

Ciao, amici di Habr. Continuiamo a condividere contenuti interessanti in vista del lancio dei nuovi corsi. Oggi, per voi, abbiamo tradotto un articolo su Google Cloud Spanner, in concomitanza con l’inizio del corso. .

Originariamente pubblicato su .
Come azienda che offre una vasta gamma di soluzioni POS cloud per rivenditori, ristoratori e venditori online in tutto il mondo, Lightspeed utilizza diversi tipi di piattaforme di database per vari casi d'uso transazionali, analitici e di ricerca. Ognuna di queste piattaforme ha i propri punti di forza e di debolezza. Pertanto, quando Google ha lanciato Cloud Spanner sul mercato, promettendo funzionalità mai viste prima nel mondo dei database relazionali, come quasi illimitata scalabilità orizzontale e un accordo sul livello di servizio (SLA) del 99,999%, non potevamo perdere l’opportunità di metterci le mani sopra!
Per fornire una panoramica completa della nostra esperienza con Cloud Spanner e dei criteri di valutazione che abbiamo utilizzato, esamineremo i seguenti argomenti:
- I nostri criteri di valutazione
- Cloud Spanner in poche parole
- La nostra valutazione
- Le nostre conclusioni

1. I nostri criteri di valutazione
Prima di approfondire le caratteristiche di Cloud Spanner, le sue somiglianze e differenze rispetto ad altre soluzioni sul mercato, parliamo prima dei principali casi d'uso che avevamo in mente quando consideravamo dove implementare Cloud Spanner nella nostra infrastruttura:
- Come sostituto (dominante) della tradizionale soluzione per database SQL
- Come soluzione OLTP con supporto OLAP
Nota: Per facilità e comodità di confronto, questo articolo confronta Cloud Spanner con le varianti MySQL delle famiglie di soluzioni GCP Cloud SQL e Amazon AWS RDS.
L'utilizzo di Cloud Spanner come sostituto della tradizionale soluzione per database SQL
Nell'ambito delle tradizionali banche dati, quando il tempo di risposta alle richieste del database si avvicina o addirittura supera i valori soglia definiti dall'applicazione (principalmente a causa dell'aumento del numero di utenti e/o richieste), esistono diversi modi per ridurre il tempo di risposta a livelli accettabili. Tuttavia, la maggior parte di queste soluzioni richiede un intervento manuale.
Ad esempio, il primo passo da compiere è esaminare le varie opzioni del database relative alle prestazioni e configurarle in modo che corrispondano al meglio ai modelli degli scenari di utilizzo delle applicazioni. Se ciò non dovesse essere sufficiente, è possibile optare per un'elevazione verticale o orizzontale del database.
L'elevazione verticale dell'applicazione implica l'aggiornamento dell'istanza del server, solitamente aumentando il numero di processori/core, la capacità di memoria RAM e le prestazioni dello storage, ecc. L'aggiunta di maggiori risorse hardware porta a un aumento delle prestazioni del database, misurato principalmente in transazioni al secondo e nella latenza delle transazioni per i sistemi OLTP. I sistemi di database relazionali (che utilizzano un approccio multithreading), come MySQL, scalano bene in verticale.
Questo approccio presenta diversi svantaggi, ma il più evidente è la dimensione massima del server disponibile sul mercato. Non appena si raggiunge il limite dell'istanza server più grande, l'unica soluzione rimasta è la scalabilità orizzontale.
La scalabilità orizzontale è un approccio in cui vengono aggiunti più server al cluster per idealmente aumentare linearmente le prestazioni con l'aggiunta di server. La maggior parte delle tradizionali dei sistemi di gestione dei database scalano male orizzontalmente o non scalano affatto. Ad esempio, MySQL può scalare orizzontalmente per le operazioni di lettura, aggiungendo lettori slave, ma non può scalare orizzontalmente per le operazioni di scrittura.
D'altra parte, grazie alla sua natura, Cloud Spanner può facilmente scalare orizzontalmente con il minimo intervento.
