

Il 26 febbraio abbiamo tenuto un meetup su Apache Ignite GreenSource, con la partecipazione dei contributori del progetto open source . Un evento significativo nella vita di questa comunità è stata la ristrutturazione del componente , che consente di distribuire microservizi personalizzati direttamente nel cluster Ignite. Questo complesso processo è stato spiegato durante il meetup da , ingegnere del software e contributore di Apache Ignite da oltre due anni.
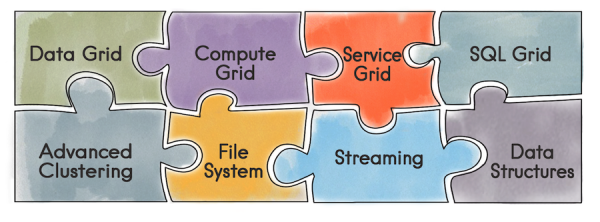
Iniziamo con una panoramica di cosa sia Apache Ignite. È un database che funge da sistema di archiviazione distribuito Key/Value con supporto per SQL, transazionalità e caching. Inoltre, Ignite consente di distribuire servizi personalizzati direttamente nel cluster Ignite. Gli sviluppatori hanno accesso a tutti gli strumenti forniti da Ignite — strutture dati distribuite, Messaging, Streaming, Compute e Data Grid. Ad esempio, utilizzando il Data Grid si elimina il problema della gestione di un'infrastruttura separata per l'archiviazione dei dati e, di conseguenza, i costi associati.
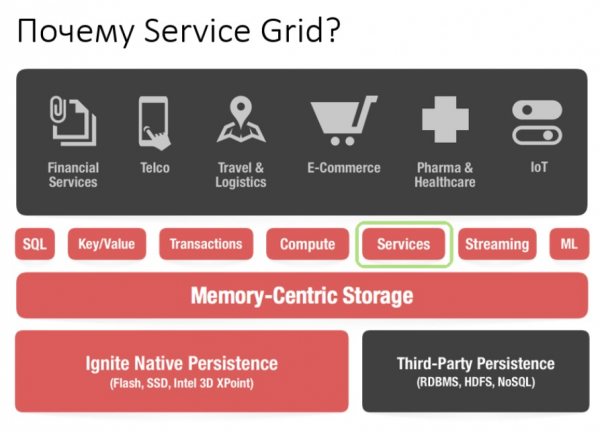
Utilizzando l'API Service Grid, è possibile distribuire un servizio semplicemente specificando nella configurazione lo schema di distribuzione e, di conseguenza, il servizio stesso.
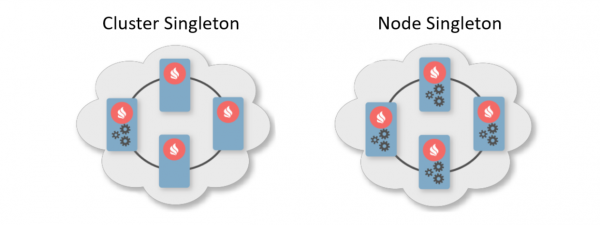
Di solito, lo schema di distribuzione indica il numero di istanze che devono essere distribuite sui nodi del cluster. Ci sono due schemi di distribuzione tipici. Il primo è il Cluster Singleton: in qualsiasi momento, nel cluster sarà garantito l'accesso a un'unica istanza del servizio utente. Il secondo è il Node Singleton: su ciascun nodo del cluster è distribuita un'istanza del servizio.
L'utente può anche specificare il numero di istanze del servizio in tutto il cluster e definire un predicato per filtrare i nodi adatti. In questo scenario, il Service Grid calcolerà autonomamente la distribuzione ottimale per la distribuzione dei servizi.
Inoltre, esiste una funzionalità chiamata Affinity Service. Affinity è una funzione che definisce la relazione tra le chiavi e le partizioni e la relazione tra i gruppi e i nodi nella topologia. In base alla chiave, è possibile identificare il nodo primario sul quale sono memorizzati i dati. In questo modo, puoi associare il tuo servizio con una chiave e la cache della funzione affinity. In caso di modifica della funzione affinity, si verificherà un ridispiegamento automatico. In questo modo, il servizio sarà sempre posizionato vicino ai dati con cui deve interagire, riducendo di conseguenza i costi di accesso alle informazioni. Questa configurazione può essere definita come una sorta di calcolo collocato.
Ora che abbiamo esaminato i vantaggi del Service Grid, parleremo della sua storia di evoluzione.
Cosa c'era prima
La precedente implementazione del Service Grid si basava su una cache di sistema replicata e transazionale chiamata Ignite. Con la parola «cache» in Ignite si intende un'archiviazione. Quindi, non si tratta di qualcosa di temporaneo, come si potrebbe pensare. Anche se la cache è replicata e ogni nodo contiene l'intero set di dati, all'interno la cache ha una rappresentazione partizionata. Questo è legato all'ottimizzazione degli archivi.
