

Habr sta cambiando il mondo. Da oltre un anno gestiamo il nostro blog. Circa sei mesi fa abbiamo ricevuto un feedback del tutto sensato da parte degli utenti di Habr: «Dodo, dite sempre di avere un vostro sistema. Qual è questo sistema? E a cosa serve nella rete delle pizzerie?».
Ci siamo seduti, abbiamo riflettuto e capito che avevate ragione. Cerchiamo di spiegare tutto in modo semplice, ma risulta frammentario e non c'è una descrizione completa del sistema. Così ha avuto inizio un lungo viaggio di raccolta di informazioni, ricerca di autori e scrittura di una serie di articoli su Dodo IS. Iniziamo!
Ringraziamenti: grazie per condividere il vostro feedback con noi. Grazie a voi abbiamo finalmente descritto il sistema, elaborato un tech radar e presto presenteremo una grande descrizione dei nostri processi. Senza di voi, avremmo continuato a tergiversare per altri 5 anni.
La serie di articoli «Cos'è Dodo IS?» parlerà di:
- Il primo monolite in Dodo IS (2011-2015). (In progress…)
- Il percorso del back office: database separati e bus. (You are here)
- Il percorso della parte client: facciata sopra il database (2016-2017). (In progress…)
- Storia dei veri microservizi. (2018-2019). (In progress…)
- La conclusione della suddivisione del monolite e la stabilizzazione dell'architettura. (In progress…)
Se ti interessa sapere qualcosa in più, scrivi nei commenti.
Opinione sull'argomento descritto cronologicamente dall'autore
Regolarmente conduco un incontro per i nuovi assunti sul tema 'Architettura del sistema'. Noi la chiamiamo 'Introduzione all'Architettura del Dodo IS' ed è parte del processo di onboarding dei nuovi sviluppatori. Parlando, in un modo o nell'altro, della nostra architettura e delle sue peculiarità, ho sviluppato un certo approccio storico alla descrizione.
Tradizionalmente, consideriamo il sistema come un insieme di componenti (tecnici o più astratti), moduli di business che interagiscono tra loro per raggiungere un obiettivo. E se per la progettazione questo punto di vista è giustificato, per la descrizione e la comprensione non è del tutto appropriato. Le ragioni di questo sono molteplici:
- La realtà è diversa da ciò che è sulla carta. Non tutto ciò che è previsto viene realizzato. Ci interessa come si presenta e funziona realmente.
- Esposizione sequenziale delle informazioni. In sostanza, si può procedere cronologicamente dall'inizio fino allo stato attuale.
- Dalla semplicità alla complessità. Non è universale, ma nel nostro caso è proprio così. Dalle soluzioni più semplici, l'architettura è passata a quelle più complesse. Spesso l'aumento della complessità ha risolto problemi di velocità di implementazione e stabilità, oltre a decine di altre caratteristiche della lista dei requisiti non funzionali ( viene ben spiegato il confronto tra complessità e altri requisiti).
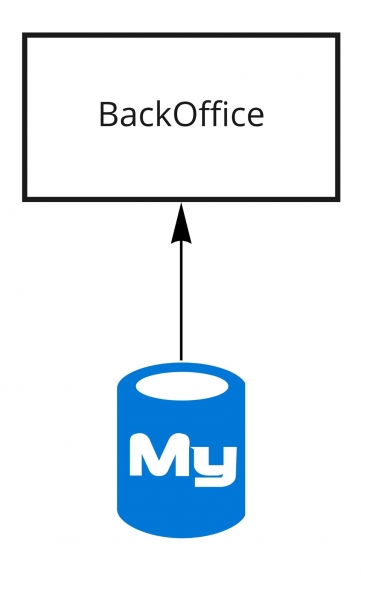
Nel 2011, l'architettura di Dodo IS appariva così:
Nel 2020 è diventata un po' più complessa e ha assunto questa forma:
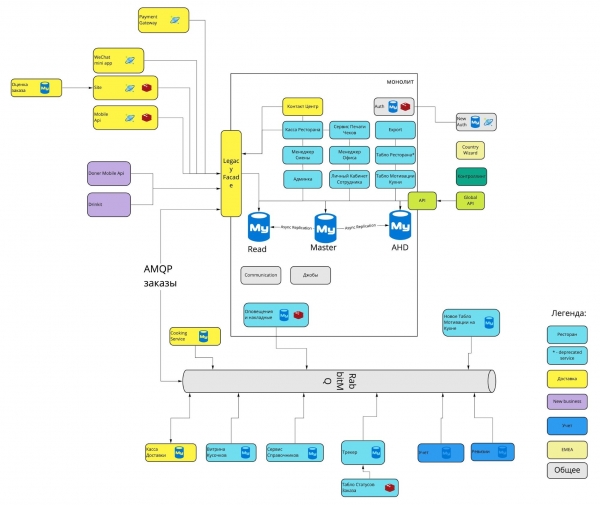
Come è avvenuta questa evoluzione? Perché sono necessarie diverse parti del sistema? Quali decisioni architetturali sono state prese e perché? Analizzeremo tutto in questa serie di articoli.