Un database come servizio deve essere valutato da diverse angolazioni. Come base, abbiamo preso il database più popolare nel cloud — Google Cloud SQL per Google e AWS RDS per Amazon. Nella nostra valutazione ci siamo concentrati sulle seguenti categorie:
- Corrispondenza delle funzionalità: estensione SQL, DDL, DML; librerie di connessione / connettori, supporto per le transazioni, e così via.
- Supporto allo sviluppo: facilità di sviluppo e testing.
- Supporto all'amministrazione: gestione delle istanze — ad esempio, scalabilità verticale/orizzontale e aggiornamenti delle istanze; SLA, backup e ripristino; sicurezza / controllo accesso.
Utilizzo di Cloud Spanner come soluzione OLTP con supporto OLAP
Sebbene Google non affermi esplicitamente che Cloud Spanner sia destinato all'elaborazione analitica, esso condivide alcune caratteristiche con altri processori, come Apache Impala & Kudu e YugaByte, progettati per carichi di lavoro OLAP.
Anche se ci fosse una piccola possibilità che Cloud Spanner integrasse un motore HTAP (elaborazione ibrida transazionale / analitica) orizzontalmente scalabile e con un set di funzionalità OLAP (più o meno) utilizzabile, riteniamo che meriterebbe la nostra attenzione.
Tenendo questo in mente, abbiamo considerato le seguenti categorie:
- Caricamento dati, indici e supporto per il partizionamento
- Prestazioni delle query e DML
2. Cloud Spanner in poche parole
Google Spanner è un sistema di gestione di database relazionali distribuiti (RDBMS) che Google utilizza per molti dei propri servizi. Google l'ha reso accessibile agli utenti di Google Cloud Platform all'inizio del 2017.
Ecco alcune delle caratteristiche di Cloud Spanner:
- Cluster RDBMS altamente coerente e scalabile: utilizza la sincronizzazione hardware del tempo per garantire la coerenza dei dati.
- Supporto delle transazioni cross-table: le transazioni possono coprire più tabelle e non devono necessariamente essere limitate a una sola tabella (a differenza di Apache HBase o Apache Kudu).
- Tabelle basate su chiavi primarie: tutte le tabelle devono avere una chiave primaria (PK) dichiarata, che può consistere in più colonne. I dati delle tabelle sono memorizzati in base alla PK, rendendoli molto efficienti e rapidi per la ricerca per PK. Come altre implementazioni basate su PK, la progettazione deve essere modellata tenendo conto di casi d'uso predefiniti per ottenere .
- Tabelle alternate: le tabelle possono avere dipendenze fisiche tra loro. Le righe della tabella figlia possono essere correlate alle righe della tabella genitore. Questo approccio accelera la ricerca delle relazioni che possono essere definite nella fase di modellazione dei dati, ad esempio, durante l'hosting congiunto dei clienti e delle loro fatture.
- Indici: Cloud Spanner supporta indici secondari. Un indice è composto da colonne indicizzate e tutte le colonne PK. Se desiderato, l'indice può includere anche altre colonne non indicizzate. L'indice può alternarsi alla tabella genitore per velocizzare le query. Aggiungono a questo, gli indici sono soggetti a varie restrizioni, come il numero massimo di colonne aggiuntive che possono essere memorizzate nell'indice. Inoltre, le query tramite indici potrebbero non essere così dirette come in altri RDBMS.
"Cloud Spanner seleziona l'indice automaticamente solo in rari casi. In particolare, Cloud Spanner non seleziona automaticamente un indice secondario se la query richiede colonne che non sono memorizzate in ».
- Accordo sul livello di servizio (SLA): distribuzione in una regione con SLA del 99,99%; distribuzioni multi-regionali con SLA del 99,999%. Anche se l'accordo sul livello di servizio è solo un accordo e non una garanzia, ritengo che i dipendenti di Google abbiano dati sufficienti per fare un'affermazione così seria. (Per riferimento, il 99,999% significa 26,3 secondi di inattività del servizio al mese.)
