

Le festività sono finite e torniamo con il nostro secondo post della serie su Istio Service Mesh.

L'argomento di oggi è il Circuit Breaker, che in termini elettrici si traduce come 'interruttore automatico' e colloquialmente è noto come 'dispositivo di protezione'. Solo che in Istio questo interruttore non disattiva un circuito sovraccarico o in corto, ma container difettosi.
Come dovrebbe funzionare idealmente
Quando i microservizi sono gestiti da Kubernetes, ad esempio all'interno della piattaforma OpenShift, si scalano automaticamente su e giù in base al carico. Poiché i microservizi operano in pod, su un singolo endpoint possono esserci più istanze di un microservizio containerizzato, e Kubernetes instraderà le richieste e bilancerà il carico tra di esse. E – idealmente – tutto ciò dovrebbe funzionare perfettamente.
Ricordiamo che i microservizi sono piccoli ed efimeri. La loro efimerità, qui intesa come semplicità di nascita e di scomparsa, è spesso sottovalutata. La nascita e la morte di un'istanza di microservizio in un pod sono eventi piuttosto attesi; OpenShift e Kubernetes gestiscono bene questa dinamica, e tutto funziona magnificamente — ma di nuovo, solo in teoria.
Come funziona realmente
Adesso immaginate che un'istanza specifica di microservizio, cioè un contenitore, sia diventata inaffidabile: o non risponde (errore 503), oppure — cosa più problematica — reagisce, ma con grande lentezza. In altre parole, sta dando problemi o non risponde alle richieste, ma non viene automaticamente rimossa dal pool. Cosa si deve fare in questo caso? Ripetere la richiesta? Rimuoverlo dallo schema di routing? E cosa significa «troppo lentamente» — quale sia il valore numerico e chi lo stabilisce? Forse, sarebbe meglio dargli una pausa e riprovare più tardi? Se sì, quanto più tardi?
Cosa significa Pool Ejection in Istio
E qui entra in gioco Istio con i suoi automatismi di protezione Circuit Breaker, che rimuovono temporaneamente i container non funzionanti dal pool di risorse di routing e bilanciamento del carico, implementando la procedura di Pool Ejection.
Utilizzando la strategia di rilevamento delle anomalie (outlier detection), Istio identifica i pod che si discostano dalla norma e li rimuove dal pool di risorse per un determinato periodo, chiamato «finestra di sonno» (sleep window).
Per mostrare come funziona in Kubernetes sulla piattaforma OpenShift, iniziamo con uno screenshot di microservizi funzionanti dall'esempio nel repository . Qui abbiamo due pod, v1 e v2, ognuno con un container attivo. Quando le regole di routing di Istio non vengono utilizzate, Kubernetes applica per default un bilanciamento uniforme del routing ciclico:
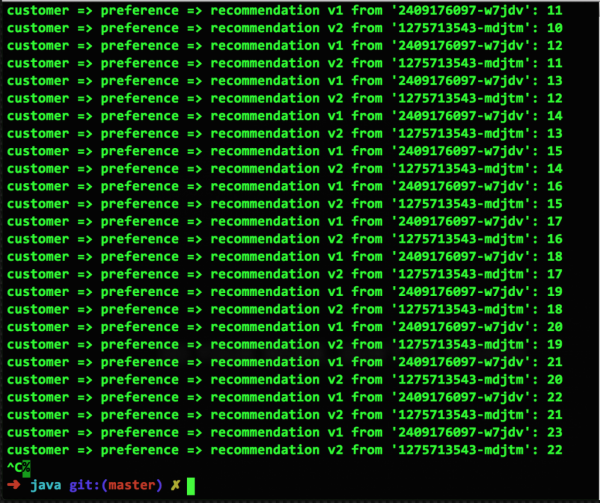
Preparandoci al guasto
Prima di effettuare il Pool Ejection, dobbiamo creare una regola di routing Istio. Supponiamo di voler distribuire le richieste tra i pod con un rapporto 50/50. Inoltre, aumenteremo il numero di container v2 da uno a due, in questo modo:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
Ora impostiamo una regola di instradamento per distribuire il traffico tra i pod in un rapporto di 50/50.