I primi problemi del 2016: perché i servizi devono uscire dal monolite
I primi articoli del ciclo parleranno dei servizi che si sono separati per primi dal monolite. Per introdurvi al contesto, racconterò quali problemi abbiamo riscontrato nel nostro sistema all'inizio del 2016 e cosa abbiamo dovuto affrontare per separare i servizi.
Un'unica base MySql, in cui tutte le applicazioni esistenti in quel momento in Dodo IS scrivevano i propri record. Le conseguenze sono state le seguenti:
- Un carico elevato (con l'85% delle richieste dedicate alla lettura).
- La base si è ampliata. A causa di ciò, il suo costo e il supporto sono diventati problematici.
- Punto di fallimento unico. Se un'applicazione che scrive nella base iniziava improvvisamente a farlo più attivamente, le altre applicazioni ne avvertivano l'impatto.
- Inefficienza nel storage e nelle query. Spesso i dati erano memorizzati in una certa struttura che era comoda per alcuni scenari, ma non adatta per altri. Gli indici acceleravano alcune operazioni, ma potevano rallentarne delle altre.
- Parte dei problemi è stata attenuata da cache affrettate e replica read dei database (di questo parleremo in un altro articolo), ma hanno solo permesso di guadagnare tempo e non risolvevano il problema in modo fondamentale.
Il problema era la presenza stessa del monolito.Le conseguenze furono le seguenti:
- Rilascio unico e raro.
- Difficoltà nella collaborazione di un gran numero di persone.
- Impossibilità di introdurre nuove tecnologie, nuovi framework e librerie.
I problemi con il database e il monolito sono stati descritti molte volte, ad esempio nel contesto dei guasti all'inizio del 2018 (, e ), quindi non mi soffermerò troppo. Vorrei solo sottolineare che volevamo offrire una maggiore flessibilità nello sviluppo dei servizi. Ciò riguardava in particolare quelli che erano i più impegnati e fondamentali dell'intero sistema: Auth e Tracker.
Il percorso del back office: database separati e bus
Navigazione del capitolo
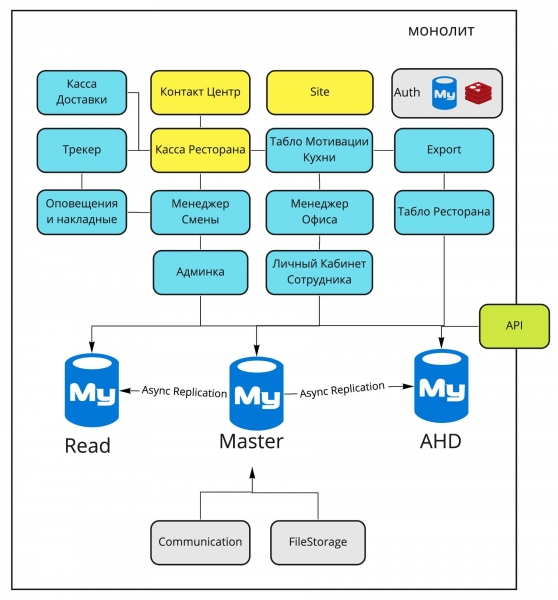
Schema del monolite del 2016
Di fronte a voi ci sono i principali blocchi del monolite Dodo IS del 2016, e un po' più in basso la descrizione delle loro principali funzioni.
