

Tutti parlano dei processi di sviluppo e test, della formazione del personale, dell'aumento della motivazione, ma questi processi sono pochi quando un minuto di inattività del servizio costa cifre da capogiro. Cosa fare quando si effettuano transazioni finanziarie con un rigoroso SLA? Come aumentare l'affidabilità e la tolleranza ai guasti dei vostri sistemi, escludendo sviluppo e test?

La prossima conferenza HighLoad++ si svolgerà il 6 e 7 aprile 2020 a San Pietroburgo. Maggiori dettagli e biglietti su . 9 novembre, 18:00. HighLoad++ Moscow 2018, sala "Delhi + Calcutta". Le tesi e .
Eugenio Kuzovlev (d'ora in poi – EK): – Amici, ciao! Mi chiamo Kuzovlev Eugenio. Vengo da EcommPay, specificamente dal dipartimento EcommPay IT, il dipartimento IT del gruppo. Oggi parleremo dei downtime – di come evitarli e di come minimizzare le loro conseguenze, se non si riesce ad evitarli. Il tema è dichiarato così: «Cosa fare quando un minuto di inattività costa 100000 dollari»? Le nostre cifre sono comparabili.
Cosa fa EcommPay IT?
Chi siamo? Perché sono qui davanti a voi? Perché ho il diritto di raccontarvi qualcosa? E di cosa parleremo più nel dettaglio?
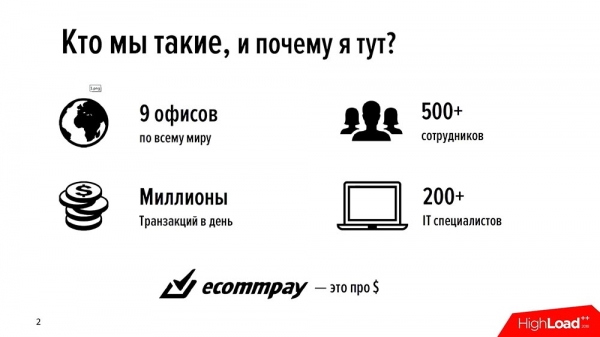
Il gruppo EcommPay è un acquirente internazionale. Gestiamo pagamenti in tutto il mondo - in Russia, Europa, e nel Sud-est asiatico (All Around the World). Abbiamo 9 uffici, 500 dipendenti in totale e circa la metà di loro sono tecnici IT. Tutto ciò che facciamo, tutto su cui guadagniamo, lo abbiamo creato noi stessi.
Tutti i nostri prodotti (e ne abbiamo abbastanza – nella nostra linea di grandi prodotti IT abbiamo circa 16 componenti diversi) li abbiamo scritti noi; noi stessi li sviluppiamo. Attualmente gestiamo circa un milione di transazioni al giorno (probabilmente sarebbe corretto dire milioni). Siamo un'azienda relativamente giovane – abbiamo circa sei anni.
Sei anni fa eravamo una startup, quando ragazzi sono arrivati con un'idea di business. Erano uniti da un'idea (non c'era nient'altro, solo l'idea), e noi abbiamo iniziato. Come ogni startup, correvamo più velocemente… Per noi la velocità era più importante della qualità.
A un certo punto ci siamo fermati: abbiamo realizzato che non potevamo più vivere con la stessa velocità e qualità, e che dovevamo concentrarci prima di tutto sulla qualità. In quel momento abbiamo deciso di sviluppare una nuova piattaforma, che fosse corretta, scalabile e affidabile. Abbiamo iniziato a scrivere questa piattaforma (iniziato a investire, sviluppare, testare), ma a un certo punto abbiamo capito che lo sviluppo e il collaudo non ci consentivano di raggiungere un nuovo livello di qualità del servizio.
Stai creando un nuovo prodotto e lo metti in produzione, ma ci sarà sempre qualcosa che non andrà come previsto. Oggi parleremo di come raggiungere un nuovo livello di qualità (come ci siamo riusciti, la nostra esperienza), lasciando da parte lo sviluppo e il collaudo; discuteremo di cosa è accessibile all'operazione – cosa può fare l'operazione stessa, cosa può offrire ai collaudi per influenzare la qualità.
Downtime. Le massime dell'operazione.
La questione centrale di cui parleremo oggi è il downtime. Una parola temuta. Quando si verifica un downtime, significa che le cose non vanno bene. Ci affrettiamo a porvi rimedio, gli amministratori cercano di mantenere i server attivi – sperando che non collassino, come dice la canzone. Su questo tema discuteremo oggi.

Quando abbiamo iniziato a cambiare il nostro approccio, abbiamo formulato 4 comandamenti. Li ho presentati nelle slide:
Questi comandamenti sono piuttosto semplici:

- Identificare rapidamente il problema.
- Eliminare il problema ancora più rapidamente.
- Aiutare a capire la causa (poi, per gli sviluppatori).
- E standardizzare gli approcci.
Vorrei richiamare la vostra attenzione sul punto n. 2. Ci liberiamo del problema, non lo risolviamo. Risolvere è un aspetto secondario. Per noi è fondamentale garantire che l'utente sia protetto da questo problema. Esisterà in un certo ambiente isolato, ma questo ambiente non avrà alcun contatto con lui. Oggi esploreremo queste quattro categorie di problemi (alcuni in dettaglio, altri meno), e vi racconterò quali soluzioni utilizziamo e quale esperienza abbiamo in merito.
Risoluzione dei problemi: quando si verificano e cosa fare?
Ma non iniziamo dall'inizio, iniziamo dal punto n. 2: come risolvere rapidamente il problema? C'è un problema e dobbiamo affrontarlo. "Cosa facciamo a riguardo?" è la domanda principale. E quando abbiamo iniziato a pensare a come risolvere il problema, abbiamo identificato alcuni requisiti che deve seguire la risoluzione dei problemi.

Per formulare questi requisiti, abbiamo deciso di porci la domanda: "Quando si presentano problemi?" E i problemi, come si è scoperto, si verificano in quattro casi:

- Guasto hardware.
- Malfunzionamento dei servizi esterni.
- Cambio di versione del software (il famigerato deploy).
- Crescita esplosiva del carico.
Non parleremo dei primi due. Il guasto hardware è piuttosto semplice da risolvere: tutto deve essere ridondante. Se si tratta di dischi, i dischi devono essere configurati in RAID; se è un server, il server deve essere ridondato; se avete un'infrastruttura di rete, dovete installare una seconda copia dell'infrastruttura di rete, quindi duplicare. E se qualcosa va in avaria, passate alle risorse di riserva. È difficile dire di più.