Ecco come appare il risultato di questa regola:
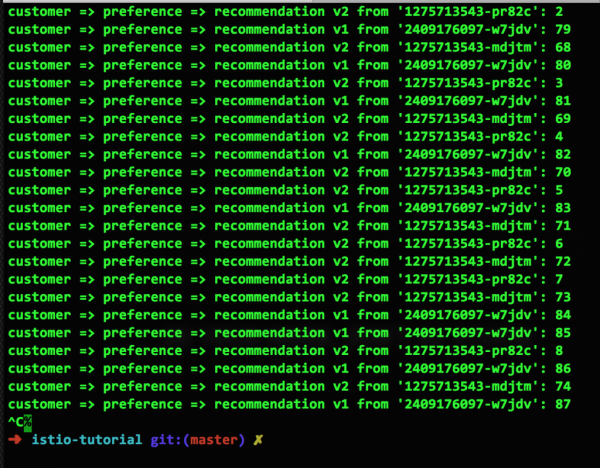
Si potrebbe obiettare che in questo screenshot non sia 50/50, ma 14:9, ma col tempo la situazione si stabilizzerà.
Causing a failure
Ora disabilitiamo uno dei due container v2, così avremo un container v1 funzionante, un container v2 funzionante e un container v2 guasto:
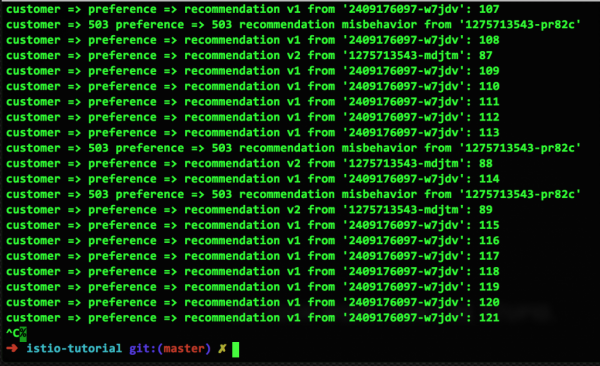
Fixing the failure
Quindi, abbiamo un container guasto e ora è il momento dell'Eiezione del Pool. Con una configurazione molto semplice, escluderemo questo container guasto da qualsiasi schema di instradamento per 15 secondi, con la speranza che torni a uno stato funzionante (o si riavvi, o ripristini le prestazioni). Ecco come appare questa configurazione e i risultati del suo funzionamento:

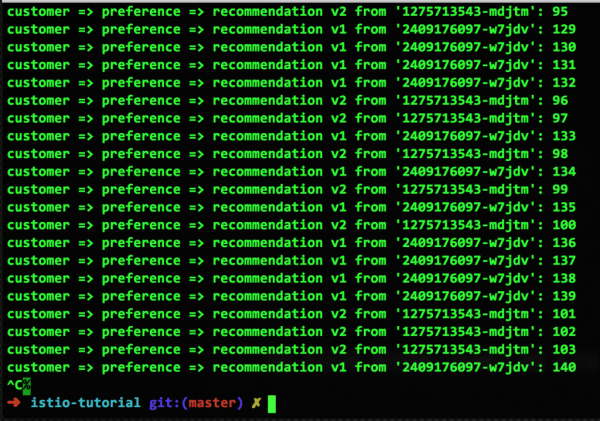
Come si può vedere, il container guasto v2 non viene più utilizzato per l'instradamento delle richieste, poiché è stato rimosso dal pool. Tuttavia, dopo 15 secondi tornerà automaticamente nel pool. Infatti, abbiamo appena mostrato come funziona l'Eiezione del Pool.
Iniziamo a costruire l'architettura
Il Pool Ejection, insieme alle capacità di monitoraggio di Istio, consente di iniziare a costruire un framework per la sostituzione automatica dei contenitori difettosi, riducendo così al minimo i tempi di inattività e i guasti.
La NASA ha un motto ben noto: Failure Is Not an Option, attribuito al direttore di volo . In italiano può essere tradotto come «Il fallimento non è un'opzione», e il significato qui è che tutto può funzionare se si ha abbastanza determinazione. Tuttavia, nella vita reale i guasti non accadono solo occasionalmente, sono inevitabili, ovunque e in ogni cosa. Come affrontarli nei microservizi? A nostro avviso, è meglio non fare affidamento sulla forza di volontà, ma sulle capacità dei contenitori. , , e .
Istio, come abbiamo già detto sopra, implementa magnificamente il concetto di interruttori automatici ben collaudato nel mondo fisico. Proprio come un interruttore elettrico disconnette una parte problematica del circuito, così il Circuit Breaker software in Istio interrompe la connessione tra il flusso delle richieste e il contenitore problematico quando c'è qualche problema con l'endpoint, ad esempio quando il server è andato in crash o ha iniziato a rallentare.
Nel secondo caso, i problemi diventano ancora più numerosi, poiché i rallentamenti di un container non solo causano ritardi a catena nei servizi che lo utilizzano e, di conseguenza, riducono le prestazioni complessive del sistema, ma generano anche richieste ripetute a un servizio già lento, aggravando ulteriormente la situazione.
Il Circuit Breaker in teoria
Il Circuit Breaker è un proxy che controlla il flusso delle richieste verso un endpoint. Quando questo endpoint smette di funzionare o, a seconda delle impostazioni configurate, inizia a rallentare, il proxy interrompe la connessione con il contenitore. Il traffico viene quindi reindirizzato ad altri contenitori per bilanciare il carico. La connessione rimane aperta (open) per un periodo di sospensione definito, diciamo due minuti, e poi viene considerata semi-aperta (half-open). Il tentativo di inviare la richiesta successiva determina lo stato successivo della connessione. Se il servizio funziona correttamente, la connessione torna attiva e si chiude (closed) nuovamente. Se invece ci sono ancora problemi con il servizio, la connessione viene interrotta e il periodo di sospensione si riattiva. Ecco come appare un diagramma semplificato del cambio di stato del Circuit Breaker:
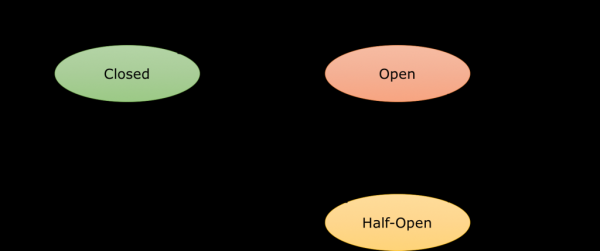
È importante notare che tutto ciò avviene a livello di architettura di sistema. Pertanto, a un certo punto, dovrete insegnare alle vostre applicazioni a lavorare con il Circuit Breaker, ad esempio, fornendo un valore predefinito in risposta oppure, se possibile, ignorando l'esistenza del servizio. A questo scopo si utilizza il pattern bulkhead, ma questo esula dall'argomento di questo articolo.
Circuit Breaker in pratica
Per esempio, eseguiremo due versioni del nostro microservizio di raccomandazioni su OpenShift. La versione 1 funzionerà normalmente, mentre in v2 inseriremo un ritardo per simulare un rallentamento del server. Per visualizzare i risultati utilizziamo lo strumento :
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
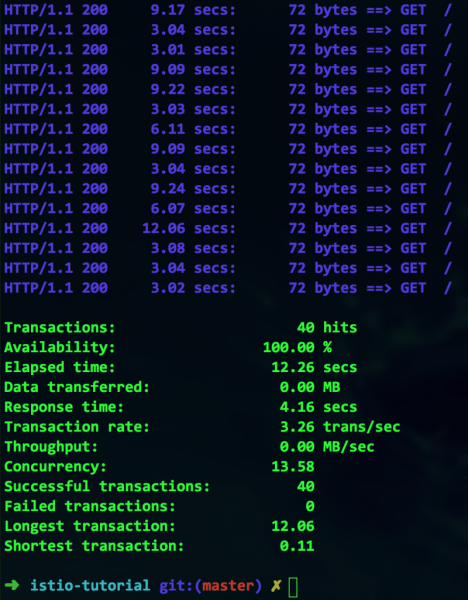
Tutto sembra funzionare, ma a che prezzo? A prima vista abbiamo il 100% di disponibilità, ma osservate meglio: la durata massima della transazione è di ben 12 secondi. Questo è chiaramente un collo di bottiglia, e deve essere ampliato.
Per fare ciò, utilizzeremo Istio per escludere le richieste ai contenitori lenti. Ecco come appare la configurazione corrispondente utilizzando il Circuit Breaker:

