


Lo sviluppo industriale di sistemi software richiede molta attenzione alla resilienza del prodotto finale, oltre a una rapida risposta in caso di guasti o malfunzionamenti, se si verificano. Certo, il monitoraggio aiuta a reagire ai guasti in modo più efficiente e veloce, ma non è sufficiente. In primo luogo, è molto difficile tenere traccia di un gran numero di server – è necessario un grande numero di persone. In secondo luogo, è importante comprendere bene come è strutturata l'applicazione, per poter prevedere il suo stato. Pertanto, è necessaria una squadra di esperti che conosca a fondo i sistemi che sviluppiamo, i loro indicatori e le loro caratteristiche. Anche supponendo di trovare un numero sufficiente di persone desiderose di occuparsene, occorre ancora tempo per formarli.
Cosa fare? Qui ci viene in aiuto l'intelligenza artificiale. Questo articolo parlerà di (manutenzione predittiva). Questo approccio sta guadagnando popolarità. Sono stati scritti numerosi articoli, anche su Habr. Le grandi aziende stanno adottando questo metodo per mantenere operativi i propri server. Dopo aver esaminato molti articoli, abbiamo deciso di provare ad applicare questo approccio. Che cosa ne è uscito?
Introduzione
Un sistema software sviluppato entra in produzione prima o poi. Per l'utente è importante che il sistema funzioni senza interruzioni. Se si verifica un'emergenza, deve essere risolta con il minor ritardo possibile.
Per semplificare il supporto tecnico del sistema software, specialmente se ci sono molti server, si usano di solito programmi di monitoraggio che raccolgono metriche dal sistema in esecuzione, permettono di diagnosticare il suo stato e aiutano a determinare cosa ha causato il guasto. Questo processo è chiamato monitoraggio del sistema software.
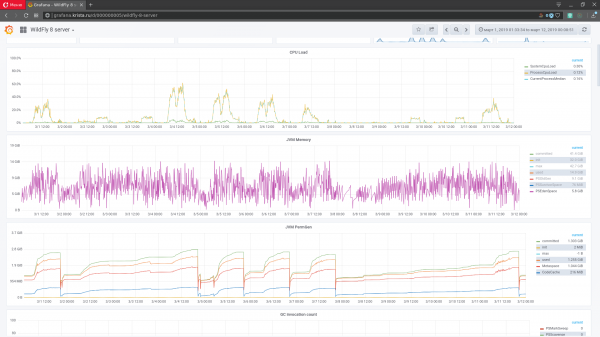
Figura 1. Interfaccia per il monitoraggio grafana
Le metriche sono diversi indicatori del sistema software, dell'ambiente di esecuzione o della macchina fisica su cui è in esecuzione il sistema, registrando il momento in cui sono state raccolte le metriche. Nell'analisi statica, i dati delle metriche sono chiamati serie temporali. Per monitorare lo stato del sistema software, le metriche vengono visualizzate in forma di grafici: sull'asse X c'è il tempo, mentre sull'asse Y i valori (figura 1). Un sistema software attivo può generare diverse migliaia di metriche (da ciascun nodo). Queste formano uno spazio metrico (serie temporali multidimensionali).
Poiché nei sistemi software complessi vengono raccolti un gran numero di metriche, il monitoraggio manuale diventa un compito difficile. Per ridurre la quantità di dati da analizzare, gli strumenti di monitoraggio contengono funzioni per rilevare automaticamente potenziali problemi. Ad esempio, è possibile impostare un trigger che scatta quando lo spazio libero su disco scende al di sotto di una certa soglia. È anche possibile diagnosticare automaticamente l'arresto del server o un significativo rallentamento delle prestazioni. In pratica, gli strumenti di monitoraggio si rivelano efficaci nel rilevare guasti già avvenuti o nel riconoscere sintomi semplici di guasti futuri, ma in generale la previsione di un possibile guasto rimane una sfida. La previsione tramite analisi manuale delle metriche richiede specialisti qualificati ed è poco produttiva. La maggior parte dei potenziali guasti può rimanere inosservata.