Il secondo motivo è il malfunzionamento dei servizi esterni. Per la maggior parte, questo non rappresenta un problema per il sistema, ma non per noi. Poiché gestiamo i pagamenti, siamo un aggregatore che si trova tra l'utente (che immette i propri dati della carta) e le banche, i sistemi di pagamento (come "Visa", "MasterCard", "Mir" e simili). I nostri servizi esterni (sistemi di pagamento, banche) possono subire interruzioni. Non possiamo influenzare questo, né voi (se avete tali servizi).
Cosa fare allora? Qui ci sono due opzioni. Prima di tutto, se possibile, dovreste duplicare questo servizio in qualche modo. Ad esempio, noi, se possiamo, reindirizziamo il traffico da un servizio a un altro: se elaboriamo carte tramite "Sberbank" e ci sono problemi con "Sberbank", reindirizziamo il traffico [in modo ipotetico] su "Raiffeisen". In secondo luogo, possiamo identificare rapidamente i malfunzionamenti dei servizi esterni, quindi parleremo della rapidità di reazione nella prossima sezione della presentazione.
In effetti, di queste quattro variabili possiamo influenzare in modo specifico il cambio delle versioni del software, intraprendendo azioni che porteranno a un miglioramento della situazione nel contesto dei deployment e della crescita esponenziale del carico. Infatti, è proprio ciò che abbiamo fatto. Qui, ancora una volta, una piccola nota…
Di questi quattro problemi, alcuni si risolvono immediatamente se si utilizza un cloud. Se sei su servizi come "Microsoft Azure", "Ozone", utilizzi i nostri servizi cloud di "Yandex" o "Mail.ru", allora almeno il guasto hardware diventa un problema loro e tu hai subito una situazione migliore riguardo a questo guasto.
Siamo un'azienda un po' atipica. Qui tutti parlano di "Kubernetes" e cloud – noi non abbiamo né "Kubernetes" né cloud. Tuttavia, abbiamo rack con hardware in molti data center, e su questo hardware siamo costretti a operare, siamo responsabili di tutto ciò. Quindi, in questo contesto, parleremo. Passando ai problemi, le prime due le abbiamo escluse.
Cambio versione software. Database
I nostri sviluppatori non hanno accesso alla produzione. Perché? Semplicemente siamo certificati PCI DSS e i nostri sviluppatori non hanno il diritto di entrare in produzione. Punto. Assolutamente. Pertanto, la responsabilità dello sviluppo finisce nel momento esatto in cui il progetto viene consegnato per il rilascio.

La nostra seconda base, che ci aiuta molto, è l'assenza di conoscenze uniche non documentate. Spero che sia lo stesso per voi. Perché, se non è così, avrete problemi. I problemi si presenteranno quando queste conoscenze uniche non documentate non saranno disponibili nel momento e nel luogo giusti. Supponiamo che una persona sappia come fare il deploy di un componente specifico - se quella persona non c'è, perché è in ferie o malata - avrete dei problemi.
Ecco la nostra terza base, alla quale siamo arrivati attraverso il dolore, il sangue e le lacrime: abbiamo capito che ogni nostro progetto contiene errori, anche se non ne mostra. Abbiamo deciso che, quando facciamo un deploy, quando lanciamo qualcosa in produzione, il nostro progetto avrà degli errori. Abbiamo definito i requisiti che il nostro sistema deve soddisfare.
Requisiti per la modifica della versione del software
Ci sono tre requisiti:

- Dobbiamo ripristinare rapidamente il deployment.
- Dobbiamo ridurre al minimo l'impatto di un deployment non riuscito.
- E dobbiamo poter effettuare un nuovo deployment rapidamente in parallelo.
Proprio in questo ordine! Perché? Perché, prima di tutto, quando si effettua il deployment di una nuova versione la velocità non è importante, ma è fondamentale per voi poter tornare indietro velocemente se qualcosa va storto e avere un impatto minimo. Ma se avete un insieme di versioni in produzione e si scopre che contengono un errore (come un fulmine a ciel sereno, non c'è stato alcun deployment, ma l'errore è presente) — la velocità del successivo deployment diventa importante. Cosa abbiamo fatto per soddisfare questi requisiti? Abbiamo adottato questa metodologia:
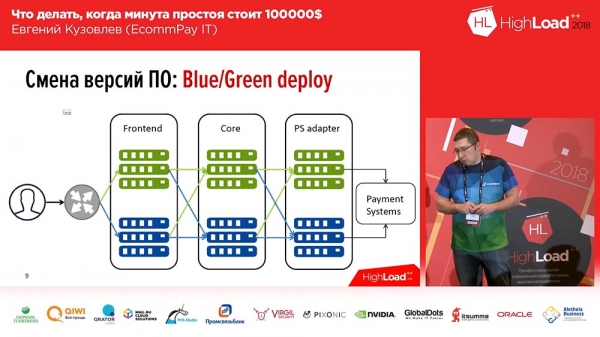
È piuttosto conosciuto, non l'abbiamo mai inventato: si tratta del deploy Blue/Green. Di cosa si tratta? Per ogni gruppo di server su cui sono in esecuzione le vostre applicazioni, dovete avere una copia. Una copia "calda": non riceve traffico, ma in qualsiasi momento quel traffico può essere inviato a questa copia. Questa copia contiene la versione precedente. Al momento del deploy, rilasciate il codice su una copia inattiva. Poi reindirizzate parte del traffico (o tutto) sulla nuova versione. In questo modo, per modificare il flusso di traffico dalla versione precedente a quella nuova, è necessaria una sola azione: dovete cambiare il bilanciatore upstream, modificare la direzione – da un upstream all'altro. È molto comodo e risolve il problema del rapido switch e del rapido rollback.Qui c'è anche la soluzione al secondo problema: la minimizzazione. Puoi indirizzare solo una parte del tuo traffico (ad esempio, il 2%) verso una nuova linea con un nuovo codice. E questi 2% non sono il 100%! Se hai perso il 100% del traffico a causa di un deploy non riuscito, è spaventoso; se hai perso solo il 2%, è sgradevole, ma non è una catastrofe. Inoltre, gli utenti probabilmente non se ne accorgono nemmeno, perché in alcuni casi (non in tutti), lo stesso utente, premendo F5, accederà a un'altra versione funzionante.
Deploy Blue/Green. Routing
Tuttavia, non è così semplice come dire "Facciamo il Blue/Green deployment"... Tutti i nostri componenti possono essere suddivisi in tre gruppi:
- il frontend (pagine di pagamento che vedono i nostri clienti);
- il core di elaborazione;
- un adattatore per lavorare con i sistemi di pagamento (banche, Mastercard, Visa...).
E qui c'è una sfumatura: la sfumatura riguarda il routing tra le linee. Se semplicemente reindirizzi il 100% del traffico, non hai questi problemi. Ma se vuoi reindirizzare il 2%, sorgono domande: «Come si fa?» La soluzione più semplice è quella diretta: puoi configurare una selezione casuale, Round Robin in nginx, e avere il 2% a sinistra, 98% a destra. Tuttavia, ciò non è sempre adeguato.