- Di più:
Nota: Il progetto Apache Tephra aggiunge supporto avanzato per le transazioni in Apache HBase (ora implementato anche in Apache Phoenix come versione beta).
3. La nostra valutazione
Quindi, abbiamo tutti letto le affermazioni di Google sui vantaggi di Cloud Spanner: scalabilità orizzontale praticamente illimitata mantenendo un'alta coerenza e un SLA molto elevato. Anche se questi requisiti sono estremamente difficili da raggiungere, il nostro obiettivo non era smentirli. Concentrati su altre cose che preoccupano la maggior parte degli utenti di database: integrità e facilità d'uso.
Abbiamo valutato Cloud Spanner come sostituto di Sharded MySQL
Google Cloud SQL e Amazon AWS RDS sono due dei sistemi di gestione di database relazionali (OLTP) più popolari nel mercato cloud, e offrono un ampio set di funzionalità. Tuttavia, per scalare questi database oltre le dimensioni di un singolo nodo, è necessario implementare il partitioning delle applicazioni. Questo approccio aggiunge complessità sia per le applicazioni che per la gestione. Abbiamo esaminato come Spanner si inserisce nello scenario della fusione di più segmenti in un'unica istanza e quali funzionalità (se ce ne sono) potrebbero dover essere sacrificate.
Supporto per SQL, DML e DDL, oltre a connettori e librerie?
Prima di tutto, quando si inizia con qualsiasi database, è necessario creare un modello di dati. Se pensi di poter collegare JDBC Spanner al tuo strumento SQL preferito, scoprirai che puoi interrogare i tuoi dati, ma non puoi usarlo per creare tabelle o fare modifiche (DDL) o per operazioni di inserimento/aggiornamento/cancellazione (DML). Il JDBC ufficiale di Google non supporta né l'uno né l'altro.
«Attualmente i driver non supportano operatori DML o DDL».
Documentazione Spanner
Con la console GCP la situazione non è migliore: puoi inviare solo query SELECT. Fortunatamente, esiste un driver JDBC con supporto per DML e DDL dalla comunità, incluso il supporto per le transazioni. Anche se questo driver è estremamente utile, sorprende l'assenza di un driver JDBC nativo di Google. Fortunatamente, Google offre un supporto piuttosto ampio per le librerie client (basate su gRPC): C#, Go, Java, node.js, PHP, Python e Ruby.
L'uso praticamente obbligatorio delle API personalizzate di Cloud Spanner (a causa dell'assenza di DDL e DML in JDBC) porta a alcune limitazioni per le aree di codice correlate, come i pool di connessione o i framework di binding del database (ad esempio, Spring MVC). In generale, quando si utilizza JDBC, è possibile scegliere liberamente il proprio pool di connessione preferito (ad esempio, HikariCP, DBCP, C3PO, ecc.) che è stato testato e funziona bene. Nel caso delle API personalizzate di Spanner, dobbiamo fare affidamento sui framework/pool di binding/sessione che abbiamo creato noi stessi.
La struttura basata sulla chiave primaria (PK) consente a Cloud Spanner di accedere ai dati molto rapidamente tramite la PK, ma porta anche ad alcuni problemi con le query.
- Non puoi aggiornare il valore di una chiave primaria; devi prima eliminare la registrazione con la PK originale e reinserirla con il nuovo valore. (Questo è simile ad altri database/storage basati su chiavi primarie.)
- Qualsiasi operatore UPDATE e DELETE deve specificare la PK nella clausola WHERE, quindi non possono esserci operatori DELETE all vuoti — deve sempre esserci una sottoquery, ad esempio: UPDATE xxx WHERE id IN (SELECT id FROM table1)
- Manca l'opzione di auto-incremento o qualcosa di simile che stabilisca una sequenza per il campo PK. Per funzionare, il valore corrispondente deve essere generato dal lato dell'applicazione.