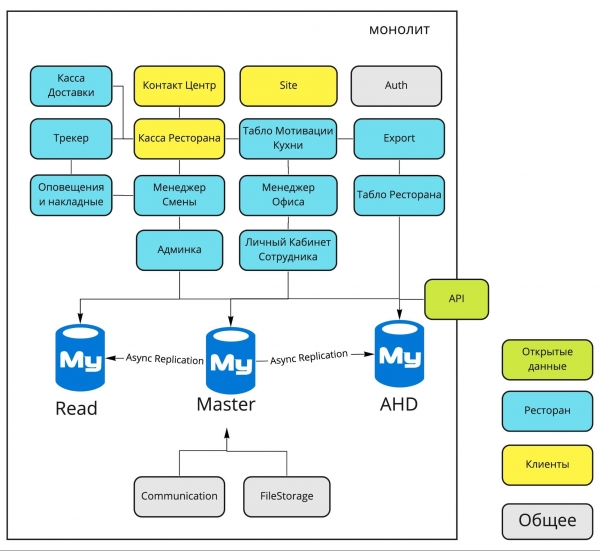
Cassa della Consegna. Gestione dei fattorini, assegnazione degli ordini ai fattorini.
Centro Contatti. Accettazione degli ordini tramite operatore.
Sito. I nostri siti (dodopizza.ru, dodopizza.co.uk, dodopizza.by, ecc.).
Auth. Servizio di autorizzazione e autenticazione per il back office.
Tracker. Tracker degli ordini in cucina. Servizio di registrazione degli stati di prontezza durante la preparazione dell'ordine.
Cassa del Ristorante. Accettazione degli ordini nel ristorante, interfacce del cassiere.
Esportazione. Esportazione dei rapporti in 1C per la contabilità.
Avvisi e bolle di accompagnamento. Comandi vocali in cucina (ad esempio, 'Nuova pizza ricevuta') + stampa delle bolle di accompagnamento per i fattorini.
Manager di Turno. Interfacce per la gestione del shift manager: elenco ordini, grafici delle prestazioni, output per il turno del personale.
Manager dell'Ufficio. Interfacce per i franchisee e il gestore: assunzione dei dipendenti, report sulle operazioni della pizzeria.
Dashboard del Ristorante. Visualizzazione del menu su televisori nelle pizzerie.
Pannello di Amministrazione. Impostazioni per una specifica pizzeria: menu, prezzi, contabilità, codici promozionali, campagne, banner per il sito, ecc.
Area Personale del Dipendente. Turni di lavoro dei dipendenti, informazioni sui dipendenti.
Dashboard di Motivazione della Cucina. Schermo separato che si trova in cucina e mostra la velocità di lavoro dei pizzaioli.
Comunicazione. Invio di sms ed email.
FileStorage. Servizio proprietario per ricevere e fornire file statici.
I primi tentativi di risolvere i problemi ci hanno aiutato, ma si sono rivelati solo una pausa temporanea. Non sono diventati soluzioni sistemiche, quindi era chiaro che dovevamo fare qualcosa con i database. Ad esempio, separare il database generale in più specialistici.
Iniziamo a sgravare il monolite: separazione di Auth e Tracker
Principali servizi che in quel periodo registravano e leggevano di più dal database:
- Auth. Servizio di autorizzazione e autenticazione per il back-office.
- Tracker. Tracker degli ordini in cucina. Servizio di marcatura degli stati di preparazione durante la creazione dell'ordine.
Cosa fa Auth
Auth è il servizio attraverso il quale gli utenti effettuano il login nel back office (del cliente è previsto un ingresso indipendente). Viene anche utilizzato per verificare che ci siano i diritti di accesso necessari e che questi diritti non siano cambiati dall'ultimo accesso. Attraverso di esso avviene anche l'accesso dei dispositivi nelle pizzerie.
Ad esempio, vogliamo aprire su un televisore appeso in sala un display con gli stati degli ordini pronti. Quindi apriamo auth.dodopizza.ru, selezioniamo 'Accesso come dispositivo', appare un codice che può essere inserito in una pagina speciale sul computer del manager di turno, specificando il tipo di dispositivo. Il televisore accederà automaticamente all'interfaccia corretta della propria pizzeria e inizierà a visualizzare i nomi dei clienti i cui ordini sono pronti.