Ad esempio, un utente interagisce con il sistema non attraverso una sola richiesta. È normale: 2, 3, 4, 5 richieste – i tuoi sistemi possono essere uguali. E se è importante che tutte le richieste dell'utente arrivino sulla stessa linea su cui è arrivata la prima richiesta, oppure (secondo punto) che tutte le richieste dell'utente arrivino su una nuova linea dopo la commutazione (potrebbe aver iniziato a lavorare con il sistema prima della commutazione), allora questa distribuzione casuale non è adatta. Ci sono quindi le seguenti opzioni:
La prima opzione, la più semplice, si basa sui parametri di base del cliente (IP Hash). Hai un IP e dividi il traffico a destra e a sinistra in base a questo indirizzo. In questo modo, si verificherà il secondo caso che ho descritto, in cui è avvenuto il deploy e l'utente ha già iniziato a lavorare con il tuo sistema; da quel momento, tutte le richieste andranno sulla nuova linea (la stessa, diciamo).Se per qualche motivo questa soluzione non ti soddisfa e hai necessariamente bisogno di inviare richieste alla stessa linea da cui è arrivata la richiesta iniziale dell'utente, allora hai due opzioni...
La prima opzione: puoi utilizzare un nginx+ a pagamento. Dispone di un meccanismo di Sticky sessions, che, all'atto della richiesta iniziale dell'utente, assegna una sessione all'utente e la collega a un determinato upstream. Tutte le richieste successive dell'utente, nell'ambito della durata della sessione, verranno inviate allo stesso upstream a cui è stata assegnata la sessione.Questo non ci ha convinto, perché avevamo già un normale nginx. Passare a nginx+ non era tanto costoso, ma per noi è stato doloroso e non molto corretto. Le "Sticky Sessions", per esempio, non hanno funzionato per il semplice motivo che "Sticky Sessions" non consentono di instradare in base al criterio "O-O". È possibile impostare che utilizziamo "Sticky Sessions" in base all'indirizzo IP o all'indirizzo IP e ai cookie o ai parametri POST, ma la logica "O-O" è già più complessa.
Pertanto, siamo arrivati alla quarta opzione. Abbiamo scelto nginx "potenziato" (questo è openresty) – è lo stesso nginx, ma supporta anche l'inclusione di script last. Puoi scrivere uno script last, darlo in pasto a questo "openresty", e questo last script verrà eseguito quando arriverà una richiesta dall'utente.
E abbiamo effettivamente scritto un piccolo script, installato "openresty" e in questo script elaboriamo 6 parametri diversi tramite concatenazione "O-O". A seconda della presenza di uno dei parametri, sappiamo che l'utente è arrivato su una pagina o su un'altra, su una linea o su un'altra.
Deploy Blue/Green. Vantaggi e svantaggi
Certo, si sarebbe potuto fare forse in modo più semplice (usando ad esempio 'Sticky Sessions'), ma abbiamo anche un particolare aspetto, poiché non è solo l'utente a interagire durante l'elaborazione di una singola transazione... Ma interagiscono con noi anche i sistemi di pagamento: noi, dopo aver elaborato la transazione (inviando la richiesta al sistema di pagamento), riceviamo un callback.
E supponiamo che all'interno della nostra rete possiamo passare l'indirizzo IP dell'utente in tutte le richieste e, sulla base dell'indirizzo IP degli utenti, fare delle suddivisioni, non possiamo dire a 'Visa': 'Ragazzi, siamo questa retroazienda, sembriamo internazionali (sul sito e in Russia)... E per favore, passateci l'indirizzo IP dell'utente in un campo aggiuntivo, il vostro protocollo è standardizzato'! È ovvio che non accetteranno.
Pertanto, per noi non andava bene – abbiamo utilizzato openresty. Di conseguenza, per quanto riguarda il routing, abbiamo organizzato le cose in questo modo:Il 'Blue/Green deployment' ha, naturalmente, vantaggi, di cui ho parlato, e svantaggi.
Gli svantaggi sono due:
- dovete occuparvi del routing;
- il secondo principale svantaggio sono le spese.
Hai bisogno di avere il doppio dei server, hai bisogno di avere il doppio delle risorse operative, hai bisogno di spendere il doppio delle energie per gestire tutto questo zoo.
A proposito, tra i vantaggi, ce n'è un altro di cui non ho parlato prima: hai una riserva in caso di aumento del carico. Se hai un'esplosione di carico, se un gran numero di utenti ti sta investendo, puoi semplicemente attivare una seconda linea con una distribuzione 50 su 50 – e avrai subito il doppio dei server nel tuo cluster, fino a quando non risolvi il problema della disponibilità dei server.
Come fare un rapido deploy?
Abbiamo parlato di come risolvere il problema della minimizzazione e del rapido rollback, ma la domanda rimane: «Come è possibile fare un deploy veloce»?
Qui è tutto semplice e conciso.- Devi avere un sistema di CD (Continuous Delivery) – senza di esso, non si va da nessuna parte. Se hai un solo server, puoi fare il deploy manualmente. Noi abbiamo circa millecinquecento server e ovviamente non possiamo farlo manualmente, potremmo mettere in piedi un'intera squadra delle dimensioni di questa sala solo per fare i deploy.
- Il deployment deve essere parallelo. Se il vostro deployment è sequenziale, la situazione è grave. Un server va bene, ma con millecinquecento server ci vorrete un'intera giornata per il deployment.
- Ancora, per velocizzare, questo non è più necessario, probabilmente. Durante il deployment, di solito viene eseguita la build del progetto. Avete un progetto web, c'è la parte frontend (lì create il webpack, utilizzate npm per la build – qualcosa del genere), e questo processo in linea di massima è breve – circa 5 minuti, ma questi 5 minuti possono essere critici. Perciò, noi per esempio non lo facciamo così: abbiamo eliminato questi 5 minuti e stiamo deployando gli artifact.
Cos'è un artefatto? Un artefatto è una build compilata, in cui è già stata eseguita tutta la parte di assemblaggio. Questo artefatto lo conserviamo nel repository degli artefatti. In passato abbiamo utilizzato due di questi repository: Nexus e ora jFrog Artifactory. Inizialmente abbiamo usato «Nexus» perché abbiamo cominciato a praticare questo approccio nelle applicazioni Java (era molto adatto). Poi abbiamo inserito anche alcune applicazioni scritte in PHP; e «Nexus» non era più adatto, quindi abbiamo scelto jFrog Artifactory, che è in grado di gestire praticamente tutto. Siamo arrivati persino a conservare in questo repository artefatti i nostri pacchetti binari, che costruiamo per i server.