Indici secondari?
Google Cloud Spanner ha un supporto integrato per gli indici secondari. Questa è una caratteristica molto apprezzata, che non è sempre presente in altre tecnologie. Apache Kudu attualmente non supporta affatto gli indici secondari, mentre Apache HBase non supporta gli indici direttamente, ma può aggiungerli tramite Apache Phoenix.
Gli indici in Kudu e HBase possono essere modellati come una tabella separata con una composizione diversa delle chiavi primarie, ma l'atomicità delle operazioni eseguite sulla tabella principale e sulle tabelle degli indici correlate deve essere gestita a livello di applicazione e non è banale in un'implementazione corretta.
Come accennato nella panoramica di Cloud Spanner, i suoi indici possono differire dagli indici di MySQL. Pertanto, è necessario prestare particolare attenzione nella costruzione delle query e nel profiling, per garantire l'uso dell'indice appropriato dove necessario.
Che ne dici delle viste?
Le viste sono oggetti molto popolari e utili nel database. Possono essere vantaggiose per un gran numero di casi d'uso; due dei miei preferiti sono il livello di astrazione logica e il livello di sicurezza. Sfortunatamente, Cloud Spanner NON supporta le viste. Tuttavia, questo ci limita solo parzialmente, poiché non ci sono dettagli a livello di colonna per le autorizzazioni di accesso, dove le viste potrebbero essere una soluzione accettabile.
Nella documentazione di Cloud Spanner, nella sezione che descrive in dettaglio le quote e i limiti (), c'è, in particolare, una che potrebbe essere problematica per alcune applicazioni: Cloud Spanner ha, di default, un limite massimo di 100 database per istanza. È evidente che questo può rappresentare un serio ostacolo per un database progettato per scalare oltre i 100 database. Fortunatamente, dopo aver parlato con il nostro rappresentante tecnico di Google, abbiamo scoperto che questo limite può essere aumentato praticamente a qualsiasi valore attraverso il supporto di Google.
Supporto per lo sviluppo?
Cloud Spanner offre un supporto piuttosto buono per i linguaggi di programmazione che lavorano con la sua API. Le librerie ufficialmente supportate sono in C#, Go, Java, node.js, PHP, Python e Ruby. La documentazione è abbastanza dettagliata, ma, come nel caso di altre tecnologie all'avanguardia, la comunità è piuttosto piccola rispetto alle tecnologie di database più popolari, il che può portare a un aumento del tempo necessario per risolvere casi d'uso o problemi meno comuni.
E quindi, che dire del supporto allo sviluppo locale?
Non siamo riusciti a trovare un modo per creare un'istanza di Cloud Spanner in un ambiente locale. L'approccio più simile che abbiamo ottenuto è un'immagine Docker , che in linea di principio è simile, ma nella pratica è molto diversa. Ad esempio, CockroachDB può utilizzare PostgreSQL JDBC. Poiché l'ambiente di sviluppo deve essere il più vicino possibile all'ambiente di produzione, Cloud Spanner non è ideale, poiché è necessario fare affidamento su un'istanza completa di Spanner. Per risparmiare costi, puoi optare per un'istanza per una sola regione.
Supporto per l'amministrazione?
Creare un'istanza di Cloud Spanner è molto semplice. È sufficiente scegliere tra la creazione di un'istanza multiregionale o di un'istanza per una sola regione, specificare la regione(e) e il numero di nodi. In meno di un minuto, l'istanza sarà avviata e pronta all'uso.
Diverse metriche di base sono direttamente disponibili sulla pagina di Spanner nella console di Google. Viste più dettagliate sono disponibili tramite Stackdriver, dove puoi anche impostare soglie per le metriche e le politiche di notifica.
Accesso alle risorse?