Da dove provengono i carichi?
Ogni utente autenticato del back office, a ogni richiesta, interroga il database, nella tabella utenti, estrae l'utente tramite una query SQL e verifica se ha i diritti necessari e le autorizzazioni per questa pagina.
Ogni dispositivo fa la stessa cosa, ma con un database di dispositivi, verificando il proprio ruolo e i propri accessi. Un grande numero di richieste al master database porta al suo sovraccarico e al consumo delle risorse del database generale per queste operazioni.
Sgraviamo Auth
Con Auth, c'è un dominio isolato, cioè i dati sugli utenti, i logins o i dispositivi arrivano al servizio (che sarà futuro) e lì rimangono. Se qualcuno ha bisogno di queste informazioni, andrà a questo servizio per i dati.
C'ERA. Lo schema di lavoro era inizialmente questo:
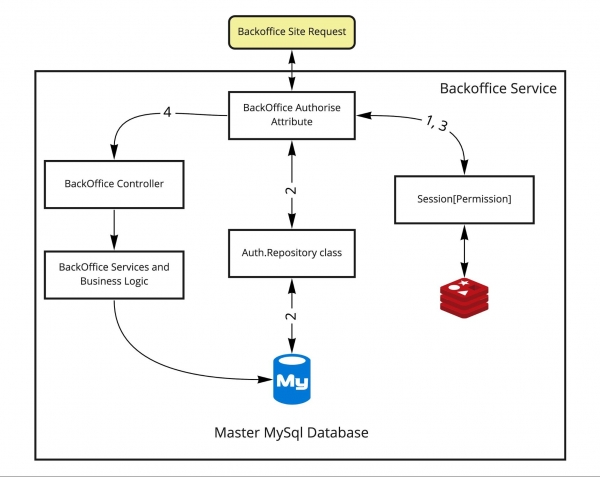
Vorrei chiarire un po' come funzionava:
- Una richiesta esterna arriva al backend (lì Asp.Net MVC), portando con sé un cookie di sessione, che viene utilizzato per ottenere i dati di sessione da Redis(1). In esso ci sono informazioni sugli accessi, e allora l'accesso al controller è aperto (3,4), oppure no.
- Se non ci sono accessi, è necessario passare attraverso la procedura di autorizzazione. Qui, per semplificare, è mostrata come parte del percorso nello stesso attributo, anche se si tratta di un passaggio alla pagina di login. In caso di scenari positivi, otterremo una sessione correttamente compilata e passeremo al Controller di Backoffice.
- Se ci sono dati, è necessario verificarli per la loro attualità nel database degli utenti. È cambiato il loro ruolo? Devono essere esclusi dalla pagina? In tal caso, dopo aver ottenuto la sessione (1), è necessario accedere direttamente al database e controllare i permessi dell'utente tramite il layer di logica di autenticazione (2). Successivamente, si procede o alla pagina di login, o al controller. Un sistema semplice, ma non del tutto standard.
- Se tutte le procedure sono state completate, si continua con la logica nei controller e nei metodi.
I dati degli utenti sono separati da tutti gli altri dati e si trovano in una tabella separata chiamata membership. Le funzioni del layer di logica AuthService possono facilmente diventare metodi API. I confini del dominio sono chiaramente definiti: gli utenti, i loro ruoli, i dati sui permessi, l'assegnazione e la revoca dei permessi. Tutto sembra indicare che si possa creare un servizio separato.
È FATTO. Così abbiamo proceduto:
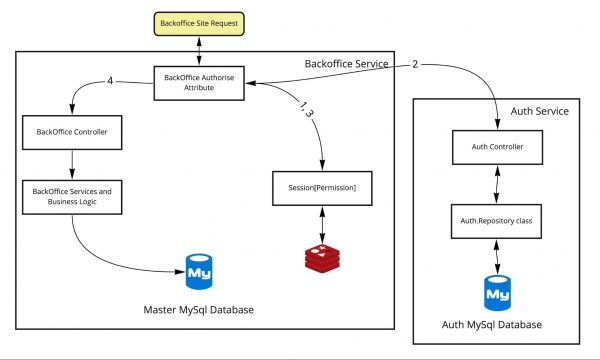
Questo approccio presenta una serie di problemi. Ad esempio, la chiamata a un metodo all'interno di un processo non è la stessa cosa di una chiamata http a un servizio esterno. La latenza, l'affidabilità, la manutenibilità e la trasparenza dell'operazione sono completamente diverse. Andrej Morevskij ha parlato in dettaglio di questi problemi nella sua presentazione. .