Crescita esplosiva del carico
Abbiamo discusso del cambio di versione del software. La prossima cosa di cui abbiamo è la crescita esplosiva del carico. Qui, probabilmente, intendo qualcosa di sbagliato per crescita esplosiva del carico...
Abbiamo sviluppato un nuovo sistema: è orientato ai servizi, elegante e bello, con worker ovunque, code ovunque, e asynchrony ovunque. In tali sistemi, i dati possono seguire flussi diversi. Per la prima transazione possono essere utilizzati il 1°, il 3° e il 10° worker, per la seconda transazione – il 2°, il 4° e il 5°. E oggi, ad esempio, al mattino hai un flusso di dati che coinvolge i primi tre worker, ma la sera cambia drasticamente e tutti utilizzano altri tre worker.
E qui si presenta la necessità di scalare i worker, di scalare i tuoi servizi, senza però gonfiare le risorse.
Abbiamo definito per noi dei requisiti. Questi requisiti sono abbastanza semplici: deve esserci Service discovery, parametrizzazione – tutto standard per costruire tali sistemi scalabili, tranne per un punto: l'amortamento delle risorse. Abbiamo dichiarato che non siamo pronti ad amortizzare le risorse per far scaldare l'aria dei server. Abbiamo adottato 'Consul' e 'Nomad', che gestiscono i nostri worker.Perché è un problema per noi? Facciamo un passo indietro. Attualmente abbiamo circa 70 sistemi di pagamento. La mattina, il traffico passa attraverso "Sberbank", poi, ad esempio, "Sberbank" va giù e lo reindirizziamo a un altro sistema di pagamento. Abbiamo avuto 100 lavoratori attivi fino a "Sberbank", e dopo dobbiamo rapidamente aumentare 100 lavoratori per un altro sistema di pagamento. E tutto questo dovrebbe idealmente avvenire senza intervento umano. Perché, se c'è partecipazione umana, un ingegnere dovrebbe essere presente 24/7 solo per questo, poiché tali guasti, con 70 sistemi attivi, si verificano regolarmente.
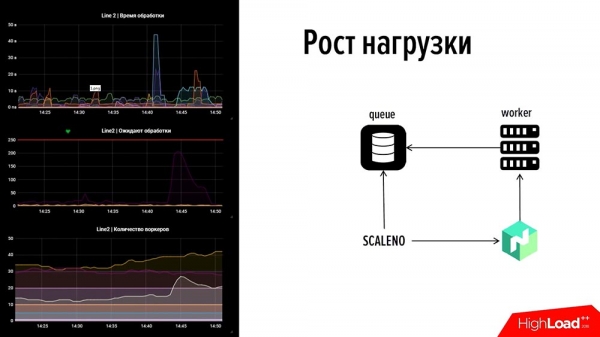
Perciò abbiamo esaminato "Nomad", che ha un IP pubblico, e abbiamo scritto la nostra soluzione Scale-Nomad – ScaleNo, che fa più o meno quanto segue: monitora la crescita della coda e riduce o aumenta il numero di lavoratori a seconda della dinamica della coda. Una volta fatto, ci siamo chiesti: "Forse potremmo renderla open source?" Poi l'abbiamo guardata e ci siamo resi conto che era semplicissima.
Finora non l'abbiamo open-sourced, ma se dopo la presentazione, dopo aver capito che avete bisogno di una cosa del genere, vi sorgesse la necessità, nell'ultima diapositiva ci sono i miei contatti: vi prego di scrivermi. Se si raccoglieranno almeno 3-5 persone, lo daremo in open source.
Come funziona? Diamo un'occhiata! Anticipando: a sinistra c'è un pezzo del nostro monitoraggio: c'è una linea, in alto – il tempo di elaborazione degli eventi, al centro – il numero di transazioni, in basso – il numero di worker.Se guardiamo questa immagine, c'è un guasto. Nel grafico superiore uno dei grafici è andato fuori scala dopo 45 secondi – uno dei sistemi di pagamento è andato in crisi. Qui è stato mostrato il traffico per 2 minuti e si è visto un aumento della coda in un altro sistema di pagamento, dove non c'erano worker (non abbiamo utilizzato le risorse – al contrario, abbiamo gestito le risorse correttamente). Non volevamo sovraccaricarli – c'era un numero minimo, circa 5-10 worker, ma non erano in grado di farcela.
Nel grafico finale si può vedere un «gobbo», che indica proprio che «Scaleno» ha raddoppiato questo numero. E poi, quando il grafico è leggermente calato, ha ridotto un po' – il numero di lavoratori è stato modificato automaticamente. Ecco come funziona questa cosa. Abbiamo parlato del punto n. 2 – «Come liberarsi rapidamente delle cause».
Monitoraggio. Come identificare rapidamente un problema?
Ora, il primo punto è – «Come identificare rapidamente un problema?» Monitoraggio! Dobbiamo comprendere rapidamente alcune cose. Quali cose dobbiamo comprendere rapidamente?
Tre cose!- Dobbiamo comprendere rapidamente e monitorare l'affidabilità delle nostre risorse.
- Dobbiamo monitorare rapidamente il guasto, controllare la funzionalità dei sistemi esterni per noi.
- Il terzo punto è l'individuazione degli errori logici. Questo succede quando il sistema funziona per voi, tutti i parametri sono a posto, ma qualcosa non va.
Qui probabilmente non dirò niente di particolarmente interessante. Sarò il capitano Evidente. Abbiamo cercato cosa c'è sul mercato. È emerso un «zoo divertente». Ecco quale zoo abbiamo attualmente:
Utilizziamo "Zabbix" per monitorare l'hardware e i principali parametri dei server. "Okmeter" è impiegato per i database. "Grafana" e "Prometheus" li usiamo per tutti gli altri parametri che non rientrano nelle prime due categorie, parte con "Grafana" e "Prometheus", parte con "Grafana" insieme a "Influx" e Telegraf.Un anno fa volevamo utilizzare New Relic. È uno strumento fantastico, fa tutto. Ma quanto più è versatile, tanto più è costoso. Quando siamo cresciuti fino a 1.500 server, ci ha contattato un venditore dicendo: "Facciamo un contratto per l'anno prossimo". Abbiamo esaminato i costi, e abbiamo deciso di non procedere. Adesso stiamo abbandonando "New Relic", ci sono rimasti circa 15 server sotto monitoraggio con "New Relic". Il prezzo si è rivelato completamente esorbitante.
Esiste uno strumento che abbiamo realizzato noi stessi: il Debugger. Inizialmente lo chiamavamo «Bagger», ma poi un nostro insegnante di inglese ha riso di gusto e lo abbiamo rinominato «Debugger». Di cosa si tratta? È uno strumento che in 15-30 secondi, come una «scatola nera» del sistema, avvia test per verificare la funzionalità di un componente.