MySQL offre impostazioni di autorizzazione/ruoli utente ampie e molto dettagliate. È possibile configurare facilmente l'accesso a una tabella specifica o anche solo a un sottoinsieme delle sue colonne. Cloud Spanner utilizza lo strumento Google Identity & Access Management (IAM), che consente di stabilire politiche e autorizzazioni solo a livello molto elevato. L'opzione più dettagliata è l'autorizzazione a livello di database, che non si adatta alla maggior parte dei casi d'uso in produzione. Questa limitazione costringe ad aggiungere ulteriori misure di sicurezza nel proprio codice, infrastruttura o entrambi per prevenire l'uso non autorizzato delle risorse Spanner.
Backup?
In parole semplici, non ci sono backup in Cloud Spanner. Sebbene i rigorosi requisiti di SLA di Google possano garantire che non perderai dati a causa di guasti hardware o del database, ci sono comunque rischi dovuti a errori umani, difetti delle applicazioni, ecc. Sappiamo tutti che la regola è: un'alta disponibilità non sostituisce una strategia di backup adeguata. Attualmente, l'unico modo per eseguire il backup dei dati è attraverso la trasmissione in streaming delle informazioni dal database a un ambiente di archiviazione separato.
Prestazioni delle query?
Per caricare i dati e testare le query, abbiamo utilizzato Yahoo! Cloud Serving Benchmark. La tabella qui sotto mostra il carico di lavoro B di YCSB con un rapporto di lettura del 95% e scrittura del 5%.
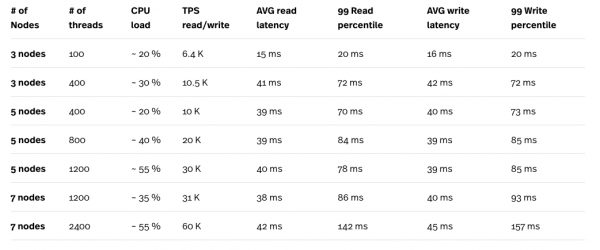
* Il test di carico è stato eseguito su un motore di calcolo (CE) n1-standard-32 (32 vCPU, 120 GB di memoria), e l'istanza di test non è mai stata un collo di bottiglia nei test.
** Il numero massimo di thread in un singolo esempio di YCSB è 400. È stato necessario avviare sei istanze parallele dei test YCSB per un totale di 2400 thread.
Osservando i risultati dei test, in particolare la combinazione del carico sulla CPU e TPS, vediamo chiaramente che Cloud Spanner scala abbastanza bene. L'elevato carico generato da un numero elevato di thread è compensato da un numero maggiore di nodi nel cluster di Cloud Spanner. Anche se la latenza appare piuttosto alta, soprattutto con 2400 thread, potrebbero essere necessari nuovi test con sei istanze inferiore del motore di calcolo per ottenere numeri più precisi. Ogni istanza eseguirà un test YCSB invece di un'unica grande istanza CE con sei test paralleli. In questo modo, sarà più facile distinguere tra la latenza delle richieste di Cloud Spanner e quella aggiunta dalla connessione di rete tra Cloud Spanner e l'istanza CE su cui viene eseguito il test.
Come si comporta Cloud Spanner come OLAP?
Partizionamento?
La suddivisione dei dati in segmenti fisicamente e/o logicamente indipendenti, noti come partizioni, è un concetto molto popolare presente nella maggior parte dei meccanismi OLAP. Le partizioni possono migliorare notevolmente le prestazioni delle query e la manutenibilità del database. Un approfondimento sulle partizioni meriterebbe un articolo a parte, quindi limitiamoci a menzionare l'importanza di avere uno schema di partizionamento e sub-partizionamento. La possibilità di suddividere i dati in partizioni e addirittura in sottopartizioni è fondamentale per le prestazioni delle query analitiche.