Negli ultimi tempi, tra le grandi aziende IT specializzate nello sviluppo software, sta guadagnando sempre più popolarità il cosiddetto servizio predittivo per i sistemi software. Questo approccio si basa sull'individuazione precoce di guasti che possono portare alla degradazione del sistema, prima che si verifichi un malfunzionamento, facendo uso dell'intelligenza artificiale. Questo metodo non esclude completamente il monitoraggio manuale del sistema, ma funge da supporto al processo di monitoraggio in generale.
Lo strumento principale per attuare il servizio predittivo è la rilevazione di anomalie nelle serie temporali, poiché quando si verifica un'anomalia nei dati è alta la probabilità che, dopo un po', si verifichi un guasto o un malfunzionamento. Un'anomalia è un certo scostamento delle metriche del sistema software, come l'individuazione della degradazione della velocità di risposta per uno specifico tipo di richiesta o la riduzione del numero medio di richieste gestite a fronte di un numero costante di sessioni client.
La ricerca di anomalie per i sistemi software presenta delle specificità. In linea di principio, per ogni sistema software è necessaria la creazione o l'adattamento dei metodi esistenti, poiché la ricerca di anomalie dipende fortemente dai dati in cui viene eseguita, e i dati dei sistemi software variano notevolmente a seconda degli strumenti utilizzati per implementare il sistema, fino all'hardware su cui è in esecuzione.
Metodi per la ricerca di anomalie nella previsione dei guasti dei sistemi software
Prima di tutto, è importante sottolineare che l'idea della previsione dei guasti è stata ispirata da un articolo . Per verificare l'efficacia dell'approccio con ricerca automatica di anomalie, è stato scelto il sistema software «Web-Consolidation», uno dei progetti dell'azienda NPO «Krista». In precedenza, veniva effettuato un monitoraggio manuale basato sulle metriche ricevute. Data la complessità del sistema, vengono raccolte numerose metriche: indicatori JVM (carico del garbage collector), indicatori del sistema operativo in cui viene eseguito il codice (memoria virtuale, % di utilizzo della CPU del sistema), indicatori di rete (carico della rete), del server stesso (carico della CPU, della memoria), metriche wildfly e metriche proprie dell'applicazione per tutti i sottosistemi critici.
Tutte le metriche sono raccolte dal sistema tramite graphite. Inizialmente è stato utilizzato il database whisper come soluzione standard per grafana, ma con la crescita della clientela, graphite ha smesso di funzionare, esaurendo la capacità di throughput del sistema di archiviazione del data center. Dopo ciò, è stata presa la decisione di cercare una soluzione più efficace. È stata scelta , che ha permesso di ridurre notevolmente il carico sul sottosistema di archiviazione e diminuire il volume occupato da cinque a sei volte. Di seguito è riportato lo schema del meccanismo di raccolta delle metriche utilizzando graphite+clickhouse (figura 2).
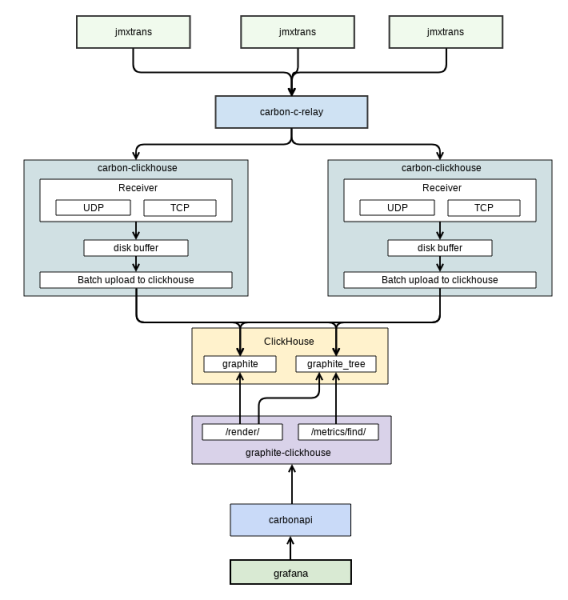
Figura 2. Schema di raccolta delle metriche
Lo schema è preso dalla documentazione interna. Mostra lo scambio di dati tra grafana (l'interfaccia utente per il monitoraggio che utilizziamo) e graphite. La raccolta delle metriche dall'applicazione è effettuata da un software separato – . Questo software le memorizza in graphite.