Il servizio di autenticazione e il servizio dispositivi vengono utilizzati per il backend, ovvero per i servizi e le interfacce utilizzate in produzione. L'autenticazione per i servizi client (come il sito web o l'app mobile) avviene separatamente senza utilizzare Auth. La separazione ha preso circa un anno e ora ci stiamo ancora occupando di questo tema, migrando il sistema verso nuovi servizi di autenticazione (con protocolli standard).
Perché la separazione è durata così a lungo?
Lungo il percorso ci sono stati molti problemi che hanno rallentato il processo:
- Volevamo trasferire i dati su utenti, dispositivi e autenticazione da database distribuiti nel paese a uno unico. Per questo è stato necessario convertire tutte le tabelle e il loro utilizzo da un identificatore int a un identificatore globale UUID (abbiamo recentemente rielaborato questo codice). e progetto open-source ). La conservazione dei dati degli utenti (poiché si tratta di informazioni personali) ha le sue limitazioni e per alcuni paesi è necessario conservarli separatamente. Tuttavia, l'identificatore globale dell'utente deve essere.
- Molte tabelle nel database hanno informazioni di audit sull'utente che ha effettuato l'operazione. Questo ha richiesto un meccanismo aggiuntivo per garantire la consistenza.
- Dopo la creazione dei servizi api c'è stata un lungo e graduale periodo di migrazione a un altro sistema. Le transizioni dovevano avvenire senza interruzioni per gli utenti e richiedevano lavoro manuale.
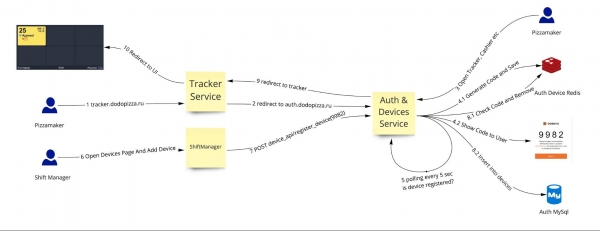
Schema di registrazione del dispositivo nella pizzeria:
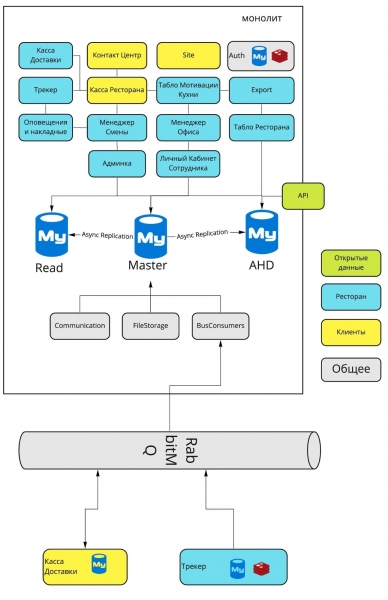
Architettura generale dopo l'isolamento del servizio Auth e Devices:
Nota. Nel 2020 stiamo lavorando a una nuova versione di Auth, che si basa sullo standard di autorizzazione OAuth 2.0. Questo standard è piuttosto complesso, ma sarà utile per lo sviluppo del servizio di autenticazione end-to-end. Nell'articolo «» abbiamo cercato di spiegare lo standard in modo semplice e chiaro, per farvi risparmiare tempo nello studio.
Cosa fa Tracker
Ora parliamo del secondo dei servizi sovraccarichi. Il tracker svolge un doppio ruolo:
- Da un lato, il suo compito è mostrare ai dipendenti in cucina quali ordini sono attualmente in lavorazione e quali prodotti devono essere preparati.
- Dall'altro, deve digitalizzare tutti i processi in cucina.

Quando un nuovo prodotto (ad esempio, una pizza) appare nell'ordine, esso entra nella stazione del tracker «Stesura». In questa stazione c'è un pizzaiolo che prende l'impasto della dimensione richiesta e lo stende, dopodiché segna sul tablet del tracker di aver completato il suo compito e passa la base stesa alla stazione successiva — «Farcitura».
