorge una difficoltà: come ottenere un alfabeto ausiliario dall'alfabeto principale? Si può mantenere lo stesso offset, ma — ahimè — qui la struttura Unicode gioca già contro di noi. Spesso, la parte principale dell’alfabeto non si trova all’inizio del blocco (ad esempio, la maiuscola russa «А» ha il codice 0x0410, mentre il blocco cirillico inizia con 0x0400). Pertanto, prendendo in «riserva» i primi 64 caratteri, potremmo perdere l'accesso alla parte finale dell'alfabeto.
Per risolvere questo problema, ho manualmente esaminato alcuni blocchi corrispondenti a vari linguaggi, e ho indicato per loro l'offset dell'alfabeto ausiliario all'interno di quello principale. Ho riorganizzato l'alfabeto latino, in via eccezionale, come fosse base64.
Ultimi ritocchi
Infine, pensiamo a dove possiamo ancora migliorare qualcosa.
Notiamo che il formato 101xxxxx xxxxxxxx xxxxxxxx consente di codificare numeri fino a 0x1FFFFF, e Unicode termina prima, a 0x10FFFF. In altre parole, l'ultimo punto di codice sarà rappresentato come 10110000 11111111 11111111. Quindi possiamo dire che se il primo byte ha la forma 1011xxxx (dove xxxx se maggiore di 0), significa qualcos'altro. Ad esempio, si possono aggiungere altri 15 caratteri, sempre disponibili per la codifica in un byte, ma ho deciso di procedere in un altro modo.
Diamo un'occhiata ai blocchi Unicode che richiedono attualmente tre byte. Principalmente, come già detto, si tratta di ideogrammi cinesi - ma è difficile fare qualcosa con essi, sono 21.000. Inoltre, ci sono anche i caratteri hiragana e katakana - e questi sono già meno, meno di duecento. E, dal momento che abbiamo menzionato i giapponesi, ci sono anche le emoji (in realtà sono sparse in molte parti del Unicode, ma i blocchi principali sono nell'intervallo 0x1F300 – 0x1FBFF). Pensando al fatto che ora ci sono emoji composte da più punti di codice (ad esempio, l'emoji è composta da ben 7 codici!), diventa davvero scioccante spendere per ognuna tre byte (7×3 = 21 byte per un singolo simbolo, è un incubo).
Pertanto, scegliamo alcuni intervalli selezionati, corrispondenti a emoji, hiragana e katakana, li rinumera in un'unica lista continua e li codifichiamo in due byte anziché tre:
1011xxxx xxxxxxxx
Eccellente: l'emoji sopra menzionata , composta da 7 punti di codice, in UTF-8 occupa 25 byte, mentre noi lo abbiamo ridotto a 14 (esattamente due byte per ogni punto codice). A proposito, Habr ha rifiutato di elaborarlo (sia nella vecchia che nella nuova editor) e quindi ho dovuto inserirlo come immagine.
Cerchiamo di risolvere un altro problema. Come sappiamo, l'alfabeto principale è essenzialmente i 6 bit superiori, che teniamo a mente e attacchiamo al codice di ciascun simbolo decodificato. Nel caso dei caratteri cinesi, che si trovano nel blocco 0x4E00 – 0x9FFF, si tratta di bit 0 o 1. Questo non è molto pratico: dovremo costantemente cambiare l'alfabeto tra questi due valori (ossia, spendere tre byte). Ma notiamo che in modalità lunga possiamo sottrarre dal codice il numero di simboli che codifichiamo usando la modalità corta (dopo tutte le astuzie sopra descritte, questo è 10240) — allora l'intervallo dei caratteri cinesi si sposterà a 0x2600 – 0x77FF, e in tal caso, in tutto questo intervallo, i 6 bit superiori (su 21) saranno pari a 0. Pertanto, le sequenze di caratteri utilizzeranno due byte per carattere (il che è ottimale per un intervallo così ampio), senza richiedere cambiamenti di alfabeto.
Soluzioni alternative: SCSU, BOCU-1
Gli esperti di Unicode, già leggendo il titolo dell'articolo, probabilmente si affretteranno a ricordare che tra gli standard Unicode c'è (SCSU), che descrive un modo di codifica molto simile a quello descritto nell'articolo.