Il sistema «Web-Consulenza» presenta alcune caratteristiche che creano problemi nella previsione dei guasti:
- c'è spesso un cambiamento di tendenza. Per questo sistema software vengono rilasciate diverse versioni. Ognuna di esse porta modifiche nella parte software del sistema. Pertanto, in questo modo gli sviluppatori influenzano direttamente le metriche di questo sistema e possono causare un cambiamento di tendenza;
- le caratteristiche di implementazione, così come gli obiettivi di utilizzo da parte dei clienti di questo sistema, spesso generano anomalie senza una precedente degradazione;
- la percentuale di anomalie rispetto all'intero set di dati è ridotta (< 5%);
- possono verificarsi interruzioni nella ricezione delle metriche dal sistema. Per brevi periodi di tempo, il sistema di monitoraggio non riesce a ottenere le metriche. Ad esempio, se il server è sovraccarico. Questo è cruciale per l'addestramento delle reti neurali. Si rende necessaria la sintesi delle lacune;
- I casi di anomalie sono spesso rilevanti solo per un numero/mese/tempo specifico (stagionalità). Questo sistema ha un regolamento chiaro per l'utilizzo da parte degli utenti. Di conseguenza, le metriche sono pertinenti solo per un momento specifico. Il sistema può essere utilizzato non costantemente, ma solo in alcuni mesi: in modo selettivo a seconda dell'anno. Ci sono situazioni in cui lo stesso comportamento delle metriche in un caso può portare al fallimento del sistema software, mentre in un altro no.
In primo luogo, sono stati analizzati i metodi di rilevamento delle anomalie nei dati di monitoraggio dei sistemi software. Negli articoli su questo argomento, con percentuali basse di anomalie rispetto al resto del set di dati, si consiglia frequentemente di utilizzare le reti neurali.
La logica principale per la ricerca di anomalie utilizzando dati di reti neurali è illustrata nella figura 3:

Figura 3. Ricerca di anomalie tramite rete neurale
Nel risultato della previsione o del ripristino della finestra del flusso attuale delle metriche viene calcolata la deviazione rispetto a quella ottenuta dal sistema software in funzione. In caso di una grande differenza tra le metriche ottenute dal sistema software e quelle della rete neurale, si può concludere che l'attuale intervallo di dati è anomalo. Si sollevano i seguenti problemi per l'uso delle reti neurali:
- per un corretto funzionamento in tempo reale, i dati per l'addestramento dei modelli di reti neurali devono includere solo dati "normali";
- è necessario avere un modello attuale per una rilevazione corretta. Un cambiamento nella tendenza e nella stagionalità delle metriche può causare un gran numero di falsi allarmi del modello. Per il suo aggiornamento è necessario definire chiaramente il momento in cui il modello diventa obsoleto. Se il modello viene aggiornato troppo tardi o troppo presto, è probabile che ci siano molti falsi allarmi.
Также нельзя забывать о поиске и предотвращении частого возникновения ложных срабатываний. Предполагается, что они будут чаще всего возникать в нештатных ситуациях. Однако они могут быть и следствием ошибки нейронной сети по причине недостататочности её обучения. Необходимо минимизировать количество ложных срабатываний модели. В противном случае ложные прогнозы будут тратить много времени администратора, предназначенного для проверки системы. Рано или поздно кончится тем, что администратор просто перестанет реагировать на «параноидальную» систему мониторинга.
Рекуррентная нейронная сеть
Для обнаружения аномалий во временных рядах можно применить с памятью LSTM. Проблема есть лишь в том, что она может применяться только для прогнозируемых временных рядов. В нашем случае не все метрики являются прогнозируемыми. Попытка применить RNN LSTM для временного ряда представлена на рисунке 4.