Qui il prossimo pizzaiolo farcisce la pizza, poi segna sul tablet di aver completato il suo compito e mette la pizza nel forno (questa è anche una stazione separata che deve essere registrata sul tablet). Questo sistema è stato presente sin dall'inizio in Dodo e fin dall'esistenza di Dodo IS. Consente di monitorare e digitalizzare completamente tutte le operazioni. Inoltre, il tracker suggerisce come preparare ciascun prodotto, guida ogni tipo di prodotto attraverso i propri schemi di preparazione, conserva il tempo di cottura ottimale e tiene traccia di tutte le operazioni sul prodotto.
 Ecco come appare lo schermo del tablet nella stazione del tracker "Stesura".
Ecco come appare lo schermo del tablet nella stazione del tracker "Stesura".
Da dove provengono i carichi?
In ogni pizzeria ci sono circa cinque tablet con il tracker. Nel 2016 avevamo più di 100 pizzerie (ora più di 600). Ogni tablet effettua una richiesta al backend ogni 10 secondi e raccoglie i dati dalla tabella degli ordini (collegamento con il cliente e l'indirizzo), dal contenuto dell'ordine (collegamento con il prodotto e indicazione della quantità), e dalla tabella di registrazione delle motivazioni (in cui viene tracciato il tempo di pressione). Quando il pizzaiolo preme sul prodotto nel tracker, viene aggiornato il registro in tutte queste tabelle. La tabella degli ordini è condivisa, e contemporaneamente le nuove inserzioni avvengono all'accettazione dell'ordine, aggiornamenti da altre parti del sistema e numerosi accessi, ad esempio, sul televisore che è presso la pizzeria e mostra gli ordini pronti ai clienti.
Durante il periodo di gestione dei carichi, quando tutto e tutti venivano memorizzati nella cache e trasferiti su una replica asincrona del database, queste operazioni con il tracker continuavano a essere eseguite sulla master database. Non ci deve essere alcun ritardo, i dati devono essere aggiornati, la dissincronizzazione è inaccettabile.
Inoltre, l'assenza di tabelle proprie e indici su di esse non ha permesso di scrivere query più specifiche, orientate al proprio utilizzo. Ad esempio, per un tracker potrebbe essere utile avere un indice sulla pizzeria nella tabella degli ordini. Estraiamo sempre dal database del tracker gli ordini relativi alla pizzeria. In questo caso, non è così importante in quale pizzeria viene effettuato l'ordine, ciò che conta di più è quale cliente ha effettuato l'ordine. Questo significa che è necessario un indice per il cliente. Inoltre, per il tracker nella tabella degli ordini, non è obbligatorio memorizzare l'id dello scontrino stampato o le promozioni correlate all'ordine. Queste informazioni non interessano al nostro servizio di tracking. Nella monolitica base dati, le tabelle potevano essere solo una soluzione compromissoria tra tutti gli utenti. Questo era uno dei problemi iniziali.
C'ERA. Inizialmente l'architettura era questa:
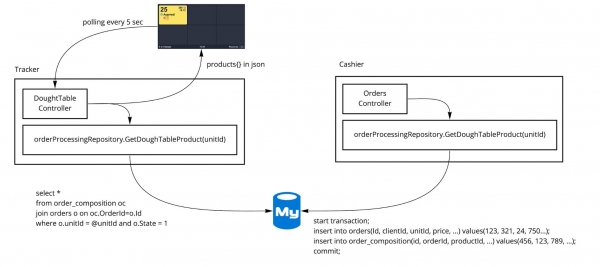
Anche dopo aver separato in processi distinti, gran parte del codice rimaneva comune a diversi servizi. Tutto ciò che era al di sotto dei controller era unico e viveva in un unico repository. Sono stati utilizzati metodi comuni per servizi, repository e un database condiviso, in cui erano presenti tabelle comuni.
Sgraviamo Tracker
Il problema principale con il tracker è che i dati devono essere sincronizzati tra diversi database. Questa è anche la sua principale differenza rispetto alla separazione del servizio Auth, poiché l'ordine e il suo stato possono variare e devono essere visualizzati in diversi servizi.