Ammetto onestamente: ho saputo della sua esistenza solo dopo essermi immerso profondamente nella scrittura della mia soluzione. Se ne fossi stato a conoscenza fin dall'inizio, probabilmente avrei provato a scrivere la sua implementazione invece di inventare il mio approccio.
Curiosamente, SCSU utilizza idee molto simili a quelle a cui sono arrivato autonomamente (invece del concetto di “alfabeti”, vengono utilizzate “finestre”, e ce ne sono più di quante ne avessi io). Allo stesso tempo, questo formato ha anche dei difetti: è un po' più vicino agli algoritmi di compressione piuttosto che di codifica. In particolare, lo standard fornisce numerosi modi di rappresentazione, ma non spiega come scegliere quella ottimale — a questo scopo, l'encoder deve applicare alcune euristiche. Pertanto, un encoder SCSU che produce un buon packaging sarà più complesso e ingombrante rispetto al mio algoritmo.
Per confronto, ho portato un'implementazione relativamente semplice di SCSU in JavaScript — in termini di quantità di codice, si è rivelata comparabile con il mio UTF-C, ma in alcuni casi ha mostrato risultati peggiori di decine di punti percentuali (a volte può anche superarlo, ma di poco). Ad esempio, i testi in ebraico e greco sono stati codificati in UTF-C addirittura con un miglioramento del 60% rispetto a SCSU (probabilmente a causa dei loro alfabeti compatti).
Aggiungo inoltre che oltre a SCSU esiste un altro metodo di rappresentazione compatta di Unicode — , ma mira alla compatibilità con MIME (cosa di cui non avevo bisogno), e utilizza un approccio di codifica leggermente diverso. Non ho valutato la sua efficacia, ma mi sembra che difficilmente possa essere superiore a SCSU.
Possibili miglioramenti
L'algoritmo che ho presentato non è universale per design (qui, probabilmente, le mie intenzioni divergono maggiormente da quelle del consorzio Unicode). Ho già accennato al fatto che è stato sviluppato principalmente per un compito specifico (memorizzazione di un dizionario multilingue in un albero di prefissi), e alcune delle sue caratteristiche potrebbero non adattarsi bene ad altri compiti. Ma il fatto che non sia uno standard può essere anche un vantaggio — puoi facilmente modificarlo per le tue esigenze.
Ad esempio, è ovvio che si può eliminare la presenza di stato, rendere la codifica stateless — semplicemente non aggiornando le variabili sconti, disattiva e è21Bit nel codificatore e nel decodificatore. In tal caso, non sarà possibile imballare efficacemente sequenze di caratteri di un singolo alfabeto, ma si avrà la garanzia che ogni stesso carattere è sempre codificato con gli stessi byte, indipendentemente dal contesto.
Inoltre, è possibile ottimizzare il codificatore per una lingua specifica, cambiando lo stato predefinito — ad esempio, orientandosi su testi russi, impostando all'inizio del codificatore e del decodificatore offs = 0x0400 e auxOffs = 0. Questo ha particolare senso proprio nel caso della modalità stateless. In generale, sarà simile all'uso dell'antica codifica a otto bit, ma non priva della possibilità di inserire caratteri da tutto il Unicode secondo necessità.
Un ulteriore svantaggio, menzionato in precedenza, è che nel testo voluminoso codificato in UTF-C non c'è un modo rapido per trovare il confine di un carattere vicino a un qualsiasi byte. Tagliando dal buffer codificato gli ultimi, diciamo, 100 byte, rischiate di ottenere spazzatura con cui non potete fare niente. La codifica non è progettata per immagazzinare log di diversi gigabyte, ma in generale questo può essere sistemato. Byte 0xBF non dovrebbe mai apparire come primo byte (ma può essere il secondo o il terzo). Pertanto, durante la codifica, è possibile inserire una sequenza 0xBF 0xBF 0xBF ogni, diciamo, 10 Kb — così, se necessario, trovare il confine sarà sufficiente scansionare il pezzo selezionato finché non si trova un marcatore simile. Dopo l'ultimo 0xBF ci sarà garantito l'inizio di un carattere. (Durante la decodifica, questa sequenza di tre byte deve ovviamente essere ignorata.)
In sintesi
Se siete arrivati fino a qui, congratulazioni! Spero che, come me, abbiate appreso qualcosa di nuovo (o rinfrescato un ricordo) sul funzionamento di Unicode.