Cloud Spanner non supporta le partizioni come tali. Divide i dati al suo interno in quelli così detti split-i basati su intervalli di chiavi primarie. La suddivisione avviene automaticamente per bilanciare il carico nel cluster di Cloud Spanner. Una funzionalità molto utile di Cloud Spanner è la suddivisione del carico di base della tabella genitore (tabella che non interseca con un'altra). Spanner determina automaticamente se split i dati vengono letti più frequentemente rispetto ai dati in altri split-ha, e può prendere decisioni su ulteriori suddivisioni. In questo modo, possono essere coinvolti più nodi nella richiesta, il che aumenta anche efficacemente la larghezza di banda.
Caricamento dati?
Il metodo Cloud Spanner per il caricamento massivo dei dati è lo stesso del caricamento normale. Per ottenere le massime prestazioni, è necessario seguire alcune raccomandazioni, tra cui:
- Ordina i tuoi dati per chiave primaria.
- Dividili in 10*numero di nodi sezioni separate.
- Crea un insieme di attività lavorative che caricano i dati in parallelo.
Con questo tipo di caricamento dati, tutti i nodi di Cloud Spanner sono utilizzati.
Abbiamo utilizzato il carico di lavoro A YCSB per generare un set di dati di 10M righe.
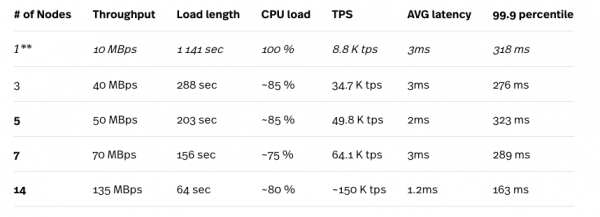
* Il test di carico è stato eseguito sul motore di calcolo n1-standard-32 (32 vCPU, 120 GB di memoria), e l'istanza di test non è mai stata un collo di bottiglia nei test.
** La configurazione con 1 nodo non è consigliata per nessun carico di lavoro produttivo.
Come accennato in precedenza, Cloud Spanner gestisce automaticamente gli split in base al loro carico, quindi i risultati migliorano dopo diversi passaggi consecutivi del test. I risultati presentati qui sono i migliori che abbiamo ottenuto. Guardando ai numeri sopra, possiamo vedere come Cloud Spanner scala (bene) con l'aumento del numero di nodi nel cluster. I numeri che spiccano rappresentano latenze medie estremamente basse, che contrastano con i risultati dei carichi di lavoro misti (95% lettura e 5% scrittura), come descritto nella sezione sopra.
Scalabilità?
Aumentare e diminuire il numero di nodi in Cloud Spanner è un compito che si svolge con un solo clic. Se desideri caricare rapidamente i dati, puoi considerare di aumentare l'istanza al massimo (nel nostro caso erano 25 nodi nella regione US-EAST), per poi ridurre il numero di nodi a quello più adatto al tuo carico abituale, tenendo presente il limite di 2 TB per nodo.
Ci è stato ricordato di questo limite anche con un database molto più piccolo. Dopo diverse esecuzioni di test di carico, il nostro database aveva una dimensione di circa 155 GB e riducendo a un'istanza singola abbiamo ricevuto il seguente errore:
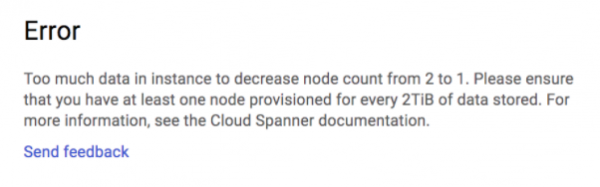
Siamo riusciti a ridurre la scalabilità da 25 a 2 istanze, ma siamo rimasti bloccati su due nodi.
L'aumento e la diminuzione del numero di nodi nel cluster Cloud Spanner possono essere automatizzati tramite REST API. Questo può essere particolarmente utile per ridurre il carico elevato sul sistema durante le ore di punta.
Qual è la performance delle query OLAP?