Accettiamo l'ordine al Punto Vendita del Ristorante (questo è un servizio), che viene salvato nel database con lo stato "Accettato". Successivamente, deve passare al tracker, dove cambierà ancora diverse volte il suo stato: da "Cucina" a "Imballato". Durante questo processo, l'ordine può subire alcuni interventi esterni da parte del Punto Vendita o dell'interfaccia del Manager di turni. Di seguito riporto una tabella con gli stati dell'ordine e le loro descrizioni:
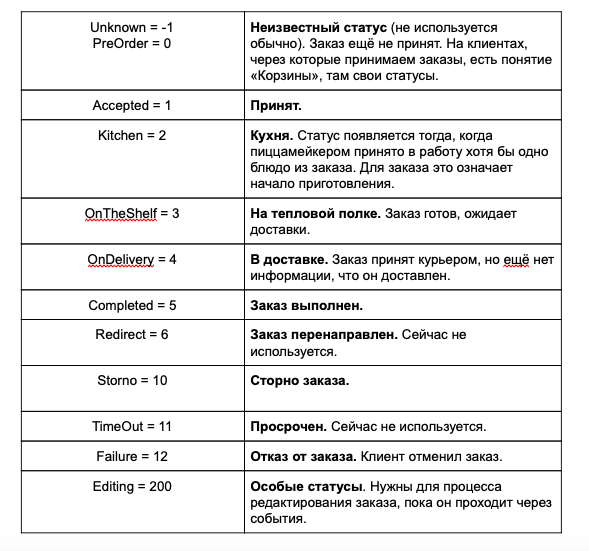
Lo schema di cambiamento degli stati dell'ordine è il seguente:
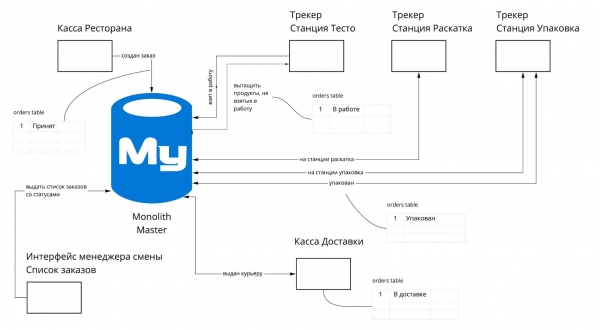
Gli stati cambiano tra diversi sistemi. In questo caso, il tracker non è l'ultimo sistema in cui si chiudono i dati. Abbiamo visto diversi approcci possibili per la separazione in tal caso:
- Concentriamo tutte le azioni dell'ordine in un unico servizio. Nel nostro caso, questa opzione richiede un servizio troppo grande per gestire l'ordine. Se ci fossimo fermati a questo, avremmo creato un secondo monolite. Non avremmo risolto i problemi.
- Un sistema chiama l'altro. La seconda opzione è già più interessante. Ma comporta possibili catene di chiamate (), una maggiore interconnessione dei componenti, gestirlo diventa più complesso.
- Organizziamo eventi, e ogni servizio scambia informazioni con gli altri tramite questi eventi. Alla fine, è stata scelta proprio la terza opzione, in cui tutti i servizi iniziano a scambiarsi eventi tra loro.
Il fatto che abbiamo scelto la terza opzione significava che il tracker avrebbe avuto il suo database, e per ogni modifica dell'ordine, inviava un evento che veniva sottoscritto da altri servizi e che, tra l'altro, finiva nel database master. Per questo avevamo bisogno di un servizio che garantisse la consegna dei messaggi tra i servizi.
Nel frattempo, avevamo già RabbitMQ nel nostro stack, quindi la decisione finale è stata di utilizzarlo come broker dei messaggi. Nello schema è mostrato il passaggio dell'ordine dalla Cassa del Ristorante attraverso il Tracker, dove cambia i suoi stati e la sua visualizzazione nell'interfaccia degli Ordini del manager. È DIVENTATO:
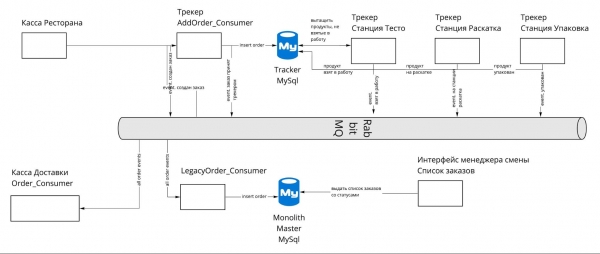
Percorso dell'ordine passo dopo passo
Il percorso dell'ordine inizia su uno dei servizi di origine degli ordini. Qui è la Cassa del Ristorante:
- All’uscita, l’ordine è completamente pronto e deve essere inviato al tracker. Si genera un evento a cui il tracker è iscritto.