Ad esempio, se si tratta di una pagina esterna (pagina di pagamento), semplicemente la apre e verifica come dovrebbe apparire. Se si tratta di un processo di elaborazione, invia una «transazione» di prova e controlla che questa «transazione» venga completata. Se riguarda la connessione con i sistemi di pagamento, inviamo una richiesta di prova dove possibile e verifichiamo che tutto funzioni correttamente.
Quali metriche sono importanti per il monitoraggio?
Cosa monitoriamo principalmente? Quali indicatori sono importanti per noi?
- Il tempo di risposta / RPS sui frontend è un indicatore molto importante. Indica immediatamente se c'è qualcosa che non va.
- Il numero di messaggi elaborati in tutte le code.
- Il numero di worker.
- Metriche principali di correttezza.
L'ultimo punto riguarda la metrica "business". Se desideri monitorare qualcosa di simile, devi definire una o due metriche che rappresentano i tuoi indicatori principali. Per noi, questa metrica è la conversione (cioè il rapporto tra il numero di transazioni riuscite e il flusso totale di transazioni). Se qualcosa cambia in questa metrica nell'arco di 5-10-15 minuti, significa che abbiamo dei problemi (se il cambiamento è significativo).
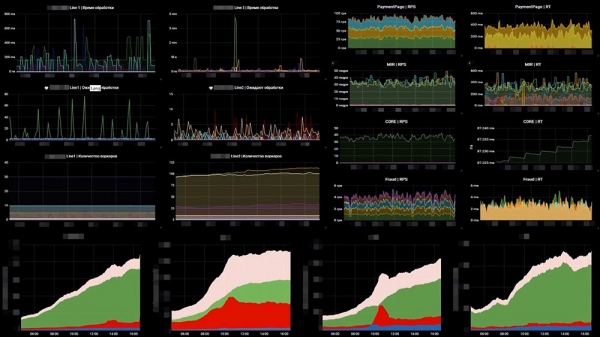
Ecco come si presenta da noi – un esempio delle nostre dashboard:
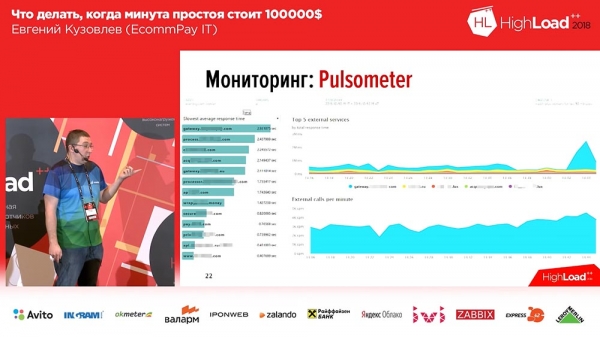
Sul lato sinistro – 6 grafici, che mostrano rispettivamente il numero di lavoratori e il numero di messaggi nelle code. A destra – RPS, RTS. In basso – la nostra metrica "business". E nella metrica "business" possiamo subito vedere che qualcosa è andato storto in due grafici centrali… È proprio qui che un altro sistema che ci supporta è andato giù.La seconda cosa che dovevamo fare era monitorare il malfunzionamento dei sistemi di pagamento esterni. Qui abbiamo adottato OpenTracing – un meccanismo, uno standard, una parodia che consente di tracciare sistemi distribuiti; e lo abbiamo un po' modificato. La parodia standard di OpenTracing prevede di costruire la tracciabilità di ogni singola richiesta. Non ne avevamo bisogno, quindi abbiamo implementato una tracciabilità aggregata. Abbiamo creato uno strumento che ci consente di monitorare la velocità dei sistemi che ci supportano.
Il grafico ci mostra che uno dei sistemi di pagamento ha iniziato a rispondere in 3 secondi – abbiamo cominciato ad avere problemi. Inoltre, questo sistema reagirà quando insorgono problemi, nel giro di 20-30 secondi.Il terzo tipo di monitoraggio degli errori è il monitoraggio logico.
Onestamente, non sapevo cosa disegnare in questa diapositiva, perché abbiamo cercato a lungo sul mercato qualcosa che si adattasse alle nostre esigenze. Non abbiamo trovato nulla, quindi abbiamo dovuto crearne uno noi.
Cosa intendo per monitoraggio logico? Immaginate di creare un sistema, come un clone di Tinder; lo sviluppate e lo lanciate. Il manager, Vasya Pupkin, lo installa sul suo telefono, vede una ragazza, la mette “mi piace”… ma il “mi piace” va non alla ragazza, ma al guardiano Mikhailovich di questo stesso centro business. Il manager scende giù e si chiede: “Perché quel guardiano Mikhailovich gli sorride così piacevolmente?”In queste situazioni… Per noi suona un po' diverso, perché (come ho scritto) si tratta di una perdita reputazionale che porta indirettamente a perdite finanziarie. La nostra situazione è opposta: possiamo subire perdite finanziarie dirette—ad esempio, se abbiamo effettuato una transazione ritenuta riuscita, ma in realtà non lo era (o viceversa). Abbiamo dovuto scrivere un nostro strumento che monitora, in base ai parametri aziendali, il numero di transazioni riuscite in dinamica su un intervallo di tempo. Non abbiamo trovato nulla sul mercato! Volevo proprio far passare questo messaggio. Per affrontare questo tipo di problemi, non c'è nulla sul mercato.
Questo era a proposito di come identificare rapidamente un problema.
Come determinare le cause del deployment
Il terzo gruppo di compiti che affrontiamo consiste nel comprendere le cause dopo aver identificato e risolto un problema. È importante capire il motivo per motivi di sviluppo, test e intervento. Pertanto, dobbiamo analizzare e raccogliere i log.
Quando parliamo di log (la causa principale sono i log), la maggior parte di essi è nel ELK Stack – è così per la maggior parte. Alcuni potrebbero non utilizzare ELK, ma se registrate log in quantità gigabyte, prima o poi arriverete ad utilizzare ELK. Noi li registriamo in terabyte.