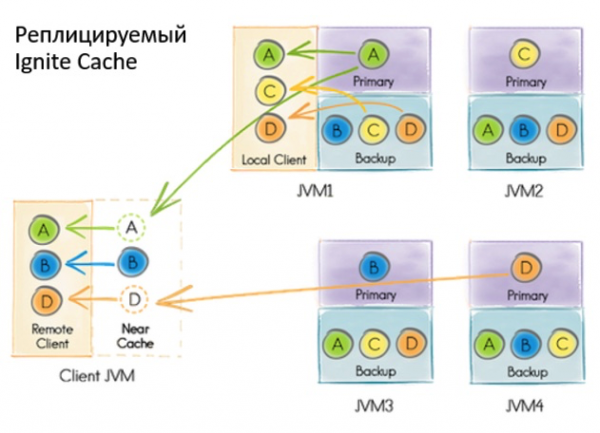
Cosa succedeva quando l'utente voleva deployare un servizio?
- Tutti i nodi nel cluster si iscrivevano agli aggiornamenti dei dati nel deposito attraverso un meccanismo integrato di Continuous Query.
- Il nodo inziatore, sotto una transazione read-committed, faceva una scrittura nel database contenente la configurazione del servizio, inclusa l'istanza serializzata.
- All'arrivo della notifica di una nuova registrazione, il coordinatore calcolava la distribuzione in base alla configurazione. L'oggetto ottenuto veniva scritto nuovamente nel database.
- Se il nodo rientrava nella distribuzione, il coordinatore doveva deployarlo.
Cosa non ci soddisfaceva
A un certo punto, abbiamo concluso che non era possibile lavorare così con i servizi. Ci sono state diverse motivazioni.
Se durante il deployment si è verificato un errore, era possibile scoprirlo solo dai log del nodo in cui è avvenuto. Esisteva solo il deployment asincrono, quindi dopo il rilascio del controllo all'utente da parte del metodo di deployment, era necessario un ulteriore tempo per l'avvio del servizio, durante il quale l'utente non poteva gestire nulla. Per sviluppare ulteriormente il Service Grid, implementare nuove funzionalità, attrarre nuovi utenti e semplificare la vita a tutti, è necessario apportare dei cambiamenti.
Nella progettazione del nuovo Service Grid, la nostra priorità era garantire un deployment sincrono: non appena il controllo torna all'utente dall'API, può immediatamente utilizzare i servizi. Volevamo anche fornire all'initiatore la possibilità di gestire gli errori di deployment.
Inoltre, volevamo semplificare l'implementazione, allontanandoci dalle transazioni e dal bilanciamento. Nonostante la cache sia replicata e non ci sia bilanciamento, durante un grande deployment con molti nodi si presentavano problemi. Durante la modifica della topologia, i nodi devono scambiarsi informazioni e in caso di un grande deployment, questi dati possono pesare molto.
Quando la topologia era instabile, era necessario ricalcolare la distribuzione dei servizi. In generale, lavorare con transazioni su una topologia instabile può portare a errori difficili da prevedere.
Problemi
Quali grandi cambiamenti possono avvenire senza problemi associati? Il primo di questi è stato il cambiamento della topologia. È importante capire che, in qualsiasi momento, anche durante il deployment di un servizio, un nodo può unirsi o uscire dal cluster. Inoltre, se durante il deployment un nodo entra nel cluster, sarà necessario trasmettere in modo consistente tutte le informazioni sui servizi al nuovo nodo. Non si tratta solo di ciò che è già stato distribuito, ma anche dei deployment correnti e futuri.
Questa è solo una delle problematiche che possiamo raccogliere in un elenco separato:
- Come distribuire servizi configurati staticamente all'avvio di un nodo?
- Cosa fare se un nodo esce dal cluster e ospitava servizi?
- Cosa fare se il coordinatore è cambiato?
- Cosa fare se un client si riconnette al cluster?
- È necessario gestire le richieste di attivazione/disattivazione e come?
- E se abbiamo chiamato distruzione della cache, ma abbiamo servizi affini legati ad essa?
E questo non è affatto tutto.
Soluzione
Come obiettivo, abbiamo scelto l'approccio Event Driven, implementando la comunicazione tra processi tramite messaggi. In Ignite sono già stati realizzati due componenti che consentono ai nodi di scambiare messaggi tra loro: communication-spi e discovery-spi.
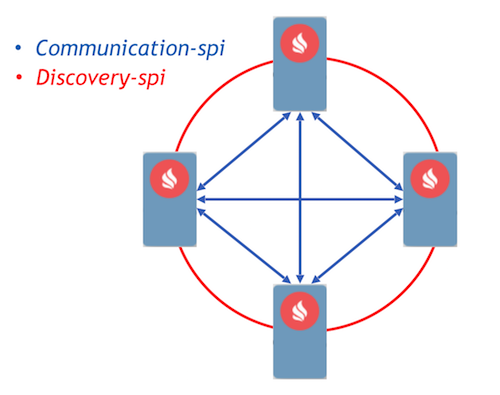
Il communication-spi consente ai nodi di comunicare direttamente e inviare messaggi. È particolarmente adatto per la trasmissione di grandi volumi di dati. Il discovery-spi permette di inviare un messaggio a tutti i nodi del cluster. Nella sua implementazione standard, ciò avviene secondo la topologia 'anello'. Esiste anche un'integrazione con Zookeeper, in questo caso viene utilizzata la topologia 'stella'. Vale la pena sottolineare un aspetto importante: il discovery-spi fornisce garanzie che il messaggio verrà consegnato nell'ordine corretto a tutti i nodi.