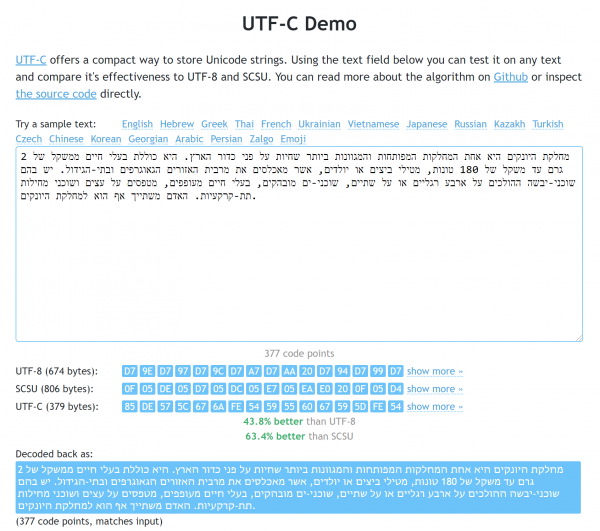
Pagina dimostrativa. Nell'esempio dell'ebraico sono visibili i vantaggi sia rispetto a UTF-8 che a SCSU.
Non considerare le ricerche sopra descritte come un'invasione degli standard. Tuttavia, sono complessivamente soddisfatto dei risultati delle mie scoperte e quindi felice di condividerli. : ad esempio, la libreria JS in forma minimizzata pesa solo 1710 byte (e non ha dipendenze, naturalmente). Come ho accennato prima, puoi vedere il suo funzionamento sulla (lì trovi anche un set di testi per confrontarla con UTF-8 e SCSU).
Infine, vorrei richiamare l'attenzione sui casi in cui usare UTF-C non vale la pena:
- Se le tue stringhe sono abbastanza lunghe (da 100 a 200 caratteri). In tal caso, dovresti considerare l'applicazione di algoritmi di compressione come deflate.
- Se hai bisogno di trasparenza ASCII, ossia se è importante che nelle sequenze codificate non compaiano codici ASCII che non erano nella stringa originale. Puoi evitare questa necessità se, interagendo con API esterne (per esempio, lavorando con un DB), trasmetti il risultato della codifica come un insieme astratto di byte, e non come stringhe. In caso contrario, rischi di incorrere in vulnerabilità impreviste.
- Se vuoi poter trovare rapidamente i confini dei caratteri per uno spostamento arbitrario (ad esempio, in caso di corruzione di parte della stringa). Questo è possibile solo scansionando la stringa dall'inizio (o applicando la modifica descritta nella sezione precedente).
- Se hai bisogno di eseguire rapidamente operazioni sul contenuto delle stringhe (ordinarle, cercare sottostringhe, concatenarle). In tal caso, è necessario prima decodificare le stringhe, quindi UTF-C sarà più lento di UTF-8 in questi casi (ma più veloce degli algoritmi di compressione). Poiché la stessa stringa è sempre codificata allo stesso modo, il confronto esatto della decodifica non è necessario e può essere eseguito byte per byte.
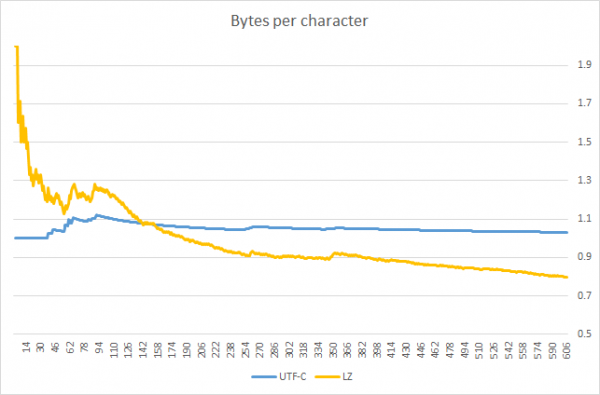
Aggiornamento: utente ha pubblicato un grafico che sottolinea il confine di applicabilità di UTF-C. Si vede che UTF-C è più efficiente dell'algoritmo di compressione generico (variazione LZW) fino a quando la stringa impacchettata è più corta ~140 caratteri (devo notare che il confronto è stato condotto su un testo; per altre lingue il risultato potrebbe essere diverso).
Fonte: habr.com