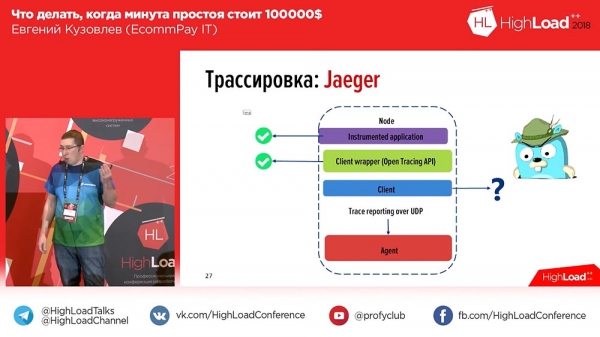
Qui c'è un problema. Abbiamo corretto un errore per l'utente e, iniziando ad approfondire, siamo entrati in Kibana, abbiamo inserito l'ID della transazione e ottenuto un output lungo (mostra molti dati). In questo output non è chiaro nulla. Perché? Perché non è evidente quale parte si riferisca a quale worker e quale parte si riferisca a quale componente. E in quel momento abbiamo capito che ci serviva una tracciabilità – quella OpenTracing di cui parlavo.Abbiamo riflettuto su questo un anno fa, volgendo lo sguardo al mercato, e abbiamo trovato due strumenti: 'Zipkin' e 'Jaeger'. 'Jaeger' è in effetti un erede ideologico, un continuatore ideologico di 'Zipkin'. In 'Zipkin' c'è tutto di buono, tranne il fatto che non sa aggregare e non riesce a includere i log nella traccia, ma solo il tracciamento del tempo. 'Jaeger' supportava questa funzionalità.
Abbiamo esaminato 'Jaeger': è possibile strumentare le applicazioni, è possibile scrivere in API (l'API standard per PHP a quel tempo, in realtà, non era approvata – era un anno fa, ora è già stata approvata), e in realtà non c'era alcun client. 'Va bene', abbiamo pensato, e abbiamo scritto il nostro client. Ecco a grandi linee come appare:
In «Eger» every message generates spans. That is, when a user opens the system, they see one or two blocks for each incoming request (1-2-3 – the number of incoming requests corresponds to the number of blocks). To make it easier for users, we added tags to the logs and the time tracing. Thus, in case of an error, our application will mark the log with the corresponding Error tag. You can filter by the Error tag, and only the spans containing that error block will be displayed. Here’s how it looks when we expand the span:
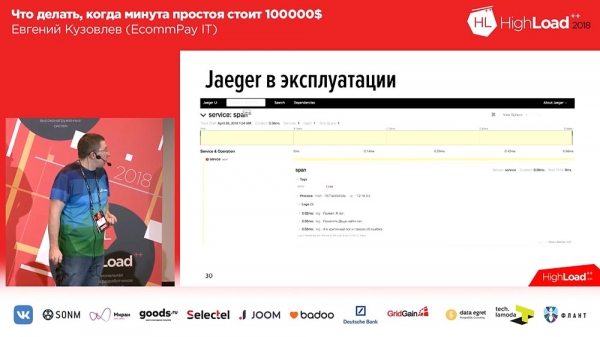
Inside the span, there is a set of traces. In this case, there are three test traces, and the third trace indicates that an error occurred. At the same time, here we can see the time trace: at the top, we have the time scale, and we can see during which time interval a particular log was recorded.Accordingly, everything went great. We wrote our own extension, and we open-sourced it. If you want to work with tracing, if you want to work with «Eger» in PHP – we have our extension available for use, as they say:
Questa estensione è un client per lavorare con l'API OpenTracing, realizzata come php-extension, il che significa che dovrete compilarla e integrarla nel sistema. Un anno fa non c'era nulla di simile. Ora sono disponibili anche altri client che fungono da componenti. Qui sta a voi: potete utilizzare Composer per scaricare i componenti, oppure utilizzare l'estensione, a vostra discrezione.Standard aziendali
Abbiamo parlato delle tre leggi. La quarta legge riguarda la standardizzazione degli approcci. Di cosa si tratta? Si tratta fondamentalmente questo:
Perché qui la parola «aziendale»? Non perché siamo una grande azienda burocratica, no! Ho voluto usare la parola «aziendale» nel contesto che ogni azienda e ogni prodotto deve avere i propri standard, e anche voi dovete averli. Quali standard abbiamo noi?- Abbiamo un regolamento per i deployment. Senza di esso non possiamo procedere, non possiamo. Effettuiamo circa 60 deployment a settimana, il che significa che abbiamo deployment praticamente costanti. Allo stesso tempo, ad esempio, nel regolamento per i deployment è vietato fare deployment il venerdì – in linea di principio, non facciamo deployment.
- La documentazione è fondamentale per noi. Nessun nuovo componente entra in produzione senza una documentazione, anche se è stato creato dai nostri RnD. Richiediamo un'istruzione per il deployment, una mappa di monitoraggio e una descrizione approssimativa (scritta dai programmatori) di come funziona il componente e come affrontare i problemi.
- Invece di affrontare la causa del problema, ci occupiamo del problema stesso – come ho già detto. È importante per noi proteggere l'utente dai problemi.
- Abbiamo delle tolleranze. Ad esempio, non consideriamo un downtime se perdiamo il 2% del traffico per due minuti. Questo non viene conteggiato nelle nostre statistiche. Se la percentuale o il tempo superano questo limite, invece, lo consideriamo.
- Scriviamo sempre postmortem. Qualsiasi situazione anomala che si verifichi in produzione sarà documentata nel postmortem. Il postmortem è un documento in cui si descrive cosa è successo, una tempistica dettagliata, cosa è stato fatto per risolvere il problema e (questo è un punto obbligatorio!) cosa si farà per evitare che accada di nuovo in futuro. È fondamentale per l'analisi successiva.
Cosa consideriamo downtime?
A cosa ha portato tutto questo?Questo ha portato al fatto che (abbiamo avuto alcuni problemi di stabilità, che non soddisfavano né i clienti né noi) negli ultimi 6 mesi il nostro indice di stabilità è stato del 99,97. Si può dire che non è molto. Sì, abbiamo molto da raggiungere. Circa metà di questo indice è la stabilità non tanto nostra, quanto del nostro web application firewall, che ci sta davanti e viene utilizzato come servizio, ma ai clienti non importa.
Abbiamo imparato a dormire di notte. Finalmente! Sei mesi fa non sapevamo farlo. E su questa nota relativamente ai risultati, vorrei fare una piccola osservazione. Ieri sera c'è stata una presentazione fantastica sul sistema di gestione di un reattore nucleare. Se ci sono persone qui che hanno scritto questo sistema – per favore, dimenticate quello che ho detto riguardo al "2% – non è downtime". Per voi, il 2% è downtime, anche se solo per due minuti!
È tutto! Le vostre domande.
Sui bilanciatori e la migrazione del database
Domanda dal pubblico (d'ora in poi - D): – Buonasera. Grazie mille per questa presentazione tecnica! La domanda è breve e riguarda i vostri bilanciatori. Avete accennato al fatto che avete un WAF, quindi, se ho capito bene, utilizzate un qualche strumento esterno come bilanciatore…
EK: – No, come bilanciatore utilizziamo i nostri servizi. In questo caso il WAF è per noi esclusivamente uno strumento di protezione contro DDoS.
D: – Posso avere qualche informazione sui bilanciatori?