Consideriamo il protocollo di deployment. Tutte le richieste degli utenti per il deployment e il rollback vengono inviate tramite discovery-spi. Questo offre le seguenti garanzie:
- La richiesta sarà ricevuta da tutti i nodi del cluster. Questo consentirà di continuare l'elaborazione della richiesta durante il cambio di coordinatore. Inoltre, ciò significa che per ogni messaggio, ogni nodo avrà tutte le informazioni necessarie, come la configurazione del servizio e la sua istanza serializzata.
- L'ordine rigoroso di consegna dei messaggi consente di risolvere i conflitti di configurazione e le richieste concorrenti.
- Poiché l'ingresso di un nodo nella topologia viene elaborato anche tramite discovery-spi, un nuovo nodo riceverà tutti i dati necessari per lavorare con i servizi.
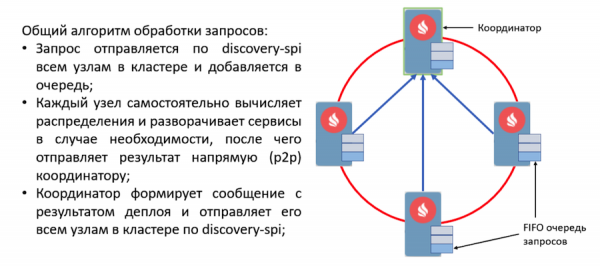
Quando un nodo riceve una richiesta, essa viene validata e si formano compiti per l'elaborazione. Questi compiti vengono messi in coda e successivamente elaborati in un altro thread da un worker separato. Questo è realizzato in questo modo perché il deployment può richiedere un tempo significativo e ritardare un costoso flusso di discovery è inaccettabile.
Tutte le richieste in coda sono elaborate dal deployment manager. Questo ha un worker speciale che prende un compito da questa coda e lo inizializza per avviare il deployment. Dopodiché si svolgono le seguenti azioni:
- Ogni nodo calcola autonomamente la distribuzione grazie alla nuova funzione di assegnazione deterministica.
- I nodi formano un messaggio con i risultati del deployment e lo inviano al coordinatore.
- Il coordinatore aggrega tutti i messaggi e formula il risultato dell'intero processo di deployment, che viene inviato tramite discovery-spi a tutti i nodi nel cluster.
- Una volta ricevuto il risultato, il processo di deployment si conclude, dopodiché il compito viene rimosso dalla coda.
Nuovo design event-driven: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Se si verifica un errore durante il deployment, il nodo include immediatamente questo errore nel messaggio che invia al coordinatore. Dopo l'aggregazione dei messaggi, il coordinatore avrà informazioni su tutti gli errori durante il deployment e invierà questo messaggio tramite discovery-spi. Le informazioni sugli errori saranno accessibili su qualsiasi nodo del cluster.
Secondo questo algoritmo di lavoro vengono trattati tutti gli eventi significativi nel Service Grid. Ad esempio, il cambiamento di topologia è anch'esso un messaggio tramite discovery-spi. In generale, rispetto a ciò che c'era prima, il protocollo risulta sufficientemente leggero e affidabile, tanto da gestire qualsiasi situazione durante il deployment.
Cosa succede dopo
Ora parliamo dei piani. Qualsiasi grande modifica nel progetto Ignite viene realizzata come iniziativa di miglioramento di Ignite, chiamata IEP. Anche il redesign del Service Grid ha un IEP — con il divertente titolo «Sostituzione dell'olio nel Service Grid». Ma in realtà abbiamo cambiato non solo l'olio nel motore, ma l'intero motore.
Abbiamo suddiviso le attività nell'IEP in due fasi. La prima è la fase principale, che consiste nella revisione del protocollo di deployment. È già stata integrata nel master, puoi provare il nuovo Service Grid che apparirà nella versione 2.8. La seconda fase include diverse altre attività:
- Redeploy caldo
- Versionamento dei servizi
- Aumento della resilienza
- Client leggero
- Strumenti di monitoraggio e conteggio di varie metriche
Infine, possiamo consigliarti il Service Grid per costruire sistemi ad alta disponibilità e resilienza. Ti invitiamo anche a unirti a noi su e per condividere la tua esperienza. La tua esperienza è davvero importante per la comunità, aiuterà a capire in quale direzione andare e come sviluppare il componente in futuro.
Fonte: habr.com