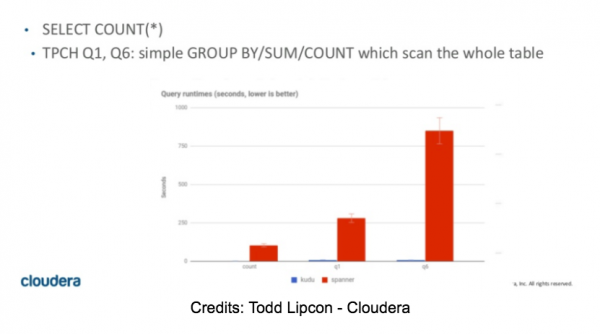
Inizialmente, avevamo pianificato di dedicare un tempo significativo alla nostra valutazione di Spanner in questa parte. Dopo diverse SELECT COUNT, ci siamo subito resi conto che il test sarebbe stato breve e che Spanner NON sarebbe stato adatto come motore OLAP. Indipendentemente dal numero di nodi nel cluster, la semplice selezione del numero di righe in una tabella di 10M righe ha impiegato da 55 a 60 secondi. Inoltre, qualsiasi query che richiedeva una maggiore quantità di memoria per memorizzare i risultati intermedi è terminata con un errore OOM.
SELECT COUNT(DISTINCT(field0)) FROM usertable; — (10M valori distinti) -> SpoolingHashAggregateIterator esaurito durante la creazione della nuova riga.
Alcuni numeri per le query TPC-H possono essere trovati nell'articolo di Todd Lipcon , diapositive 42 e 43. Questi numeri sono in linea con i nostri risultati (sfortunatamente).
4. Le nostre conclusioni
Date le attuali funzionalità di Cloud Spanner, è difficile immaginare una semplice sostituzione per le soluzioni OLTP esistenti, specialmente quando le vostre esigenze supereranno le sue capacità. Sarebbe necessario investire un tempo considerevole per costruire una soluzione tenendo conto delle limitazioni di Cloud Spanner.
Quando abbiamo iniziato a valutare Cloud Spanner, ci aspettavamo che le sue funzionalità di gestione fossero a livello, o comunque non molto distanti da altre soluzioni Google SQL. Ma siamo rimasti sorpresi dalla completa mancanza di backup e dal controllo degli accessi ai risorse molto limitato. Per non parlare dell'assenza di viste, della mancanza di un ambiente di sviluppo locale, di sequenze non supportate, JDBC senza supporto per DML e DDL e così via.
Quindi, dove può andare chi deve scalare un database transazionale? Sembra che attualmente sul mercato non ci sia una soluzione unica adatta a tutti gli use case. Ci sono molte soluzioni sia open che closed source (alcune delle quali menzionate in questo articolo), ognuna con i propri punti di forza e di debolezza, ma nessuna di esse offre un SaaS con SLA del 99,999% e un alto grado di coerenza. Se un alto livello di SLA è il tuo obiettivo principale e non sei inclino a costruire una soluzione personalizzata per diversi ambienti cloud, Cloud Spanner potrebbe essere la risposta che cerchi. Ma devi essere consapevole di tutte le sue limitazioni.
A scopo di giustizia, è importante notare che Cloud Spanner è stato reso disponibile al pubblico solo nella primavera del 2017, quindi è ragionevole aspettarsi che alcuni dei suoi attuali difetti possano eventualmente scomparire (si spera), e quando ciò accadrà, potrebbe cambiare il gioco. Dopotutto, Cloud Spanner non è solo un progetto esterno per Google. Google lo utilizza come base per altri prodotti Google. E quando Google ha recentemente sostituito Megastore in Google Cloud Storage con Cloud Spanner, ciò ha reso Google Cloud Storage rigorosamente coerente per gli elenchi di oggetti a livello globale (cosa che non si applica ancora a ).
Quindi, c'è ancora speranza… noi speriamo.
Questo è tutto. Proprio come l'autore dell'articolo, noi continuiamo a sperare, e cosa ne pensi tu? Scrivi nei commenti
Tutti coloro che sono interessati sono invitati a visitare il nostro nel quale parleremo in dettaglio del corso di OTUS.
Fonte: habr.com