L'ultima riga con il parametro httpMaxRequestsPerConnection indica che la connessione deve essere interrotta quando si tenta di creare una nuova, seconda connessione oltre a quella già esistente. Poiché il nostro contenitore simula un servizio lento, tali situazioni si presenteranno periodicamente, e allora Istio restituirà un errore 503, ed ecco cosa mostrerà siege:
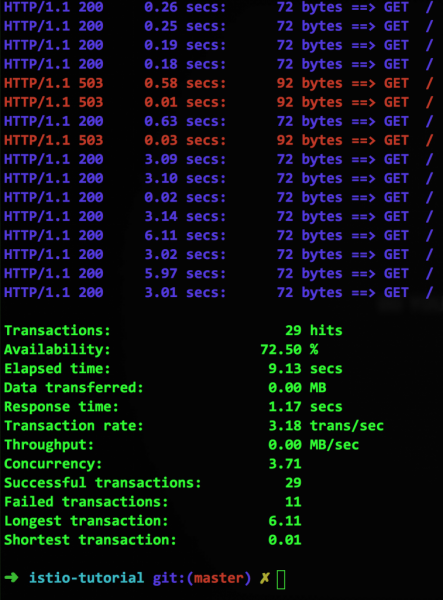
OK, abbiamo un Circuit Breaker, e adesso?
Quindi, abbiamo implementato l'auto-disconnessione senza toccare il codice sorgente dei servizi stessi. Utilizzando il Circuit Breaker e la procedura di Pool Ejection sopra descritta, possiamo rimuovere i contenitori lenti dal pool delle risorse fino a quando non tornano alla normalità e controllare il loro stato a intervalli regolari – nel nostro esempio, ogni due minuti (parametro sleepWindow).
Si noti che la capacità dell'applicazione di rispondere all'errore 503 è comunque definita a livello di codice sorgente. Esistono numerose strategie per lavorare con il Circuit Breaker, che vengono applicate a seconda della situazione.
Nel prossimo post: parleremo del tracciamento e del monitoraggio già integrati o facilmente aggiungibili in Istio, così come di come introdurre errori nel sistema in modo intenzionale.
Fonte: habr.com