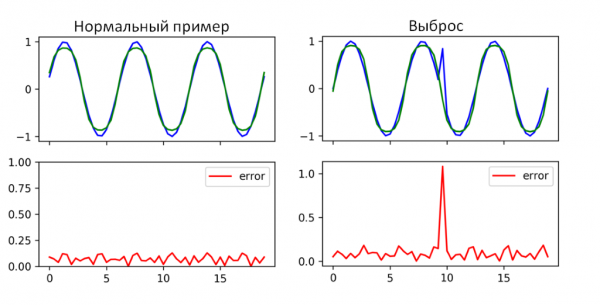
Рисунок 4. Пример работы рекуррентной нейронной сети c ячейками памяти LSTM
Come si può vedere nella figura 4, la RNN LSTM è riuscita a rilevare l'anomalia in questo intervallo di tempo. Dove il risultato mostra un'alta percentuale di errore nella previsione (errore medio), si è effettivamente verificata un'anomalia nei valori. L'uso di una sola RNN LSTM non sarà sufficiente, poiché è applicabile a un numero limitato di metriche. Si può utilizzare come metodo ausiliario per la ricerca di anomalie.
Autoencoder per la previsione dei guasti
– essenzialmente una rete neurale artificiale. Lo strato di ingresso è l'encoder, lo strato di uscita è il decoder. Lo svantaggio di tutte le reti neurali di questo tipo è che localizzano male le anomalie. È stata scelta l'architettura di un autoencoder sincrono.
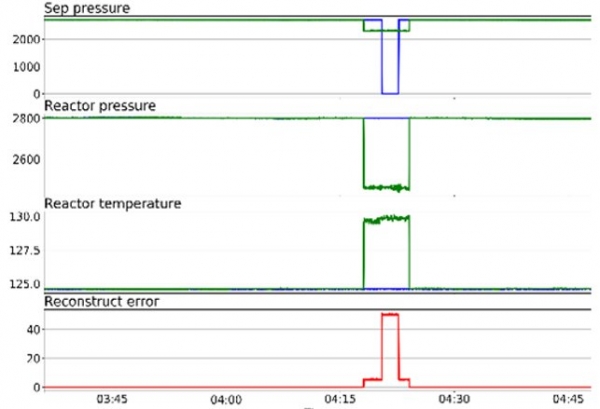
Figura 5. Esempio di funzionamento di un autoencoder
Gli autoencoder vengono addestrati su dati normali e poi trovano qualcosa di anomalo nei dati immessi nel modello. Proprio ciò che serve per questo compito. Resta solo da scegliere quale autoencoder si adatti a questa esigenza. La forma architettonicamente più semplice di autoencoder è una rete neurale semplice e diretta, molto simile a (perceptron multistrato, MLP), con un livello di ingresso, un livello di uscita e uno o più strati nascosti che li collegano.
Tuttavia, le differenze tra gli autoencoder e gli MLP sono che nell'autoencoder il livello di uscita ha lo stesso numero di nodi dell'ingresso e che, invece di apprendere a prevedere il valore target Y dato l'ingresso X, l'autoencoder impara a ricostruire il proprio X. Pertanto, gli autoencoder sono modelli di apprendimento non supervisionato.
L'obiettivo dell'autoencoder è trovare gli indici temporali r0 … rn corrispondenti agli elementi anomali nel vettore di ingresso X. Questo effetto viene raggiunto cercando l'errore quadratico.
Figura 6. Autoencoder sincrono
Per l'autoencoder è stata scelta . I suoi vantaggi: la possibilità di utilizzare la modalità di elaborazione in streaming e un numero relativamente ridotto di parametri della rete neurale rispetto ad altre architetture.
Meccanismo per minimizzare i falsi allarmi
Considerando che possono verificarsi varie situazioni anomale e che è possibile una situazione di insufficiente addestramento della rete neurale, è stata presa la decisione di sviluppare un meccanismo per minimizzare i falsi positivi per il modello di rilevamento delle anomalie in fase di sviluppo. Questo meccanismo si basa su un database di modelli classificati dall'amministratore.
(algoritmo DTW, dall'inglese dynamic time warping) permette di trovare la corrispondenza ottimale tra sequenze temporali. È stato applicato per la prima volta nel riconoscimento vocale: utilizzato per determinare in che modo due segnali vocali rappresentano la stessa frase pronunciata. Successivamente, sono stati trovati impieghi anche in altri settori.