EK: – Come ho già detto, si tratta di un gruppo di server in openresty. Attualmente abbiamo 5 gruppi riservati, che si occupano esclusivamente… cioè, il server su cui è installato esclusivamente openresty si limita a fare il proxy per il traffico. Per capire, il nostro flusso di traffico attuale è di alcune centinaia di megabit. Se la cavano bene, non si sforzano neanche.
D: – Anche una domanda semplice. Esiste il deployment Blue/Green. E cosa fate, ad esempio, con le migrazioni dal database?
EK: – Ottima domanda! Nel nostro processo di deploy Blue/Green abbiamo code separate per ciascuna linea. Cioè, quando parliamo di code di eventi che vengono trasferiti da un worker all'altro, ci sono code separate per la linea blue e la linea green. Per quanto riguarda il database, lo abbiamo deliberatamente semplificato il più possibile, spostando quasi tutto nelle code; nel database conserviamo solo lo stack delle transazioni. E lo stack delle transazioni è unico per tutte le linee. In questo contesto, non separiamo il database tra blue e green perché entrambe le versioni del codice devono essere a conoscenza di ciò che sta accadendo con la transazione.
Amici, ho anche un piccolo premio per stimolarvi – un libro. E devo consegnarlo per la miglior domanda.
D: – Buongiorno. Grazie per la presentazione. Ho una domanda. Monitorate i pagamenti, monitorate i servizi con cui interagite… Ma come monitorate che una persona sia arrivata sulla vostra pagina di pagamento, abbia completato l'acquisto e il progetto le abbia accreditato i fondi? Cioè, come monitorate che il merchant sia disponibile e abbia accettato il vostro callback?
EK: – Per noi, il «Merchant» è esattamente lo stesso tipo di servizio esterno del sistema di pagamento. Monitoriamo il tempo di risposta del «merchant».
Sulla crittografia del database
D: – Salve. Ho una domanda correlata. Avete dati sensibili secondo il PCI DSS. Vorrei sapere come memorizzate i PAN nelle code in cui è necessario inoltrarli? Utilizzate qualche crittografia? E la seconda domanda che ne deriva: secondo il PCI DSS è necessario effettuare periodicamente la ri-cifratura del database in caso di modifiche (licenziamento di amministratori, e così via) – come avviene in questo caso per l'accessibilità?
EK: – Ottima domanda! Innanzitutto, non memorizziamo i PAN nelle code. Non abbiamo il diritto di memorizzare i PAN in chiaro, pertanto utilizziamo un servizio speciale (lo chiamiamo «Keydaemon») – è un servizio che fa solo una cosa: accetta un messaggio in ingresso e restituisce un messaggio cifrato. E noi memorizziamo tutto con questo messaggio cifrato. Di conseguenza, la lunghezza della chiave è sotto un kilobyte, per garantire che sia davvero seria e affidabile.D: – Ora servono già 2 kilobyte?
EK: – Pare che anche ieri fosse 256… Ma dove andiamo?!
Questo è il primo punto. E in secondo luogo, la soluzione attuale supporta la procedura di re-encrypting – ci sono due coppie di "keks" (chiavi), che generano "deks", i quali si occupano della criptazione (key è la chiave, dek è un derivato della chiave che cripta). E in caso di avvio della procedura (che avviene regolarmente, ogni 3 mesi o giù di lì) carichiamo una nuova coppia di "keks" e i dati vengono ri-cripitati. Abbiamo servizi separati che estraggono tutti i dati, li criptano nuovamente; accanto ai dati si trova l'identificativo della chiave con cui sono stati criptati. Una volta che i dati sono criptati con le nuove chiavi, eliminiamo quelle vecchie.
A volte i pagamenti devono essere effettuati manualmente…
D: – Quindi se arriva un rimborso per qualche operazione, decryptate con la chiave vecchia?
EK: – Sì.
D: – Allora ho un'altra piccola domanda. Quando c'è un guasto, una caduta, un incidente, occorre elaborare la transazione manualmente. Ci sono casi del genere.
EK: – Sì, capita.
D: – Da dove estrai questi dati? O te li procuri manualmente in questo archivio?
EK: – No, certo, abbiamo un sistema di back-office che contiene un'interfaccia per il nostro supporto. Se non sappiamo in quale stato si trovi una transazione (ad esempio, finché il sistema di pagamento non risponde per timeout) - non lo sappiamo a priori, quindi assegniamo lo stato finale solo con certezza totale. In questo caso, mettiamo la transazione in uno stato speciale per la lavorazione manuale. La mattina, il giorno successivo, non appena il supporto riceve informazioni che nel sistema di pagamento ci sono ancora determinate transazioni, le elaborano manualmente in questa interfaccia.
D: – Ho un paio di domande. Una di queste riguarda la continuazione della zona PCI DSS: come estraete i log dal loro perimetro? Questa domanda nasce dal fatto che lo sviluppatore avrebbe potuto inserire qualsiasi cosa nei log! La seconda domanda è: come distribuite i hotfix? A mano nel database – questa è una possibilità, ma potrebbero esserci hotfix gratuiti – qual è la procedura? E la terza domanda è probabilmente legata a RTO e RPO. La vostra disponibilità era del 99,97, quasi quattro nove, ma capisco che avete sia un secondo data center, sia un terzo data center, sia un quinto data center… Come gestite la loro sincronizzazione, replicazione e tutto il resto?EK: – Iniziamo con la prima. La prima domanda riguardava i log? Quando scriviamo i log, abbiamo uno strato che maschera tutti i dati sensibili. Questo sistema controlla in base a una maschera e campi aggiuntivi. Di conseguenza, i nostri log escono già con dati mascherati e conformi al PCI DSS. Questo è uno dei compiti regolari assegnati al dipartimento di testing. Sono obbligati a controllare ogni attività, compresi i log che scrivono, e questo è parte delle attività di revisione del codice, per monitorare che lo sviluppatore non registri dati non autorizzati. Una successiva verifica avviene regolarmente da parte del dipartimento di sicurezza informatica circa una volta alla settimana: vengono selezionati casualmente i log dell'ultimo giorno e analizzati tramite uno scanner speciale dai server di test per effettuare i controlli.
Riguardo ai hot-fix. Questo è incluso nel nostro regolamento dei deploy. Abbiamo un punto separato sui hot-fix. Riteniamo di poter effettuare hot-fix 24 ore su 24 quando ne abbiamo bisogno. Non appena la versione è pronta, una volta che è stata eseguita e abbiamo l'artefatto, un amministratore di sistema di turno viene contattato dal supporto e lo deploya nel momento necessario.Riguardo alle "quattro nove". Il dato attuale che abbiamo è stato realmente raggiunto, e abbiamo mirato a questo anche con un altro data center. Ora che abbiamo un secondo data center, iniziamo a fare il routing tra di loro, e la questione della replica cross data center è davvero non banale. Abbiamo provato a risolverla in vari modi: abbiamo tentato di usare lo stesso "Tarantool" — ma non ha funzionato, lo dico subito. Pertanto, siamo arrivati alla conclusione di fare ordini di "senza" manualmente. Ogni applicazione, infatti, esegue la sincronizzazione asincrona necessaria "change – done" tra i data center.