- Il tracker, accettando l’ordine, lo salva nel proprio database, generando l’evento "OrdineAccettatoDalTracker" e inviandolo a RMQ.
- Nella bus degli eventi, ci sono già diversi gestori iscritti all’ordine. Per noi è importante quello che si occupa della sincronizzazione con il database monolitico.
- Il gestore riceve l’evento, estrae i dati significativi: nel nostro caso, lo stato dell’ordine "AccettatoDalTracker" e aggiorna la propria entità ordine nel database principale.
Se qualcuno ha bisogno dell’ordine esattamente dalla tabella monolitica degli ordini, può anche leggerlo da lì. Ad esempio, questo è necessario per l’interfaccia Ordini nel Gestore dei Turni:
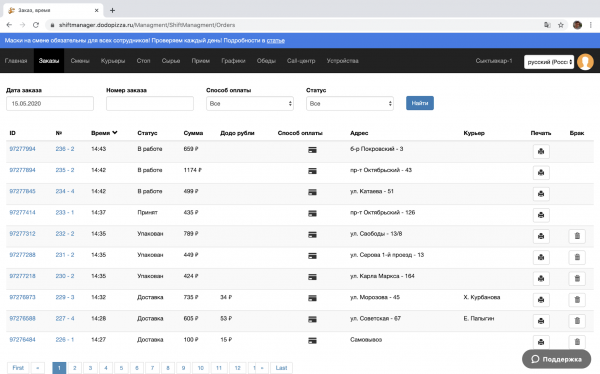
Anche tutti gli altri servizi possono iscriversi agli eventi degli ordini dal tracker, per utilizzarli a loro favore.
Se dopo un certo periodo l'ordine viene preso in carico, il suo stato cambia prima nel database (database del Tracker) e poi viene immediatamente generato un evento "OrdineInLavorazione". Questo viene anche inviato a RMQ, da cui si sincronizza nel database monolitico e viene recapitato ad altri servizi. Durante questo percorso possono sorgere vari problemi, che possono essere approfonditi nella relazione di Evgeny Peshkov. .
Architettura finale dopo le modifiche in Auth e nel Tracker
Ricapitolando: in principio pensavo di condensare la storia di nove anni del sistema Dodo IS in un solo articolo. Volevo raccontare rapidamente e semplicemente le tappe dell'evoluzione. Tuttavia, una volta immerso nel materiale, ho capito che tutto è molto più complesso e interessante di quanto sembri.
Riflettendo sull'utilità (o sulla sua assenza) di un tale materiale, sono giunto alla conclusione che uno sviluppo continuo non è possibile senza cronache complete degli eventi, retrospettive dettagliate e analisi delle proprie decisioni passate.
Spero che ti sia stato utile e interessante conoscere il nostro percorso. Ora mi trovo di fronte alla scelta su quale parte del sistema Dodo IS descrivere nel prossimo articolo: scrivi nei commenti o vota.
Solo gli utenti registrati possono partecipare al sondaggio. , per favore.
Quale parte di Dodo IS ti piacerebbe conoscere nel prossimo articolo?
24,1%Il monolite iniziale in Dodo IS (2011-2015)
24,1%I primi problemi e le loro soluzioni (2015-2016)
20,7%Il percorso della parte client: il front-end sopra il database (2016-2017)
36,2%La storia dei veri microservizi (2018-2019)
44,8%La conclusione del monolite e la stabilizzazione dell'architettura
29,3%Le future pianificazioni per lo sviluppo del sistema
19,0%Non voglio sapere nulla di Dodo IS
58 utenti hanno votato. 6 utenti si sono astenuti.
Fonte: habr.com