Il principio fondamentale per ridurre i falsi positivi è la creazione di una base di riferimento attraverso un operatore che classifica i casi sospetti rilevati tramite reti neurali. Successivamente, si confronta il campione classificato con il caso identificato dal sistema, e si determina se il caso è da considerare un falso positivo o un malfunzionamento. Per il confronto di due serie temporali si utilizza l'algoritmo DTW. Lo strumento principale per la riduzione rimane comunque la classificazione. Si prevede che, dopo aver raccolto un gran numero di casi di riferimento, il sistema inizierà a richiedere meno intervento da parte dell'operatore a causa della somiglianza della maggior parte dei casi e della comparsa di casi simili.
Di conseguenza, sulla base dei metodi delle reti neurali descritti sopra, è stato sviluppato un programma sperimentale per la previsione dei guasti del sistema "Web-Consolidazione". L'obiettivo di questo programma era, utilizzando l'archivio esistente dei dati di monitoraggio e le informazioni sui guasti già verificatisi, valutare l'efficacia di questo approccio per i nostri sistemi software. Lo schema di funzionamento del programma è mostrato di seguito, nella figura 7.
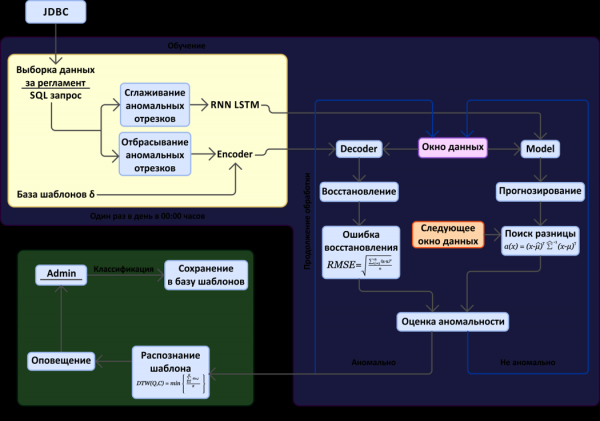
Figura 7. Schema di previsione dei guasti basata sull'analisi dello spazio delle metriche.
Nella schema si possono evidenziare due blocchi principali: la ricerca di segmenti anomalous nel flusso di dati di monitoraggio (metriche) e il meccanismo di minimizzazione dei falsi allarmi. Nota: a scopo sperimentale, i dati vengono ottenuti tramite una connessione JDBC da un database in cui sono archiviati in Graphite.
Di seguito è mostrata l'interfaccia del sistema di monitoraggio sviluppato (figura 8).
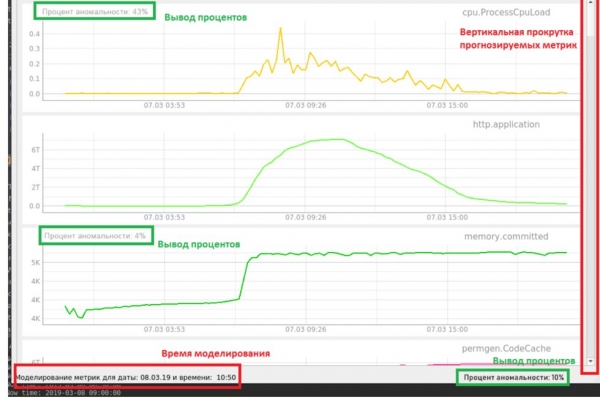
Figura 8. Interfaccia del sistema di monitoraggio sperimentale.
Nell'interfaccia viene visualizzata la percentuale di anomalia delle metriche ottenute. Nel nostro caso, l'acquisizione è simulata. Abbiamo già tutti i dati di alcune settimane e li carichiamo gradualmente per verificare il caso di un'anomalia che porta a un guasto. Nella barra di stato in basso viene visualizzata la percentuale complessiva di anomalia dei dati al momento, che è determinata mediante un autoencoder. Inoltre, per le metriche previste viene visualizzata una percentuale separata, calcolata da RNN LSTM.
Esempio di rilevamento di anomalie nei parametri della CPU utilizzando la rete neurale RNN LSTM (figura 9).