D: – Se hai un secondo, perché non ne hai un terzo? Perché il problema del split-brain nessuno...
EK: – Da noi non c'è 'Split-brain'. Poiché ogni applicazione utilizza un multimasters, non ha importanza in quale centro è arrivata la richiesta. Siamo pronti per il caso in cui uno dei nostri data center fallisca (ne teniamo conto) e durante la richiesta dell'utente venga deviata al secondo data center; siamo pronti a perdere quell'utente, davvero; ma saranno solo rarissimi casi, assolutamente rari.
D: – Buona sera. Grazie per la relazione. Parlavi del tuo debugger, che esegue alcune transazioni di test in produzione. Ma parlaci delle transazioni di test! Fino a che punto arriva?
EK: – Essa completa il ciclo di tutto il componente. Non ci sono differenze tra una transazione di test e una in produzione per il componente. E dal punto di vista logico, è semplicemente un progetto separato nel sistema, dove vengono eseguite solo transazioni di test.
D: – E dove la interrompi? Ecco, il Core ha inviato…
EK: – Seguiamo il 'Core' in questo caso per le transazioni di test... Abbiamo un concetto che chiamiamo routing: il 'Core' sa a quale sistema di pagamento inviare – noi inviamo a un sistema di pagamento fittizio, che restituisce solo una risposta http e basta.
D: – Mi scusi, ma la vostra applicazione è scritta come un grande monolite, o l'avete suddivisa in servizi o addirittura in microservizi?
EK: – Non abbiamo un monolite, ovviamente, abbiamo un'applicazione orientata ai servizi. Abbiamo una battuta che dice che abbiamo servizi da monoliti – sono davvero abbastanza grandi. Non possiamo nemmeno chiamarli microservizi, ma si tratta pur sempre di servizi, all'interno dei quali lavorano dei worker su macchine distribuite.
Se un servizio sul server è compromesso…
D: – Allora ho la seguente domanda. Anche se fosse un monolite, avete detto che avete molti di questi server istantanei, e tutti in pratica elaborano dati. Quindi la domanda è: «In caso di compromissione di uno dei server istantanei o di un'applicazione, di un singolo anello, hanno qualche controllo accesso? Chi può fare cosa? A chi rivolgersi per quali dati?»
EK: – Certamente. I requisiti di sicurezza sono piuttosto severi. Prima di tutto, abbiamo flussi di dati aperti e le porte sono solo quelle su cui prevediamo in anticipo il movimento del traffico. Se un componente comunica con un database (supponiamo con 'MySQL') su 5-4-3-2, verranno aperte solo le porte 5-4-3-2, e altre porte, altre direzioni del traffico non saranno accessibili. Inoltre, bisogna capire che in produzione ci sono circa 10 diversi contorni di sicurezza. Anche se l'applicazione fosse compromessa in qualche modo, Dio non voglia, l'attaccante non potrà accedere alla console di gestione del server, perché è un'altra zona di sicurezza della rete.D: – A me interessa di più il fatto che avete dei contratti con i servizi – cosa possono fare, attraverso quali "azioni" possono interagire tra di loro... In un flusso normale, alcuni servizi richiedono una serie di "azioni" dagli altri. Con gli altri, non si connettono in situazioni normali, e hanno zone di responsabilità diverse. Se uno di loro viene compromesso, può interagire con le "azioni" di quel servizio?..
EK: – Capisco. Se in una situazione normale la comunicazione con un altro server era consentita, allora – sì. Secondo il contratto SLA, non monitoriamo che ti sono consentite solo le prime 3 "azioni", mentre la 4ª "azione" non è consentita. Questo sarebbe probabilmente eccessivo per noi, perché abbiamo comunque un sistema di protezione a 4 livelli per i contorni. Preferiamo proteggerci a livello di contorno, piuttosto che all'interno.
Come funzionano Visa, MasterCard e "Sberbank"
D: – Vorrei chiarire un punto riguardo al passaggio dell'utente da un data center all'altro. Per quanto ne so, "Visa" e "MasterCard" operano tramite il protocollo binario sincrono 8583, dove sono presenti dei mix. Volevo sapere, stiamo parlando di un passaggio diretto – riguarda direttamente "Visa" e "MasterCard" o include anche i sistemi di pagamento e i processori?
EK: – Riguarda i mix. I mix si trovano in un solo data center.
D: – In sostanza, avete un unico punto di connessione?
EK: – Per "Visa" e "MasterCard" – sì. È semplicemente perché "Visa" e "MasterCard" richiedono investimenti significativi nell'infrastruttura per stipulare contratti separati per ottenere un secondo paio di mix, ad esempio. Sono riservati all'interno di un solo data center, ma nel caso, Dio non voglia, il data center che ospita i mix per la connessione a "Visa" e "MasterCard" dovesse guastarsi, perderemmo la connessione con "Visa" e "MasterCard"...
D: – Come possono essere riservati? So che "Visa" consente solo di mantenere una connessione in linea di principio!
EK: – Forniscono loro stessi l'attrezzatura. In ogni caso, ci è stato fornito dell'hardware che è riservato a livello fisico.
D: – Quindi, è la rack dei loro Connects Orange?..
EK: – Sì.
D: – Ma in questo caso: se il tuo data center si interrompe, come procedi? O semplicemente il traffico si ferma?
EK: – No. In questo caso, semplicemente reindirizzeremo il traffico su un altro canale, che, ovviamente, sarà più costoso per noi e per i clienti. Ma il traffico non passerà attraverso la nostra connessione diretta a «Visa», «MasterCard», ma attraverso un ipotetico «Sberbank» (in modo molto esagerato).
Mi scuso profondamente se ho offeso i dipendenti di «Sberbank». Ma secondo le nostre statistiche, tra le banche russe, «Sberbank» va in down più spesso. Non passa mese senza che qualcosa da «Sberbank» non si disconnetta.

Un po' di pubblicità 🙂
Grazie per essere con noi. Ti piacciono i nostri articoli? Vuoi vedere più contenuti interessanti? Supportaci effettuando un ordine o raccomandandoci ai tuoi conoscenti, , un'alternativa unica ai server entry-level, che abbiamo creato per te: (disponibili opzioni con RAID1 e RAID10, fino a 24 core e fino a 40GB DDR4).
Dell R730xd a metà prezzo nel data center Equinix Tier IV ad Amsterdam? Solo da noi nei Paesi Bassi! Dell R420 — 2x E5-2430 2.2GHz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — a partire da $99! Scopri di più su



















Fonte: habr.com