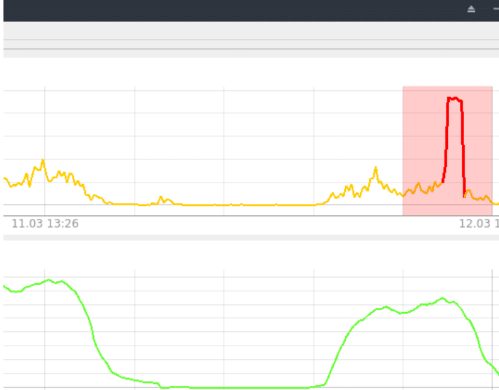
Figura 9. Rilevamento RNN LSTM
Un caso piuttosto semplice, fondamentalmente un'uscita normale, ma che porta a un guasto del sistema, è stato rilevato con successo utilizzando RNN LSTM. Il livello di anomalia in questo intervallo di tempo è pari all'85-95%; qualsiasi valore superiore all'80% (soglia definita sperimentalmente) è considerato un'anomalia.
Esempio di rilevamento di anomalie quando il sistema non riesce a caricarsi dopo un aggiornamento. Questa situazione viene rilevata dall'autoencoder (Figura 10).
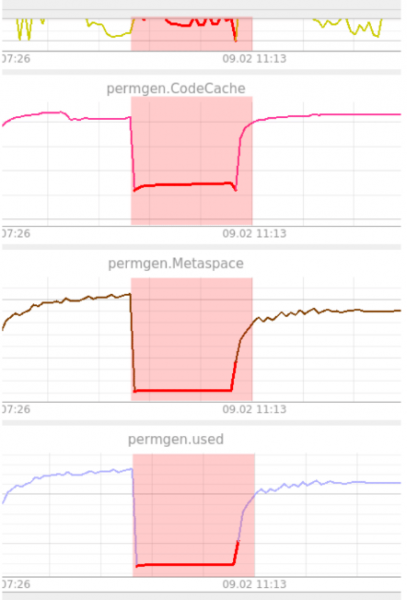
Figura 10. Esempio di rilevamento da parte dell'autoencoder
Come si può vedere dalla figura, PermGen è rimasto bloccato a un certo livello. L'autoencoder ha considerato questo comportamento strano, poiché non aveva mai visto nulla di simile in precedenza. Qui l'anomalia si mantiene costante al 100% fino al ripristino dello stato operativo del sistema. L'anomalia viene visualizzata su tutte le metriche. Come detto in precedenza, l'autoencoder non è in grado di localizzare le anomalie. L'operatore è chiamato a svolgere questa funzione in tali situazioni.
Conclusione
Il sistema «Web-Consolidation» è in fase di sviluppo da diversi anni. Attualmente, il sistema è in uno stato abbastanza stabile e il numero di incidenti registrati è limitato. Tuttavia, sono state trovate anomali che possono portare a un guasto da 5 a 10 minuti prima dell'effettivo problema. In alcuni casi, un avviso tempestivo sul guasto avrebbe potuto ridurre il tempo di inattività programmato, che è previsto per le operazioni di 'manutenzione'.
Per gli esperimenti condotti, è ancora presto per trarre conclusioni definitive. Al momento, i risultati sono contraddittori. Da un lato, è evidente che gli algoritmi basati su reti neurali sono in grado di rilevare anomalie 'utili'. Dall'altro, rimane un alto tasso di falsi positivi e non tutte le anomalie che un specialista qualificato può individuare riescono ad essere rilevate dalla rete neurale. Tra i lati negativi, va anche considerato che al momento la rete neurale richiede un addestramento supervisionato per funzionare correttamente.
Per lo sviluppo ulteriore del sistema di previsione dei guasti e per portarlo a uno stato soddisfacente, si possono considerare diverse strade. Un'analisi più dettagliata dei casi con anomalie che portano a guasti, arricchendo così la lista delle metriche importanti che influenzano fortemente lo stato del sistema e scartando quelle superflue che non influenzano. Inoltre, seguendo questa direzione, si possono tentare specializzazioni degli algoritmi specificamente per i nostri casi di anomalie che portano ai guasti. C'è anche un altro percorso: il miglioramento delle architetture delle reti neurali e, grazie a ciò, l'aumento della precisione delle rilevazioni con una riduzione dei tempi di apprendimento.
Desidero ringraziare i colleghi che mi hanno assistito nella redazione e nel mantenimento dell'accuratezza di questo articolo: e Sergey Finogenov.
Fonte: habr.com
